How to translate SRE mindsets into an EMS stability playbook
In the control room, you live the problem every shift—driver shortages, weather and traffic disruptions, and late pickups. This playbook converts SRE ideas into repeatable guardrails you can actually use: clear ownership, predictable escalation, and runbooks you can follow even during peak or night shifts. It’s not a demo; it’s a practical plan to reduce firefighting and keep leadership confident in reliability.
Is your operation showing these patterns?
- 2 a.m. escalation spikes with driver no-shows and unreachable vendors
- GPS/app outages create blind spots just as dispatch needs visibility
- Vendor tickets pile up with conflicting updates, delaying decisions
- Dashboards show green OTP while riders experience long ride times
- Night shift fatigue and rushed substitutions after hours
- Routes blocked or vehicle issues trigger manual fallbacks that feel chaotic
Operational Framework & FAQ
Operational guardrails and escalation discipline
Defines who acts during outages, how to escalate, and how to recover without chaos; establishes fallback, communications, and ownership you can rely on in off-hours.
For our employee commute ops, what does an SRE mindset mean in day-to-day terms, and how is it different from our usual SLA reviews?
B1454 Meaning of SRE mindset — In India corporate Employee Mobility Services (EMS) commute operations, what does an "SRE mindset" actually mean day-to-day for transport reliability, and how is it different from a normal transport SLA review meeting?
An SRE mindset in Indian Employee Mobility Services means running daily transport like a mission‑critical system using reliability engineering, live telemetry, and incident playbooks, not just chasing monthly SLA numbers. It focuses on preventing failures, reducing impact when they occur, and continuously improving OTP, safety, and compliance with data, rather than blaming vendors after things break.
In day‑to‑day EMS ops, an SRE mindset changes how the transport or facility head, command center, and vendors work. Command center operations, alert supervision systems, and dashboards are treated as core tools to detect issues early and triage them fast. Route optimization, fleet utilization, and driver performance are tuned continuously using data‑driven insights rather than adjusted only after escalations. Business continuity plans, mitigation for technology failures, and contingency routing are rehearsed so that GPS outages, EV charging delays, or monsoon traffic do not turn into night‑shift crises.
A normal transport SLA review is retrospective and commercial. It checks OTP%, incident counts, billing disputes, and penalties once a month or quarter. An SRE mindset is operational and continuous. It asks why specific trips were late, how exception detection and closure time can be reduced, and what automation or SOP changes will prevent recurrence. A normal review focuses on whether SLAs were met. An SRE mindset focuses on making the next week more stable through change management, capacity buffers, and better observability.
For a facility or transport head, the practical differences show up as:
- Daily reliability stand‑ups using live command‑center dashboards instead of waiting for MIS.
- Runbooks for geofence violations, over‑speeding, GPS failure, or app downtime, with clear escalation matrices.
- Continuous tuning of routing, fleet mix (EV/ICE), and driver rosters based on OTP and incident data.
- Structured post‑incident reviews that change SOPs, alerts, or vendor configuration, not just “noted for future.”
An SRE mindset therefore reduces firefighting and 2 a.m. calls by designing reliability, safety, and continuity into EMS operations, while a normal SLA review mostly reports how bad the firefighting was after the fact.
Why should our transport team use SLOs and error budgets instead of only tracking OTP, and what pain does it actually solve?
B1455 Why SLOs over OTP — In India corporate ground transportation for employee commute (EMS), why would a Facilities/Transport Head adopt SLOs and error budgets instead of just tracking on-time pickup/drop, and what business pain does that shift solve?
In Indian employee commute operations, a Facilities/Transport Head adopts SLOs and error budgets to convert vague “good service” into explicit, tolerated failure ranges that can be governed, traded off, and defended. This shift reduces constant firefighting, stabilizes night-shift operations, and gives transport teams a clear control-room language to align HR, Procurement, and vendors around reliability, safety, and cost.
Traditional on-time pickup/drop (OTP) tracking is backward-looking and coarse. It shows how many trips were late, but it does not define how much unreliability is acceptable, for which routes or shifts, and at what cost. It also ignores other critical EMS dimensions like exception closure time, route adherence, safety incidents, and dead mileage, which directly affect hybrid-work elasticity, driver fatigue, and vendor performance under SLAs.
Service Level Objectives (SLOs) define reliability targets across multiple EMS KPIs. Error budgets define how much deviation from these targets is acceptable in a given period before a response is triggered. This creates predictable rules for when to relax constraints (e.g., during extreme weather or political disruption) and when to tighten operations or invoke business continuity playbooks.
This shift solves several recurring pains for the Facilities/Transport Head. It reduces subjective blame when traffic, charging gaps, or vendor constraints cause delays, because agreed error budgets and escalation matrices exist. It enables data-driven conversations with vendors under outcome-linked contracts, where payouts and penalties are mapped to SLO adherence, not just OTP snapshots. It also supports centralized command-center operations by tying alert thresholds and triage workflows to explicit error budgets instead of ad-hoc reactions.
For hybrid and EV-heavy EMS programs, SLOs and error budgets help balance reliability, fleet utilization, and ESG outcomes. A transport head can decide, for example, how much OTP degradation is tolerable to gain higher EV utilization or reduced dead mileage, and then monitor that trade-off transparently. Over time, this reduces operational noise, protects the Facilities/Transport team from 2 a.m. escalations without context, and provides audit-ready evidence that reliability and safety are being managed proactively rather than reactively.
How do runbooks help with recurring issues like late pickups or app/GPS problems, and what should a solid runbook include so night shifts aren’t dependent on one person?
B1456 Runbooks for commute incidents — In India corporate Employee Mobility Services (EMS), how do runbooks work in practice for recurring commute incidents (late pickups, no-shows, GPS/app outages), and what should a good runbook contain so the night shift doesn't depend on one heroic person?
In Indian corporate Employee Mobility Services, effective runbooks convert recurring commute incidents into predefined, stepwise responses that any night-shift coordinator can execute. A good runbook specifies clear triggers, roles, time-bound actions, and communication templates so late pickups, no-shows, and GPS or app outages are handled predictably, not via individual heroics.
In practice, runbooks sit between the command center SOPs, the EMS operation cycle, and the escalation matrix. Operations teams use real-time dashboards, alert supervision systems, and transport command centres to surface incidents, then follow the runbook to triage and close each case within defined SLAs. A common failure mode is a runbook that describes “what should happen” but not “who does what in which minute,” which forces the night-shift lead to improvise.
A robust EMS incident runbook for recurring issues should include:
- Precise triggers per scenario. Example: “Pickup delay >10 minutes vs ETA,” “driver not reachable for 5 minutes,” “vehicle icon not moving for 8 minutes,” “app downtime > 5 minutes for >10% users.”
- Role-by-role actions. Specific steps for transport desk, vendor supervisor, command center operator, and, when needed, security/EHS.
- Minute-by-minute response timelines. For late pickup: T+0 detection, T+5 driver contact attempts, T+10 backup dispatch, T+15 mandatory escalation, T+20 alternative arrangement rule.
- Communication scripts. Short, pre-approved SMS/IVR/app message templates for employees, team managers, and security for each state change.
- Decision trees and fallbacks. For example, when GPS fails, the runbook must define how to switch to phone-based location checks, how often to call, and when to downgrade to manual trip sheets.
- Escalation matrix linkage. Clear thresholds for when to push from desk-level to duty manager, vendor owner, or security, aligned to the documented escalation mechanism and MSP governance structure.
- Safety overlays. Different paths for women night-shift routing, missed check-ins, or lone-traveller incidents, aligned with women-centric safety protocols, chauffeur controls, and SOS processes.
- Data capture and closure. Mandatory fields for incident logs, including timestamps, root cause tags, and closure notes, feeding into management reports and data-driven insights.
Typical runbook sections for the three common scenarios:
- Late pickups and delays. OTP thresholds, backup vehicle pools or standby cars, dynamic re-routing rules, and coordination with HR or team managers when shift start is at risk. This aligns with “Management of on Time Service Delivery” practices and the ETS operation cycle.
- No-shows (driver or employee). Rules for wait time, verification steps, photographic or IVR evidence, re-routing of the remaining roster, and billing/penalty logic mapped back to centralized billing SOPs.
- GPS / app outages. Switchover SOP to manual mode, use of call-center scripts, SMS-based OTP and trip confirmation, and later reconciliation with telematics data once systems recover.
A good runbook also ties into the business continuity plan and contingency slides so that during larger disruptions (strikes, heavy rain, partial tech failure), the same night team can follow pre-agreed playbooks instead of escalating everything to leadership. When runbooks are explicit, tested in drills, and wired into dashboards and alert systems, the “2 a.m. shift” depends on predictable systems and buffers, not on one exhausted coordinator’s memory.
Beyond OTP, what SLOs should we track—like response time or time-to-restore—and how do we pick measures that people can’t game?
B1457 Selecting meaningful commute SLOs — In India corporate employee transport (EMS), which service-level objectives (SLOs) are most meaningful for live commute reliability beyond on-time pickup/drop—like incident response time, escalation latency, or "time to restore" after breakdowns—and how do you choose ones that won't be gamed?
In Indian corporate employee transport, the most meaningful SLOs for live commute reliability measure how fast operations detect, respond to, and close disruptions, not just how often cabs are on time. Strong SLOs focus on detection time, escalation latency, incident response and “time to restore” normal service, with definitions that are tightly scoped, auditable, and hard to game.
The core live-reliability SLOs usually build around a few operational moments. Detection SLOs measure the maximum allowed delay from a real-world issue occurring to the command center flagging it, using GPS, missed-OTP, geo-fence or no-movement alerts. Escalation SLOs measure how long the command center can take to escalate an exception from first detection to the responsible role on the vendor, transport desk, or security side. Response SLOs track how quickly a human takes control after escalation, such as calling the driver, rider, or dispatching a backup. “Time to restore” SLOs measure how long it takes to get every impacted employee either en route or safely rescheduled after a breakdown, accident, or extreme delay.
These SLOs become credible when they are defined on top of immutable trip logs, standard incident codes, and independent command-center dashboards. A common failure mode is defining SLOs only on self-reported vendor data, which encourages under-reporting or late tagging of incidents. Another is tracking only averages, which allows chronic outliers that ruin night shifts but do not breach the mean.
To make SLOs hard to game, organizations should anchor them to data that is generated automatically from telematics and apps, not only from manual status changes. They should define clear inclusion criteria such as “all trips that cross X minutes delay from ETD or lose GPS for Y minutes are auto-classified as exceptions.” They should measure both median and tail performance, for example “95% of safety incidents acknowledged within 2 minutes” and “99.5% of trips have no unacknowledged SOS beyond 60 seconds.” They should combine live SLOs with audit mechanisms such as random route adherence checks, command-center quality sampling, and cross-checks against HRMS attendance or no-show patterns.
Over time, organizations select the most useful SLOs by linking them directly to shift adherence, safety incidents, and escalation noise reaching HR and senior leadership. The SLOs that matter are the ones that reduce 2 a.m. firefighting and still stand up under audit.
How do we set an error budget for late or missed trips across shifts, without it turning into a blame tool for coordinators or vendors?
B1458 Error budgets without blame — In India corporate EMS commute operations, how should an Operations/NOC lead set an error budget for late pickups or missed drops across shifts, and how do you prevent the error budget from becoming a tool for blaming individual coordinators or vendors?
In Indian corporate EMS operations, an Operations or NOC lead should set an explicit, shift-wise error budget for late pickups and missed drops that is tied to overall OTP targets, route risk, and demand variability, not to individual coordinators or single vendors. The error budget should be treated as a shared system capacity for failure that drives process improvement and routing changes, rather than as a quota for punishing people.
A practical pattern is to start from a top-line OTP target that leadership accepts as “good enough” for reliability and shift adherence. Many mature EMS programs target 98% on-time arrivals across routes and timebands. The residual 2% can be treated as the total error budget for late pickups and missed drops combined. The Operations or NOC lead can then slice this 2% by shift window, criticality level, and root-cause category. Night shifts, women-first routes, and critical production shifts should be given stricter sub-budgets, because safety and business-continuity risk is higher in these windows. Day-shift and low-risk routes can tolerate slightly higher variance. High-disruption periods like monsoon or known city events should have pre-agreed temporary adjustments with explicit mitigation plans, as seen in WTicabs’ monsoon-routing case where dynamic re-routing supported a 98% on-time arrival rate even under adverse conditions.
Error budgets remain healthy when most exceptions map to known, controlled causes such as extreme weather, law-and-order issues, or major infrastructure failures. Error budgets become a red flag when a growing share of exceptions cluster in controllable buckets such as routing quality, driver allocation, vehicle readiness, app failure, or poor command-center response. The NOC should categorize every late pickup and missed drop into operational root causes tied to routing, fleet, driver, technology, or external conditions. This allows the error budget to guide where to act, rather than who to blame.
To prevent the error budget from turning into a personal or vendor-blame instrument, the NOC lead should embed three structural safeguards. First, performance reviews should focus on trend lines and systemic patterns across time, not on isolated incidents. Coordinators and vendors should be assessed on how quickly they detect and recover from exceptions, and how they contribute to route optimization, driver training, and preventive maintenance. Second, accountability should be layered through a clear escalation matrix and a command-center governance model so that no single individual is seen as the “owner” of every failure. Combined central and site command centers, as described in WTi’s MSP governance structure, show how responsibilities can be distributed between central supervision and local on-ground response.
Third, the error budget should be integrated with continuous-improvement loops, not with incident-driven punishment. Real-time dashboards, such as those used for CO₂ tracking and operational visibility in EV fleet programs, can be extended to show OTP% by shift, route, and root cause. Weekly NOC reviews should focus on which process changes, routing rules, or vendor adjustments reduce future consumption of the error budget. This reframes late pickups and missed drops as signals for redesigning routing logic, boosting standby capacity, or tightening driver and vehicle induction protocols, instead of as reasons to penalize individuals. Over time, the error budget becomes a stabilizing tool for the Operations and NOC team, helping them reduce firefighting, manage high-risk shifts more calmly, and demonstrate to HR and leadership that commute reliability is controlled through governed processes rather than reactive blame.
If our data is split across vendors and spreadsheets, what’s a practical way to baseline reliability—OTP, exceptions, incidents, and time-to-resolve—so we know what’s broken?
B1459 Baseline reliability with messy data — In India corporate ground transportation for employee commute (EMS), what is a practical way to baseline reliability today (OTP, exception rate, incident frequency, mean time to resolve) when data is fragmented across vendor apps and manual registers?
A practical way to baseline reliability with fragmented data is to define a single “trip ledger” for the enterprise, then backfill it weekly from all available sources using a light, SOP-driven process, instead of trying to fix every system first. The baseline becomes a governed spreadsheet or database that standardizes trip IDs, timestamps, and exceptions across vendor apps, GPS exports, and manual registers.
The first step is to lock the reliability definitions before touching data. Operations teams need a simple, written one-pager that defines what counts as On-Time Performance, what is tagged as an exception, what constitutes a safety or service incident, and what “resolved” means for Mean Time to Resolve. This reduces arguments later when HR, vendors, or Security look at the same numbers.
The next step is to nominate a weekly “trip ledger owner” within the transport or command-center team. That person should receive exports from vendor apps, GPS tools, and Excel logs from sites, then normalize them into a common schema. The schema should minimally include trip date, site, vendor, vehicle, employee count, planned vs actual pickup time, exception flags, incident flags, and closure timestamps.
Once that schema is stable, organizations can calculate OTP as on-time trips divided by total trips, exception rate as trips with any operational deviation, and incident frequency as safety or service incidents per 1,000 trips. Mean Time to Resolve can be calculated from first logged time of an incident to its documented closure in the ledger, even if initial inputs were emails or phone calls.
A simple control-room style SOP keeps this manageable. Transport heads can fix a weekly cut-off, run spot checks against raw logs, and review outliers with vendor supervisors. Over time, this ledger becomes the single source for SLA discussions, vendor scorecards, and compliance audits, even while integration with HRMS, NOC dashboards, or command centers matures in parallel.
images:
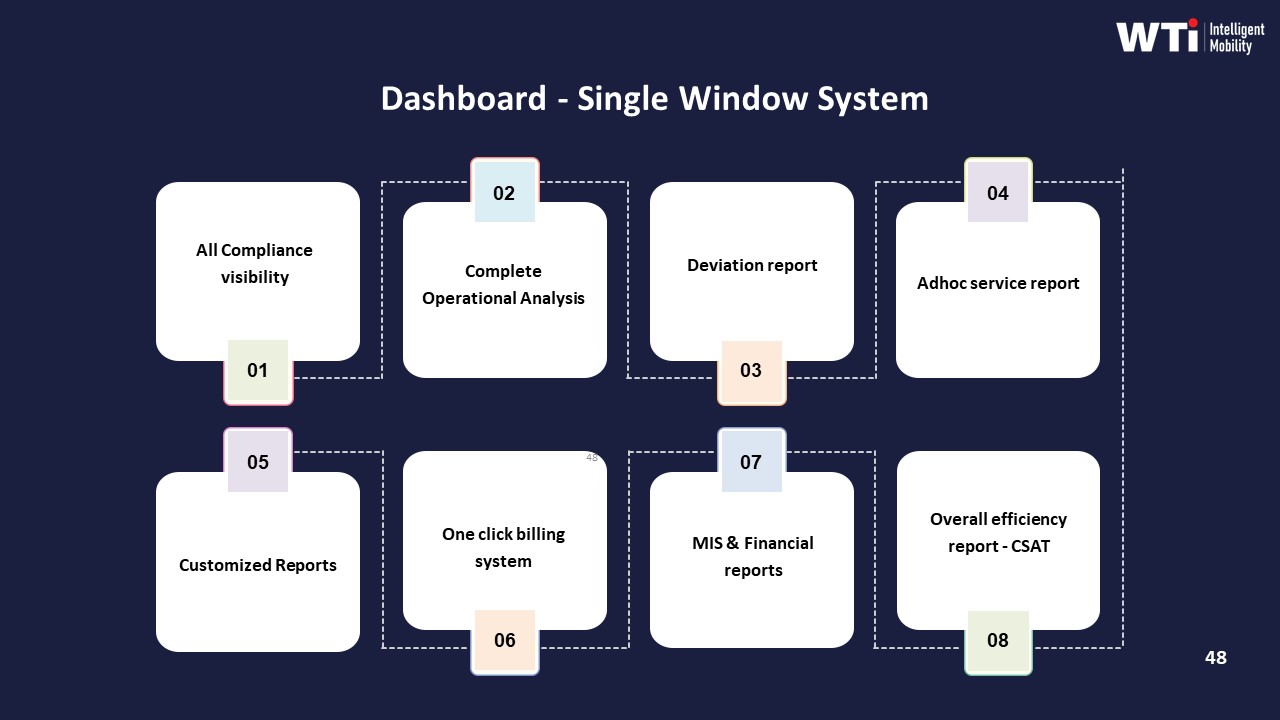
How do we run post-incident reviews without it becoming vendor-bashing or blaming HR, and what data do we need to make it action-oriented?
B1460 Blameless post-incident reviews — In India corporate Employee Mobility Services (EMS), how do post-incident reviews (PIRs) work without turning into a vendor-bashing or HR-blaming session, and what evidence (trip logs, call records, GPS traces) is typically needed to make the PIR action-oriented?
Post-incident reviews in Indian Employee Mobility Services work best when they are run as a governed, evidence-led process owned by a cross-functional group, not by any single vendor or HR. A structured PIR uses verified trip data, GPS traces, and call/chat logs to reconstruct the trip lifecycle and then assigns corrective actions to transport, vendor, security, and HR based on where controls actually failed.
A common failure mode is an unstructured review that starts with blame. That usually happens when the command center does not have a clean trip ledger, when GPS data is fragmented across vendors, or when there is no clear escalation matrix. In those cases, people argue over narratives instead of checking a unified trip record, and PIRs tend to stall on “who is at fault” rather than “which control broke”.
An effective PIR in EMS usually pulls data from the command center tools, alert supervision systems, and mobility apps. Typical evidence includes trip creation and approval records from the EMS platform, GPS traces and route adherence reports from telematics or IVMS, and event timelines from SOS or geofence alerts. Call-center or helpdesk logs, driver app manifests, and employee app check-in or OTP data help validate timestamps, while compliance dashboards confirm whether driver KYC, vehicle fitness, escort rules, and women-safety protocols were in force.
To stay action-oriented, the PIR bench-marks the incident against defined SLA and safety KPIs such as on-time performance, route adherence audit scores, incident response time, and escort compliance. Responsibilities are then tied to specific control gaps, like roster design, routing decisions, driver fatigue management, command-center escalation, or vendor governance, rather than to broad categories like “HR” or “the vendor”. A follow-up cadence, often run through a command-center governance model, tracks whether routing rules, SOPs, and tech configurations were updated so the same pattern of failure does not repeat.
What early signals predict a 2 a.m. escalation, and how do we monitor them without flooding coordinators with alerts?
B1461 Early warnings without alert fatigue — In India corporate EMS commute operations, what are the early warning signals that predict a 2 a.m. escalation (driver no-show, app latency, route deviations), and how should an SRE-style monitoring approach reduce coordinator cognitive load rather than increase alerts?
In Indian corporate employee mobility operations, the most useful early warning signals are those that show a pattern shift before a driver no‑show, app failure, or route deviation reaches employees. An SRE‑style monitoring approach should therefore track a small, opinionated set of “golden signals” tied to OTP, safety, and app reliability, and should auto‑correlate and suppress noise so that coordinators only see 5–10 prioritized incidents per shift, not hundreds of raw alerts.
Early warning signals for a 2 a.m. escalation typically appear 30–90 minutes earlier at the system, fleet, and roster levels. Repeated driver app reconnects on poor networks, rising ETA variance on a specific corridor, or an unusual spike in unassigned or re‑routed trips in the routing engine often precede visible no‑shows and deviations. A sudden increase in manual overrides by coordinators and last‑minute roster edits is also a strong predictor that the system is trending into a reactive mode.
An SRE-inspired monitoring design should treat the transport command center like a production NOC. It should define 4–6 shift‑level SLOs such as OTP%, trip adherence rate, routing engine latency, and driver app uptime, and trigger incidents only when these breach pre‑set thresholds by corridor, vendor, or timeband. The command layer should absorb raw GPS, HRMS, and app telemetry, group related failures into one incident, and attach a playbook step list so coordinators execute a known SOP instead of improvising under stress.
To reduce cognitive load rather than increase alerts, monitoring should focus on a few practical patterns:
- Turn many low‑level metrics into one health score per route cluster or vendor for each shift window.
- Escalate early only when trends persist across multiple trips or drivers, not for single blips.
- Route non‑critical anomalies into summary reports while keeping the live dashboard for only action‑requiring events.
A transport head gains operational calm when the command center surfaces only those incidents that can still be influenced before employees are affected, while the system silently logs everything else for SLA, billing, safety, and ESG reporting.
How can SLOs and runbooks help me defend our transport performance when leadership asks why an incident happened and what we changed?
B1462 Defensible performance for leadership — In India employee transport (EMS), how can a Facilities/Transport Head use SLOs and runbooks to protect job security—i.e., make performance defensible when leadership asks, "Why did this incident happen and what changed so it won't repeat?"
In India employee transport, a Facilities/Transport Head protects job security by converting messy daily operations into explicit Service Level Objectives (SLOs) and pairing them with clear, tested runbooks. This creates a defensible record that incidents were anticipated, monitored, and handled according to agreed standards.
SLOs give leadership a shared definition of “good enough” for EMS. Typical SLOs cover on-time performance, exception detection-to-closure time, route adherence, safety incident rate, and driver or fleet compliance. These SLOs should be aligned to business context such as shift windowing, women’s night-shift policies, and business continuity expectations documented in continuity plans. When an incident occurs, the Transport Head can show whether the relevant SLO was breached, how quickly it was detected through command-center monitoring, and what mitigation was triggered.
Runbooks translate SLO breaches into predictable actions. For example, there can be specific runbooks for GPS failures, cab shortages, political strikes, monsoon disruptions, or app downtime, similar to the documented business continuity and mitigation plans. Each runbook defines triggers, steps, escalation paths, and communication templates, and is wired into command center operations, alert supervision systems, and escalation matrices.
To make performance defensible, the Transport Head needs three practices:
- Anchor SLOs and runbooks in formal governance, escalation, and BCP documents, so they are approved expectations, not ad-hoc reactions.
- Use dashboards, alert systems, and incident logs to prove detection, response times, and closure actions for every material event.
- Continuously update SLOs and runbooks after each root-cause analysis, so leadership sees a closed loop from incident to structural change.
When leadership asks “Why did this incident happen and what changed?”, the Transport Head can walk through the relevant SLO, show the timestamped incident record from the command center or transport control centre, the executed runbook steps, any gaps found, and the updated SOP, routing, or vendor-compliance rule. The narrative becomes “this is how our designed system behaved and here is how we have raised the guardrail,” rather than a personal defence based on memory.
This approach directly supports centralized command-center models, business continuity playbooks, and safety and compliance frameworks already common in Indian EMS, and it shifts accountability from individual heroics to governed, auditable process.
How do we align HR’s safety/experience goals with Finance’s cost pressure when SRE practices look like they add cost?
B1463 HR vs Finance on reliability cost — In India corporate ground transportation (EMS), how do you reconcile HR’s focus on employee experience and safety with Finance’s demand for cost control when SRE practices (extra monitoring, redundancy, on-ground support) appear to increase costs?
In Indian employee mobility (EMS), organizations reconcile HR’s safety and experience priorities with Finance’s cost pressure by treating SRE-style investments (monitoring, redundancy, on‑ground support) as cost re-allocation that improves reliability, reduces leakage, and prevents high‑severity risk rather than as pure cost add-ons. The shift is from “more spend on transport” to “more predictable unit economics and lower incident risk per trip.”
Most enterprises start with fragmented vendors, manual rostering, and reactive firefighting. This creates hidden dead mileage, poor On‑Time Performance, and escalations that hit HR’s safety narrative and Finance’s CET/CPK targets. SRE-like practices in EMS—24×7 command center supervision, alert systems, defined escalation matrices, and business continuity playbooks—directly improve OTP, incident response, and auditability, which are shared KPIs across HR, Finance, and Security. The Industry Insight Summary frames this as moving from manual control to “Centralized NOC & Observability” and “Assurance by design,” where exceptions are surfaced early and closed faster.
From a Finance perspective, these controls are justified when they are tied to measurable outcomes such as reduced SLA breach rate, lower incident rate, and better Vehicle Utilization Index and Trip Fill Ratio. Cost control then focuses on total cost of ownership—cost per employee trip plus the avoided cost of disputes, audits, and serious incidents. Outcome-linked contracts and analytics (for example, dead mileage reduction and vendor rationalization) allow SRE capabilities to pay for themselves over time by cutting waste and improving transparency. HR gains a defensible safety and experience story with audit-ready evidence, while Finance gets predictable, explainable numbers rather than recurring “exception” spend.
