How to keep mobility operations calm: a practical guardrails playbook for peak shifts
This is a practical, no-nonsense playbook that translates 31 critical questions into six operational guardrails you can run from the dispatch desk. It’s built for real-world shifts when driver shortages and weather disruptions are the daily norm. Use these lenses to define SOPs, escalation routes, and recovery steps you can execute in minutes during peak or off-hours. Every item links to a concrete action, an owner, and verifiable evidence so leadership and Compliance stay confident.
Explore Further
Operational Framework & FAQ
Reliability, NOC governance & escalation playbooks
Establish a repeatable, 24x7 command-center approach with clear escalation paths, recovery procedures, and guardrails to minimize firefighting during peak shifts.
How do we balance a central 24x7 command center with local control so we can scale across cities without slowing down exception handling?
B0005 Central NOC vs local autonomy — In India corporate ground transportation, what is the right balance between centralized command-center governance (24x7 NOC observability, incident readiness) and local/site autonomy so that the program scales across cities without becoming a bureaucracy that slows exception handling?
Balanced mobility governance combines a 24x7 centralized command center for standards, visibility, and escalation control with lightweight local cells that own day-to-day routing, driver deployment, and micro-decisions within those standards.
The centralized command center should own policy, SLA templates, safety and compliance guardrails, and a single-source-of-truth dashboard for OTP, incident rates, fleet uptime, and ESG metrics. The command layer also needs integrated telematics, alert supervision, and ticketing so exceptions, SOS events, and BCP triggers are visible across EMS, CRD, ECS, and LTR programs in real time.
Local or site command centers should own shift-wise rostering, driver and escort allocation, traffic and weather workarounds, and on-ground coordination with security and facility teams. Local teams should be allowed to deviate from standard routes or fleets to protect OTP or safety, as long as they capture the trip lifecycle and reasons in the system so the central NOC retains audit trails and can refine policies.
A practical balance is to centralize the “what” and “why” and localize the “how” and “when.” Central governance defines KPIs like OTP%, Trip Adherence Rate, incident-closure SLA, Driver Fatigue Index, and EV utilization, while local cells tune routing, buffer capacity, and vendor mix to hit those targets in each city. Centralization improves consistency, evidence, and cross-city benchmarking, but it should never own minute-by-minute routing decisions that depend on local traffic, labour, or charging constraints.
To avoid bureaucratic drag, enterprises can set clear autonomy thresholds. For example, local teams can clear any exception within predefined risk and cost bands, only escalating cross-city capacity moves, repeated SLA failures, or high-severity safety incidents to the central command center. This keeps the 24x7 NOC focused on pattern detection, vendor tiering, and BCP activation, while preserving local speed for nightly disruptions, driver no-shows, and route recalibration.
What are the usual ‘lock-in’ traps in mobility platforms and contracts—like closed APIs or messy data exports—and how should Procurement and Legal prevent them before signing?
B0007 Neutralize mobility vendor lock-in — In India corporate ground transportation, what are the most common hidden lock-in mechanisms in mobility contracts and platforms (data formats, restricted APIs, termination fees, proprietary KPI definitions), and how should Procurement and Legal neutralize them upfront?
In Indian corporate ground transportation, lock‑in usually hides in how data, APIs, KPIs, and commercials are structured rather than in one obvious clause. Vendors often keep control of telemetry, workflows, or definitions so that switching becomes risky, slow, or audit‑sensitive for the buyer.
Common hidden lock‑in mechanisms include proprietary trip and fleet data schemas that cannot be exported cleanly, restricted or chargeable APIs for HRMS and ERP integration, and closed access to raw GPS or EV telematics streams. Platforms sometimes only expose summary dashboards, which blocks independent validation of OTP, safety events, and CO₂ calculations across EMS, CRD, ECS, and LTR programs. This creates long‑term dependence on one vendor for reporting to HR, Finance, ESG, and Audit teams.
Lock‑in also appears through custom KPI definitions for OTP, Trip Adherence Rate, seat‑fill, and emissions that cannot be reconciled with internal metrics. Outcome‑based contracts can then be benchmarked only by the incumbent platform, which weakens Procurement’s position at renewal. Commercially, auto‑renewal with long notice periods, early‑termination penalties tied to “technology investments,” and bundled pricing for routing, apps, and command‑center services make partial vendor replacement difficult.
Procurement and Legal should neutralize these risks by hard‑coding data and interoperability rights into RFPs and MSAs. Contracts should guarantee buyer ownership of all trip, routing, safety, and emissions data with periodic full‑fidelity exports in open formats. Legal should require documented, API‑first integration options for HRMS, ERP, and security systems and avoid exclusive dependencies on a single routing engine or command‑center stack.
Commercially, Procurement should cap termination fees, forbid automatic multi‑year rollovers, and align payment with clearly defined and internally reproducible KPIs. Legal should mandate transparency of KPI formulas for OTP, Cost per Employee Trip, and emissions, and reserve the right to audit underlying logs and change KPI baselines during rebids. Together, they can insist on migration assistance clauses so that a new vendor can reuse existing routes, policies, and historical data without operational disruption.
Useful safeguards to include are: - A clear data‑ownership clause in favor of the enterprise. - Minimum export standards for raw and derived data at agreed frequencies. - Open‑API and documentation requirements as part of technical compliance. - Explicit limits on exclusivity, renewals, and termination‑linked penalties.
Beyond the demo, how do we assess if reliability will hold up in real life—especially exception handling and escalation at odd hours like 2 a.m.?
B0011 Validate reliability beyond the demo — In India employee mobility services across multiple cities, what is the right way to evaluate ‘operational reliability’ beyond a demo—so a Facility/Transport Head can trust that exception handling, NOC escalation, and vendor responsiveness will work at 2 a.m. under real conditions?
How a Facility / Transport Head should evaluate real operational reliability (not just a demo)
Facility and Transport Heads should test operational reliability by validating live NOC behavior, exception-handling SOPs, and multi-city governance under stress scenarios instead of relying on demos or pitch decks. The most reliable indicator is how the provider performs in controlled pilots and night-shift drills that mimic 2 a.m. failures across multiple cities.
The first filter is proof of a functioning 24x7 command center and escalation framework. A credible provider runs a Central Command Centre plus local hubs with defined SLAs for OTP, incident response, and exception closure. The Facility Head should ask for written SOPs for geo-fence violations, GPS failures, driver no-shows, political strikes, and tech downtime, and then verify that these SOPs are wired into the NOC tools, alert supervision systems, and escalation matrix. Absence of audit logs, incident tickets, and closure timestamps is a common failure mode.
The second filter is evidence from live operations and pilots. A provider with multi-city presence and an established ETS/EMS operation cycle can show actual OTP%, fleet uptime, exception counts, and closure SLAs for comparable clients. In practice, Facility Heads should insist on a limited-scope pilot on real shift windows, including at least one night band, and pre-agree test events such as simulated GPS loss, sudden roster change, and vehicle breakdowns. The evaluation metric is not just resolution time but also who called first, what alternative routing or standby playbooks were triggered, and whether HR/security were kept in the loop.
The third filter is governance structure and business continuity planning. A mature operator documents a Managed Service Provider governance model, with clear roles for central and site command centers, and has a written Business Continuity Plan covering cab shortages, natural disasters, political strikes, and technology failure. The Facility Head should check that the MSP governance structure, BCP, and compliance dashboards translate into concrete early-warning alerts, capacity buffers, and cross-city fleet substitution rules. Weak or generic BCPs usually translate into all problems landing on the client team during crises.
Additional practical checks include sample reports from the transport command center, alert supervision logs for overspeeding and tampering, driver and fleet compliance records, and the vendor’s escalation matrix with named contacts for each level. A Facility or Transport Head can use these elements as a repeatable checklist to decide whether a vendor will reduce firefighting or quietly add more of it.
What should we insist on in vendor governance so support and escalation aren’t dependent on one person, and we have a resilient operating model for employee transport?
B0028 Resilient vendor governance model — In India-based corporate ground transportation, what should a buyer insist on in vendor governance (capability audits, tiering, escalation responsiveness, substitution rules) to make sure ‘who answers the phone’ is not a single individual but a resilient operating model?
In India-based corporate ground transportation, buyers should insist on vendor governance that formalizes capability audits, tiered vendor roles, and codified escalation and substitution rules into the contract and SOPs, so operational control rests on a resilient operating model instead of one contact person. The governance model must be anchored in a 24x7 command-center construct, clear KPIs, and pre-agreed playbooks for disruption, rather than informal relationships.
A robust governance design starts with structured capability and compliance audits at onboarding and at periodic cadence. These audits should cover fleet compliance and induction, driver assessment and training, centralized compliance management, safety and women-safety frameworks, and business continuity plans. Evidence such as command-center dashboards, alert supervision systems, and indicative management reports gives the buyer verifiable proof of real operating depth and not just fleet size.
Tiering and substitution rules help avoid dependence on any single supplier node. Vendor and statutory compliance frameworks should define performance tiers, backup fleet buffers, and substitution playbooks during cab shortages, strikes, or technology failures. Business continuity plans and project transition planners should explicitly describe how additional vehicles, associated businesses, and alternative routes or timebands are activated, and who authorizes these switches.
Escalation responsiveness must be expressed as an escalation matrix with named roles, time-bound response SLAs, and linkage to a centralized command center or transport command centre. Buyers should require a dual-layer model. The model should include a centralized command centre for governance, SLA tracking, and safety monitoring, and location-specific command centres for local incident handling. The micro functioning of the command centre and principle role of command centre collateral show how policy design, supervision, risk mitigation, and user satisfaction monitoring are institutionalized.
To make this resilient in daily operations, buyers should lock in the following elements contractually and in joint SOPs.
- Capability and compliance audits tied to go/no-go and continuation decisions.
- Formal vendor tiering with pre-approved secondary suppliers and buffer capacity.
- Escalation matrices mapped to command-center roles with response-time SLAs.
- Substitution and continuity playbooks for cab shortages, political events, technology downtime, and extreme weather.
- Command-center based monitoring, alerting, and reporting as the primary control room, not a single relationship manager.
When buyers insist on this level of vendor governance, daily reliability depends on a tested operating model with centralized visibility, safety and compliance assurance, and codified continuity measures, rather than on who happens to pick up the phone at 2 a.m.
At a high level, what does a mobility command center/NOC do, and why do enterprises see it as essential for SLA reliability and incident response?
B0029 Explain mobility NOC and value — In India corporate employee mobility services, what does a ‘centralized command center / NOC’ actually mean in practical governance terms, and why do enterprises treat NOC observability as table stakes for SLA reliability and incident readiness?
In India corporate employee mobility, a centralized command center or NOC means a 24x7 control-room function that supervises all trips, vendors, vehicles, and exceptions in one place and runs mobility as a governed operation, not as ad-hoc cab booking. Enterprises treat NOC observability as table stakes because reliable SLAs and credible incident readiness are impossible if routing, telematics, safety events, and vendor performance are not visible, correlated, and acted on in real time.
A practical command center consolidates feeds from driver and employee apps, GPS/IVMS, routing engines, and vendor systems into a single operational view. The command team monitors on-time performance, trip adherence, geo-fencing, SOS alerts, and compliance status and follows defined escalation matrices and business continuity playbooks for cab shortages, weather, political events, and tech failures. The command center typically owns exception detection-to-closure SLAs, runs centralized or site-based monitoring desks, and maintains trip and incident logs as audit trails for HR, Security, and ESG reporting.
