How to install a control-room governance for driver & fleet that delivers OTP stability under peak demand
In peak shifts, weather disruptions, and driver shortages, daily firefighting becomes the norm. This playbook groups governance questions into five operational lenses to help you map guardrails that keep the operation calm and auditable. This isn't a product pitch. it's a field-tested sequence of rigorous controls—onboarding, substitution, incentives, data, and incident response—that the dispatch floor can implement tonight to reduce escalations and protect driver trust.
Is your operation showing these patterns?
- Persistent firefighting during night shifts with missed first pickups
- GPS or app downtime leaving dispatch blind
- Vendor response delays that stall substitutions
- Escalations pile up after outages with unclear ownership
- Driver shortages force last-minute substitutions and employee complaints
- Audit trails look loose under peak pressure
Operational Framework & FAQ
onboarding, compliance, and fatigue governance
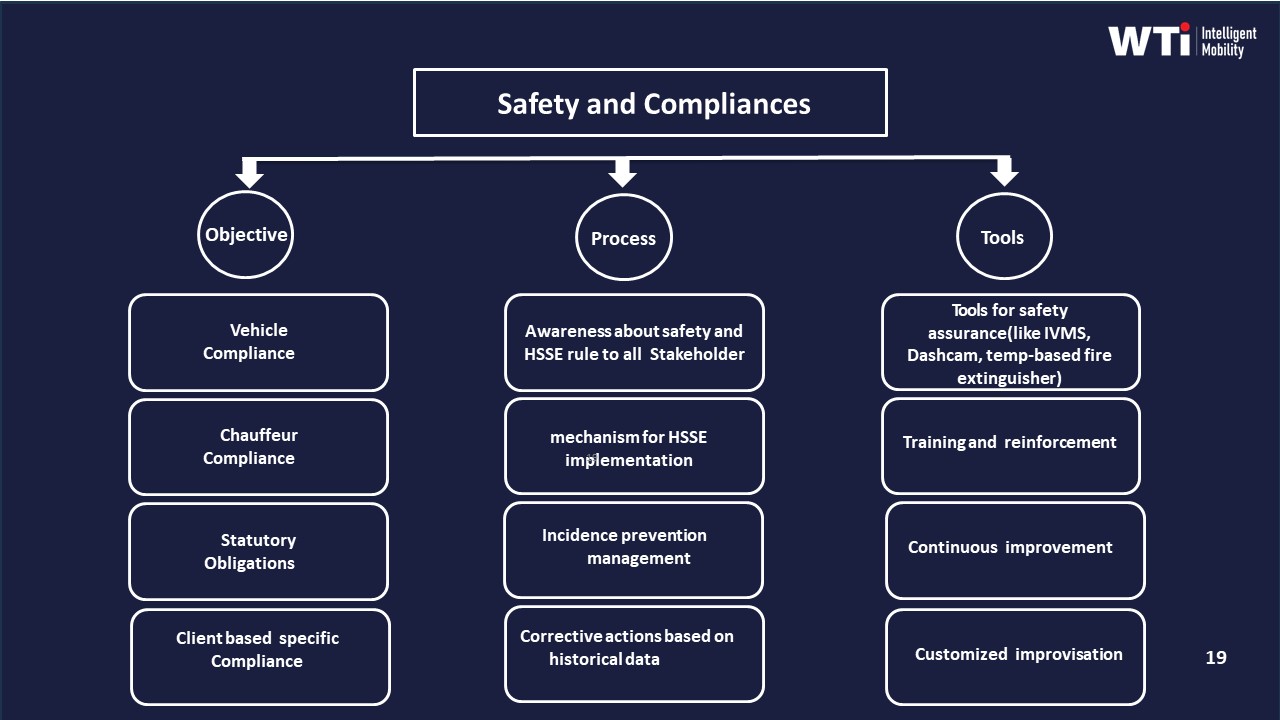
Covers driver onboarding cadence, KYC/PSV validation, vehicle checks, and fatigue management to keep operations auditable and safe while minimizing friction.
For our employee commute program, what all falls under driver and fleet governance in practice, and what usually goes wrong when that governance is weak even if routing and the control room exist?
B1286 Define driver & fleet governance — In India corporate Employee Mobility Services (EMS), what does “driver & fleet governance” actually include day-to-day (driver onboarding, KYC/PSV validation, performance reviews, incentives, and substitution rules), and what typically breaks when governance is weak even if routing and a command center are in place?
Driver and fleet governance in Indian Employee Mobility Services covers the entire lifecycle of drivers and vehicles. It spans onboarding and verification, daily deployment rules, performance tracking, corrective action, and structured substitution policies for drivers and cars.
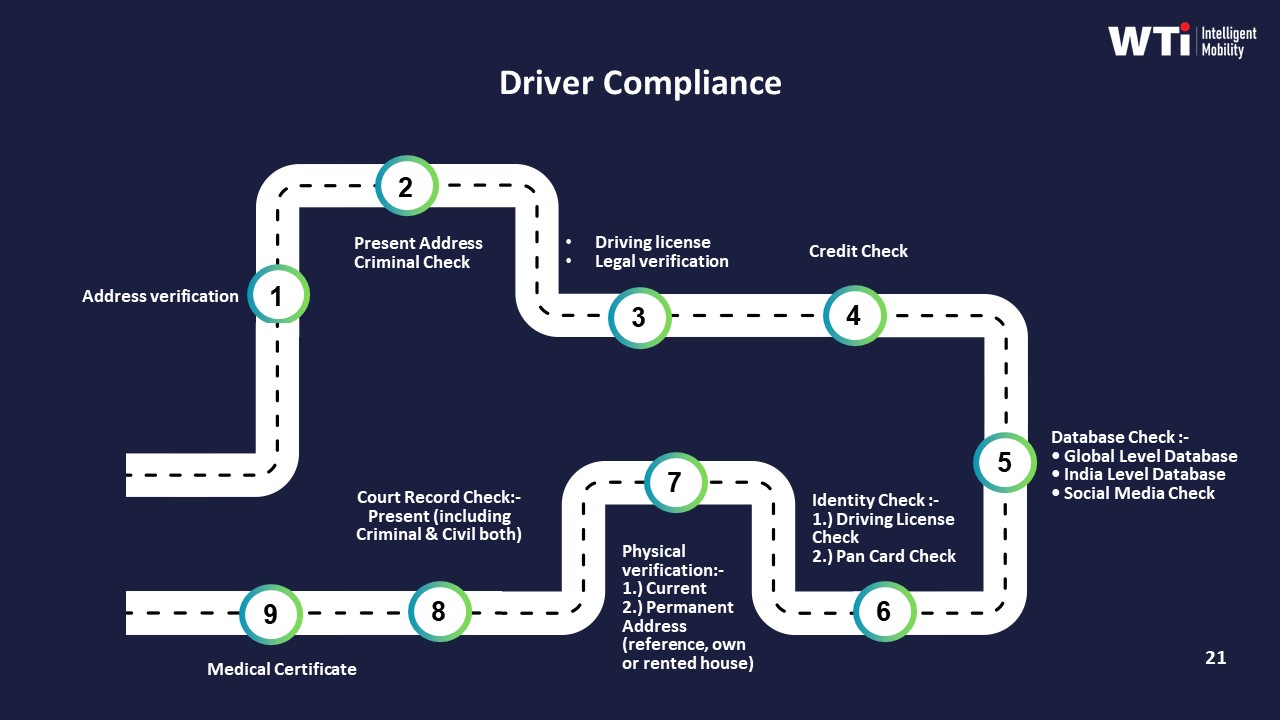
Day to day, strong driver governance starts with standardized onboarding. Organizations run documented Driver Assessment & Selection Procedures that include VIVA or interview rounds, written tests, and practical driving evaluations. They verify licensing, background, health, and past experience using address verification, criminal checks, license validation, credit checks, court record checks, and medical certification. They then induct drivers through structured two-day training on traffic laws, soft skills, POSH, customer handling, and defensive driving.
Daily operations rely on compliance and monitoring. Centralized compliance management systems track licence and document expiry, fitness, and vehicle age limits. They use checklists for vehicle safety inspection and fleet compliance to ensure statutory documentation, mechanical health, and safety equipment are in place before deployment. Command centers monitor driving behaviour with alerts for overspeeding, geofence violations, device tampering, and route deviations.
Performance management adds continuous governance. Driver management programs conduct periodic audits, feedback reviews, retraining, and rewards and recognition. They track accident rates, customer satisfaction, and safety incidents, and then adjust training, coaching, or route allocation. Incentive and recognition frameworks tie safe driving, punctuality, and service quality to tangible rewards while also enforcing disciplinary action for repeated non-compliance.
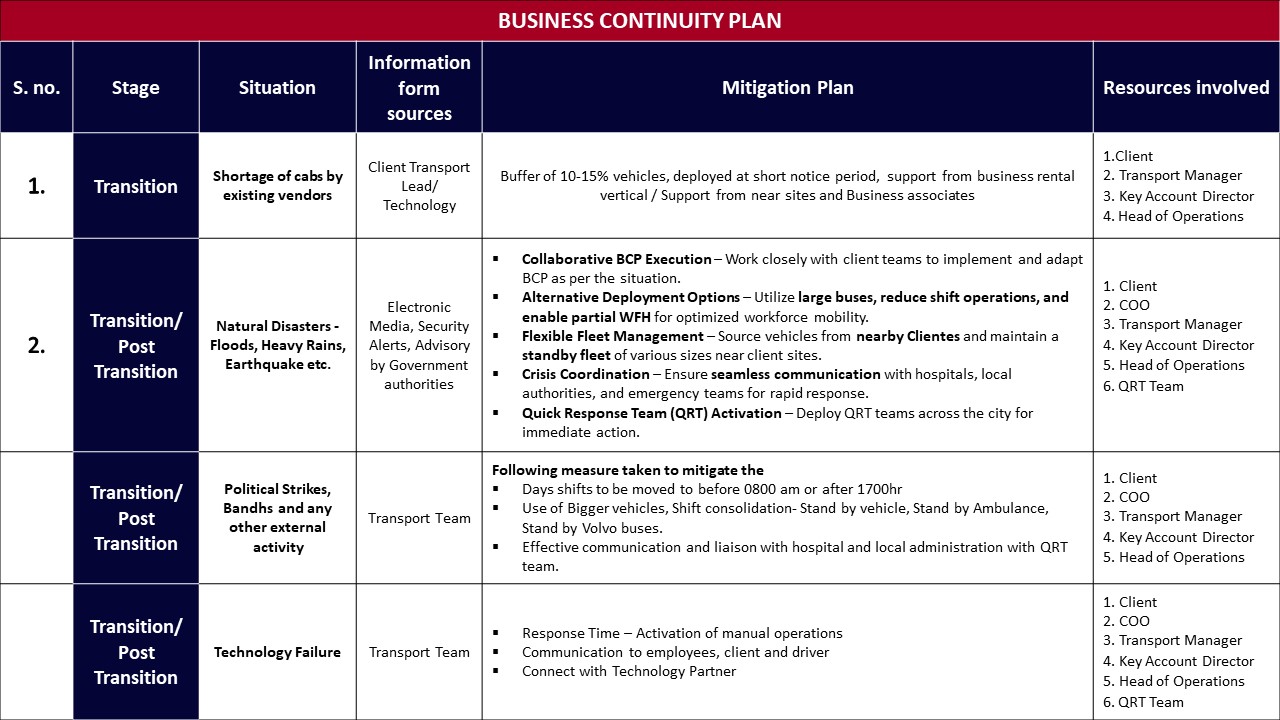
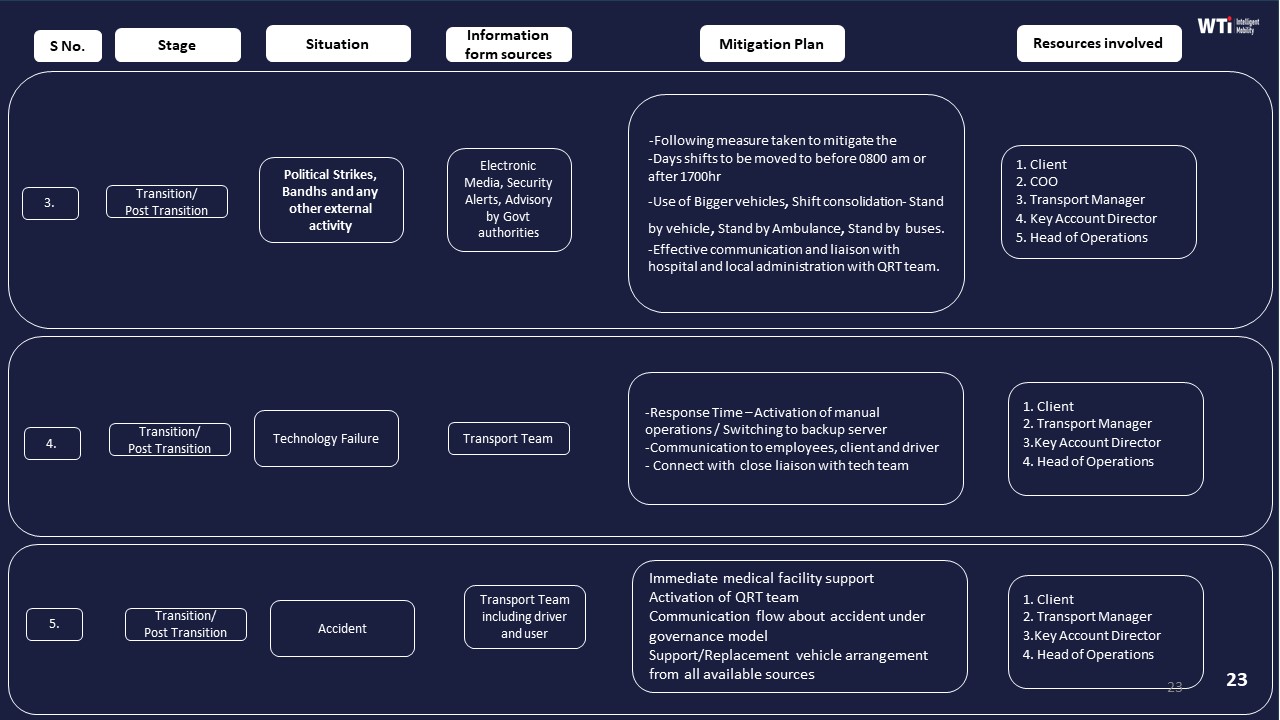
Substitution and contingency rules are part of mature governance. Business continuity plans define buffers of standby vehicles, support from associated businesses, and actions for strikes, weather events, technology failures, or cab shortages. Clear substitution rules control when a driver or vehicle can be swapped, under what compliance checks, and how changes are recorded and approved.
When driver and fleet governance is weak, problems appear even if routing tools and a command center exist. A common failure mode is non-compliant drivers or vehicles entering service because KYC and induction checks are incomplete or not enforced. Safety protocols can fail when escort, women-centric safety rules, or SOS escalation processes are not tied to driver behaviour and audit trails.
Weak governance also leads to inconsistent OTP and reliability. Routing engines may plan optimal trips but unmonitored drivers can deviate, accept unauthorized detours, or ignore SOPs, which erodes on-time performance and trust. Fleet uptime suffers when pre-induction checks and preventive maintenance are lax, causing higher breakdowns and last-minute substitutions that bypass compliance controls.
Billing and audit integrity degrade when governance is not embedded. Vehicle deployment and quality assurance steps may be bypassed, creating gaps between trip logs, GPS data, and invoices. This results in disputes, revenue leakage, and an inability to defend numbers during audits or client reviews.
Safety and reputational risk sharply increase under weak governance. Without strict driver compliance, ongoing training, and documented incident-response protocols, organizations struggle to reconstruct incidents, prove due diligence, or show that women-safety measures were actually enforced. In practice, command centers become reactive fire-fighting units rather than proactive supervisors when driver and fleet governance are not fully integrated into daily operations.
Why do driver and vehicle substitution rules impact OTP/OTD so much, sometimes more than routing, and how do we explain that trade-off to HR and Finance?
B1287 Why substitution rules drive OTP — In India corporate ground transportation (employee commute and corporate car rental), why do driver substitution rules and fleet replacement rules influence on-time pickup/on-time drop (OTP/OTD) more than most “smart routing” improvements, and how should an operations leader explain that trade-off to HR and Finance stakeholders?
In Indian corporate ground transportation, clear driver substitution rules and fleet replacement rules protect on-time pickup/drop (OTP/OTD) more than most “smart routing” tweaks because they solve the biggest real failures—no-show vehicles, fatigued or absent drivers, and breakdowns—before routing even matters. Smart routing can only optimize trips that actually start on time with a fit driver and a healthy vehicle.
Driver substitution rules create a predictable response when a driver falls sick, gets stuck, or exceeds duty hours. Without pre-approved backup drivers, rest norms, and escalation timelines, routes collapse at the last minute. Fleet replacement rules do the same for vehicles. Pre-inducted standby cabs, preventive maintenance, and uptime SLAs ensure a working vehicle is available when the primary one fails. These controls directly remove the most common OTP killers the Facility or Transport Head sees every night.
Operations leaders can explain the trade-off to HR and Finance in outcome terms. HR cares that escorts, women-safety rules, and night-shift rides are never compromised. Substitution and replacement SOPs ensure a compliant, verified driver and vehicle are always available, which reduces safety incidents and reputational risk more than another 2–3% routing gain. Finance cares about Cost per Employee Trip and SLA penalties. A missed pickup due to a failed substitution costs far more in lost productivity, re-dispatch, and penalties than the marginal savings from slightly shorter routes. A simple narrative works well: “First guarantee wheels and drivers on time, then optimize kilometers.”
Practical signals that these rules are working include higher fleet uptime, reduced exception calls to the command center, lower dead mileage caused by late replanning, and stable OTP above agreed thresholds. Smart routing and AI optimization still matter, but they should sit on top of robust substitution and replacement SOPs, not replace them.
In our shift commute setup, how do we tell if OTP issues are really a driver retention/incentive problem versus traffic, routing, or vendor capacity excuses?
B1288 Diagnose retention vs routing issues — In India Employee Mobility Services (EMS) for shift-based commutes, how should a buyer think about the linkage between driver retention, incentive design, and OTP stability—what are the practical signals that retention is the root cause rather than traffic, routing, or vendor capacity claims?
In shift-based Employee Mobility Services in India, driver retention and incentive design are core levers for on-time performance (OTP) stability, and recurrent OTP failures often trace back to unstable driver supply rather than traffic or routing issues. Buyers should treat driver attrition, fatigue, and pay structures as operational risk variables that directly affect no-shows, last‑minute trip drops, and SLA adherence in night and peak shifts.
When driver retention is weak, operations drift into a chronic firefighting mode. Transport heads see repeated last-minute vehicle substitutions, heavy dependence on standby cars, and frequent “app is down / GPS not working” excuses that mask underlying manpower shortages. High churn breaks the link between command-center planning and what actually happens on the road. New or ad-hoc drivers are less familiar with routes, safety protocols, and SOPs, which amplifies risk for women’s night shifts and raises escalation rates to HR and Security/EHS leaders.
The practical diagnostic is to correlate OTP behavior with driver continuity patterns instead of only looking at traffic or routing. Signals include frequent vendor requests to relax escort or routing rules during high‑churn periods, recurring short-notice roster changes, rising incident noise despite unchanged route plans, and OPS teams reporting “good days” mapped to days when the regular driver pool is intact. Buyers should press vendors for transparent metrics on driver tenure by route or shift, driver fatigue controls, and how incentives are structured across night, early‑morning, and low‑demand bands. Where OTP stabilizes after targeted incentives, recognition programs, or structured driver management and training (as described in the collateral), it is a strong indication that retention and incentive design—not just traffic or capacity—were the primary constraints.
To separate retention as root cause from convenient vendor narratives about traffic or routing, buyers can use a few concrete checks:
- Trend OTP against driver assignment stability at a route or cluster level.
- Compare incident and delay patterns between long-tenured and frequently rotated drivers.
- Audit how often “backup” or “partner” vehicles are used on the same critical shifts.
- Review how many drivers are trained and cleared for women‑safety and night‑shift protocols versus the number actually rostered.
These signals help Facility / Transport Heads and HR distinguish genuine external constraints from fixable driver-management issues, and they give Procurement and Finance a basis for linking commercial models and incentives directly to predictable OTP and reduced escalation risk.
Where do HR, Transport, and Procurement usually clash on driver incentives/penalties, and what governance keeps it from becoming daily escalation noise?
B1289 Align HR–Ops–Procurement incentives — In India enterprise employee transport operations, what are the most common hidden conflicts between HR (employee experience and safety), Facilities/Transport (operational stability), and Procurement (cost discipline) when setting driver incentives and penalties, and how do high-performing programs prevent those conflicts from turning into daily escalations?
In enterprise employee transport in India, the most common hidden conflicts around driver incentives and penalties arise because HR, Facilities/Transport, and Procurement optimize for different outcomes using the same levers. HR optimizes for safety and employee experience, Facilities/Transport for daily stability and OTP, and Procurement for cost and contract discipline. High-performing programs prevent these tensions from becoming daily escalations by making incentives outcome-linked, data-backed, and governed through clear SOPs rather than ad-hoc reactions.
The first conflict is “cheap vs safe vs reliable.” Procurement pushes for low per‑km or per‑trip rates. Facilities/Transport needs enough budget headroom for standby vehicles, fatigue management, and night-shift premiums. HR wants women-safety compliance, verified chauffeurs, and audit-ready incident handling. When driver pay is squeezed without compensating for night hours, traffic risk, or EV-specific constraints, OTP and safety degrade. The operations team then firefights, and HR receives escalations that are actually consequences of commercial design.
The second conflict is around penalties. Procurement often designs strict vendor penalties for SLA breaches. Facilities/Transport depends on the same drivers and vendors to save a bad night, so over-aggressive penalties can damage cooperation and driver retention. HR expects “zero incident” performance and fast closure on complaints, which can translate into pressure for immediate punitive action against drivers without a consistent, evidence-based process. This creates mistrust between on-ground teams and HR and can reduce honest reporting of edge cases.