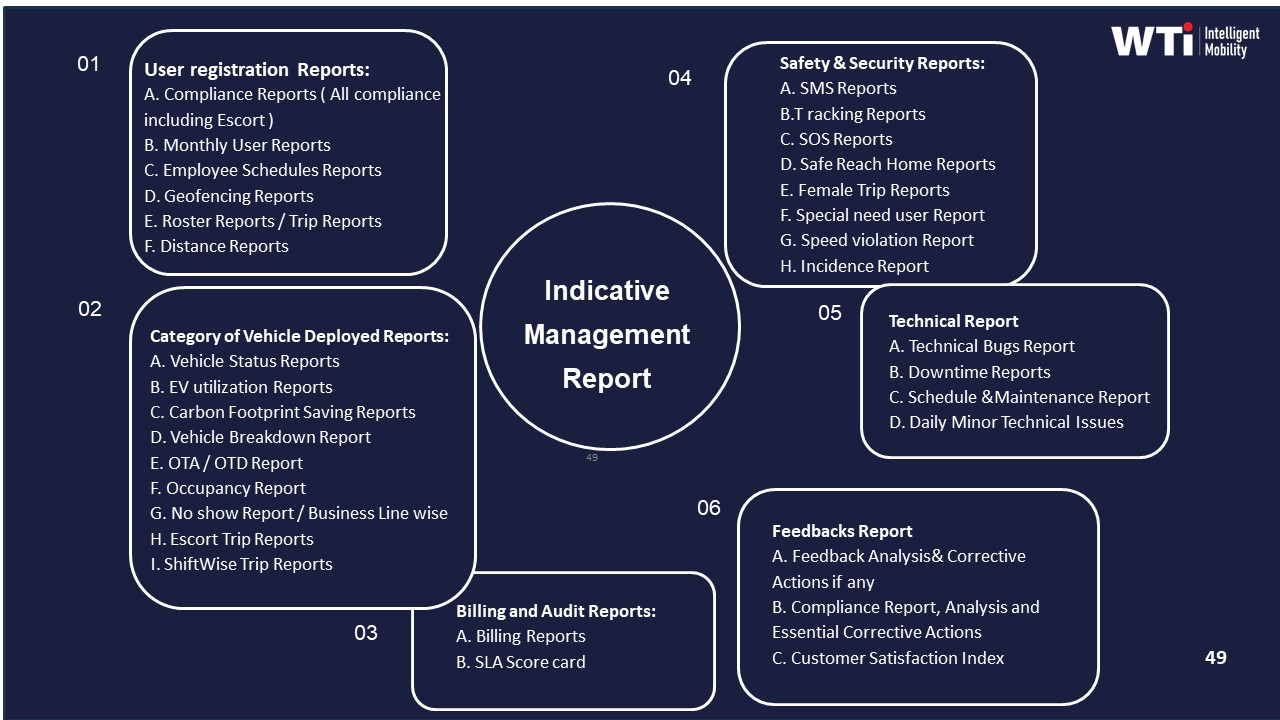
images:

What review cadence actually reduces incidents—daily, weekly, monthly—and how do we avoid adding meetings that don’t improve reliability?
B1464 Cadence for continuous improvement — In India corporate EMS commute operations, what governance cadence actually works for continuous improvement—daily ops review, weekly trend review, monthly SLO/error budget review—and how do you avoid creating a meeting-heavy process that still doesn’t reduce incidents?
In Indian corporate employee mobility operations, a three-layer cadence works best for continuous improvement. Daily operational huddles keep shifts stable, weekly trend reviews catch patterns, and a monthly service-level and error-budget review realigns contracts and routing. Each layer only works when it is tightly scoped to specific data, clear ownership, and decision rights, or the process becomes meeting-heavy without reducing incidents.
Daily reviews are most effective when they behave like a control-room stand-up rather than a long meeting. Operations teams should focus on the last 24 hours of On-Time Performance, exception closure time, and critical safety deviations surfaced by the command center or alert supervision system. A common failure mode is mixing long-term discussions into these daily huddles, which dilutes focus and increases fatigue for the facility or transport head.
Weekly trend reviews work when they stay analytical and cross-functional. Transport, HR, and Security can study route adherence audits, Trip Adherence Rate, driver fatigue signals, no-show clusters, and complaint themes from rider apps. This weekly lens is where continuous improvement sprints, routing tweaks, and driver coaching actions are agreed. A common failure is turning these into status updates instead of decisions tied to measurable changes in OTP or incident rate.
Monthly SLO and error-budget reviews are the right place for Procurement, Finance, and ESG leads. These sessions should reconcile SLA breaches, cost per employee trip, EV utilization ratios, and carbon-abatement metrics with billing, penalties, and incentives. Most organizations overload this meeting with operational detail and vendor storytelling. The meeting works only if it stays contractual and KPI-driven, using standardized dashboards, audit trails, and command-center reports.
To avoid a meeting-heavy culture that still fails to reduce incidents, organizations need three guardrails. Each recurring meeting must have a single owner, a fixed metric set, and predefined decisions that can be taken in that forum. Incident prevention actions must be time-bound and traced back to subsequent KPIs so that repetition is avoided. Finally, command-center tooling and automated alerts should absorb routine variance so that human meetings focus only on exceptions that truly need escalation or design change.
Who should own SLOs, runbooks, and post-incident reviews—transport, HR, vendor NOC, or IT—and what RACI prevents night-time gaps?
B1465 RACI for SRE-style operations — In India corporate Employee Mobility Services (EMS), what roles typically own SLO definitions, runbook upkeep, and post-incident reviews—Facilities/Transport, HR, vendor NOC, or enterprise IT—and what RACI prevents gaps when incidents happen at night?
In Indian corporate Employee Mobility Services, Facilities or Transport teams usually own day-to-day SLO definitions and runbooks, while HR owns safety and experience policies, the vendor’s NOC runs live monitoring and first response, and Security/EHS and sometimes IT provide oversight and evidence for post-incident review. A clear RACI that anchors operational ownership with Transport but formalizes HR, Security/EHS, and vendor roles is what prevents gaps when incidents occur at night.
Facilities or Transport heads act as the internal “operations command center” for EMS. They are responsible for shift-aligned routing, daily reliability, SLA-bound delivery, and command-center operations. They therefore typically lead SLO setting for OTP, route adherence, and exception closure, maintain runbooks for routing, escalation, and vendor coordination, and chair or co-chair operational post-incident reviews.
HR owns the duty-of-care narrative and women-safety policies. HR is accountable for ensuring commute safety, night-shift provisions, and employee experience, and participates in post-incident reviews to address trust, policy gaps, and communication back to employees and leadership.
The vendor’s centralized NOC or command center runs real-time monitoring, alerts, and escalation workflows. The NOC is responsible for following the agreed runbooks, logging incidents and responses, and providing auditable trip and GPS data into post-incident reviews.
Security or EHS leads own safety compliance and incident governance. They are accountable for safety-by-design controls, HSSE compliance, and reconstructing incidents from evidence, so they should co-own SLOs for safety (incidents, escort compliance) and lead safety-focused RCAs.
Enterprise IT guards data, integration, and uptime. IT is usually consulted for SLOs on platform availability, data retention, audit trails, and privacy but is not the operational owner of transport incidents. IT supports post-incident reviews where data, logs, or integrations are implicated.
A practical night-shift RACI that reduces gaps looks like this:
- Responsible (R): Vendor NOC for real-time detection, first-line containment, and notifications; Transport/Facilities for on-ground coordination, rerouting, and immediate continuity actions.
- Accountable (A): Transport/Facilities head for operational SLO adherence and runbook execution; HR for duty-of-care outcomes and employee communication on safety incidents; Security/EHS for safety compliance and final RCA sign-off on safety-related cases.
- Consulted (C): HR, Security/EHS, and IT for SLO design, runbook updates, and complex incident reviews that touch on safety, policy, or data integrity.
- Informed (I): Senior leadership, Procurement, and CFO for major incidents, SLA breaches, or patterns that affect contracts or risk posture.
When this RACI is explicit for EMS, with Transport owning the “2 a.m.” operational response and the vendor NOC bound to clear escalation SLAs, organizations reduce ambiguity, close safety and compliance gaps, and make post-incident reviews evidence-driven rather than blame-driven.
Where can SLOs look green but employees still complain, and how do we design SLOs that match real commute experience?
B1466 Green metrics, bad experience — In India corporate employee commute operations (EMS), what are the common failure modes where SLOs look green but employees still complain (e.g., punctuality met but long ride time, poor escalation handling), and how do you design SLOs to reflect lived experience?
In Indian corporate employee commute operations, SLOs often look “green” when they track only vendor-centric metrics like on-time pickups or trip completion, while employees judge the commute on total journey effort, perceived safety, and how issues are handled in real time. A more accurate design links SLOs to the full trip lifecycle, including routing quality, safety controls, communication, and complaint closure, rather than just punctuality or kilometers.
Common failure modes emerge when routing and operations are optimized for cost or SLA optics instead of lived experience. Route planners can hit high seat-fill and OTP while creating excessively long routes and detours, leading to fatigue and dissatisfaction. Centralized command centers can show good GPS uptime and trip adherence even when escalation handling is slow or fragmented. Safety and compliance dashboards can show “all clear” if they measure document validity but not escort rules, women’s night-shift protocols, or SOS responsiveness.
Better SLOs tie directly to how employees experience each shift. Organizations can define separate targets for door-to-door commute time bands, not just route start OTP. They can measure Trip Adherence Rate for route stability, not only whether a cab eventually arrived. They can track complaint closure SLAs and incident latency from alert to action, alongside safety metrics like incident rates and audit trail integrity. Integrating HRMS and feedback data allows commute SLOs to correlate with attendance, attrition, and Commute Experience Index, making “green” dashboards reflect reality instead of only operational inputs.
images:

How do we use GPS/app/coordinator telemetry for reliability without it feeling like surveillance, while still staying audit-ready for incidents?
B1467 Telemetry without surveillance culture — In India corporate ground transportation (EMS), how do you prevent SRE-style telemetry (GPS traces, app events, coordinator actions) from feeling like "Big Brother" surveillance for coordinators, drivers, and employees while still being audit-ready for incidents?
In Indian employee mobility programs, telemetry works when it is framed as safety-and-reliability tooling with clear limits, not as people-surveillance, and when those limits are documented, communicated, and technically enforced while still preserving incident-ready audit trails.
Most organizations reduce the “Big Brother” perception by explicitly separating what is monitored for safety and SLA assurance from what is not monitored about individual behavior. Telemetry such as GPS traces, app events, and coordinator actions is positioned as evidence for on-time performance, route adherence, SOS readiness, and women’s safety compliance, not as a productivity or disciplinary tool. This orientation is reinforced through written policies, driver and employee induction, and HSSE briefings that explain purpose, scope, and retention in plain language.
Audit readiness is maintained by treating telemetry as a structured “trip ledger” rather than a live feed on people. Organizations retain time-bounded trip data with chain-of-custody for specific use cases such as incident reconstruction, compliance audits, and SLA disputes. Access to raw traces is restricted through role-based controls so that command-center teams see what is needed for live operations, while detailed historical data is exposed only to designated safety, HR, or audit stakeholders under defined SOPs.
Practical guardrails that reduce surveillance anxiety include limiting tracking to rostered duty windows, disabling or obfuscating precise location outside trips, aggregating metrics for dashboards, and using telemetry primarily to power routing, exception alerts, and EV uptime rather than individual scoring. A common failure mode is silent data expansion, where new fields or longer retention are added without updating policies or communication; this quickly erodes trust even if the technical intent is benign.
Early involvement of Transport, HR, and Security in defining “acceptable monitoring” standards typically improves adoption. Driver and coordinator training that links telemetry to concrete benefits like fewer disputes, faster SOS response, and protection against false allegations helps reposition the system as a shield rather than a spotlight. In practice, programs that publish clear escalation matrices, incident SOPs, and data-access rules achieve both operational observability and social acceptability more reliably than those that rely only on technology design.
In an EMS RFP, what should we ask vendors to prove they can support runbooks and post-incident reviews, not just quote high OTP?
B1468 RFP requirements for SRE ops — In India corporate Employee Mobility Services (EMS), what should Procurement ask for in an RFP to ensure vendors can support SRE-style runbooks and post-incident reviews (e.g., evidence retention, escalation participation, change management) rather than just promising high OTP?
In Indian corporate Employee Mobility Services, procurement should explicitly require vendors to submit SRE-style runbooks, incident workflows, and evidence models as evaluated deliverables, not just commit to OTP percentages. RFP questions and scoring should focus on how vendors detect, handle, and learn from failures across command-center operations, data trails, and governance, with OTP treated as an outcome of that system rather than the only KPI.
Procurement teams should ask vendors to attach concrete runbooks for typical EMS failure modes. These runbooks should cover driver no-show, GPS or app downtime, vehicle breakdown, women-safety escalation, and severe-weather disruption. Each runbook should show step-by-step actions, decision thresholds, handoffs between the 24x7 command center and local teams, and targeted recovery times for restoring service and communication.
The RFP should demand a clear post-incident review process. Vendors should describe how they conduct root-cause analyses, which stakeholders are involved, what data is used from trip logs and command-center dashboards, and how corrective actions are tracked to closure. Procurement should ask for sample redacted incident reports to verify depth, not just templates.
To make SRE-style governance auditable, RFPs should require detailed evidence retention and audit-trail descriptions. Vendors should specify how long they store GPS traces, manifests, SOS logs, and escalation timestamps. They should explain how they ensure audit trail integrity and chain-of-custody for safety and compliance reviews. Procurement can link payment or performance evaluation to the completeness and accessibility of this evidence during audits.
The RFP should also cover change management for routes, apps, and policies. Vendors should describe how they roll out routing-engine changes, app updates, and new safety protocols without destabilizing operations. They should present approval workflows, rollback plans, and communication SOPs when shift patterns, fleet mix, or escort rules change. This aligns with centralized command-center practices and hybrid-work elasticity.
To embed vendor participation in governance, procurement can require structured escalation matrices and joint review cadences. The RFP should ask for the vendor’s proposed escalation ladder, participation in monthly SLA reviews and quarterly business reviews, and how incident and SRE learnings will update EMS operating procedures. Evaluation should favor vendors who already run centralized NOCs, use data-driven insights, and treat EMS as a governed service with continuous improvement rather than a dispatch-only operation.
How do we tie contracts to SLOs and error budgets so vendors improve behavior, without triggering constant SLA disputes and billing fights?
B1469 Contracts aligned to SLOs — In India corporate employee transport (EMS), how do you structure outcome-linked contracts so SLOs and error budgets drive behavior (vendor staffing, response times, preventive actions) without creating endless SLA disputes and invoice holds?
In Indian corporate employee transport, outcome-linked contracts work best when a small set of clear SLOs and explicit error budgets govern behavior, and when the contract hardwires how data, reviews, and penalties are applied automatically. Contracts fail when they overload SLAs, use ambiguous data sources, or leave disputes to monthly negotiation instead of pre-defined rules.
The most stable structure starts with a narrow KPI set that reflects real EMS priorities. On-time performance for pick‑up/drop, safety incident rate, and Trip Adherence Rate are usually primary. Vehicle utilization, dead mileage caps, and complaint-closure time can sit as secondary levers. Each KPI needs a precise definition, a single system of record, and a measurement window that both sides accept in advance.
Error budgets should be defined as explicit tolerance bands rather than binary pass/fail triggers. For example, the contract can allow a 3–4% OTP shortfall in a month before any penalty applies. This protects both client and vendor from normal volatility in traffic, weather, or one-off events. The error budget also acts as a trigger for preventive actions, such as joint route recalibration, driver retraining, or adding standby capacity during certain shifts.
Dispute volume drops when the contract codifies a hierarchy of causes and exclusions. Most organizations map “vendor‑controllable” breaches separately from external or client‑driven causes and agree a standardized exception list. This separation is essential for tying penalties only to controllable failure modes, such as driver shortages, roster errors, or missed dispatch, and not to last‑minute roster changes or security holds.
Contracts are easier to administer when SLAs are linked to an agreed command-center view. Centralized dashboards, trip logs, and alert histories become the authoritative data. This is strongly supported by industry practice around 24x7 NOCs, geo-fencing, SOS events, and real-time route monitoring described in the context. The same dashboards can also surface CO₂ metrics and EV utilization where sustainability outcomes are part of the scope.
To keep behavior positive, many enterprises pair monetary penalties with structured performance tiers. Higher tiers can unlock eligibility for more lanes, renewal weightage, or gain-share on demonstrated cost or emission reduction. Lower tiers can trigger corrective action plans rather than immediate commercial punishment. This tiering makes vendors invest in preventive measures such as better driver training, fatigue management, or buffer vehicles.
A predictable governance rhythm is critical. Quarterly business reviews aligned to a fixed template can review SLO performance, error-budget consumption, incident RCA packs, and planned improvements. Between reviews, a short weekly or fortnightly operational huddle can focus on early warning signals such as rising exception rates, specific night-shift clusters, or recurring complaint themes.
The contract also needs clear playbooks for “what happens when we miss.” That usually includes root‑cause analysis timelines, agreed corrective steps, and how quickly metrics must return within the error budget. When these steps are defined upfront, both sides can avoid ad‑hoc argument and focus on repairs rather than blame.
Finally, data ownership, API access, and auditability clauses should be explicit. Continuous assurance depends on preserved GPS logs, incident records, and compliance dashboards that can be revisited during audits. This supports HR, Security, and ESG leads in defending numbers and safety narratives, and it reduces Finance’s reliance on manual reconciliations that often drive invoice holds.
images:
Should we pilot SLOs and runbooks on one site/shift first or roll out everywhere, and what early proof would Finance accept before scaling?
B1470 Pilot vs scale SRE practices — In India corporate EMS commute operations, what implementation approach reduces risk: piloting SLOs/runbooks on one site or shift band first versus rolling out enterprise-wide, and what early results should a CFO accept as proof before scaling?
For Indian corporate EMS commute operations, piloting SLOs and runbooks on one site or a narrow shift band is the lower‑risk path, and CFOs should treat that pilot as a controlled “proof of unit economics and reliability” before any enterprise‑wide rollout. A focused pilot limits exposure if routing, vendor behavior, or tech integration underperform, and it creates clean before/after baselines that can be defended in Finance and Audit reviews.
A limited-scope pilot also fits how EMS actually operates. Most issues concentrate in specific high‑risk zones such as night shifts, monsoon-heavy locations, or high-volume tech parks. Running new SLOs and SOPs there lets teams validate real on-time performance, driver behavior, and safety compliance under stress conditions. Centralized command center practices, alert supervision, and business continuity playbooks are easier to tune with one control room plus a small number of routes before extending them to other regions.
For a CFO, pilot “success” should be defined by a small, auditable set of metrics that link directly to cost, risk, and reliability rather than anecdotal satisfaction. These early proof points should include a stable or improving cost per km and cost per employee trip, a clear uptick in fleet uptime and trip adherence, and visibly lower escalation volume from that site or shift band. Reduction in dead mileage and idle time, fewer billing disputes due to cleaner trip data, and evidence that business continuity plans work during disruptions are additional signals that the SLOs and runbooks are mature enough to justify scaling.
SRE-minded reliability metrics, SLOs, and runbooks
Translates reliability concepts into practical targets and repeatable procedures; specifies runbooks, non-gameable SLOs, and how to avoid gaming or misreporting.
After a post-incident review, how do we make sure action items actually get closed with owners, deadlines, and verification instead of becoming a forgotten report?
B1471 Closing actions after incidents — In India corporate employee transport (EMS), how do you operationalize "continuous improvement" after post-incident reviews so action items actually close (owner, due date, verification) rather than becoming a report nobody revisits?
Continuous improvement after transport incidents only works when post-incident actions are treated as operational work with owners, SLAs, and verification, not as recommendations in a PDF. Effective EMS teams in India convert every significant incident into a tracked “mini-project” with a defined owner, due date, and closure proof, and they review these items in the same forum that reviews OTP and safety KPIs.
A common failure mode is treating incident reviews as one-off meetings. Transport heads often circulate a report by email without linking actions to the existing command center, escalation matrix, or compliance dashboards. This causes the same GPS gaps, driver issues, or routing errors to reappear in later incidents because no one is accountable for finishing the fixes. Continuous improvement fails when action items are not logged into a system that operations already use daily, such as the command center ticketing tool, alert supervision system, or transport MIS.
Strong operators use a simple but strict loop. They register each incident in a central log, identify root causes that tie back to controllable levers such as routing, driver behavior, fleet compliance, or app reliability, and then create specific actions with named owners and realistic deadlines. They align these actions with existing governance mechanisms like HSSE audits, business continuity plans, or centralized compliance checks so that follow-up happens during routine reviews, not as extra work that gets dropped.
To keep control-room life manageable, most teams limit “improvement projects” to a small set of high-impact themes. They pick recurring issues such as late pickups in specific timebands, driver fatigue, or monsoon routing failures and define a short list of measures, for example route rule changes, driver retraining, or buffer vehicles. They then track success using existing KPIs such as OTP, incident rate, or audit scores, rather than creating new parallel metrics.
In practice, the operational guardrail is to insist that no incident is considered closed until three elements exist. There must be a recorded action plan with owners and dates, an implemented change such as a modified SOP or system rule, and a verification step, such as a random route audit or command center check, that is visible in regular dashboards or management reports.
When the app or GPS fails, what should our fallback look like, and how do runbooks keep service running without chaos?
B1472 Graceful degradation in commute ops — In India corporate EMS commute operations, what does "graceful degradation" look like during app downtime or GPS failure—manual fallback, phone tree, paper manifest—and how do runbooks ensure service continuity without chaos?
Graceful degradation in Indian corporate EMS commute operations means that when apps or GPS fail, core shift movements continue through predefined manual fallbacks, and every action still leaves an auditable trail. It replaces “smart automation” with simple, rehearsed SOPs so drivers, coordinators, and command centers can run the operation on phones, paper, and spreadsheets without collapsing OTP or safety controls.
In practice, most mature EMS operators already design for failure alongside automation. Command centers use alert supervision systems and transport command center dashboards to monitor trips, but they also maintain manual tools like duty slips, phone-based confirmations, and SMS/IVR updates. Centralized compliance and safety frameworks remain in force, because driver vetting, fleet compliance, and women-centric safety protocols do not depend on an app being live at that moment.
Runbooks define very specific fallbacks for app downtime and GPS loss. Typical steps include switching from app manifests to pre-generated route sheets, using operator phone trees and WhatsApp broadcast lists for last-mile coordination, and updating shift and no-show reports manually for later reconciliation in billing systems. Business continuity plans and contingency slides in the collateral show that operators map these failure modes in advance alongside other disruptions such as strikes, disasters, or cab shortages.
Well-written runbooks also hard-code who does what in the first 5–15 minutes of a failure. They assign responsibility to command center staff, routers, supervisors, and vendor partners for actions such as confirming critical pickups by call, enforcing escort and women’s safety rules manually, and logging exceptions for later audits. This preserves SLA governance, safety and compliance even when technology partially fails, and it keeps the Facility/Transport Head out of emergency firefighting on every minor outage.
As HR, how do we tell if reliability work is actually improving employee trust—what signals matter beyond dashboard numbers?
B1473 Measuring trust beyond dashboards — In India corporate Employee Mobility Services (EMS), how should a CHRO judge whether SRE-style reliability work is improving employee trust—what signals matter (complaint recurrence, escalation sentiment, perceived safety) beyond a dashboard score?
In corporate Employee Mobility Services in India, a CHRO should judge whether reliability work is improving employee trust by tracking whether safety incidents, commute disruptions, and escalation noise actually reduce and stay down over time. Dashboard scores are useful, but trust becomes visible when complaints stop recurring, sentiment in escalations softens, and night-shift and women employees report that “commute is a non-issue” in HR and EX forums.
A first signal is recurrence. A serious complaint or incident should never look identical twice. If SRE-style reliability is working, similar issues cluster early, are fixed with clear SOP or system changes, and then disappear from logs. If the same failure modes keep reappearing by route, time-band, or vendor, then reliability work is not translating into trust, regardless of OTP%.
A second signal is escalation sentiment and channel. When trust improves, fewer commute issues jump directly to CHRO, senior leaders, or social media–like forums. Employees use normal transport helpdesks or in-app feedback instead of bypassing them. Language inside tickets shifts from fear and anger (“unsafe,” “ignored,” “no one responded”) to inconvenience (“late,” “confusing”) and then to low-volume, neutral feedback.
A third signal is perceived safety, especially for women and night shifts. Night-shift and women-centric routing, escort compliance, SOS responsiveness, and audit-ready evidence are central in EMS. If women employees and ERG groups report feeling safer, if night-transport is not discussed as a risk topic in townhalls, and if Security/EHS can reconstruct and close incidents with clean trip logs, then reliability work is supporting trust, not only SLA charts.
Additional practical signals a CHRO can use include: - Attendance and attrition deltas for heavy-commute teams, particularly in late shifts. - The ratio of raw incidents to “near-miss” or early alerts detected by the command center before employees escalate. - Closure SLAs for safety-linked complaints and the quality of communication back to employees. - Whether HR can answer leadership questions like “How often does this happen, and what changed after last time?” with precise, consistent data rather than anecdote.
When SRE-style reliability is aligned with EMS operations, centralized command-center practices, and safety-by-design controls, the commute moves out of HR’s crisis agenda. The strongest indicator of improved trust is that employees no longer talk about transport as a daily risk, and the CHRO is no longer on the defensive after every incident review.
How do we train coordinators and vendors on runbooks and post-incident reviews without creating fear that mistakes will be punished?
B1474 Training without fear culture — In India corporate employee commute operations (EMS), how do you coach coordinators and vendor teams to use runbooks and post-incident reviews without creating fear that mistakes will be used for punishment or performance downgrades?
In Indian EMS operations, coordinators and vendor teams use runbooks and post‑incident reviews constructively when leaders explicitly separate “learning events” from “disciplinary events,” and back this separation with clear SOPs, metrics, and behavior from the command center and management. Fear reduces incident reporting and hides weak signals, while a learning-focused review culture improves OTP, safety, and ESG compliance over time.
A common failure mode is using post‑incident reviews mainly to find a person to blame. This discourages coordinators from escalating early when GPS fails, a driver is fatigued, or a vehicle is non‑compliant. In contrast, mature EMS operations treat runbooks like cockpit checklists. The runbook defines what a 2 a.m. coordinator does during cab shortages, app downtime, or monsoon disruption, and the review asks, “Was the playbook clear and realistic?” before asking, “Did the person follow it?”
To make this work in daily EMS reality, supervisors should coach teams that:
- Runbooks are protection tools, not surveillance tools. If coordinators follow them and document exceptions in the command center or ETS/Commutr systems, that becomes evidence they acted responsibly under pressure.
- Post‑incident reviews are about strengthening the playbook and infrastructure. For example, adding backup routing when the mobility app or GPS fails, tightening BCP triggers for political strikes, or adjusting vendor buffers when driver attrition spikes.
- Only willful negligence or repeated ignoring of critical safety steps (like escort rules for women at night, or skipping SOS escalation) triggers a different, HR/EHS‑led disciplinary track. This boundary must be written, socialized, and repeated in daily shift briefings.
Linking reviews to system fixes also reduces fear. When teams see outcomes like extra standby vehicles added via the Business Continuity Plan, adjusted routing in heavy rain based on the Mumbai monsoon case study, or new alerts via the Alert Supervision System, they experience incident reviews as a path to operational calm, not as a threat. This is reinforced when command centers share aggregate indicators (OTP%, incident closure times, audit scores) rather than naming and shaming individuals.
Over time, coordinators trust the process when three things are consistent. First, leaders use data from dashboards and NOC tools to fix processes and infrastructure gaps before questioning individual capability. Second, reviews focus on “What made it hard to follow the runbook at that hour?” instead of “Who dropped the ball?” Third, vendors see that honest self‑reporting of near‑misses feeds into structured improvements in compliance, BCP, and driver training, rather than automatic commercial penalties.
If reliability doesn’t improve even after runbooks and PIRs, how do we figure out if it’s the vendor, our internal policies, or lack of visibility—without triggering a blame war?
B1475 Diagnosing root causes politically — In India corporate EMS commute operations, when reliability stays poor despite runbooks and PIRs, how do you tell whether the root cause is vendor behavior, internal policy constraints (shift changes, approvals), or lack of observability, without starting a political blame war?
