How to turn EMS reliability into an always-on control-room playbook
Operational reliability in EMS is a discipline you execute in real time, not a chart to admire. This guide translates the chaos of shift-based commutes into a practical, control-room playbook you can run during every shift to prevent firefighting from reaching senior leadership. It lays out clear ownership, NOC responsibilities, and proven SOPs for incidents, with observable metrics and escalation paths that your team can actually execute within minutes, even in peak or off-hours.
Explore Further
Operational Framework & FAQ
Governance and ownership of reliability
Define who owns routing, rostering, and the NOC, and establish clear accountability with unambiguous escalation paths to prevent blame-shifting during SLA misses.
How do we split ownership between routing/rostering and the 24x7 control room so accountability is clear and we don’t get blame games after an SLA miss?
B1097 Clarify ownership between routing and NOC — In India’s corporate employee transportation (EMS), how should a CHRO and Head of Facilities set clear ownership between the routing/rostering team and the 24x7 command center (NOC) so that incident accountability is unambiguous and doesn’t turn into blame-shifting after an SLA miss?
In India’s employee mobility programs, incident accountability stays clear when the CHRO and Facilities Head define separate, written mandates for the routing/rostering team and the 24x7 command center, and then tie SLAs, logs, and escalations to those mandates instead of to individuals. Each team needs explicit “own this, decide this, log this” responsibilities across the trip lifecycle so post-incident reviews are about evidence and SOP compliance, not memory and opinion.
The routing/rostering team should own all “before the trip” decisions. This includes roster accuracy, entitlement and policy checks, vehicle and driver allocation, route design, and seat-fill targets. Their KPIs should cover data quality (correct shifts and addresses), planning lead time, dead mileage, and whether the planned routes respect safety and compliance rules like female-first policies and escort requirements.
The 24x7 command center (NOC) should own “during and after the trip” monitoring and intervention. This includes GPS-based live tracking, geo-fencing alerts, SOS escalation, exception handling, and real-time coordination with drivers, vendors, and security. Their KPIs should cover on-time performance, exception detection-to-closure time, incident handling within defined SLAs, and completeness of trip and incident audit trails.
To prevent blame-shifting after SLA misses, leaders should implement three guardrails. First, create a shared RACI-style matrix for the full ETS operation cycle that splits planning vs execution ownership and marks where joint decisions are required. Second, enforce tech-based evidence through duty slips, GPS logs, command-center dashboards, and incident tickets so that post-incident reviews rely on auditable data rather than conflicting narratives. Third, run structured post-incident reviews that check, step-by-step, whether the roster design, route approval, NOC alerts, and escalation SOPs were each followed, and then correct gaps in process or training instead of defaulting to personal blame.
Clear division of ownership also supports vendor governance and outcome-linked contracts. Routing KPIs can drive commercial levers around cost per employee trip, seat-fill, and dead mileage, while NOC KPIs can drive penalties and incentives around on-time performance, safety SLA adherence, and incident response quality. This separation of planning and live operations allows the CHRO to assure leadership that safety and employee experience are governed proactively, while the Facilities Head gets a practical, control-room-friendly model where each escalation has a predefined owner, time window, and evidence trail.
How can HR tell if our reliability problems are due to vendor capability or our own internal governance—like late rosters, weak policy adherence, or unclear escalation owners?
B1109 Vendor issue or internal governance issue — In India’s corporate employee mobility services (EMS), how can a CHRO tell whether operational reliability issues are primarily a vendor capability problem or an internal governance problem (late roster finalization, weak policy adherence, unclear escalation ownership)?
In corporate employee mobility in India, a CHRO can distinguish vendor capability issues from internal governance issues by checking where failures cluster in the trip lifecycle and what the data and SOPs show. Operational reliability usually breaks either at planning and policy stages inside the company or at execution and responsiveness stages with the vendor.
Vendor capability gaps typically show up after the plan is frozen. Common signals include missed SLAs despite stable rosters, poor fleet uptime, repeated GPS or app failures during live trips, and slow response from the command center during incidents. Patterns like frequent last-minute vehicle substitutions, high dead mileage despite fixed routes, or inability to maintain women-safety protocols even when rules are clear, usually indicate weak vendor command-center operations, routing, or driver management rather than HR or transport policies.
Internal governance gaps show earlier in the chain. Typical markers include late or frequently changing rosters from HRMS, unclear eligibility and policy rules for who is entitled to what service, and multiple exceptions being granted outside the standard EMS process. Escalation ambiguity is another strong indicator of internal issues, especially when nobody is sure who owns a delay or safety decision across HR, Facilities, and Security. If vendor reports and dashboards show they received final rosters late, or route optimization had to be rerun multiple times close to shift start, then internal governance is driving unreliability even if the vendor is technically competent.
A practical way for a CHRO to separate the two is to ask for three aligned artefacts and review them in a joint governance meeting. First, time-stamped roster and change logs mapped against OTP and no-show performance by shift window. Second, vendor command-center evidence such as trip logs, alert closure times, and fleet uptime or ETA adherence. Third, a clear escalation matrix and incident register showing who was called, when, and how often issues were resolved within agreed SLAs. If rosters are frozen on time, policies are stable, and escalations were triggered correctly yet performance KPIs like OTP, Trip Adherence Rate, and driver availability remain poor, then the root cause sits squarely with vendor capability. If most exceptions can be traced back to late changes, unmanaged hybrid-work attendance, or ad-hoc approvals, then the core problem is internal governance and policy discipline rather than the mobility operator.
images:

How do we decide if fixing driver/fleet governance will improve reliability more than buying new routing tech?
B1115 Driver governance vs routing tech trade-off — In India’s shift-based employee transport (EMS), how can a Head of Facilities evaluate whether better driver and fleet governance (substitution rules, performance reviews, retention incentives) will improve SLA reliability more than investing in new routing technology?
In India’s shift-based employee transport, Heads of Facilities typically see faster and more reliable SLA improvement from tightening driver and fleet governance than from adding another layer of routing technology. Governance closes daily failure modes like absentee drivers, poor discipline, and non-compliant vehicles, while routing tech works only if those fundamentals are stable and predictable.
Driver and fleet governance directly influences on-time performance, safety compliance, and escalation volume. The provided collateral shows that strong driver assessment and selection, structured training, compliance checks, and daily briefings support 98% on-time arrival in adverse conditions like monsoon traffic, and raise employee satisfaction. Systems such as Centralized Compliance Management, Alert Supervision, and Transport Command Centres also rely on reliable drivers and compliant vehicles to act on alerts quickly and prevent SLA breaches. Poorly governed fleets can nullify even advanced command centers or apps.
Routing technology typically improves dead mileage, seat fill, and route adherence once basic fleet uptime and driver reliability are under control. The context shows tech stacks with dynamic routing, driver apps, and command dashboards delivering better visibility and cost control, but their effectiveness still depends on drivers following manifests, maintaining duty cycles, and staying with the program. A common failure mode is investing in AI routing while still firefighting driver no-shows, fatigue, and ad-hoc substitutions.
A Head of Facilities can run a simple evaluation before prioritizing spend:
- Quantify current gaps in driver and fleet stability. Measure driver no-show rate, last-minute substitutions, vehicle breakdowns, and credential lapses versus route planning errors or app issues.
- Check whether existing tools are fully used. Verify if current routing and tracking features, command center workflows, and SOS and alert systems are consistently followed in daily shifts.
- Estimate impact on SLA. Model how many late pickups tie back to governance issues versus routing inefficiencies, and track how improved driver compliance and retention would change OTP% and incident escalations.
- Pilot governance changes first. Tighten substitution rules, run structured performance reviews, and implement driver incentives on one or two critical shifts while holding tech constant, then compare SLA reliability.
If most SLA breaches trace back to people and vehicle stability rather than routing logic, strengthening driver and fleet governance will usually deliver more SLA reliability, and will also make any future routing technology investment perform closer to its promised levels.
Reliability metrics, diagnosis, and ROI
Identify core metrics, root-cause analysis methods, and ROI validation that separate real bottlenecks from dashboard noise.
For our employee transport in India, what should we mean by “operational reliability,” and what are the few SLAs HR and transport should track beyond OTP?
B1094 Define operational reliability for EMS — In India’s corporate employee mobility services (EMS), what does “operational reliability” actually mean in day-to-day shift transportation, and how should HR, Facilities/Transport, and Procurement translate it into a small set of measurable SLAs beyond just on-time pickup/drop?
Operational reliability in India’s EMS context means that shift transport runs predictably and safely with minimal firefighting, where exceptions are surfaced early, handled within defined time limits, and are fully auditable. It is experienced day-to-day as stable routing and fleet uptime, safety and compliance by design, and a command-center that prevents issues from reaching employees and leadership.
In practice, operational reliability is built on governed EMS operations rather than ad-hoc vendor dispatch. It depends on shift-aligned rostering and route planning, real-time tracking, driver and vehicle compliance, and a 24x7 command center or NOC that manages alerts, escalations, and business continuity. A common failure mode is focusing only on basic OTP percentages while ignoring exception closure time, compliance drift, and night-shift safety governance.
HR, Facilities/Transport, and Procurement should therefore convert “reliability” into a compact SLA set that goes beyond on-time pickup/drop and that can be tied to outcome-based contracts:
- Service Reliability SLAs. On-Time Performance (OTP%) by shift band, Trip Adherence Rate (planned vs actual routes completed), and exception detection-to-closure time for missed pickups, app failures, or vehicle breakdowns.
- Fleet & Uptime SLAs. Fleet Uptime %, minimum standby/buffer availability per shift window, and dead mileage caps to prevent chronic under-utilization or last-minute shortages.
- Safety & Compliance SLAs. Zero-tolerance metrics for serious incidents, driver and vehicle compliance currency (licences, permits, fitness), women-centric night routing adherence, and audit trail completeness for trips and SOS events.
- Experience & Escalation SLAs. Complaint closure SLA by severity, NOC responsiveness (who answers at 2 a.m. and in how many minutes), and basic Commute Experience or satisfaction scores per site or shift.