A third conflict emerges in what gets rewarded. Drivers are often paid on trip count or hours, which encourages taking marginal routes, stretching duty cycles, or skipping breaks. Facilities/Transport likes higher utilization because it helps cost metrics and capacity. HR needs adherence to rest norms, night-route protocols, and women-safety rules. Without a shared model, incentives unintentionally reward behavior that increases risk, while penalties target the resulting incidents rather than the underlying design.
High-performing programs reduce these conflicts by standardizing three things in advance instead of negotiating them shift by shift. They define a clear outcome stack for drivers and vendors that explicitly balances OTP, safety/compliance, and employee feedback, and they connect payouts and penalties to those combined outcomes, not to a single metric. They back this with continuous observability through centralized command centers, IVMS and GPS logs, incident records, and compliance dashboards, so disputes are resolved with data, not opinion. They also codify driver-focused SOPs around duty cycles, night-shift routing, and women-safety (escort rules, SOS handling, geo-fencing) and align Procurement’s contracts with those SOPs so that “cheapest” bids that cannot sustain compliant operations are filtered out early.
The most effective structures use a governance rhythm rather than ad-hoc blame. HR, Facilities/Transport, and Procurement review common KPIs together, including OTP%, incident rates, driver attrition, and complaint closure SLAs. Corrective actions then focus on route design, fleet mix, or scheduling instead of only punishing drivers. Incentive pools are structured so that drivers gain from consistent OTP, clean compliance audits, and positive employee ratings, while vendors carry commercial penalties for systemic failures. This shifts the system from reactive penalty battles to a predictable, shared-operating model that keeps front-line teams out of daily cross-functional conflict.
What are the must-have driver and vehicle onboarding checks we should enforce, without making the process so heavy that vendors start bypassing it?
B1290 Right-size onboarding checkpoints — In India corporate Employee Mobility Services (EMS), what onboarding checkpoints for drivers and vehicles (including driver KYC/PSV cadence and vehicle fitness/permit validity) are essential to keep operations audit-ready without creating so much friction that vendors bypass the process?
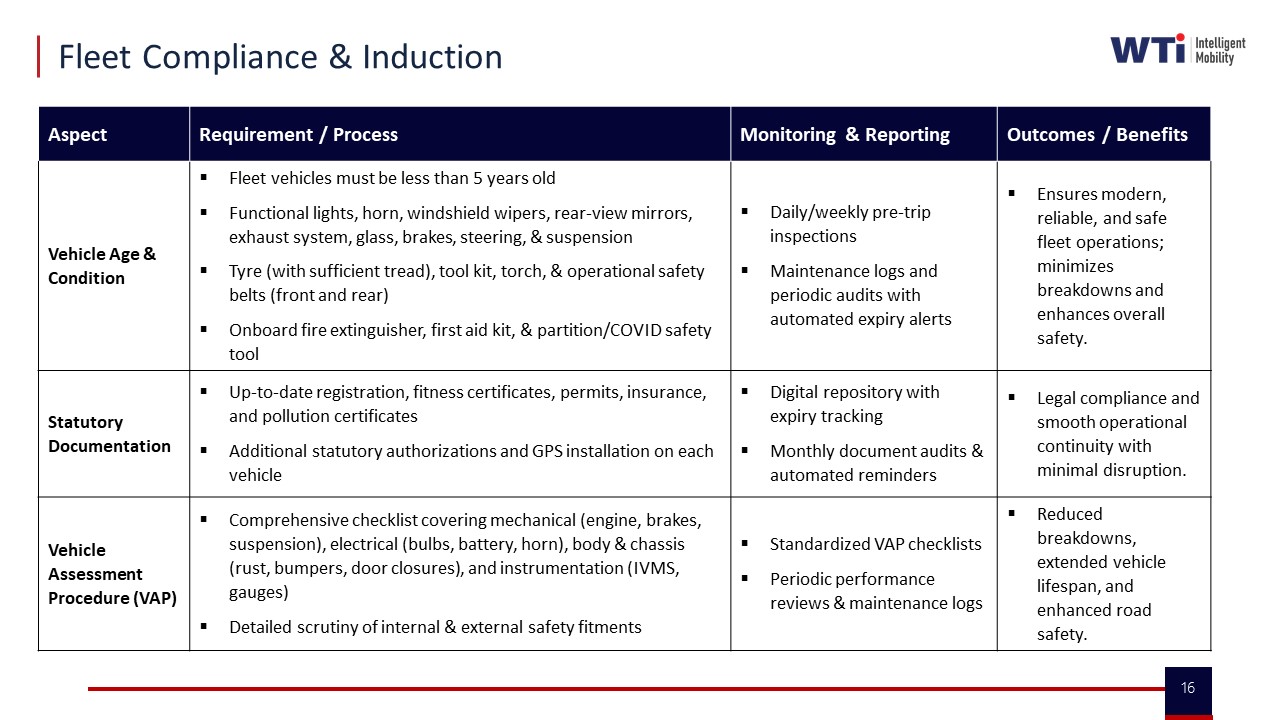
In India EMS programs, onboarding must enforce non‑negotiable safety and compliance checks for every driver and vehicle, but the workflow must be templated, time‑bound, and tech‑assisted so vendors can complete it quickly and repeat it easily. The goal is continuous audit‑readiness with predictable SOPs, not one‑time heavy vetting that operators try to work around.
For drivers, most organizations treat KYC and PSV as a structured pipeline rather than ad‑hoc paperwork. A robust model uses a documented Driver Assessment & Selection Procedure that starts with basic eligibility screening, a VIVA interview, written test, and practical driving evaluation. Parallel to skill assessment, a compliance track runs full background verification using an address verification database, criminal and court‑record checks, license authenticity checks, credit checks, social media/database scans, and medical certification. These checks create a single compliance record per driver that can be monitored through periodic audits and refresher training on traffic laws, POSH and customer handling, seasonal risk (e.g., monsoon), and defensive driving. A clear cadence is critical. Many EMS operators run renewal audits on licensing and background currency at defined intervals, and they embed this into a centralized compliance management system that issues automated alerts before expiries. This reduces friction for vendors because they get a predictable calendar instead of surprise audits, and it gives Security and HR a continuous assurance trail.
For vehicles, onboarding typically hinges on pre‑induction essential checks backed by a Maker & Checker policy. Before a vehicle is tagged to EMS duty, teams inspect statutory documentation such as registration, fitness certificate, permits, insurance, tax tokens, and pollution certificates, and they record these digitally. In parallel, a mechanical and electrical inspection checks brakes, lights, tyres, seat belts, mirrors, and basic safety equipment against a standard safety inspection checklist. Operators also apply vehicle age and condition thresholds to keep the fleet modern and reliable. These steps are supported by photo/document uploads into a centralized compliance management platform so each asset has a complete digital file. Audit‑readiness depends on two aspects. First, fleets run periodic re‑inspection and document‑validity checks under a defined schedule, with automated reminders to vendors before expiry and a clear rule that expired vehicles move off duty until compliant. Second, command centers and dashboards surface compliance status in real time, including lapsed documents, upcoming expiries, and non‑compliant vehicles, so Transport heads and Security can act before issues appear in an external audit.
To keep vendors engaged rather than evasive, leading EMS programs apply a few practical safeguards during onboarding and renewal cycles:
- Use standardized checklists and digital forms so drivers and fleet owners know exactly what is required and can submit once, not via repeated back‑and‑forth.
- Bundle induction steps into a time‑boxed process that combines driver assessment, classroom soft‑skills, and vehicle checks, so operators do not face fragmented demands spread over weeks.
- Run centralized compliance management with automated notifications and clear Maker & Checker roles, so vendors see predictable enforcement rather than arbitrary decisions.
- Link vendor performance and allocation to compliance scores, making adherence commercially relevant without adding extra manual paperwork.
When driver and vehicle onboarding are treated as a recurring, technology‑supported compliance cycle with transparent rules, vendors experience a stable process they can operationalize, and enterprises get the audit‑ready evidence trail they need across safety, regulatory, and ESG commitments.
How do we set clear substitution rules for driver no-shows or vehicle breakdowns that protect OTP but don’t create employee complaints about safety or vehicle quality?
B1291 Substitution rules without complaints — In India shift-based employee transport, how can a Facilities/Transport Head design substitution rules for last-minute driver no-shows or vehicle breakdowns so OTP is protected without triggering employee complaints about safety, vehicle quality, or perceived favoritism?
In India shift-based employee transport, substitution rules work best when they are pre-coded into SOPs and tech workflows with clear safety, quality, and fairness thresholds that operations cannot bypass. The Facilities/Transport Head should define objective triggers, a prioritized substitution sequence, and non-negotiable compliance checks, and then automate as much of this as possible through the command center, routing tools, and alert systems.
A common failure mode is ad‑hoc substitutions made under time pressure with no documented rules. This often protects OTP for a few employees but creates perception of favoritism, safety anxiety for women on late shifts, and future escalations to HR. Substitution rules are more stable when they are documented in the ETS Operation Cycle, linked to centralized compliance dashboards, and visible in a 24/7 command center or Transport Command Centre.
OTP is better protected when the substitution logic begins with pre-tagged standby vehicles and drivers that have already passed driver and fleet compliance and induction checks. Backup drivers should go through the same Driver Assessment & Selection Procedure, driver compliance verification, and training modules used for regular drivers, including women-centric safety protocols and HSSE responsibilities.
Safety complaints reduce when any substitution, especially on night shifts or for female-only routes, is constrained by women-safety SOPs. These SOPs should include rules around escort compliance, geo-fencing, SOS availability in employee and driver apps, and women-centric safety protocols such as route approvals and home-safe confirmation.
Vehicle quality concerns are minimized when only inducted vehicles that have passed fleet compliance & induction and a safety inspection checklist are allowed into the substitution pool. The Facilities/Transport Head should ensure that pre-induction checks, maker–checker validation, and periodic audits also apply to standby vehicles, not just primary fleet.
Perceived favoritism reduces when route-level prioritization rules are explicit and auditable. Priority can be based on shift-criticality, plant or process dependency, and gender and time-band risk categories rather than individual names. The command center can use standardized routing and capacity logic so that any reassignment is logged and later visible in management reports and user satisfaction index reviews.
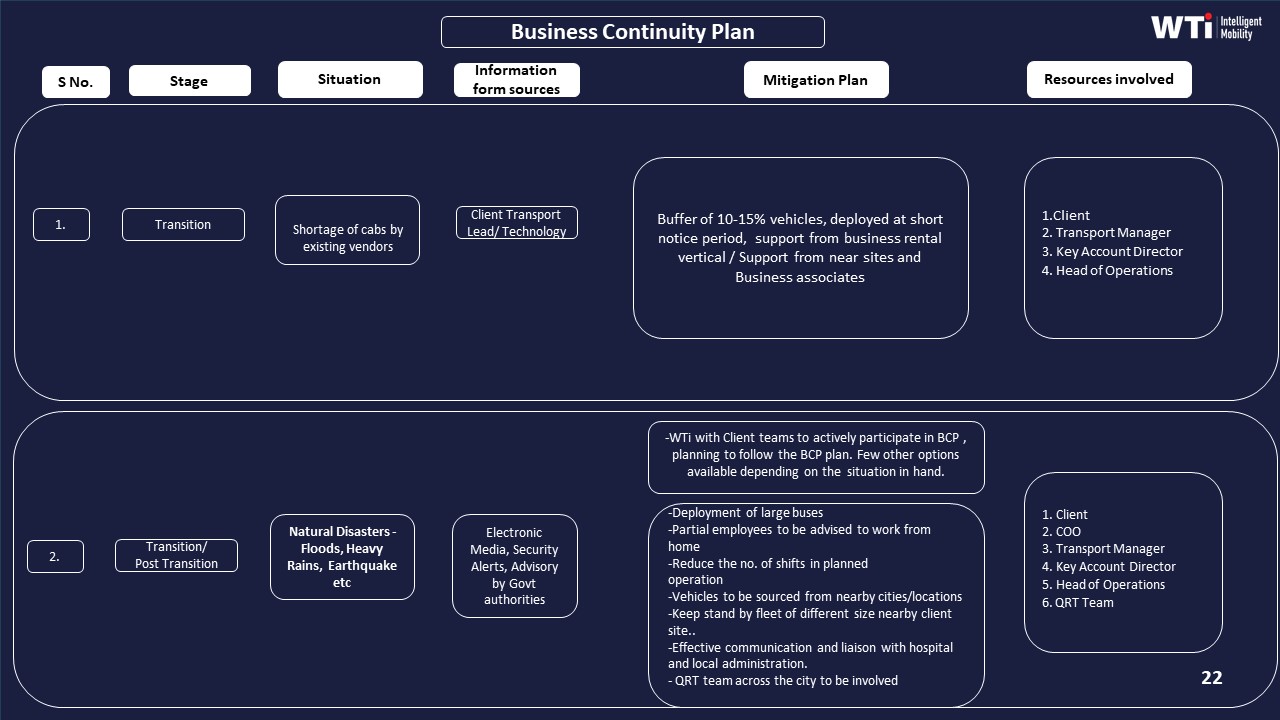
A practical substitution SOP usually defines: when to trigger a standby car, when to merge trips using dynamic route optimization, when to borrow capacity from another site under a Business Continuity Plan, and when to escalate to HR if some passengers will inevitably be delayed. These steps should be rehearsed in BCP drills and captured in micro functioning of the command centre documentation.
To keep employees calm during last-minute substitutions, communication must be baked into the workflow. Employee and driver apps can push real-time notifications with new vehicle and driver details, live tracking links, and reassurance that safety controls like SOS and call-masking remain active. This reduces call volume into the helpdesk and protects the perception of control.
Data-driven insights from dashboards and indicative management reports help the Facilities/Transport Head tune substitution rules over time. Patterns of repeated no‑shows or breakdowns by vendor, route, or time-band can then feed back into vendor & statutory compliance reviews, account management and operational excellence models, and cost optimization frameworks.
Clear governance around substitution should be co-signed by HR, Security/EHS, and Procurement. HR can validate fairness and women-safety aspects, Security can validate HSSE and incident-readiness, and Procurement can ensure the rules are reflected in SLAs, penalties, and Business Continuity Plan clauses with vendors.
images:

What should a fair, evidence-based driver performance review process look like so we can remove or retrain drivers without it feeling arbitrary or political?
B1292 Evidence-based driver reviews — In India corporate Employee Mobility Services (EMS), what does a defensible driver performance review system look like (metrics, frequency, coaching actions, and escalation thresholds) so that removing a driver is seen as fair and evidence-based rather than political or arbitrary?
A defensible driver performance review system in Indian Employee Mobility Services relies on a small, clearly defined metric set, fixed review cadences, documented coaching steps, and pre-agreed escalation rules that are visible to drivers, vendors, Transport, HR, and Security teams alike. The system must join telematics-style data, compliance checks, safety incidents, and feedback into an audit-ready record so that any removal decision can be traced back to objective patterns rather than personal opinions.
A robust metric stack typically monitors on-time performance, route adherence, and fleet uptime alongside safety and compliance signals such as speeding alerts, geofence violations, SOS triggers, and credential currency. Organizations often complement these operational KPIs with a driver-level experience index derived from employee app feedback, complaint closure SLAs, and night-shift or women-safety protocol adherence. This combination links driver behavior to both shift reliability and duty-of-care outcomes without relying on a single data point.
The review cadence works best when layered. Daily or shift-level checks handle red-flag events such as major safety breaches, drunk driving suspicion, or willful non-compliance, which trigger immediate suspension pending investigation. Weekly or fortnightly views at the command center help identify emerging risk patterns such as rising incident rates, frequent GPS tampering, or repeated OTP failures. Monthly or quarterly reviews with vendors consolidate metrics like Driver Fatigue Index, incident rate, audit trail completeness, and trip adherence into scorecards that support contractual governance.
A fair system encodes coaching as a mandatory intermediate step for non-critical issues. First-level deviations such as a minor OTP breach, a single complaint about behavior, or an isolated route deviation lead to documented counseling, refresher training, or soft-skills sessions. Recurring but non-critical patterns, like persistent minor delays or low feedback scores, should move drivers into structured improvement plans involving ride-alongs, seasonal and specialized training, or rewards and recognition linkage. Every action, from briefing to re-training, needs to be logged with timestamps and references to specific trips or alerts.
Escalation thresholds become defensible when they are numerically explicit and contractually visible. For example, a defined limit on speeding alerts in a rolling period, a maximum count of validated complaints, or a minimum acceptable performance band on a composite driver KPI index can be agreed with vendors and communicated in induction. Once a driver crosses a threshold despite documented coaching, temporary removal from night shifts, reassignment to lower-risk routes, or final off-boarding can proceed under a pre-signed SLA and Vendor Governance Framework. This reduces the perception of politics and anchors decisions in measurable risk to employee safety, service reliability, and compliance obligations.
In practice, organizations strengthen defensibility by mapping driver-level KPIs to three adjacent governance layers. The first is centralized compliance management, which ensures that documentation, audits, and Maker–Checker style validations back every credential and policy check. The second is command-center operations, which provide real-time observability and exception handling for events like over-speeding, route tampering, or SOS activations. The third is safety and HSSE oversight, which ensures each driver’s record can be reconstructed for incident investigations and external audits. When driver performance governance is aligned with these layers, driver exits naturally appear as the final step of a transparent, safety-first system rather than an ad hoc decision.
How can Finance check that driver incentives are really moving OTP and reducing escalations, and what proof should connect payouts to outcomes?
B1293 Prove incentives drive outcomes — In India enterprise employee transport, how should Finance validate that driver incentive payouts are actually improving OTP and reducing escalations—what evidence should link incentives to operational outcomes so Finance isn’t funding a feel-good scheme?
Finance teams should only back driver incentive schemes when there is a clear, data-backed link between payouts, on-time performance (OTP), and reduction in safety or service escalations. The validation must connect driver-level incentives to trip-level KPIs, aggregate fleet performance, and complaint trends over defined time windows.
To avoid “feel-good” spending, Finance should insist on a baseline period with frozen incentive rules and a post-change period with the new incentive logic. The comparison should use standard mobility KPIs such as OTP%, Trip Adherence Rate, exception detection-to-closure time, and escalation volume. Trip and incident logs should come from a governed platform or command center, not from spreadsheets manually curated by the vendor, to preserve audit trail integrity.
A robust validation approach usually includes:
- Driver-level views that correlate payout bands with OTP%, no-show rates, and incident-free shifts.
- Route and time-band views showing whether night-shift or high-traffic windows actually improved after incentives.
- Escalation and complaint analysis that tracks changes in volume and severity, mapped against the same driver cohorts.
Finance should also check that incentive cost per trip or per km is offset by measurable gains in utilization, reduced dead mileage, fewer re-dispatches, or lower SLA penalties. If OTP and incident metrics do not move meaningfully for the same or lower unit economics, Finance is justified in challenging or redesigning the scheme rather than continuing to fund it.
What incentive structures improve driver retention without pushing unsafe driving or OTP gaming, especially for night shifts?
B1294 Incentives without unsafe behavior — In India corporate ground transportation, what are practical incentive designs that improve driver retention without encouraging risky driving, overspeeding, or gaming OTP reporting—especially in night-shift employee commute programs with safety-sensitive protocols?
Practical incentive design in Indian corporate ground transport focuses on rewarding consistent, safe, compliant service rather than raw speed or trip volume. Incentives that work in safety‑sensitive, night‑shift employee commute programs usually blend fixed stability, safety-linked bonuses, and data-backed fairness using telematics, command-center monitoring, and audit trails.
Safe programs avoid paying drivers directly for “more trips” or “shorter trip times.” These models tend to increase overspeeding, lane-cutting, and fatigue, which directly undermine women-safety protocols, escort rules, and night-shift HSSE obligations described in the industry brief. Operators instead index rewards to on-time performance within a defined window, adherence to approved routes, and zero-incident records validated via GPS, IVMS, and command-center logs.
A common pattern is to separate pay components into:
- A predictable base linked to duty hours and cab duty cycle to reduce pressure for unsafe extra runs.
- Safety and compliance bonuses tied to clean driver KYC/PSV currency, no geofence violations, no tampering alerts, and successful HSSE audits over a month.
- Service consistency bonuses linked to OTP% within an allowed ETA band, low no-show disputes, and positive employee feedback, all validated through trip logs and NOC dashboards.
Command centers and NOC teams play a central role in preventing gaming. They use route adherence audits, exception monitoring, and incident-response SOPs to verify OTP, TAR, and complaint data before releasing incentives. This approach discourages practices such as short-routing, fake delays, or collusion on manual duty slips because payouts depend on multiple independent signals, not just a single self-reported metric.
Incentive schemes that integrate defensive driving training completion, women-centric safety protocol adherence, and low Driver Fatigue Index scores further align driver behavior with night-shift duty-of-care requirements. This balances retention and morale with compliance expectations from HR, Security/EHS, and CFO/Procurement, while keeping operational risk and reputational exposure under control.
How do we quantify the ops drag from weak onboarding and ad-hoc substitutions—extra calls, approvals, escalations—and baseline it before we change vendors or rules?
B1295 Measure operational drag baseline — In India Employee Mobility Services (EMS), how do organizations measure the “operational drag” created by weak driver onboarding and ad-hoc substitutions (extra calls, manual approvals, escalations, and trip rework), and how can a buyer baseline that before changing vendors or governance rules?
In Indian Employee Mobility Services, organizations usually measure “operational drag” from weak driver onboarding and ad‑hoc substitutions indirectly through exception and rework metrics rather than a single named KPI. Buyers can baseline this drag before changing vendors by creating a short, time-bound “exception ledger” that tags every driver-related deviation and rolls it up into a few standard cost and reliability indicators.
Weak onboarding and substitutions typically surface as recurrent exceptions in the ETS or command-centre operation cycles. These include late vehicle reporting, driver no-shows, wrong driver or vehicle credentials, failed compliance checks, and safety escalations related to unverified or poorly briefed drivers. Command centre dashboards, alert supervision systems, and transport command centres already log many of these events as geo-fence violations, fixed device tampering, overspeeding, and SOS triggers, which can be classified as onboarding or substitution-induced drag.