In Indian corporate EMS commute operations, the fastest way to separate vendor failure from internal policy constraints and observability gaps is to move the discussion from opinions to trip-level evidence and KPI timelines. A transport team can do this by reconstructing the full trip lifecycle against agreed SOPs and SLAs and asking, at each step, “Who had control here, and what data proves it?”
A practical pattern is to start from symptoms that matter to operations, such as repeated OTP misses on specific shifts, frequent last‑minute roster edits, or unexplained no‑shows. Each symptom is then traced along the ETS / EMS operation cycle, from booking request to routing, vendor allocation, dispatch, trip execution, and closure, using logs from the EMS platform, NOC, and HRMS integration. Where the evidence trail breaks, the likely root domain is lack of observability. Where the trail is clear but shows conflicting instructions or late approvals, the root domain is internal policy and process. Where the trail is clear, policies were respected, and allocations were stable, yet OTP or safety still fails, the root domain is vendor behavior.
To avoid a “blame war,” most organizations define a neutral, shared KPI set for EMS covering OTP%, Trip Adherence Rate, exception detection‑to‑closure time, and Vehicle Utilization Index. These KPIs are sliced by control dimension, such as “cases with last‑minute roster change,” “cases with on‑time roster but late vehicle arrival,” or “cases with app or GPS downtime flagged by command center.” A pattern where OTP collapses only when rosters move after cutoff indicates policy constraints. A pattern where OTP is poor even on stable rosters across multiple vendors indicates observability or routing issues. A pattern where OTP is poor only for a specific vendor, timeband, or cluster—despite on‑time rosters and clean telemetry—points to vendor discipline, driver fatigue, or fleet adequacy.
Command centers are critical for this separation because they create tamper‑evident trip ledgers and alert histories that everyone can see. Centralized NOC or Transport Command Centre tooling allows neutral classification of every exception as routing/technology, policy/roster, or vendor/driver. This reduces personal blame and shifts the conversation to structural levers such as changing shift‑change cutoffs, tightening vendor SLAs, adjusting fleet mix, or improving HRMS integration.
images:
For our employee transport ops, how do we set SLOs and error budgets that match realities like OTP, missed trips, and response time—without committing to unrealistic “zero issues”?
B1476 SLOs and error budgets mapping — In India corporate Employee Mobility Services (EMS) operations, how do SLOs and error budgets translate into practical service expectations like on-time pickup/drop, missed-trip rates, and incident response—so the Transport Head can defend performance without promising “zero issues”?
In Indian Employee Mobility Services operations, SLOs and error budgets convert abstract “99% reliability” into explicit, defendable thresholds on OTP, missed trips, and incident response times. The SLO defines the target performance level. The error budget defines how many failures are acceptable before the vendor and transport team must slow changes or trigger corrective actions.
In practice, a transport head can use SLOs to set clear expectations on on-time pickup and drop performance. For example, an EMS SLO can specify that a defined percentage of trips must meet shift windowing and Trip Adherence Rate targets. The error budget then allows a small, quantified buffer for delays due to traffic, weather, or roster changes without labeling the operation as a failure. This framing makes “occasional exceptions” acceptable as long as overall OTP and exception-closure metrics stay within the agreed window.
Missed-trip and no-show rates can be similarly governed through SLOs on Trip Adherence Rate and No-Show Rate. The error budget here identifies the allowable percentage of missed or aborted trips in a period. This keeps pressure on vendors to maintain fleet uptime, driver retention, and routing quality, while protecting the transport head from unrealistic zero-failure expectations.
Incident response SLOs focus on exception detection and closure time. Centralized command-center operations, alert supervision systems, and escalation matrices are measured on how quickly they detect a route deviation, SOS trigger, or compliance breach and close the ticket. The error budget defines how many slow or failed responses are tolerated in a cycle before governance actions and root-cause analysis are mandatory.
For a facility or transport head, the key is to tie every SLO and error budget to traceable KPIs such as On-Time Performance percentage, Trip Adherence Rate, exception detection-to-closure time, and incident rate. This linkage allows them to show leadership that most trips run within agreed thresholds, exceptions are within the error budget, and every breach produces an audit-ready root cause and corrective action rather than vague excuses.
images:

When teams try SRE-style ops for mobility but still get late-night escalations, what usually goes wrong—and how do we figure out if it’s process, vendor behavior, or tool gaps?
B1477 Why SRE still causes escalations — In India corporate ground transportation (EMS/CRD), what are the common failure modes when teams adopt an SRE mindset (SLOs, runbooks, post-incident reviews) but still end up with 3 AM escalations—and how can Operations diagnose whether the issue is process, vendor behavior, or tooling gaps?
Most transport teams that adopt an SRE-style model still get 3 a.m. escalations because the SLOs and runbooks are defined on paper but not anchored to real-world mobility constraints, fragmented vendors, and live command-center behavior. Operations can usually diagnose whether the root cause is process, vendor behavior, or tooling by tracing a few concrete signals: where did detection happen, who had authority to act, and what data was actually visible in the command center at the time of the incident.
Process failure is common when ETS/CRD ops cycles remain partially manual. Manual rostering, ad-hoc route overrides, and weak hand-offs between HR, Transport, and vendors undermine even well-written SOPs. A typical symptom is that OTP% and TAR targets exist but shift windowing, dead-mile caps, and business continuity playbooks are not enforced in day-to-day routing and capacity decisions.
Vendor behavior is usually the core issue when a multi-vendor aggregator model exists without firm vendor governance frameworks and periodic capability audits. A high SLA breach rate concentrated in specific timebands, sites, or vendors indicates that driver fatigue management, fleet uptime, and standby buffers are being offloaded to the customer. A pattern of last-minute no-shows, poor escort compliance, or repeated RTO/permit non-compliance despite clear SOPs points to structural vendor gaps rather than process design.
Tooling gaps are evident when the command center lacks real-time observability, automation, and integrated data flows across EMS/CRD, HRMS, and finance. If alerts are reactive rather than predictive, if routing engines are not traffic- or hybrid-work aware, or if the NOC cannot see cross-vendor fleet utilization, then SLOs are not backed by actionable telemetry. Data silos between telematics, employee apps, and billing also block fast root cause analysis, leading to repeated 3 a.m. escalations.
To separate these dimensions, Operations leaders can run three focused diagnostics:
- Process: Map the ETS/CRD operation cycle against actual incident timelines and check where manual workarounds bypassed the defined TOM, escalation matrix, or business continuity plans.
- Vendor: Compare OTP%, incident rate, and compliance audit findings by vendor and timeband to see if failures cluster around specific operators, geographies, or vehicle types.
- Tooling: Review whether the command center’s alerts, routing decisions, and audit trails surfaced the risk before impact, and whether data from driver and rider apps, telematics, and billing could be reconciled quickly post-incident.
When these diagnostics are run consistently, most 3 a.m. escalations resolve to a visible blend of all three: process that tolerates exceptions, vendors without real teeth in their SLAs, and tooling that reports yesterday’s state instead of predicting tonight’s risk.
What early warning signals should we track to prevent missed pickups, without making drivers or employees feel like we’re policing them?
B1478 Leading indicators without surveillance — In India enterprise employee commute operations (EMS), how should a Facility/Transport Head choose a small set of reliability signals (leading indicators) that predict breakdowns before they become missed pickups—without creating a ‘Big Brother’ surveillance culture for drivers and employees?
In Indian enterprise employee commute operations, a Facility or Transport Head should focus on a small set of operational leading indicators that sit close to the trip lifecycle, tie clearly to On-Time Performance (OTP), and can be explained to drivers and employees as safety and reliability tools rather than surveillance. These indicators should be built from existing EMS data such as routing, GPS tracking, driver duty cycles, and exception logs, and should be governed through clear SOPs, communication, and limited access rules to avoid a “Big Brother” perception.
The most predictive reliability signals usually come from the command center view of trip adherence and fleet health. Early signs such as recurring pre-shift routing changes, clusters of last-minute roster edits, or repeated manual overrides of the routing engine often precede missed pickups. Patterns in Vehicle Utilization Index, dead mileage, and shift windowing can expose routes that are too tight to absorb normal Indian traffic or weather disruptions, as shown in case studies where dynamic route optimization maintained a 98% on-time arrival rate even in monsoon conditions. When combined with simple driver-side metrics like duty cycles and repeated late sign-ins, these signals give early warning of potential OTP drops without monitoring personal behavior beyond what is operationally necessary.
To avoid a surveillance culture, each chosen indicator must be purpose-limited, transparent, and aggregated where possible. Trip-level GPS and route adherence data should be used to monitor fleet performance and safety KPIs like Trip Adherence Rate, not to micro-manage individual drivers outside duty hours. Driver fatigue or overwork risks can be inferred from shift patterns and duty slips rather than invasive tracking. Command-center teams can use structured escalation matrices and exception workflows that focus on resolving operational risks early, while compliance and safety dashboards can provide anonymized or role-appropriate views to HR, Security, and ESG stakeholders.
Practical selection criteria for a small reliability signal set include:
- Each signal must have a proven link to missed pickups, late logins, or high exception latency.
- Each signal should be calculable from data already captured for routing, billing, or safety compliance.
- Each signal should be explainable to drivers and employees as a safety, compliance, or reliability control.
- Access to raw trip-level data should be restricted, with aggregated views used for leadership reporting.
images:
images:
images: 
For night-shift safety cases like SOS or driver no-show, what should the runbook include—and how do HR and Security split ownership so reviews don’t become blame games?
B1479 Night-shift safety runbook design — In India corporate EMS night-shift transportation, what does a good runbook look like for women-safety escalations (SOS, geo-fence breach, driver no-show), and how do EHS/Security and HR align on escalation ownership so post-incident reviews don’t turn into blame?
A good women-safety escalation runbook in India EMS night-shift transport is explicit, time-bound, and evidence-backed. It defines what is “critical,” who owns each minute of response, and how EHS/Security and HR split roles between incident control and employee care. It also bakes in audit-ready data from SOS, geo-fence, and no-show events so post-incident reviews stay factual instead of becoming blame discussions.
A strong runbook starts with clear trigger definitions. An SOS press by a woman employee, a geo-fence breach into a disallowed zone, a route deviation beyond a defined buffer, driver/app device tampering, or a night-shift driver no-show past a set threshold must all be classified and tiered. The Alert Supervision System, SOS control panel, and transport command centre tooling should map each trigger to an automated alert, with escalation paths and time-stamped logs for when the command centre, vendor, EHS/Security, and HR were notified.
EHS/Security should own the live incident response. EHS/Security leads immediate controls such as contacting the vehicle/driver, activating SOS workflows, coordinating with local security or police if needed, and ensuring safe rerouting or evacuation. HR owns parallel employee support. HR ensures that the affected employee is contacted by a designated, trained responder, that safe accommodation or alternate commute is arranged, and that managers are informed in a way that protects confidentiality and avoids victim-blaming.
Post-incident, the runbook should mandate a joint EHS–HR review structured around data, not opinion. Command centre trip logs, GPS traces, geo-fence alerts, driver compliance records, and SOS timelines feed into a standard RCA template. EHS documents control failures and process gaps. HR captures employee impact and communication gaps. Both sign off on a corrective-action plan that may include driver retraining or de-induction, routing rule changes, or app-level improvements, and this is then fed into safety and compliance dashboards for continuous assurance.
To keep reviews from becoming blame cycles, the runbook should codify ownership boundaries and language. EHS/Security is accountable for “safety controls worked or failed.” HR is accountable for “employee was supported and heard.” Transport operations is accountable for “SOPs and routing were feasible and followed.” Vendors are accountable for “driver behavior and fleet compliance.” Joint governance forums, such as command-centre led service reviews, should use predefined KPIs like incident rate, route adherence, and complaint closure SLAs so that leadership looks at patterns and systemic fixes instead of single-person fault.
How do we run post-incident reviews that actually reduce repeat issues and speed up recovery, instead of creating reports that just sit in a folder?
B1480 Post-incident reviews that stick — In India enterprise-managed employee mobility services (EMS), how do mature teams structure post-incident reviews so they drive measurable improvement (fewer repeats, faster recovery) instead of producing reports that nobody trusts or uses?
In India enterprise employee mobility, mature teams treat post-incident reviews as a governed, data-backed operational process owned by Transport, Safety/EHS, HR, and IT together, not as a one-off blame exercise. They anchor every review to auditable trip data from the command center and apps, tie findings to specific SOP changes and KPIs like OTP%, incident-rate, and closure time, and then track whether those metrics improve in the following weeks.
Mature teams start with an immediate, factual reconstruction using GPS logs, app manifests, IVMS and SOS data rather than driver or employee memory. Transport command centers and NOC tools provide route adherence, timestamps, and escalation sequences so EHS and HR can verify what actually happened. This protects credibility with CHRO, CFO, and Security because conclusions rest on telemetry and audit trails, not opinions.
They also separate root-cause analysis from individual blame. Operations look at routing logic, vendor performance, driver fatigue, compliance gaps, and app behaviour as part of a repeatable “trip lifecycle” view. Security and ESG leads examine duty-of-care and regulatory exposure, while IT validates whether any data or system failures contributed. This multidisciplinary pattern reduces defensive behaviour and makes it easier to change rosters, routes, vendor mix, or EV/ICE allocation where needed.
To ensure reviews drive change, teams define a small set of corrective actions with explicit owners, deadlines, and KPIs. Examples include tightening escort or women-first rules on certain timebands, changing shift windowing on congested corridors, updating driver coaching based on behaviour analytics, or revising vendor SLAs and penalties. Subsequent QBRs and mobility governance forums then check if incident rates, response times, or Trip Adherence Rates have actually improved, and they keep telemetry as evidence.
A common failure mode is treating post-incident work as PDF reports that sit outside daily operations. Mature EMS operators instead wire review outputs back into routing engines, command center alert rules, driver training calendars, vendor scorecards, and business continuity playbooks. This turns each serious incident into an input for routing optimisation, compliance automation, and resilience design, which is what ultimately reduces repeat events and accelerates recovery.
images:
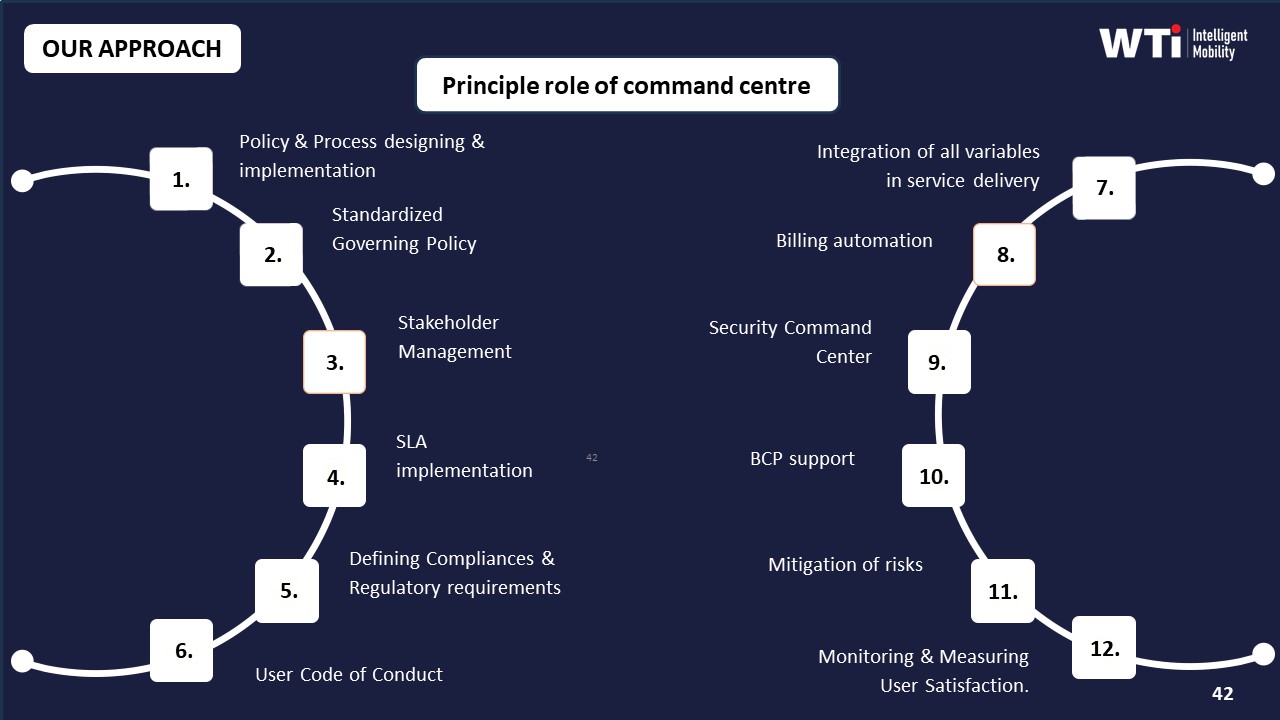
During incidents, what evidence should we capture for audit-ready RCA—without burying the ops team in paperwork?
B1481 Audit-ready incident evidence — In India corporate ground transportation (EMS/CRD), what evidence should be captured during commute incidents (timestamps, GPS/trip logs, call recordings, ticket notes) to support audit-ready RCA without overwhelming the ops team with documentation overhead?
In corporate ground transportation in India, audit-ready incident evidence focuses on a small, consistent data spine per trip rather than exhaustive paperwork for every ride. The core principle is to standardize a minimum evidence set that systems capture automatically and operations enrich only when an exception occurs.
A practical incident record usually links to a single trip ID and includes time-sequenced telemetry, human decisions, and communication traces. Most organizations rely on GPS/trip logs, app events, and ticket data as the backbone. Call recordings, chat logs, and manual notes are attached only when escalation or safety risk crosses a defined threshold.
To stay audit-ready without overwhelming the transport team, the evidence model can be kept to a tight checklist for each incident:
- Trip metadata. Trip ID, employee ID codes (or anonymized reference), vehicle and driver identifiers, route ID, shift window, and scheduled pickup/drop times.
- Time and location trace. GPS track with timestamps, key waypoints, and geofence events to reconstruct where the vehicle was, when.
- Event timeline. System-generated events such as booking time, assignment, driver “en route,” arrival, boarding, trip start/end, cancellations, and SOS presses.
- Exception signals. Alerts from the Alert Supervision System such as geofence violation, device tampering, overspeeding, or missed checkpoints, tied to the same trip ID.
- Communication snapshot. For material incidents only, a short summary plus references to call recordings, app chats, or email tickets stored in the command center or call center system.
- Action and closure log. The incident ticket with classification (safety, delay, behaviour, technical), who responded, actions taken (reroute, vehicle replacement, security notified), and closure time and status.
Most of this information can be captured automatically by the mobility platform, command center, and call center systems. The additional burden on the operations team is limited to entering a concise incident summary and closure notes when they open or update a ticket. This allows facility or transport heads to reconstruct root cause, demonstrate compliance with safety and women-centric protocols, and satisfy EHS, HR, and external auditors, without turning every shift into a paperwork exercise.
If multiple vendors are involved in EMS, how do error budgets work in practice when leadership still wants one owner accountable for reliability?
B1482 Error budgets in multi-vendor EMS — In India corporate EMS operations, how do error budgets work when service delivery depends on multiple vendors (fleet operators, telematics, escort services) and the business still expects a single accountable owner for reliability?
Error budgets in Indian corporate EMS work as a single reliability “allowance” at the program level, while vendor-specific tolerances and penalties are derived beneath it so the enterprise still has one accountable owner for outcomes. The EMS operator or managed mobility integrator owns the top-line reliability target and error budget, and then decomposes it into SLAs, buffers, and governance rules for each contributing vendor or subsystem such as fleet, telematics, and escorts.
In practice, the enterprise usually defines a primary SLO around on-time performance and safety. The SLO might be expressed through KPIs like OTP%, Trip Adherence Rate, incident rate, and SLA breach rate. The corresponding error budget is the permitted deviation window before escalation, penalties, or reconfiguration of the model are triggered. The managed mobility provider then sets stricter internal SLAs for each vendor tier, uses a centralized command center to monitor real-time exceptions, and uses audit-ready logs and telematics data to attribute failures to specific layers without passing fragmentation back to the client.
A common failure mode is when each vendor is contracted in isolation, with no integrated command framework or unified incident management. In that setup, no one party can defend the overall error budget or reconstruct incidents cleanly. More mature EMS setups use a single governed platform, integrated HRMS and telematics feeds, and a vendor governance framework so that multi-vendor variability is absorbed beneath one accountable service, while the enterprise still sees one contract, one set of KPIs, and one escalation path.
How do we put SLOs and runbook compliance into the contract so penalties are fair and billing disputes don’t keep blowing up?
B1483 Contracting SLOs without disputes — In India enterprise Employee Mobility Services (EMS), how can Procurement and Operations write SLOs and runbook compliance into contracts so penalties feel fair and disputes don’t explode every billing cycle?
In India EMS contracts, service level objectives and runbook compliance need to be written as specific, measurable obligations with shared data sources and pre-agreed exception rules. Penalties feel fair and billing disputes reduce when every clause points to the same operational logs, escalation matrix, and SOPs that Transport actually uses on night shifts.
Procurement and Operations should first translate operations reality into 5–7 core SLOs. Each SLO should have a clear definition, metric, data source, and review frequency. Typical SLOs in EMS include On-Time Performance for pickups and drops, Trip Adherence Rate to planned routes, seat-fill or utilization thresholds, exception detection-to-closure time, safety incident rate, and command-center uptime for the NOC tooling. Each SLO should be tied to the same routing engine, GPS system, and centralized command-center dashboards that already govern day-to-day EMS operations, not to ad hoc spreadsheets.
Runbook compliance should then be codified as mandatory “how” clauses rather than vague promises. Contracts should reference concrete SOPs such as roster lock times, driver KYC and PSV verification cadence, incident response steps for SOS events, pre-trip compliance checks, and emergency BCP playbooks for events like political strikes or monsoon disruptions. Each SOP should have a verifiable artifact like a compliance dashboard entry, trip log, or audit report so that reviewers can check if the vendor followed the runbook even when external disruptions hit.
Penalty logic should be laddered, capped, and exception-aware instead of binary. Contracts should distinguish between structural failures such as chronic OTP breaches and unavoidable events such as city-wide floods, using clear criteria and a documented BCP response. A common pattern is to index payouts and penalties to bands of OTP or seat-fill performance and to link a part of the vendor’s monthly fee to outcome-based metrics, while capping total penalties at an agreed percentage of monthly billing to avoid runaway disputes.
To keep penalties and evidence aligned, Procurement and Operations can define a shared “data truth” section in the contract. That section should specify the primary data sources for SLA measurement such as the trip ledger from the EMS platform, GPS logs, command-center alert history, and HRMS-linked shift rosters. It should also define how corrections are requested and approved when data gaps emerge. This avoids arguments later about which numbers are valid.
Finally, governance rituals need to be built into the master agreement so escalations do not pile up until audit time. Quarterly business reviews with cross-functional stakeholders can validate SLO performance, random route-audit findings, safety and compliance logs, and incident RCAs. A tiered escalation matrix with response-time expectations for both client and vendor reduces ambiguity when issues occur, and a documented change-control process keeps SLOs and SOPs aligned with evolving hybrid work patterns and city conditions.
images:
Before we tie payments or renewals to reliability metrics, how can Finance verify the SLO numbers are real and not just dashboard theater?
B1484 Finance validation of SLO claims — In India corporate ground transportation billing and governance (EMS/CRD), how should the CFO validate that reported SLO attainment is real (not ‘dashboard theater’) before tying payouts or renewals to reliability metrics?
In corporate ground transportation for EMS/CRD, a CFO should only trust SLO-linked payouts when reliability metrics are independently reconstructable from raw trip and billing data and are traceable through an auditable chain-of-custody. Reported SLO attainment is credible when OTP, trip adherence, and exception-closure SLAs reconcile cleanly with invoices, command-center logs, and internal HRMS/finance systems without manual patchwork.
A common failure mode is “dashboard theater,” where vendors present attractive OTP or SLA numbers that cannot be reproduced from trip-level logs or billing details. This usually appears when there is fragmented data between the EMS/CRD platform, GPS feeds, and finance, or when the vendor controls the only source of truth. CFOs avoid this by demanding role-based access to operational dashboards, underlying trip ledgers, and indicative management reports that mirror what Transport and HR see, rather than accepting screenshots.
Validation improves when the CFO’s team runs periodic route adherence and OTP spot checks using indicative management reports, exception logs from the command center, and billing summaries side by side. SLO claims become defensible when exceptions like no-shows, detours, or late pickups are visible both in alert supervision systems and in the final invoice or penalty calculations. Reliable partners support this with technology-based measurable and auditable performance flows and transport command center visibility, where outcome measurement, verification through audits, and CSAT are tied together.
Before tying payouts or renewals to reliability metrics, CFOs can insist on three safeguards. They can require contract language that links SLAs to clearly defined KPIs derived from trip-level data. They can perform quarterly reconciliation where finance, transport, and the vendor jointly review OTP%, incident logs, and billing variances. They can ensure that any incentive or penalty computation is reproducible by finance using the same data as the vendor, not a black-box calculation.
images:
How do we set up on-call and escalation so the transport lead isn’t the single point of failure and the team can actually sleep?
B1485 On-call model for EMS ops — In India enterprise commute operations (EMS), what’s a pragmatic way to set an on-call model and escalation matrix so the Facility/Transport Head isn’t the single point of failure—and the team can actually sleep?
In India EMS operations, the only pragmatic way to stop the Facility/Transport Head being the single point of failure is to formalize a 24x7 on-call roster anchored in a command-centre model and a written escalation matrix, with clear thresholds for when each level is woken up. The command centre handles 80–90% of noise, and only SLA, safety, or continuity risks move up the ladder.
A workable pattern is to treat the Transport Command Centre as Level 1 and give it real tools and authority. The Alert Supervision System, Transport Command Centre dashboards, and centralized compliance management already support geofence violations, overspeeding, fixed device tampering, and trip deviations in real time. These alerts should land with L1 controllers, who work off SOP playbooks tied to ETS / EMS operation cycles, business continuity plans, and on-time service delivery rules.
The escalation matrix should then mirror the existing “Escalation mechanism and matrix” and MSP governance structure. Level 1 is command-centre executives with checklists and decision rights for standard incidents. Level 2 is shift leads or site-specific command centres who step in for repeated SLA breaches, high NSR pockets, or vendor non-response. Level 3 is the Key Account Manager or Transport Lead for sustained pattern failures, vendor substitution, or BCP activation. The Facility/Transport Head should only be Level 4, reserved for safety incidents, women-safety escalations, or business continuity threats.
To make this hold at 2 a.m., the on-call model needs three guardrails:
- Published weekly rosters for L1, L2, and vendor duty officers, mapped to the Transport Command Centre and SOS control panel.
- Written SOPs per alert type, linked to Business Continuity Plans and Safety & Security for Employees protocols, so L1 does not improvise.
- Post-incident reporting via Indicative Management Reports and tech-based measurable performance dashboards, so repeat issues trigger structural fixes, not more phone calls.
This structure shifts night firefighting from an individual to an engineered system, using the command centre, alert supervision, and BCP playbooks as the primary safety net, with the Facility/Transport Head as the final fallback rather than the default first call.
After a serious incident, leadership may demand ‘zero issues’—how do HR and EHS use SLOs/error budgets/blameless RCA to set realistic expectations without sounding careless?