HR should own safety, women’s night-shift governance, and experience-linked SLAs. Facilities/Transport should own control-room metrics such as uptime, buffers, routing quality, and exception closure. Procurement should embed these SLAs into contracts as outcome-linked commercials, with clear penalties for chronic breach and protections against vendor lock-in.
In our shift commute program, what usually causes repeated SLA misses—routing, rostering changes, fleet/driver issues, or weak escalations—and how do we figure out the real bottleneck before switching providers?
B1095 Diagnose true causes of SLA misses — In India’s corporate ground transportation for shift-based employee commutes (EMS), what are the most common root causes of repeated SLA breaches—routing logic, rostering/late changes, fleet/driver governance, or command-center escalation—and how can a buyer diagnose which one is the true bottleneck before changing vendors?
In shift-based employee mobility in India, repeated SLA breaches usually trace back to weak rostering and late-change handling, followed by routing logic gaps and fleet/driver governance issues, with command-center escalation failures acting as an amplifier rather than the first cause. A buyer can isolate the true bottleneck by correlating breach patterns with roster timestamps, routing exceptions, vehicle/driver availability, and escalation logs before blaming the vendor or the app.
Most operations see the first cracks at the roster stage. Frequent last-minute shift changes, manual overrides, and poor HRMS–transport integration create unstable demand signals. Routing engines then “optimize” on bad inputs, which leads to unrealistic ETAs, dead mileage, and missed pickups. Fleet and driver governance issues surface as high absenteeism, fatigue, and non-compliant vehicles, which directly impact On-Time Performance and safety SLAs. Command-center failure usually shows up as slow response to predictable patterns, weak alerting, and lack of a clear escalation matrix.
A practical diagnosis approach is to treat this as a control-room audit instead of a vendor blame exercise and to use a short, focused review window.
- Pull a 30–60 day SLA report split by time band, route type, and site, and mark where breaches cluster.
- Overlay roster change logs and HRMS attendance data to see if peaks match late bookings or manual edits.
- Compare planned vs actual routes, seat-fill, and dead mileage to test routing logic and capacity planning.
- Review driver and vehicle rosters for the same days against compliance and availability records.
- Check NOC/command-center tickets for alert time, first response time, and closure time on those trips.
If SLA failures spike when rosters are stable, the root is usually routing logic or fleet governance. If they spike exactly when rosters are edited late, rostering and policy are the bottleneck. If alerts are raised on time but not acted on, command-center process and escalation design need fixing.
What reliability metrics will actually reduce night escalations—MTTD/MTTR, missed pickups, no-shows, vendor response time—and how do we govern them across sites and vendors?
B1096 Metrics that reduce night escalations — In India’s enterprise-managed employee mobility services (EMS), what reliability metrics best predict “3 AM escalation risk” for the Facilities/Transport head—mean time to detect, mean time to recover, missed pickups, no-shows, or vendor response latency—and how should those be governed across multiple sites and vendors?
In India’s enterprise employee mobility operations, the strongest leading indicators of “3 a.m. escalation risk” are missed pickups, no‑shows, and vendor response latency. Mean time to detect (MTTD) and mean time to recover (MTTR) matter, but only after these front-line failures have already created a problem for the Facilities/Transport head.
Missed pickups and no‑shows directly convert into late logins and safety escalations. Vendor response latency determines whether a small issue (driver stuck, GPS failure, app glitch) is contained quietly or becomes a multi-level crisis. MTTD and MTTR are useful NOC and command-center metrics, but they are secondary for the operator who is judged on whether employees got to the gate on time and safely.
Governance across sites and vendors works best when these metrics are standardized and surfaced in a single command-center view. Most organizations rely on a centralized or dual-command structure with a 24/7 Transport Command Centre or NOC that monitors OTP%, missed pickup count, no-show rate, and live exceptions across all EMS locations and vendors. This model allows local command centers or site teams to act quickly, while a central team enforces common SLAs and escalation rules.
Effective governance uses vendor-agnostic definitions of missed pickup, no‑show, and response time. It also links these to clear escalation matrices, buffer capacity rules, and business continuity playbooks that cover cab shortages, tech failures, weather, and strikes. Vendors are then tiered and reviewed based on consistent performance against these reliability indicators rather than self-reported data.
images:
As Finance, how do we verify routing/rostering improvements are real—less dead mileage, better seat-fill, less manual work—and not just dashboard reporting, especially with multiple vendors?
B1100 Validate routing ROI beyond dashboards — In India’s corporate employee transportation (EMS), what’s the practical way for a CFO to validate that improvements in routing and rostering are real (reduced dead mileage, higher seat-fill, fewer manual interventions) rather than just dashboard optics, especially in a multi-vendor program?
A CFO can validate routing and rostering improvements only by tying “optimization” claims directly to reconciled trip data, fuel/billing baselines, and exception logs, instead of relying on front-end dashboards alone. The verification needs to follow the money, the kilometers, and the exceptions across all vendors, and it must be repeatable month after month.
A practical starting point is to lock in a pre‑change baseline for cost per kilometer, cost per employee trip, dead mileage, Trip Fill Ratio, and exception volumes such as manual overrides and ad‑hoc dispatches. These baselines should be built from vendor trip logs, GPS data, and current invoices so they are auditable. After new routing and rostering logic goes live, Finance can demand the same metrics from the same sources, but now under a normalized schema that covers every vendor in the program.
A strong signal that improvements are real is when reduced dead mileage, higher seat‑fill, and better Vehicle Utilization Index correlate with lower CET/CPK and fewer disputes during billing reconciliation. An equally important signal is a drop in manual interventions recorded by the command center, such as emergency re‑routing, manual roster edits, or off‑system trips. If dashboard trends look positive but dead kilometers, CET, exception counts, or SLA breach penalties do not move in the same direction, the CFO can treat the “optimization” as cosmetic.
In multi‑vendor environments, CFOs can insist on a common trip ledger and service-level reporting format for all partners. Vendors should provide trip‑level data exports that align with Finance and Procurement’s settlement logic, so outcome‑based contracts that reference OTP%, Trip Adherence Rate, and seat‑fill can be computed independently of any one vendor’s platform. This cross-checking approach makes routing and rostering gains financially defensible instead of just visually impressive.
What should we ask to confirm the vendor can handle peak loads—multiple shifts, last-minute roster changes, festival surges—without the control room becoming a bottleneck?
B1113 Prove peak-load reliability beyond headcount — In India’s corporate employee commute operations (EMS), what should a buyer ask to confirm the vendor can sustain reliability during peak loads (multiple shift windows, sudden roster edits, festival surges) without the command center becoming a human bottleneck?
In India’s employee mobility operations, a buyer should press vendors on how they avoid “command center overload” by using automation, clear buffers, and exception-based control instead of manual micro-management. The questions should test routing intelligence, capacity planning, and NOC design across multiple shift windows, surges, and last-minute roster edits.
Buyers should probe how routing and capacity are handled under stress. They should ask how the vendor models shift windowing, seat-fill targets, and dead-mile caps during peak EMS loads. They should ask how dynamic route recalibration works when rosters change late, and what SLA exists for re-routing after a last-minute employee add/cancel. They should ask for quantified examples of On-Time Performance under festival traffic or weather disruptions, and how often manual overrides are needed.
Buyers should test the vendor’s command center operating model. They should ask if operations run on a 24x7 central command center with regional hubs, or on ad-hoc local desks. They should ask what exception management SLAs, escalation matrices, and automated alerts exist for no-shows, GPS failure, or driver shortages. They should ask how many trips a single controller can supervise concurrently and which tasks are automated versus manual.
Buyers should verify technology and data integration that reduce human bottlenecks. They should ask how HRMS integration drives automated roster ingestion rather than spreadsheet uploads. They should ask whether routing engines, driver apps, and passenger apps are tightly integrated with the NOC tools, and how often the vendor falls back to fully manual operations. They should ask what observability exists around OTP%, Trip Adherence Rate, and exception closure time during peaks.
Buyers should insist on playbooks and BCP for surges. They should ask for documented peak-load and festival playbooks, including buffer fleet policies, pre-booked capacity, and alternate routing options. They should also ask how driver fatigue is managed when multiple peaks cluster, and how driver retention is protected while maintaining SLA reliability.
NOC design, incident response, and escalation playbooks
Describe the 24x7 command center responsibilities, runbooks, and escalation matrices that keep operations calm under pressure and ensure rapid containment during disruptions.
What does a real playbook-driven model look like for common exceptions, and how do we ensure the playbooks are actually followed on ground, not just written?
B1102 Verify playbooks are followed on-ground — In India’s corporate employee mobility services (EMS), what does a credible ‘playbook-driven’ operating model look like for exceptions (no-shows, vehicle breakdowns, last-minute roster changes, app/GPS failures), and how should leadership check that playbooks are actually used in the field—not just documented?