Operational drag can be baselined by mapping these exceptions to hard impacts. The impacts include on-time performance drops, extra trips or re-routing, manual roster edits, duplicate coordination with vendors, and increased call-centre load. Buyers can derive per-shift counts for such events using indicative management reports, ETS operation-cycle logs, alert supervision data, and escalation matrices. These counts can then be translated into estimated “extra minutes of work” or “additional trips and calls per 1000 journeys,” which makes the drag visible alongside standard KPIs like OTP, fleet uptime, and customer satisfaction scores.
A practical baselining approach before changing vendors or governance rules is to run a focused diagnostic over 4–6 weeks with four simple lenses: - Count of trips involving last-minute driver or vehicle substitution. - Count of trips held up by missing or failed driver or fleet compliance checks. - Volume of escalations and SOS or safety tickets linked to driver conduct or process deviation. - Additional calls, manual approvals, and re-dispatches logged by the command centre or transport desk per shift.
These observations can be layered over existing dashboards for fleet uptime, incident logs, women safety protocols, and driver compliance frameworks. Buyers can then compare the “with current onboarding” baseline against a targeted improvement model that uses structured driver assessment and selection procedures, formal driver compliance and induction, and daily shift-wise briefings. The difference between the two states defines the avoidable operational drag that a new vendor or revised governance model is expected to remove.
How do we avoid the feeling that some locations or teams get ‘better drivers/vehicles,’ and how should HR and Transport communicate allocation and substitution rules to keep trust high?
B1296 Prevent favoritism perception — In India enterprise employee transport, what governance practices reduce the perception that “certain sites or teams get better drivers and vehicles,” and how should HR and Facilities jointly communicate driver allocation and substitution rules to protect trust and morale?
In Indian enterprise employee transport, transparent, rule-based driver and vehicle allocation combined with visible, data-backed governance is what reduces perceptions of “favouritism,” while joint HR–Facilities communication converts these rules into trust. Allocation must be policy-driven, auditable, and explained in simple language that employees and managers can reference when disputes arise.
Governance is most effective when allocation logic is standardized across locations. Fleet tagging, shift windowing, and duty cycles should be defined in advance for EMS, CRD, and ECS rather than left to ad-hoc local decisions. Centralized or regional command centres can enforce a single routing and allocation engine for all sites, with clear escalation matrices and vendor-governance frameworks to prevent informal “VIP-only” patterns. Audit trails and dashboards described in the context, including trip ledgers, route adherence audits, and driver duty logs, should be regularly reviewed to validate that allocation follows defined SLAs and compliance requirements, not personal preference.
Communication works best when HR owns the “why” and Facilities owns the “how.” HR should publish a concise, policy-level note explaining allocation tiers, safety priorities for women’s night shifts, fatigue management norms, and EV/ICE mix rules in plain language. Facilities should translate this into SOP-style explanations for employees: how drivers are rotated, when substitutions occur, what happens in contingencies, and which metrics (OTP, safety incidents, compliance currency) trigger reallocation. Joint HR–Facilities forums can then use simple, periodic communications and floor connects to show evidence from dashboards and management reports, reinforcing that any perceived difference in driver or vehicle quality is grounded in safety, compliance, and operational logic rather than favoritism.
What RFP/contract terms make onboarding compliance and substitution discipline реально enforceable, while still letting ops stay flexible to protect OTP during peaks and disruptions?
B1297 Contract terms for enforceable governance — In India corporate ground transportation procurement, what contract language and SLA constructs make driver onboarding compliance and substitution discipline enforceable (not just promised), while still giving operations enough flexibility to keep OTP stable during peak demand or disruptions?
In India corporate ground transportation, driver onboarding compliance and substitution discipline become enforceable when contract language ties vendor revenue and continuity to verifiable documentation, audit rights, and exception logging, while explicitly allowing controlled, time‑bound relaxations during peaks or disruptions. Contracts that embed measurable KYC/PSV, training, and background‑check standards into SLAs, and link any deviation to pre‑defined penalty or suspension rules, create real enforcement but must also define “emergency substitution” corridors so operations can protect OTP and safety simultaneously.
Contracts work best when driver onboarding requirements are written as binary, auditable conditions. Vendors should be required to maintain complete driver compliance packs, including licensing, address verification, criminal checks, medical fitness, POSH training, and soft‑skills modules, supported by maker–checker workflows and upload into a centralized compliance dashboard. Procurement can make this enforceable by adding rights to periodic and random audits, trip‑level spot checks, and the ability to suspend non‑compliant drivers or vehicles from rosters until corrective action is recorded.
Substitution discipline becomes real when substitutions are treated as governed exceptions. Contracts should require that any driver or vehicle substitution is logged with identity, compliance status, reason code, time band, and approval trail, and that repeated non‑compliant substitutions trigger escalating commercial and governance consequences. At the same time, SLAs should define controlled flex rules for peaks and disruptions, such as pre‑approved standby pools, pre‑vetted backup drivers, and clear criteria for invoking emergency substitution without SLA breach when documented and reported to the command center within a fixed timeframe.
To protect OTP stability, commercial constructs should separate structural non‑compliance from documented emergency use. Outcome‑linked payments can combine minimum compliance thresholds with OTP and safety metrics, where vendors earn full payout only when both compliance currency and reliability KPIs are met. Business continuity clauses and playbooks can mandate pre‑planned buffers, multi‑vendor tiers, and contingency rosters so that driver attrition, weather, strikes, or system issues do not force uncontrolled substitutions, while preserving the buyer’s right to enforce compliance through audits, dashboards, and route‑level evidence packs over time.
In a multi-vendor setup, how do we define substitution and escalation authority so vendors can’t play the blame game, but we still keep end-to-end control?
B1298 Authority model in multi-vendor — In India Employee Mobility Services (EMS) with multi-vendor aggregation, how should an operations leader set clear substitution and escalation authority so vendors can’t blame each other during incidents, yet the enterprise retains end-to-end control of driver and vehicle decisions?
In Indian Employee Mobility Services with multi-vendor aggregation, an operations leader should centralize decision rights in a command center and define one “single throat to choke” per shift, while codifying vendor substitution rules and escalation paths in SOPs and SLAs. The enterprise must retain final approval for driver and vehicle usage through centralized compliance management, but allow the command center to trigger pre-approved substitutions without waiting for ad‑hoc vendor consent.
A common failure mode is letting each vendor run its own mini-command center. This fragments accountability and creates space for mutual blame during incidents. The operations leader should instead run a Transport Command Centre or similar 24x7 control room that owns routing, dispatch decisions, and incident response across all vendors. Vendor partners should be responsible for supply and uptime. The command center should be responsible for who runs which trip, with what driver and vehicle, and with what safety controls and logs.
Clear substitution authority requires a written vendor governance framework. That framework should define buffer vehicles, standby drivers, and cross-vendor substitution rules that are visible on a central dashboard. It should link vendor SLAs to fleet uptime, credential currency, and response times, not to subjective explanations. When a vehicle or driver fails compliance checks, the central command center should be empowered to pull that asset from duty and assign a compliant alternative, with the incident logged for later billing and penalty reconciliation.
Escalation authority should be anchored in a documented escalation matrix. The matrix should specify who in the enterprise transport team can override a vendor on routing, driver allocation, and vehicle replacement decisions. It should define time-bound response windows and evidence requirements for each escalation level, aligned with business continuity and HSSE responsibilities. This approach keeps end-to-end control of driver and vehicle decisions with the enterprise, while making vendors transparently accountable to a unified operational chain of command.
images:

What’s the risk if vendors do ‘shadow onboarding’ to meet demand, and how can we detect it early without trusting vendor self-reports?
B1299 Detect shadow onboarding — In India corporate employee transport, what are the operational and reputational risks of allowing vendor-side “shadow onboarding” (drivers added informally to meet volume), and how can a buyer detect it early without relying on vendor self-reporting?
The operational and reputational risk from vendor-side “shadow onboarding” in India corporate employee transport is that enterprises lose real control over who is actually driving employees, which directly undermines safety, compliance, and auditability, and turns every incident into a potential governance failure for HR, Security, and leadership. Shadow onboarding improves short-term vehicle availability for the vendor, but it increases incident probability, breaks HSSE and labour compliance, and makes post-incident defence almost impossible for the buyer.
Shadow-onboarded drivers are typically outside the formal Driver Compliance & Induction process. They often bypass documented checks like address and criminal verification, licence validation, medical fitness, POSH and customer-handling training, and periodic audits. This creates a higher-risk pool of drivers that still appear to the enterprise as “approved supply,” so one safety incident can quickly escalate into a reputational event, especially for women’s night-shift travel and ESG / CSR narratives about “safe commute.” In audits or legal proceedings, the enterprise may be unable to prove that HSSE, escort, and rest-hour norms were enforced, because trip logs and compliance records do not match the human being who was actually behind the wheel.
Shadow onboarding also degrades operational reliability. Unvetted or poorly briefed drivers are more prone to route deviations, no-shows, GPS/device misuse, and fatigue-related issues, which erode On-Time Performance and increase daily firefighting for the facility / transport head. It weakens any “zero-incident” posture and can trigger internal blame cycles between HR, Procurement, and Operations when something goes wrong.
Buyers can detect shadow onboarding early without relying on vendor self-reporting by using independent, data-anchored and process-anchored controls that bind the physical driver to the digital and compliance trail.
Key practical controls include:
• Mandatory driver identity binding at trip start.
Use the driver app (or IVR if offline) to enforce driver login with unique credentials tied to a verified profile, combined with periodic selfie/ID capture before duty. Any trip where the logged-in ID does not match the last-approved driver list is a red flag.
• Centralized compliance dashboards with live “credentialing currency.”
Maintain a buyer-side list of approved drivers with status of background checks, licence validity, medical fitness, and training completion. Compare daily active-driver lists (from telematics / trip data) against this master. Any driver ID or device generating trips but missing from the compliance ledger indicates shadow or lapsed onboarding.
• Device and SIM binding to driver identity.
Fix GPS devices or driver phones to individual driver IDs rather than vehicles. A sudden spike in “device swaps,” frequent IMEI changes, or trips with “generic” or shared accounts signal shadow use of non-inducted drivers even if vehicles look compliant.
• Random route and field audits.
Schedule unannounced on-ground audits where security or HSSE teams verify driver identity documents, training tags, and app profiles against the approved list at pickup gates or campus entries. Mismatches give early evidence of off-roster drivers being used to meet volume.
• Cross-checking HRMS / roster data against trip manifests.
For EMS, reconcile passenger manifests and shift rosters with actual trip execution records. If the routing and trip patterns suddenly show increased reliance on “new” or rarely-seen driver IDs without corresponding induction records, that indicates backdoor capacity additions.
• Alert supervision and anomaly detection.
Use an Alert Supervision System or NOC dashboard to flag patterns such as excessive duty hours for some IDs followed by appearance of “fresh” IDs in the same cluster, or spike in minor incidents and complaints on newly-appearing drivers. These patterns frequently accompany shadow onboarding in high-pressure time bands.
• Contractual and billing controls.
Tie payment eligibility to driver-level compliance, not just trips. For example, trips driven by IDs not present in the central compliance and induction registry are automatically non-billable or penalty-bearing. Periodic reconciliation of billing MIS with the approved-driver table surfaces hidden driver rotation.
• Integrate driver onboarding with centralized compliance management.
Ensure there is a single, buyer-governed workflow for Driver Assessment & Selection, compliance verification, and induction, feeding directly into the transport command centre. Any driver that appears in operations without a completed workflow in this system is by definition shadow-onboarded.
• Structured HSSE and safety inspections.
Use a Safety & Security or safety-and-compliance program that explicitly defines responsibility for driver vetting, refresher training, and audit logs. When conducting safety inspections or incident RCAs, insist that every trip’s driver identity is supported by a chain-of-custody from onboarding to trip closure. Gaps in this chain reveal shadow practices.
These controls give Facility / Transport Heads early operational signals, while also providing CHRO, Security/EHS, and CFO with defensible evidence that only fully-inducted, compliant drivers are allowed to move employees, even during peak loads or disruptions.
How can HR tell if the driver review and incentive plan will really reduce complaints and improve commute NPS, instead of just shifting the pain to ops or the vendor helpdesk?
B1300 Link governance to commute NPS — In India Employee Mobility Services (EMS), how should a CHRO evaluate whether driver performance reviews and incentive plans will actually reduce employee complaints and improve commute NPS, rather than simply shifting problems from HR to Facilities or the vendor helpdesk?
In India Employee Mobility Services, a CHRO should evaluate driver performance reviews and incentive plans by checking whether they are built on hard trip-level data, tied to commute-specific KPIs, and integrated with HR’s own feedback and NPS metrics, rather than managed as an isolated vendor HR initiative. Driver programs only reduce employee complaints when safety, OTP, behavior, and grievance closure are measured continuously and linked to both rewards and corrective action in a closed loop.
A common failure mode is treating driver incentives as a generic “morale program” owned by the vendor. In practice, the CHRO needs visibility into structured assessment and training like WTI’s Driver Assessment & Selection Procedure (DASP), defensive driving and POSH training, and ongoing compliance verification. Programs that lack formal assessment criteria, refresher trainings, and documented RNR logic usually just re-label issues as “operations problems” without changing commute experience.
Robust designs anchor incentives to measurable EMS KPIs such as OTP%, incident rate, complaint rate, and feedback scores, then cross-link them with employee app feedback, SOS events, and safety dashboards from a centralized command center. CHROs should insist that driver reviews, route adherence audits, and safety incidents surface into HR/ESG reporting alongside EV utilization, carbon reduction, and HSSE metrics, so HR can see whether complaints and commute NPS actually move in the right direction.
Practical evaluation questions for CHROs include: - Are driver KPIs directly mapped to commute NPS, complaint volume, and women-safety incidents? - Do incident logs, GPS data, and safety tools (SOS, geo-fencing, IVMS) feed into driver scoring and coaching? - Is there a clear escalation and corrective-action SOP, not just rewards? - Does HR receive periodic, auditable reports linking driver performance, complaints, and NPS trends?
If the answer to these questions is “no,” the plan is likely shifting noise to Facilities or the vendor helpdesk instead of reducing it at source.
If we want ‘set it and forget it’ governance for onboarding, renewals, and reviews, what can actually be automated and what will still stay manual in real life?
B1301 Set-and-forget governance reality — In India corporate ground transportation operations, what does a realistic “set it and forget it” governance model look like for driver onboarding, renewals, and periodic reviews, and what manual steps stubbornly remain even with strong automation?
A realistic “set it and forget it” governance model in Indian corporate ground transport automates the cadence, checks, and evidence for driver onboarding, renewals, and reviews, but it still relies on some manual verification, training, and exception handling. Automation can own the calendar, checklists, and alerts, while humans still own judgment, coaching, and local edge cases.
A mature operator defines a single governance spine across Employee Mobility Services, Corporate Car Rental, Events/Project commute, and Long-Term Rental. The same spine covers driver assessment and selection, ongoing compliance, and safety culture. Systems centralize documentation, expiry tracking, alerting, and reporting. Governance focuses on continuous assurance instead of one-time audits.
A practical “set it and forget it” model typically includes: - Standardized Driver Assessment & Selection Procedures. VIVA, written tests, and practical driving evaluations are pre-defined. Education, attitude, and verification checks follow a fixed playbook. This reduces subjective hiring decisions. - Centralized driver compliance workflow. Address verification, criminal and court-record checks, driving license verification, credit and database checks, PAN and identity verification, medical certification, and physical address verification run as a structured sequence. A compliance management system tracks completion and audit trails. - Defined compliance and induction matrix. Licensing and background, health and experience, and specialized training map to monitoring and reporting processes like audits, feedback reviews, and health reassessments. - Time-bound refreshers and reviews. Two-day induction programs, seasonal training (e.g., monsoon, peak season), POSH and customer-handling modules, and rewards-and-recognition cycles operate on a calendar. This keeps safety and service skills current. - Integrated safety and HSSE governance. Driver roles and responsibilities are tied into broader HSSE frameworks and safety and compliance objectives. Tools like IVMS, dashcams, and safety checklists feed into audits and corrective actions. - Command-center backed observability. Centralized dashboards can surface expiry risks, incident patterns, and compliance gaps. This allows proactive action instead of relying on ad-hoc local checks.
Within this structure, automation can reliably handle: - Expiry tracking for licenses, permits, and medical fitness certificates with automated reminders. - Document capture, validation workflows, and maker–checker approvals for driver and vehicle compliance. - Scheduling and logging of mandatory training, refreshers, and toolbox talks, with attendance and test results captured digitally. - Centralized alerts on non-compliance (e.g., missing documents, lapsed checks, uncompleted training). - Standard management reports for audits and leadership reviews covering completion rates, incident correlation, and renewal adherence.
However, several steps remain stubbornly manual or judgment-heavy: - Final hiring decision after assessments. Human evaluation of attitude, responsiveness, and cultural fit still matters beyond test scores. - Physical driving assessments and road-behavior observation. Evaluators must check real-world behavior, adherence to traffic norms, and defensive driving practices. - In-person POSH, empathy, and customer-handling evaluation. Soft skills and gender sensitivity often need live role-play and observation. - Health checks where medical exam quality depends on physical examination and local providers. - Local background verification nuances in areas where digital records are incomplete or unreliable. - Incident investigations and root-cause analysis. Teams must reconstruct context, interview drivers and passengers, and interpret telemetry and logs. - Coaching and corrective action. Turning behavior analytics into improved practice needs one-on-one feedback, mentoring, and sometimes disciplinary decisions. - Field audits and surprise checks. Spot inspections of documents in vehicles, safety equipment presence, and real-world adherence to SOPs still require physical visits. - Driver engagement and retention conversations. Addressing fatigue, morale, and grievances requires human interaction beyond dashboards.
In practice, robust governance does not eliminate manual work. It concentrates manual effort on high-judgment, high-impact tasks while letting automation handle volume, reminders, and record-keeping. Organizations that succeed treat automation as the nervous system for renewals and reviews, and treat supervision, training, and HSSE enforcement as disciplined, recurring manual muscles.
How do Legal and Procurement set substitution rules that are enforceable but don’t push unsafe duty cycles or fatigue risks for drivers?
B1302 Substitution rules vs duty-of-care — In India corporate employee transport, how should Legal and Procurement balance enforceable substitution rules with labor and duty-of-care considerations (e.g., fatigue, duty cycles), so the enterprise doesn’t create perverse incentives that increase incident risk?
In Indian corporate employee transport, Legal and Procurement need to hard-code substitution flexibility and duty‑of‑care limits into the same contract, so vendors can replace capacity without being forced to overwork drivers or cut safety corners. Contracts that push “vehicle must be provided at any cost” without rest-hour and fatigue safeguards usually shift risk onto drivers, which increases incident probability even if SLAs look compliant on paper.
The starting point is to treat driver fatigue, duty cycles, and women‑safety norms as non‑negotiable contractual constraints rather than vendor “manageables.” Legal should embed explicit caps on shift lengths, night‑shift rules, escort policies and rest periods that reflect Motor Vehicles and labour/OSH expectations, and then tie substitution rules to those same caps. Procurement should avoid clauses that allow penalties for no‑show while remaining silent on how the vendor met duty-cycle limits, because this silently rewards unsafe practices.
A practical balance comes from designing substitution rules with multiple levers instead of a single “produce a cab or pay” trigger. The contract can allow secondary vendors, pre‑approved standby fleets, or temporary routing relaxations during disruptions, while explicitly prohibiting breach of rest-hour or night‑shift safety norms as a means of meeting OTP. Outcome‑based commercials should therefore consider OTP, incident rates, and audit findings together, so vendors are not pushed to hit time metrics at the expense of safety.
images:
What early warning signs tell us driver churn is about to rise and OTP will drop, and what actions should ops take before night-shift escalations begin?
B1303 Early warnings for driver churn — In India enterprise Employee Mobility Services (EMS), what are good “early warning” indicators that driver churn is about to spike (and OTP will degrade), and how should an operations team operationalize those indicators into governance actions before the night-shift escalations start?
In Indian enterprise Employee Mobility Services, early warning indicators for upcoming driver churn and OTP degradation are visible in driver behavior, asset utilization, and exception patterns well before resignations or no-shows occur. Operations teams should treat these indicators as control-room signals, wire them into daily dashboards, and hard-code governance actions and SOPs that trigger automatically when thresholds are breached.
First, driver fatigue and disengagement show up in operational metrics. A rising Driver Fatigue Index, increasing late logins to first duty, more last-minute duty refusals, and a growing share of single-shift or partial-shift attendance are all precursors to churn. A common pattern is a gradual rise in short-notice roster changes, substitution requests, and increased dependency on buffer cars to protect OTP. Safety and behavior signals also worsen early. Near-miss incidents, speeding and harsh-braking alerts from IVMS, more geofence violations, rising complaint volume naming the same drivers, or repeated route-adherence deviations indicate stress and disengagement, not just bad behavior.
Second, economics and utilization typically move before exits. A drop in Revenue per Cab or Vehicle Utilization Index, growing dead mileage, frequent long unpaid waits, or duty cycles that regularly breach rest norms increase perceived unfairness and push drivers to aggregators or alternate employers. Vendor-level indicators matter too. Sudden increases in “replacement vehicle requested,” delays in vehicle induction, slower closure on minor maintenance issues, or more billing disputes from a particular vendor usually precede a wave of driver exits from that supply pool.
To operationalize this, organizations need a simple, explicit playbook inside the command center rather than ad-hoc responses. The fleet and driver data that many EMS platforms already capture for OTP and compliance should be repurposed into a driver-stability view that aggregates fatigue, utilization, safety alerts, complaints, and roster adherence per vendor and site. Thresholds should be defined for each signal and agreed in advance with vendors and internal stakeholders. Examples include maximum permissible DFI score per week, caps on consecutive night duties, limits on near-miss or speeding alerts per 1,000 km, and minimum utilization and earning benchmarks per driver per month.