B1486 Reframing zero-incident demands — In India corporate EMS, when leadership demands “zero incidents” after a high-profile safety escalation, how can HR and EHS reframe the discussion using SRE concepts (SLOs, error budgets, blameless RCA) without looking like they’re lowering the bar on duty of care?
In corporate employee mobility, HR and EHS protect “zero incidents” as the north star but translate it into SRE-style guardrails such as explicit safety SLOs, error budgets, and blameless RCAs. They position these not as a relaxation of duty of care but as the only practical way to keep risk visible, controllable, and continuously reducing in a volatile, multi-vendor commute environment.
Most organizations treat “zero incidents” as a slogan. HR and EHS gain credibility when they separate the aspirational goal from the operational contract. They can define a small set of safety SLOs across night-shift routing, escort compliance, driver credential currency, and incident response SLAs. They anchor these SLOs in auditable telemetry from EMS apps, command-center logs, GPS traces, and compliance dashboards.
Error budgets help HR and EHS move leadership away from emotional, incident-by-incident reactions. They can frame an error budget as the pre-agreed tolerance on specific safety failure modes before mandatory interventions trigger. They keep “zero serious incidents” as non-negotiable while using budgets on lower-severity deviations such as minor route breaches, delayed check-ins, or documentation lapses to prioritize fixes instead of spreading attention thin.
Blameless RCA allows HR and EHS to show that every breach of the safety SLOs converts into structured learning, not scapegoating. They can insist that each significant deviation produces a time-bound action list for routing rules, vendor SLAs, driver training, or app design. They demonstrate to leadership that psychological safety for reporters and operators actually reduces risk faster and that duty of care is enforced through systematic change rather than punishment alone.
To avoid any perception of lowering the bar, HR and EHS can explicitly lock three principles in writing. They can state that the legal and moral duty of care benchmark remains “zero tolerance” for severe harm. They can commit to transparent reporting of SLO performance and error-budget consumption to leadership at a fixed cadence. They can tie vendor governance, commercial penalties, and process changes directly to SLO breaches, making SRE language an enforcement tool rather than an escape clause.
How do we stop SLO dashboards from turning into a punishment system, so the ops team reports issues early instead of hiding them?
B1487 Avoiding KPI punishment culture — In India enterprise employee transportation (EMS), how do you prevent SLO dashboards from becoming a punishment tool for the ops team—so people report issues early instead of hiding them to protect their ratings?
In Indian enterprise employee transport, SLO dashboards stop being a punishment tool when leadership treats them as an early‑warning system for routes and vendors, not a scorecard on individuals. SLOs must be tied to process improvement and root‑cause patterns, while personal performance is governed through separate, clearly defined SOPs.
A common failure mode is using OTP%, incident counts, and exception tickets directly in individual appraisals. This drives under‑reporting, “manual fixes,” and data tampering. In mature EMS operations, SLO dashboards sit inside the command center and mobility governance framework as a real‑time risk radar. Individual performance is then evaluated on controllable behaviors such as adherence to rostering SOPs, escalation timelines, and documentation quality, not blunt outcome metrics alone.
Most organizations need explicit rules that protect truthful reporting. For example, first‑time flags or repeat structural issues on a route are treated as design or vendor problems. Only ignored alerts or breached escalation SLAs trigger people‑level consequences. This separation allows the Facility / Transport Head to encourage shift leads, vendors, and drivers to log GPS failures, app downtime, or unsafe stops without fear, which is critical for women‑safety protocols and night‑shift compliance.
Practical guardrails that support “report early, fix fast” behavior include:
- A written policy that SLO dashboards are for route, vendor, and system performance, not individual punishment.
- Incentives for early escalation and accurate logging during disruptions, especially in monsoon, strike, or infra‑failure scenarios.
- Quarterly reviews where HR, Security/EHS, and Transport use SLO trends to adjust routing rules, buffers, fleet mix, and vendor tiers, rather than blame night‑shift supervisors.
When SLO data is framed as shared risk intelligence for HR, Security, Finance, and Transport, command centers gain honest signals, driver fatigue can be managed proactively, and Safety/ESG teams get auditable evidence without burning out the ops floor.
images:
Vendor governance and multi-vendor accountability
Clarifies vendor roles, contractual incentives and penalties, and cohesive DR/coordination across a multi-vendor ecosystem; ensures a single accountable owner remains responsible for reliability.
During audits, what’s the minimum set of SLO/runbook artifacts we should have ready—and how do we keep it lightweight so daily dispatch doesn’t slow down?
B1488 Audit expectations for SRE artifacts — In India corporate ground transportation operations (EMS/CRD), what are the minimum runbook and SLO artifacts that Internal Audit typically expects to see during a governance review, and how can teams produce them without slowing day-to-day dispatch?
In Indian corporate ground transportation for EMS and CRD, Internal Audit usually expects a small, repeatable set of runbooks and SLO-linked evidence packs that prove operations are governed, not ad‑hoc. Teams can meet these expectations by codifying what they already do in dispatch, routing, safety, billing, and incident response, and by configuring existing command-center and app tools to auto-generate logs and reports instead of adding manual work.
Internal Audit typically looks for four categories of artifacts. Auditors expect a documented operating model describing Employee Mobility Services and Corporate Car Rental scopes, routing and dispatch flows, vendor governance, and escalation matrices tied to a 24x7 command center or NOC. Auditors also look for runbooks and SOPs that cover rostering and route planning, on-demand booking flow for CRD, driver KYC and fleet compliance checks, women-safety night-shift protocols, and incident response and business continuity steps.
Internal Audit also expects SLO and SLA definitions with mapped KPIs for on-time performance, trip adherence, safety incidents, and complaint closure. Audit teams want to see how OTP, exception closure time, and incident rates link to contract SLAs and vendor scorecards. They also look for evidence trails such as GPS trip logs, SOS and alert histories, billing-to-trip reconciliation reports, and periodic compliance dashboards that can be sampled and traced back to specific trips or duty cycles.
Operations teams can produce these without slowing dispatch by embedding runbook steps into tools already in use. Rostering, routing, and trip lifecycle steps can be defined once and then executed via transport apps, command center dashboards, and alert supervision systems that automatically log actions and exceptions. Driver and fleet compliance processes can be configured as checklists in centralized compliance management modules so every induction or renewal leaves a timestamped record without extra paperwork.
Safety, women-centric protocols, and business continuity procedures can be maintained as simple, version-controlled SOPs that are referenced inside the command-center playbook. When incidents or disruptions occur, command center operators can follow predefined escalation flows so that incident data, root cause, and closure status are captured by the system rather than in ad‑hoc emails. Billing systems that map tariffs to trip IDs and automate reconciliation also generate the audit trails Finance and Procurement need, again without adding work at the transport desk.
To keep day-to-day operations fast, teams can adopt three practical steps. They can standardize a minimal runbook set around four daily workflows: plan routes, run shifts, handle exceptions, and close the day. They can align SLO metrics with what the command center already tracks in real time so audit KPIs are just scheduled exports. They can schedule light, periodic reviews to ensure that runbooks, escalation matrices, and BCP notes match actual practice, so operators are never forced to choose between “doing the right thing now” and “updating the document later.”
When employees see missed pickups, they don’t care if it’s app downtime, GPS, or vendor dispatch—how do IT and Ops agree on who owns what for reliability?
B1489 IT vs Ops reliability ownership — In India enterprise EMS, how do IT and Operations agree on reliability ownership when app downtime, GPS gaps, and vendor dispatch failures all look the same to employees complaining about missed pickups?
In Indian enterprise employee mobility, IT and Operations align on reliability ownership by hard-splitting what each team owns, and then binding them with shared, observable SLAs across the entire trip lifecycle. Employees only see a “missed cab,” so IT and Operations need a joint reliability model that traces every failure back to either platform, integration, network, or on-ground execution with audit-ready evidence.
IT typically owns application uptime, integration stability, data security, and API availability. Operations (transport teams and vendors) own roster quality, driver readiness, routing decisions, and command-center response. A common failure mode is having no shared telemetry, so every missed pickup becomes an argument about “whether the app was down” or “driver didn’t show.”
Most organizations reduce this friction by defining a single reliability stack that spans routing engines, driver and rider apps, telematics, and 24x7 command-center workflows. Command centers and data platforms provide streaming trip logs, GPS trails, and alert histories, which let teams categorize incidents into distinct buckets such as app outage, GPS loss, driver no-show, or vendor dispatch breach.
Clear, outcome-linked KPIs like On-Time Performance, Trip Adherence Rate, exception closure time, and Vehicle Utilization Index then become joint scorecards. IT is measured on SLOs for uptime and latency. Operations is measured on OTP%, dead mileage, and incident response. A centralized NOC and escalation matrix finally ensures that, at 2 a.m., there is no debate about “who owns it.” There is instead a playbook that pinpoints root cause and assigns remediation to the right side of the stack.
For EMS, should SLOs be by city, site, shift, or route cluster—how do we pick a level that gives clarity without creating a metric maintenance nightmare?
B1490 Right granularity for SLOs — In India corporate employee commute operations (EMS), what’s the right level of granularity for SLOs—city-level, site-level, shift timeband, route cluster—so leaders get clarity without the ops team drowning in metric maintenance?
In Indian employee commute operations, most organizations get the best balance by defining SLOs at the city + timeband + service-type level, and then using route or site metrics only as diagnostic drill-downs rather than primary SLOs. City-level SLOs give leadership clarity on reliability and safety, while timeband and service-type filters keep night-shift and women-safety performance visible without creating thousands of tracked objects for the transport team.
At the top layer, leadership usually needs 6–15 SLO views across EMS, not hundreds. A practical pattern is to track OTP%, safety incidents, and complaint closure at the level of “City × Timeband (Day / Night) × Service Category (regular EMS vs special programs)”. This aligns to how hybrid work, shift-windowing, and escort policies actually run, and it matches how a centralized command center or NOC supervises operations across regions.
Route-level, cluster-level, and site-level metrics still matter, but they work best as exception analytics. The command center can run route adherence audits and dead-mile analysis at the route or cluster level, and only surface outliers that breach the city-level SLOs. That approach supports data-driven routing optimization, vendor governance, and EV deployment decisions without forcing the ops team into manual SLO maintenance for every route.
Transport and facility heads can then run a simple SOP in the control-room. They review city-level SLOs for OTP, safety, and seat-fill each shift. When a threshold is missed in a specific timeband or service type, they drill into the affected sites or clusters for root cause and corrective action. This keeps the “command center” view stable and reduces firefighting, while still giving HR, Security, and ESG teams enough granularity to trust the numbers and defend them during audits or board reviews.
How do we use error budgets to decide when to freeze changes versus keep optimizing—especially in peak periods when failures can become a career issue?
B1491 Using error budgets to freeze change — In India corporate ground transportation (EMS), how can a Transport Head use error budgets to decide when to freeze change (new routes, vendor swaps, app updates) versus pushing optimization—especially during peak seasons when failures are career-limiting?
In employee mobility services, a Transport Head can use an “error budget” by converting all reliability targets into a fixed, pre‑agreed allowance of acceptable failures, and then using up/down movement in that allowance to govern when changes are allowed. The error budget shrinks during peak seasons, so once incidents start consuming that allowance faster than planned, the default action is to freeze non‑essential changes until stability is restored.
A practical error budget for EMS should be defined in the same units that already matter to HR and leadership. Typical units include on‑time performance percentage, delay minutes per 100 trips, no‑show rate, safety and compliance incidents, and exception closure time. The Transport Head can set a monthly or weekly error budget, such as a maximum number of delayed trips beyond a defined SLA, and a maximum number of route violations or app failures that force manual interventions.
The Transport Head should link this error budget to the command center dashboards and alert supervision systems. Real‑time monitoring of OTP, geofence violations, and app/GPS downtime should continuously update how much of the error budget is “spent.” When consumption is low, the control room can safely experiment with optimizations such as dynamic routing tweaks, vendor redistribution, new EV routes, or app feature rollouts. When error budget burn accelerates, the team should automatically switch into a “stability-first” mode with strict change controls.
Clear SOP triggers are essential for 2 a.m. decisions. Typical triggers include freezing new route launches once OTP drops below a defined threshold for two consecutive shifts, delaying vendor swaps or vehicle mix changes when exception tickets exceed a set daily cap, and blocking non-critical app updates during monsoon, elections, or known festival peaks. The Transport Head should document these rules in the ETS operation cycle, so NOC staff and vendors know exactly when optimization stops and reliability protection starts.
During peak seasons, the Transport Head should pre‑negotiate a tighter error budget and additional buffers. Extra standby vehicles, stricter driver fatigue rules, conservative routing instead of maximum pooling, and prior testing of any app updates on low‑risk routes reduce the chance that a small error will escalate into a career‑limiting incident. Most organizations see better outcomes when they treat EV rollouts, new vendors, and algorithmic routing changes as off‑peak activities, and reserve peak windows for proven playbooks only.
To keep leadership aligned, the Transport Head should present the error budget as a joint safety and reliability contract with HR, Security, and Finance. A simple weekly review of error budget burn—paired with evidence from dashboards, incident logs, and BCP plans—helps explain why some optimizations are paused. This reduces blame when problems originate from external factors such as weather or city disruptions, because decisions to freeze or proceed with change are clearly rule‑based rather than personal judgment.
- Define error budgets in business terms: OTP, delays, incidents.
- Wire error budget consumption into the command center dashboard.
- Use explicit thresholds to trigger change freezes vs. safe optimization windows.
- Tighten budgets and add buffers during monsoon, festivals, and audit periods.
- Review error budget burn with HR, Security, and Finance to maintain trust and avoid reactive blame.
What should HR ask to make sure vendor post-incident reviews are honest and corrective, not just PR that leaves us holding the reputational risk?
B1492 Detecting PR-style incident reviews — In India enterprise Employee Mobility Services (EMS), what questions should HR ask to verify that the vendor’s post-incident reviews are truly blameless and corrective—rather than PR documents that protect the vendor and leave HR holding reputational risk?
In India EMS programs, HR should test whether post-incident reviews describe system causes, concrete fixes, and shared accountability. Reviews that focus mainly on blaming a driver or “isolated lapses” usually leave HR with reputational risk and no real prevention.
HR leaders get better protection when they probe how the vendor’s command center, safety protocols, and compliance systems are involved in every review. Vendors with real Transport Command Centre capabilities and documented Business Continuity Plans usually connect each incident to routing rules, driver training, fleet compliance, and escalation matrices instead of only narrative explanations. Case studies that show measurable improvements in OTP, safety, or satisfaction after a disruption are strong signals that reviews are corrective, not cosmetic.
Key questions HR should ask in due diligence and QBRs include:
- Scope and ownership of reviews
- “Who owns the post-incident review on your side, and who must sign it off?”
- “Do reviews always involve your centralized command centre and compliance teams, or only local staff?”
- “Can you share redacted examples of past reviews for safety incidents and major service failures?”
- Depth of facts and evidence
- “What standard data elements must every review include? For example: GPS logs, route details, driver duty cycles, SOS alerts, call logs.”
- “How do you prove audit trail integrity for trip and incident data?”
- “How do you reconcile the incident narrative with system data from your dashboards and alert supervision systems?”
- Root-cause analysis quality
- “How do you distinguish between human error, process gaps, and technology or infrastructure failures?”
- “Do you systematically check driver compliance, fleet compliance, routing, and command centre response in every review?”
- “Can you show a case where the root cause was your own process or system design, and what changed afterwards?”
- Corrective and preventive actions
- “What is your standard format for corrective and preventive actions? Who is accountable and by when?”
- “How do you link actions to your training programs, Business Continuity Plan, or safety and compliance framework?”
- “How do you verify that changes, such as routing rules or driver SOPs, are actually implemented on the ground?”
- Women safety and night-shift specifics
- “How are women-centric safety protocols reflected in every relevant incident review?”
- “After a women-safety escalation, what changes do you make to escorts, routing, or SOS handling?”
- “Can you share an example where your women-safety cell or SOS system changed operations after a review?”
- Client involvement and transparency
- “At what severity level are HR, Security, and Transport from our side automatically included in the review process?”
- “Do you share full underlying data (trip logs, GPS, call records) with us, or only summary PDFs?”
- “How quickly after an incident do you provide an interim note and a final RCA to HR?”
- Measurable improvement over time
- “Which KPIs do you track to prove that similar incidents have reduced? For example: incident rate, on-time performance, women-safety alerts, customer satisfaction.”
- “Can you show ‘before and after’ metrics from an account where your reviews led to better OTP or safety scores?”
- “How are learnings from one site rolled out to other locations or services?”
- Protection of HR and shared accountability
- “In client communications, how do you ensure shared accountability so HR is not left solely responsible in front of employees?”
- “What language appears in your standard reports about responsibility, apologies, and next steps?”
- “Are your incident reviews designed to be attached directly to our internal investigations and ESG or safety reporting?”
Post-incident reviews become genuinely blameless when they consistently:
1) Use command-center data and compliance records to reconstruct the event.
2) Name process and system changes, not just “retraining” individuals.
3) Feed into the vendor’s Business Continuity Plan, safety framework, and technology improvements.
If a vendor cannot show this linkage in real examples, HR should assume the documents are more PR than protection.
For a junior coordinator handling live issues, what should the runbook standardize vs what can be judgment calls, so escalations go down not up?
B1493 Runbooks for junior coordinators — In India corporate employee mobility operations (EMS), how should a junior transport coordinator use runbooks in the moment—what decisions should be standardized versus left to judgment—so escalations reduce instead of increasing?
In Indian corporate employee mobility operations, a junior transport coordinator should treat runbooks as the “first line of decision” for all repeatable situations and reserve judgment only for genuinely unusual edge cases. Standardized decisions should cover routing, communication, safety, and vendor handling so that at 2 a.m. the coordinator is executing clear steps, not inventing new responses under pressure.
Runbooks work best when they map directly to real EMS scenarios such as late cabs, no-shows, GPS failures, EV low-battery risks, and weather or political disruptions. The collateral shows that organizations use structured ETS operation cycles, command-center micro-functioning, alert supervision systems, and business continuity plans to drive predictable responses and maintain ≥98% on-time performance. In practice, every alert like geofence violation, overspeeding, or device tampering should trigger a pre-defined action, timeline, and escalation path so coordinators do not improvise.
Standardize decisions where outcomes must be consistent and auditable. Typical examples include when to trigger standby vehicles, when to reroute or merge trips, how to handle women’s safety rules at night, what to do on EV low-battery alerts, when to inform HR or Security, and when to switch to manual operations if apps or GPS go down. Leave judgment for exceptions that fall outside defined thresholds, such as combined impacts of severe weather plus protests, conflicting instructions from multiple stakeholders, or cases where applying the rule would clearly create a safety risk.
A practical way to reduce escalations is to structure runbooks as short decision trees per situation, with three clear elements:
- Trigger: what the coordinator sees (alert, call, app failure, ETA breach).
- Standard action: specific steps to take within defined time limits.
- Escalation: who to call, with what information, if the standard action does not restore control.
Runbooks should align with the ETS operation cycle, command center roles, safety and compliance frameworks, and business continuity plans already defined in the organization. When these documents match what actually happens on the ground, coordinators gain operational calm, escalations become rarer but more meaningful, and leadership sees consistent, evidence-backed decision-making rather than ad-hoc firefighting.
How do we build runbooks for airport delays, driver no-shows, and breakdowns that protect executive trips—without over-staffing and overspending?
B1494 Runbooks for executive trip continuity — In India corporate ground transportation (CRD/EMS), how do you design runbooks for airport delays, no-show drivers, and vehicle breakdowns so executive travel isn’t disrupted—without over-staffing the control desk and blowing the budget?
Runbooks for airport delays, no‑show drivers, and vehicle breakdowns work best when they are trigger‑based, time‑bound, and tiered by traveller criticality, so the control desk only intervenes on real risks instead of micromanaging every trip. The core idea is to codify a small set of “if X by time T, then do Y” actions that tie back to clear SLAs, escalation paths, and standby capacity rules rather than adding more headcount.
For airport trips, most organizations link bookings to flight data and define time‑gated checks. The runbook sets thresholds for ETA variance and flight delays, then auto‑flags only exceptions to the command center. The control team steps in when an SLA is at risk, such as when a flight diverts or the vehicle’s GPS shows route deviation, and they trigger predefined options like reassigning a nearby car, adjusting pickup time, or informing the executive via SMS and app notifications.
For no‑show drivers, the standard approach uses a strict check‑in window, automated driver app alerts, and a short escalation ladder. The runbook defines when a trip is reassigned to a backup vehicle, when a supervisor calls the driver, and when to notify the executive or travel desk. This keeps accountability on the vendor and driver compliance framework instead of on constant manual chasing by the control desk.
For vehicle breakdowns, the runbook relies on basic standby capacity rules and proximity‑based reassignment, rather than large idle fleets. Most operators hold a limited buffer of standby vehicles per city or cluster and use telematics to quickly redirect the nearest available car. The control team follows a breakdown SOP focused on safety, alternative pickup, and documenting the incident for vendor governance and maintenance analysis.
A lean, budget‑controlled setup usually limits human monitoring to genuinely high‑risk segments and high‑priority personas, such as CXO travel or late‑night airport drops. Lower‑risk segments rely more on automated alerts from the platform, such as geofence breaches, over‑speeding, or app‑reported exceptions.
To avoid over‑staffing, organizations often centralize the command center and use a single‑window dashboard for multiple locations. Real‑time visibility, alert supervision systems, and escalation matrices allow a small team to manage large volumes by focusing only on deviations from normal operating patterns.
Clear runbooks also depend on driver and fleet compliance, because robust vetting, training, and preventive maintenance reduce the number of exceptions that ever reach the control room. This includes driver assessment, induction, and recurrent training, as well as detailed vehicle compliance checks before induction into the fleet.
Many teams complement runbooks with business continuity plans that cover wider disruptions such as natural events or strikes. These plans define mitigation options like buffer vehicles, alternate vendors, and adjusted shift times so that even large‑scale disruptions do not overwhelm the control desk.
images:
images:
What are the signs our mobility observability is turning into messy data sprawl, and how can IT enforce consistent definitions without slowing urgent ops work?
B1495 Preventing observability data sprawl — In India enterprise EMS, what are the early warning signs that “observability” is becoming data sprawl (too many dashboards, inconsistent definitions), and how should the CIO enforce a reliable semantic layer without blocking urgent ops needs?
In India enterprise EMS, observability turns into data sprawl when every function runs its own dashboards and reports with conflicting KPI definitions and no single governed schema. Data sprawl is also visible when incident resolution still depends on manual reconciliation across tools despite “real-time visibility” claims.
Early warning signals include multiple parallel views of the same metric. Transport, HR, Finance, and vendors use different OTP%, Trip Adherence Rate, or Cost per Employee Trip numbers for the same period. Another signal is growing meeting time spent arguing about “which data is right” instead of discussing decisions. A third sign is that adding new cities, vendors, or EV fleets requires custom integrations each time, because there is no canonical mobility data model.
CIOs should enforce a semantic layer by standardizing a small, explicit EMS KPI library and data schema. The semantic layer should define canonical entities such as trip, vehicle, employee, vendor, route, and SLA event with clear relationships and ownership. The CIO should mandate that all routing engines, driver apps, HRMS integrations, and NOC tools write to a governed Mobility Data Lake or equivalent store.
To avoid blocking urgent operations, the CIO should separate control from consumption. NOCs and transport teams can keep using their familiar dashboards and tools. However, those tools must map their metrics to the governed semantic layer via APIs and ETL pipelines. This allows fast on-ground decisions while preserving a single source of truth for OTP, Trip Fill Ratio, incident rate, and emission intensity.
Governance should focus on a few strict rules. There should be one authoritative KPI catalog with version control. Any new report or dashboard must reference that catalog. Vendors should be contractually required to expose raw trip and telematics feeds aligned to the semantic model and not only proprietary summaries. Periodic audits should compare system KPIs to invoice lines and SLA reports to detect divergence early.
images:

If we tie renewals to SLOs, how do we prevent vendors from gaming the numbers—like redefining ‘on-time’ or closing tickets without fixing issues?
B1496 Preventing vendor SLO gaming — In India corporate EMS, how can Procurement avoid vendors gaming SLOs (e.g., redefining ‘on-time’, excluding bad routes, closing tickets without resolution) when contracts and renewals are tied to reliability metrics?
In India corporate employee mobility, Procurement can reduce SLO gaming only by hard-coding unambiguous KPI definitions, independent data sources, and audit rights into EMS contracts. Vendor-reported reliability must be continuously cross-verified against HRMS, access-control, and command-center logs, with penalties for data tampering and misclassification, not just for misses.
Procurement teams need to own the KPI dictionary. On-time pickup and drop should have precise, contractually fixed buffers by route type and shift window, with no vendor-side right to reclassify “difficult” routes or exclude trips from the denominator. Seat-fill, no-show, cancelled trips, and re-routed cabs should be defined in writing, with examples of what counts as success or failure.
A common failure mode is letting the vendor be the sole system of record. Independent observability is critical. HRMS attendance, building access times, and command-center GPS logs should be treated as primary evidence for OTP and Trip Adherence Rate. Auditability clauses should allow Procurement, Internal Audit, or Security to run periodic random route audits and compare vendor dashboards with raw trip logs and geo-fencing data.
Contracts should also treat process shortcuts as breaches. Forced ticket closure without employee feedback, unilateral “exception” tagging, and exclusion of problem routes or timebands should be explicitly prohibited and linked to SLA-breach penalties. Outcome-based commercials should use rolling windows and sample-based verification, not single headline OTP%.
To keep renewals honest, Procurement should insist on: a frozen KPI and SLO annexure, transparent exception-taxonomy, API-level access to mobility data, and the right to re-baseline metrics after independent audits. Vendors that resist data-sharing, HRMS integration, or command-center observability are high-risk for metric gaming.
If employees feel tracking and incident logs are invasive, how do we explain the purpose and limits under DPDP while still keeping safety workflows effective?
B1497 DPDP-safe telemetry messaging — In India enterprise employee transport (EMS), when employees complain that tracking and incident logging feels invasive, how should HR and Legal explain the purpose and limits of telemetry under the DPDP Act while still keeping the system effective for safety runbooks?
In enterprise employee transport in India, HR and Legal should explain that telemetry and incident logging exist to meet duty-of-care and compliance obligations, and that under the DPDP Act they must be purpose-limited, proportionate, time-bound, and auditable. They should clarify that data is collected to ensure safe routing, enable rapid response to SOS events, and create defensible evidence for incident investigation and regulatory compliance, not to micro‑monitor personal lives or performance.
HR should position commute telemetry as a specific “safety and compliance” system within Employee Mobility Services, separate from performance management, attendance policing, or general location tracking outside defined shift windows. Legal should explain that the DPDP Act requires a clear lawful basis, explicit notice of what is collected (trip logs, GPS traces during trips, SOS events), why it is collected (safety, audit, investigation), how long it is retained, and who can access it within the command center and governance structure.
To keep systems effective but acceptable, organizations should define and communicate guardrails in plain language, for example:
• Telemetry activates only for rostered trips within defined shift windows.
• GPS and trip logs are used for routing, on-time performance, and safety runbooks, not for continuous off-duty tracking.
• Access to raw telemetry is role-based and logged, with security, transport, and command-center teams operating under documented SOPs and escalation matrices.
• Trip and incident data is retained only for a defined period aligned to safety, audit, and legal needs, then archived or anonymized for analytics.
HR should also emphasize that these controls underpin women-centric safety protocols, night-shift escort rules, geo-fencing, and SOS workflows, and that having a complete, tamper-evident audit trail is what allows the organization to protect employees and defend them in investigations. Legal should reinforce that employees retain rights to information, grievance redressal, and correction where applicable, and that telemetry is governed like any other critical enterprise system, with compliance dashboards, audits, and business continuity playbooks to prevent misuse or unauthorized surveillance.