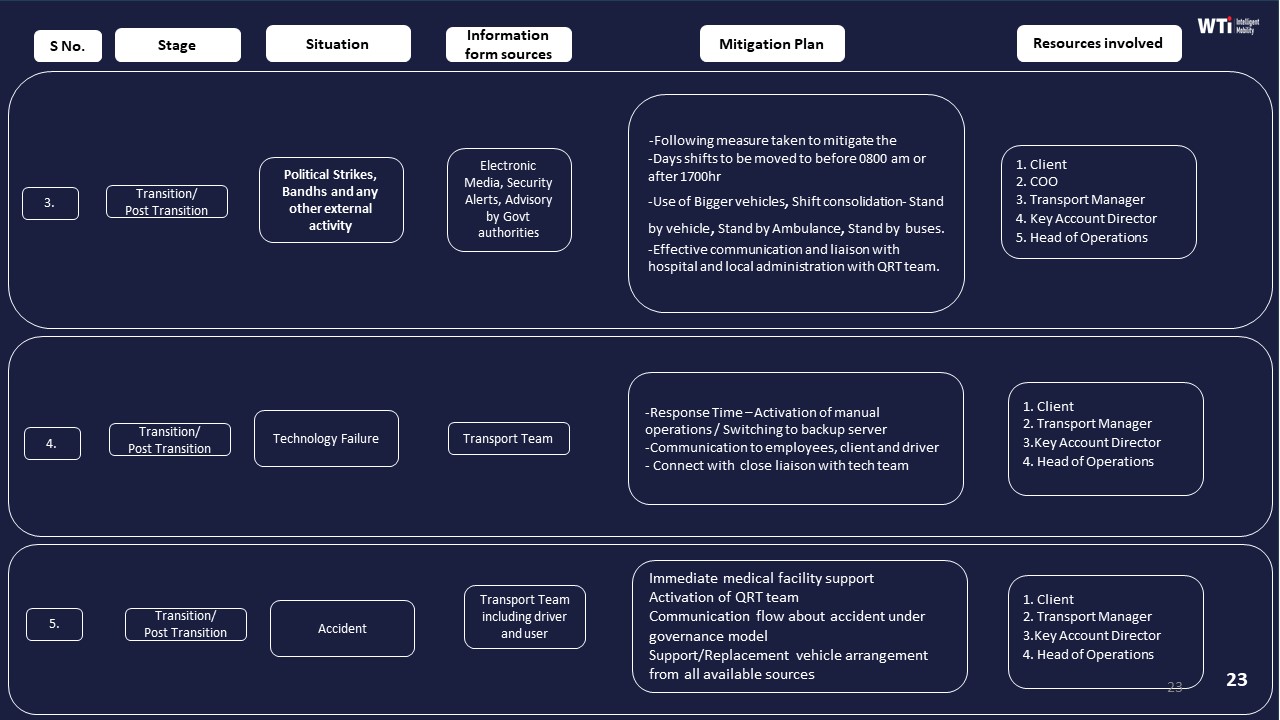
A credible playbook-driven EMS exception model in India is built around clear, pre-approved SOPs for every common exception type, 24x7 command-center execution, and audit-ready evidence for every decision taken on the ground. Leadership should verify it by checking live command-center behaviour, incident closure metrics, and random trip-level evidence, not just policy documents.
A robust exception playbook separates each scenario into distinct flows such as no-show, vehicle breakdown, last-minute roster change, and tech failure like app or GPS downtime. Each flow carries clear triggers, time-bound actions, defined communication templates to employees and security, and escalation paths for when first-line fixes fail. The playbooks work best when they are embedded into a central command centre or Transport Command Centre workflow with real-time alerts, geo-fencing breaches, SOS triggers, and routing changes flowing through one console instead of ad-hoc calls and chats.
A credible model also encodes buffers and BCP measures directly into operations. Examples include pre-tagged standby vehicles for breakdowns, pre-planned re-routing rules during monsoon or strike conditions, and manual fallbacks for app outages such as SMS manifests, voice-based location verification, and paper duty slips that can be reconciled later. Driver fatigue limits, women-safety escort rules, and HSSE escalation matrices should be part of the same playbooks so that safety is not compromised in the rush to recover OTP.
Leadership should test real usage through a few concrete checks. They can review command-centre dashboards for exception-volume trends, closure times, and percentage of exceptions closed within SOP timelines. They can ask for 5–10 randomly chosen exception cases from the last month and reconstruct each one from alert to closure, verifying timestamps, communication logs, and approvals. They should also speak directly with night-shift transport staff and drivers to see whether they can explain exception steps from memory, which indicates operational adoption instead of “PowerPoint adoption.”
Leadership can strengthen assurance by tying vendor payouts and internal KPIs to measurable exception metrics such as exception closure SLA compliance, repeat exceptions on the same route or vehicle, and incident-free recoveries for women night-shift trips. They should require audit-ready reports that combine GPS or telematics traces, command-centre actions, and employee feedback for each serious exception so that every recovery step is reconstructable in an investigation or audit. Regular joint drills using BCP scenarios such as cab shortages or political strikes help validate whether the playbooks work at 2 a.m., not only during reviews.
images:
How do we measure NOC toil—manual calls, spreadsheet tracking, follow-ups—so we can judge if a new platform will actually reduce workload instead of just moving it elsewhere?
B1103 Measure and reduce NOC toil — In India’s shift-based employee transportation (EMS), how should a Head of Facilities quantify operational ‘toil’ in the NOC (manual calls, spreadsheet triage, repeated follow-ups) and use that baseline to evaluate whether a platform or managed service will truly reduce workload rather than shifting it around?
In shift-based employee transport, a Head of Facilities should quantify NOC “toil” as measurable, recurring manual effort per shift and then compare that baseline against a target operating model where exceptions are handled by rules, automation, and a 24x7 command center rather than by ad‑hoc calls and spreadsheets.
Toil in a transport NOC is best quantified around four buckets. Manual exception handling covers calls and chats to fix late cabs, wrong routes, no‑shows, or driver shortages. Roster and route triage covers spreadsheet work to rebalance loads after last‑minute shift or attendance changes. Compliance and safety chasing covers manual follow‑ups for driver KYC, escort rules, women‑safety policies, and incident documentation. Coordination overhead covers time spent aligning HR, security, vendors, and employees when things go wrong.
A practical baseline usually starts with time sampling and tagging. Operations teams can track, for a representative week, how many tickets or calls were handled, how many minutes per ticket were spent on manual triage, and how many incidents were repeated because root causes were not structurally fixed. These measurements can be linked to known EMS outcomes such as on‑time performance, trip adherence, driver fatigue, and no‑show rates to show how current toil masks deeper reliability gaps.
When evaluating a platform or managed service, the Head of Facilities should insist on explicit workload hypotheses. Vendors should show which current manual steps will move into automated routing, integrated driver and rider apps, or a centralized command center with defined SLAs. It is important to check whether features like real‑time tracking, geo‑fencing, and smart dispatch actually reduce exception volume or only create more alerts that operators must clear manually. A common failure mode is replacing one large spreadsheet with multiple dashboards that still require the NOC to orchestrate every exception.
Clear evaluation criteria can prevent this shift of work. The NOC can define target metrics for reduction in manual calls per 100 trips, reduction in after‑hours escalations, and reduction in average exception handle time. Any EMS platform or managed service should be assessed on its ability to deliver these reductions without compromising safety, women‑centric routing rules, business continuity plans, or compliance audit trails. The most effective solutions usually combine automation with a governed central command center so that operational toil is structurally redesigned rather than just redistributed.
What uptime and performance expectations should we set for the rider/driver apps and control-room tools so operations don’t fail during peak shifts or poor connectivity?
B1107 Set app and NOC performance expectations — In India’s corporate employee transportation (EMS), how should a CIO and Head of Facilities define uptime/latency expectations for rider and driver apps and the NOC tooling, so operational reliability doesn’t collapse when connectivity is poor or systems degrade during peak shift windows?
In Indian EMS programs, CIOs and Facility Heads should define uptime and latency expectations so that rider and driver apps remain usable and the NOC stays “situationally aware” even when networks or back-end systems degrade. Uptime targets must be paired with offline-first behavior, graceful degradation, and clear SOPs for peak windows rather than relying only on a headline “99.9%.”
CIOs should set differentiated SLOs instead of a single blanket number. The highest priority is the trip lifecycle and safety-critical flows. That includes roster and route visibility, OTP-based trip start, live GPS updates to the command center, and SOS or panic events flowing into NOC tooling. Latency expectations for these flows need to be strict during shift start and end windows, because this is when poor performance immediately converts into escalations, no-shows, and safety anxiety.
The Facilities or Transport Head should insist that apps and NOC tooling fail “operationally safe” in low-connectivity zones. Rider and driver apps should cache manifests, routes, and OTPs in advance of the shift window. The system should queue telematics and trip events locally and sync when the network returns. NOC views should continue to show the last known good position, route, and ETA, with visible indicators that data is stale so controllers can fall back to voice coordination.
Together, CIO and Facilities should formalize an observability and response model anchored in operations. That means defining monitoring around trip start success rate, telemetry freshness, exception detection-to-closure time, and command-center uptime during known high-stress windows, instead of generic API health alone. It also means codifying escalation paths and manual reversion SOPs for when routing, GPS, or apps degrade, so night-shift operators do not have to improvise under pressure.
To translate these principles into practical guardrails, joint CIO–Facilities specifications commonly include:
- Separate SLOs for trip-critical APIs and background analytics.
- App behavior requirements for offline-first operation in coverage gaps.
- NOC tooling expectations for dealing with delayed or partial telemetry.
- Playbooks that specify when and how to switch to voice or SMS coordination.
By defining uptime and latency in terms of how many trips can be safely and punctually completed under degraded conditions, rather than only in terms of raw percentages, CIOs and Facility Heads can protect daily reliability even when networks and systems are under strain.
What questions confirm the vendor’s control room can actually solve incidents—with decision rights and backup vehicles—instead of just logging tickets?
B1121 Assess whether NOC can resolve incidents — In India’s corporate employee mobility services (EMS), what should a senior Facilities/Transport leader ask to assess whether a vendor’s NOC is truly empowered to resolve incidents (decision rights, access to fleet substitutes, escalation authority) rather than acting as a call center that only logs tickets?
A senior Facilities or Transport leader should probe how a vendor’s NOC makes decisions in real time, what levers it can pull on its own, and what evidence exists that those levers are actually used during live shifts. The core test is whether the NOC owns outcomes like OTP%, safety closure SLAs, and business continuity, or merely records issues for others to fix later.
A first focus area is decision rights and on-ground control. Leaders should ask who in the NOC is authorized to reroute trips, swap vehicles, or overrule static routes during disruptions. It is important to check whether the NOC can directly call out buffer vehicles from standby fleets defined in business continuity plans. It is also critical to confirm whether the NOC controls vendor allocation rules across multi-vendor supply and can trigger escalation to alternative suppliers when a primary vendor fails.