When these thresholds are crossed, the system should auto-create operational tasks tied to clear SOPs. For fatigue and safety breaches, that means enforced rest windows, temporary route reassignment, mandatory counselling or refresher training, and short-term increase of standby vehicles in vulnerable timebands. For economic and utilization risks, that means revisiting roster and route design to reduce dead mileage, improving seat-fill, rebalancing trips across vendors, and running joint reviews with specific vendors to correct payout anomalies or duty patterns. Buffer capacity policies should be formally linked to risk scores so that sites with deteriorating driver indicators automatically get increased standby cover before OTP is visibly hit.
Governance actions should be plugged into recurring forums instead of waiting for crises. Weekly driver-stability reviews with vendor partners using a standard scorecard, monthly QBRs that correlate driver risk indicators with OTP and incident logs, and a live risk register at the command center help ensure that leadership hears about “near misses” in driver supply before hearing about missed cabs and night-shift escalations. HR, EHS, and Procurement should all see the same evidence so that adjustments to escort policies, incentive schemes, or commercial terms are grounded in shared data rather than anecdote. Structured Business Continuity and Contingency Plans that already exist for strikes, disasters, or technology failures can be extended to include driver-supply shocks, with pre-defined levers for spot-sourcing, cross-city reallocation, or temporary commercial relaxations to stabilize supply.
In practice, an effective pattern for operations teams is to manage a compact set of driver risk KPIs alongside OTP and incident metrics on the command-center dashboard, and to codify three tiers of response intensity. A first tier of alert triggers soft actions like extra briefings and closer supervision. A second tier adds hard controls like enforced rest and temporary duty caps. A third tier escalates to vendor and internal leadership, activates buffer capacity, and may temporarily accept controlled cost increases to protect night-shift safety and OTP. This structure keeps control in the hands of the transport head and command center rather than leaving them to firefight after OTP has already degraded and HR or Security are facing escalations.
For executive car rentals, how do we set fleet and chauffeur standards and substitution rules that protect exec experience without causing cost blowouts or lots of exceptions?
B1304 Executive fleet standards and exceptions — In India corporate car rental services (CRD) for executives, how should an admin/travel desk define fleet governance standards (vehicle class, cleanliness, chauffeur behavior, substitution rules) so executive experience is protected without creating cost blowouts or constant exceptions?
In corporate car rental services for executives in India, fleet governance works best when vehicle, chauffeur, and substitution standards are pre-defined by policy tier and enforced through SOPs and audit, not ad‑hoc exceptions. Admin and travel desks should lock these standards into contracts, apps, and duty slips so every trip follows the same rules, and cost or upgrades are handled by tiered entitlements instead of case‑by‑case approvals.
Admin teams can define vehicle standards by creating a clear class matrix linked to executive grades. Each grade gets a pre-approved vehicle category and age band, with baseline comfort and safety features mandated through fleet compliance and induction checks. Fleet compliance processes in the collateral show pre-induction essential checks and maker–checker validation for documentation and fitness, which admins can convert into minimum standards for executive vehicles to avoid surprise downgrades or unreliable older cars.
Cleanliness and condition should be treated as checklist items rather than preference. The “Safety Inspection Checklist for Vehicle” and “Fleet Compliance & Induction” collaterals describe structured inspection points for documents and mechanical condition. Admin can extend these to visible interior condition and amenities and mandate periodic audits and quality scores as part of vendor and statutory compliance. This reduces subjective complaints and lets the travel desk enforce non‑compliance penalties without debate.
Chauffeur behavior standards should rely on the existing driver assessment, compliance, and training frameworks. The “Driver Assessment & Selection Procedure (DASP),” “Driver Compliance & Induction,” and “Driver Management & Training” materials describe a full stack of background checks, POSH and customer-handling training, and ongoing performance monitoring. Admin can define that only drivers who pass this stack and maintain a threshold feedback score are allowed on executive trips, using RNR and refresher training to sustain quality while protecting driver morale and retention.
Substitution rules should be codified to protect experience and cost simultaneously. Evidence from “Business Continuity Plan,” “Vehicle Deployment & Quality Assurance,” and “WTiCabs – Support for Corporates” shows use of standby cars, buffer fleets, and rapid deployment playbooks. Admin can specify that any substitution must be same‑class or one‑class higher at vendor cost, with clear emergency downgrade rules requiring pre‑approved justification and documented in the shift or trip report to prevent exception creep and cost disputes.
To keep costs controlled and avoid constant exceptions, standards should be embedded in commercial and operational models rather than handled manually. Billing models and cost frameworks in the collateral show per‑km, per‑trip, and monthly rental structures with tariff mapping and centralized billing. Admin can align executive entitlements to these models, use benchmarking and year‑over‑year cost reduction targets from the “Cost 2” slide, and enforce no‑surprise pricing through all‑inclusive or pre‑agreed tariffs. This allows high standards for executives without unplanned upgrades, because any deviation is either vendor’s cost or a formally approved, budgeted exception.
images:
.JPG)
When ops wants strict rules and HR wants a smoother experience, where should we be rigid and where can we be flexible to protect OTP and morale?
B1305 Rigid vs flexible governance choices — In India Employee Mobility Services (EMS), when operations wants strict governance and HR wants a smoother employee experience, how should a senior sponsor decide where to be rigid (onboarding, safety checks) versus flexible (substitutions, exceptions) to protect both OTP and morale?
In Indian Employee Mobility Services, senior sponsors should enforce rigidity on anything that protects life, law, and auditability, and allow flexibility only on elements that affect comfort, convenience, and short-term continuity. Rigid guardrails sustain OTP and liability protection, while controlled flex points absorb real-world chaos and protect morale.
Rigid rules work best where failure has irreversible or regulatory consequences. Rigid governance is critical for driver and fleet onboarding, KYC and PSV validation, women-safety and night-shift protocols, route and geo-fence approvals, and business continuity playbooks. These controls need codified SOPs, automated checks, and immutable audit trails, and operations teams should not be allowed to override them during peak pressure or escalations.
Flexibility is safer on how service is delivered, not whether it meets core standards. Flex rules can cover short-notice substitutions within a pre-vetted driver and vehicle pool, dynamic routing within pre-approved corridors, seat pooling and cab sharing norms, and hybrid-work fluctuations in roster cut‑off times. These flex points should be policy-driven with clear eligibility, caps, and escalation paths, so that exceptions remain predictable and do not erode baseline governance.
A practical approach is to classify every EMS rule into three buckets. Senior sponsors can define a non-negotiable layer tied to compliance, safety, and data integrity. They can define a conditional-flex layer where operations can deviate under documented triggers with automatic logging and approval. They can define a user-experience layer where HR and Transport can iterate frequently, based on commute feedback, CEI/OTP metrics, and complaint patterns, without touching the core assurance spine.
images:
How do we structure governance and reporting so transport ops isn’t unfairly blamed for OTP misses that are really due to vendor driver shortages?
B1306 Defensible accountability for OTP misses — In India enterprise employee transport, what’s the best way to structure responsibility so a Facilities/Transport Head isn’t personally blamed for OTP misses caused by vendor driver shortages, and how should governance and reporting make accountability clear and defensible?
The most effective way to protect a Facility / Transport Head from unfair blame is to formalize a shared-responsibility model in contracts and governance, with OTP tied to clearly defined vendor obligations, internal dependencies, and a central command-center view of exceptions. Responsibility becomes evidence-based and role-based, not opinion-based after a bad shift.
Governance works best when OTP is defined as a joint KPI with split accountability. Vendor SLAs should own fleet availability, driver count, credentialing, and buffer capacity. The enterprise transport team should own accurate rosters, shift windows, and timely approvals. A 24x7 command center or NOC should own real-time monitoring, escalation, and incident logging. Each leg needs documented SOPs so every exception is traceable to a breach in a specific responsibility, not a person.
To make accountability defensible, organizations need a governed reporting layer. OTP dashboards should show planned vs deployed vehicles, driver shortages, no-shows, and last-minute roster changes as separate root-cause codes. Exception-to-closure times, vendor SLA breaches, and internal process delays should be visible in a single report pack that goes to HR, Procurement, and leadership. A common failure mode is having only topline OTP% without cause codes, which turns every miss into a political argument.
Clear R&R documents, escalation matrices, and quarterly vendor governance reviews should explicitly state who owns which part of reliability. When incident reviews use this data and structure, the Facility / Transport Head is evaluated on whether governance ran as designed, while vendor performance and internal policy gaps are assessed on their own merits.
How do we run monthly/quarterly driver and fleet reviews so they lead to real actions—coaching, removals, retraining, vehicle replacement—instead of becoming a ritual meeting?
B1307 Make governance reviews action-driven — In India corporate Employee Mobility Services (EMS), how should an enterprise set up periodic governance reviews (monthly/quarterly) for driver performance and fleet health so the process produces decisions (coach, remove, retrain, replace vehicles) rather than becoming a ritual meeting with no consequences?
In corporate Employee Mobility Services in India, governance reviews only drive action when they are built around a small, fixed KPI set, pre-agreed decision thresholds, and a clear “owner + action + due date” for every variance. Reviews must explicitly connect driver performance and fleet health metrics to consequences such as coaching, route reassignment, off-boarding, or vehicle replacement.
A common failure mode is to let monthly reviews become reporting rituals. Transport teams then narrate incidents and OTP numbers without a structured link to driver rosters, vendor scorecards, or fleet replacement plans. Most organizations avoid hard decisions when thresholds and escalation paths are not defined in advance and when Procurement, HR, and vendors are not in the same room.
The most effective pattern is to treat the review like a control-room checkpoint rather than a presentation. A short, standard deck from the command center or transport desk should show OTP, incident rate, Trip Adherence Rate, Driver Fatigue-linked issues, vehicle uptime, and compliance currency at driver and vehicle level. The central command-center and compliance dashboards described in the context are suitable sources, because they already consolidate GPS, alert supervision, driver compliance, and vehicle fitness.
Enterprises should define a small set of red-line triggers that automatically require an action decision. Typical examples are repeat safety incidents for a driver, repeated geo-fence or over-speeding alerts, vehicle uptime below an agreed threshold, or expired documentation identified by centralized compliance management. Each trigger should have a predefined menu of actions such as targeted coaching, temporary removal from night shifts, full retraining under existing driver training modules, or permanent de-induction of drivers and vehicles using the fleet and driver compliance frameworks.
To avoid “no consequence” meetings, the governance forum should record every exception as a ticket with an owner and a closure SLA. Subsequent reviews should begin by checking closure on previous actions before moving to fresh data. This approach aligns with the industry’s focus on continuous assurance and audit-ready safety culture, and it keeps the Facility or Transport Head in proactive control instead of constant firefighting.
How do we avoid lock-in around driver/fleet governance data like onboarding and performance history so we can switch vendors without losing continuity?
B1308 Avoid lock-in of governance data — In India corporate ground transportation, what are practical ways to prevent vendor lock-in specifically around driver and fleet governance data (onboarding records, performance history, substitutions), so Procurement and IT can switch vendors without losing operational continuity?
In corporate ground transportation in India, the only reliable way to avoid vendor lock-in on driver and fleet governance data is to make portability and independent ownership of that data a core requirement in contracts, integrations, and operating processes. Procurement and IT need to treat trip, driver, vehicle, and compliance records as “enterprise master data” instead of something that lives only inside a vendor’s system.
Procurement can mandate in RFPs that all driver KYC/PSV records, onboarding checks, compliance status, and performance history are stored in an exportable, standardized schema. Contracts can define that trip logs, GPS trails, incident reports, fatigue indices, and substitution records are enterprise-owned and must be available via APIs and periodic dumps. A common failure mode is accepting PDFs and ad-hoc reports as “data,” which breaks continuity during vendor transitions.
IT teams can push for an API-first architecture and a mobility data lake, where driver and fleet identifiers, telematics, and governance metrics are synchronized from all vendors. This type of integration fabric reduces dependence on any single provider’s UI. Independent keys for driver, vehicle, and route help preserve continuity when switching from one fleet aggregator to another.
Organizations improve resilience when they separate governance from execution. A central command center or NOC can operate on normalized data feeds from multiple vendors, preserving SLA tracking, OTP%, fatigue risk and incident analytics even as vendor mix changes. Vendors then become replaceable execution layers under a stable governance and observability layer.
Practical safeguards include: - Explicit data-ownership and export clauses for all driver, vehicle, and trip records. - Standardized schemas for onboarding, compliance, and performance KPIs across vendors. - Periodic full data extracts plus real-time APIs into an internal data lake. - Command-center tooling that reads normalized data rather than a single vendor’s proprietary structures.
For a new site launch, what’s the minimum driver governance we need—onboarding, incentives, substitutions—to avoid night-shift chaos without making it too complex to follow?
B1309 Minimum governance for new sites — In India enterprise employee commute operations, what’s a realistic “minimum viable” driver governance model for a new site launch (onboarding, incentives, substitutions) that prevents night-shift chaos, without overbuilding a complex framework that teams won’t follow?
A realistic minimum viable driver governance model for a new India site launch focuses on a few non‑negotiable controls across onboarding, daily allocation, and escalation, rather than a complex policy book. The model must harden night‑shift reliability and safety through simple, checkable steps that a transport team and vendors can actually run every day.
A practical baseline starts with structured onboarding using a defined Driver Assessment & Selection Procedure. The model should require documented background checks, licence verification, address and criminal record checks, and a short, mandatory induction on traffic laws, POSH and women‑safety handling, and customer behaviour, as described in the DASP and driver compliance collaterals. The onboarding should end with a simple “fit for night duty” list that transport can see at a glance, supported by periodic audits.
Daily governance should concentrate on an operationally light control room model. A single transport command centre view, supported by a driver app, ensures every night driver has visible trips, real‑time navigation, and an SOS path, while the command centre watches basic alerts like overspeeding or route deviation via an alert supervision system. This reduces manual chasing of drivers and gives early warning on fatigue, route issues, or no‑shows.
Substitution and incentives should be codified as SOPs rather than ad‑hoc phone calls. A buffer pool of pre‑onboarded standby drivers and vehicles, backed by a simple escalation matrix, enables quick swaps when a driver drops out, aligning with business continuity plans that call for additional vehicles and backup arrangements. Incentives should reward consistent on‑time performance, safety adherence, and complaint‑free trips, while penalties or retraining trigger automatically after defined breaches captured in management reports and command‑centre logs.
Transport heads should keep governance artifacts short and visible. These include a one‑page night‑shift driver checklist, a clear escalation ladder for 2 a.m. issues, and a simple dashboard of on‑time performance, incident reports, and driver compliance status. This minimum framework stabilizes night operations, gives HR and Security auditable confidence, and avoids over‑engineering that front‑line teams cannot realistically maintain over long shifts.
How can HR check if better driver onboarding and performance governance is actually improving attendance and reducing manager complaints, not just making dashboards look better?
B1310 Connect governance to attendance stability — In India Employee Mobility Services (EMS), how can HR measure whether changes in driver onboarding and performance governance are improving attendance stability and reducing manager complaints, rather than just improving mobility dashboards?
In India Employee Mobility Services, HR can measure the impact of better driver onboarding and performance governance only by tying driver-related changes to HR-linked metrics such as attendance stability, late-login patterns, and manager complaints, instead of stopping at fleet OTP and app dashboards. HR should treat mobility data as an input, and attendance and grievance trends as the outcome that validates whether governance changes are actually working.
HR teams gain clearer insight when they correlate command-center metrics like On-Time Performance and Trip Adherence Rate with HRMS data on shift adherence and absence rates. This correlation helps HR see whether fewer routing failures and better driver compliance are translating into fewer late logins and fewer short-absence patterns. A common failure mode occurs when HR celebrates improved transport OTP on dashboards but ignores that manager complaints and employee NPS about commute still remain high.
A practical approach is to define a small set of “bridge KPIs” that sit between transport and HR. Example bridge metrics include late-logins per 100 trips by route or shift, commute-linked manager complaints per month, and night-shift no-shows tagged as transport-related. These bridge metrics can be trended before and after driver induction changes, such as stricter KYC/PSV checks, structured training, or fatigue management rules.
It is useful when HR, Transport, and Security jointly review incident logs, SOS events, and women-safety escalations alongside driver performance reports. This joint review makes it possible to see if improved onboarding and continuous training are reducing safety-related incidents and grievance reopenings. HR can then present a single narrative to leadership that shows how operational governance around drivers is stabilizing attendance and reducing noise from line managers, not just improving mobility dashboards.
What’s the best way to manage driver exception requests—like an employee refusing a driver/vehicle—so we protect trust but don’t drown ops in one-off cases?
B1311 Process for driver exceptions — In India corporate ground transportation operations, what’s the most effective way to handle “driver exceptions” (employee refuses driver/vehicle, repeated complaints) so the process protects employee trust while preventing the operations team from being overwhelmed by one-off requests?
In Indian corporate ground transportation, the most effective way to handle driver exceptions is to run a structured, tiered SOP that separates genuine safety or pattern issues from one-off discomfort, anchors all actions in data and audit trails, and routes only validated cases to escalation. A predictable, tech-backed workflow protects employee trust while preventing the transport team from being pulled into ad-hoc, emotional decisions every shift.
A common failure mode is treating every refusal as a one-off negotiation between employee, driver, and vendor. This quickly overwhelms the control room and erodes consistency. Instead, organizations benefit when they define clear “exception types” such as red-flag safety concerns, service-quality complaints, and preference-only issues, and then hard-wire different treatments for each into their employee app, driver app, and command center workflow.
The command center should receive all exceptions via a single channel with mandatory fields. Each incident should be linked to trip ID, driver ID, time band, and GPS trail from systems like an Alert Supervision System or Transport Command Centre. This enables pattern detection, for example repeated complaints against a specific driver across different employees, or recurring refusals from a specific employee across multiple drivers.
Practical safeguards usually include:
• A strict, immediate override rule for safety or POSH-linked complaints.
• Temporary driver suspension from the roster when repeated, corroborated incidents occur.
• Thresholds for “no-serve lists” on both sides, where either a driver is barred from a site or an employee can no longer refuse without managerial approval.
Most organizations combine this with structured driver training, compliance checks, and reward-and-recognition for high-rated drivers. That balance reduces emotional escalations, keeps OTP and fleet uptime stable, and signals to employees that genuine concerns will be taken seriously without turning every discomfort into a shift-breaking exception.
images:

For our shift-based employee transport, how can we tell if OTP issues are mainly due to driver churn vs planning issues, and what proof should we ask the vendor for?
B1312 Separating churn vs planning — In India employee mobility services (EMS) for shift-based corporate transport, how do you diagnose whether on-time pickup (OTP) instability is primarily a driver retention problem versus a routing/rostering problem, and what evidence should HR and Transport Ops ask vendors to provide to avoid blaming the wrong root cause?
In Indian employee mobility services, recurring OTP instability is usually a routing/rostering problem if vehicles and drivers are available but assignments, sequencing, and buffers are weak, and it is usually a driver retention problem if there are frequent last-minute no-shows, high attrition, and chronic under-supply in specific timebands. HR and Transport Ops should insist on trip-level data, timeband-wise supply–demand views, and vendor-side workforce metrics before attributing blame to drivers or “bad traffic.”
OTP instability linked to routing and rostering shows specific patterns. Vehicles start late despite being available. Routes are too long for the shift window. Seat-fill is low while dead mileage is high. There are frequent reassignments within a shift and clustering of delays on complex routes or new sites. A strong routing engine with HRMS integration, as used in EMS platforms like Commutr and WTi’s ETS Operation Cycle, should be able to show planned vs actual ETAs, trip adherence rate, and where dynamic recalibration was triggered.
OTP instability linked to driver retention and supply shows different signatures. There are repeated last-minute cancellations by the same vendor pockets. Night shifts and unpopular routes chronically run short of assigned cabs. Substitute vehicles arrive without proper induction, raising compliance and safety risks. Driver fatigue incidents and complaint rates climb before OTP collapses. Vendors with structured Driver Management & Training, DASP processes, and reward programs can evidence stable duty cycles and lower driver attrition.
HR and Transport Ops should ask vendors for specific evidence packs before concluding root cause. These include shift-wise OTP and Trip Adherence Rate with route-level breakdowns. They need Vehicle Utilization Index, Trip Fill Ratio, and dead mileage to see if routing is efficient. They should demand driver roster stability data, including absenteeism, attrition by timeband, and average duty hours, to assess workforce stress and retention. They should review incident and exception logs from the command center, such as alert supervision and SOS dashboards, to understand escalation and recovery times.
They should also require proof of governance and continuity practices. This includes documented business continuity plans, buffer vehicle policies, and escalation matrices. It should include evidence of centralized command-center monitoring, daily shift briefings, and management of on-time service delivery that uses traffic trend analysis. Vendors ought to share sample compliance dashboards that link OTP, safety incidents, and driver credential currency on a single window.