Most enterprises see this observability as non-negotiable because EMS and CRD reliability, women-safety protocols, and EV fleet uptime depend on early alerts and coordinated response, not post-facto explanations. Without a NOC, OTP%, safety incident rates, EV utilization, and cost KPIs become spreadsheet reconstructions instead of streaming, governed metrics. With a NOC, organizations can enforce outcome-linked contracts, automate compliance checks, support hybrid-work routing changes, and prove carbon and safety performance with traceable data rather than narrative claims.
Safety, Duty of Care & Compliance defensibility
Define day-one defensibility, policy ownership, and defensible incident evidence in alignment with women-safety and DPDP requirements.
If we run employee transport in India, what should HR, Finance, and IT insist is in place from day one so we’re covered for safety incidents, audits, and DPDP privacy compliance?
B0002 Day-one defensibility checklist — In India’s corporate employee mobility services, what should a CHRO, CFO, and CIO each expect to be true on day one for safety & duty of care, billability/auditability, and data privacy (DPDP Act) so that the mobility program is defensible if an incident or audit happens?
Day-one non-negotiables for a defensible mobility program
On day one, a defensible employee mobility program in India must have codified safety SOPs with audit trails, traceable billing linked to approved trips, and DPDP-aligned data flows with role-based access and logs. Each of CHRO, CFO, and CIO should be able to show written policies, live systems, and retrievable evidence that map directly to these three themes.
CHRO – Safety & duty of care
The CHRO should insist that every trip is traceable with a complete trip lifecycle record that includes roster, route, driver identity, GPS trace, OTP/boarding, and feedback closure. There should be women-safety and night-shift policies implemented in routing rules, escort rules, and geo-fencing, not only on paper. An incident response SOP must exist with clear escalation matrices, 24x7 command-center visibility, SOS triggers, and time-stamped incident logs. The CHRO should be able to pull a commute experience and safety report that shows incident rates, closure SLAs, and compliance with escort and rest-hour norms.
CFO – Billability & auditability
The CFO should see that every invoice line item can be reconciled to a specific, system-recorded trip, with time, distance, roster, and SLA status available. Billing models and tariffs must be documented and mapped to contracts so that cost per kilometer and cost per employee trip are explainable from system data. There should be clear linkage between SLAs and commercials, including how penalties or incentives are calculated from OTP, utilization, and exception closure metrics. The CFO must have access to standardized reports that tie vendor invoices to mobility data and to Finance systems without manual reconstruction.
CIO – Data privacy, DPDP & integration
The CIO should require that personal data used for mobility is minimized, purpose-bound, and stored in systems that enforce role-based access and encryption. There must be a documented data-flow and integration map covering HRMS, transport platform, and command center tools, with clear data ownership and retention policies. Audit logs should record who accessed which employee or trip data and when, to support DPDP compliance and incident investigations. The CIO should also verify that vendors expose APIs and export mechanisms so that the enterprise can retain raw mobility data for audits, without being locked into opaque platforms.
What’s the minimum evidence we should capture for safety—incident logs, GPS trip proof, escalations—so we can produce audit-ready reports instantly if needed?
B0008 Audit-ready duty-of-care evidence — In India employee mobility services, how should an enterprise define and govern the minimum evidence standard for safety & duty of care (incident logs, trip GPS chain-of-custody, escalation trails) so that reporting is ‘panic-button ready’ when an auditor or regulator asks for proof?
Enterprises in India employee mobility should define a minimum evidence standard for safety and duty of care as a clearly documented “proof pack” per trip, with tamper-evident GPS logs, incident records, and escalation trails that can be produced within minutes on demand. A practical rule is that every night-shift, women-commute, or escorted trip must be reconstructable end-to-end, from roster approval to drop confirmation, using system-of-record data rather than ad-hoc explanations.
A robust minimum standard starts with codifying what must be captured for every trip. Each trip record should include roster reference, driver and vehicle compliance status, employee manifest, and time-stamped GPS trace aligned with route plans and geo-fence rules. The chain-of-custody must ensure that GPS and trip events come from trusted telematics or app sources, with access-logged changes and retention aligned to Indian transport and labor audit expectations. Safety-related events, such as SOS triggers or route deviations, must create immutable alerts and tickets that link to specific trips and drivers.
Incident and escalation governance needs its own minimum template. Every incident must have a unique ID, time-stamped detection event, assigned severity, and a recorded escalation path that follows a pre-agreed matrix from command center to Security or HR. Closure notes should document actions taken, communication with the employee, and any corrective steps such as driver retraining or vendor penalties. A common failure mode is fragmented handling through calls and chats without tying back to the trip ledger, which leaves HR and Security unable to defend decisions later.
To make reporting “panic-button ready,” organizations should maintain a standardized query and report library in their command center tools. These reports should allow an auditor or regulator to see, in one view, all trips for a given employee, date, site, or incident type, including compliance status, GPS replay, and incident outcomes. Safety dashboards and user satisfaction indices are useful for pattern analysis, but the minimum legal and reputational protection comes from being able to drill down from those summaries into complete, verifiable evidence for any specific case.
Governance of this evidence standard should sit within a formal mobility or transport governance framework that spans HR, Security, Transport, and IT. Policy documents must define retention periods for trip and incident data, ownership of raw telemetry, and DPDP-compliant access controls. Regular internal audits and random route adherence checks should test whether the defined standard is being met in practice, not just on paper. Centralized compliance management, driver and fleet induction processes, and safety inspection checklists are adjacent controls that reinforce the integrity of the evidence captured for each trip.
Enterprises should also integrate this minimum evidence standard into vendor contracts and SLAs. Contracts should specify that vendors provide continuous GPS data, driver compliance proofs, and incident logs in a format compatible with the enterprise command center, with clear penalties for missing or manipulated records. Business continuity plans and command-center micro-functioning playbooks should explicitly cover how evidence capture and retrieval will continue during technology failures, political disruptions, or natural disasters, so that the proof pack remains intact even under stress.
Finally, leadership should treat this as a “continuous assurance” practice rather than a one-time setup. Tools like alert supervision systems, transport command centers, and safety-and-compliance dashboards help move from reactive incident handling to proactive risk detection. The test of readiness is simple and operational: if a serious allegation arises on a past night shift, the organization should be able to reconstruct the full trip within a single working session, supported by auditable data rather than memory or manual logs.
For women-safety and night shifts, what should HR, Ops, and Security/EHS each own, and how do companies stop ‘ownership gaps’ where no one is truly accountable?
B0010 Decision rights for women-safety — In India corporate ground transportation, what decision rights should sit with HR versus Operations versus Security/EHS for women-safety policies (night-shift escort rules, route approvals, SOS and escalation matrices), and how do leading enterprises prevent gaps where everyone assumes someone else owns the risk?
In Indian corporate ground transportation, leading enterprises give HR ownership of policy and employee protection outcomes, Operations ownership of daily execution and evidence collection, and Security/EHS ownership of risk standards and incident governance. Enterprises that avoid “everyone assumed someone else owns it” codify these decision rights in transport policy, escalation matrices, and command-center SOPs, and then tie them to audit trails and QBR-style reviews.
HR typically owns women-safety policy definitions. HR sets who is eligible for transport, night-shift cut-off timings, escort requirements by route and timeband, and mandatory rider protocols. HR usually owns communication to employees and managers, alignment with HRMS and shift policies, and final sign-off on what “safe enough” means for employer brand and diversity goals.
Operations (Transport/Facility) usually owns how policies are executed every shift. Operations controls vendor instructions, route design, roster configuration, and vehicle allocation to meet escort rules and secure routing constraints. Operations teams work through a centralized or site-based command center, monitor OTP and route adherence, and act on live alerts from routing tools, IVMS, and SOS systems. Operations also maintain daily logs, exception reports, and evidence packs needed later by HR, Security/EHS, and auditors.
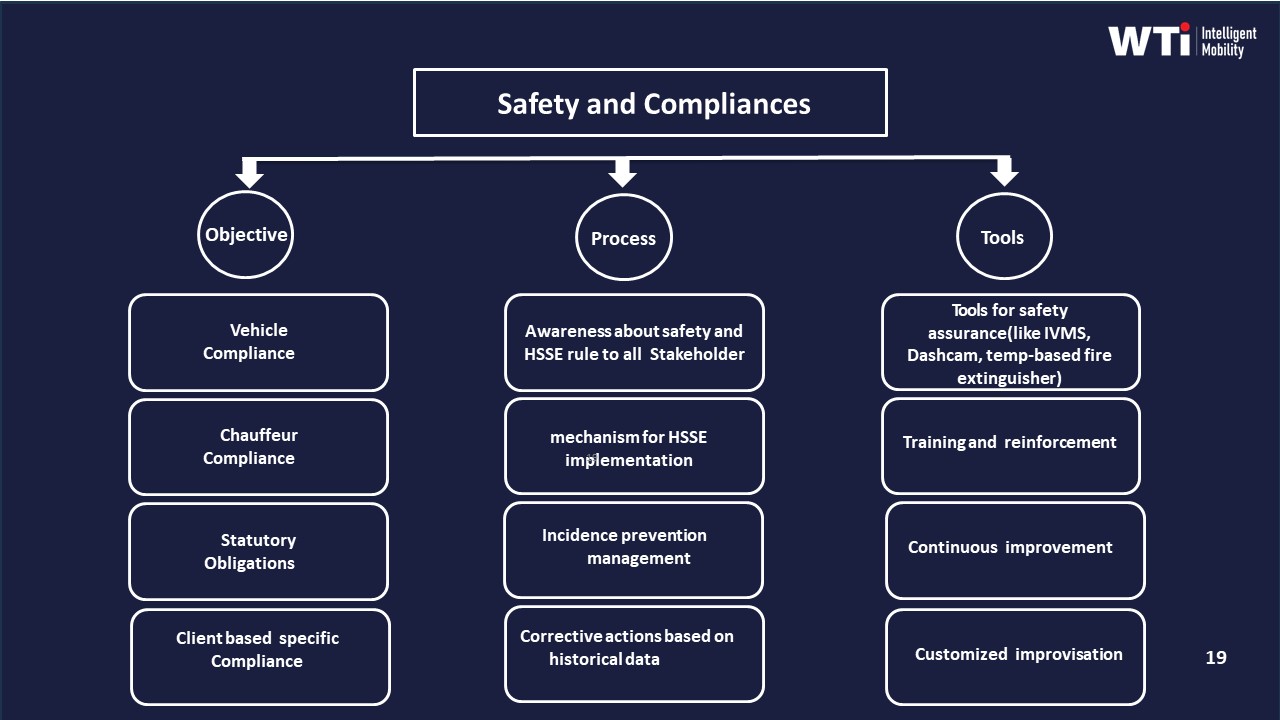
Security/EHS defines safety standards, approves high-risk routes, and governs incident response. Security/EHS specifies escort compliance rules, driver credential thresholds, rest-hour norms, and geofencing or “no-go” zones for night shifts. Security/EHS teams define the SOS and escalation matrix, review serious incidents, and sign off on corrective actions and retraining. They treat trip data, alerts, and dashcams as inputs for risk assessments and HSSE culture programs.