A second focus area is access to substitutes and continuity levers. Leaders should ask how many standby cabs are tagged in the system during peak and night hours. It is important to confirm whether the NOC has visibility over both ICE and EV fleets and can reallocate between them when EV charging or range issues occur. It is also relevant to validate if the NOC can activate contingency playbooks documented in business continuity collateral for technology failures, strikes, and weather events.
A third focus area is escalation authority and closure discipline. Leaders should ask for the formal escalation matrix from ground supervisor up to key account manager level and confirm time-bound thresholds. It is important to see how the NOC integrates with alert supervision systems for geofence violations, overspeeding, and women-safety incidents. It is essential to verify that the NOC runs a command-center style operation with clear incident response SOPs, audit logs, and management reports on exception detection-to-closure time.
Useful signals include single-window dashboards that combine routing, safety, and CO₂ metrics, transport command centre process diagrams, and documented business continuity plans with named roles and timelines. Vendors whose NOC is tied to measurable SLA outcomes, data-driven insights, and real-time fleet visibility are more likely to operate as empowered control rooms rather than passive ticketing desks.
What is a mobility command center/NOC, why does it matter for reliability, and what should it be responsible for beyond just tracking vehicles on a map?
B1123 Explain mobility command center and purpose — In India’s corporate employee mobility services (EMS), what is a “command center/NOC” at a high level, why is it considered table stakes for reliability, and what are the most important responsibilities it must own besides monitoring GPS on a map?
A command center or NOC in corporate employee mobility is a 24x7 control room that owns real-time visibility, exception handling, and SLA governance across all employee transport operations. It is considered table stakes for reliability because shift adherence, women’s safety compliance, and on-time performance now depend on continuous supervision, fast escalation, and auditable evidence, not just vendor promises or driver apps.
A command center in EMS consolidates data from routing engines, driver and employee apps, telematics, and compliance systems into a single operational view. Command center operations are a core element of the target operating model for Employee Mobility Services and are directly linked to OTP, safety incident response, and SLA adherence. Most organizations treat this as the internal “operations command center” for HR, Security, and Transport teams.
The command center’s responsibilities extend far beyond watching GPS pins. Critical ownership areas include:
- Exception detection and closure. Detect delays, route deviations, no-shows, and app/GPS failures early and drive closure within defined SLAs.
- Incident readiness and escalation. Run panic/SOS workflows, women-safety protocols, escort compliance checks, and incident response SOPs with an audit trail.
- Governance and SLA tracking. Track OTP%, Trip Adherence Rate, incident rates, and closure times against contracts and trigger penalties or improvements.
- Business continuity and resilience. Execute playbooks for cab shortages, political strikes, tech outages, and extreme weather using predefined BCP plans.
- Compliance assurance. Enforce driver KYC/PSV validity, vehicle fitness, route approvals, and night-shift safety rules through continuous checks, not just periodic audits.
- Data quality and auditability. Ensure trip logs, GPS traces, and incident records are complete, tamper-evident, and ready for HR, Finance, ESG, and safety audits.
- Feedback and continuous improvement. Aggregate complaints, NPS, and route-level issues into changes in routing, fleet mix, and vendor governance.
Without a command center that owns these functions, EMS programs revert to fragmented vendor control, manual firefighting, and unverifiable claims about safety, cost, and carbon impact.
What do runbooks and escalation matrices mean in employee transport, and how do they reduce chaos during peak shifts without creating extra bureaucracy?
B1124 Explain runbooks and escalation matrices — In India’s shift-based employee transport (EMS), what do “runbooks” and “escalation matrices” mean for non-technical stakeholders, and how do they reduce operational chaos during peak shifts or disruptions without adding bureaucracy?
In India’s shift-based employee transport, a “runbook” is a written step-by-step playbook for common transport situations, and an “escalation matrix” is a clear map of who gets called, in what order, when something goes wrong. Together they turn night-shift chaos into repeatable responses so issues are handled the same way every time, instead of through ad‑hoc decisions and blame.
A runbook in EMS translates daily transport work into simple SOPs. Each runbook covers a scenario such as first-trip dispatch, no‑show employee, vehicle breakdown, GPS failure, heavy rain/strike, or night-shift women-safety routing. It lists in order what the transport desk, command center, driver, and security must do, what time limits apply, what to log, and when to switch to backup (standby cabs, alternate routing, manual calling). This reduces dependence on one “hero” operator and allows new staff to manage shifts with confidence.
An escalation matrix defines who is responsible at L1, L2, L3 for each type of issue, with time limits and channels. For example, a routing issue may start with the router or shift executive, then move to transport lead, then vendor key account manager or security if safety is involved. This avoids random calls to leadership, ensures the right person answers the phone at 2 a.m., and gives HR and Security a predictable path for serious incidents.
These tools reduce bureaucracy when they are short, scenario-based, and tied to real-time alerts from the command center or EMS platform. Most organizations keep them to one page per scenario, link them to simple dashboards and SMS/IVR/app alerts, and review them only in monthly or quarterly reviews. As a result, peak shifts feel calmer, OTP stabilizes, and fewer issues reach senior leadership because frontline teams know exactly what to do and whom to involve, without needing fresh approvals in the middle of a disruption.
Expansion, multi-site governance, and vendor coordination
Set rules for regional expansion, Tier-2/3 coverage, and multi-vendor reliability to prevent fragmentation and protect SLA strength during growth.
If we expand into Tier-2/3 cities, when should we run a central 24x7 command center vs site control desks, given partner availability and slower escalations?
B1098 Central vs regional command center model — In India’s corporate ground transportation for employee commutes (EMS), what is the right governance model for a centralized 24x7 command center versus regional/site-based control desks when expanding into Tier-2/3 cities with weaker partner density and slower escalation reach?
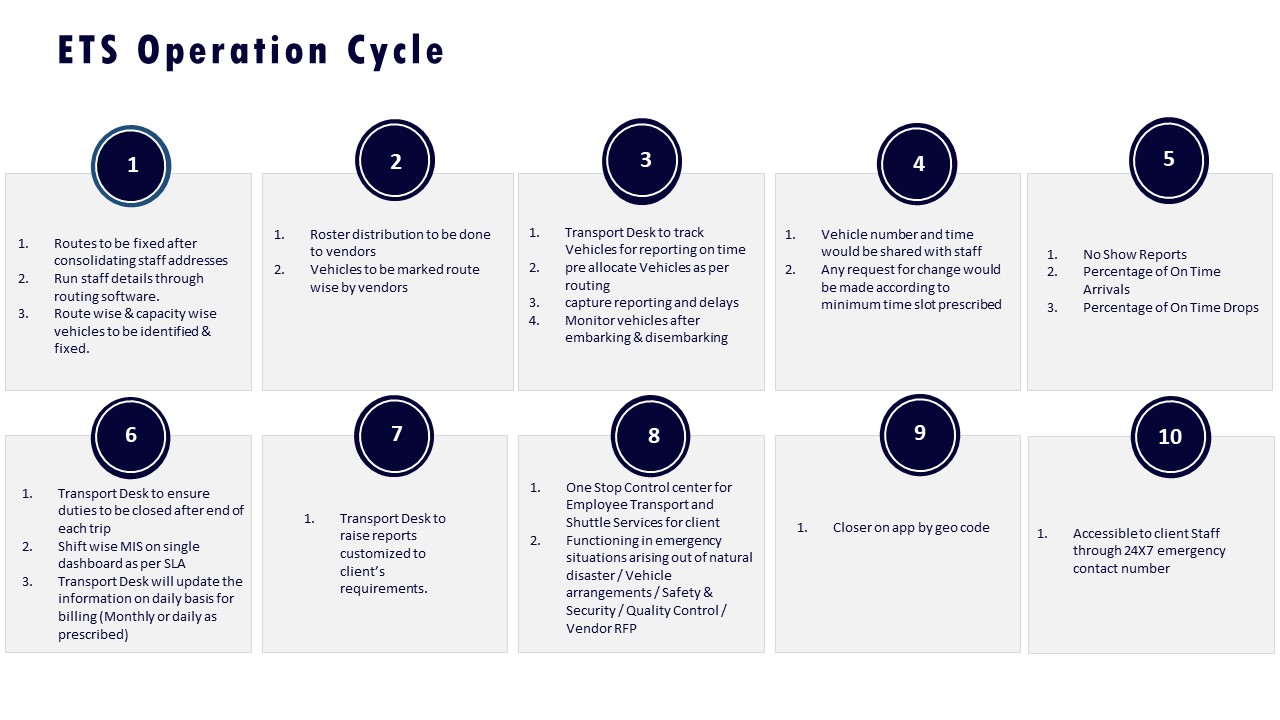
A dual-layer governance model works best for Employee Mobility Services in India. A centralized 24x7 command center should own standards, observability, and vendor governance, while regional or site-based control desks handle local dispatch nuances, last-mile coordination, and emergency response in Tier-2/3 cities.
A centralized command center gives organizations single-SLA control across EMS, CRD, and ECS. The central node should run the routing engine, telematics dashboards, and incident ticketing. It should enforce uniform safety and compliance policies, maintain the Mobility Risk Register, monitor OTP%, TAR, Trip Fill Ratio, and exception closure times, and govern multi-vendor performance tiers. This layer also stabilizes EV transition, ESG reporting, and HRMS integration, which are easier to control once for all locations.
Regional or site-based control desks are needed because Tier-2/3 cities often have fragmented supply, weaker partner density, and slower infrastructure response. Local desks should own driver attendance, ad-hoc rerouting during weather or political events, and direct coordination with local authorities. They should also manage escorts for women’s night shifts, last-mile communication with employees and security, and immediate containment when GPS or network fails.
To balance both layers, organizations can define a target operating model in which the central 24x7 command center sets policy and monitors KPIs, while regional desks run shift windowing, vendor allocation, and on-ground execution. Clear escalation matrices, exception SLAs, and data schemas are needed so that incidents raised locally are visible centrally with full audit trails. A common failure mode is over-centralizing decision rights without giving Tier-2/3 desks enough autonomy to handle real-time constraints, which leads to delayed responses and higher escalations.