If routing and rostering are the issue, OTP improves as soon as dynamic route optimization, better seat pooling, and realistic buffer times are implemented. If driver retention is the issue, OTP stabilizes only when duty cycles, incentives, and training are adjusted and when onboarding and compliance processes are tightened. A common failure mode is blaming “drivers” without checking whether the vendor’s routing engine, command center, and fleet planning actually support predictable, fatigue-safe operations.
images:
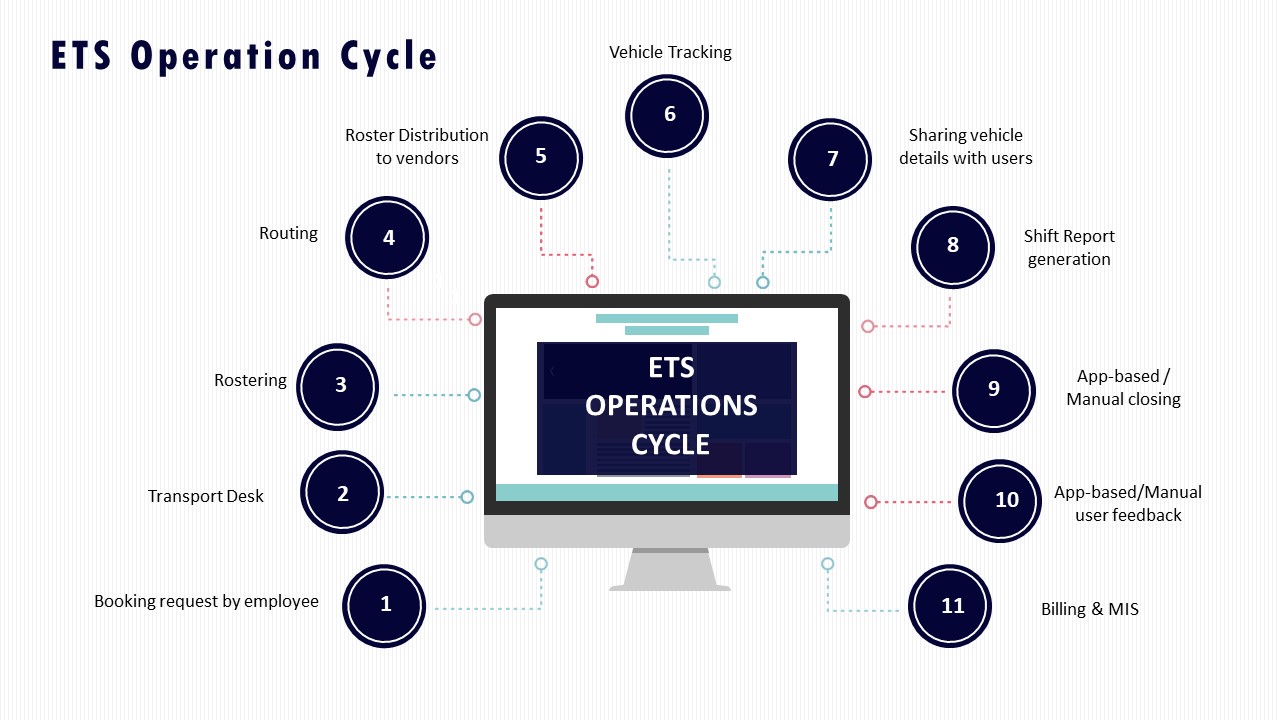


What driver governance practices reduce daily rider complaints without adding a lot of admin work for our transport team?
B1313 Reducing complaints without admin — In India corporate ground transportation for employee mobility services (EMS), what governance mechanisms actually reduce daily employee complaints about drivers (behavior, cancellations, late arrivals) without creating so much administrative overhead that the Transport Head’s team burns out?
In corporate employee mobility services in India, daily driver-related complaints reduce sustainably when governance combines three elements. These elements are clear SOPs for drivers, real-time command-center visibility, and outcome-linked vendor governance that is simple to operate from a transport control room. Administrative overhead stays manageable when controls are automated in tools like routing platforms, command centers, and alert systems instead of being run by spreadsheets and manual follow-ups.
The most effective baseline is a defined driver lifecycle that is enforced centrally. Driver assessment and selection procedures that include written tests, practical driving checks, and soft-skills evaluation reduce behavior complaints at the source. Structured compliance and induction processes with documented checks on licensing, background, health, and specialized training create a continuous filter for unsafe or unsuitable drivers. Refresher training, women-safety protocols, and rewards and recognition programs for good behavior keep standards from degrading over time.
Centralized command and alert supervision systems give the Transport Head real-time levers instead of post-facto firefighting. A 24/7 command center with geofencing, over-speeding, and device-tampering alerts enables early intervention when drivers deviate, so complaints do not escalate into incidents. Dynamic route optimization and traffic-aware planning, as used in monsoon case studies delivering 98% on-time arrivals, tackle late arrivals proactively rather than relying on manual rescheduling. An integrated dashboard with trip tracking, deviations, and service reports provides a single window for monitoring instead of multiple fragmented tools.
Vendor and fleet governance work best when they are based on simple, repeatable rules. Centralized compliance management systems that track vehicle and driver documents with automated reminders reduce manual chasing. Vendor and statutory compliance frameworks that specify audits, Maker–Checker checks, and corrective actions prevent repeated complaints about the same operators. Business continuity and contingency plans for cab shortages, technology failures, and strikes ensure that cancellations are handled via predefined buffers and alternate supply, not ad-hoc calls at shift start.
To avoid burning out the Transport Head’s team, governance mechanisms should be configured as SOP blocks rather than case-by-case decisions. Practical patterns include: • Standardized driver scoring linked to training and RNR instead of ad-hoc punishment. • Fixed escalation matrices and command-center playbooks for late arrivals, route deviations, and no-shows. • Indicative management reports that summarize exceptions, vendor performance, and user feedback so leadership sees trends, not raw noise.
When driver governance, command-center observability, and vendor compliance sit on a single platform with rider, driver, and admin apps, daily employee complaints drop while the transport team works from alerts and dashboards instead of reactive phone calls.
For night shifts, how should we set up driver onboarding and re-checks so they’re audit-ready but still practical at scale?
B1314 Audit-ready driver verification — In India employee mobility services (EMS) for night-shift employee transport, how should an EHS/Security lead evaluate driver onboarding and periodic re-verification (KYC/PSV, incident history, training) so that duty-of-care controls are auditable while still being operationally feasible at scale?
In Indian employee mobility for night shifts, an EHS/Security lead should treat driver onboarding and re-verification as a recurring, evidence-backed control loop rather than a one-time checklist, with every control leaving a verifiable, time-stamped trail that is queryable by auditor, investigator, or leadership.
A common failure mode is relying on manual files and vendor assurances without a centralized compliance dashboard. This usually breaks during incidents when the organization cannot quickly prove that KYC, PSV badge, background checks, and training were valid at the time of the trip. An audit-ready model links each trip to the exact driver credential set, training status, and incident history visible through a transport command centre or equivalent compliance system.
Operational feasibility at scale improves when verification workloads are stratified by risk and frequency. High-risk attributes such as criminal checks, address verification, and licence validation are done at onboarding and then revalidated on a fixed annual or semi-annual cadence. Currency checks such as PSV badge validity, medical fitness, and refresher training completion are governed through automated alerts and maker–checker processes as described in centralized compliance management collateral. This reduces manual chasing while keeping high-risk lapses rare and discoverable early.
EHS/Security leads should require that vendors adopt standardized onboarding frameworks similar to the Driver Assessment & Selection Procedure (DASP), with documented VIVA, written, and practical evaluations. Evidence of POSH and customer handling training, defensive driving, seasonal training (for monsoon or other conditions), and periodic refresher modules must be recorded in a driver management and training system, not just sign-in sheets. This allows security teams to correlate specific incident patterns with training gaps and update curricula systematically.
Incident history management should be tightly integrated with alert supervision systems and the command centre. Every over-speeding alert, geofence violation, fixed device tampering, SOS trigger, or complaint is logged against a driver profile and closed with a root-cause and corrective action. EHS/Security can then use this longitudinal profile to define tiered responses: coaching and warnings for first-level deviations, temporary suspension and retraining for repeated issues, and permanent debarment for serious safety or women-safety violations. This helps demonstrate proportionality and learning when questioned by regulators or internal audit.
To keep controls feasible for large fleets and multi-vendor setups, the EHS/Security lead should push for: a single compliance dashboard covering driver and vehicle documentation, automated expiry alerts feeding into operations planning, and integration with routing and dispatch so that non-compliant drivers cannot be assigned to night-shift or women-only routes. This reduces the burden on transport teams who otherwise track compliance in spreadsheets and ensures duty-of-care is embedded into everyday operations instead of added on top.
images:
substitution, escalation, and vendor accountability
Defines substitution rules, escalation paths, authority, and anti-shadow onboarding to ensure rapid responses without finger-pointing.
When vendors say they have driver substitution rules, what usually goes wrong, and how can we test this in a pilot to avoid unapproved substitutions?
B1315 Testing substitution rules in pilots — In India corporate employee mobility services (EMS), what are the most common failure modes when a vendor claims they have strict driver substitution rules, and how can a Facility/Transport Head test those rules in a pilot to avoid ‘ghost substitutions’ that break OTP and safety compliance?
In Indian corporate employee mobility services, vendor “strict driver substitution rules” often fail because controls exist on paper but not in daily dispatch execution, real-time monitoring, or audit trails. The weakest links are usually manual workarounds at the vendor yard, gaps in command-center observability, and lack of traceable linkage between the rostered chauffeur, the vehicle, and the trip log.
Common failure modes include driver swaps after initial allocation that are never updated in the roster or app, incomplete or expired driver KYC and PSV details for substitute drivers, and call-centre agents overriding rules under pressure to “save” OTP. Another frequent pattern is weak integration between driver compliance systems and the dispatch engine, so non-compliant or untagged drivers can still be assigned. Many vendors also lack tamper-evident audit trails, so it is impossible to reconstruct who actually drove a specific trip when incidents occur.
A Facility or Transport Head can test these rules in a pilot by designing substitution as an explicit, measured scenario rather than assuming it will work. The pilot should enforce trip-level mapping of driver ID, vehicle ID, and route, and require that any change triggers an automated alert to the command center and a refreshed manifest on the driver and employee apps. It is important to demand random route adherence audits, surprise physical checks at departure hubs, and reconciliation of driver compliance logs with trip data on a weekly basis. Facility teams should also track OTP and incident metrics separately for original vs substituted drivers, and they should insist on access to raw audit logs so they can detect unreported swaps. Solutions with centralized compliance management, driver onboarding checks, and command-center based alert supervision make these tests easier to operationalize and keep “ghost substitutions” from silently eroding OTP and safety compliance.
How do we set up driver performance reviews so they actually improve OTP and rider experience, not just create paperwork that gets gamed?
B1316 Performance reviews that change outcomes — In India corporate ground transportation for employee mobility services (EMS), how should HR and Transport Ops structure driver performance reviews (scorecards, coaching loops, consequences) so that improvements show up in OTP and employee satisfaction rather than just creating paperwork that vendors ‘game’?
Driver performance reviews in Indian employee mobility work when they are built around a few hard operational KPIs tied to OTP and safety, use data streams that are difficult to manipulate, and trigger specific coaching or consequence actions on a predictable cadence. Reviews fail when they are form-heavy, vendor-owned, or detached from real trip and complaint data.
A practical approach is to anchor the driver scorecard in observable, tech-backed metrics. These metrics usually include on-time performance for pickups and drops, route adherence from GPS or IVMS logs, incident and complaint counts, and basic compliance such as valid documents and training currency. Organizations that combine these with fatigue and duty-cycle checks tend to see more stable OTP and fewer safety escalations.
The review loop needs to be owned jointly by the internal transport command center and the vendor. The internal command center already monitors real-time operations, alert supervision, and incident tickets. This same data can feed monthly driver performance summaries, which are then discussed in structured sessions that mix coaching, refresher training, and clear warnings where required.
Consequences must be standardized and pre-agreed in vendor SLAs. Typical levers include mandatory retraining after defined complaint thresholds, temporary suspension from night shifts for safety or punctuality issues, or removal from the account after repeated breaches. Rewards can balance this with recognition for high OTP and positive feedback to support driver retention.
A simple structure that HR and Transport Ops can operationalize is:
- A concise driver scorecard with a small set of weighted KPIs linked directly to OTP, safety incidents, and employee feedback.
- Monthly performance review and coaching sessions using data from the centralized command center and management reports.
- A transparent consequence and reward ladder for vendors and individual drivers that is written into contracts and communicated clearly.
When driver performance reviews are built on live operational data, governed by the internal command center, and linked to specific actions, improvements in driver behavior reliably surface in on-time performance and employee satisfaction instead of remaining as paperwork artifacts.
What driver incentives reduce cancellations/no-shows at peak shifts without pushing unsafe driving or risky shortcuts?
B1317 Incentives without unsafe behaviors — In India employee mobility services (EMS), what incentive design patterns for drivers reduce last-minute cancellations and no-shows during peak shift changes without encouraging unsafe driving or corner-cutting that increases incident risk?
In India EMS operations, the most reliable way to cut driver cancellations and no‑shows at shift change is to reward consistent, compliant trip completion over time and to penalize avoidable bail‑outs, while keeping all incentives explicitly de‑linked from speeding or risky shortcuts. Incentives must be tied to attendance, OTP, and safety compliance metrics aggregated across a defined period, not to raw trip counts or aggressive timing on individual runs.
A common failure mode is paying per-trip or per-OTP alone. This pattern pushes drivers to overbook, speed, or skip SOPs to “make the number”. Most organizations that stabilize peak shifts move to composite scorecards that include completed shifts, incident-free operations, and audit-readiness. These scorecards are anchored in data from driver apps, IVMS, and command-center monitoring and are reconciled with compliance dashboards and safety inspection logs.
A safer pattern is to use hard “gates” that must be met before any bonus is paid. One gate is zero major safety violations, including geo-fence breaches, over-speeding alerts, and tampering reported by an alert supervision system. Another gate is full driver KYC/PSV currency as shown in centralized compliance management and driver-compliance checks. A third gate is absence of critical complaints or SOS events attributable to driver behavior.
Within those gates, incentives can reward drivers based on period-level performance. Relevant measures include no unapproved cancellations during peak windows, adherence to roster and routing as visible in NOC dashboards, and consistent on-time arrival supported by dynamic route optimization rather than speeding. Integration with driver training and RNR programs reinforces that safe driving, POSH compliance, and seasonal hazard training are part of “good performance” and not optional.
Practical EMS structures often blend three elements. First, there is a fixed, predictable earning floor so drivers are not forced into risky behavior for income. Second, there is a modest, capped bonus for clean attendance and incident-free OTP in high-risk windows such as late-night shifts. Third, there are non-monetary rewards and recognition for exemplary safety and reliability, as seen in structured driver training and rewards collateral, which reduces pressure to game the system.
Clear SOPs and escalation matrices are critical adjuncts to incentives. Drivers need unambiguous rules about when they may decline a trip for safety, fatigue, or vehicle condition reasons without penalty. Command-center teams require playbooks for rapid substitution so that genuine safety refusals do not cascade into service failures. Without these safeguards, incentive schemes often backfire by silently pressuring drivers to run even when they or their vehicles are not fit for duty.
To keep incentives from drifting into unsafe territory, organizations should monitor a small set of joint KPIs. These include OTP and no-show rate, but also incident rate, driver fatigue indicators from duty-cycle data, and audit trail integrity for trips and compliance checks. Any improvement in cancellations that coincides with higher incident flags or safety complaints is a signal that incentives need recalibration or that training and supervision are not aligned with policy.
Finally, the most durable designs position incentives inside a broader “safety by design” framework. This framework uses pre-induction checks for drivers and vehicles, recurring training modules, safety inspection checklists for vehicles, and continuous monitoring via transport command centres. In that context, incentives become a reinforcing signal rather than the primary control, and peak-shift reliability is achieved through a combination of early alerts, strong SOPs, and data-backed governance instead of sheer financial pressure on drivers.
How can Finance verify driver incentives/penalties are calculated correctly and tied to trip outcomes, so we avoid disputes and audit issues?
B1318 Audit-proof incentive calculations — In India corporate ground transportation for employee mobility services (EMS), how can a CFO verify that driver incentives, penalties, and performance-linked payments are calculated correctly and are traceable to trip outcomes, so Finance isn’t exposed to disputes or audit findings later?
In employee mobility services in India, a CFO can verify driver incentives, penalties, and performance-linked payments by insisting that every rupee flows from a common, auditable trip ledger that reconciles vendor contracts, trip data, and Finance systems. Finance reduces dispute risk when driver payouts are derived from clearly defined SLAs, are computed by rule-based engines rather than spreadsheets, and can be sampled back to underlying trip events, GPS logs, and approved rosters.
A robust approach starts with contract design. Organizations specify incentive and penalty logic in outcome-linked terms such as On-Time Performance, Trip Adherence Rate, incident-free trips, and utilization metrics. Each rule is written in unambiguous formulas that can be encoded in systems, including thresholds, caps, and rounding rules. This reduces scope for interpretation when trips are later evaluated.
Data integrity is critical. Driver performance calculations rely on a single trip lifecycle record that captures rostered shift, planned route, actual timestamps, GPS traces, exceptions, and closure actions. A centralized command center and mobility platform generate these records in real time and preserve audit trails. Telemetry, SOS events, and route deviations are logged with timestamps so that “what actually happened” is reconstructable.
The CFO needs traceability into calculation logic. Performance-linked pay engines should read from this trip ledger and apply the same incentive and penalty rules that exist in the contract. Each driver payout line can be expanded to show the underlying trips, KPIs achieved or missed, and the rule that generated the amount. This links abstract SLAs directly to specific rides.
Controls are strengthened when billing, incentives, and penalties share the same data foundation. Vendor invoices, driver incentive summaries, and internal MIS draw from the same trip dataset. Finance can then use standard checks such as random sampling of trips, cross-verification of OTP numbers against dashboards, and reconciliation of aggregated KPIs with payouts. Discrepancies indicate either data-quality problems or misconfigured rules.
To keep audits clean, organizations implement formal governance. A defined SLA and incentive governance framework identifies which department owns rule changes, how exceptions are approved, and how often rules are reviewed. Periodic reviews with HR, Transport, and Procurement align operational realities with financial exposure. Evidence packs, including trip logs, GPS trails, and calculation reports, are retained under auditability norms so that historical payouts can be defended to internal and external auditors.
images:
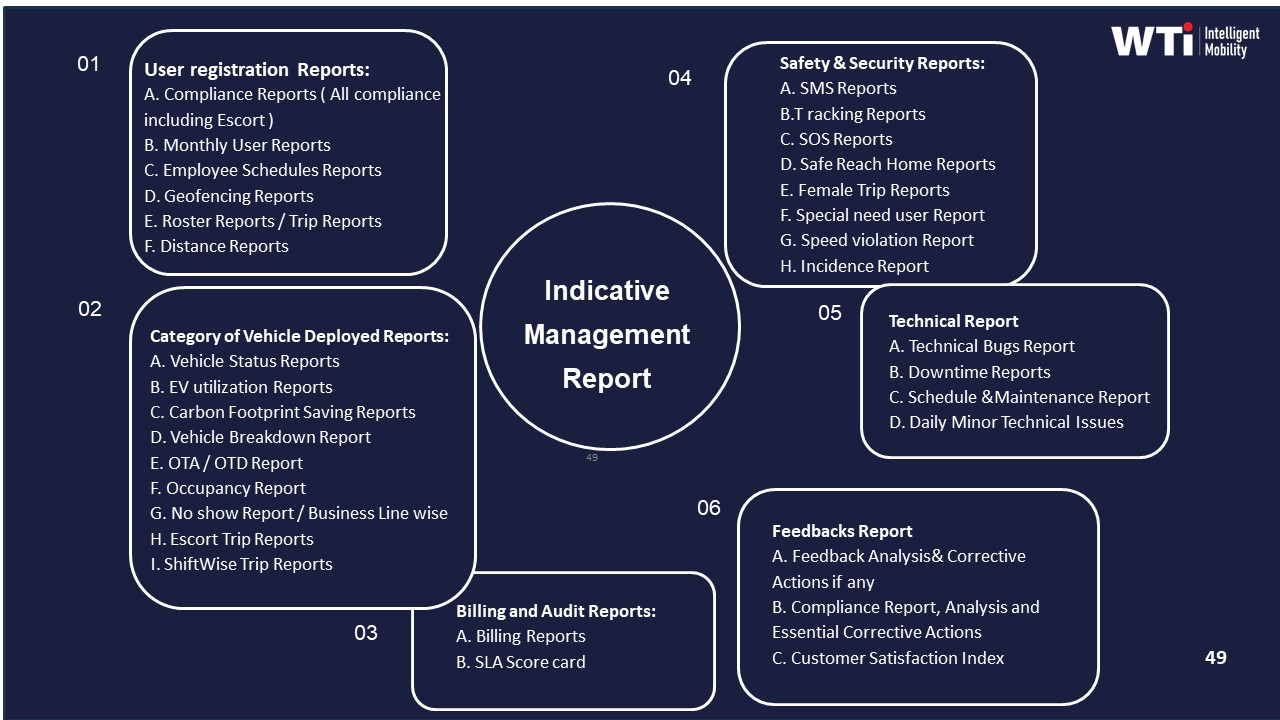
If a driver keeps getting complaints but we can’t replace them right away, what escalation and interim controls should we use so HR doesn’t take the heat?
B1319 Managing bad drivers under constraints — In India employee mobility services (EMS), what’s a realistic escalation path when a driver repeatedly triggers employee complaints but operations can’t remove them immediately due to supply constraints, and how do mature programs keep HR credibility intact during that gap?
In Indian employee mobility services, mature programs use a dual-track escalation path. The driver is immediately put under tighter controls, retraining, and monitoring, while vendor management and routing are adjusted to phase the driver out as soon as supply allows. HR credibility is protected when every step is codified in SOPs, logged in systems, and visible to HR through dashboards and reports.
A realistic escalation path typically uses four operational moves in parallel. Operations first treat repeated complaints as a safety and service-risk signal, not just “noise”. The driver is flagged in the system, assigned for targeted counselling or refresher training, and put on a structured “observe and improve” window with more frequent checks. Command-center style alert supervision, with over-speeding, route deviation, or device tampering alerts, is activated more aggressively for that driver. Trip allocation is then constrained so the driver is removed from the most sensitive use-cases first, such as women-only or late-night routes, while standby or buffer vehicles from the Business Continuity Plan are used to cover the riskiest shifts.
Mature EMS programs keep HR credibility intact by giving HR clean evidence and clear status, even before the driver is fully removed. Complaint trends, counselling sessions, and route changes are documented in centralized compliance and safety systems and surfaced as part of indicative management reports. HR can then tell leadership and employees, “This driver is under review, these controls are in place, and here is the removal timeline anchored to buffer fleet and vendor capacity.” Governance models with defined escalation matrices, command-center oversight, and engagement reviews ensure Transport, HR, Security, and the vendor agree on when a driver moves from “under watch” to “off the roster”, so HR is never left defending vague promises.