Enterprises that avoid ownership gaps make decision rights explicit at three levels. Policy-level documents state which function is accountable for defining rules versus implementing controls versus verifying compliance. Operational SOPs then map each women-safety control to a step in the ETS/EMS operation cycle, with named roles in HR, Transport, Security/EHS, vendor supervisors, and command centers. Governance-level mechanisms, such as engagement models and command-center frameworks, ensure regular cross-functional reviews of women-safety metrics, incidents, and audit findings.
A common failure mode is assuming that because escort rules and SOS exist in contracts, the vendor “owns the risk.” In practice, enterprises that perform well treat vendors as executors under an internal governance structure. They use centralized compliance management and command-center monitoring to ensure driver KYC, vehicle compliance, escort deployment, and women-centric safety protocols stay current and auditable.
To prevent “grey zones,” leading organizations connect women-safety decision rights directly to data and alerts. HR, Operations, and Security/EHS align on a shared set of KPIs such as night-shift OTP, escort compliance rate, geo-fence violations, and incident closure SLAs. These metrics are surfaced in single-window dashboards or transport command centers, with clear rules on who must respond when thresholds are breached.
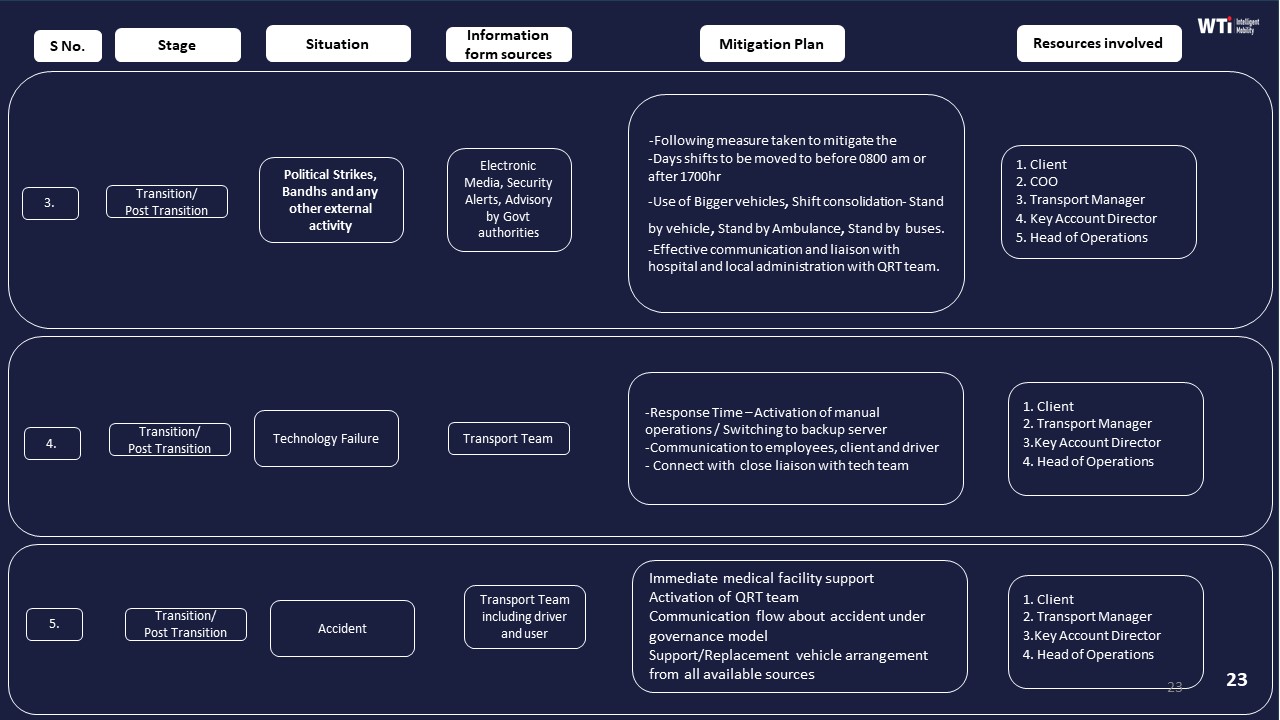
Well-run programs also embed women-safety into business continuity and contingency plans. Political strikes, technology failures, or cab shortages are pre-mapped with explicit responsibilities for HR (employee communication and policy relaxations), Operations (alternate routing and fleet buffers), and Security/EHS (temporary risk overrides and additional controls). This reduces improvisation during crises, when ownership confusion is most dangerous.
Practical signals that decision rights are healthy include: HR can answer leadership questions about “how often this happens” with data; Operations can show live compliance dashboards and route audits; and Security/EHS can reconstruct incidents with complete trip and SOS logs. When any one of these functions lacks that visibility, ownership is usually unclear.
In summary, women-safety in night-shift transport is governed best when HR defines the duty-of-care line, Operations runs a command-center style execution engine, and Security/EHS treats the entire system as a controllable risk domain. Enterprises close gaps by making these roles explicit, wiring them into technology, and reviewing them through structured governance rather than leaving responsibility to implication or vendor promises.
For short-term event or project transport, what should we check so fast scale-up doesn’t break safety compliance, audit trails, or SLA control?
B0018 Scale-up ECS without compliance drift — In India project/event commute services (ECS), what should Operations and Procurement look for to ensure rapid scale-up does not compromise safety compliance, audit trails, and SLA governance when fleet capacity is mobilized temporarily across locations?
In India project and event commute services, operations and procurement should treat rapid scale-up as a governed “pop-up EMS program” with the same safety, compliance, and audit discipline as BAU employee mobility, not as an exception for speed. They should insist on pre-verified supply, command-center visibility, and outcome-linked contracts before any temporary fleet is mobilized across locations.
They should first qualify vendors on continuous compliance automation rather than only fleet counts. This requires proof of driver KYC/PSV cadence, escort and women-safety protocols for night shifts, documented HSSE roles, and fleet induction checks with maker–checker processes. Vendor and statutory compliance frameworks should already exist, including vehicle-age norms, fitness and permit logs, route-approval workflows, and centralized compliance dashboards that surface credential expiries and audit gaps in real time.
Operations should demand a temporary yet fully functional command-center layer for every ECS program. This includes live GPS tracking and geo-fencing, alert supervision for over-speeding and device tampering, a defined escalation matrix, and 24x7 NOC coverage for the event window. Early-warning dashboards for OTP%, route deviations, and incident tickets reduce firefighting and protect on-time performance targets during peak-load movements.
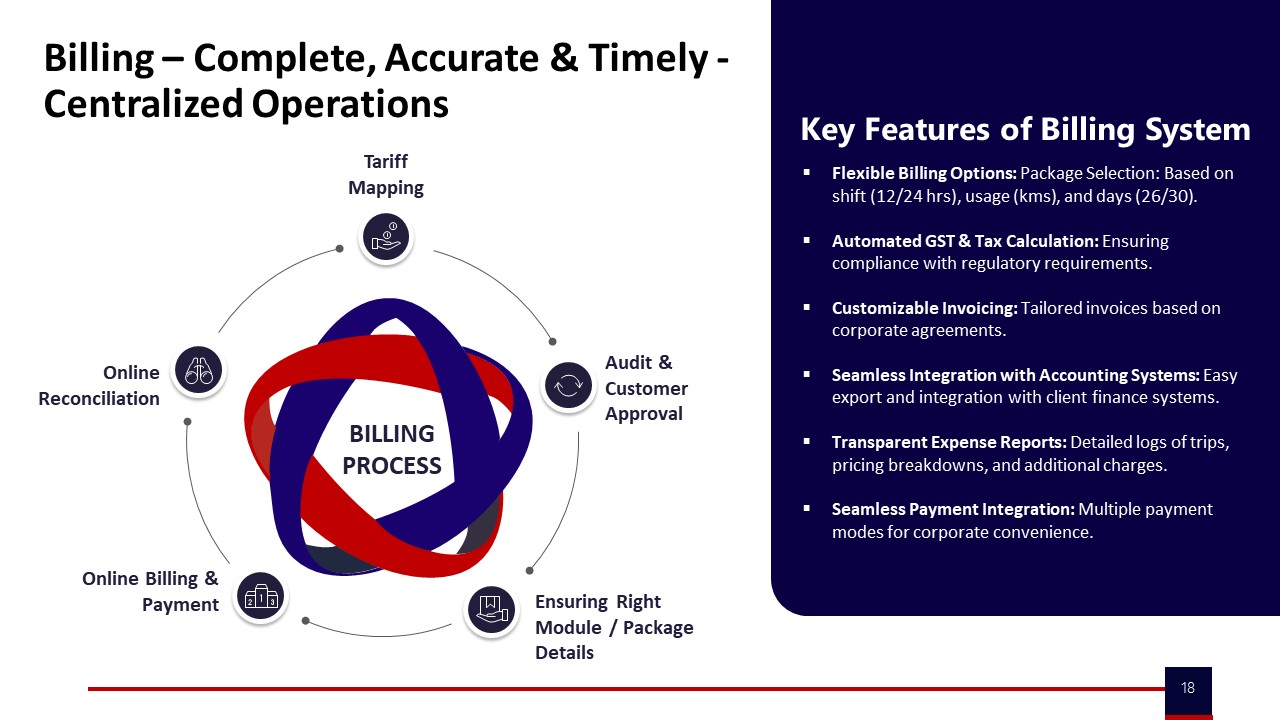
Procurement should structure contracts around verifiable outcomes instead of only per-vehicle or per-hour rates. ECS commercials should reference SLA metrics such as OTP, incident rate, trip adherence, and complaint closure SLAs, with clear penalty and earnback ladders tied to these KPIs. Billing systems should support centralized, auditable invoices with tariff mapping, trip-level reconciliation, and integration-friendly data exports for Finance and Audit.
To keep audit trails intact under time pressure, teams should standardize on a single trip lifecycle and data schema across locations. All rides should run through a common platform for manifests, OTP boarding, SOS events, and feedback, even if fleets are multi-vendor. Command center tooling should preserve tamper-evident trip logs, incident records, and CO₂ reporting where EVs are involved, so post-event reviews and compliance checks are based on traceable evidence rather than manual summaries.
images:

What does duty of care really include for corporate employee transport beyond GPS, and how do companies translate it into policy, evidence, and clear accountability?
B0030 Explain duty of care scope — In India employee mobility services, what does ‘duty of care’ cover for corporate transport beyond basic GPS tracking, and how do leading enterprises translate that into policy, evidence, and defensible accountability?
In India employee mobility services, ‘duty of care’ in corporate transport extends far beyond installing GPS. It covers end‑to‑end safety governance, predictable reliability, and audit‑ready proof that the employer took reasonable, documented steps to protect employees before, during, and after every trip.
Leading enterprises translate duty of care into three layers: policy, live controls, and evidence.
They start with policy. Organizations define who is eligible for transport, night‑shift and women‑safety rules, escort requirements, shift-window limits, rest hours for drivers, and mandatory compliance for vehicles and chauffeurs under Motor Vehicles and labour/OSH norms. These policies explicitly cover EMS routes, corporate car rentals, and project/event commute programs so there are no grey zones in responsibility.