With hybrid attendance changing daily, what usually breaks first in shift transport—spikes, late roster changes, late approvals—and what governance keeps reliability stable on peak days?
B1104 Govern reliability under hybrid demand swings — In India’s enterprise employee mobility services (EMS), what are the typical failure modes when hybrid-work demand elasticity meets fixed shift windows—like sudden attendance spikes, ad-hoc roster changes, or late approvals—and what governance mechanisms prevent reliability from collapsing during peak days?
In India’s enterprise employee mobility services, reliability usually collapses when volatile hybrid-work demand is managed with static, paper-based controls and no command-center governance. Stability on peak days comes from treating routing, capacity, and approvals as a governed system with early signals, dynamic rules, and clear escalation paths, not as last-minute manual fixes.
Typical failure modes appear at three pinch-points. At the demand edge, late roster uploads, ad-hoc shift extensions, and manager-side “exceptions” break pre-planned routes. This leads to under-declared attendance, seat overflows, and no-show confusion. At the supply edge, fixed fleet allocations and rigid vendor SLAs cannot flex for sudden spikes, so dead mileage rises while actual OTP falls. At the control edge, fragmented apps, GPS gaps, and weak escalation matrices force the facility head into reactive firefighting with no single view of trip adherence, vehicle utilization, and exception closure time.
Governance mechanisms that prevent breakdown focus on predictable elasticity and observable operations. Central 24x7 command centers with defined SLOs monitor OTP%, Trip Adherence Rate, and exception latency across all shift windows. Shift windowing and dynamic route recalibration allow fleets to flex by timeband, with peak vs non-peak capacity buffers and seat-fill targets to curb dead mileage. HRMS–transport integration ties bookings and rosters to policy, so outcome-based contracts can index payouts to on-time arrivals, safety incidents, and seat-fill, discouraging unmanaged ad-hoc approvals.
Strong vendor governance frameworks and multi-tier vendor models limit single-supplier failure during spikes. Business continuity playbooks and multi-hub NOC structures provide pre-agreed responses for weather, political events, or tech outages. Audit-ready safety and compliance dashboards, including women-safety protocols for night shifts, keep EHS and HR in control even when demand elasticity is high.
images:
How do we enforce SLAs but still keep flexibility during disruptions like festivals or bad weather, so vendors don’t cut corners or reduce coverage just to protect metrics?
B1105 Balance SLAs with disruption flexibility — In India’s corporate ground transportation for employee commutes (EMS), how should leadership balance strict SLA enforcement with operational flexibility during disruptions (traffic events, weather, festival surges) so that the vendor doesn’t become overly conservative and reduce service coverage to protect metrics?
Leadership should keep core safety and reliability SLAs non‑negotiable, but explicitly define disruption playbooks and “grace zones” in contracts so vendors can stretch capacity during shocks without being punished on headline metrics. The balance comes from separating normal‑day performance from disruption‑day behaviour, and rewarding transparent, proactive management of exceptions rather than pure numbers.
In India’s EMS context, most vendors become conservative when SLAs are rigid and penalties are blind to ground reality. Vendors then avoid marginal routes, late-night clusters, or festival peaks to protect OTP%, which quietly erodes coverage. A more resilient governance model defines clear disruption triggers (e.g., Level‑X rain, city‑wide bandh, major religious events) and ties them to pre-agreed alternative thresholds for OTP, routing rules, and escalation timelines. That preserves discipline on ordinary days but avoids fear-driven under‑service when conditions are abnormal.
Operationally, leadership can codify three levers. First, create “protected services” where minimum coverage and women-safety protocols stay mandatory regardless of penalty relaxations. Second, anchor a command‑center based exception process, where real‑time alerts, route recalibration, and BCP plans (buffer vehicles, alternate vendors, shift staggering) are logged and auditable. Third, shift part of the commercial model to outcome bands rather than single-point targets, so a vendor that maintains coverage and transparent reporting through disruptions is not penalized like one that quietly cancels trips.
Leadership should also insist on robust data and reporting. Centralized dashboards, alert supervision systems, and management reports allow separation of systemic underperformance from disruption‑specific variance. When exception days are tagged and measured distinctly, procurement and finance can run incentives and penalties by “day type,” which reduces vendor anxiety and encourages honest escalation. This approach supports driver retention and fatigue management, because vendors are not forced into unsafe duty cycles just to save monthly metrics.
For the facility or transport head, the practical signal is simple. If every disruption leads to late‑night firefighting and vendor excuses, SLAs are probably misaligned with real on‑ground variability. If disruptions trigger structured BCP steps, pre‑agreed temporary thresholds, and stable coverage with fewer calls, then leadership has likely set the right balance between strictness and flexibility.
For Tier-2/3 expansion, what should we look for to confirm real regional support—supervisors, partner tiering, backup vehicles, escalation reach—and how do we validate it during evaluation?
B1106 Evaluate Tier-2/3 operational support — In India’s multi-site employee mobility programs (EMS), what does ‘good’ regional coverage and Tier-2/3 support look like in operational terms—on-ground supervisors, partner tiering, spares availability, and escalation reach—and how should this be evaluated during vendor due diligence without relying on promises?
In India’s multi-site employee mobility programs, “good” regional coverage means the vendor already runs governed operations across multiple cities with local command capability, pre-qualified supply, and clear continuity plans, not just a promise to “scale when needed.” It also means tier 2/3 cities are supported by an established supply chain, trained on-ground teams, and a 24x7 command centre that can enforce SLAs, safety, and compliance remotely with auditable data.
Strong on-ground coverage is usually visible in three places. First, a defined team structure exists beyond metro HQ, with location-specific command centres, pickup–drop coordinators, and daily shift-wise briefings to control OTP, safety checks, and driver discipline. Second, the vendor runs a documented business continuity plan that covers cab shortages, political strikes, technology failures, and natural disasters, with buffer vehicles and alternative arrangements clearly assigned. Third, the partner ecosystem is tiered and governed through central compliance management, fleet and driver induction frameworks, and periodic audits rather than informal local aggregators.
Tier 2/3 capability also shows up in infrastructure and resilience. Mature operators demonstrate current EV or ICE fleet presence across smaller cities, vendor and statutory compliance processes that work outside metros, and transport command centre dashboards that monitor all branches through a single window with alerts, exception handling, and indicative management reports.
During due diligence, buyers should de‑risk “promise-only” coverage by requesting: live or recent route and OTP reports by city, including smaller locations; proof of current fleet and driver counts mapped to those locations; copies of fleet and driver compliance dashboards and BCP documents; and a clear escalation mechanism and team structure for each region. Evaluation should focus on whether the vendor can evidence centralized governance plus local execution, with traceable reports, SOPs, and audit trails that can be checked independently, rather than generic claims of “pan-India presence.”
In a multi-vendor setup, how do we stop each vendor optimizing for their own metrics while overall employee transport reliability gets worse?
B1112 Prevent multi-vendor reliability fragmentation — In India’s multi-vendor corporate employee transportation (EMS), what governance mechanisms prevent reliability from being ‘optimized locally’ by each vendor (shifting blame, inconsistent SOPs) while overall service quality deteriorates at the enterprise level?
In multi-vendor employee mobility in India, reliability stops being “locally optimized” only when the enterprise runs a single, command-led governance model with common SLAs, common data, and common SOPs across all vendors. The core principle is that performance, safety, and cost are measured and enforced at the enterprise program level, not negotiated one vendor at a time.
A centralized 24x7 command center or NOC is the anchor mechanism. The command center monitors all EMS routes, vendors, and cities on a unified dashboard with standard KPIs such as OTP%, Trip Adherence Rate, incident closure times, and seat-fill. The command center uses real-time alerts, escalation matrices, and exception workflows to intervene early instead of waiting for vendor explanations after failures.
A single vendor-governance framework further prevents local optimization. Enterprises define one SLA stack, one safety and compliance baseline, and one audit trail standard that every vendor must meet. Vendor performance is tiered using common KPIs, and capacity is reallocated using structured rebalancing rules instead of ad-hoc favors. Outcome-based contracts index payouts and penalties to the same reliability, safety, and utilization metrics, which reduces room for “my route is fine, others failed” arguments.
Standardized operating procedures and data schemas are also critical. Routing, rostering, women-safety protocols, escort rules, and incident response follow one documented SOP set across locations. Trip logs, GPS data, and incident records flow into a single mobility data lake with a governed KPI layer, which enables route adherence audits and continuous assurance rather than episodic, vendor-led reporting.
To make this sustainable, organizations institutionalize a mobility governance board and structured review cadence. Quarterly reviews, procurement scorecards, and mobility maturity roadmaps evaluate the fleet mix (including EVs), hybrid-work elasticity handling, and cost-per-trip outcomes across all vendors together. This keeps optimization focused on enterprise-wide reliability, safety, cost, and ESG metrics instead of fragmented vendor narratives.
What reliability controls should we centralize vs keep site-specific so we don’t end up with policies that don’t work anywhere?
B1114 Centralize vs localize reliability controls — In India’s corporate employee mobility services (EMS), how should Facilities/Transport and HR decide which reliability controls must be centralized (SLA governance, escalation matrix) versus localized (site constraints, security rules) to avoid ‘one-size-fits-none’ policies?
In India’s employee mobility services, reliability controls that depend on uniform data, auditability, and 24x7 monitoring should be centralized, while controls driven by local geography, traffic, and security realities should be localized under a clear SOP envelope. Centralizing SLA governance, command-center visibility, and escalation logic creates consistency and evidence, while local teams tune routing, buffers, and site-specific safety rules to keep operations realistic and resilient.