What signs show a vendor is relying on a few key drivers and will struggle on OTP if they leave, and how can we test resilience before we sign?
B1320 Detecting star-driver dependency — In India corporate employee transport (EMS), what governance signals indicate a mobility vendor is over-dependent on a few ‘star drivers’ and will collapse on OTP when those drivers churn, and how should a Transport Head pressure-test resilience before signing?
Over-dependence on a few “star drivers” shows up as thin, personality-based governance rather than system-based operations, and it usually breaks OTP as soon as those individuals churn or fall sick.
One clear signal is when the vendor explains good OTP in terms of specific names instead of processes. Another signal is lack of a documented Driver Assessment & Selection Procedure, weak Driver Compliance & Induction checks, and no visible Driver Management & Training cadence. A third is when women-safety and night-shift performance are attributed to a small “trusted pool” instead of escort rules, routing policies, and command-center monitoring. These patterns indicate OTP is driven by a few dependable people, not by robust ETS Operation Cycles, Alert Supervision Systems, and centralized compliance management.
A Transport Head should pressure-test resilience by asking for hard evidence at the driver-program level rather than generic OTP reports. They should request anonymized driver-level tenure and attrition data, samples of DASP and refresher training records, and proof of periodic driver audits, rewards programs, and safety drills. They should also ask the vendor to walk through their Business Continuity Plan, especially what happens for cab shortages, political strikes, tech failures, or monsoon disruptions, and how standby fleets and associated businesses are activated without relying on particular drivers. Finally, they should simulate a “star-driver outage” scenario in the RFP: remove the top X drivers from a shift, then ask the vendor to demonstrate routing, replacement, and SLA governance via their command center, escalation matrix, and data-driven insights platform.
How should we draft driver/vehicle substitution and removal clauses so we can enforce standards fast during incidents without endless disputes?
B1321 Enforceable substitution contract clauses — In India employee mobility services (EMS), how should Procurement write substitution and removal clauses for drivers and vehicles so the enterprise can enforce standards quickly during incidents without triggering constant commercial disputes or vendor non-cooperation?
Procurement teams in Indian employee mobility services should write substitution and removal clauses that give the enterprise clear unilateral rights to immediately remove unsafe drivers or vehicles, but link any commercial penalties to patterns of non-compliance proven through auditable data and SOPs. Clauses work best when they combine objective standards, graded responses, and transparent evidence rules, so vendors experience them as governance rather than arbitrary punishment.
Procurement should first anchor the clause in existing compliance and safety frameworks. The contract can reference documented driver compliance checks, induction and training requirements, vehicle compliance and induction criteria, and centralized compliance management processes. This ensures removal or substitution is triggered by failure to meet known standards such as documentation currency, background verification, training completion, or vehicle fitness and safety checklist items.
The clause should differentiate between immediate safety-critical removals and operational quality issues. Safety-critical triggers justify instant suspension from duty for a driver or vehicle with mandatory substitution, using inputs from alert supervision systems, command center monitoring, women-safety protocols, or HSSE responsibilities. Operational quality issues such as repeated OTP failures or minor deviations should flow through a defined escalation mechanism and matrix, with warnings, corrective training, and only then commercial impact.
To reduce disputes, the contract should require that each removal or substitution decision is backed by evidence from tech systems and governance forums. This includes trip logs, GPS or IVMS data, alerts, audit findings, or dashboards from the transport command centre. It should also define review cadences under an account management and operational excellence model, where patterns of non-compliance are tabled and mutually agreed corrective actions precede any structural commercial changes.
Commercially, Procurement should avoid per-incident punitive billing changes. Instead, the clause can tie penalties or vendor rebalancing to aggregated KPIs over a period, such as SLA breach rate, incident rate, OTP, or audit scores, using management reports and indicative dashboards. This aligns with outcome-based governance while giving vendors predictable exposure, supported by clear escalation routes and BCP commitments if large-scale substitutions are required.
images:


What are the trade-offs between fixed drivers vs flexible driver pooling, and how do we choose a model that protects OTP and night-shift safety?
B1322 Fixed vs pooled driver governance — In India corporate employee mobility services (EMS), what are the operational trade-offs between strict driver standardization (fixed driver mapping) versus flexible pooling (dynamic driver allocation), and how do you decide which governance model better protects OTP and women-safety policies for night shifts?
In Indian employee mobility services, strict driver standardization protects women-safety compliance and incident defensibility, while flexible pooling protects OTP and fleet utilization. The best governance model for night shifts usually combines fixed, vetted “A‑tier” drivers on women-sensitive and high-risk routes with dynamic allocation elsewhere, controlled through route- and time-band based rules rather than ad‑hoc dispatch.
Strict driver standardization uses fixed driver–route or driver–client mapping with pre-qualified, repeatedly-audited chauffeurs. This improves behavioral consistency, enables deeper women-safety training, simplifies escort and route-approval enforcement, and strengthens audit trails for EHS and HR teams. The trade-off is lower Vehicle Utilization Index, more dead mileage, and tighter capacity during spikes, which can hurt OTP if demand fluctuates or if a fixed driver is absent.
Flexible pooling uses a shared driver pool across routes and shifts. This improves Trip Fill Ratio, reduces Cost per Employee Trip, and gives Transport Heads more levers to defend OTP during disruptions, monsoon traffic, or driver shortages. The operational risk is variability in driver familiarity with night routes, more room for fatigue and policy drift, and harder reconstruction of responsibility during incidents unless compliance automation and audit trails are strong.
Most organizations therefore decide governance at the level of route, time band, and risk profile, not at the level of the entire EMS program. Typical patterns include fixed mapping for women-only or women-first night routes, last-drop employees, and geo-fenced high-risk corridors, and dynamic pooling for mixed-gender, peak-day, or low-risk routes. Transport Heads then rely on command-center tools such as driver KYC/PSV status, fatigue indicators, geo-fencing, panic/SOS workflows, and trip-ledger audit trails to keep both OTP% and women-safety policies in control under either model.
images:

How can we measure the admin/ops load from driver onboarding and reviews, and how do we know when governance has become too heavy to run?
B1323 Measuring governance operational drag — In India employee mobility services (EMS), how do experienced Transport Heads measure the ‘operational drag’ created by driver onboarding, training, and performance reviews, and what thresholds signal the governance process is too heavy to sustain?
In India EMS operations, experienced Transport Heads treat driver onboarding, training, and performance reviews as necessary “governance load” and measure operational drag primarily through capacity loss, escalation volume, and schedule instability. Operational drag is considered acceptable when compliance and safety are maintained without visibly harming fleet uptime, OTP, or driver retention. It is considered too heavy when the governance process starts to reduce available vehicles, increase night-shift firefighting, or push good drivers out of the system.
Transport Heads typically quantify drag through a few practical lenses. They monitor fleet uptime and available vehicles versus rostered demand and check how many cabs are off-road due to induction, audits, or training compared to the total deployed pool. They track OTP% and exception SLAs to see if safety briefings, compliance checks, or paperwork are increasingly causing late departures or missed shift windows. They also watch driver attrition and onboarding churn to understand if the assessment and verification framework, refresher training cadence, and audit routines are driving experienced drivers away faster than new ones can be inducted.
There are clear thresholds that usually signal governance has become too heavy for EMS realities. A common red flag is when more than a small buffer of vehicles remain in “pending induction” or “compliance hold” during peak shift windows and this situation repeats for multiple weeks. Another is when OTP drops despite stable traffic and demand because trips are delayed by documentation, audits, or repeated training pulls. Operational drag is also visible when driver sentiment and availability decline after stricter processes are introduced and Transport Heads face sustained difficulty in filling night or remote routes even though there is adequate overall fleet on paper.
What should IT own in driver/fleet governance data so Ops has control but we don’t create DPDP privacy risk?
B1324 IT role in governance data — In India corporate ground transportation for employee mobility services (EMS), what role should IT play in driver and fleet governance data—especially around identity, access, and audit logs—so that operational teams get control without creating DPDP Act privacy exposure?
IT should own the architecture, standards, and controls for driver and fleet governance data, while letting transport teams operate within tightly defined, role-based “guardrails” that are DPDP-compliant by design. IT’s role is to design identity, access, and audit-log patterns so operations get full observability for EMS without unrestricted access to personal data or uncontrolled telemetry retention.
IT should first establish a canonical driver and vehicle identity model. This model should separate operational identifiers used by EMS routing and command centers from high-risk personal identifiers stored in HR, compliance, or vendor systems. IT should then enforce a single identity and access management layer across driver apps, fleet dashboards, and NOC tools, so every action is tied to a verifiable identity, but exposed only at the minimum detail required for shift planning, OTP%, TAR, and safety governance.
IT should define role-based access policies for Transport, HR, Security, Procurement, and ESG teams. Each persona should see only the data fields and historical range they need for their SLAs, investigations, or reporting. IT should centralize audit logs for trip lifecycles, routing decisions, SOS events, and compliance checks, and treat these logs as regulated records with controlled retention and tamper-evident integrity. This improves incident reconstruction and SLA verification, while reducing DPDP Act exposure by limiting who can query raw telemetry and how long it is kept.
IT should also own API and integration standards for EMS platforms, telematics, and HRMS/ERP. This includes contractually requiring open APIs, clear data schemas, and data-portability paths, so driver and fleet governance data does not fragment into uncontrolled silos. When operations request new dashboards, exception alerts, or AI routing features, IT should insist on privacy-by-design reviews that check lawful purpose, field minimization, and retention alignment before rollout.
images:

After a serious safety escalation, what driver governance changes actually work in 30–60 days, and what’s just optics that won’t stick?
B1325 Post-incident governance changes that stick — In India employee mobility services (EMS), when leadership demands ‘zero incidents’ after a high-profile safety escalation, what changes to driver governance (training, probation, monitoring, substitution) typically work in the next 30–60 days, and what changes are mostly optics that won’t hold up operationally?
In India employee mobility services, “zero-incident” responses that actually work in 30–60 days put driver governance on a tighter, auditable cycle of vetting, training, fatigue control, and rapid substitution. Purely symbolic actions like one-time townhalls, generic “safety pledge” posters, or blanket vendor warnings without data and follow-through usually fail to change on-ground risk.
Effective near-term changes start by hardening driver onboarding and probation. Operators typically tighten KYC and PSV checks, extend background verification using address and court-record data, and enforce maker–checker reviews before a driver is cleared for women’s night shifts. Structured two-day training modules that cover traffic law, POSH, soft skills, and defensive driving are reinforced with on-road assessments. Driver probation is made explicit with closer monitoring of complaint rates and incident-free duty cycles before full confirmation.
Continuous monitoring and substitution policies then become the main control levers. Command centers lean more on IVMS/telematics, geo-fencing, speed alerts, SOS events, and random route audits to identify risky patterns early. Clear fatigue rules and duty cycles are enforced, with pre-defined substitution playbooks when a driver breaches safety thresholds or documentation currency. This approach aligns with broader HSSE frameworks, centralized compliance dashboards, and escalation matrices that make safety “by design” instead of reactive.
Optical responses tend to focus on visible but weak signals. Examples include one-off safety campaigns without linking them to driver scorecards, increasing escort use without fixing routing or driver behavior, or announcing “zero tolerance” policies without clear SOPs for investigation, evidence, and re-allocation. These measures can calm leadership briefly but usually collapse under the daily pressures of driver shortages, hybrid rosters, and traffic conditions unless they are backed by command-center observability, vendor governance, and audit-ready trip data.
images:
How do we stop vendors from inflating driver scorecards, and what checks can we use to confirm improvements are real (OTP/complaints)?
B1326 Preventing scorecard grade inflation — In India corporate employee transport (EMS), how do you prevent vendors from ‘grade inflation’ in driver performance scorecards, and what independent checks can Facilities or Internal Audit use to validate that reported improvements correlate with real OTP and complaint reduction?
In India EMS programs, organizations prevent vendor “grade inflation” by anchoring driver performance scorecards to independent operational data streams. Facilities and Internal Audit then validate vendor-reported improvements against hard metrics such as OTP%, Trip Adherence Rate, incident logs, and complaint trends rather than relying on self-scored ratings.
Facilities teams typically start by standardizing a driver scorecard that is data-linked. Each component is mapped to verifiable sources like GPS-based route adherence audits, Command Center alerts, SOS triggers, and HRMS-linked attendance variance. A common failure mode is allowing vendors to submit qualitative ratings without binding them to this telemetry. That failure leads directly to grade inflation and a false sense of safety and reliability.
Independent validation works best when Internal Audit and Facilities triangulate three evidence sets. The first is operational telemetry from the NOC or Command Center, including On-Time Performance (OTP%), Trip Adherence Rate, exception closure times, and dead mileage. The second is safety and compliance data such as driver KYC/PSV validity, random route audit outcomes, and incident or near-miss logs. The third is employee-side signals, including complaint volumes, grievance closure SLAs, and commute experience feedback captured through rider apps or structured surveys.
Facilities and Internal Audit can then run simple correlation checks over time. They compare periods where the vendor claims improved driver scores with changes in OTP%, incident rate, and complaint numbers. If scores trend upward while OTP and complaints do not improve, that discrepancy flags potential inflation and triggers deeper route audits or sample-based ride checks. This creates a feedback loop where vendor scorecards must continuously reconcile with independently captured EMS KPIs and documented complaint reduction.
How do we govern driver fatigue (duty hours/rest) in a way vendors actually follow, without hurting OTP during peak weeks?
B1327 Enforceable fatigue governance — In India employee mobility services (EMS), how should a Facility/Transport Head set up governance for driver fatigue management (duty cycles, rest windows, shift allocations) so it’s enforceable with vendors and doesn’t quietly degrade OTP during high-demand weeks?
In Indian employee mobility services, a Facility or Transport Head needs a formal, data-backed fatigue governance model that is written into vendor contracts, enforced via trip and roster data, and protected by exception rules so OTP does not collapse during peak demand weeks. Driver duty cycles, rest windows, and shift allocations must be configured as non-negotiable constraints in routing and vendor deployment, not as guidelines that can be overridden ad hoc.
A common failure mode is treating driver fatigue limits as a manual checklist rather than as a hard rule encoded in the operation cycle and command center. This usually breaks during month-end, monsoon, or festival peaks when extra trips are layered on the same drivers to “save the shift,” which temporarily protects OTP but increases incident risk and leads to hidden non-compliance. Industry practice shows that transport operations are more stable when fatigue rules sit at the same priority level as women-safety protocols, escort rules, and statutory compliance, and when they are visible inside centralized dashboards and alert systems rather than only in policy documents.
To keep OTP stable while enforcing fatigue rules, governance needs clear thresholds, automated checks, and predefined fallback playbooks. The Facility or Transport Head can structure this in three layers:
- Define explicit numerical limits for duty cycles and rest windows in policy and in vendor SLAs.
- Encode these limits into rostering, routing, and command-center monitoring as hard constraints.
- Pre-define high-demand contingency mechanisms that add capacity without breaking fatigue rules.
First, driver fatigue limits must be quantified and referenced consistently. Duty hours per day and per week, maximum continuous driving blocks, and mandatory off-duty rest windows between shifts need to be clearly specified. These limits should align with internal HSSE expectations and labour norms highlighted in the industry brief, and should be visible in driver compliance and induction documentation similar to WTI’s DASP and ongoing driver management processes. Vendors should sign that their internal deployment systems respect the same thresholds, and they should agree to periodic audits of duty logs, GPS traces, and trip manifests.
Second, these thresholds must be integrated into the operational systems. The Facility or Transport Head can configure the routing and rostering engine so a driver cannot be assigned beyond the defined duty cap and cannot be rostered into a shift unless the minimum rest window has elapsed. This aligns with the broader trend towards automated compliance and in-vehicle monitoring. Command center dashboards and alert supervision systems should display real-time duty counters per driver and trigger alerts when a driver is nearing maximum duty, similar to how they surface speeding or geofence violations. Any manual override should require documented approval, appear in an exception report, and be reviewed in governance meetings with vendors.
Third, OTP protection during high-demand weeks requires deliberate buffer planning and business continuity playbooks. Instead of quietly stretching drivers, the Facility or Transport Head can work with vendors to maintain standby capacity, flex fleets, and fallback suppliers that are pre-inducted and compliance-checked. WTI’s Business Continuity Plan examples show the value of buffer vehicles, associated business support, and transition mitigation plans. For EMS, that means having pre-agreed levers such as activating additional cabs, rebalancing routes, or temporarily adjusting seat-fill targets while keeping driver duty rules intact. These levers should be codified in a documented BCP and tied to triggers such as planned events, monsoon alerts, or forecasted volume spikes.
Vendor performance and fatigue compliance should be reviewed through a structured account management and operational excellence model. Quarterly or monthly governance forums can examine indicators like OTP%, exception count, incident reports, and any fatigue-rule overrides. Vendors with repeated fatigue non-compliance should see this reflected in their performance scorecards and commercial consequences, in line with outcome-based procurement trends. At the same time, high-compliance vendors can be rewarded with preferential volume or longer tenures.
To keep the operation calm for the Facility or Transport Head, the key is early warning and predictable response. Command centers and transport desks should not only monitor live trips but also see leading indicators such as drivers nearing weekly duty caps or clusters where standby capacity is being exhausted. When these indicators breach defined thresholds, pre-planned measures like pulling in buffer vehicles, adjusting routing, or temporarily easing non-safety constraints can be triggered before OTP drops. This shifts the system from reactive firefighting to controlled, playbook-driven intervention while keeping driver fatigue governance intact and auditable.
For executive cars, what fleet and chauffeur governance rules protect experience without creating nonstop exceptions and VIP escalations for Admin/Travel?
B1328 Governance that reduces VIP escalations — In India corporate car rental services (CRD) for executive movement, what fleet governance rules (vehicle standardization, chauffeur quality gates, substitution approvals) are necessary to protect executive experience without causing constant exceptions and ‘VIP escalation’ politics inside Admin/Travel Desk teams?
In India corporate car rental for executives, fleet governance works best when vehicles and chauffeurs are standardized by policy and measured by SLA, while substitutions and “VIP asks” are handled through clear, pre‑defined exception tiers rather than ad‑hoc approvals. This protects executive experience and also shields Admin/Travel Desk from daily “special case” pressure.
A common failure mode is keeping executive standards undocumented. Admin teams then negotiate car models, chauffeur changes, and upgrades on every trip. This increases exceptions, fuels “VIP politics,” and breaks SLA discipline. Governance is most stable when vehicle categories, age limits, OEM lists, and fitment (AC, Wi‑Fi, water, cleanliness checks) are codified as catalog items and audited through fleet compliance checks and route‑level vehicle deployment audits.
Chauffeur quality needs a formal gate. Successful programs use documented driver assessment and selection procedures, background verification, and recurring training. This includes VIVA and practical driving tests, POSH and customer handling training, seasonal refreshers, and structured rewards and recognition. Quality gates reduce safety incidents and complaints, which directly reduces escalations from senior executives.
Substitution risk is best controlled through rules that are known in advance. Organizations define when a lower segment car or non‑dedicated driver can be used, what approvals are required, and what compensations or credits apply. These rules are embedded into the CRD process and communicated via policy, so Travel Desk can point to governance instead of negotiating case‑by‑case.
To avoid constant “VIP escalations,” travel policies can define executive entitlements by band, city, and trip type. Admin teams then use a command‑center style dashboard and alert supervision system to monitor SLA, OTP, and exceptions, rather than manually managing personalities. Data‑driven insights and indicative management reports help demonstrate that standards are being met, which further reduces pressure for one‑off favours.
In long-term rentals, how should we handle replacement and downtime substitutions so Ops gets continuity and Finance gets predictability—and who decides when they clash?
B1329 Decision rights for LTR substitutions — In India long-term rental (LTR) programs for corporate fleets, how do you structure fleet replacement and downtime substitution governance so operations get continuity while Finance gets predictable cost, and who should hold the decision rights when those priorities conflict?
In India long-term rental programs for corporate fleets, fleet replacement and downtime substitution governance work best when they are codified as explicit uptime SLAs with pre-agreed substitution rules, and when decision rights are split so Operations owns service continuity within those rules while Finance controls cost guardrails and exception approvals. This structure protects daily reliability for users while keeping lifecycle costs and commercial exposure predictable for Finance and Procurement.
A robust LTR construct treats uptime and continuity as primary design goals. Vehicle replacement planning is defined over the full contract tenure. Operators commit to preventive maintenance schedules, fitness and compliance currency, and clear triggers for pre-emptive swap-outs of aging or underperforming vehicles. Downtime substitution is then specified as a standard obligation rather than an ad-hoc favor. Typical clauses define maximum allowable downtime per incident, response-time targets to place a substitute vehicle, and any thresholds beyond which service credits or penalties apply. This aligns with industry emphasis on fleet uptime, preventive maintenance, and assured availability as core LTR outcomes.
Cost predictability is preserved by translating these technical and operational commitments into structured commercial instruments. Fixed monthly rentals with defined inclusions and exclusions keep budgets stable for Finance, while substitution and replacement are embedded into the base SLA rather than billed as premium exceptions. Outcome-based elements can be added, where persistent uptime or SLA breaches trigger credits, and where operators are incentivized to manage maintenance intelligently without pushing cost volatility back onto the client. Over the contract life, vehicle performance, utilization, and compliance are monitored, with periodic performance reporting forming the basis for scheduled replacements, not reactive negotiations.
When priorities conflict, decision rights should follow the underlying accountability. The Facility/Transport Head should have day-to-day authority to activate substitutions and rerouting within the agreed commercial and SLA framework. The CFO/Finance Controller, working through Procurement, should own decisions that alter cost baselines, extend contract scope, or introduce non-standard solutions such as premium temporary vehicles or accelerated fleet refresh outside the agreed lifecycle. Governance forums, such as quarterly performance reviews involving Operations, Finance, and Procurement, should arbitrate structural trade-offs between stricter uptime targets and rental rates, using data on uptime, incident-related disruptions, and unit economics to recalibrate policies rather than resolving conflicts case-by-case.