By consistently separating “safety telemetry during trips” from “general surveillance,” and by showing how telemetry drives reliable OTP, zero-incident goals, and ESG reporting rather than personal profiling, HR and Legal can reduce perceived intrusiveness while preserving the integrity of safety runbooks and command-center operations.
How do we check if runbooks are truly being followed during disruptions, without turning it into a demotivating compliance theater?
B1498 Measuring runbook adherence fairly — In India corporate EMS operations, how do you measure whether runbooks are actually being followed during live commute disruptions, without creating a compliance theater that demoralizes the team?
In Indian corporate EMS operations, organizations measure runbook adherence during live commute disruptions by linking a small set of observable, time-stamped actions to outcomes, and by validating them through command-center tooling and after-action reviews rather than constant manual policing. The focus shifts from “Did you tick every box?” to “Did the right controls fire in the right sequence, and did we recover safely and on time?”
A common pattern is to convert critical runbook steps into concrete signals in the EMS tech stack. Dispatch changes, route overrides, SOS triggers, escort allocation, and vendor escalations can all generate time-stamped events in the command center, driver app, and transport dashboards. These events form an objective trail that shows if the prescribed playbook was used when a GPS failure, cab breakdown, extreme weather, or no-show hit a shift. This aligns with centralized NOC operations, alert supervision systems, and escalation matrices that many Indian EMS programs already use.
A second layer is outcome-based verification. On-time performance, exception detection-to-closure time, incident rate, and user complaints provide evidence of whether runbooks work under pressure. Organizations review a sample of disruptions in weekly or monthly governance forums instead of micro-checking every trip. They check if escalation levels were used correctly, if business continuity steps (standby vehicles, rerouting) were invoked, and whether communication SLAs to employees and HR were met.
To avoid compliance theater and team fatigue, leading EMS operators limit measurement to high-risk and high-impact scenarios and automate evidence capture. They use simple, pre-agreed markers such as “who acknowledged the alert, when was the backup cab dispatched, when was HR/security notified, when did the employee board.” Supervisors are then evaluated on stability and predictability of operations, not on sheer volume of forms submitted. This allows the transport head to run a control room that surfaces early alerts and structured responses, while keeping morale intact in night and peak shifts.
images:
When HR, Finance, and Security all say their issues are ‘critical,’ how should Ops prioritize reliability fixes from post-incident reviews with limited bandwidth?
B1499 Prioritizing fixes across stakeholders — In India enterprise Employee Mobility Services (EMS), how should an operations leader prioritize reliability fixes from post-incident reviews when every stakeholder (HR, Finance, Security) claims their issue is ‘critical’ and the team has limited capacity?
In Indian enterprise Employee Mobility Services, an operations leader should prioritize reliability fixes from post-incident reviews by ranking each fix against a small, explicit set of shared criteria tied to safety, regulatory exposure, and service continuity, not by which stakeholder shouts loudest. The most effective approach is to use a simple, repeatable scoring method that translates incidents into risk to people, risk to operations, and risk to the company’s license to operate, then schedule fixes in that order within the real capacity envelope of the team.
First, operations leaders should anchor all post-incident reviews in a common language of impact. Safety and compliance incidents need to be classified based on severity, especially those involving women’s night-shift commuting, escort rules, or Motor Vehicles / labour law exposure. Reliability incidents should be tied to measurable service outcomes such as On-Time Performance, Trip Adherence Rate, and exception closure time, because these directly affect shift adherence and employee attendance.
Second, fixes should be prioritized through a lightweight scoring lens that is visible to HR, Finance, and Security. One dimension should rate the potential for a repeat safety incident or regulatory breach. Another dimension should rate the potential for systemic operational disruption across multiple shifts or locations. A third should rate financial or reputational exposure, such as large cost leakage or material damage to ESG or employer-brand commitments.
Third, the operations leader should convert this scoring into a short, capacity-aware reliability backlog. The top of the backlog should contain fixes that reduce immediate safety or compliance risk, especially where audit trails, SOS mechanisms, or driver/vehicle credentialing controls are weak. The next band should contain improvements that stabilize the command-center’s observability and incident response, including alerting, escalation matrices, and routing adjustments that reduce dead mileage or missed pickups.
To maintain trust, the operations leader should communicate the prioritization logic transparently. Fewer, better-defined priorities reduce firefighting and allow HR, Finance, and Security to see where their concerns sit on a shared risk map. This approach also supports centralized command-center governance, vendor management, and business continuity planning, because every high-impact fix improves multiple KPIs rather than serving a single stakeholder narrative.
What should count as a ‘major incident’ in EMS/ECS—missed pickup volume, safety triggers, PR risk—so we know when to invoke the full incident process vs handle as routine?
B1500 Defining major incidents for mobility — In India corporate ground transportation (EMS/ECS), what should a ‘major incident’ definition include (missed pickups volume, safety triggers, PR risk) so the command team knows when to invoke a formal incident process versus handling it as routine exceptions?
A major incident in Indian corporate employee mobility should be defined by objective safety triggers, disruption scale, and reputational/PR exposure so that anything that risks people, shifts, or brand automatically moves out of “ops exception” and into a formal, logged incident process. A clear definition must separate routine SLA misses from patterns that indicate systemic failure or material risk.
A safety-first trigger set is non-negotiable. Any allegation of harassment or misconduct in transit, any women’s night-shift SOP breach (no escort where mandated, route deviation, unauthorized drop sequence change), any serious traffic accident or medical emergency in the vehicle, and any loss of GPS/contact with a vehicle beyond a set time window should be auto-classified as a major incident. This aligns with duty-of-care, HSSE expectations, and women-safety protocols described in the safety, chauffeur excellence, and women-centric collateral.
Operationally, the definition should include quantified service disruption. Typical EMS/ECS practice would treat as “major” any event that impacts multiple routes or a meaningful slice of a shift window. Examples include simultaneous missed pickups for a defined number of employees on a route cluster, systemic routing or app failure during a peak shift, or fleet unavailability crossing a threshold that threatens shift start adherence. This reflects command-center and NOC style governance where OTP, route adherence, and exception closure times are monitored continuously.
Reputational and compliance risk needs its own dimension. A single event may qualify as a major incident if it is likely to trigger external inquiries, social media escalation, client leadership intervention, or regulatory exposure. Indicators here include police involvement, hospital admission, local media presence, or any complaint explicitly invoking women-safety, legal non-compliance, or discrimination. This mirrors ESG, HSSE, and CSR sensitivities where one visible failure outweighs many routine successes.
To keep command teams out of constant “red alert,” organizations can set a small, explicit rule set, for example:
- Any safety, harassment, or women-safety SOP breach is a major incident irrespective of numbers.
- Any outage or failure that endangers shift start for a defined proportion of a site or key process is a major incident.
- Any event involving police, regulators, media, or potential legal action is a major incident.
Everything else stays under routine exception management with SLA-based closure, even if escalated internally, which helps the transport head and command center reserve the formal incident process for the few situations that truly demand full playbooks, evidence packs, and cross-functional response.
How do we keep SLO dashboards trustworthy and stable, while still evolving metrics based on incident learnings—so people don’t tune out?
B1501 Preventing metric fatigue — In India corporate EMS, how do you avoid ‘metric fatigue’ where managers stop trusting SLO dashboards because definitions keep changing, while still improving the system based on learnings from post-incident reviews?
In India corporate employee mobility, organizations avoid metric fatigue by hard-freezing a small set of SLO definitions and only evolving the controls and playbooks behind them. Managers trust dashboards when OTP, incident rate, and other core KPIs mean exactly the same thing quarter after quarter, even as routing logic, SOPs, EV mix, and escalation flows are continuously improved in the background.
Most transport and facility heads lose trust when OTP% or safety SLOs are repeatedly “redefined” after escalations. A more stable pattern is to codify a canonical KPI dictionary once, align it with EMS operations, HRMS-linked attendance, and audit expectations, and then treat post-incident learnings as changes to processes, alerts, and routing policies rather than to the KPI meaning. Post-incident reviews can then feed into command-center SOPs, driver training, women-safety protocols, BCP playbooks, or EV routing rules without touching the headline definitions for OTP, Trip Adherence Rate, incident severity, or complaint-closure SLAs.
A common failure mode is retrofitting metrics to make a bad quarter look better, for example by changing time windows or exclusion rules. This erodes credibility with HR, Security, and Finance. A more resilient approach is to version any genuine metric change explicitly, keep old and new series visible, and explain the impact in regular governance forums or management reports. The continuous-improvement loop then focuses on better routing, stronger compliance automation, more predictive alerts from the command center, and refined vendor governance, while preserving a stable, auditable SLO language that busy managers can rely on during every night shift and every audit cycle.
How do we explain SLOs to business leaders so they understand trade-offs and don’t treat every miss as a personal failure of the transport team?
B1502 Executive alignment on SLO trade-offs — In India enterprise employee transport (EMS), what’s the best way to socialize SLOs with business leaders so they understand trade-offs (cost vs redundancy, speed vs safety checks) and don’t escalate every miss as a personal failure of the Transport Head?
In enterprise employee transport in India, SLOs land best when they are framed as jointly owned “risk guardrails” with clear thresholds, not as personal promises from the Transport Head. The most effective approach is to agree SLOs in advance with HR, Finance, Security, and IT, translate them into simple control-room style dashboards, and review them on a fixed cadence so trade-offs are visible and normalized before individual misses become escalations.
The starting point is to define a small, stable SLO set that maps directly to what business leaders care about. On-time performance, safety incident rate, and cost per employee trip should be positioned as the primary service health indicators. Redundancy levels, EV utilization, and driver fatigue controls can be positioned as levers that improve these indicators but also increase cost or reduce routing flexibility.
A common failure mode is to discuss SLOs only at contract sign-off and then revert to incident-driven conversations. A more robust pattern is to set a monthly or quarterly “mobility review” where the command-center view is shown in the same way every time. Trend lines for OTP, exception closure times, safety deviations, and spend should be overlaid with explicit notes on driver availability, severe weather, or charging infrastructure constraints.
SLO socialization works better when trade-offs are made explicit in advance. Higher standby buffers and more escorts improve resilience and women’s safety but raise per-trip cost. Tighter SLAs during peak monsoon windows require more dead mileage and additional vendor commitments. Leaders respond well when these relationships are laid out as choices with quantified impacts instead of implied obligations.
To protect the Transport Head from being seen as a single point of failure, ownership of each SLO should be distributed and documented. OTP should be co-owned with vendors and HR rostering. Safety metrics should be co-owned with Security and compliance teams. Cost metrics should be co-owned with Finance and Procurement through agreed commercial models and outcome-linked contracts.
Clear escalation matrices reduce emotional escalations. When business leaders see that command-center operations have structured thresholds, alerting, and playbooks for breakdowns, strikes, severe congestion, or app downtime, they are more likely to treat outliers as managed exceptions within an agreed risk framework. This reinforces that the system, not an individual, is the primary control surface for EMS performance.
images:

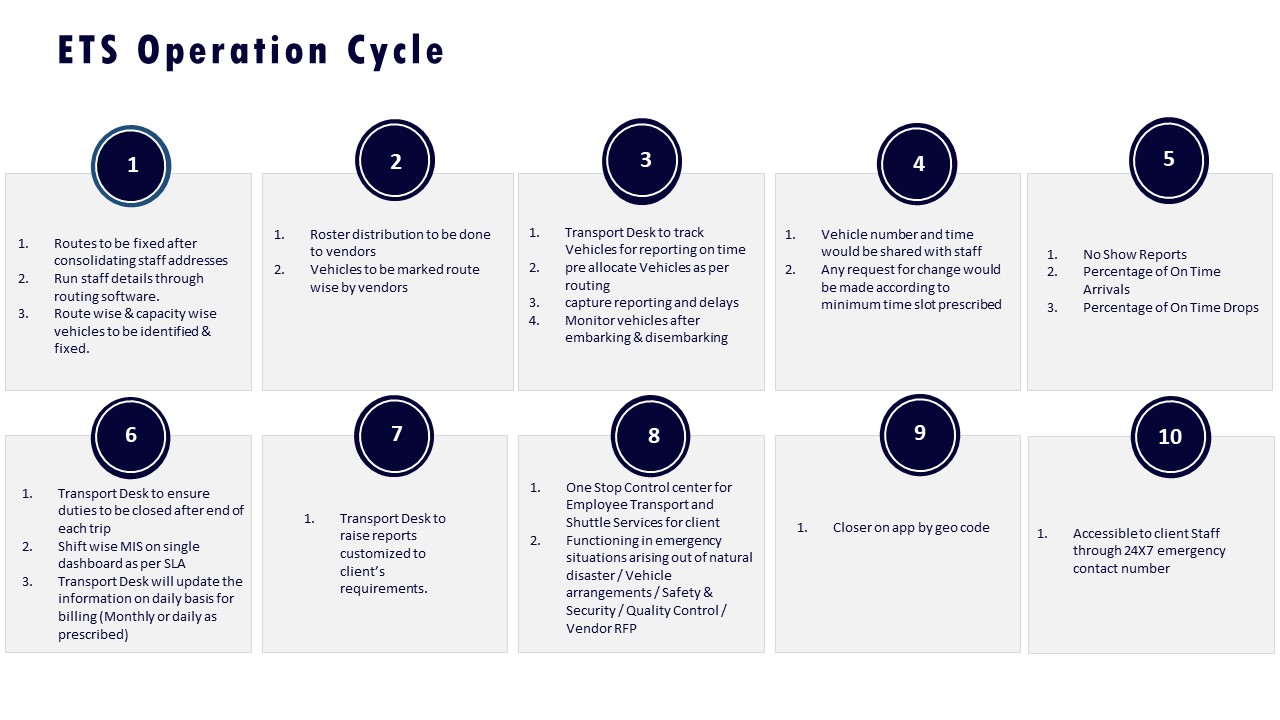
If a vendor says they do ‘SRE-style governance’ with runbooks, what proof should we ask for to tell real maturity from buzzwords?
B1503 Proof of real SRE maturity — In India corporate EMS operations, when a vendor claims they have ‘runbooks’ and ‘SRE-style governance,’ what specific proof should an expert buyer ask for (samples, incident timelines, change logs) to separate mature practice from buzzwords?
In Indian corporate employee mobility operations, a vendor claiming “runbooks” and “SRE‑style governance” should be able to show concrete, dated artefacts that link incidents, SLAs, and change to daily EMS reality. Mature practice always leaves a paper trail across runbooks, command‑center workflows, incidents, and continuous‑improvement logs.
An expert buyer should at minimum ask for three types of proof: live operational artefacts, recent incident histories, and structured change governance records. These should map clearly to EMS realities like night‑shift routing, GPS failures, EV range issues, driver shortages, and weather or political disruptions.
Key requests can include:
- Runbooks and Command‑Center SOPs Ask for redacted copies of current runbooks that cover specific EMS scenarios. Check for step‑by‑step actions, time‑bound SLAs, and role ownership for issues like app downtime, GPS loss, driver no‑show, vehicle breakdown, and severe weather or political bandh. A mature vendor will also show command‑center micro‑functioning documents, escalation matrices, and daily shift‑wise briefing templates aligned to these runbooks.
- Incident Timelines and Closure Evidence Request 3–5 recent, anonymized incident timelines with exact timestamps, from detection in the command center to final closure. Each should show alert source, escalation levels, communication with employees, and restoration time. Supporting artefacts should include SOS or safety‑alert logs, Transport Command Centre dashboards, and Business Continuity Plan playbooks that were actually invoked.
- Change, Capacity, and BCP Governance Logs Ask for change‑log samples showing how routing logic, fleet mix, or app features were modified after repeated issues, including before/after OTP% or customer‑satisfaction metrics. Review Business Continuity Plans and transition planners to see how they handle cab shortages, technology failures, monsoon disruptions, and strikes, along with evidence of at least one real BCP activation with measurable impact on uptime and safety.
Mature SRE‑style governance in EMS usually also shows up in structured dashboards and audits. So a buyer should additionally request redacted command‑center dashboards with SLA and OTP tracking, indicative management reports that tie exceptions to actions, and compliance or safety audit reports that reference specific trip logs and GPS trails.
How can HR tell if better SLOs and faster recovery are truly reducing attendance issues and complaints, not just making internal ops metrics look better?
B1504 Linking SLOs to HR outcomes — In India enterprise EMS, how should HR measure whether reliability improvements (SLO adherence and faster incident recovery) actually reduce attendance volatility and employee complaints, rather than just improving internal ops metrics?
HR teams should link reliability SLOs directly to a few commute-linked workforce outcomes and then track how those outcomes move when SLO adherence and incident closure improve. The most robust approach is to treat On‑Time Performance and incident recovery as input metrics and attendance volatility, transport complaints, and commute experience index as output metrics from the same trip data and HRMS systems.
HR first needs to baseline current patterns. HR should quantify late logins, no‑shows, and shift adherence for employees using EMS and segment these by route, shift band, and vendor. HR should also measure current complaint volume, themes, and closure SLAs from existing helpdesk or app feedback features that already support real‑time tracking, SOS, and issue reporting. HR can then create a simple Commute Experience Index that consolidates survey scores, complaint rates, and escalation counts into one trackable trend.
Once SLOs for OTP% and incident recovery are tightened with the transport team and command center, HR should monitor whether specific cohorts show reduced attendance volatility and fewer escalations. The strongest evidence comes from before‑and‑after comparisons at route or shift level and from A/B pilots when dynamic routing, alert supervision, or women‑centric safety protocols are introduced on only part of the network.
To keep this practical, HR can focus on four decision signals:
- Are late‑login and early‑logout rates falling faster on routes where OTP% and TAR have improved?
- Are complaint and SOS-triggered incident volumes per 1,000 trips reducing as recovery SLAs tighten?
- Do commute-specific satisfaction scores move in the same direction as fleet uptime, VUI, and SLA compliance metrics visible on dashboards?
- Are high-risk cohorts, such as night-shift women, showing lower escalation frequency when safety playbooks and audit-ready evidence improve?
images:
images:
images: 
People safety, fatigue, and executive alignment
Balances safety, fatigue, and experience; creates on-call models and training that reduce burnout while preserving duty of care and performance.
If Ops wants higher reliability SLOs, what extra costs should Finance expect (redundancy, monitoring, supervision), and how do we decide what’s worth paying for?
B1505 Funding higher reliability SLOs — In India corporate Employee Mobility Services (EMS), what trade-offs should Finance expect if Operations asks for higher reliability SLOs—like redundancy vehicles, tighter monitoring, or more on-ground supervision—and how can the CFO decide what’s worth funding?
In corporate Employee Mobility Services in India, higher reliability SLOs almost always trade lower firefighting and incident risk for higher visible spend and tighter operational constraints. Finance should expect cost-per-trip and cost-per-km to rise in exchange for fewer service failures, more predictable OTP%, and lower reputational and safety exposure.
Higher reliability typically means adding buffers into the operating model. Redundancy vehicles, standby cabs, or higher-capacity fleet reduce driver shortages and dead-mile–driven failures but increase fixed or minimum guarantees. Tighter monitoring through a 24x7 command center, alert supervision, and centralized compliance management improves Trip Adherence Rate and incident response time but adds software, telematics, and people costs. More on-ground supervision, such as daily briefings, safety audits, and project/event control desks, lowers exception risk across sites but increases overhead in field coordinators and supervisors.
Finance can decide what is worth funding by linking each reliability ask to measurable outcomes and unit economics. The CFO can insist on baseline vs target metrics for On-Time Performance, escalation volume, incident rate, and driver attrition, and then model impact on Cost per Employee Trip, Cost per Kilometer, and Utilization Index. A practical approach is to fund reliability where business exposure is highest, such as women’s night-shifts or critical production shifts, using outcome-linked contracts with clear SLAs, earn-backs, and penalties. The CFO can also prioritize investments that improve both control and efficiency, like route optimization and centralized dashboards, over purely additive headcount, and require audit-ready data so future ESG, safety, and cost narratives remain defensible.
For our shift-based employee transport, what would an SRE-style setup look like in daily operations—what SLOs, error budgets, and runbooks are practical for on-time pickups/drops and incident handling?
B1506 Practical SRE model for EMS — In India-based corporate employee mobility services (shift-aligned EMS commute operations), what does adopting an SRE mindset actually look like day-to-day—what SLOs, error budgets, and runbooks are realistic for pickup/drop reliability and incident response?
In India-based EMS commute operations, an SRE mindset means treating shift-aligned transport like a production service with declared SLOs, explicit error budgets, and blunt runbooks for night-shift reality. The priority is on-time pickups/drops, safe trip closure, and predictable incident response, not on elegant technology alone.
A practical SLO set focuses on a small number of high-signal metrics. On-time performance is defined as a percentage of trips starting and ending within a tight shift window. Trip Adherence Rate is tracked as the share of trips that follow approved routes without unapproved detours. Exception detection-to-closure time is defined per severity band for safety, compliance, and operational incidents. Command-center uptime is expressed as availability of routing, tracking, and alerting tools during critical shift windows.
Error budgets convert these SLOs into allowable failure. For on-time performance, a small miss band is accepted at the daily and weekly level before triggers fire. For incident response SLOs, an explicit number of breaches in a time window is tolerated before change freezes, routing rules, or vendor allocations are revisited. The error budget for command-center tooling is also explicit so that planned maintenance does not destroy night-shift observability.
Runbooks are written for the control-room, not architects. Each runbook defines what to monitor, when to escalate, and when to fall back to manual mode. Separate playbooks exist for routing failures and GPS or app downtime, with manual roster and call-tree steps. Safety and women-centric incidents follow stricter runbooks that combine SOS handling, geo-fencing breaches, escort rules, and evidence capture from command center dashboards. EV operations require additional runbooks for low battery, charger unavailability, and range-risk management on critical routes.
Realistic SRE practice in EMS uses these constructs to drive vendor governance, driver fatigue management, and routing policy. The SLOs tie into SLA contracts and billing, the error budgets decide when to pause new feature rollout in favor of stability, and the runbooks keep the facility or transport head out of constant firefighting during peak and night operations.
For employee commute trips, how should we define OTP SLOs so they’re measurable and not easy for vendors or teams to game?
B1507 Defining non-gameable OTP SLOs — In India corporate ground transportation for employees (EMS commute reliability), how do operations leaders translate 'on-time pickup/drop' into measurable SLO definitions that won’t get gamed by vendors or internal teams?
Operations leaders in India usually convert “on-time pickup/drop” into a small set of precise, time‑window SLOs tied to auditable trip data, and they define clear inclusion/exclusion rules so neither vendors nor internal teams can game the numbers. The most robust definitions treat OTP as a governed KPI across the full trip lifecycle, not just a simple “driver pressed start on time” metric.
A common pattern is to define separate SLOs for pickup OTP% and drop OTP%, each with agreed time bands around scheduled times. Each SLO uses GPS and app trip logs as the primary evidence source instead of manual duty slips or vendor reports. This prevents back‑dated entries or selective reporting. Leaders usually exclude vendor‑cancelled trips, no‑shows, and roster changes from OTP% only when there is a matching, time‑stamped reason code in the system.
Most operations leaders reduce gaming risk by linking SLO definitions to three additional controls. The first control is route adherence audits using geo‑fencing and telematics to ensure that drivers are not taking unrealistically short or unsafe routes just to “hit OTP.” The second control is exception→closure SLAs, where late pickups create tickets that must be closed with root‑cause codes and evidence, which discourages casual reclassification of trips. The third control is a periodic independent review by the central command center or NOC that samples raw trip logs against reported OTP%.
For EMS environments with hybrid work and shifting demand, leaders often pair OTP SLOs with seat‑fill or Trip Fill Ratio targets and dead‑mileage caps. This prevents vendors from meeting on‑time SLOs by running half‑empty vehicles or over‑supplying fleet. Some organizations also index a portion of commercial payouts to combined OTP, safety incident rate, and complaint‑closure KPIs, which balances punctuality with duty‑of‑care and employee experience.
To keep SLOs credible over time, operations teams usually document them in transport policy and vendor governance frameworks. They align SLO semantics with the centralized command‑center dashboards, incident management workflows, and HRMS‑linked rosters. This ensures that when escalations reach HR, Finance, or Security, everyone is reading the same OTP definition off the same underlying data.
For night shifts and women-safety, what SLOs and runbooks should we have for escorts, SOS response, and closure so we can show duty of care if something happens?
B1508 Women-safety SLOs and runbooks — In India employee mobility services (night-shift EMS operations), what SLOs and runbooks should exist specifically for women-safety workflows like escort adherence, SOS response time, and escalation closure—so HR and EHS can prove duty of care after an incident?
In India night-shift EMS operations, women-safety workflows need explicit, measurable SLOs plus runbooks that bind HR, Transport, Security/EHS, and the vendor under one command-center model. These SLOs should cover escort adherence, SOS detection→response, and incident closure with auditable evidence, so HR and EHS can demonstrate duty of care to leadership, auditors, or regulators after any incident.
Core SLOs for Women-Safety in Night EMS
Organizations should define separate, stricter SLOs for night-shift and women-specific trips. Each SLO must have a clear metric, data source, and reporting owner.
- Escort Compliance SLOs
- Escort adherence rate: Target ≥ 99% of trips where policy mandates an escort (e.g., first pickup / last drop of women employees) must show an approved escort in the passenger manifest or security log.
- Route adherence score: Target ≥ 98% for trips with women employees, based on GPS route adherence audits and geo-fencing of “no-go” areas.
- Unauthorized de-boarding incidents: Target = 0 per month; any deviation is treated as a P1 incident with root-cause and remediation.
- SOS / Panic Workflow SLOs
- SOS signal capture uptime: 24x7 availability with ≥ 99% uptime for employee app SOS and IVR/emergency numbers.
- First operator response time: ≤ 30–60 seconds from SOS trigger to live contact from Command Center or security desk.
- Vehicle immobilization / diversion initiation (if applicable): ≤ 3 minutes from SOS to instruction logged in Command Center system.
- Local security / law-enforcement notification (where triggered): ≤ 10–15 minutes from SOS classification as high-risk.
- Incident & Escalation Closure SLOs
- P1 safety incident acknowledgement: ≤ 5 minutes by duty officer with incident ID created in ticketing/ITSM system.
- Interim update to employee and HR: ≤ 30 minutes with a documented status and immediate safeguards.
- P1 investigation closure: ≤ 24–48 hours for fact-finding, log collation, and preliminary RCA with corrective actions.
- Final closure & HR/EHS sign-off: ≤ 5–7 working days, including disciplinary actions, vendor remediation, and policy changes.
- Evidence pack completeness SLO: ≥ 99% of P1 incidents must have complete GPS logs, call/SOS logs, driver and escort credentials, and communication trail attached.
Runbook Elements for Women-Safety Workflows
Runbooks should be written as control-room SOPs, not policy slides, with clear “who does what, in which system, within how much time.” They should be tested during drills and tied to Command Center operations.
- Pre-Trip Runbook
- Night roster vetting to identify women-first / women-last trips and auto-tag them in the routing system.
- Automatic escort assignment rules enforced by the routing engine, with hard stops if an escort is missing.
- Pre-trip checks: driver KYC currency, escort credentials, IVMS/ GPS health, SOS and panic API health; non-compliant assets are auto-blocked.
- Pre-shift security briefing for drivers/escorts on women-safety protocols, contact numbers, and no-compromise rules.
- In-Trip Monitoring Runbook
- Command Center dashboard filters to highlight all active trips with women employees during night hours.
- Geo-fencing and random route audit rules for high-risk corridors with automatic alerts on deviations or long halts.