They then hard‑wire controls into operations and technology. Central command centers run 24x7 monitoring, exception alerts, and escalation matrices. Driver KYC, PSV, background checks, and structured training are mandatory. Vehicle fitness, statutory documents, and periodic audits are governed through centralized compliance management. Routing engines enforce approved routes, geo‑fences, and night‑shift rules, while SOS and panic flows are integrated with command centers and security teams.
Finally, they make accountability defensible through evidence. Trip logs, GPS traces, duty slips, driver credentials, and incident records are stored with audit trail integrity. SLAs for on‑time performance, incident response, and complaint closure are measured and linked to vendor governance and commercials. Safety and ESG metrics, including EV utilization and emission reductions, are reported through dashboards that can stand up to HR, EHS, audit, and investor scrutiny.
images:
What does outcome-based procurement mean for mobility, and what needs to be in place—data trust, SLAs, dispute rules—before we tie payments to performance safely?
B0031 Explain outcome-based procurement prerequisites — In India corporate ground transportation and employee mobility services, what does ‘outcome-based procurement’ mean at a high level, and what conditions must exist (trusted data, clear SLAs, dispute rules) before tying payments to OTP/OTD, incidents, and closure SLAs is actually safe?
In Indian corporate ground transportation and employee mobility, outcome-based procurement means structuring contracts so vendors are paid, incentivized, or penalized based on operational outcomes such as on-time performance, safety, utilization, and issue-closure speed rather than only on input metrics like number of vehicles or flat per-km rates. Outcome-based procurement shifts commercial risk towards the mobility provider and forces both sides to agree on measurable reliability, safety, cost, and experience standards before operations start.
Outcome-linked contracts only work safely when the operational data is trusted, the KPIs are precisely defined, and dispute-handling mechanisms are pre-agreed. Organizations need a governed data pipeline that captures trip logs, GPS traces, SOS and incident events, and closure timestamps in a way that is tamper-evident and auditable. Centralized command-center operations, standard trip lifecycle management, and HRMS integration are important so attendance, rosters, and transport data reconcile consistently.
Every KPI used in payouts must have a written definition, scope, and sampling rule. For example, OTP or OTD needs clear grace windows, exclusion rules for force majeure, and a method for dealing with hybrid-work variability. Safety and incident metrics require a shared incident taxonomy and evidence requirements. Closure SLAs need unambiguous start and stop triggers so exception latency can be measured fairly.
Before tying money to outcomes, contracts should include a dispute-resolution playbook, data-ownership and access clauses, and rules for handling data gaps or system downtime. A short calibration phase is usually required, where both client and operator run the metrics in “shadow” mode to validate baselines, seasonality effects, and vendor governance processes across EMS, CRD, and project or event commute services.
Data, Privacy, Security posture & governance
Clarify data handling, a single source of truth, and verifiable security posture with explicit exit strategies and integration non-negotiables.
From an IT view, what are the non-negotiables in APIs, HRMS/ERP integration, reliability, and offline support so we don’t end up locked in or stuck with tech debt?
B0006 IT non-negotiables to avoid debt — In India employee mobility services, what should a CIO consider ‘non-negotiable’ in technology & integration (API-first, HRMS/ERP connectors, uptime/SLOs, offline modes) to avoid building long-term integration debt that later blocks multi-vendor orchestration?
In Indian employee mobility services, CIOs should treat open, documented, and API-first integration, explicit uptime/SLO commitments, and offline-capable apps as non-negotiable conditions for any platform they approve. These elements are what prevent long-term integration debt and keep the enterprise free to orchestrate multiple vendors under a governed MaaS model later.
CIOs need mobility platforms that expose stable, well-documented APIs as the primary way to integrate. The APIs should support HRMS integration for rosters and entitlements, ERP/finance integration for billing and cost attribution, and connectors to security systems, telematics, and charging networks. Any vendor that limits raw data access or locks critical workflows inside proprietary interfaces will create data silos and make future multi-vendor orchestration far harder.
Service-level objectives for uptime and latency should be explicit, monitored, and tied to command center operations. Mobility apps and routing engines must degrade gracefully during partial outages. Driver and employee apps should function in offline or low-connectivity modes with queue-and-sync for manifests, OTPs, and trip logs. Platforms that assume perfect connectivity will fail during peak loads, network glitches, or adverse weather, which are exactly when transport heads need reliability most.
CIOs should insist on clear data schemas, event streams, and audit logs that map to defined KPIs such as OTP%, Trip Adherence Rate, and cost per employee trip. Ownership and portability of trip and telemetry data must be contractually guaranteed so organizations can add or switch vendors without re-architecting. Without these guarantees, each new vendor increases integration debt and operational risk.
For DPDP privacy compliance, what should Legal/DPO insist on around consent, retention, and breach response when we also need live tracking for safety and incidents?
B0014 DPDP privacy vs safety tracking — In India employee mobility services, what should Legal and the Data Protection Officer require in data privacy & governance (lawful basis, consent UX, minimization, retention, breach response) when continuous tracking is also needed for safety and incident response?
In Indian employee mobility services, Legal and the Data Protection Officer should insist on a narrowly scoped, policy-backed tracking model that is clearly lawful, consented, and auditable, while still preserving continuous visibility for safety and incident response. Continuous tracking is acceptable only when the lawful basis, purpose limits, retention rules, and breach playbooks are precisely defined, implemented in technology, and demonstrable in audits.
Lawful Basis, Purpose & Policy Backbone
Legal should mandate a written mobility and safety policy that expressly defines tracking as a safety and compliance control rather than a generic monitoring tool.
The lawful basis should be framed around legitimate interests and legal obligations for employee safety, women’s night-shift protection, and transport compliance.
The policy should clearly separate safety use-cases from productivity or performance surveillance to avoid function creep.
Legal should require an internal DPIA-style risk assessment for tracking, documenting necessity, proportionality, and mitigations.
Consent UX, Transparency & Employee Trust
The DPO should require that rider and driver apps present plain-language privacy notices at onboarding and before enabling location services.
The consent UX should explain what is tracked, when tracking is active, and who can see the data.
Employees should be able to see their own trip history and have access to an easy channel for questions or complaints about tracking.
Legal should require that tracking is visibly tied to an active trip, shift window, or duty cycle rather than 24x7 background collection.
Minimization, Data Design & Role-Based Access
The DPO should insist that location data is collected at the granularity needed for routing, OTP, and incident reconstruction, but not more.
Systems should store only data points required for safety, compliance, billing, and audit trails defined in the policy.
Role-based access controls should restrict raw GPS and trip logs to command center and safety teams with a documented need.
Aggregated or anonymized views should be used for analytics and ESG reporting so individual employees are not exposed unnecessarily.
Retention, Audit Trails & Incident Reconstruction
Legal should define retention windows separately for operational use, billing and finance reconciliation, safety and legal defense, and ESG reporting.
The DPO should require a retention schedule where detailed GPS logs are kept only as long as needed for incident investigation and statutory limitation periods.
Systems should implement automatic deletion or irreversible anonymization aligned to this schedule.
Audit logs should record access to trip and location data so that any incident investigation is reconstructable and traceable.
Breach Response, Vendor Governance & Chain-of-Custody
Legal should require a formal incident response plan specifically covering location data and trip logs.
The DPO should ensure contracts with mobility vendors, telematics providers, and app operators embed DPDP-aligned security, notification timelines, and cooperation duties.
Chain-of-custody requirements should govern how trip data is exported for law enforcement, internal investigations, or external audits.
Command centers should be able to demonstrate both continuous observability for safety and strict controls on who can extract or share underlying data.
What proof should we demand that we can export all mobility data—trips, GPS, incidents, billing—in usable formats so we can change vendors without losing audit history?
B0015 Proof of mobility data exit — In India corporate ground transportation, what should a buyer ask for as proof of ‘data sovereignty & exit strategy’ for mobility data (trip logs, GPS telemetry, incident records, invoicing datasets) so they can switch vendors without losing audit trails or breaking Finance reconciliation?
In India corporate ground transportation, buyers should treat “data sovereignty & exit strategy” as hard, contractable requirements with concrete evidence rather than verbal assurances. Buyers should ask vendors to prove where mobility data lives, who controls it, how it can be exported in full, and how long it will remain auditable after contract end so Finance, Audit, HR, Security, and ESG teams are not exposed.
Buyers should ask vendors to demonstrate, not just promise, the following points.
-
Data ownership, location, and retention
Buyers should insist on a written statement that the enterprise is the legal owner of all mobility data. Buyers should require clarity on where data is physically hosted and how long trip logs, GPS telemetry, incident records, and invoicing data are retained in auditable form. Buyers should ask for configurable retention policies that align with internal audit and statutory needs, including tax and labour records. -
Complete, structured data export
Buyers should require proof that all core datasets can be exported in standard, machine-readable formats without vendor intervention delays. Buyers should ask to see sample exports for at least four domains: trip lifecycle data, GPS/telematics streams, incident and SOS logs, and billing and reconciliation data. Buyers should verify that exports have stable identifiers linking trips, vehicles, drivers, employees, and invoices so Finance and Audit can reconcile independently. -
API-first access and schema documentation
Buyers should ask for current API documentation that exposes trip, roster, GPS, incident, and invoice objects in a consistent schema. Buyers should check that the vendor supports near-real-time pulls into the enterprise data lake, HRMS, ERP, and BI tools. Buyers should verify that there are no contractual or technical blocks on building parallel reporting and analytics outside the vendor’s UI. -
Exit playbook and decommissioning SOP
Buyers should request a written exit playbook that describes how a full data extract will be delivered, how long the platform remains read-only, and how evidence will be preserved for audits after termination. Buyers should ask for timelines, formats, and responsible roles for both sides during offboarding so operations, HR, and Finance can switch vendors without data loss. -
Audit trail integrity and chain of custody
Buyers should require evidence that trip logs, GPS traces, and incident records are time-stamped and tamper-evident so they remain defensible after exit. Buyers should ask how the vendor protects log integrity and how those records can be independently validated later by auditors or legal teams. -
Contractual protections against lock-in
Buyers should ensure contracts explicitly allow ongoing API and export access, prohibit data withholding during disputes, and define SLAs for providing final data dumps. Buyers should also require clauses confirming that data formats and schemas will not be changed without notice in ways that break downstream Finance, HR, or ESG reporting.
How do we set up one consistent source of truth across rosters, access control, trip execution, and billing so Finance isn’t reconciling forever and HR has clean answers?
B0016 Create one mobility source of truth — In India employee mobility services, how should an enterprise create a single ‘source of truth’ across HRMS rosters, access control, trip execution, and ERP invoicing so that Finance doesn’t spend every month reconciling exceptions and HR can answer leadership questions with confidence?
A single ‘source of truth’ in Indian employee mobility services is created by treating HRMS, access control, transport platform, and ERP as producers of events into one governed mobility data layer, and then making all reports, SLAs, and invoices read from that common layer. The enterprise must standardize trip and employee identifiers, enforce API-based integrations, and lock commercial logic to the same dataset that operations and Finance use.
The most resilient pattern is to anchor truth at the trip-lifecycle level. The employee roster in HRMS defines who is eligible and for which shift. The routing and dispatch engine consumes that roster and generates trip IDs, seat manifests, and planned ETAs. Access control or gate systems then validate actual boarding and de-boarding against those manifests. The command center uses telematics and driver apps to record real execution data such as route adherence and OTP. The same immutable trip record then feeds billing and ERP, so that every invoice line item maps back to a verifiable trip ID, employee list, and SLA outcome.