Centralization works best where EMS depends on shared systems and common definitions. SLA libraries, OTP and exception KPIs, escalation matrices, BCP playbooks, and vendor governance frameworks should be owned at the central level. Central command centers, NOCs, and tools like alert supervision, centralized compliance dashboards, and CO₂ tracking need single-source-of-truth data and standard trip logs to keep Finance, HR, Security, and ESG aligned. Central teams should define baseline rules for women-safety protocols, credentialing cadence, business continuity, and minimum tech stack (driver/employee apps, GPS, SOS, audit trails).
Localization is critical wherever ground reality diverges by city, timeband, or site type. Facilities and HR should allow city or site transport leads to adjust routing patterns, buffer times, and fleet mix based on monsoon impact, political risk, or industrial constraints, using dynamic routing and real-time command-center guidance. Local rules on escorts, staging points, or pickup windows can be stricter than central baselines when risk or infrastructure demands it. Local BCP variants for cab shortages, strikes, or tech outages should plug into the central framework but be owned by city teams who know which levers actually work at 2 a.m.
A practical split is to treat certain items as “must be global” and others as “must be tuned locally”:
- Central: KPI definitions and targets, escalation tiers and response SLAs, audit and compliance processes, safety and women-centric baseline protocols, vendor and billing governance.
- Local: Route design and seat-fill tactics, peak and night-shift capacity buffers, on-ground driver management and fatigue control, site access protocols, and local emergency coordination.
Facilities and HR should formalize this split in a documented operating model that links a centralized command center with location-specific command desks. The central team sets the guardrails and monitors outcome metrics like OTP, incident rates, and CO₂ intensity, while local leads own day-to-day decisions inside those guardrails and feed back data for continuous policy tuning. This approach avoids “one-size-fits-none” policies by keeping governance and evidence uniform, but leaving enough operational freedom for each site to stay safe, compliant, and on time under its own constraints.
During a pilot, what early warning signs tell us reliability will fail at scale—roster volatility, too many exceptions, weak Tier-2/3 coverage—so we can stop before a bad rollout?
B1117 Pilot red flags for scale failure — In India’s employee mobility services (EMS), what are the warning signs during pilots that operational reliability will fail at scale—especially around roster volatility, exception volume, and Tier-2/3 coverage—so a buyer can stop early before a high-visibility rollout goes wrong?
In India’s employee mobility services, the most reliable warning sign that operations will fail at scale is when a pilot already needs constant manual overrides to keep OTP and safety SLAs intact. If a small pilot feels like firefighting, a full rollout will break command-center stability, inflate exception volumes, and expose Tier‑2/3 weaknesses.
Early in a pilot, high roster volatility exposes weak routing and capacity models. A critical warning signal is when every minor shift change or no‑show forces manual re‑routing by transport teams instead of being absorbed by the routing engine. Another signal is rapidly rising dead mileage and half‑empty cabs despite similar demand patterns. A third signal is when OTP depends on a handful of “hero” dispatchers working outside the system instead of the platform handling dynamic routing and resequencing.
Exception volume during pilots reveals whether the model is truly elastic. A serious red flag is when exception tickets per 100 trips remain high even after two or three weeks of stabilization. Another is when the same exception types recur daily, such as missed pickups at the same hubs, repeated geofence violations, or repeated SOS / escalation delays. Exception closure time that stretches into the next shift, or requires parallel tracking in spreadsheets, indicates the vendor’s incident workflows will not withstand volume.
Tier‑2/3 coverage issues almost always appear first as vendor and driver fragility. A red flag is inconsistent fleet availability in smaller cities even at low pilot volume. Another is patchy GPS and app uptime in those locations, forcing phone‑based coordination instead of NOC‑based observability. A third is frequent BCP invocation for basic issues like local strikes, fuel shortages, or road closures, which signals the supply chain and contingency model are thin.
Buyers can protect themselves by defining hard pilot exit criteria tied to observable markers. Useful thresholds include maximum acceptable OTP variance, cap on exceptions per 100 trips, minimum coverage reliability across Tier‑2/3, and demonstrable reduction in manual intervention week over week. If these metrics stall or degrade during the pilot, most organizations are better off stopping early rather than carrying an unstable EMS model into a high‑visibility rollout.
When we open new sites/cities, how do we set a minimum reliability standard so expansion doesn’t drag down existing SLAs and create employee backlash?
B1118 Set minimum reliability standard for expansion — In India’s corporate employee transportation (EMS), how should the executive sponsor decide the ‘minimum viable reliability’ standard for new sites or new cities, so expansion doesn’t dilute the existing SLA performance and trigger a backlash from employees and business leaders?
In corporate employee transportation in India, an executive sponsor should define “minimum viable reliability” for new sites as a slightly lower but tightly-bounded SLA band than mature locations, backed by explicit guardrails on safety, observability, and escalation time. The standard should be framed as a temporary “stabilization SLA” with clear thresholds for OTP, exception-closure, and safety compliance that cannot be compromised even in the first 90 days.
The reliability baseline needs to separate non‑negotiables from ramp-up flex. Non‑negotiables usually include women-safety protocols, escort rules, driver KYC/PSV, SOS working end‑to‑end, geo-fencing, and traceable trip logs. Ramp-up flex can sit in a narrow band for OTP and routing efficiency, for example accepting a slightly lower OTP% or higher dead mileage for the first quarter while routing patterns, driver pools, and local vendors stabilize.
The decision should be data-led and tied to existing EMS performance. Sponsors can define expansion reliability as a percentage of current OTP and Trip Adherence Rate, set hard limits on exception latency, and pre‑agree how many SLA breaches per week trigger a corrective action review. Centralized command-center visibility and a clear escalation matrix protect the core brand promise when new cities launch under imperfect local supply. A common failure mode is expanding on paper SLAs without extra buffers in fleet, drivers, and NOC coverage, which quickly erodes trust among employees and business leaders.
A practical playbook for setting minimum viable reliability includes:
- Fix a floor, not a target, for OTP% and safety compliance in new sites.
- Add explicit buffers for fleet and drivers in early months to absorb demand variability.
- Link vendor payouts in expansion cities to outcome metrics like OTP and complaint-closure time.
- Require centralized monitoring and incident-ready SOPs before first employee shifts go live.
SOP standardization, auditing, and reliability engineering
Establish standardized SOPs, credible reliability reporting, post-incident reviews, and a maturity path toward reliability engineering to sustain gains.
How should Procurement design outcome-based SLAs for routing, rosters, and exception handling without vendors gaming the numbers or hiding incidents?
B1099 Outcome SLAs without metric gaming — In India’s enterprise employee mobility services (EMS), how can Procurement structure outcome-based SLAs so that routing quality, roster adherence, and exception handling are all incentivized—without creating perverse incentives where the vendor hides incidents or games the metrics?
Procurement can structure outcome-based SLAs in EMS so they improve routing quality, roster adherence, and exception handling only when three conditions are met. Each outcome metric must be paired with data transparency requirements, counter-balancing KPIs, and clear “no reward if you hide” governance rules that make concealment riskier than honest reporting.
Outcome-based SLAs are most stable when routing quality, OTP, and exception handling are defined as system-generated, audit-ready metrics rather than self-declared vendor numbers. In practice, this means anchoring SLAs on data coming from a shared platform or command center, with immutable trip logs, GPS traces, and app events that both client and vendor can see. Random route audits, like those used in centralized compliance and command-center models, act as a separate control to verify that “good numbers” reflect real rides, not manipulation.
Perverse incentives reduce when every positive KPI has a paired “integrity” KPI. High on-time performance is only fully rewarded if incident reporting volume looks realistic and complaint closure SLAs are met. Roster adherence bonuses are contingent on seat-fill and dead-mile caps, so vendors cannot game routing by over-supplying empty vehicles. Exception handling incentives are linked to detection-to-closure time and root-cause classification quality, not just low incident counts.
Procurement can further reduce gaming risk by using structured escalation matrices, periodic management reports, and command-center dashboards as part of the contract evidence pack. These governance tools, which already exist in EMS environments with centralized compliance and business continuity plans, ensure that safety, women-centric protocols, and BCP triggers have explicit SLAs that are non-negotiable, even if they temporarily hurt cost metrics.
- Define 3–5 core outcome KPIs per cluster: routing (Trip Fill Ratio, dead-mileage caps), reliability (OTP%, Trip Adherence Rate), and exceptions (incident response and closure time).
- Make achievement conditional on data-sharing: access to trip ledgers, GPS logs, and standard dashboards is a prerequisite for any bonus or earnback.
- Include “red lines” where safety, compliance, and women-safety breaches override all incentives and trigger penalties or remediation.
- Use quarterly reviews to recalibrate thresholds so that EV adoption, hybrid-work fluctuations, and new sites do not force vendors into silent non-compliance.
What integrations usually cause reliability issues—HRMS rosters, attendance, access control, vendor apps—and how should IT govern them so we don’t build brittle hacks that fail later?
B1101 Integration weak points impacting reliability — In India’s enterprise-managed commute operations (EMS), what integration and data-handshake dependencies typically break operational reliability—HRMS rosters, attendance, access control, or vendor apps—and how should the CIO govern these interfaces to avoid brittle workarounds that create future outages?
In India’s enterprise employee mobility services, operational reliability usually breaks at three integration points. HRMS roster feeds and attendance systems often desync with the transport platform. Access control logs rarely align cleanly with trip and route data. Vendor apps and telematics streams fail or drift from enterprise data standards.
The core pattern is that EMS operations depend on a clean handshake between HRMS rosters, the routing/dispatch engine, driver and rider apps, and any access control or security systems. When these feeds are schema-less, batch-based, or manually adjusted, nightly roster changes, hybrid-work variability, and shift windowing create mismatches that surface as no-shows, wrong routing, or late pickups. When access systems and EMS are not reconciled to a shared identity model and time semantics, auditability of on-time performance and duty-of-care breaks. When vendor apps are integrated as black boxes without API-first contracts, telemetry, GPS, and SOS data end up in silos with no consistent trip ledger.