- Mandatory check-in calls or in-app confirmations at defined milestones for critical trips (e.g., last drop in low-density areas).
- Special handling for app / GPS failure: predefined voice/IVR check-in protocol and fallback manual tracking until tech is restored.
- SOS / Panic Runbook
- Triaging algorithm that classifies SOS as P1 (immediate personal safety), P2 (vehicle breakdown in unsafe area), etc., based on metadata and operator assessment.
- Step-by-step script for the Command Center agent: verify employee identity, location, and immediate risk; keep the line open where required.
- Parallel actions: notify security/EHS duty officer, alert local site security, ping driver app with instructions, and, if needed, contact local police.
- Mandatory creation of a single incident ticket that links SOS trigger, telematics, and all follow-up actions, with time stamps.
- Post-Incident & Evidence Runbook
- Within 24 hours: sealed capture of GPS/trip ledger, driver & escort records, IVR/SOS logs, and CCTV (where applicable) into an immutable audit repository.
- Joint HR–EHS–Transport review meeting for each P1 case, generating an RCA and corrective/preventive actions (driver retraining, vendor penalty, routing change).
- Communication protocol to the affected employee, her manager, and, if required, Internal Committee / POSH or legal teams.
- Periodic anonymized reporting of incident metrics and corrective actions to leadership and, where relevant, to ESG or risk committees.
How HR and EHS Prove Duty of Care
To defend duty of care after an incident, organizations need not just SLOs and runbooks but also an audit-ready data layer.
- Maintain a centralized compliance dashboard for women-safety KPIs, including escort adherence rate, night-trip OTP%, SOS response times, and closure SLAs.
- Ensure every night-shift trip with women employees is traceable through a trip ledger with GPS tracks, manifest, credentials, and approvals.
- Run quarterly route adherence audits and women-safety drills, and store results as part of the HSSE governance record.
- Align vendor contracts and penalties to these specific SLOs so Procurement and Finance can link payments to safety performance.
When HR and EHS can show defined SLOs, tested runbooks, and complete evidence packs for each serious event, they move from reactive defense to a demonstrable “safety by design” posture in night-shift EMS operations.
For EMS operations, which few metrics actually predict a rough shift early—without flooding the team with alerts?
B1509 Early-warning SLIs without alert fatigue — In India corporate employee commute operations (EMS), how do you choose a small set of SRE-style SLIs that predict 'bad nights' early (e.g., vendor non-response, GPS gaps, driver no-shows) without overwhelming the transport desk with alerts?
In Indian employee commute operations, the most effective SRE-style SLIs are a small set of shift-level, leading indicators that correlate tightly with on-time performance, safety incidents, and vendor responsiveness. These SLIs should focus on early deviation in routing, supply, and systems health, and they should be routed through a command-center SOP that suppresses noise and only escalates when thresholds are crossed.
The strongest predictors of “bad nights” usually sit in four buckets. The first bucket is supply readiness and driver compliance. A useful SLI is the percentage of rostered shifts where vehicles, drivers, and statutory documents are fully “green” 60–90 minutes before pickup. Another SLI is driver no-show or late-login rate at roster lock time, which Transport Command Centres can track through driver apps and compliance dashboards. A third is escort or women-safety resource shortfall for night shifts, which strongly predicts last-minute routing chaos.
The second bucket is routing and GPS health. Route adherence deviation rate from the routing engine, measured as trips with significant detours or repeated geo-fence violations, is a good leading signal. So is GPS signal continuity, measured as the fraction of live trips with acceptable tracking continuity, since extended GPS gaps degrade both safety assurance and control-room visibility.
The third bucket is vendor and platform responsiveness. A practical SLI is median incident triage time in the command center, measured from alert creation to first human action. Another is open-incident backlog per shift for issues like app downtime, vehicle failures, or late reporting by vendors. Command-center collateral in the context shows that 24x7 monitoring and escalation matrices already exist, so tying SLIs to those workflows is feasible.
The fourth bucket is shift-level experience risk. Transport teams can track short-notice roster changes and late bookings that exceed a pre-validated planning window. They can also track predicted vs actual seat-fill and dead mileage because poor utilization often signals routing instability and potential cost and reliability problems.
To avoid overwhelming the transport desk, each SLI should have a clearly defined SLO band, an escalation matrix, and a playbook. Teams can aggregate SLIs into a simple shift “health” view in their single-window dashboards and command centers, as described in the collateral around micro functioning of command centres and data-driven insights. Alerting should only fire when multiple SLIs breach agreed thresholds within a shift window, and batch reports can be used for trend analysis instead of real-time noise.
How do we set an error budget for commute reliability that balances cost and service—so Finance doesn’t call it overspend and HR isn’t stuck with repeat delays?
B1510 Error budgets that balance cost — In India enterprise-managed mobility (EMS commute execution), how do you set an error budget that balances reliability with cost—so Finance doesn’t accuse Ops of overspending for 'gold-plated' service while HR won’t accept recurring delays?
In India EMS commute operations, an effective error budget defines a target on-time performance band, links cost to that band, and allocates a small, explicit “acceptable failure” margin that is auditable trip-by-trip. The error budget must be framed in terms of business outcomes like OTP%, Trip Adherence Rate, and complaint closure SLAs rather than abstract uptime targets, and it should be contractually tied to incentives and penalties so Finance sees cost discipline while HR sees predictability and control.
The starting point is to baseline current operations using canonical KPIs like On-Time Performance (OTP%), Trip Adherence Rate, Cost per Employee Trip, and complaint or incident rates. The EMS team then defines a realistic OTP target by shift and corridor, and converts the shortfall between 100% and the target into an “error budget” expressed as a percentage of trips or minutes of delay. A common failure mode is setting a uniform, aspirational number without accounting for hybrid-work variability, traffic patterns, or high-risk timebands.
The error budget becomes a finance tool when costs are modeled against OTP bands so Procurement and CFO can see how each additional reliability step-up affects Cost per Kilometer and Cost per Employee Trip. The same error budget becomes an HR and safety tool when embedded into SLAs, escalation matrices, and command center playbooks so that every breach is logged, triaged, and closed with evidence. Teams should review budget consumption in monthly QBRs, rebalancing routing rules, fleet mix, and vendor allocation rather than simply buying more capacity whenever complaints spike.
How can we run blameless post-incident reviews when vendors and teams worry the metrics will be used to punish people or trigger penalties?
B1511 Blameless PIRs under vendor pressure — In India corporate ground transportation programs (EMS + CRD operations), what’s a realistic way to operationalize 'blameless post-incident reviews' when vendors, drivers, and internal stakeholders are worried metrics will be used for punishment or contract penalties?
Blameless post-incident reviews in Indian EMS and CRD programs become realistic only when organizations separate safety and learning data from commercial and HR action data, and codify that separation in governance, contracts, and SOPs.
Most organizations struggle because they use the same incident logs for SLA penalties, driver disciplinary action, and safety learning. This creates fear across vendors, drivers, transport teams, and even HR or Security. A more workable model is to treat the review as part of an assurance and resilience framework, aligned with command-center operations, business continuity planning, and compliance dashboards, rather than as an extension of procurement or HR discipline.
A practical pattern is to define two explicit layers in the mobility governance model. One layer focuses on incident reconstruction and root-cause analysis using command center telemetry, GPS trip ledgers, SOS logs, and audit-ready evidence, with participation from HR, Transport, Security/EHS, and the vendor. A second layer focuses on commercial and disciplinary consequences, driven by pre-agreed SLA frameworks, procurement scorecards, and penalty benchmarks that look at patterns and rates, not single events. This reduces the pressure to “defend” each incident and supports continuous improvement.
Blameless reviews become credible when the organization publishes an SOP that states what will and will not happen after an event. Typical elements include clear escalation matrices, defined roles for HR, Security/EHS, and the command center, an approved format for incident timelines, and thresholds where the review moves from learning to compliance or disciplinary action. Transport heads gain operational calm when this SOP is tied to business continuity plans, driver training programs, and safety and compliance frameworks, so that each incident feeds into route audits, driver coaching, or EV/ICE fleet mix decisions instead of ad-hoc blame.
- Use command-center dashboards and audit trails for structured RCA, not ad-hoc questioning.
- Anchor the review in safety, continuity, and ESG obligations before cost and penalties.
- Measure trends such as incident rate and closure time, not just individual failures.
- Feed findings into driver management, routing optimization, and vendor governance cycles.
For typical late-night issues like a vendor not picking up, a breakdown, a no-show, or a blocked route—what should our runbooks include so we’re not improvising?
B1512 2 a.m. EMS runbook contents — In India employee mobility services (EMS), what should a runbook include for the most common ‘2 a.m.’ scenarios—vendor not answering, vehicle breakdown, rider no-show, route blocked—so the transport head isn’t improvising every night?
In India employee mobility services, a 2 a.m. runbook must give the transport head pre-agreed decision trees, contacts, and time-bounds for each failure mode, so night ops follow SOPs instead of improvisation. The runbook should define who does what, in what sequence, and by when, for vendor non-response, vehicle breakdowns, rider no-shows, and route blockages, with clear escalation and documentation steps.
For vendor not answering, the runbook should specify a response-time threshold, then auto-switch to backup supply. It should list a ranked backup sequence across vendors, a live escalation matrix, and authority for the command center to reassign trips without fresh approvals. The alert supervision system or command center tooling should generate and log alerts, so chronic non-response is visible in vendor performance reports and SLA reviews.
For vehicle breakdown, the runbook should define immediate driver actions, passenger communication, and maximum wait times before dispatching a replacement. It should include criteria for using standby cars, nearby idle vehicles from other routes, or on-demand CRD supply, plus rules on escort continuity for women on night shifts and mandatory incident logging to the command center.
For rider no-show, the runbook should standardize call attempts, wait-time rules at pickup, and auto-closure in the system. It should define when to leave, how to record no-shows for billing and MIS, and how to adjust routing so other riders are not delayed. The EMS platform should support real-time updates to manifests and route plans, so downstream OTP is protected.
For route blocked by traffic, weather, or local events, the runbook should pair dynamic route recalculation with pre-defined safety and compliance rules. It should specify when control-room routing overrides driver discretion, when to coordinate with local authorities, and when to split or reroute trips using alternative vehicles or hubs. Dynamic routing must still respect escort policies, geo-fencing, and women-safety protocols, with the command center documenting all deviations.
images:
How do we define escalation ownership in runbooks so incidents don’t bounce between HR, Facilities, Security, and the vendor with everyone saying it’s not their KPI?
B1513 Clear runbook ownership and escalations — In India shift-based employee transportation (EMS), how do you define escalation matrices and ownership in runbooks so incidents don’t bounce between HR, Facilities, Security/EHS, and the mobility vendor with everyone claiming it’s ‘not my KPI’?
In shift-based employee transport, escalation matrices work best when every incident type has a single accountable owner per stage, written KPIs, and pre-agreed handoff rules across HR, Facilities/Transport, Security/EHS, and the mobility vendor. Clear runbooks define who detects, who leads, who supports, and what “done” means at each escalation level, so no team can opt out by saying “not my KPI.”
Effective designs start by classifying incidents into a small number of categories. Typical transport categories include reliability failures such as no-shows and chronic late pickups, safety and women-safety events, compliance breaches, and technology failures such as GPS or app downtime. Each category then maps to a lead function by default. Facilities or Transport usually lead reliability and tech issues, Security/EHS leads safety incidents, and HR leads employee grievance and communication.
The escalation matrix then defines three to four levels with explicit triggers and time-bounded KPIs. Level 1 is command-center or vendor NOC response with a target like immediate acknowledgment and a fixed closure SLA. Level 2 is Transport or Security duty manager involvement for issues that miss Level 1 targets or involve night-shift or women employees. Level 3 is HR and senior leadership review for severe incidents or repeated SLA breaches. Each level specifies one “incident owner” and which other functions must participate.
Runbooks remove ambiguity by turning this matrix into stepwise SOPs. Each runbook entry states the detection source such as app SOS, GPS alert, or complaint, mandatory first actions, maximum time limits before escalation to the next level, communication templates for employees and managers, and evidence to capture for audits. Ownership is reinforced by linking these steps to KPIs such as OTP%, incident closure SLA, audit trail completeness, and women-safety compliance, and by reviewing them in joint QBRs across HR, Facilities, Security/EHS, and the vendor.
In PIRs for commute issues, how do we separate what we could control from what we couldn’t, without it becoming a blame game?
B1514 Root-cause separation in PIRs — In India corporate employee commute operations (EMS), how do you run post-incident reviews that separate controllable root causes (process, vendor behavior) from uncontrollable ones (weather, road closures) without turning it into blame-shifting?
Post-incident reviews in Indian employee commute operations work best when they are run as a fixed, evidence-based process that classifies each contributing factor as “controllable,” “influenceable,” or “uncontrollable,” and then assigns actions only against the first two. The review must be anchored in SOPs, logs, and SLAs, not in opinions about people, so that the discussion focuses on system gaps rather than blame.
A common failure mode is starting the review from complaints or anecdote. Operations leaders who start from the trip ledger, GPS trail, alert history, and escalation timestamps usually separate facts from noise more cleanly. This is where a command center, alert supervision system, and centralized compliance dashboards are useful, because they create an auditable timeline of what actually happened during the shift.
A practical pattern is to define clear categories before the meeting. For example, weather, sudden road closures, and police nakabandis are logged as “uncontrollable,” but the absence of a buffer vehicle, no re-route attempt, non-responsive vendor, or poor driver judgment under those conditions are logged as “controllable” or “influenceable.” The Business Continuity Plan and on-time delivery playbooks should explicitly state how operations must respond to those uncontrollable triggers, so teams are accountable for the response, not the trigger.
To keep reviews from becoming blame-shifting, most organizations benefit from three guardrails:
- A standard, written incident review template owned by Transport/HSSE that records timeline, data evidence, category of each factor, and agreed CAPA.
- Cross-functional participation (Transport, Security/EHS, vendor, sometimes HR) with the rule that individuals are not named unless there is willful violation.
- Follow-through via command-center dashboards and management reports, where recurring controllable causes (e.g., driver fatigue, chronic vendor OTP failure, routing gaps) are tracked as metrics and fed into vendor governance, driver training, and BCP updates.
This approach keeps the Facility/Transport Head in control of operational learning, gives HR and Security defensible evidence for leadership, and signals to vendors and drivers that the system is being improved continuously rather than looking for someone to blame.
For incident tickets, what evidence should we capture—timestamps, GPS, calls/messages, acknowledgements—so we can defend what happened in an audit or serious escalation?
B1515 Audit-ready incident ticket evidence — In India enterprise employee mobility (EMS), what evidence and audit trail should be captured in SRE-style incident tickets (timestamps, GPS logs, comms, acknowledgements) so Internal Audit and HR can defend decisions after a serious escalation?
In Indian enterprise employee mobility, incident tickets need to look like an SRE log plus a legal file note. Every serious commute escalation should have a single ticket that can reconstruct who knew what, when they knew it, what data they saw, and what they did in response. Internal Audit and HR can defend decisions only if timestamps, GPS evidence, communication records, and closure notes are complete, consistent, and tamper-evident.
Each ticket should start with a precise incident header. This includes unique incident ID, trip ID, vehicle ID, driver ID, employee IDs, route details, shift window, and service type such as EMS, CRD, or ECS. The header should capture booking source, policy tier, and applicable safety rules such as women night-shift policies or escort requirements. This establishes the context of what was supposed to happen.
The timeline section should record system and human events with accurate timestamps. Required events include booking creation, roster and route finalization, vehicle reporting time, employee boarding time, SOS or alert trigger time, escalation time, and incident closure time. Each line in the timeline should show the actor, channel, and action taken. This enables auditors to see latency between detection and response.
Location and telemetry evidence should be attached for the full trip window. This includes GPS traces with coordinates and speed, geo-fence entries and exits, route adherence versus planned route, and any tamper or device-offline alerts. Battery level and vehicle health are relevant for EV fleets. These logs should be exportable, read-only, and linked to the ticket rather than stored in personal inboxes.
Communication and acknowledgement records need to show who was informed and what they were told. The ticket should capture employee app events such as SOS presses and in-app feedback, driver app events such as SOS presses and acknowledgement taps, command center actions including outbound calls and instructions, and security or EHS notifications. For each item, the record should show channel, content summary, recipients, and acknowledgement status. This protects HR and Transport when challenged on “you did not act” claims.
Compliance and safety checks should be visible inside the ticket as facts, not promises. Required elements include driver KYC and background status at trip start, vehicle compliance and fitness validity, escort allocation and check-in for women’s night-shift trips, and HSSE requirements such as induction or training completion. Attachments should include checklists, certificates, and app screenshots where relevant. This gives Internal Audit and Security a clear compliance snapshot.
The decision and escalation trail should read like an SRE post-incident log. It should show escalation levels reached, including duty officer, transport manager, security lead, and HR representative. Each decision entry should include timestamp, person, role, information available, and decision taken. Any refusal, override, or delay should be explicitly recorded. This allows HR to justify why a particular course of action was reasonable in the moment.
Corrective and preventive actions should be captured as structured fields. Examples include driver suspension or retraining, vendor warning or route suspension, SOP change in routing or escort policy, and technology fixes such as geo-fence tuning or alert thresholds. Each action must have an owner, due date, and closure timestamp, and the ticket should not be marked resolved until preventive actions are complete.
The ticket system itself should support auditability. There should be immutable change logs for ticket edits, role-based access control, and retention policies aligned with HR, legal, and regulatory requirements. The combination of structured fields, raw data attachments, and immutable logs is what lets Internal Audit and HR demonstrate that the organization had control, visibility, and evidence during and after a serious escalation.
How do we set a sensible incident severity model so the NOC escalates correctly and leadership isn’t pulled into routine issues?
B1516 Incident severity taxonomy for EMS — In India corporate employee transport (EMS), how do you decide the right 'incident severity' taxonomy (SEV1/SEV2 etc.) so the command center escalates appropriately and senior leaders aren’t paged for routine noise?
In corporate EMS command centers, the “right” incident severity model is one that is tightly mapped to safety risk, service impact, and evidence requirements, not to who is shouting the loudest. A practical taxonomy in India EMS usually anchors SEV‑levels to three dimensions. These are life and safety risk, shift continuity/OTP impact, and compliance or reputational exposure. The goal is that SEV1 always means “drop everything, page leadership,” while SEV3/SEV4 stay within the command center and vendor teams with clear closure SLAs.
A common failure mode is mixing pure service irritation with safety or legal exposure. This leads to alert fatigue, where senior stakeholders start ignoring dashboards and late‑night calls. Command centers work better when SEV1 is reserved for events like women’s night‑shift safety threats, serious accidents, missing employees, or confirmed escort and route‑deviation violations. These incidents demand immediate escalation to Security/EHS, HR, and Transport, with audit‑ready trip logs, IVMS data, and SOS traces from the employee/driver apps.
Mid‑tier severities in EMS are better tied to operational impact. Examples are multi‑vehicle breakdowns before a critical shift window, repeated OTP breaches on a route cluster, or tech outages that force a fallback to manual routing. The command center should own these as SEV2 or SEV3, with defined response times, rerouting playbooks, and business continuity actions such as buffer vehicles, alternate vendors, and manual manifests.
Lower severities fit routine noise that Transport Heads want contained. Examples are single‑cabs running 10–15 minutes late within SLA tolerance bands, one‑off GPS glitches with driver contact confirmed, or isolated app login issues where backup processes exist. These sit as SEV3/SEV4 with closure expectations measured in hours, not minutes, and should not trigger late‑night calls to CHRO, CFO, or CSO unless they start forming a pattern.
To make this workable on the floor, organizations typically define a short, written matrix. The matrix maps each incident type to SEV level, the owning team, the first response SLA, and who must be informed versus who must be woken up. It relies on integrated tools like the Transport Command Centre dashboards, Alert Supervision System, SOS control panel, and centralized compliance management to give the command team live data and audit trails without manual triage guesswork.
Over time, incident logs from dashboards and management reports become the calibration mechanism. Transport Heads and Security teams periodically review closed incidents to see which SEV assignments were overreactive or under‑called. They then retune thresholds so that SEV1 count stays low and meaningful, SEV2 stays within the 24×7 command center’s capacity, and SEV3/SEV4 are largely handled quietly by vendors and dispatch, keeping senior leaders informed through weekly or monthly summaries instead of middle‑of‑the‑night pages.
How do we measure time-to-detect and time-to-recover when we often learn about issues from employee complaints, not system alerts?
B1517 Measuring TTD/TTR with human signals — In India corporate ground transportation operations (EMS/CRD), what’s the right way to measure 'time to detect' and 'time to recover' for commute incidents when detection may come from an employee complaint rather than system telemetry?
In Indian corporate ground transport operations, ‘time to detect’ and ‘time to recover’ should be measured from the first objective evidence of an incident to two separate points in the incident lifecycle. ‘Time to detect’ should run from the earliest signal that could reasonably have revealed the incident (system alert or employee complaint log time) to the moment the command center classifies it as an incident. ‘Time to recover’ should run from that classification timestamp to the time service is restored to a safe, acceptable state for the affected employee or route.
Most organizations should treat employee complaints, SOS triggers, and call-center tickets as valid detection sources alongside GPS or telematics. Command centers and transport desks should therefore log every complaint, SOS, and exception in a common alert supervision or command-center system so that the “first seen” timestamp is always machine-readable. A common failure mode is measuring only from system telemetry and ignoring when the employee first raised the issue, which systematically understates detection time and weakens audit credibility for HR, Security, and ESG reporting.
Operations teams should also separate primary recovery and full closure. Primary recovery is when the immediate impact to the employee shift is mitigated, for example when a replacement cab is assigned or a stranded employee is safely handed over to security. Full closure is when root cause analysis, compliance checks, and corrective actions are completed. Measuring all three timestamps (first-signal, incident-classification, primary-recovery) allows transport heads, command centers, and HR to benchmark SLA performance, refine business continuity playbooks, and link penalty or incentive models to outcome-based procurement.
How do we set SLOs that capture employee experience like waiting time and grievance closure, without Finance dismissing them as ‘soft’ metrics?
B1518 EX-focused SLOs without pushback — In India employee mobility services (EMS), how do you set SLOs that reflect the employee experience (waiting time, communication quality, grievance closure) rather than only operational metrics—without HR being accused of ‘soft’ KPIs by Finance?
In Indian employee mobility services, SLOs reflect employee experience best when they translate “soft” commute pain into hard, auditable KPIs that Finance can reconcile with operations and cost. The practical approach is to define a small set of experience SLOs with precise formulas, clear data sources, and explicit linkage to existing EMS operational metrics like OTP, TAR, and CET.
The most robust pattern is to anchor experience SLOs on specific, measurable events in the ETS/EMS operation cycle. Employee waiting time can be expressed as “max X minutes variance between app ETA and actual vehicle arrival” and tied to routing engine logs and trip adherence audits. Communication quality can be encoded as “percentage of trips where pre-trip notifications and revision alerts were delivered within Y minutes of schedule change,” using app notification logs and command-center records instead of subjective surveys. Grievance closure can be defined as “Z% of transport tickets closed within N working hours with documented RCA in the mobility system,” backed by the same ITSM or command-center tooling used for SLA governance.
Finance pushback reduces when these experience SLOs are mapped directly to cost and risk levers. Waiting-time SLOs correlate with attendance stability and reduced no-show rate, which influence cost per employee trip and overtime leakage. Communication and alert SLOs reduce last-minute cancellations and dead mileage, which are already tracked via CPK and Trip Fill Ratio. Grievance-closure SLOs lower incident recurrence and safety exposure, which aligns with vendor penalties, insurance posture, and business continuity risk.
A workable EMS SLO set typically includes three to five experience-focused targets that meet three conditions:
- Each SLO is defined in operational language (time, percentage, count) rather than sentiment language.
- Each SLO is sourced from systems HR, Transport, and Finance jointly trust, such as routing logs, trip ledgers, NOC dashboards, and ticketing tools.
- Each SLO is explicitly linked in the contract to at least one financial or risk outcome, such as CET, SLA breach rate, utilization, or incident rate.
This structure allows HR to defend employee-centric SLOs as part of an outcome-linked procurement model, not as “soft” additions. It also lets Transport and the command center run early-warning dashboards that combine OTP, seat fill, SOS alerts, and complaint closure into a single Commute Experience Index that is still grounded in data, audit trails, and SLA governance.
What are the common ways SLO reports get ‘massaged’ in commute ops, and how do we prevent it without turning into a policing culture?
B1519 Preventing SLO manipulation in EMS — In India shift-based EMS commute operations, what are the most common ways SLO reporting gets manipulated (e.g., redefining ‘arrived’, ignoring missed pickups), and how do you design governance to prevent that without creating a policing culture?
In Indian shift-based Employee Mobility Services, SLO reporting often gets manipulated by redefining operational events and selectively omitting failures. Governance needs to anchor definitions, data sources, and review rhythms in a way that makes gaming hard, yet frames transparency as shared protection for HR, Transport, vendors, and drivers rather than a policing exercise.
Common manipulation patterns include redefining “on time” and “arrived” to protect OTP%, excluding missed pickups or aborted trips from the dataset, and marking vendor-initiated cancellations as “employee no-show.” Manipulation also occurs when manual overrides quietly adjust GPS timestamps, when “escort compliance” or women-safety rules are logged as met without real-world verification, and when complaint closure times are reset by re-opening or reclassifying tickets. Centralized command center teams sometimes aggregate data in ways that dilute incident rates, especially when multiple vendors and regions are blended without breakouts.
Governance works best when there are canonical SLO definitions with explicit time-stamps and event states, when those SLOs are computed from immutable trip logs in a mobility data lake, and when Transport, HR, and vendors all see the same KPI layer. A strong vendor governance framework ties commercial incentives and penalties to those canonical metrics, but also incorporates grace rules and exception categories that are pre-approved, documented, and auditable. Route adherence audits, random trip-level spot checks, and automated anomaly detection highlight gaps without accusing individuals.
To avoid a policing culture, organizations should present observability as risk-sharing. Transport and vendors benefit from audit-ready evidence when incidents occur, while HR and Security gain defensible duty-of-care logs. Joint QBRs can review OTP%, seat-fill, incident rates, and complaint SLAs alongside positive metrics like Commute Experience Index and driver fatigue indicators, so conversations are about continuous improvement rather than blame. Clear escalation matrices, transparent root-cause analyses, and playbook-style SOPs for exceptions help shift the narrative from “who failed?” to “which control failed, and how do we harden it?”
From an IT/privacy angle, how do we check if SRE-style monitoring will collect too much data and trigger DPDP issues or employee surveillance concerns?
B1520 SRE monitoring vs DPDP and trust — In India corporate employee transport (EMS), how should a CIO evaluate whether SRE-style monitoring and incident workflows will increase data collection in ways that raise DPDP privacy concerns or employee ‘surveillance’ backlash?
In Indian corporate employee transport, a CIO should evaluate SRE-style monitoring and incident workflows by explicitly mapping every data signal to a legitimate business purpose, checking it against DPDP principles, and stress-testing how it will feel to employees who already worry about surveillance. The CIO’s decision is sound when each telemetry stream can be justified as essential for safety, reliability, or compliance, and when the same outcome cannot be achieved with less intrusive data.
The CIO should first list all data points that SRE-style observability would introduce or intensify. Typical categories include trip-level GPS traces, routing logs, driver behavior metrics, app event logs, and command-center incident workflows. Each category should then be classified as operational telemetry or personal data, and further split into identifiers (name, phone, employee ID, photo) versus behavioral traces (movement patterns, check-ins, feedback).