Finance gains control when billing rules are bound to this shared trip ledger instead of vendor-side spreadsheets. Cost per kilometer, cost per employee trip, dead mileage caps, and penalties or incentives are calculated from the same dataset that operations uses for OTP and utilization KPIs. HR gains confidence when leadership questions on safety incidents, women’s night-shift compliance, or no-show patterns are answered from auditable logs with chain-of-custody, rather than ad-hoc reconciliations.
- Standardize IDs for employees, routes, vehicles, and trips across HRMS, access, and transport systems.
- Use API-first integrations so that roster changes, access events, and trip status updates stream into one mobility data lake.
- Define contracts so that invoicing, SLA measurement, and ESG reporting all reference the same governed KPI layer.
What questions help us confirm a mobility provider’s security is real—access controls, encryption, audit logs, incident response—so we’re not relying on paper compliance under DPDP?
B0023 Validate real security posture — In India corporate employee transport, what should a buyer ask to validate that a mobility provider’s security posture (RBAC, encryption, audit logs, incident response) is real and not ‘paper compliance,’ given DPDP Act exposure and sensitive location/identity data?
In India corporate employee transport, buyers should validate a mobility provider’s security posture by forcing the provider to expose how access, data flows, and incidents are handled in practice, not just described in policies. The questions must demand concrete artefacts, live demonstrations, and links to operational tools like command centres, compliance dashboards, and SOS systems that already exist in their ETS/CRD stack.
Access control and RBAC
Buyers should ask mobility providers to show role definitions mapped to real users in their transport platforms and command centres. They should request a demonstration of how the provider separates access for drivers, employees, admins, and command centre staff in tools such as the admin transportation app, Commutr dashboard, and EV command centre dashboards. Buyers should ask who can see PII, trip history, and live locations, and how that differs from who can only see anonymized or aggregated views.
They should ask to see evidence of periodic access reviews and deprovisioning when staff or vendors exit. They should check whether escalation matrices and command centre workflows enforce least privilege when handling incidents or SOS alerts. They should insist on clarity about data access for subcontracted fleet owners, call-centre teams, and OEM or charging partners.
Encryption, data flows, and retention
Buyers should ask where employee and trip data is stored, which systems it flows through, and how long GPS and identity data are retained. They should verify that data used for CO₂ dashboards, ESG reporting, and EV performance analytics is logically separated from PII used for trip operations. They should ask how the provider protects sensitive data within real-time systems such as transport command centres, alert supervision systems, and SOS control panels.
They should ask for written confirmation that any third-party integrations, such as HRMS, partner booking tools, and EV charging networks, follow the same encryption and retention practices. They should review whether billing systems, centralized invoicing, and management reports mask or tokenize employee identifiers while still being reconcilable for audits.
Audit logs and continuous evidence
Buyers should ask mobility providers to demonstrate their audit and reporting capabilities live, using dashboards such as centralized compliance management, safety and security frameworks, and technology-based measurable performance flows. They should verify that every trip, route change, SOS trigger, and command centre intervention creates immutable logs with timestamps and user IDs.
They should ask how long these logs are retained, how often they are reviewed, and how they are tied to KPIs like on-time performance, incident rates, and compliance dashboards. They should verify whether the provider can quickly produce evidence packs for a specific trip, including GPS trails, driver compliance status, and any alerts or escalations during that window.
Incident response and DPDP readiness
Buyers should ask for the provider’s transport-specific incident response SOP covering safety incidents, data exposure, and app or GPS outages. They should examine how SOS alerts from employee apps flow into the command centre, how tickets are created, and how closure and communication are recorded. They should ask for examples of how business continuity plans and contingency playbooks have been used during technology failures, political strikes, or natural events.
They should verify that the provider aligns response processes with DPDP expectations by defining data breach detection, notification timelines, and responsibilities. They should ask who signs off on incident reports, how corrective actions are tracked, and how these link into HSSE tools, safety and compliance frameworks, and user-satisfaction tracking.
Commercials, ROI & governance framework
Structure outcome-based contracts and governance that align safety, reliability, and cost without gaming or disputes.
How do we define ROI for employee transport (attendance, retention, productivity, brand) without relying on the vendor’s own attribution claims?
B0003 ROI without vendor-owned attribution — In India corporate ground transportation programs, how should an enterprise define “business outcomes & ROI” for employee mobility (attendance stability, retention, productivity, and employer brand) without letting the mobility vendor ‘grade their own homework’ on attribution?
Enterprises should define employee mobility ROI using HR-linked outcomes that are owned, measured, and validated inside the enterprise, and only then correlated with vendor data. Vendor data can inform analysis, but HR, Finance, and Transport must control the definitions, baselines, and attribution rules to avoid “grading their own homework.”
Enterprises can start by fixing a small set of business outcomes for employee mobility programs. Typical outcomes include attendance stability, shift start adherence, attrition in transport-dependent cohorts, productivity proxies such as late-login incidents, and sentiment scores tied to commute experience. Each outcome should have a clear KPI, such as no-show rate for transport-linked absenteeism or a Commute Experience Index for commute satisfaction.
The next step is to establish pre-implementation baselines from internal systems. HRMS and time-attendance systems can show late arrivals and absenteeism patterns. HR can track attrition and grievance trends in transport-dependent teams. Employer brand signals can be proxied through internal pulse surveys focused on commute and safety. These internal measures create vendor-independent starting points.
Enterprises should then define a measurement design that separates “what is measured” from “who supplies the data.” Vendor trip logs, OTP percentages, seat-fill, and safety alerts can feed into analysis. However, business impact should be calculated by HR and Finance teams using their own systems and methods. This reduces the risk of mobility providers overstating their impact on employee attendance or retention.
Attribution discipline is strengthened by cohort-based comparisons and time windows. HR can compare teams that use the managed employee mobility service versus teams that do not, or compare pre- and post-rollout periods for the same shifts and locations. Controlling for seasonality and policy changes helps ensure that commute changes are not given full credit for broader HR interventions.
Finally, vendor contracts and governance should explicitly separate operational SLAs from outcome attribution. Operational SLAs can include on-time performance, incident response times, and compliance completeness. Business outcome narratives should be validated during joint reviews using enterprise-owned data. This maintains vendor accountability on service delivery while preserving enterprise control over how employee mobility ROI, including employer brand and productivity, is interpreted and reported.
What governance model stops the usual Finance vs HR clash where Finance optimizes cost but HR gets blamed for safety—especially for women and night shifts?
B0004 Prevent CFO–CHRO mobility conflict — In India employee mobility services, what governance model best prevents recurring CFO–CHRO conflict where Finance pushes lowest per-trip cost while HR is held emotionally accountable for women-safety and night-shift duty of care outcomes?
A dual-mandate governance model works best, where a single mobility board owns both unit-cost targets and women-safety / night-shift duty-of-care outcomes under one, codified SLA framework. This model only reduces CFO–CHRO conflict when safety and reliability are treated as non‑negotiable constraints and cost optimization is applied within those guardrails, not against them.
In practice, this requires a formal Mobility Governance Board that includes HR, Finance, Procurement, Transport, Security/EHS, and IT. HR and Security define explicit safety baselines for women and night shifts, such as escort rules, route approvals, driver KYC/PSV cadence, and SOS and geo-fencing requirements. Finance and Procurement then structure commercials so that vendors compete on cost and efficiency only once those safety baselines are met and continuously evidenced with audit trails and incident logs.
This governance model relies on outcome-linked SLAs and tech-backed evidence. On-time performance and incident-free night-shift metrics sit alongside cost-per-trip and seat-fill KPIs. A 24x7 command-center function centralizes observability and incident response and produces unified reports that both CHRO and CFO can defend. This shifts debates from “cost vs care” to “is the vendor meeting jointly-agreed safety and reliability standards at an efficient cost?” and reduces recurring blame cycles after women-safety or night-shift escalations.
images: 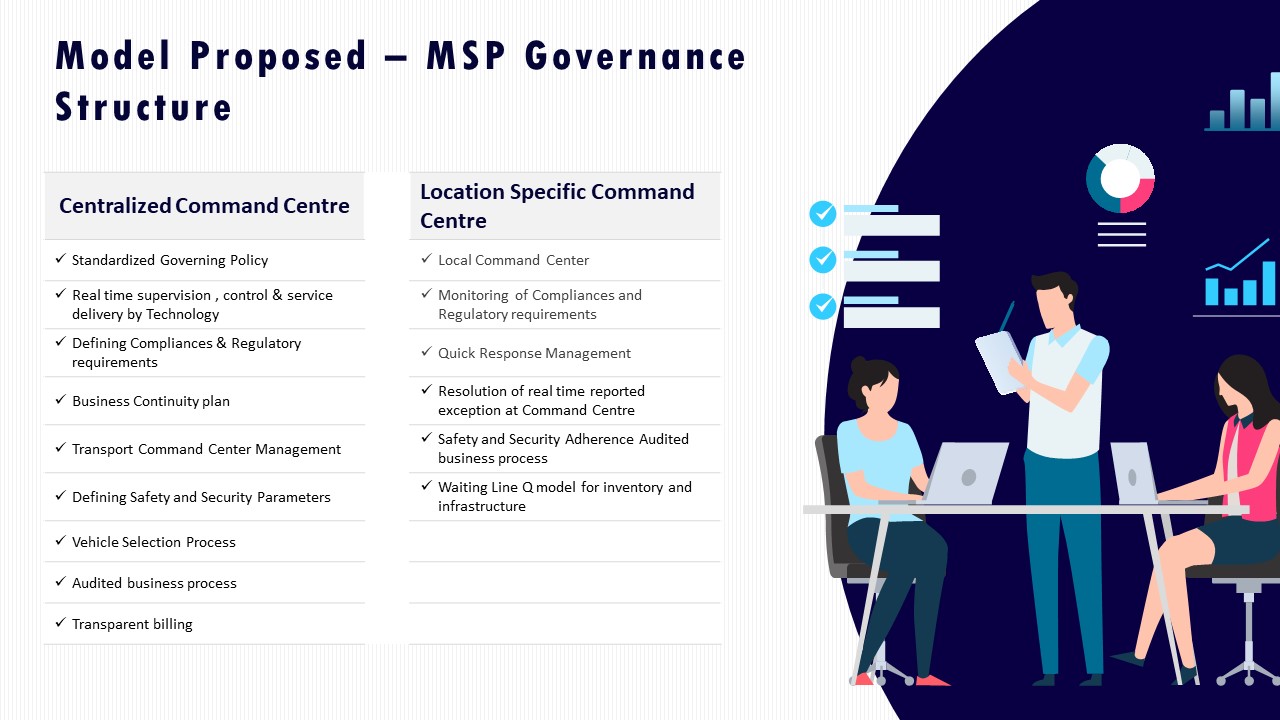
For executive travel cars, how do we balance VIP experience with cost and policy control without creating exceptions that break audit discipline?
B0017 Govern VIP mobility without exceptions — In India corporate car rental services (CRD) and executive mobility, how do buyers govern the trade-off between executive experience (punctuality, vehicle standardization) and cost control without creating ‘VIP exceptions’ that undermine policy discipline and auditability?