CIOs should treat EMS as part of the enterprise integration fabric and not as an isolated vendor stack. CIOs should define canonical data schemas for employee identity, shift windows, and trip lifecycle. CIOs should mandate API-first HRMS integration with clear SLAs on latency, error handling, and change propagation. CIOs should insist that all vendor apps expose open Trip Ledger APIs that stream trip, GPS, and incident data into a governed mobility data lake.
CIOs should also require role-based access control across EMS, HR, security, and finance systems with consistent identifiers and audit logs. CIOs should prohibit hard-coded mappings, manual CSV uploads, and one-off scripts that bypass governance. CIOs should define SLOs for uptime and latency on each integration, with observability hooks for schema drift, failed events, and reconciliation gaps.
Key governance actions for the CIO include: - Standardizing semantic models for rosters, routes, trips, and attendance. - Enforcing contractually that mobility vendors support open APIs and data export. - Implementing streaming pipelines from telematics and vendor apps into a central KPI layer. - Aligning EMS integrations with data privacy and security controls under the DPDP context.
After incidents, what governance makes RCAs lead to real fixes in routing/rosters/vendor behavior instead of becoming a ritual that doesn’t reduce escalations?
B1108 Make incident reviews drive real change — In India’s enterprise-managed employee commute operations (EMS), what governance practices ensure post-incident reviews lead to real fixes (routing rules, roster processes, vendor accountability) rather than becoming repetitive ‘RCA theater’ that doesn’t reduce future escalations?
In enterprise employee commute operations in India, post-incident reviews only reduce future escalations when they are embedded in a governed, evidence-backed process that updates routing rules, rosters, and vendor SLAs by design. Effective governance links every incident to command-center observability, compliance dashboards, and vendor performance metrics, so that each review produces a concrete, implemented change instead of a narrative explanation.
Robust post-incident governance starts with reliable trip and safety data. Centralized command centers and tools like the Alert Supervision System and Transport Command Centre give real-time logs for geofence violations, speeding, device tampering, SOS events, and route deviations. These trip-level records feed compliance dashboards and safety frameworks such as Safety & Security for Employees, Centralized Compliance Management, and Safety and Compliances, which enable factual reconstruction of what actually happened instead of opinion-based debates.
Stronger governance models assign clear ownership and escalation paths. Structured engagement and escalation matrices, along with MSP governance structures and TCC roles and responsibilities, define who convenes the review, who can change routing and roster rules, and how quickly corrective actions must be implemented. Vendor and statutory compliance frameworks and Chauffeur Excellence and Driver Compliance processes ensure that non-compliance leads to tangible outcomes such as retraining, fleet induction checks, or vendor performance actions, which are visible in management reports and user satisfaction indices.
To avoid “RCA theater,” organizations embed post-incident actions into standard operating cycles that are auditable. Command-center micro-functioning models, step-by-step induction processes, and data-driven insights platforms convert findings into updated routing parameters, revised night-shift or women-safety protocols, refreshed driver training, and modified buffer capacity or standby rules. These changes are then tracked through measurable KPIs such as OTP, incident rates, and customer satisfaction scores that appear in dashboards and indicative management reports, ensuring that incident learnings are tested against real-world performance in subsequent shifts.
Where do HR, transport, and Finance usually disagree on reliability for employee transport, and how should a sponsor align them into priorities that hold up in a real incident?
B1110 Align HR, Ops, and Finance on reliability — In India’s corporate ground transportation for shift commutes (EMS), where do reliability expectations typically diverge between HR (employee experience), Facilities (operational calm), and Finance (cost control), and how should an executive sponsor reconcile these into a single set of priorities that won’t collapse during the first crisis?
In corporate employee mobility services in India, HR usually defines reliability as “safe, respectful, hassle‑free commutes,” Facilities defines it as “no night-shift firefighting,” and Finance defines it as “predictable cost per trip with clean books.” An executive sponsor must convert these three expectations into a small, non-negotiable reliability spine that is measured in common KPIs and enforced in contracts, SOPs, and command-center routines.
HR’s reliability expectation centers on employee experience and safety. HR prioritizes on-time pickups for shifts, zero-tolerance for women-safety lapses, and audit-ready evidence for every trip. HR becomes anxious when there are repeated late pickups, incomplete incident logs, or fragmented data that cannot answer leadership questions after an escalation.
Facilities or the Transport Head defines reliability as control-room stability. This role focuses on early alerts, predictable driver and fleet availability, and routing that can absorb hybrid-work variability. Facilities loses trust when GPS or apps fail during peak windows, vendors do not respond at 2 a.m., or manual rostering forces reactive decisions without predictive support.
Finance views reliability through the lens of cost, control, and auditability. Finance expects trip data to reconcile cleanly to invoices, steady cost per kilometer and per employee trip, and contracts without hidden dead mileage or opaque surcharges. Finance’s expectations diverge when SLAs are vague, billing does not tie to operational metrics, or ESG and EV initiatives are proposed without clear TCO logic.
A common failure mode is to treat each expectation separately. HR pushes for more safety and experience features, Facilities demands operational buffers, and Finance pressures for lower unit costs. Under crisis—such as a night-shift incident, sustained OTP degradation, or a billing dispute—the organization discovers that KPIs, SLAs, and governance structures do not agree on what “reliable” means.
An executive sponsor can reconcile these by defining a single reliability spine with three to five shared priorities. These priorities should bind service design, vendor selection, contracts, and command-center practices. Each priority must have a cross-functional KPI, an explicit trade-off rule, and a crisis playbook.
A robust reliability spine in EMS typically includes: shift-aligned on-time performance, safety and compliance by design, cost and utilization discipline, centralized visibility with incident readiness, and audit-ready data across HR, Facilities, and Finance. Every major decision should be tested against this spine before implementation.
To operationalize this, the executive sponsor should set up a mobility governance structure that includes HR, Facilities, Finance, IT, and Security. This group should define a shared EMS service catalog, outcome-linked SLAs, and a clear escalation matrix that connects command center alerts to decision makers.
The reconciled priorities must be encoded into commercial models and contracts. Outcome-based procurement can link payouts and penalties to on-time performance, seat-fill, safety incidents, and exception closure times. This approach makes trade-offs explicit, such as when extra buffer capacity is funded to protect OTP during monsoons.
During the first major crisis, such as monsoon-induced disruptions or a vendor-side fleet shortage, this unified spine prevents collapse. HR can see that safety controls and incident evidence are intact. Facilities can rely on predefined rerouting and buffer capacity rules. Finance can see that emergency measures are within pre-agreed cost guardrails.
Without this unification, each stakeholder tends to improvise under pressure. HR may demand additional safety measures that are not costed or contracted. Facilities may bypass SOPs to “get cabs somehow.” Finance may freeze spending or challenge invoices after the fact. These reactions typically worsen trust and increase noise.
Executives should therefore invest early in cross-functional KPI design, shared dashboards, and integrated command-center operating models. These tools should bring together on-time performance, safety incidents, cost per trip, and seat-fill into a single view that each stakeholder can interpret according to their mandates.
In practice, a reconciled reliability model becomes more resilient when it is backed by platformized EMS operations, central NOC observability, and vendor governance frameworks. These capabilities allow the organization to move from reactive firefighting to predictive support, even as hybrid attendance and EV adoption introduce new uncertainties.
Over time, the executive sponsor should use quarterly reviews to adjust buffers, routing rules, and commercial levers based on observed data. This continuous improvement loop helps align HR’s experience targets, Facilities’ operational calm, and Finance’s cost expectations, so that the agreed priorities remain stable even as the commute context evolves.
What’s a realistic maturity journey from manual dispatch to a reliability-engineered setup with SLOs and runbooks, and how do we know we’re ready for it?
B1111 Maturity path to reliability engineering — In India’s employee mobility services (EMS), what is a realistic ‘maturity path’ from manual dispatch and reactive firefighting to a reliability-engineered operation (SLOs, error budgets, runbooks), and what early indicators show the organization is ready for that shift?
A realistic EMS maturity path in India moves from ad‑hoc, person-dependent dispatch to a command‑centered, data‑driven operation where reliability is engineered through defined SLOs, automated controls, and runbooks. The shift is gradual and typically follows discrete stages in routing, command-center design, technology integration, and governance, rather than a single “big bang” transformation.
Early stages focus on stabilizing basics. Organizations standardize trip lifecycles, define minimum OTP and safety baselines, and centralize visibility into a single dashboard for rostering, routing, and GPS tracking. Transport heads usually move from spreadsheet rostering and phone-based dispatch to an EMS platform that links driver apps, employee apps, and a simple command-center view for live trips, exceptions, and SOS events. This reduces pure firefighting but still relies heavily on human judgment in night shifts and peak windows.
Mid-maturity introduces explicit SLAs and observable KPIs. Transport and HR teams start tracking OTP%, Trip Adherence Rate, no-show rates, incident counts, and driver credentials currency. Escalation matrices, business continuity plans, and women-safety protocols become standard. Centralized compliance management for fleet and drivers, plus alert supervision systems for geofence violations and overspeeding, allow command centers to prioritize interventions and shorten exception closure times. At this stage, dashboards for CO₂, cost per trip, and fleet uptime also appear, preparing the ground for SLO thinking.
Reliability-engineered operations emerge when those metrics turn into “promises with guardrails.” The command center operates against defined SLOs for OTP%, incident response times, app uptime, and data freshness. Error budgets for OTP or incident rates are monitored so Transport Heads can decide when to freeze new changes (e.g., routing experiments or vendor switches) and focus on stability. Runbooks codify responses for recurring scenarios such as monsoon disruptions, technology failures, cab shortages, political strikes, and night-shift escort breaches, drawing directly on existing business continuity plans and mitigation playbooks.
Several early indicators signal readiness to move into this reliability-engineered phase: - The organization already runs a 24x7 NOC or command center with live trip and incident visibility. - OTP, safety incidents, and customer satisfaction are measured consistently and trusted by HR, Finance, and Security. - Business continuity and women-safety protocols exist as written SOPs and have been used at least once in real disruptions. - Transport, HR, and IT teams are willing to treat routing and vendor choices as controlled “changes” rather than daily improvisations. - Leadership has started asking for trend views and root-cause patterns instead of only daily status explanations.