For DPDP compliance, the CIO should check whether lawful basis is clearly defined for each data category. Employee mobility systems usually rely on contractual necessity and legal obligations around safety and labour/transport rules. The CIO should confirm that trip logs, GPS traces, and incident records are retained only as long as required for SLA governance, safety investigations, and auditability of employee transport, and that retention schedules are explicitly codified. Data minimization checks should test whether exact home locations, historical route archives, or inferred behavior scores are really required at full resolution, or whether aggregation, pseudonymization, or shorter look-back windows are sufficient.
To reduce surveillance backlash, the monitoring design should separate what the command center sees from what line managers see. The mobility command center can legitimately access fine-grained trip telemetry for real-time safety and SLA control, while HR or functional managers should usually see only aggregate commute KPIs and exception summaries. Role-based access control and audit logs can enforce these bounds and provide comfort that commute data is not repurposed for performance reviews or attendance policing beyond stated policies.
The CIO should also examine SRE practices like incident post-mortems, alert routing, and dashboards for privacy impact. Error logs and traces should avoid embedding free-text personal data, screenshots with names, or raw chat transcripts unless strictly required for safety investigations. Dashboards used for NOC operations should default to pseudonymous identifiers where possible, revealing identity only through controlled drill-down for authorized users under defined incident SOPs.
Before rollout, the CIO should insist on a plain-language data and monitoring notice to employees that explains what is collected, why, for how long, and who can see it. Framing SRE-style observability as a safety and reliability control for employee mobility, rather than a productivity surveillance tool, reduces backlash risk. Internal FAQs should explicitly state that commute data is governed under mobility SLAs, safety protocols, and DPDP-aligned retention policies, not used as a general-purpose tracking system.
To operationalize this evaluation, a CIO can use a short set of checks:
- Purpose–data fit. For each metric or log type, verify a direct link to commute reliability, safety, compliance, or auditability. Flag any SRE metric that is merely “nice to have” but privacy-costly.
- Resolution and retention. Reduce GPS precision, shorten log history, and aggregate where this does not degrade SLA governance or incident reconstruction.
- Access and context. Limit raw trace access to the 24x7 command center and security/EHS under documented SOPs, while giving HR and leadership aggregated KPIs like OTP%, incident rates, and complaint closure SLAs.
- Exit and portability. Confirm that if the enterprise exits a mobility vendor, data exports and deletions are clearly defined, ensuring DPDP-compliant lifecycle closure rather than uncontrolled long-term storage.
A CIO should also run a DPDP-aware privacy impact assessment for the mobility stack. This assessment should explicitly model worst-case perceptions. For example, a risk scenario might describe a night-shift employee discovering that her historical commute routes and timing are available to non-transport managers. If the architecture or governance model allows such access in practice, the underlying monitoring design fails both DPDP’s purpose limitation spirit and the employee trust test, even if it is technically lawful.
SRE-style observability in employee transport works best when it is framed as “safety and reliability telemetry with observable guardrails” rather than “full-spectrum behavioral analytics.” If the CIO cannot clearly articulate what operational KPI or SLA would materially degrade by removing or aggregating a given telemetry stream, that stream is a candidate for reduction or removal. Continuous assurance for safety and reliability is compatible with DPDP and employee expectations, but only when data scope, retention, and access are engineered as tightly as uptime and latency.
How do we validate our runbooks are actually usable—through drills, shift handovers, and involving vendors—before a real incident happens?
B1521 Runbook readiness testing checklist — In India enterprise mobility programs (EMS), what’s a practical checklist to validate that runbooks aren’t just documents—i.e., how do you test them through drills, shift handovers, and vendor participation before a real incident hits?
In Indian enterprise mobility programs, runbooks stop being “just documents” when organizations routinely rehearse them through controlled drills, structured handovers, and live vendor checks with auditable evidence. A practical checklist focuses on whether every critical failure mode has been walked through end-to-end with the command center, vendors, drivers, and HR/security teams under realistic conditions.
Most organizations start by mapping EMS runbooks to their real risk surface. Transport leaders align each SOP to concrete scenarios such as night-shift vehicle no-show, GPS or app outage, political strike, severe weather, or EV charging failure. A common failure mode is documenting dozens of SOPs but never assigning clear owners and time-bounded actions per step, so every scenario in the playbook needs a named role, an SLA, and a measurable outcome like on-time performance recovery or safe-drop completion.
Runbooks are then exercised through planned drills that replicate the ETS/EMS operation cycle. Command centers simulate alerts for route disruption, women-safety escalation, or business continuity triggers and check if routing, vendor dispatch, SOS handling, and escalation matrices work as written. Drills are more reliable when they include driver briefings, employee communication templates, and coordination with security and HRMS-linked rosters, not just control-room actions.
Shift handovers serve as daily micro-tests of runbooks. Transport heads use structured checklists covering open incidents, exception queues, vendor gaps, fleet uptime, and driver fatigue risks. A common gap is unlogged verbal handovers, so organizations increasingly require a short, timestamped NOC or dashboard note with pending actions, SLA risks, and mitigation status per shift window.
Vendor participation is validated by embedding SOP steps into contracts and SLAs. Enterprises test vendor readiness via surprise spot checks, BCP drills (cab shortage, political strike, monsoon disruption), and compliance audits of driver training, fleet induction, women-centric safety protocols, and EV/ICE backup plans. A frequent weakness is over-reliance on one vendor’s manual processes without cross-vendor comparability or a clear substitution playbook.
Transport command centers and data-driven dashboards close the loop by capturing OTP, incident rate, exception closure times, and BCP drill performance. Organizations treat each drill like a mini-incident, generating a post-incident review, root-cause analysis, and SOP change log that feeds into governance forums with HR, security, and procurement. Runbooks become living tools when every deviation in a drill leads to a specific update in routing rules, escalation matrices, vendor governance, or driver training rather than staying as a static PDF.
- Confirm every high-risk scenario has a runbook owner, SLA, and measurable outcome.
- Schedule periodic multi-party drills that exercise command center, drivers, and vendors together.
- Standardize shift handover templates capturing open risks and exceptions.
- Build vendor obligations for drills, BCP, and women-safety compliance into EMS contracts.
- Use dashboards and audits to track drill performance and enforce continuous SOP revisions.
Post-incident learning, evidence, and continuous improvement
Provides auditable evidence, PIR cadence, and a strong improvement backlog; ensures actions close and leadership can see tangible reliability gains.
For executive and airport trips, what SLOs and runbooks should cover flight delays and missed pickups so the travel desk isn’t scrambling manually?
B1522 CRD airport SLOs and runbooks — In India corporate car rental services (CRD) for executives and airport transfers, what SLOs and incident runbooks should exist for flight delays, gate changes, and missed pickups—so the travel desk isn’t forced into last-minute manual coordination?
For executive CRD and airport transfers, providers should commit to explicit, measurable SLOs for flight-linked changes, plus pre-agreed incident runbooks that shift work from the travel desk to the command center. The SLOs must cover response times for detecting changes, re-dispatching vehicles, communicating updates to travelers, and closing exceptions with auditable logs.
A practical SLO set ties dispatch and monitoring directly to flight data. The CRD vendor’s system should track flight status and trigger automated alerts for delays, early arrivals, or terminal/gate changes. On top of this automation, the command center should guarantee specific response windows, such as a defined number of minutes to re-align pickup time after a delay, and a defined number of minutes to re-brief the chauffeur when a terminal changes. Missed pickups should be governed by an on-time performance SLO, a re-dispatch SLO, and a communication SLO that state exactly when an alternate cab must be assigned and when the passenger and travel desk must be informed.
Runbooks need to function like control-room SOPs rather than ad-hoc firefighting. For flight delays, the runbook should define thresholds for “minor” vs “major” delay, the actions for each, and who approves any cost-impacting decisions. For gate or terminal changes, the runbook should specify how the command center gets updates, how instructions reach chauffeurs, and what evidence is logged. For missed pickups, the runbook should encode root-cause capture, immediate recovery steps, and escalation paths so that the travel desk primarily receives status notifications, not tickets to solve manually.
Key elements that should be clearly documented and agreed include: - Time-bounded detection and response steps for flight status changes. - Standard communication templates to executives, chauffeurs, and the travel desk. - Escalation matrices linking the command center, local supervisors, and vendors. - Post-incident reporting with trip logs and GPS traces to protect the travel desk from blame.
These SLOs and runbooks reduce last-minute calls, move decision-making into the command center, and give the travel desk predictable, auditable handling of disruptions instead of case-by-case coordination.
For large events/projects, how do we set realistic reliability targets when everyone expects zero delays but ground reality makes perfection impossible?
B1523 Realistic SLOs for ECS peaks — In India project/event commute services (ECS) with time-bound, high-volume movement, how do you set an SRE-style reliability target when ‘zero tolerance for delays’ is the expectation but real-world traffic and venue constraints make perfection impossible?
In high-volume project or event commute services in India, reliability targets are best set as explicit SRE-style error budgets that translate “zero tolerance for delays” into quantified OTP thresholds, tight exception windows, and closure SLAs, rather than a literal 100% perfection goal. Organizations define an acceptable On-Time Performance band, cap the proportion and severity of allowable exceptions, and bind vendor payouts and escalation to those SLOs so that “near-zero” delay becomes operationally realistic yet still non-negotiable in governance.
For project / event commute services, demand is time-bound and high-stakes, so buyers expect zero visible failures even though real-world constraints like traffic, weather, and access bottlenecks exist. A common pattern is to define strict time windows for shift-aligned arrivals and departures, then measure reliability via OTP%, Trip Adherence Rate, and exception detection-to-closure time, using a dedicated project control desk or temporary command center for live coordination. When organizations centralize observability through NOC tooling and telematics, they can treat every deviation as an incident with a defined response playbook, instead of as an unstructured “delay.”
The trade-off is that tighter SLOs increase the need for buffers in routing, peak capacity, and standby fleet, which raises cost per trip but reduces execution risk. Most enterprises handle this by explicitly pricing resilience into the ECS commercial model through peak-load capacity buffers, rapid scale-up/down clauses, and outcome-based SLAs where payouts are indexed to OTP, safety, and service continuity. A practical reliability target therefore embeds: strict OTP thresholds for the critical windows, a small but explicit error budget for minor deviations, and hard SLAs for exception closure, all enforced through vendor governance and live project control rather than aspirational “100% on-time” promises.
What PIR cadence and attendee list actually works for commute ops so it drives improvement and doesn’t become a performative meeting?
B1524 PIR cadence that drives improvements — In India shift-based employee transport (EMS), what should a post-incident review cadence look like (daily/weekly/monthly), and who needs to attend, so continuous improvement happens without turning into performative meetings?
In India shift-based employee transport, post-incident reviews work best on three cadences. Daily reviews handle quick triage and immediate fixes. Weekly reviews look for patterns and process gaps. Monthly reviews focus on structural changes and governance. Each layer must have a clear scope, limited attendees, and pre-agreed data inputs so it does not become performative.
Daily reviews are control-room level. These should run as 15–20 minute stand-ups on every operating day. The transport lead or shift supervisor should chair them. Attendees should be operations dispatch, command-center analysts, and vendor shift leads. The focus should be on previous shift incidents, SLA breaches, SOS triggers, GPS or app failures, and immediate mitigations. A common failure mode is inviting HR or leadership into this forum, which turns it into a blame conversation instead of rapid stabilization.
Weekly reviews are operational improvement forums. These work well as 45–60 minute scheduled meetings anchored by the Facility or Transport Head. HR operations, vendor managers, safety or EHS representatives, and sometimes IT support for routing or app issues should attend. The purpose is to review recurring incident types, route adherence issues, driver fatigue flags, women-safety protocol breaches, and command-center alert quality. A common failure mode is mixing billing disputes and commercial escalations into this forum, which dilutes focus on safety and reliability improvements.
Monthly reviews are governance and strategy checkpoints. These should be formally chaired by HR or Admin leadership with Finance, Procurement, Security or EHS, IT, and vendor account leadership present. The monthly agenda should use consolidated data on on-time performance, incident rates, audit trail completeness, and employee feedback. The goal is to agree on policy changes, commercial levers, EV or ESG adjustments, and command-center or SOP upgrades. A common failure mode is turning this into a presentation-only meeting without clear action owners, timelines, or follow-through into the next month’s review.
A simple guardrail is to fix three things for each cadence. The first is a standard incident summary pack so the conversation is data-led, not anecdotal. The second is a clear decision scope so daily forums cannot re-open monthly decisions. The third is a tracked action log with owners and due dates so issues move from detection to closure rather than being re-discussed indefinitely.
How do we use error budgets to pause non-critical changes when reliability drops, without getting stuck in politics or finger-pointing?
B1525 Using error budgets to pause change — In India corporate employee mobility (EMS), how do you design error-budget policies so teams can safely pause non-critical changes (new routing rules, vendor onboarding) when reliability is suffering, without politics derailing the decision?
Error-budget policies in Indian EMS work best when they are treated as hard, pre-agreed operating rules tied to On‑Time Performance and incident KPIs, and not as ad‑hoc judgments. The core idea is simple. When reliability or safety drops below a defined threshold, all non‑critical changes pause automatically until the numbers recover, and this rule is owned by the command center and transport leadership, not by any single vendor or function.
To keep politics out, the error budget needs a clear, written construct. The transport team and command center should define 2–3 measurable guardrails such as OTP%, Trip Adherence Rate, and safety/incident rate. These metrics need a weekly and monthly target and an agreed “floor.” When performance hits that floor, the EMS team invokes a documented “stability mode.” In stability mode, only actions that directly improve reliability, safety, or compliance are allowed. Examples include driver and fleet substitution, route recalibration to handle monsoon traffic, and configuration fixes in the EMS platform.
Non‑critical work is clearly tagged in advance. Examples include introducing new routing rules, onboarding a new vendor, piloting EVs on sensitive night routes, or changing billing or commercial constructs. The EMS operating model should place these items behind a change‑advisory gate controlled by a joint group from Transport, HR, Security, and IT. This group should meet on a fixed cadence and have authority to classify changes and to declare stability mode based purely on KPIs that are already visible on the command‑center dashboards.
A practical way to keep decisions depersonalized is to tie error‑budget consumption to a single, shared view in the command center. The Transport Command Centre and alert supervision system already generate live OTP, exception, and safety alerts. The same dashboards can show “reliability health” against thresholds. When the health score crosses the threshold, the system raises a ticket and sends notifications to HR, Security, and Procurement. The trigger and the response are both automated and documented, which reduces scope for last‑minute lobbying.
Error‑budget policies become credible when they map to SOPs and escalation matrices. The MSP governance structure and micro‑functioning of the command centre already define roles for centralized and location‑specific teams. The same governance can assign who is allowed to override stability mode, under what conditions, and how that override is logged. Any override should require at least two independent approvals, for example from the Facility/Transport Head and Security/EHS lead, and should create an auditable record for later review.
To prevent long freezes that hurt improvement, stability mode should be time‑bounded and recovery‑oriented. The SOP should specify a minimum observation window and exit criteria. For example, stability mode stays in effect until OTP is above the floor for two consecutive weeks and no major safety incidents occur. During stability mode, the transport team focuses on route optimization for current loads, driver fatigue management, and vendor performance audits, using data‑driven insights from the mobility dashboards and management reports.
Error‑budget design also needs explicit alignment with commercial and vendor governance. Vendors should know in advance that when error budgets are exhausted, new route experiments, EV pilots, or additional cities will be temporarily paused. The challenges–solution–outcome matrices, vendor and statutory compliance framework, and cost‑reduction processes can reference error‑budget triggers as recognized reasons for deferring scope expansions without penalty disputes. This approach protects Procurement from accusations of favoritism when projects are delayed.
From an on‑ground control‑room perspective, error‑budget policies must be framed as SOPs, not as “management calls.” The alert supervision system and transport command centre can define a short runbook for agents. When reliability scores drop, agents follow a script. They freeze roster or routing configuration changes beyond a defined window. They escalate any demand for exceptions through the formal escalation matrix. This gives night‑shift teams cover and reduces pressure to accept risky changes under informal instructions.
In India’s regulatory context, error budgets should be aligned with safety and compliance obligations. Security and EHS leads remain personally accountable for HSSE and women‑safety outcomes. The safety and compliance diagrams, driver and fleet compliance frameworks, and women‑centric safety protocols already emphasize zero‑incident goals. Error‑budget floors can be set more conservatively for night‑shift or women‑only routes, with any breach automatically forcing stability mode. This design places legal and reputational protection above experimentation.
Finally, politics diminishes when every stakeholder sees benefits aligned to their priorities. HR can see that error budgets reduce safety incidents and employee complaints. Finance can see that stability mode prevents cost escalations from emergency fixes and SLA penalties. Procurement is protected by clear, documented criteria for when projects pause. The Facility and Transport Head gains operational calm because non‑essential change stops the moment reliability dips, instead of after another bad week. Over time, error‑budget reviews can become part of quarterly governance and command‑center performance reports, turning them from a contentious tool into a standard feature of EMS operational excellence.
images:
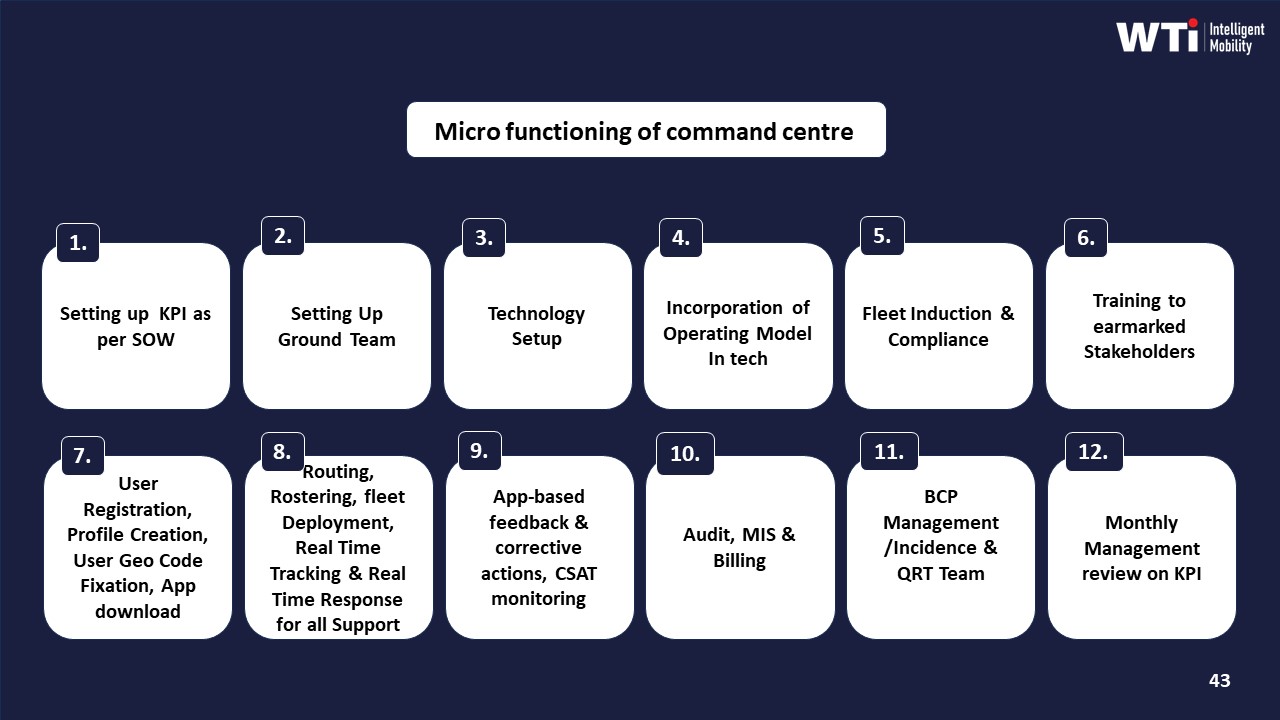
How can we align vendor penalties/credits with error budgets so Procurement has enforceability but vendors don’t start hiding incidents?
B1526 Penalties aligned to error budgets — In India enterprise-managed commute operations (EMS), what’s the best way to align vendor penalties/credits with SRE concepts like error budgets, so Procurement gets enforceability without encouraging vendors to hide incidents?
In India enterprise-managed employee mobility services, the most effective way to align vendor penalties and credits with SRE-style error budgets is to contract on transparent, shared reliability targets and exception-closure quality instead of raw incident counts or opaque uptime numbers. Procurement gets enforceable SLAs by anchoring payouts to clearly defined On-Time Performance and exception-closure KPIs, while vendors are rewarded for surfacing and resolving issues quickly rather than suppressing them.
A practical pattern is to treat OTP% and exception latency as the “SRE SLOs” for EMS. The contract then defines an allowed “error budget” for lateness and service deviations per period. The vendor is not penalized for every breach inside that budget. The vendor is instead penalized when the aggregated error budget is exhausted, or when incident closure quality does not meet agreed standards. This discourages under-reporting and encourages early flagging of risks through the command center.
To avoid incident hiding, incident detection and logging should sit in a centralized command-center environment that is visible to both client and vendor. Real-time tracking, alert supervision systems, and CO₂ / ESG dashboards in the existing collateral show how telemetry can be centralized and made auditable. A command-center model with shared dashboards and audit trails turns exceptions into shared data, not vendor-owned narratives.
Procurement can structure commercials so that a portion of spend is fixed and a smaller portion is variable against outcome KPIs such as OTP%, Trip Adherence Rate, and complaint-closure SLA. Positive credits can be tied to stretch performance or demonstrable cost savings like reduced idle time or higher fleet uptime, as shown in the EV and efficiency case studies. Penalties can apply only when both the error budget is exceeded and evidence shows avoidable operational lapses, aligning incentives with continuous improvement rather than concealment.
images:
For commute incidents, what’s the minimum ‘done’ checklist so tickets aren’t closed without real resolution—like comms, RCA, and corrective actions?
B1527 Definition of done for incidents — In India corporate ground transport (EMS), what should be the minimum ‘definition of done’ for an incident—e.g., employee communication completed, RCA documented, corrective action assigned—so closures are real and not just ticket status changes?
In Indian corporate employee mobility services, an incident is only “done” when the facts are reconstructed, impact on people is addressed, and a verifiable prevention step is in place with an owner and a timeline. A common failure mode is treating closure as a ticket status change instead of a documented lifecycle that links detection, response, communication, root cause, and prevention into one audit-ready record.
A robust minimum definition of done needs to cover five checkpoints. The incident log must be complete and time-stamped. The record should capture trip details, GPS or IVMS data if available, driver and vehicle identity, and all escalation steps, because incomplete logs break future audits and weaken HSSE credibility. The immediate response must be confirmed, including contact with the affected employee, any medical or security support, and safe completion of the trip or alternative arrangements, since duty-of-care failures quickly escalate to CHRO and Security.
Human communication must be closed on two levels. The directly impacted employee should receive a clear closure update, and HR or Transport should update internal stakeholders where required, because silent closures drive distrust and repeat escalations. A basic root-cause analysis and corrective action must be documented in the same system. Each action should have a named owner, due date, and link to controls such as driver retraining, routing changes, or compliance checks.
Finally, the incident should be visible to governance. The case must appear in periodic HSSE or command-center reviews with metrics such as incident rate and closure SLA, because unreviewed incidents tend to repeat. Without these five elements, organizations risk reactive firefighting, weak compliance, and inability to defend safety performance during audits.
How do we use reliability dashboards without it feeling like surveillance to drivers or employees, but still give leaders enough visibility to manage risks?
B1528 Visibility without surveillance backlash — In India employee mobility services (EMS), how do you prevent SRE dashboards from becoming ‘Big Brother’ tools that damage driver and employee trust, while still giving leadership enough visibility to act on safety and reliability risks?
In India EMS, SRE-style dashboards avoid becoming “Big Brother” when they are explicitly designed as risk and reliability instruments, not as people-surveillance tools, with tight scoping, governance, and communication. Leadership still gets strong visibility on OTP, safety and compliance risks when the platform focuses on trip-level and pattern-level signals, with controlled access to individual-level detail only under defined SOPs and audits.
Dashboards that try to expose granular, person-identifiable data to too many stakeholders quickly erode trust. A common failure mode is surfacing real-time location and personal histories of specific employees or drivers to non-critical users. This creates a perception of continuous monitoring and can trigger resistance from both drivers and employees, especially in night-shift and women-safety contexts. A better practice is role-based views that limit who can see live location, trip manifests, or incident trails, anchored in the actual duties of Transport, Security/EHS, and Command Center teams.
Trust increases when organizations are transparent about what is monitored, why it is monitored, and how long the data is retained. Driver and employee communication that links telemetry explicitly to on-time performance, safety outcomes, and compliance with transport rules reduces anxiety about hidden agendas. When dashboards aggregate data into KPIs like OTP%, incident rates, seat fill, and route adherence scores for routine reviews, and reserve identity-level drill-down for defined incident investigations, leadership still gets actionable insight without normalizing surveillance.
To maintain balance, SRE dashboards should embed clear governance: documented access rights, audit logs of who viewed what, and SOPs for how alerts (e.g., geofence violations, overspeeding, SOS triggers) are triaged and closed. This shifts the narrative from “we are watching people” to “we are watching the network and routes for failures,” while still enabling root-cause analysis and continuous improvement on safety, reliability, and compliance.
How can we quantify the business cost of unreliable commute ops—late logins, overtime, escalations—so we can justify an SRE-style program?
B1529 Business case for reliability investment — In India corporate employee commute operations (EMS), what’s a practical way to quantify the ‘cost of unreliability’ (late logins, overtime, escalations) so an SRE program has a business case beyond ‘we want fewer fires’?
In Indian corporate employee commute operations, the “cost of unreliability” is best quantified as a simple, recurring rupee value per month that links late or missed trips to lost productivity, overtime, and escalation handling effort. The most practical pattern is to define a small set of measurable unreliability events, attach realistic unit costs to each, and roll them into a monthly “Unreliable Commute Cost” (UCC) that can sit next to CET/CPK and OTP% in dashboards and reviews.
A useful approach starts by treating commute as an SLA-bound service. Each breach then becomes a priced incident rather than vague “noise.” Most organizations already track basic EMS trip data, shift adherence, and HR attendance, so the inputs for this model usually exist even if they are not yet combined. An SRE-style program can then focus on reducing the volume and severity of these incident types, not just OTAs in the abstract.
A practical first-cut model can be built around four event buckets:
- Late arrivals impacting production or service SLAs. Count trips where pickup delay or route deviation pushes employees beyond an agreed grace window for login. Convert to cost using a standard “cost per productive hour” for the affected roles, multiplied by minutes lost.
- Overtime and extended shifts caused by missed relief. When a replacement shift arrives late, the on-duty staff must stay back. Quantify this as overtime cost (including statutory components) plus any fatigue-related productivity factor if the extended duty happens frequently in certain sites or timebands.
- Operational firefighting and escalations. Track high-severity transport escalations per week (e.g., night-shift disruption, missed critical shift, vendor no-show). Apply a standard cost per escalation that bundles:
- Ops and Transport team time at their fully loaded cost.
- Manager time spent on calls and internal coordination.
- Any explicit compensations (cab reimbursements, spot incentives, exception transport).
- Attrition and disengagement signals linked to commute failures. Use HR’s attendance and exit-interview data to define a “commute-linked churn” estimate, even if conservative. Assign a standard replacement cost per employee (recruitment plus onboarding), and attribute a small, defensible fraction of that to commute unreliability where commute issues are explicitly cited.
With these buckets, Transport and HR can express a simple formula such as:
Unreliable Commute Cost (monthly) = Cost of late-logins + Cost of overtime + Cost of escalations + Commute-linked churn cost
Two implementation details keep this credible and usable for an SRE-style program:
- Use conservative, transparent assumptions. Document all unit-cost assumptions and, where uncertain, choose lower bounds. This reduces pushback from Finance and increases trust in the directionality of the number, even if it is a proxy.