Buyers in India govern the trade‑off between executive experience and cost control by pushing everything through a governed CRD program with defined service tiers, common SLAs, and centralized, auditable workflows instead of ad‑hoc “VIP favors”. They protect executive experience at the design level of the service catalog, and then enforce cost and policy discipline through platformized booking, standardized commercials, and SLA‑linked reporting.
In practice, organizations define a small number of clearly documented service tiers for executives. Each tier has pre‑approved vehicle categories, SLA expectations for response time and punctuality, and airport/intercity handling rules. This converts “VIP needs” into catalog items rather than one‑off exceptions. Centralized booking tools and approval workflows then route all CRD demand, including CXO travel, through the same platform. This reduces side‑door vendor use and gives Finance and Procurement a single audit trail for who booked what, under which policy, and at what rate.
Cost control is governed by locking in commercial models and rate cards per tier. Trip‑level analytics and CRD dashboards allow Finance to monitor cost per kilometer and cost per trip per persona, and to detect patterns like “luxury category overuse” or excessive dead mileage. Procurement and Finance can then challenge patterns with data instead of anecdote. Airport and intercity SLA assurance is handled by linking bookings to flight data and publishing punctuality KPIs, so Admin can defend executive experience without needing informal workarounds.
A common failure mode is allowing informal “VIP overrides” at the transport desk. These quickly erode contract discipline and confuse auditors. A more robust approach assigns specific entitlement rules to executive personas and configures them into the booking and billing systems. SLAs for punctuality and vehicle standardization are then measured at the tier level, not negotiated per trip. This keeps CXO expectations aligned with what the system is designed to deliver and makes deviations visible.
To avoid “special treatment” undermining governance, leading buyers use three operational guardrails:
- All trips, including for top executives, must be in the platform and appear in the same centralized billing and MIS.
- Any deviation from standard entitlements requires a recorded exception reason and an approver, visible in audits.
- Outcome‑linked SLAs (response time, on‑time performance, vehicle quality incidents) are tied to vendor scorecards and QBRs, not to informal feedback alone.
This model gives CHRO and Admin the reliability and consistency needed for executive mobility, while giving CFO and Procurement verifiable controls, rate integrity, and a defensible audit story.
For long-term rentals, how do Finance and Ops govern uptime, maintenance, and replacements so continuity is protected without surprise add-on charges?
B0019 Govern LTR lifecycle and upsells — In India long-term rental (LTR) corporate fleets, how should Finance and Operations govern lifecycle risk (uptime, preventive maintenance, replacement planning) so service continuity is protected without the vendor pushing opaque ‘upsell’ maintenance charges?
In India long-term rental corporate fleets, Finance and Operations protect service continuity and avoid opaque upsell charges by hard-coding lifecycle risk into contracts, SLAs, and data-backed governance instead of leaving maintenance to vendor discretion. Service continuity is preserved when uptime, preventive maintenance, and replacement are governed by clear KPIs, evidence trails, and pre-agreed commercial rules rather than ad-hoc approvals.
Finance and Operations teams should first fix a lifecycle governance model for LTR vehicles. This model should define target fleet uptime, acceptable downtime windows, scheduled preventive maintenance cadence, and conditions that trigger vehicle replacement. These elements should be explicitly linked to On-Time Performance, Trip Adherence Rate, and driver duty cycles in employee mobility or corporate car rental contexts.
A common failure mode is letting the vendor define “necessary” maintenance without transparent diagnostics. This failure mode is avoided when all maintenance events are logged in a shared, auditable system with telematics integration and itemized work orders. Finance can then reconcile maintenance against utilization, Cost per Kilometer, and Cost per Employee Trip, rather than relying on narrative justifications.
Service continuity improves when replacement planning is governed by objective thresholds like age, utilization, and recurring defect patterns. Replacement triggers should be encoded in the LTR contract with clear uptime SLAs and defined substitution timelines. This approach protects Operations from repeated breakdowns while blocking vendor-driven “early replacement” pitches that are not supported by data.
Finance should insist on outcome-linked commercials for LTR, where a portion of the rental assumes the risk of preventive maintenance and uptime delivery. Additional maintenance charges should only be billable when they fall outside the agreed duty cycle, misuse patterns, or accident categories, and when they are supported by verifiable incident reports and inspection evidence.
Governance routines such as monthly performance reviews and quarterly business reviews should use a standardized dashboard. That dashboard should track uptime, exception closure times, incident rate, and maintenance cost ratio across the LTR fleet. This gives Operations early warning when a model, route, or vendor location is drifting towards higher lifecycle risk.
Data and integration guard against upsell and hidden risk. Organizations should require access to telematics data, maintenance logs, and compliance records for all LTR vehicles in a structured, exportable form. This data access keeps exit options open, supports benchmarking against alternative vendors, and reduces dependency on any single provider’s narrative.
To keep Finance in control without slowing Operations, organizations can define a simple approval matrix tied to objective thresholds. For example, minor maintenance within a capped amount and predefined categories can auto-approve. Repairs above that cap or outside defined categories should require Finance review with attached diagnostics, trip logs, or incident reports.
Operations teams benefit from codified preventive maintenance windows that align with shift patterns and peak load forecasts. Planned downtime should be scheduled into routing and allocation logic, with standby capacity policies to protect On-Time Performance.
A structured Vendor Governance Framework for LTR improves lifecycle risk control. This framework can tier vendors by uptime performance, complaint rate, and audit findings. Underperforming vendors can then be rebalanced away from critical routes or timebands, reducing systemic exposure.
In practice, Finance and Operations should align on a single “lifecycle scorecard” for LTR vehicles. This scorecard should combine utilization, uptime, incident history, and maintenance cost against contract norms. Vehicles or routes that fall below target can be flagged for proactive intervention, whether through additional maintenance, reassignment, or replacement.
Finally, organizations should treat data portability and auditability as non-negotiable design criteria when selecting LTR partners. Clear rights to trip logs, maintenance records, and compliance documents enable independent audit, support internal and external investigations, and limit the vendor’s ability to frame upsell maintenance as non-negotiable.
What board-level KPIs best balance safety, reliability, and cost without encouraging vendors or teams to hide incidents or game SLA numbers?
B0025 Board KPIs without gaming — In India corporate ground transportation, what governance KPIs are most effective for a board-level view that balances safety & duty of care, operational reliability, and financial exposure—without incentivizing frontline teams or vendors to hide incidents or manipulate SLA reporting?
The most effective board-level governance KPIs in Indian corporate ground transportation separate outcome metrics from truth-telling quality metrics, and they track safety, reliability, and cost together across a consistent trip and audit data trail. Boards get a balanced view when OTP, incident rates, and unit costs are paired with measures of reporting integrity, audit coverage, and exception-closure quality.
A robust dashboard starts with a small, stable set of transport outcomes. On the safety and duty-of-care side, boards track serious-incident rate, women-safety compliance breaches, and credentialing currency for drivers and vehicles. These safety outcomes sit alongside evidence of continuous assurance, such as audit trail completeness, route-adherence audit scores, and coverage of random route audits across high-risk timebands and corridors.
For operational reliability, on-time performance percentage and trip adherence rate are core indicators. These reliability KPIs are anchored in trip lifecycle data, with supporting metrics like exception detection-to-closure time and fleet uptime. The board sees not only headline percentages but also how quickly the command center detects and resolves deviations through defined escalation workflows and business continuity playbooks.
Financial exposure is governed through unit-economics KPIs such as cost per kilometer, cost per employee trip, and maintenance cost ratio. These are drawn from reconciled trip and billing data to avoid leakage and dead mileage blindspots. Outcome-based contracts then link a portion of payouts to reliability, utilization, and safety indicators, while maintaining auditability and avoiding rigid targets that encourage under-reporting.
To prevent gaming or incident hiding, governance adds “meta-KPIs” about the integrity of data and controls. Boards review incident-reporting density relative to trip volume, complaint-closure SLA compliance, and results of periodic independent audits on GPS logs and compliance documentation. Vendor or internal performance is evaluated on transparency, completeness of evidence packs, and responsiveness to corrective actions rather than on low incident counts alone.
Adoption, UX & Change management
Diagnose adoption friction, set minimum UX standards, and confirm audit-ready processes before scale.
For corporate employee transport in India, why do mobility programs still go wrong on safety, on-time performance, or costs even after a vendor is signed, and what early warning signs should leaders watch for?
B0001 Why mobility programs fail early — In India-based corporate ground transportation and employee mobility services (EMS/CRD/ECS/LTR), what are the most common reasons mobility programs fail to deliver predictable safety, SLA reliability, and cost control—even after a vendor is contracted—and how can leadership recognize those failure modes early?
Why contracted mobility programs still fail on safety, reliability, and cost
Corporate mobility programs in India most often fail after vendor selection because governance and data discipline are weaker than the contract language. Leadership can usually detect failure modes early by watching a small set of operational, safety, and cost signals rather than waiting for escalations.
The most common breakdown is fragmented control of EMS, CRD, ECS, and LTR across HR, Transport, Procurement, and Finance. Operations then runs on manual rostering, ad‑hoc routing, and reactive decisions instead of a governed target operating model with a 24x7 command center and exception SLAs. A related failure mode is treating technology as a one‑time “app deployment” rather than an integrated routing engine, driver and rider app stack, NOC tooling, and HRMS/ERP integration.
Safety and compliance often erode when driver KYC/PSV, women‑safety protocols, route approvals, and escort rules remain paper‑based. This creates gaps in audit trails, incident reconstruction, and night‑shift assurance. Cost control fails when dead mileage, seat‑fill, vehicle utilization, and SLA breaches are not tied to billing logic, so leakage stays hidden inside monthly invoices.
Early warning signals leaders should track
Leadership can recognize emerging failure modes early by tracking a few concrete indicators.
- Service reliability: OTP%, Trip Adherence Rate, exception detection→closure time, and repeat complaints by site or timeband.
- Safety and compliance: credentialing currency of drivers and vehicles, escort and route audit scores, incident rate, and quality of GPS trip logs.
- Cost and utilization: cost per employee trip, dead mileage share, Trip Fill Ratio, and Revenue per Cab or Vehicle Utilization Index drift.
- Data and governance: consistency between HRMS rosters, trip logs, and invoices, plus existence of a functioning escalation matrix and quarterly mobility reviews.
When any of these signals are opaque, manually stitched, or repeatedly disputed, most mobility programs are already off track even if the vendor is technically “in contract.”
If employees aren’t using the transport smoothly and complaints are rising, how do we quickly tell if the root cause is policy, operations, or the app experience—before morale takes a hit?
B0012 Diagnose adoption and EX breakdowns — In India corporate mobility programs, how can a CHRO diagnose whether low adoption and poor employee experience (booking/boarding friction, grievance closure delays) are caused by policy design, vendor operations, or technology UX—before the workforce morale drops and managers revolt?
CHROs can isolate whether adoption and commute experience issues come from policy, operations, or technology by treating the mobility program like any other governed process. The CHRO should first separate what is promised (policy and SLAs), what is actually happening (operations and vendor behavior), and how employees touch the system (apps and UX), then test each layer with simple, repeatable diagnostics before morale and manager trust collapse.