With multiple transport vendors, what driver governance standards should we centralize vs let each vendor run, and how do we avoid standards dropping?
B1330 Central vs vendor-specific standards — In India employee mobility services (EMS) with multi-vendor aggregation, what driver governance standards should be centralized across vendors (onboarding, training, incident thresholds) versus left vendor-specific, and how do you avoid a lowest-common-denominator outcome?
In multi-vendor EMS in India, organizations should centralize non-negotiable driver governance standards for safety, compliance, and auditability, and only allow vendor-specific variation in how these standards are operationalized or exceeded. Centralization must cover onboarding criteria, training baselines, monitoring and incident thresholds, and evidence requirements, while leaving leeway in pedagogy, incentives, and value-added practices so vendors can compete upwards rather than drag standards downwards.
Centralized standards work best when defined as explicit, cross-vendor controls tied to SLAs and data. Central governance typically sets common requirements for driver KYC and PSV verification, background and criminal checks, medical fitness, minimum experience, and periodic re-verification. The same applies to training: there should be one auditable curriculum baseline across vendors on traffic laws, defensive driving, women-safety and POSH awareness for night shifts, technology usage, and incident/SOS protocols. A shared escalation matrix and common definitions for incident severity, “near miss,” and disqualifying events help align safety and compliance management across a fragmented vendor base.
To avoid a lowest‑common‑denominator outcome, organizations should standardize outcomes and evidence rather than micromanaging every process step. Vendors should be measured against uniform KPIs such as incident rate, Driver Fatigue Index proxies, credential currency, and training completion, using a centralized compliance dashboard and common audit trail expectations for GPS logs, trip manifests, and investigation records. A vendor tiering model and outcome-based incentives can then reward over-compliance and better training or retention practices, while penalties and rebalancing rules protect EMS reliability and ESG disclosures.
images:
images:
images:
incentives, performance, and otp linkage
Align incentives with measurable OTP outcomes, track retention signals, and ensure finance can audit incentive effectiveness while preventing unsafe behavior.
How can we link driver governance to employee satisfaction in a way HR can defend to leadership, without setting easy-to-game targets?
B1331 Linking governance to satisfaction credibly — In India corporate employee transport (EMS), what are practical ways to link driver governance outcomes to employee satisfaction so HR can credibly show ‘we fixed it’ to leadership—without setting targets that drivers or vendors can manipulate?
In Indian corporate employee transport, HR can link driver governance to employee satisfaction by tying a few hard-to-game operational metrics to independently captured employee feedback and then tracking both in a single, audit-ready view. Driver governance must be measured through evidence-based controls such as compliance, safety behavior, and on-time performance, while employee satisfaction is captured through app-based feedback and floor connects that HR owns, not vendors.
A practical starting point is to anchor driver governance on verifiable inputs that sit outside driver or vendor control. Organizations can use centralized compliance management for driver KYC, background checks, licensing, medical fitness, and refresher trainings, supported by automated alerts and maker–checker workflows. This ensures driver eligibility and training quality are proven through documents, audit logs, and periodic evaluations rather than self-reporting. HR can then show leadership that all drivers on the roster meet defined compliance thresholds.
Operations teams can then layer in telematics and command-center data to track behavior and reliability at scale. On-time pickup and drop adherence, speeding alerts, geofence violations, device tampering, and duty-hour patterns can be monitored through an alert supervision system and transport command center with escalation matrices. Drivers see only their trips, while HR and transport see aggregated patterns through dashboards, reducing the risk of data manipulation. HR can then correlate reduced violations and improved OTP with changes in commute satisfaction.
To connect this with employee sentiment without giving drivers room to game the system, organizations can collect rider feedback through the employee app with trip-level ratings, SOS usage, and narrative comments flowing into a user satisfaction index. Feedback should be stored in the mobility platform and surfaced through indicative management reports rather than routed through vendors manually, which helps avoid selective reporting. Periodic floor connects and surveys run by HR further validate that app ratings match lived experience.
HR can then present leadership with a simple governance-to-EX story that uses both streams of data. For example, a period showing tightened driver compliance, fewer speeding and geofence alerts, and a stable on-time arrival rate above 98% can be shown alongside an improved commute satisfaction score and lower transport-related complaints. When this structure is embedded into a standard engagement model with regular reviews and account governance, HR can credibly say “we fixed it” because each claim rests on system-generated evidence, multi-source feedback, and independent audits rather than numbers that a single party can massage.
What clear non-negotiables should we set for driver behavior and escalation so our ops team can act confidently and not get second-guessed later?
B1332 Non-negotiables for driver conduct — In India employee mobility services (EMS), how should an operations leader set ‘non-negotiables’ for driver behavior and escalation (e.g., refusal, misconduct, route deviation) so front-line teams have clear authority and aren’t second-guessed after taking action?
Operations leaders in India EMS should define a short, written list of driver-behavior and escalation “non-negotiables” and link each item to a pre-agreed consequence and evidence requirement. This gives front-line teams clear authority to act in real time and protects them from being second-guessed later.
The non-negotiables should focus on behaviors that directly hit safety, reliability, or compliance. Typical examples are trip refusal after assignment, route deviation without approval, over-speeding or tampering alerts from IVMS/GPS, women-safety protocol breaches, and abuse or misconduct reported by employees. Each non-negotiable should have a simple operational definition so dispatch, command-center staff, and supervisors can quickly decide whether a line has been crossed.
Every non-negotiable needs a mapped response ladder that is approved by HR, Legal, Security/EHS, and vendor management. Front-line SOPs should state what happens on first, second, and critical violations. For example, immediate trip off-boarding and alternate cab dispatch for misconduct, temporary suspension pending investigation for safety breaches, and permanent blacklisting for confirmed harassment. The Alert Supervision System, driver app logs, GPS data, and SOS tickets should be treated as primary evidence so decisions are anchored in auditable data rather than opinion.
Clear escalation paths should be documented for each scenario. These should define who is authorized to block a driver, who informs the vendor, and when incidents move from operations to Security/EHS or HR. A command-center playbook and an escalation matrix aligned with Business Continuity Plans can hard-code that front-line staff are expected to prioritize employee safety and service continuity first. Review cadences with vendors and internal stakeholders should then focus on patterns and RCA, not on revisiting individual frontline calls made within the approved framework.
What driver governance info should site admins be able to see vs not see, so we balance control, privacy, and internal politics?
B1333 Visibility rules for governance data — In India corporate employee mobility services (EMS), what governance data should be visible to site-level admins (e.g., driver ratings, substitution approvals, complaint history) versus restricted, to balance operational control with privacy and internal politics?
Site-level admins in Indian employee mobility programs should see data that directly affects daily reliability, safety, and SLA compliance, and be restricted from data that exposes sensitive personal, financial, or politically charged information. Governance works best when operations-facing data is granular, while identity, pay, and certain risk signals stay abstracted or aggregated.
Operational control at the site level depends on visibility into real-time trip status, OTP/OTD, roster adherence, route deviations, driver KYC validity, vehicle fitness, and open incidents or complaints linked to shifts. Admins need driver performance signals such as fatigue-risk indicators, recent safety violations, and an averaged rating history, because these influence routing, substitution decisions, and whether to deploy a driver on a critical night shift. They also need access to substitution approvals, escalation status, and closure notes for local complaints so they can act quickly and avoid repeat issues.
A common failure mode is giving local teams access to raw complaints with employee identities, pay details, or narrative that can trigger local politics. Another risk is exposing driver-level financials, incentive logic, or comparative ranking which can damage morale and feed site-level bias. Governance data like carbon metrics, strategic cost baselines, and cross-site vendor performance benchmarking should stay at central command or leadership level and only reach sites as targets or summarized KPIs.
To balance control with privacy and internal politics, most organizations standardize role-based access and design tiered views where the same event appears with different detail per role. Complaint records can show pattern, category, and SLA status to site admins but keep reporter identity masked. Driver ratings can be bucketed (e.g., green/amber/red) instead of raw scores, while audit logs, GPS traces, and trip manifests remain fully accessible only to the central NOC, Security/EHS, and investigation roles.
How can we quantify the impact of driver churn on OTP and complaints, so we can justify retention spend to Finance?
B1334 Quantifying churn impact for Finance — In India employee mobility services (EMS), what’s the most reliable way to quantify how driver churn impacts OTP and employee complaints, so a Transport Head can justify budget for retention incentives without being accused of ‘soft spending’ by Finance?
In Indian employee mobility services, the most reliable way to quantify driver churn impact is to correlate driver-stability metrics with On‑Time Performance (OTP) and complaint data over time and then express this as cost per lost driver and cost per 1% OTP drop. This converts “soft” retention spending into a hard, auditable business case that Finance can defend.
A practical pattern is to track a small, fixed KPI set per month or per quarter. Transport teams can track driver churn rate by vendor or city. The same period’s OTP, trip adherence rate, and exception-closure times can be taken from the command center or NOC reports. Employee complaints and escalations can be counted from call-center logs, app feedback, and HR grievance data. Industry practice treats these as standard EMS KPIs rather than ad-hoc metrics.
A common failure mode is to talk only about “morale” or “relationship with drivers” without linking numbers. Transport Heads gain credibility when they show that clusters with higher churn also show lower OTP, higher no-show handling, and more safety or service complaints. Finance can then see increased dead mileage, extra backup vehicles, and penalty exposure as quantifiable cost outcomes of churn.
To make the retention budget defensible, teams can show three linked figures. They can show the incremental cost of service recovery and backup deployment in high-churn periods. They can show the impact on cost per employee trip (CET) when OTP drops and additional trips or remediations are triggered. They can show how many additional complaints and escalations correlate with each 5–10% increase in churn, converting trust loss into measurable operational noise instead of a “soft” narrative.
For a big event commute where we need to mobilize fast, what’s the realistic minimum driver onboarding/briefing we should require, and what usually slows teams down?
B1335 Minimum viable governance for events — In India project/event commute services (ECS) for large corporate events, what minimum driver onboarding and briefing governance is realistic when you have to mobilize fleet fast, and where do teams typically overreach and create execution delays?
In India project/event commute services for large corporate events, the realistic minimum governance is a compressed but standardized driver onboarding plus a tightly scripted daily briefing, rather than a full EMS-style induction. Most organizations succeed when they separate non‑negotiable safety and compliance checks from nice‑to‑have training that can be deferred or dropped.
A realistic minimum onboarding stack usually includes pre‑vetted vendor partners, a short‑form driver compliance verification, and a basic induction block. The collateral describes structured DASP processes, background checks, and driver compliance verification covering license validity, criminal checks, address proof, and medical fitness. For fast ECS mobilization, operators typically lean on pre-qualified vendors whose fleets and drivers already meet these standards, instead of re-running the full workflow for every event. They use simple checklists at vehicle induction to confirm key documents, visible fitness, and safety equipment before tagging vehicles to routes.
Briefings work best when they are short, repetitive, and focused on event specifics. The “Daily Shift Wise Briefing” and “Safety First, On Time Delivery Must” materials show practical patterns that scale. Supervisors conduct quick huddles on route plans, reporting lines, OTP expectations, women-safety rules, SOS escalation, and parking or gate protocols, reinforced by the command center and Alert Supervision System.
Execution delays usually come from overreaching on depth and format during a time‑bound ramp-up. Common overreach patterns are trying to run full two‑day classroom training for all temporary drivers, replicating detailed long-term EMS driver management and rewards programs, or insisting on complex HSSE workshops and multiple audit cycles before the first shift. Teams also slow themselves down by demanding exhaustive re-documentation when vendor fleets are already under a centralized compliance management program, or by rolling out too many app features and complex SOPs at once instead of starting with a minimal, stable stack of routing, trip manifests, and SOS handling.
In practice, the most reliable ECS programs keep the non‑negotiables tight: documented identity and license checks, basic health and behavior screening, a short safety and women-safety briefing, and clear escalation paths to the transport command centre and security. Everything beyond that is phased in only after launch, when operations have stabilized and the initial surge risk is under control.
How can we set up driver incentives and grievance handling so drivers feel treated fairly (and stay), but employees still see fast complaint resolution?
B1336 Fairness balance: drivers vs employees — In India corporate ground transportation for employee mobility services (EMS), how do you design driver grievance and incentive systems so drivers don’t churn due to perceived unfairness, while employees still feel complaints are taken seriously and resolved quickly?
In corporate employee mobility in India, driver grievance and incentive systems work best when they are rule-based, transparent, and two-sided. They need to protect drivers from arbitrary penalties while giving employees a fast, visible path to raise and resolve complaints with clear audit trails.
A common failure mode is one-sided “customer is always right” policies. These create silent driver resentment, higher attrition, and eventually more reliability and safety issues. A second failure mode is informal, verbal resolution without records. That weakens trust for both drivers and employees and makes incident patterns invisible to Transport Heads and HR.
Robust designs use structured processes around existing elements like driver assessment and training, compliance checks, safety frameworks, and command-center operations. Centralized systems already monitor issues such as overspeeding, geofence violations, and SOS alerts. The same command-and-control approach can host a ticketed grievance and feedback workflow with defined SLAs, where every complaint from an employee or driver generates a traceable case, a fact-finding step, and a documented closure.
Incentives then anchor on measurable, auditable parameters instead of subjective impressions. Examples include on-time performance, absence of safety violations, completion of training and refresher sessions, and positive employee feedback trends. Evidence-based reward and recognition programs for safe driving, customer handling, and seasonal challenges already exist, and they can be tied directly into this framework.
When drivers know that complaints will be investigated using GPS logs, trip manifests, and app data, they perceive the system as fair. When employees see a clear escalation matrix, real-time alerts, and closure communication from the command center, they feel complaints are taken seriously. This combination reduces day-to-day firefighting for the Facility/Transport Head and stabilizes both driver retention and employee satisfaction.
What SLA commitments should we put in place for overnight driver/fleet failures, and how do we stop vendors from blaming subcontractors during incidents?
B1337 2 a.m. accountability in SLAs — In India employee mobility services (EMS), what governance commitments should be included in SLAs around ‘who answers at 2 a.m.’ for driver/fleet failures, and how do you ensure vendors can’t shift responsibility between subcontractors during incidents?
In India EMS contracts, SLAs should explicitly name a single accountable command entity with 24x7 authority to act, and they should bind that entity to incident response, not its subcontractors. Governance clauses must make the Managed Mobility Provider or primary vendor the “owner of last resort” for any 2 a.m. failure, with no dilution through partner or fleet-owner layers.
The SLA should define who runs the command center, who has decision rights during incidents, and what escalation matrix is active at night. The contract should treat the centralized command center or Transport Command Centre as a governed function with KPIs for response time, incident closure, and on-time performance, rather than as a “best-effort” support line. A common failure mode is leaving night response to fragmented vendor or driver networks without a central, SLA-bound operations owner.
Responsibility shifting is contained by making the primary EMS vendor contractually accountable for all subcontracted fleets, driver compliance, and technology uptime. Subcontractors should appear in vendor-governance, compliance, and fleet-induction processes, but without direct contractual escape routes on incidents or safety lapses. The SLA should tie outcome-based metrics such as OTP, incident rate, and closure SLAs to the primary vendor’s commercial model, with no carve‑outs for third-party or “associated businesses.” This aligns with vendor-governance frameworks in the sector and protects the Facility/Transport Head from 2 a.m. finger‑pointing across the supply chain.
As a transport admin, what’s the right way to document driver/vehicle substitutions so the audit trail is clear and I’m protected if something goes wrong?
B1338 Audit trail that protects admins — In India corporate employee mobility services (EMS), how should a junior transport administrator document driver and vehicle substitutions so that, if something goes wrong, the audit trail protects the admin from blame and makes accountability clear?
In Indian employee mobility services, a junior transport administrator is best protected when every driver and vehicle substitution is documented as a traceable, time-stamped change to the original trip record, with clear approval, reason, and compliance status captured in one system of record. The audit trail must show who changed what, when, why, and with which safety and statutory checks in place.
A robust substitution log should start from the planned roster and route, as seen in structured ETS operation cycles and command centre workflows. Each deviation needs a linked entry to that original trip ID. The administrator should record the substitution trigger time, the reason for change, and the new driver and vehicle identifiers. The log should capture that driver’s compliance status from centralized compliance management and driver compliance checks, plus the vehicle’s compliance status from fleet compliance and induction records. This keeps legal and safety responsibility anchored to documented checks rather than memory or WhatsApp threads.
The administrator should also log who authorized the substitution, whether by SLA-defined escalation matrix or command center SOP. The actual time of system update and notification to employees must be recorded using tools like the transport command centre, alert supervision system, or mobility app. When possible, the administrator should attach automated GPS and trip data, including start–end times and route adherence, from technology platforms such as Commutr or the WTI command centre. A short exception report after the shift, summarizing all substitutions, reasons, and compliance status, should be shared with the transport head or command centre lead for sign-off, ensuring responsibility is clearly escalated and not left with a junior admin.
images:

For executive trips, how do we govern chauffeur performance and substitutions so leaders get consistency, but Admin can still handle last-minute changes?
B1339 Executive chauffeur consistency vs flexibility — In India corporate car rental services (CRD), how do you govern chauffeur performance and substitution so executives don’t face repeated ‘new driver every day’ experience, but Admin can still handle last-minute changes without service collapse?
In India corporate car rental services, organizations govern chauffeur performance and substitution by treating drivers as a managed, auditable resource pool tied to SLAs, not as anonymous supply, and by routing all last‑minute changes through a command-center playbook. Chauffeur deployment stability is protected through rosters, tagging, and compliance frameworks, while controlled substitution rules and real-time supervision give Admin flexibility for breakdowns or no‑shows without visible chaos to executives.
A stable executive experience starts with a defined chauffeur compliance and induction framework. Drivers are vetted through documented processes such as address and criminal checks, license verification, health and experience validation, and database checks across multiple sources. Training and refresher programs then standardize behaviour and safety, using modules on defensive driving, POSH, customer handling, and seasonal conditions, with periodic audits and rewards to retain proven drivers and reduce churn.
To avoid the “new driver every day” effect, most mature programs use driver–account tagging and structured rosters. Specific chauffeurs are mapped to key executives or accounts, supported by daily shift-wise briefings and clear HSSE role expectations, so behaviour and route familiarity are consistent. Substitution is permitted only under defined conditions and is controlled centrally through a command centre or transport desk that can see real-time driver availability, compliance status, and performance history before assigning a replacement.
Admin retains last-minute flexibility via an escalation matrix, standby vehicles and drivers, and a Business Continuity Plan that covers shortages, technology failures, and disruptions. When a substitution is necessary, the system enforces pre-induction and ongoing driver compliance checks, and the command centre monitors trips via GPS, alert supervision (over-speeding, tampering, geofence violation), and SOS workflows. This reduces the risk that an unfamiliar replacement driver also becomes a compliance or safety weak point.
Centralized dashboards and indicative management reports then close the loop by tracking incident rates, on-time performance, customer feedback, and complaint closures per chauffeur and per vendor. Underperforming or non-compliant drivers can be coached or exited, while high performers are retained and preferentially deployed for sensitive executive assignments. Over time, this creates a smaller, more reliable inner pool for executives, backed by a larger, governed pool for genuine last‑minute needs.
What should we ask peer companies to get honest lessons on driver governance, not just polished vendor stories?
B1340 Peer reference questions that reveal truth — In India employee mobility services (EMS), what are the most telling questions HR can ask peer companies about driver governance (retention, substitutions, incentives) to get honest ‘post-mortem’ lessons rather than polished vendor success stories?
In India EMS, HR leaders get the most honest driver-governance lessons by asking peers for specific, incident‑anchored examples, not generic “how is it” questions. The most revealing questions force numbers, timelines, and post‑mortem actions on driver retention, substitutions, fatigue, safety, and pay structures.
Peers usually open up when questions focus on “what broke, how often, and what you would not repeat”. Questions that work well are precise, time‑bound, and tied to metrics like on‑time performance, incident rate, and driver attrition.
Examples of telling peer‑to‑peer questions for India EMS HR teams include:
- “In the last 12 months, what was the worst driver shortage or attrition spike you faced on night shifts, and how did it actually show up in OTP and escalations?”
- “When a regular driver quits suddenly, what really happens to substitutions on critical routes, and how often does that lead to safety or compliance exceptions?”
- “Which incentive or penalty scheme for drivers looked good in the contract but failed on the ground, and why did drivers or vendors push back?”
- “Have you ever rolled back a new driver incentive or roster rule because fatigue, accidents, or complaints went up?”
- “How transparent are trip counts, idle time, and payouts to drivers in your vendor model, and where have you caught mismatches between app data and driver pay?”
- “What is your vendor’s real response when you flag a problematic driver: replacement within a defined SLA, or long negotiations and excuses?”
- “Which early‑warning metrics on drivers (no‑shows, last‑minute substitutions, behaviour complaints) you now track that you completely missed in year one?”
- “If you were re‑running your EMS RFP today, what 2–3 hard driver‑governance clauses or SLAs would you insist on that were missing earlier?”
These kinds of questions shift the conversation from vendor marketing to operational reality. They link driver governance directly to safety, compliance, and business continuity, which are central concerns in Indian EMS operations.
If Finance is pushing lowest cost, what driver governance red flags should Procurement treat as non-negotiable deal-breakers because they’ll cause OTP and complaints later?
B1341 Low-cost bid governance deal-breakers — In India employee mobility services (EMS), when Finance pushes for lowest-cost vendor bids, what driver governance red flags should Procurement treat as disqualifiers because they predict OTP failures and employee backlash later?
In Indian employee mobility services, weak driver governance almost always converts into poor on-time performance and employee backlash, even if the per‑km rate looks attractive. Procurement teams should treat missing, shallow, or purely “on paper” driver controls as hard disqualifiers, because they strongly predict OTP failures, safety incidents, and escalation-heavy operations later.
Procurement should see the absence of structured driver assessment and selection as a critical warning sign. A vendor that cannot show a documented process like a multi-step Driver Assessment & Selection Procedure with VIVA, written tests, and practical driving evaluation is likely relying on ad-hoc hiring. This usually leads to inconsistent driving standards and higher incident and breakdown risk during peak or night shifts.