- Anchor to the existing KPI stack. Map each cost bucket to KPIs already understood in EMS governance, such as OTP%, Trip Adherence Rate, exception closure time, no-show rate, and Commute Experience Index. The SRE backlog can then prioritize work that clearly drives down a rupee-denominated UCC alongside service reliability metrics.
Once this baseline exists for 2–3 months, an SRE program can justify investments in routing improvements, better command-center observability, EV uptime enhancements, business continuity playbooks, or driver fatigue management by projecting potential reduction in UCC, not just “fewer fires.”
After PIRs, who should own the improvement backlog, how do we prioritize it, and how do we stop repeat issues from coming back?
B1530 Owning the reliability improvement backlog — In India enterprise employee mobility (EMS), what governance model works best for continuous improvement actions from post-incident reviews—who owns the backlog, how is priority decided, and how do you stop the same issues recurring?
In India enterprise employee mobility, continuous improvement from post‑incident reviews works best when it is owned by a cross‑functional mobility governance structure with a clear “command center + steering” model. The command center owns the operational backlog and closure, while a mobility governance board sets priorities, approves design changes, and tracks whether repeat issues actually disappear from metrics and audit logs.
A practical pattern is to anchor day‑to‑day ownership in the 24x7 command center or transport desk. The command center consolidates incidents across EMS, vendors, and sites into a single queue. The command center maps each incident to a standardized category such as safety, reliability, compliance, or experience. The command center then opens actions against the appropriate owner such as vendor, routing, driver training, or app/IT.
Backlog governance typically sits with a mobility governance board or equivalent committee. HR, Transport, Security/EHS, Procurement, Finance, IT, and ESG are represented on this board. HR usually owns policy and employee communication. Transport owns SOPs, routing and vendor enforcement. Security/EHS owns safety controls and investigations. IT owns platform changes and data. Procurement owns contract levers and penalties. Finance and ESG validate cost and carbon implications of changes.
Priority is normally decided using a small set of explicit lenses. Safety and legal compliance issues are treated as “stop‑everything” items. Systemic reliability problems that threaten OTP, shift adherence, or business continuity are next. Cost and ESG improvements are slotted after safety and reliability, but still tracked to closure. This avoids the failure mode where cosmetic improvements are delivered while core risks remain.
To stop the same issues recurring, most mature organizations couple post‑incident reviews with changes to both design and evidence. A change is only considered closed when there is a modified SOP or rule, a corresponding control embedded into routing, apps, or command‑center tooling, and a metric and audit trail that can prove the new control is working over time. Safety‑related changes are often tied to women‑safety protocols, driver KYC/PSV cadence, route approvals, and escort rules. Reliability‑related changes are usually tied to OTP%, Trip Adherence Rate, and exception‑closure SLA.
The most effective governance models treat each serious incident as a trigger for three parallel tracks. There is an immediate containment track to protect current riders and upcoming shifts. There is a root‑cause and design track to modify policies, routing rules, training, or vendor allocation. There is a monitoring track to audit the affected routes, drivers, or vendors for a defined stability window. Many organizations formalize this into a periodic mobility governance review that looks explicitly at repeat‑incident patterns and converts them into structural backlog items.
Useful signals that the model is working include: falling repeat‑incident rate by category, improving audit trail integrity, faster exception detection and closure, and less variance in OTP across sites or vendors. A common failure mode is when incident reviews remain narrative and email‑based. In that pattern, actions are agreed verbally but not codified into the routing engine, driver app stack, vendor governance framework, or compliance dashboards. Another failure mode is when backlog ownership is distributed informally between HR, Transport, and vendors. This often leads to gaps and blame‑shifting.
Organizations that avoid recurrence problems usually invest in a few specific guardrails. They maintain a single incident ledger at command‑center level with unique IDs, links to trip logs and GPS, and status fields. They define a small, fixed taxonomy for incident causes to allow pattern detection. They tie vendor scorecards and penalties to incident categories and repeat counts. They require that any “closed” incident that reappears in the same route, time band, driver, or vendor automatically escalates to a higher governance tier.
In practice, continuous improvement is sustainable only when it uses mobility data as a first‑class input. Streaming telematics, HRMS‑linked rosters, and unified dashboards allow the command center and governance board to test whether a fix has actually changed OTP, dead mileage, seat‑fill, or incident rate. Without that observability layer, post‑incident reviews tend to re‑discover the same problems without ever exhausting them.
Overall, the governance model that works best in India EMS is one where operational control is centralized, but accountability for improvement is distributed across a formal multi‑stakeholder board. The board owns the change backlog and its prioritization. The command center owns incident intake, categorization, and execution tracking. Vendors are treated as governed partners with explicit, outcome‑linked SLAs. Repeat issues are squeezed out not by one‑time reviews, but by embedding each lesson into routing logic, safety protocols, compliance automation, and vendor governance so that the system itself makes the same failure harder to repeat.
If we have multiple mobility vendors, how do we run PIRs that are fair but still lead to real corrective actions—not vendor blaming and disputes?
B1531 Multi-vendor PIRs without disputes — In India corporate mobility operations (EMS/CRD), when multiple mobility vendors are involved, how do you run post-incident reviews that are fair across vendors and still drive corrective actions rather than finger-pointing and contract disputes?
In multi-vendor Indian corporate mobility programs, post-incident reviews stay fair and effective when organizations standardize evidence, KPIs, and SOPs across all vendors and run reviews through a neutral command-center governance process rather than bilateral blame discussions with individual vendors. Fairness comes from using the same data sources, metrics, and investigation steps for every incident, while effectiveness comes from converting each incident into specific corrective actions, time-bound owners, and auditable follow-through.
A common failure mode is incident meetings that rely on conflicting narratives from drivers, employees, and different vendors. A better pattern is to anchor every review on one unified trip record that includes GPS/telmatics logs, app events, SOS alerts, and call-center tickets from all parties. Centralized command center tooling, alert supervision systems, and unified dashboards make this possible because they track trip lifecycle data independently of any single vendor’s version of events.
Another frequent problem is vendors being judged on subjective impressions instead of defined service KPIs such as on-time performance percentages, incident rates, or route adherence scores. Most organizations get better outcomes when they define a shared SLA and KPI library at contracting stage and then use the same indicators for all vendors during post-incident analysis. This also makes it easier for Procurement and Finance to link incident patterns to penalties, incentives, or route reallocations without renegotiating terms each time.
To keep reviews corrective rather than adversarial, many operators use a command-center led playbook that separates “fact-finding” from “commercial consequences.” In practice, the Transport or Facility Head, with Security/EHS and HR, first runs a neutral root-cause analysis using command center data, driver compliance records, and fleet compliance logs. Only after causes are agreed in writing are actions triggered, such as driver retraining, routing changes, or EV/ICE fleet rebalancing for specific shifts or corridors.
A structured model for multi-vendor post-incident reviews usually includes: - A single, enterprise-owned incident log and trip ledger that sits above all vendors. - Standardized safety and compliance requirements for drivers, vehicles, and women-safety protocols that apply equally to all. - A predefined escalation matrix and business continuity playbooks so every vendor knows in advance how incidents will be handled. - Periodic governance forums (for example, monthly or quarterly reviews) where incident trends and corrective-action completion are examined across vendors, not just case by case.
This command-center and governance approach reduces subjective finger-pointing because every vendor is evaluated on the same data and SLA framework. It also strengthens the position of HR, Security/EHS, and the Facility Head, since they can show leadership that incidents are being managed through a predictable, audit-ready process rather than reactive dispute cycles.
images:

If the rider app or GPS tracking goes down, what should our runbooks say so we can keep service running without compromising safety?
B1532 Runbooks for app/GPS failure mode — In India corporate employee transport (EMS), what ‘graceful degradation’ expectations should exist in runbooks when the rider app or GPS tracking fails—so operations can keep service running without losing safety controls?
In Indian corporate employee transport, graceful degradation runbooks should assume that rider apps and GPS will fail sometimes, but shift operations and safety controls must continue using pre-agreed manual fallbacks that are auditable, time-bounded, and reversible back to normal once systems recover.
Most operations teams need an explicit “app/GPS down” mode in the EMS runbook. This mode should rely on pre-published rosters and manifests, driver app alternatives, and command-center support instead of live tracking. Safety controls like women-safety routing, escort rules, and SOS handling should switch from app-based automation to phone-based verification, call-center tracking, and paper or SMS duty slips. A common failure mode is ad-hoc improvisation by night-shift staff, which erodes both OTP% and auditability.
Graceful degradation expectations should cover at least four dimensions. For reliability, there should be defined SOPs for moving from dynamic routing to static pre-approved routes and from auto-dispatch to phone-based dispatch. For safety and compliance, there should be backup mechanisms for trip verification OTP, geofencing, and women-centric protocols that still generate an incident log usable in audits. For governance, the central command center or NOC should capture manual overrides, escalations, and exceptions into a single-window dashboard once systems come back online. For communication, HR, security, and employees should receive clear, time-bound advisories so trust is maintained even when GPS or apps are partially blind.
After an incident, what should we share with leadership versus keep within Ops so we build trust without creating panic or reputational overreaction?
B1533 Leadership reporting boundaries after incidents — In India employee mobility services (EMS), what post-incident review outputs should be shared with senior leadership versus kept within operations, to build trust and support without triggering panic or reputational overreaction?
In India employee mobility services, post-incident reviews should give senior leadership concise facts, root causes, and high-level corrective actions, while keeping granular logs, personnel-level detail, and raw operational debate within Transport, HR, Security, and the command center. This separation protects auditability and accountability but avoids unnecessary panic, blame spirals, or reputational overreaction.
For senior leadership, most organizations benefit from a standard, brief “executive incident pack.” This usually includes a factual incident summary, severity classification, immediate response taken, confirmed impact on employees or operations, the validated root cause, and a short list of corrective and preventive actions with owners and timelines. It often also highlights whether existing safety, compliance, and business continuity controls worked as designed or were breached, connecting back to duty-of-care, legal exposure, and ESG or women-safety commitments rather than operational minutiae. Over time, aggregated trend views (incident rates, closure SLAs, repeat-category reduction) are more useful at this level than single-event technical detail.
Within operations, teams typically retain the full trip ledger and command-center data, including GPS traces, IVMS feeds, SOS alert timelines, route adherence checks, driver and escort duty cycles, and raw call-center or app transcripts. Internal post-mortems often document detailed “what-if” analyses, fatigue or behavior assessments, routing-edge cases, vendor performance deviations, and specific disciplinary or contractual actions. Keeping this depth inside the EMS governance layer allows frank diagnosis and continuous improvement on routing algorithms, vendor tiering, driver management, and BCP playbooks without turning every operational correction into a leadership or board-level crisis.
A practical pattern is to define clear information tiers:
- Tier 1 (Leadership view): severity score, brief narrative, impact, legal or policy risk, high-level RCA category, and status of fixes.
- Tier 2 (Control-room / HR / Security view): time-stamped sequence of events, system behavior, human decisions, and compliance checks against SOPs.
- Tier 3 (Forensics / audit view): immutable raw data, detailed logs, and evidence packs kept ready for regulators, internal audit, or investigations.
This tiering helps Facility and Transport Heads maintain operational calm and systematic learning, while giving CHRO, CFO, ESG, and Security leaders enough visibility to defend decisions, uphold duty-of-care, and support investment in better EMS controls without being forced into reactive public responses after every non-critical event.
How do we train coordinators to actually follow runbooks during high-pressure shifts, instead of depending on tribal knowledge that walks out with people?
B1534 Runbook adoption for frontline coordinators — In India shift-based EMS operations, how do you coach frontline transport coordinators to follow runbooks under pressure, instead of relying on tribal knowledge that disappears when experienced staff leave?
In Indian shift-based EMS operations, organizations keep frontline coordinators using runbooks under pressure by turning runbooks into the default control-room “system” and wiring SOP use into tools, reviews, and incentives. Runbooks work when they drive every decision in the NOC, show up in the transport app and command center screens, and are reinforced by daily briefings, alert workflows, and audit checks, not when they sit in a folder.
Coordinators follow runbooks more reliably when each critical scenario has a short, visual, stepwise playbook. Each step needs a clear trigger, timeframe, and owner. Command center micro-functioning, escalation matrices, alert supervision systems, and business continuity plans all become training material. These are converted into simple checklists for late pickups, GPS failure, vehicle no-show, driver absence, and women-safety escalations so coordinators do not have to “remember” what a senior did last year.
A common failure mode is keeping SOPs on paper while coordinators improvise in the system. Organizations avoid this by baking SOP logic into routing tools, the ETS operation cycle, alert dashboards, and the transport command centre. Exception screens can force a choice of “playbook” and record actions taken. Daily shift-wise briefings are then used to walk through previous-shift incidents using the same runbooks, so coaching happens against real cases.
Transport heads reinforce this with three simple mechanisms:
- Use post-shift reviews to ask “Which SOP did you follow?” for each deviation.
- Link coordinator KPIs to OTP, escalation compliance, and closure within defined SLAs.
- Run periodic drills using BCP scenarios, so coordinators practice runbooks before the real 2 a.m. calls.
Over time, this shifts knowledge from individuals into the command center process, so new staff can step in without the operation collapsing when experienced coordinators move on.
If we want to roll out SRE practices, what should a 30/60/90-day plan include so people see stability improvements fast?
B1535 30/60/90-day SRE rollout plan — In India corporate employee commute programs (EMS), what should a 30/60/90-day rollout plan for SRE practices include—baseline SLOs, initial runbooks, PIR rhythm—so stakeholders see stability improvements quickly?
In corporate employee commute programs in India, a 30/60/90‑day SRE rollout should focus on a small, critical set of SLOs, a thin but reliable runbook library for peak shifts, and a predictable incident and PIR cadence. SRE practices should show visibly fewer escalations for HR and Transport within the first 30–60 days and generate audit-ready evidence for Finance, Security, and ESG over 90 days.
30 DAYS – BASELINE & “STOP THE BLEEDING”
In the first 30 days, SRE work should define what “good” looks like for EMS in operational terms and stabilize the worst pain points.
- Define a minimal SLO set for EMS. At least: OTP% for shift start and end windows, platform uptime for rider and driver apps, and command-center alert response time.
- Baseline current performance using existing dashboards, duty slips, and incident logs. Capture OTP by shift band, city, and vendor; app/API uptime; SOS alert latency.
- Identify top 3–5 “burning” failure modes. Examples include missed pickups at shift start, app login failures at roster cut-off time, GPS drops near key campuses, and repeated vendor no-shows on night shifts.
- Create initial runbooks for these critical scenarios. Each runbook should define detection signal, first actions in the command center, escalation path, communication template to employees and HR, and closure criteria.
- Stand up a simple incident classification and logging standard. Tag all issues by severity, root cause bucket, shift band, vendor, and impact on OTP or safety.
- Start a weekly incident review rhythm with Transport, HR operations, and vendors. Focus review on trend visibility and quick wins, not blame.
60 DAYS – RELIABILITY MUSCLE & CONTROL-ROOM CALM
In the next 30 days, SRE work should deepen observability, expand runbooks, and introduce predictable PIRs.
- Refine SLOs and define error budgets. For example, define acceptable OTP miss percentage per month, app downtime minutes per week, and maximum allowed SOS escalation delay.
- Instrument key SLI dashboards for command-center use. Focus on shift-window OTP, routing engine health, vendor-wise failure rates, and SOS/incident queues.
- Expand runbook coverage to 10–15 recurring scenarios. Include dynamic route recalibration during weather events, driver no-show handling, partial app outages, high no-show routes, and EV range or charging exceptions if applicable.
- Formalize PIR cadence. Run a structured PIR for every Sev‑1 or Sev‑2 incident that affects safety, large groups of employees, or shift-start adherence. Require a standard PIR template and 7–10 day closure checks for actions.
- Introduce early-warning alerts for the command center. Trigger alerts on pre‑shift risk indicators such as high driver fatigue patterns, known protest or weather events, or routing engine degradation.
- Share a fortnightly reliability summary with HR, Transport, and Security. Report OTP trend, incident counts, closure times, and emerging risks in two to three pages.
90 DAYS – GOVERNED SRE & AUDIT-READY OPERATIONS
By 90 days, SRE practices should be embedded into EMS governance, with clear links to SLAs, vendor management, and audits.
- Lock SLOs into EMS SLAs and vendor scorecards. Tie a portion of payouts or penalties to OTP, response time, and incident-closure SLOs.
- Stabilize the runbook library and assign ownership. Ensure each major EMS failure mode has a named operational owner and review cycle.
- Institutionalize a monthly cross-functional PIR and improvement forum. Include HR, Finance, Security, IT, and Transport in one review, focusing on trends and systemic fixes.
- Integrate SRE metrics into management reports. Include SLO attainment, error budget consumption, top incident causes, and time-to-detect/time-to-recover in standard dashboards.
- Align SRE telemetry with ESG and safety reporting where relevant. Use OTP, dead mileage, EV utilization, and incident rates as inputs into ESG mobility reports and safety audits.
- Document a minimal SRE playbook for EMS. Cover SLO structure, incident severity model, runbook index, PIR process, and governance cadence so practices survive personnel changes.
After we put SLOs and runbooks in place, what early signals should we track to know night escalations will drop within a month?
B1536 Leading indicators of fewer escalations — In India corporate ground transportation for employees (EMS), after implementing SRE-style SLOs and runbooks, what leading indicators should a Facility/Transport Head look for to confirm the team will actually get fewer night escalations within a month?
The strongest leading indicators for fewer night escalations are earlier, cleaner signals in OTP, exception latency, and command-center workload before complaints spike. A Facility/Transport Head should track whether issues are being detected, triaged, and closed faster in the NOC than they are being reported by employees or HR.
First, incident handling must move “left” into the command center. A reliable sign is that geofence, over-speeding, GPS tamper, and SOS alerts from tools like an Alert Supervision System are rising in count but dropping in open duration. Another is that more trips are being corrected mid-route by the command center before they become HR or leadership escalations. This pattern shows SLOs and runbooks are being used as an operational guardrail, not just as documentation.
Second, service stability at night should become measurable. The Facility/Transport Head should see OTP% for night shifts stabilizing above the agreed SLO, with fewer extreme outliers. Exception detection-to-closure time should reduce, especially for high-severity cases like no-show drivers, app downtime, or routing failures. Night-shift route adherence and Trip Adherence Rate should improve because issues are resolved from the command center before they cascade.
Third, operational noise should change shape in the first month. The night command desk should log more internally resolved tickets and fewer HR- or employee-initiated escalations. Driver fatigue and roster exceptions should be visible earlier in the shift cycle, which suggests runbooks are triggering pre-emptive actions like backup vehicle dispatches or rerouting. When SRE-style SLOs and runbooks work in EMS, escalation volume does not disappear immediately. It first shifts from uncontrolled, late-night calls into predictable, early, and shorter-lived alerts owned by the transport team itself.
When HR wants stricter safety targets, Finance wants lower cost, and Ops says vendors can’t meet both, what compromise framework actually works?
B1537 Resolving HR-Finance-Ops SLO conflicts — In India employee mobility services (EMS), how do you handle the politics when HR wants stricter safety SLOs, Finance wants lower cost, and Operations claims the vendor ecosystem can’t meet both—what’s a workable compromise framework?
In Indian employee mobility services, a workable compromise comes from making safety, cost, and operational feasibility all explicit in one governed framework, then tying money and measurement to a small, shared set of KPIs instead of letting each function negotiate in isolation.
A common failure mode is that HR hardens women-safety and night-shift rules on paper, Finance pushes for lowest cost per km, and Operations continues to run a fragmented vendor mix that cannot meet either reliably. This creates constant firefighting, weak audit trails, and blame-shifting after incidents. A more stable pattern is to define one “enterprise mobility contract” where safety SLOs, cost envelopes, and operational realities are jointly specified and traded off up front.
A pragmatic compromise usually has four elements: 1. HR, Finance, and Transport agree core KPIs first. Typical set includes On-Time Performance %, Trip Adherence Rate, incident rate, and cost per employee trip. Safety SLOs then live as measurable thresholds on incident rate, escort compliance, route adherence, and audit trail completeness instead of vague “maximum safety” language. 2. Finance agrees a clear cost band, not a single number. The contract defines a base CET/CPK for standard shifts and codifies explicit premiums for high-risk bands like night shifts, low-density routes, or mandatory escorts. This protects HR’s safety posture without pretending that all trips cost the same. 3. Operations helps design service tiers and fleet mix that are actually deliverable. For example, a base tier for high-density routes using pooled shuttles, and a higher-control tier for sensitive or low-density routes, possibly with more EVs or dedicated vehicles. This accepts that not every lane gets the same unit economics, but the portfolio does. 4. Procurement encodes this into outcome-linked commercials. Payouts are indexed to OTP, safety incidents, and seat-fill, with transparent penalties and incentives. This rewards vendors that hit safety and reliability while exposing the true cost when they do not. It also gives Finance a defensible ROI story and HR auditable evidence.
When this framework is used, HR gets enforceable duty-of-care with audit-ready logs. Finance gets predictable bands and clear linkage between SLOs and spend. Operations gets realistic SLAs built around actual vendor capacity, instead of inherited promises that only exist in RFP decks.
When root causes are split between our internal policies and vendor execution, how do we make PIRs lead to structural fixes instead of repeating the same issues?
B1538 Making PIRs produce structural fixes — In India corporate employee transport (EMS), what’s a realistic approach to ‘continuous improvement’ when the root causes are split between internal policy (shift changes, approvals) and vendor execution—how do you avoid PIRs becoming repetitive with no structural fixes?
Continuous improvement in Indian EMS works only when enterprises separate signal from noise and hard‑wire fixes into both internal policy and vendor operations through a single, governed loop. Continuous improvement fails when post‑incident reviews stay anecdotal, when ownership is unclear across HR, Transport, Procurement, and vendors, and when actions are not tied to measurable EMS KPIs like OTP, incident rate, and seat‑fill.
A practical approach is to treat every PIR as input into a standing “mobility improvement loop” instead of a one‑off investigation. Transport and HR teams can route PIR findings into three distinct buckets. One bucket is internal policy changes such as shift windowing, approval cut‑off times, and escort rules. The second bucket is vendor execution controls such as routing logic, driver allocation, and command‑center alerting. The third bucket is data and system gaps such as HRMS–transport integration, roster accuracy, and GPS or app stability.
Most organizations need a centralized command‑center or NOC view over EMS to make this work. That command function can correlate PIRs with operational data like OTP%, no‑show rates, and route adherence, and can distinguish one‑off anomalies from recurring patterns. This reduces blame games between internal teams and vendors because root causes are grounded in trip logs, alerts, and audit trails rather than perceptions.
To stop PIRs from becoming repetitive, enterprises typically formalize a cadence and threshold‑based governance. A monthly or quarterly mobility review across HR, Transport, Procurement, Security, and the vendor compares PIR themes with KPIs and defines only a few structural changes per cycle. Those changes might include adjusting contract SLAs and penalties, tightening driver or fleet compliance, updating routing rules for monsoon or election periods, or revising employee booking rules.
Three concrete guardrails help keep the loop productive rather than cyclical and reactive:
• Standardize PIR templates so every incident captures the same minimum data fields and can be aggregated.
• Map every accepted action to a specific KPI shift and review that shift in the next governance meeting.
• Limit “quick fixes” that rely on manual heroics and instead prioritize changes in SOPs, routing logic, or contract terms that permanently reduce similar incidents.
In an RFP, what should we ask to validate a vendor’s SRE maturity—real runbooks, incident metrics, PIR examples—beyond demos?
B1539 RFP questions to validate SRE maturity — In India enterprise-managed mobility (EMS/CRD), what questions should Procurement ask in an RFP to verify a vendor’s SRE maturity—real runbooks, incident metrics history, PIR examples—without relying on polished demos?
Procurement teams should translate “SRE maturity” into verifiable artefacts, past behaviour, and hard numbers. The RFP should ask for specific documents, logs, and examples, and should force vendors to expose how they behave during outages, not just when systems are green.
Below are targeted question areas and example asks that fit EMS/CRD reality in India.
1) Production reliability baselines
• “Share your last 12 months of uptime and incident metrics for EMS/CRD deployments in India. Provide raw monthly figures for application uptime, API uptime, average response time, and major incident count.”
• “Define your current SLOs (availability, latency) for rider app, driver app, routing engine, and NOC dashboards. Attach the SLO document you share with existing enterprise clients.”
2) Incident history & PIR evidence
• “List the five most significant production incidents in the last 18–24 months affecting routing, GPS, rostering, billing, or safety features in EMS/CRD.”
• For each incident, request a redacted Post‑Incident Review: timeline, root cause, blast radius, MTTD/MTTR, temporary workaround, and permanent fix.
• “Explain one incident that occurred during India night shifts or peak commute windows and how you maintained OTP and safety compliance during the outage.”
3) Runbooks and on-ground SOPs
• “Submit 2–3 sample runbooks used by your NOC/command center, covering:
– App unavailability or degraded login
– GPS or telematics failures at city or tower level
– Routing engine degradation affecting shift rosters.”
• “For each runbook, indicate: detection method, first-line actions, escalation path, communication with client transport desk, and criteria for declaring incident closure.”
4) Alerting, monitoring, and NOC operations
• “Describe your monitoring stack for EMS/CRD: what is instrumented (apps, APIs, routing, GPS integrations, HRMS/ERP connectors) and what alerts are generated.”
• “Provide your current alert taxonomy and escalation matrix used in your 24x7 command center, including time targets for acknowledgment and resolution at each level.”
• “Share anonymised weekly or monthly incident/alert reports from an existing Indian enterprise client, including ticket volumes, severities, and closure performance.”
5) Change management and release discipline
• “Explain your release process for rider/driver apps, routing engine, and integrations. How do you avoid breaking live rosters or airport SLAs during updates?”
• “Provide change records for 3 recent production releases that impacted routing, HRMS/ERP integration, or billing logic, including rollback criteria and any related incidents.”
6) Business continuity and resilience in Indian conditions
• “Share your written BCP/DR playbook specifically for:
– Regional network outages (e.g., data-center or telco issues in a metro)
– Mass traffic disruptions (strikes, floods, city-wide events)
– Third-party dependency failures (maps, SMS gateway, GPS provider).”
• “Provide 1–2 examples where this playbook was activated for an Indian EMS/CRD client and the resulting impact on OTP, safety incidents, and escalations.”
7) Data, auditability, and client visibility
• “How can clients independently view reliability and incident metrics? Provide screenshots or exports from your production dashboards showing SLO compliance and incident timelines.”
• “Describe your audit trail for incidents: what is logged, how long it is retained, and how it can be shared with clients for internal audit or regulatory reviews.”
8) Roles, staffing, and on-call model
• “Share the organisational structure of your SRE/NOC team serving Indian EMS/CRD clients, including shift patterns, on-call rotation, and coverage for night shifts and weekends.”
• “Specify who answers the phone at 2 a.m. during a priority incident and their decision rights regarding workarounds, routing overrides, and vendor escalations.”
9) Client references focused on reliability, not only features
• “Provide 2–3 Indian enterprise references where we may speak specifically about incident handling, OTP impact during outages, and the quality of your PIRs and communications.”
• “Request those clients to confirm whether they receive regular reliability reviews (monthly/quarterly) and what metrics are shared.”
Using these questions, Procurement can demand artefacts (PIRs, runbooks, dashboards, NOC reports) and incident narratives that reveal real SRE maturity, rather than relying on polished demos or generic assurances.