A structured diagnosis starts with evidence, not anecdotes. The CHRO can pull a 4–6 week snapshot of basic commute KPIs like on-time performance, trip adherence, no-show rates, complaint volume by category, and complaint closure times. This can be correlated with roster data from HRMS to see whether issues align with particular shifts, locations, or user groups. If there are women’s night-shift safety complaints, for example, these should be cross-checked with escort rules, geo-fencing, and SOS activation logs to confirm whether safety protocols worked but felt slow or failed outright. This gives a first pass on whether the problem looks like systemic underperformance, specific route clusters, or a few high-risk time bands.
The next step is to test policy design independently of vendor and tech. Policy diagnostics focus on entitlement rules, approvals, and exception handling. The CHRO can ask whether current commute policies match hybrid work patterns, if eligibility rules or rigid cut-off times are forcing employees into informal workarounds, and whether there are enough buffers during peak or monsoon periods. If attendance and adoption dip even when OTP and app performance look acceptable, then policy friction is likely dampening usage. Conversely, if policy seems fair and clear but escalation noise is still high, operations or UX are more probable root causes.
Vendor operations are best tested through a command-center lens. Here CHROs can work with the transport head to review daily dashboards, route-wise OTP, fleet uptime, driver availability, and exception → closure timelines. If OTP is consistently below agreed thresholds in specific corridors, if dead mileage is high, or if fleets are chronically short in late-night shifts, these patterns point to vendor capacity or discipline gaps rather than policy or tech. A quick audit of vendor compliance—driver KYC, training records, fatigue management, and GPS uptime—highlights whether safety and reliability controls that look fine on paper are breaking in the field.
Technology UX needs its own focused assessment. CHROs can run 20–30 ride-along tests with volunteers across personas and time bands to directly experience booking, boarding, real-time tracking, and feedback flows. This is complemented by app analytics like drop-offs in the booking journey, frequency of failed OTPs, or SOS button use. If employees report that they default to calls and WhatsApp despite having an app, and telemetry confirms high call-center usage with low in-app booking, then UX and reliability issues are likely the main cause of low adoption. Conversely, if UX tests fine but drivers are late without proactive communication, the fault sits more in routing and operations.
To prevent morale erosion, the CHRO can codify a simple triage SOP that runs every month. This includes a short survey anchored around commute experience (booking ease, boarding predictability, safety perception, and grievance closure), mapped against hard operational data and app metrics. Responses can be tagged to clusters: “policy conflict,” “service unreliability,” or “interface and communication.” Where policy is at fault, quick wins often sit in relaxing cut-offs, clarifying entitlements, or adjusting shift-aligned routing rules. Where operations fail, corrective actions include adding standby vehicles, revising routing logic for congested corridors, and enforcing vendor performance ladders. Where technology fails, the CHRO should work with IT and vendors to simplify flows, harden uptime, and ensure graceful fallbacks for GPS or network failures.
This kind of structured diagnosis creates operational calm. It lets CHROs enter conversations with HR leadership, Finance, and Facilities with data-backed clarity on whether policy reform, vendor discipline, or tech hardening is required. It also helps define outcome-linked procurement and targeted vendor governance, so that shifts in policy or partner mix are driven by measurable gaps rather than escalating frustration from managers and employees.
What kind of peer references should we ask for—same industry, similar scale, similar shift and women-safety needs—so we can defend the mobility platform choice internally?
B0022 Right social proof for mobility — In India corporate ground transportation, what ‘social proof’ should a risk-averse buyer demand (industry peers, similar scale, similar shift patterns, comparable women-safety constraints) before backing a mobility platform decision internally?
In India corporate ground transportation, a risk-averse buyer should insist on social proof that matches their own risk profile on scale, shift patterns, and women-safety exposure. The most defensible internal case is built on references and evidence from industry peers with comparable network complexity, night operations, and governance expectations, not from generic testimonials.
A strong social-proof set usually combines three elements. First, peer logos and contract tenures from similar enterprises help show that organizations of comparable scale and scrutiny already trust the provider. Long-running contracts with Fortune-500 tech firms, banks, or global corporates are especially persuasive when they use structured employee mobility services and corporate rentals with SLAs. Second, detailed case studies are needed that mirror the buyer’s operating reality. For example, references where an EV fleet was deployed for a tech campus with 24/7 shifts, or where women’s late-night commute reliability improved to 98% on‑time with higher satisfaction, are more credible than generic “improvement” claims. Third, quantified before–after metrics should be present on reliability, safety, and sustainability. Evidence such as on-time performance rising to the high 90s, customer satisfaction scores above 90%, material CO₂ reduction, or documented reduction in complaints gives the CFO, HR, and Security functions something concrete to defend.
Risk-averse buyers should also verify that social proof includes command-center operations, business continuity planning, and centralized compliance management across multiple cities. They should check that women-safety protocols, driver vetting, and SOS flows have been exercised at scale and are supported by audit-ready logs and dashboards, not only by policy documents.
images:


How do we set a minimum UX and ease-of-use bar so employees don’t reject the new transport system and revert to Excel workarounds?
B0026 Set minimum UX for adoption — In India employee mobility services, how should an enterprise set a ‘minimum acceptable user experience’ standard (learning curve, app stability, fallback processes) so adoption doesn’t collapse when frontline employees and supervisors compare it unfavorably to their existing Excel-driven workflows?
An enterprise should define “minimum acceptable user experience” for employee mobility tools as a set of non‑negotiable operational behaviours: near-zero learning curve for frontline staff, predictable app stability in peak and night shifts, and clear offline or manual fallback SOPs that keep trips running when technology misbehaves. This standard must be framed in operational terms that beat or at least match the reliability of existing Excel- and phone-driven workflows.
A common failure mode is treating UX as screens and features instead of shift-level behaviours. Frontline supervisors benchmark new tools against today’s reality of WhatsApp groups, Excel rosters, and direct driver calls. If the app adds steps, slows roster changes, or fails during GPS or network glitches, adoption silently drops back to manual methods. A practical standard therefore ties UX expectations to KPIs like on-time performance, exception closure time, and number of calls per shift, not just to training completion.
The “minimum acceptable” standard should be codified before rollout as a short, testable checklist that Transport Heads and site supervisors can own. For example: - Learning curve: A new supervisor should be able to create and modify rosters and routes solo after one live shift of shadowing. Any process that still needs central support after a week is too complex. - App stability: The employee and driver apps, plus the dispatcher console, must stay usable during peak windows and night shifts with defined uptime targets. Error states must be simple and recoverable, with clear prompts that avoid data loss on re-login or poor connectivity. - Fallback processes: For every critical step in the ETS / EMS operation cycle—booking, rostering, routing, dispatch, tracking, SOS, and closure—there should be a documented manual alternative that is no slower or riskier than the current Excel and phone method. These SOPs should include who switches to manual, how trips are recorded for billing and compliance, and how data is later synchronized.
Most operations teams also need “control-room simplicity.” That means a single-window dashboard for core tasks instead of multiple tabs and tools, predefined views for each role (command centre, transport desk, vendor), and alerting that surfaces only the exceptions that require action. If supervisors must hunt through complex menus to do what they previously managed in one spreadsheet, the system will be bypassed during busy shifts.
To reduce resistance from employees and drivers, the UX baseline should prioritize a few high-impact behaviours. This includes one-tap trip check-in and SOS in rider apps, clear “today’s trips” and navigation in driver apps, and real-time visibility of vehicle ETAs that matches or exceeds current informal phone updates. These behaviours directly influence perceived reliability and safety, which are stronger adoption drivers than abstract “digitalization” goals.
Finally, minimum UX standards should be validated through a controlled pilot rather than assumed from design. A short pilot with one or two sites, run across full ETS operation cycles, can measure whether calls to the transport desk drop, Excel usage genuinely reduces, and OTP and incident rates at least hold steady. If the tool cannot match Excel-era stability under real monsoon, festival, or night-shift stress, the enterprise should treat it as not yet meeting the minimum acceptable user experience for scale rollout.
What audit surprises happen most often in corporate transport—missing trip proof, roster mismatches, GPS issues, penalty disputes—and how do we design governance so we’re not scrambling during an audit?
B0027 Prevent audit surprises in mobility — In India corporate mobility programs, what are the most common ‘audit surprise’ scenarios (missing trip evidence, mismatched rosters, unverifiable GPS logs, disputed penalties), and how should governance be designed so leadership isn’t scrambling when auditors are onsite?
In Indian corporate mobility programs, the most common “audit surprises” are missing or inconsistent trip evidence, roster–trip mismatches, unverifiable GPS or safety logs, and penalties or EV/ESG claims that cannot be tied back to auditable data. Governance needs to be designed so that every trip, exception, safety event, and invoice line has a clear, tamper-evident trail from HR roster to GPS log to bill and report.
The first failure pattern is fragmented data. Manual rostering, ad-hoc vendor logs, and un-synced HRMS, finance, and transport systems create gaps between who was rostered, who actually traveled, and what was billed. A second pattern is weak command-center discipline. Exceptions, SOS events, geofence violations, and delays are handled reactively, but the closure actions and timestamps are not logged in a structured way, so they are hard to reconstruct later. A third pattern is compliance-by-declaration. Driver KYC, vehicle fitness, women-safety protocols, and night-escort rules exist on paper, but there is no continuous, system-backed evidence, only periodic audits and spreadsheets.
A resilient governance design relies on a central command framework, integrated with HRMS, ERP and telematics, and built around continuous assurance rather than end-of-year clean-up. Each trip should generate a unified record that includes roster reference, trip OTP/manifest, GPS trace, driver and vehicle compliance status, and any exception tickets. Penalties, incentives, and EV-related ESG metrics should be computed from this common record, so auditors see one consistent source of truth.
To prevent leadership scrambling when auditors arrive, operations teams typically need four concrete guardrails:
- A single mobility dashboard that exposes OTP, incident logs, CO₂ metrics, and billing KPIs from the same data backbone.
- A defined SLA and escalation matrix for incident detection-to-closure, with command-center logs retained as evidence.
- Automated compliance alerts for expiring documents, route deviations, and SOS events, with closure comments stored.
- Standardized, exportable evidence packs for random route audits, safety incidents, and ESG reporting.
EV/Infrastructure, Data discipline & Exit readiness
Address EV charging topology, data exit, and supplier substitution readiness with ownership and evidence trails.
How should we design outcome-based payments and penalties for on-time performance, incidents, and seat-fill so it actually reduces disputes instead of increasing billing headaches?
B0009 Outcome-linked commercials without disputes — In India corporate employee mobility (EMS and CRD), how should Finance structure outcome-linked commercials (earnbacks/penalties tied to OTP/OTD, incidents, seat-fill, closure SLAs) so they reduce disputes and gaming rather than creating new reconciliation work each billing cycle?
Finance teams in India should structure outcome-linked commercials in employee mobility so that a small, clearly defined set of KPIs is contractually tied to payouts, and every KPI is calculated from the same reconciled trip data that already drives billing. Outcome-linked incentives should sit “on top of” a stable base model rather than forcing a parallel reconciliation process.
A core design principle is to use a narrow KPI basket that reflects how EMS and CRD actually run. Finance can prioritize on-time performance for pickups and drops, incident rate, seat-fill levels, and closure SLAs that measure how quickly issues are resolved. Each KPI should be precisely defined in the contract, with unambiguous formulas and data sources aligned to central command-center telemetry and trip logs. This prevents disputes about “what counts” during monthly settlement.