Once these signals show up, moving toward SLOs, error budgets, and runbooks typically makes the Facility or Transport Head’s life easier rather than more complex, because it turns 2 a.m. chaos into a finite set of rehearsed plays and predictable thresholds for action.
What should Audit/Risk check to trust our reliability reporting—missed trips, escalations, recovery times—and ensure it’s not being selectively reported?
B1116 Audit reliability reporting credibility — In India’s corporate ground transportation for employees (EMS), what should Internal Audit or Risk look for to be confident that operational reliability reporting (missed trips, escalations, recovery times) is accurate and not selectively reported by the vendor or the command center?
Internal Audit or Risk can gain confidence in EMS operational reliability reporting only when missed trips, escalations, and recovery times are driven by system-enforced evidence, not by manual declarations. Reliable reporting in Indian corporate employee mobility requires a traceable trip lifecycle, independent data sources, and auditable exception workflows that Internal Audit can test without vendor mediation.
Internal Audit should first check whether every employee trip has a unique, end-to-end trip lifecycle record. This record should include booking source, rostered route, GPS trace, driver and vehicle IDs, timestamps for each trip milestone, and trip-close method. A missing or editable segment in this chain is a common failure point that enables selective reporting of cancellations, no-shows, or partial trips.
Audit teams should then assess if the command center and vendor reports are generated from a governed data store rather than from spreadsheets or manually compiled logs. A mobility data lake, or equivalent centralized repository, should hold raw telematics, app events, and HRMS roster data, which can be reconciled to calculate OTP, missed trips, and recovery times. Internal Audit can sample a set of days and independently recompute OTP% and exception closure SLAs from raw data to test vendor claims.
Escalation and recovery reporting must be anchored in a ticketing or incident management system. Each escalation should have a time-stamped record from detection to closure, linked to the underlying trip or route. Internal Audit can verify whether escalation volume, severity, and mean time to recover come from this ticketing ledger, not from narrative summary decks prepared by the vendor or transport team.
To guard against selective suppression of failures, Internal Audit should verify that alerts and exceptions are generated algorithmically based on defined rules such as geo-fence violation, route deviation, prolonged stoppage, or late departure beyond SLA thresholds. Manually raised incidents alone are insufficient, since they can underrepresent real deviation volume during peak or night shifts.
A critical validation step is cross-checking vendor reports against independent enterprise systems. HRMS attendance and shift-adherence data can be compared with mobility OTP reports to detect systematic under-reporting of missed or delayed pickups. Similarly, security gate logs or access systems can validate actual arrival times against reported drop times.
Internal Audit should examine the role-based access and change-logging model for the command center tools. Reliable reporting requires that trip events, incident logs, and KPIs cannot be retroactively altered without leaving an audit trail. This includes tamper-evidence for GPS logs, edit history for duty slips, and versioning of SLA calculation logic.
Finally, Internal Audit should ensure that the vendor governance framework links reported metrics to commercial outcomes, such as outcome-based contracts where payouts or penalties depend on OTP, incident rates, and closure SLAs. Once money is tied to these numbers, the integrity of the measurement system, including route adherence audits and random trip verifications, becomes a formal control topic rather than a purely operational concern.
If systems go down, what limited-mode capabilities should we insist on so routing, trip confirmation, and escalations still work and shift operations don’t freeze?
B1119 Graceful degradation for commute operations — In India’s enterprise employee mobility services (EMS), what should a buyer require in terms of ‘graceful degradation’ when systems fail—so that routing, trip confirmation, and escalations still work in a limited mode rather than causing a full operational freeze during shift changes?
In India’s enterprise employee mobility services, buyers should demand explicit “graceful degradation” modes where core EMS functions continue through predefined fallbacks when apps, GPS, or integrations fail. The minimum requirement is that shift routing, trip confirmation, and safety escalations keep working in a limited but controlled mode instead of forcing a shutdown of transport operations.
A robust graceful degradation design keeps three flows alive under failure conditions. Routing must fall back from fully automated, traffic-aware optimization to pre-approved static routes and shift windowing that dispatch known vehicles and drivers from a printed or cached roster. Trip confirmation must switch from app-based OTP and manifests to SMS/voice confirmations and manual attendance capture that still generate audit-ready duty slips and trip logs. Escalations must move from in-app tickets to call-center–driven workflows using a central Transport Command Centre with an escalation matrix, so incidents are still logged, triaged, and closed within defined SLAs.
A common failure mode is EMS platforms that collapse when HRMS, GPS, or the routing engine is unavailable. This breaks OTP, makes route adherence unverifiable, and floods the Facility / Transport Head with manual firefighting during peak shift changes. Buyers reduce this risk by requiring offline-first driver and employee apps, cached rosters and route plans for upcoming shifts, and a documented “manual operation mode” with clear SOPs. Buyers should insist that the vendor demonstrate, not just claim, these fallbacks through drills that simulate GPS loss, app downtime, or HRMS integration failure.
To make graceful degradation enforceable, buyers can hard-code requirements into SLAs and governance. Contracts should define which KPIs (OTP%, incident closure time, safety coverage) must still be met under partial failure and which capabilities can be temporarily relaxed, such as real-time analytics or non-critical reports. Vendors should provide an Integrated Mobility Command Framework with a central 24x7 command center, clear escalation matrices, and a business continuity plan that covers technology failures alongside cab shortages, political strikes, and extreme weather. The Facility / Transport Head should be able to point to a single, tested playbook that explains exactly how the system behaves during failures and who answers the phone at 2 a.m.
How do we standardize SOPs and SLAs for employee transport while still allowing local exceptions for different campuses, security gates, and traffic conditions?
B1120 Standardize SOPs without breaking local fit — In India’s shift-based employee commute services (EMS), how should a buyer balance process standardization (common SOPs, consistent SLAs) with the reality that different business parks, security gates, and traffic patterns require local routing and escalation exceptions?
In India’s shift-based employee mobility, buyers should standardize the governance and safety envelope end‑to‑end, while deliberately localizing routing, buffers, and escalation playbooks at each site. Process standardization must define what “good” looks like everywhere, and local exceptions must only change how that standard is achieved on the ground, not the standard itself.
A practical pattern is to fix a common EMS backbone at enterprise level. This includes uniform SLAs for on‑time performance, safety and women‑safety protocols, escort rules, driver KYC and vehicle compliance requirements, command‑center monitoring expectations, incident response steps, and audit‑ready evidence like GPS logs and trip OTPs. The ETS / EMS operation cycle, centralized compliance management, women‑centric safety protocols, and alert supervision systems from the collateral are examples of this governed backbone.
Local flexibility then lives in a controlled layer under that backbone. Different parks and cities can have their own route designs, gate‑pass norms, reporting buffers, EV versus diesel mix, monsoon traffic playbooks, and local escalation trees. The Mumbai monsoon case study and the “Management of on Time Service Delivery” and Business Continuity Plan collaterals exemplify how location‑specific routing, traffic analysis, and contingency steps can still report into a common command center, safety framework, and SLA dashboard.
To keep this balance stable, most organizations use four concrete guardrails:
- Define a single EMS service catalog and SLA set for all locations, and explicitly tag which parameters are non‑negotiable (safety, compliance, incident closure) versus tunable (lead times, fleet mix).
- Run a central 24x7 command center with standardized alerts, reports, and escalation matrices, and then plug in location‑specific command centers or transport desks underneath it as shown in the MSP governance and command‑centre collaterals.
- Mandate one audit and compliance model across India, but allow regional route audits, BCP variants, and EV/charging topologies that reflect local roads, permits, and infrastructure.
- Use common technology and dashboards (EMS apps, NOC tools, CO₂ and OTP reporting) so that all local exceptions are visible, measurable, and can be continuously tuned instead of becoming undocumented workarounds.
In simple terms, what does “SRE mindset for mobility” mean, and how does it change SLA ownership, incident response, and improvement versus traditional transport management?
B1122 Explain SRE mindset for mobility — In India’s enterprise commute operations (EMS), what does “SRE mindset for mobility” mean in plain terms for senior leaders, and how does it change accountability for SLAs, incident response, and continuous improvement compared to traditional vendor-managed transport?
An “SRE mindset for mobility” means treating employee transport like a critical production system that is engineered, measured, and improved continuously, instead of a vendor-driven, best-effort service. It shifts accountability for uptime, SLAs, and incidents from “the transport vendor” to a joint, data-driven operating model owned by the enterprise’s EMS governance, with clear reliability targets and evidence.
In traditional vendor-managed transport, reliability is negotiated in contracts but managed reactively. Vendors handle routing, driver allocation, and daily exceptions. Escalations happen after failures, and root-cause analysis is often anecdotal. SLAs exist on paper but are not tightly coupled to a centralized command center, real-time observability, or outcome-linked commercials such as OTP%, safety incidents, or closure SLAs.
Under an SRE-style mobility approach, EMS runs on explicit reliability objectives such as on-time performance, trip adherence, and incident closure times. These are monitored in a central 24x7 command center with streaming telematics, geo-fencing, and alerting. Exception detection and closure become measured workflows rather than ad-hoc phone calls. Incident response follows codified playbooks, with audit-ready trip and GPS logs acting as a single source of truth across HR, Security, and Procurement.
This mindset also changes how continuous improvement is run. Traditional models focus on vendor supervision and periodic reviews. An SRE-like model treats routing, fleet mix, EV utilization, seat-fill, and dead mileage as tunable system parameters. Data lakes, analytics, and automated governance tools identify patterns such as recurring delays, driver fatigue risks, or charging gaps. Reliability improvements are implemented through formal change cycles, not one-off fixes.
For senior leaders, this means EMS becomes a governed enterprise capability with shared, measurable reliability targets, integrated technology, and outcome-based contracts. Responsibility is no longer “blame the vendor when something breaks” but “operate a mobility system that is observable, predictable, and continually optimized.”