Another safeguard is to anchor all earnbacks and penalties to a small number of threshold bands instead of complex, continuous formulas. This reduces gaming, because operators cannot easily chase marginal gains that are hard to verify, and it also keeps calculation effort low for each billing cycle. The same SLA trackers and audit trails used for operational governance can then be used as the reference system for finance, so there is no separate “finance-only” dataset to reconcile.
To avoid new reconciliation work, Finance can insist that the vendor’s platform outputs a single, standardized summary each month. That summary should show invoiced trips, calculated KPIs, and resulting incentive or penalty amounts in one integrated report. Finance then only needs to check sample-level evidence where variances are large, rather than recomputing everything. This aligns with the broader industry move toward outcome-linked procurement, where payments are indexed to clearly measured reliability, safety, and service governance rather than ad hoc negotiation after each exception.
What are the real governance trade-offs between multi-vendor mobility vs a single consolidated vendor, and how do we choose without creating internal politics and blame later?
B0013 Multi-vendor vs single-vendor trade-offs — In India corporate ground transportation, what are the governance risks of running a multi-vendor aggregation model for EMS/CRD (tiering, substitution playbooks, data consistency) versus single-vendor consolidation, and how do buyers choose without creating political fallout internally?
In corporate ground transportation in India, multi-vendor aggregation increases governance complexity and data risk but reduces dependency, while single-vendor consolidation simplifies governance but concentrates operational and political risk. Buyers usually choose by mapping reliability, safety, cost, and data-control outcomes to each model and then designing explicit governance, tiering, and exit mechanisms so that no single function is blamed when issues surface.
Multi-vendor EMS/CRD models create governance risk when vendor tiering and substitution rules are informal. A common failure mode is having “A/B/C vendors” without clear entry and performance criteria, no documented substitution playbooks by timeband or region, and inconsistent trip and billing schemas across partners. This undermines centralized command-center operations, weakens SLA comparability, makes route adherence and OTP% hard to benchmark, and complicates audit trails for safety, driver KYC/PSV, and billing.
Data consistency is a second risk in multi-vendor models. When each vendor uses different telematics, routing engines, and trip‑closure logic, HRMS integration, Finance reconciliation, and ESG emissions reporting become manual and error-prone. This erodes CFO confidence in CET/CPK numbers, limits ESG and EV reporting credibility, and raises DPDP and auditability concerns for CIO and Security teams.
Single-vendor consolidation shifts risk in the opposite direction. Governance is simpler because SLAs, routing policies, safety protocols, and billing models are standardized and observable through one command framework. However, buyers face concentration risk, vendor lock-in through closed APIs and proprietary data schemas, and higher political exposure if that vendor fails on women’s safety, night‑shift reliability, or EV uptime after Board or ESG commitments have been made.
To choose without internal political fallout, most enterprises align the model to stakeholder KPIs and then hard‑code protections into the operating model. HR and Security prioritize safety and audit trails, the CFO and Procurement prioritize CPK/CET predictability and clean billing, the Facility/Transport Head prioritizes OTP and driver reliability, and the ESG lead prioritizes EV utilization ratio and emission-intensity metrics. Governance risk is then reduced through explicit multi-vendor tiering rules, standardized trip and billing schemas, SLA-linked substitution playbooks, and API‑first data ownership clauses that keep exit and rebalancing options open, even under a lead-vendor or “single throat to choke” structure.
If we’re pushing EV and ESG in mobility, what do we need for investor-grade emissions numbers—traceability, method clarity, and audit readiness—so we don’t face greenwashing accusations?
B0020 Investor-grade mobility emissions proof — In India corporate mobility programs pursuing ESG & EV transition, what should an ESG Lead require to make emissions reporting investor-grade (traceable inputs, consistent methods, audit-ready calculations) so the organization avoids greenwashing risk?
Investor-grade commute emissions reporting in Indian corporate mobility requires that ESG leaders demand traceable raw data, a consistent calculation method, and an audit-ready control framework that links trips to carbon outcomes. Emission claims must be reconcilable to enterprise systems, vendor logs, and recognized ESG frameworks, or they will be vulnerable to greenwashing accusations.
An effective ESG lead first anchors emissions reporting in operational reality. Commute data should originate from governed Employee Mobility Services and Corporate Car Rental platforms rather than spreadsheets. Each trip should have a unique identifier, GPS or odometer-backed distance, vehicle type or powertrain, and employee or cost-center tag. Vendors should expose this through a mobility data lake or API, preserving audit trail integrity and enabling Scope 3 calculations. In EV programs, telematics data on battery usage and charging sessions should be linked with shift windows and route patterns to support EV utilization ratio and emissions intensity per trip.
A consistent, defensible calculation method is critical for emission factors, baseline selection, and attribution rules. ESG leaders should align methods with frameworks already referenced in collateral, such as SEBI BRSR and GRI, and ensure commute emissions are tied back to procurement and finance data rather than stand-alone ESG reports. Diesel-to-EV transition metrics, such as CO₂ reduction per 100 km or per ride, must be derived from transparent comparisons between specific ICE and EV models, as illustrated in carbon reduction comparisons and EV case studies.
Finally, the ESG function should insist on a controls and governance layer around commute emissions. This includes dashboards for real-time CO₂ reductions, documented procedures for data extraction and calculation, and periodic internal or third-party audits of mobility data. EV programs should maintain clear evidence of fleet mix, charger deployment, uptime, and cost per kilometer, similar to case-study style results that show CO₂ tonnage reductions and operational KPIs over time. A structured governance model with a central command center, compliance dashboards, and managed service provider oversight ensures that emission numbers are continuously assured rather than assembled ad hoc at reporting time.
If we add EVs for employee transport, how do we assess charging and range risks for night shifts and peak hours, and who should be accountable for those risks?
B0021 Own EV reliability risk — In India employee mobility services with EV adoption, how should Operations evaluate the risk that charging topology and range constraints will degrade SLA reliability for night shifts and peak windows, and who should own that risk—Transport Ops, ESG, or the vendor?
Operations teams in India should treat EV charging topology and range constraints as a first-order reliability risk that must be quantified through data and modeled against shift windows, and this risk should be co-owned under a clear split: Transport Ops own service design and SLA outcomes, the vendor owns EV and charging performance within defined parameters, and ESG owns only the integrity of emission claims, not uptime.
Most organizations need to start with a structured risk analysis anchored in their actual EMS operation cycle. Transport heads should map every night-shift and peak route to required pax-km and buffer, then stress-test vendor proposals against those patterns. A practical failure mode is assuming “city has chargers” without checking charger density where night clusters actually are or whether 30–40 km of dead mileage plus queue time pushes batteries below safe operating thresholds.
Command-center data and telematics should be used to simulate a mixed ICE/EV fleet across peak windows, capturing OTP%, fleet uptime, and dead mileage under different charging schedules. If the EV fleet cannot maintain OTP and Trip Adherence Rate in modeled peak and night bands, then the charging topology is not production-ready, regardless of ESG benefit. A common pattern of failure is delegating all design responsibility to the vendor without codified guardrails on minimum EV state-of-charge at shift start, hard limits on mid-shift charging, and replacement rules.
Risk ownership should be explicit in contracts. Transport Ops should own route design, shift windowing, and the decision on EV share per band, and they should be accountable for SLA governance at the command center. The vendor should own EV-specific risks inside clearly defined operating envelopes, such as battery health, charger uptime, response time for replacement vehicles, and compliance with agreed charging topology. ESG teams should own sustainability metrics, such as gCO₂/pax-km and EV utilization ratio, but they should not be accountable for on-time performance in night shifts.
To keep night-shift reliability stable, Operations can use these practical guardrails:
- Run a pilot in the hardest timebands first, with full OTP and incident logging, before scaling EV share.
- Define separate EV/ICE fleet-mix policies for night vs day and for peak vs non-peak windows.
- Build SLA clauses for charger uptime, response time for breakdowns, and mandatory backup ICE capacity for defined critical routes.
- Anchor ESG reporting on data from the same telematics and trip ledger used for OTP and fleet uptime to avoid greenwashing and hidden reliability trade-offs.
When HR is urgent, Finance is strict, and IT is blocking on integration, how should Procurement run a defensible mobility buying process without politics or a rushed decision?
B0024 Run defensible mobility buying process — In India employee mobility services, how should Procurement run a defensible buying process when HR is demanding urgency after incidents, Finance wants tighter controls, and IT is blocking on integrations—so the process doesn’t collapse into politics or a rushed, risky award?
In India employee mobility services, Procurement runs a defensible buying process by forcing the discussion into explicit outcomes, evidence, and constraints, and then encoding these into a structured, multi-criteria evaluation that all stakeholders sign off on before vendors are shortlisted. Procurement protects itself from politics and rushed awards by fixing the “rules of the game” early, making every trade‑off visible, and tying final selection to traceable, audit‑ready artefacts instead of verbal pressure.
Procurement needs to start by defining scope and boundaries across EMS, CRD, ECS, and LTR. Procurement should document what problems are in scope, such as night‑shift safety, OTP gaps, or fragmented billing, and what is out of scope, such as retail taxi use or ad‑hoc non‑compliant vendors. This scoping prevents HR’s incident-driven urgency from broadening requirements mid‑process.
Procurement should convert stakeholder tensions into explicit evaluation dimensions. HR’s safety and employee-experience concerns translate into scored criteria for women-safety protocols, audit trails, OTP, and incident closure SLAs. Finance’s control requirements become checks on billing transparency, linkage of invoices to trip logs, and the ability to support CET/CPK baselines and outcome-linked commercials. IT’s integration constraints become mandatory items for HRMS/ERP APIs, data ownership, DPDP-compliant security, and role-based access.
Procurement then needs to define minimum technical and compliance gates before commercials. Vendors should be screened first on compliance automation, command-center capability, safety by design, and integration fit. Only vendors who clear this gate should reach price comparison. This sequencing avoids a lowest-cost, highest-risk award that HR or Security will later contest.
A structured RFP and scoring matrix should be created that assign explicit weightages to safety, reliability, technology, cost, and ESG impact. Procurement should align these weightages with HR, Finance, IT, and Security up front. This alignment should be documented with sign-offs so that late-stage political pressure is constrained by the pre-agreed scoring.
Procurement can reduce politics by insisting on evidence, not promises. Vendors should be asked for live or documented proof of OTP %, incident handling, EV uptime, and command-center performance. Case studies that demonstrate performance under stress, such as monsoon conditions or night-shift safety programs, are particularly useful. The WTicabs case study on Mumbai monsoon routing is an example of such evidence.
Finally, Procurement should plan for resilience and exit at the contracting stage. Contracts should include multi-vendor or buffer capacity, business continuity playbooks, and clear exit and data-portability clauses. This reassures IT and Finance that the organization is not locked into a weak vendor and makes HR more comfortable that escalation paths exist if a vendor’s performance degrades.
- Define scope and non-scope clearly across EMS, CRD, ECS, and LTR.
- Translate HR, Finance, and IT concerns into explicit, weighted evaluation criteria.
- Use hard technical and compliance gates before opening commercials.
- Demand operational evidence and command-center capability, not just feature lists.
- Design contracts with clear exit, BCP, and data-portability to limit downside risk.