Lack of rigorous background verification is another disqualifier. Vendors should demonstrate a multi-layer driver compliance process that includes address verification, criminal record checks, licence legal verification, credit checks, database checks, court record checks, and medical certification. If these checks are missing or vaguely described, Procurement should expect higher safety risk and reputational exposure.
Vendors without a defined driver compliance and induction framework are also high risk. Robust programs specify licensing and experience criteria, health checks, specialized training, periodic audits, feedback reviews, and reassessment mechanisms. When vendors cannot show this level of detail, overtime there is usually drift in driver quality, rising complaint rates, and unstable OTP.
Training depth is another predictor. Procurement should insist on evidence of formal driver training and refresher programs covering safe and defensive driving, POSH and customer handling, seasonal and specialized training, and clear rewards and recognition linkages. Where training is treated as a one-time induction event, fatigue, unsafe shortcuts, and poor employee experience tend to surface after go-live.
Continuous management of drivers is equally important. Vendors should present a structured driver management and training program with ongoing performance monitoring, refresher sessions, and corrective coaching. If all governance appears “pre-contract” with no recurring mechanism post-deployment, Procurement should assume that early discipline will decay and OTP will suffer.
For women’s safety and night shifts, Procurement should flag any vendor that cannot demonstrate women-centric safety protocols. These include class A chauffeur standards, specific women safety cells, SOPs for late-night travel, and integrated SOS/alert flows between driver, app, and command centre. Gaps here often lead to high-sensitivity escalations that land on HR and Security.
A vendor’s approach to command-and-control over drivers is another filter. Strong providers anchor driver behaviour within a Transport Command Centre or centralized command centre that monitors routes, speed, geofencing, and incident alerts. If a bidder has only basic GPS and no evidence of alert supervision (e.g., fixed device tampering, geofence violations, overspeeding alerts), Procurement should expect more manual firefighting and unexplained delays.
Business continuity around driver availability must be visible. Collateral that describes Business Continuity Plans, buffers of additional vehicles, mitigation for strikes, technology failures, and natural disasters signals mature governance. If a low-cost vendor has no documented mitigation for driver shortages or disruptions, Finance’s savings will likely be offset by last-minute premium fixes and SLA penalties.
Procurement can use a small set of qualification questions as hard gates before even comparing commercials:
- Is there documented DASP-style driver assessment (VIVA, written, practical) with evidence?
- Can the vendor show the full driver compliance checklist and verification steps performed by a third-party or defined internal team?
- Is there a recurring training and rewards program, not just a one-time induction?
- How are drivers monitored in real time, and who responds to alerts at 2 a.m.?
- What specific women safety and night-shift protocols apply at the driver level?
- What Business Continuity Plan exists for driver shortages, strikes, or technology outages?
When any of these drivers of governance are missing or vague, the “cheapest” EMS bid is almost always the most expensive in OTP losses, employee churn, and reputational risk.
For our employee transport program, what driver onboarding checks should be mandatory so HR isn’t left exposed if there’s a night-shift incident?
B1342 Non-negotiable driver onboarding checks — In India corporate Employee Mobility Services (EMS) operations, what specific driver onboarding checks (KYC, PSV badge validation, police verification cadence, training evidence) should be non-negotiable in driver & fleet governance so HR is not left defending safety gaps after a night-shift incident?
In Indian corporate Employee Mobility Services, non-negotiable driver onboarding checks must create an auditable chain from identity and criminal history to training and ongoing compliance. HR avoids post‑incident blame only when every night‑shift driver in the roster can be tied to verifiable documents, background checks, and training records that are current and centrally visible.
A robust governance baseline starts with identity and licensing verification. Driver KYC checks should include government ID validation, legal verification of driving licence status and class, and address verification using a structured process. The collateral describes a nine-step driver compliance flow that includes present and permanent address verification, criminal checks, credit checks, database checks at global, national, and social-media levels, identity checks for licence and PAN, physical address verification, court record checks, and medical certification. These checks give HR and Security a defensible foundation for “who is behind the wheel” on every trip.
Public Service Vehicle (PSV) and statutory compliance must be treated as hard gates before any employee trip. Onboarding frameworks in the collateral emphasise licence and background, health and experience, and specialized training, combined with periodic audits and feedback reviews. Police verification, criminal record checks, and court record searches should be completed before induction and then revisited on a defined cadence, supported by centralized compliance management that issues alerts before any credential expires. This continuous-verification posture prevents lapsed documents or unchecked drivers from entering night rosters.
Training and behavioural readiness require equally strong evidence. The Driver Assessment & Selection Procedure (DASP) combines VIVA interviews, written tests, and practical driving evaluations, covering education, attitude, and verification checks. A two‑day training program covers road safety, traffic laws, customized soft skills, vehicle controls, and road safety practices, followed by assessments. Separate modules cover safe driving and defensive techniques, POSH and customer handling, seasonal and specialized training, with formal evaluation and rewards. These records provide concrete proof that drivers handling women’s night-shift trips have been sensitized and evaluated, not just instructed verbally.
Ongoing compliance and monitoring must close the loop from onboarding to daily operations. Collateral on driver compliance and induction highlights recurring audits, feedback reviews, health reassessments, and refresher training. Centralized compliance dashboards and alert systems ensure that document expiry, health checks, and performance issues are visible before they become safety gaps. When combined with a command-centre model, real-time GPS monitoring, alert supervision (over‑speeding, geofence violations, device tampering), and SOS workflows, this creates a continuous assurance environment rather than a one‑time onboarding event. In an incident review, HR can then point to a complete, time‑stamped trail of KYC, PSV, police verification, training, audits, and live monitoring that were in force for the specific driver and trip.
How should we set driver substitution rules so OTP stays stable but employees don’t complain about unfamiliar drivers or fairness issues?
B1343 Driver substitution without complaints — In India corporate ground transportation (EMS/CRD) operations, how should driver substitution rules be written in driver & fleet governance so Operations can keep OTP stable without triggering employee complaints about unfamiliar drivers, route discomfort, or perceived favoritism?
In India EMS/CRD operations, driver substitution rules work best when they are written as clear, auditable SOPs that prioritize OTP and safety first, and then control how, when, and how often a driver can be changed on a route. The rules need to cap unplanned substitutions, define when substitutions are allowed, and specify how employees are informed and protected so that operations can fix gaps without appearing arbitrary or unsafe.
Strong driver substitution governance starts by defining permissible substitution triggers in writing. Operations teams should explicitly allow driver swaps only for conditions such as sudden sickness, approved weekly offs, vehicle breakdown, or compliance expiry identified by centralized compliance management. This reduces ad hoc swapping that employees interpret as favoritism. Each substitution should be logged with reason, time, and approving role in the command center or transport desk tooling so that HR and Security can audit decisions later.
The rules should also define continuity bands for specific routes, shifts, and employee groups. For example, a primary driver can be mapped to a fixed set of routes or clusters, with one or two pre-inducted backup drivers trained on the same route, employee sensitivities, women-safety protocols, and site entry norms. This pattern uses the kind of structured induction and driver management already described in WTi’s driver assessment, compliance, and training collateral, and it helps maintain familiarity while still giving the command center flexibility to protect OTP during last-minute roster changes.
Employee-facing guardrails reduce complaints when a substitution is unavoidable. The SOP should require that any substituted driver be fully cleared through driver compliance and induction checks, and be visible in the employee app with photo, name, and vehicle details before pickup. For late-night or women-only trips, substitution rules should be stricter, aligning with women-centric safety protocols, SOS frameworks, and escort or routing norms used in WTi case studies on female employee safety. Operations should prohibit last-minute substitutions on these trips unless approved by Security or the command center and notified to employees via app alerts or SMS.
To avoid perceptions of favoritism, governance should force rotation according to objective logic instead of manual choice. The assignment logic in the dispatch or routing engine should consider duty hours, fatigue limits, and previous shift allocations rather than informal preferences. Tying this to a centralized command center view, where supervisors can see driver duty cycles and receive alerts when a driver nears maximum safe hours, prevents overuse of “favourite” drivers and supports HSSE compliance and driver retention.
Finally, the rules should include monitoring and feedback loops to catch discomfort early. Transport heads can use dashboards, indicative management reports, and user satisfaction indices to track how often drivers are substituted on particular routes and whether those routes generate higher complaint rates. If a specific pattern of substitution correlates with negative feedback, governance can require route-level reviews, retraining under driver management programs, or remapping of drivers. Clear escalation paths, already described in WTi’s escalation matrices and business continuity plans, ensure that repeated substitution issues are addressed before they become HR or leadership escalations.
How do we tie driver retention to OTP without becoming dependent on a few star drivers who could become single points of failure?
B1344 Avoid dependence on star drivers — For India corporate Employee Mobility Services (EMS) shift transport, what governance model best links driver retention to OTP stability—without Operations becoming dependent on a few “star” drivers and creating single points of failure during peak shifts or festivals?
A governance model that links driver retention to OTP stability without over-relying on “star” drivers is one that treats drivers as a managed, auditable resource pool governed by clear SOPs, multi-vendor capacity buffers, and command-center based rota and fatigue management, rather than as informal individual heroes. Such a model stabilizes OTP by standardizing skills, schedules, and contingencies across the entire driver base, and by making driver well-being and availability a tracked KPI at the same level as OTP and safety.
The core of this governance model is a 24/7 command-center–led operation that owns driver allocation rules, fatigue limits, and backup deployment. The command center uses structured routing, rostering, and alert supervision to avoid ad-hoc last-minute dependence on a few trusted drivers. Driver management and training are standardized using formal selection procedures, compliance checks, and periodic refresher and rewards programs, so that more drivers can safely handle critical routes, including women-heavy and night-shift routes.
This model links driver retention and OTP through explicit metrics and reviews. Command and governance forums track OTP, incident rates, and driver attrition together, and they run corrective plans via business continuity playbooks, backup vendor capacity, and escalation matrices. The governance model deliberately builds redundancy, like standby vehicles and multi-location command centers, for peak or festival periods, so that the system can absorb absence or churn without collapsing around a few high-performing drivers.
images:
What should our driver performance review scorecard include so Procurement can defend it when vendors dispute ratings?
B1345 Defensible driver performance scorecards — In India corporate ground transportation procurement for EMS/CRD, what should an outcome-linked driver performance review framework include (OTP contribution, incident rate, complaints, cancellations, fatigue flags) so Procurement can defend vendor scorecards during disputes?
An outcome-linked driver performance review framework in Indian corporate EMS/CRD should convert every driver’s shift into a small, auditable “scorecard” that rolls up cleanly into vendor-level KPIs. Procurement can then defend vendor scorecards during disputes because every score is traceable to trip logs, NOC data, and incident records rather than subjective opinions.
A robust framework anchors each driver’s review to a few outcome families. Each family needs a clear definition, data source, and dispute-ready evidence pack. On-time performance must be measured at pickup and drop, tied to shift windows and route adherence, and normalized for approved exceptions such as road closures. Incident rate must separate safety-critical events from minor operational deviations and must be backed by trip IDs, GPS traces, and closure notes. Complaint metrics must map employee or stakeholder complaints to specific trips and closure SLAs, with clear severity tagging and verified outcomes. Cancellation behavior must distinguish driver-initiated cancellations, no-shows, and system/vendor reassignments, with reasons coded so drivers are not penalized for command-center decisions.
Fatigue and risk flags should be captured via duty hours, rest-period compliance, and telematics or behavior indicators, and they should inform coaching or removal from high-risk shifts rather than only penalties. Each of these domains should roll into a composite Driver Performance Index that feeds the vendor’s SLA score, with weighting rules agreed upfront in contracts and visible to HR, Transport, and Security. Procurement can then defend vendor scorecards by showing how individual driver indexes aggregate to vendor-level SLCI, OTP%, incident rate, and complaint closure performance in a way that is consistent, repeatable, and auditable across sites and timebands.
How do we fairly attribute OTP misses (driver vs traffic vs roster changes) so the transport team isn’t blamed for things outside their control?
B1346 Fair attribution for OTP misses — In India corporate Employee Mobility Services (EMS), how do teams define a fair and tamper-resistant process for attributing OTP misses to driver behavior vs traffic vs roster change, so Facilities/Transport doesn’t get blamed for failures outside their control?
In India EMS programs, fair and tamper‑resistant OTP attribution comes from defining a standard “trip truth” data model upfront, then locking attribution rules to objective telemetry and audit trails rather than opinions or emails. Teams treat every late trip as an incident with a structured root‑cause code that is derived from time‑stamped GPS, system logs, and roster data instead of manual blame assignment.
Most mature organizations start by defining a canonical trip lifecycle. They record roster lock time, vehicle reporting time at hub or first stop, actual gate‑out time, geofenced arrival and departure at each stop, and employee boarding or no‑show status. They also capture last‑minute roster edits, address changes, and shift time changes with user IDs and timestamps. This creates an immutable event sequence for every trip.
On top of this, they implement a simple but rigid cause‑coding framework. Driver‑attributable delays are limited to patterns like late vehicle reporting against duty start, unexplained route deviation, or excess stoppage time where traffic feeds show no anomaly. Traffic‑attributable delays are tagged only when delay windows correlate with known congestion, weather, or road closure events. Roster‑ or client‑side causes are used when shift times move after roster lock, new employees are added after routing freeze, or boarding points change without SLAs for recalculation.
To keep attribution tamper‑resistant, central command centers run daily or shift‑wise exception reports that auto‑propose a cause code per breach based on rules applied to raw data. Facilities, vendors, or HR can request reclassification, but only through a workflow that leaves a comment trail and requires supporting evidence. Quarterly route adherence audits and random trip log reviews then test whether cause coding matches the underlying telemetry.
Clear commercial linkages reduce blame on Facilities. SLAs and penalties are tied to OTP misses only in driver‑ or operator‑coded buckets, while traffic and client‑side buckets are excluded from vendor penalties and internal performance scoring. Facilities and Transport are measured on controllable indicators like exception detection→closure time and roster finalization discipline, not on late shifts driven by last‑minute business changes or city‑level disruptions.
For night shifts, what rules should we set for escorts, driver selection, and last-minute substitutions to avoid women-safety escalations but still keep trips running?
B1347 Night-shift substitution safety rules — For India corporate ground transportation (EMS) night-shift operations, what specific governance rules should exist for escort assignment, driver selection, and last-minute substitutions to prevent women-safety escalations while still keeping service continuity?
For India EMS night-shift operations, governance must hard-code women-safety rules into escort assignment, driver selection, and substitutions. Service continuity should only be allowed when escorts and vetted drivers are assured and when every deviation is time-stamped, approved, and auditable.
Escort Assignment Rules
Escort presence should be mandatory for night drops on defined time bands and risk-prone routes.
Escort requirement should be encoded in the roster and routing engine, not left to manual discretion.
Drop sequencing should ensure women employees are never last drop without an escort unless a documented, pre-approved exception policy exists.
Any last-woman-drop without escort should require prior written approval from Security or HR and should create an automatic incident log.
Command center teams should receive real-time alerts if a mandated-escort trip is dispatched or running without escort mapped in the manifest.
Driver Selection & Allocation Rules
Only drivers with valid PSV, clean KYC, and completed women-safety and POSH training should be eligible for night-shift and women-only routes.
Night-shift assignment should be blocked in the system for drivers with expired documents, pending verification, or prior safety-related complaints.
Driver duty cycles and rest-period rules should be enforced via system checks to avoid fatigue on night shifts.
Repeat night-route allocation for the same women clusters should prefer known, consistently rated drivers with low incident history.
Every night-shift trip should be traceable to a unique driver ID with tamper-evident GPS and trip logs for post-incident audit.
Last-Minute Substitution Rules
Substitution of driver or vehicle after trip lock should only be allowed through the command center, not by field staff directly.
Any substitute driver should meet the same compliance and training criteria as the primary driver before being assigned to a women route or night-shift trip.
System workflows should trigger mandatory approvals and digital acknowledgment for substitutions involving women passengers or escort removal.
Employees should automatically receive updated driver, vehicle, and escort details through the app or SMS when a substitution is made.
High-risk substitutions, such as no-escort scenarios or new drivers on sensitive routes, should auto-escalate to Security or EHS with a defined response SLA.
Operational Controls That Reduce Firefighting
A 24x7 command center should monitor geo-fencing, route adherence, SOS, and escort presence for all night trips.
Exception dashboards should show live counts of trips running without mandated escort, high-risk last-drops, and non-compliant drivers.
Standard operating procedures should define who can override rules, under what conditions, and how quickly an incident must be reported.
Vendor SLAs should tie payouts and penalties to women-safety compliance metrics such as escort adherence, document currency, and incident-free night-shift performance.
Post-shift reviews should use trip logs and alerts to refine routing rules, escort policies, and driver allocations for future nights.
governance, data, auditability, and change management
Outlines decision rights, data visibility, SLA governance, and post-incident governance change to reduce firefighting and maintain control.
How should we structure driver incentives to improve OTP and experience without causing unsafe driving or gaming of check-ins?
B1348 Incentives without unsafe gaming — In India corporate Employee Mobility Services (EMS), how should driver incentive design be structured so it improves OTP and rider experience without encouraging unsafe driving, route skipping, or “gaming” check-ins to protect payouts?
Driver incentives in Indian Employee Mobility Services should reward verified on-time performance and rider experience at the trip or shift level, but always capped by hard safety and compliance gates. Incentives must never be paid when there is speeding, route deviation, credential lapse, or tampered GPS, even if OTP looks good.
In practice, most operators get better OTP and calmer shifts when they design incentives as a small, predictable top‑up per day or per trip, with clear SOPs, rather than aggressive “winner-takes-all” bonuses. Unsafe driving, skipped manifests, and fake check-ins become common when payouts are tied to raw speed or app events without cross-checks from telematics, geo-fencing, and command center audits.
A robust structure usually has three layers. The first layer is eligibility filters based on compliance and safety. A driver qualifies for any incentive only if documents are current, there are no serious incidents, and IVMS or app data shows no harsh speeding, device tampering, or repeated route violations. The second layer is core performance metrics that matter to Transport and HR, such as OTP%, trip adherence rate, and a basic rider feedback score, measured over a week or month rather than a single shift.
The third layer is anti-gaming controls. OTP and check-ins should be validated against GPS traces, approved routing, and seat-fill, so drivers do not short-route, skip pickups, or rush dangerously just to hit a target. Incentive logic should ignore trips where geo-fence or routing audits show deviations, and the command center should run random route adherence audits on “perfect” records. Most organizations also protect drivers by including fatigue limits and duty cycle rules in the design, so no one feels forced to accept unsafe hours to defend payout.
For a Facility or Transport Head, the operational signal is simple. If incentives are driving more 2 a.m. escalations, near-miss safety reports, or sudden spikes in deviations flagged by the command center, the scheme is misaligned and needs to be reset. If incentives are leading to steadier OTP, fewer no-shows, lower driver attrition, and cleaner route-audit reports, the design is working without adding hidden risk.
For executive car rentals, what fleet standards should we enforce (vehicle age, maintenance, replacement SLA), and how do we stop exceptions from becoming routine?
B1349 Executive fleet standards and exceptions — For India corporate Corporate Car Rental (CRD) services, what fleet governance standards (vehicle age, cleanliness checks, maintenance logs, replacement SLAs) matter most for executive experience, and how do Admin and Finance prevent exceptions from quietly becoming the norm?
For corporate car rental services in India, the fleet governance standards that most directly protect executive experience are strict limits on vehicle age, auditable cleanliness and safety checklists per trip, time-bound maintenance and replacement SLAs, and centralized compliance tracking rather than ad-hoc vendor assurances. Admin and Finance prevent exceptions from becoming the norm by codifying these standards in contracts, linking invoices to compliance evidence, and using exception reporting as a governance signal instead of allowing “one-time” deviations to pass silently.
Vehicle age caps matter because older vehicles correlate with higher breakdown risk, visible wear, and comfort issues. Most organizations treat maximum vehicle age, fitness validity, and documented pre-induction checks as baseline controls for executive fleets. Cleanliness checks and safety-inspection checklists before each duty are critical because executives often judge service quality on visible hygiene and perceived safety, and these are easy to standardize and audit. Maintenance logs and preventive schedules support uptime and reduce mid-trip failures, especially when combined with centralized fleet compliance dashboards and random route or vehicle audits.
Replacement SLAs are central for executive experience because even the best-maintained fleet fails occasionally, so Admin teams rely on written, time-bound commitments for replacement cabs, buffer vehicles, and escalation matrices. Admin and Finance stop “one-off” exceptions from normalizing by enforcing maker–checker reviews on fleet induction, tying payment to SLA and compliance KPIs, and using centralized billing plus trip-level data to spot patterns of repeated exceptions.
Key practices Admin and Finance teams use to keep standards real and not aspirational include:
-
Embedding hard thresholds into contracts.
Examples include maximum vehicle age, mandatory fleet-compliance checks before induction, and required documentation (fitness certificates, permits, insurance). -
Using checklists and logs that are trip-linked.
Cleanliness and safety inspection checklists attached to trip records ensure that hygiene and safety are not left to driver discretion. -
Requiring centralized compliance management.
Admin relies on systems that track document expiries, inspection status, and non-compliance flags for vehicles and drivers rather than manual spreadsheets. -
Auditing exception handling.
Replacement SLAs and business continuity plans are tested through real incidents and drills, with Admin tracking time-to-replace and cause of failure. -
Linking Finance approvals to evidence.
Finance uses centralized, accurate, and timely billing tied to trip and SLA data, so that chronic non-compliance (e.g., repeated use of over-age vehicles) shows up as a pattern, not as invisible noise. -
Designing contracts to avoid silent drift.
Contracts include penalties, performance guarantees, and escalation paths, ensuring that “temporary” deviations cannot quietly become the default operating model without being visible in reports or QBRs.
These governance standards directly influence executive satisfaction and perceived reliability, while the combination of contractual controls, centralized data, and active exception management helps Admin and Finance maintain discipline over time instead of normalizing shortcuts.
images:
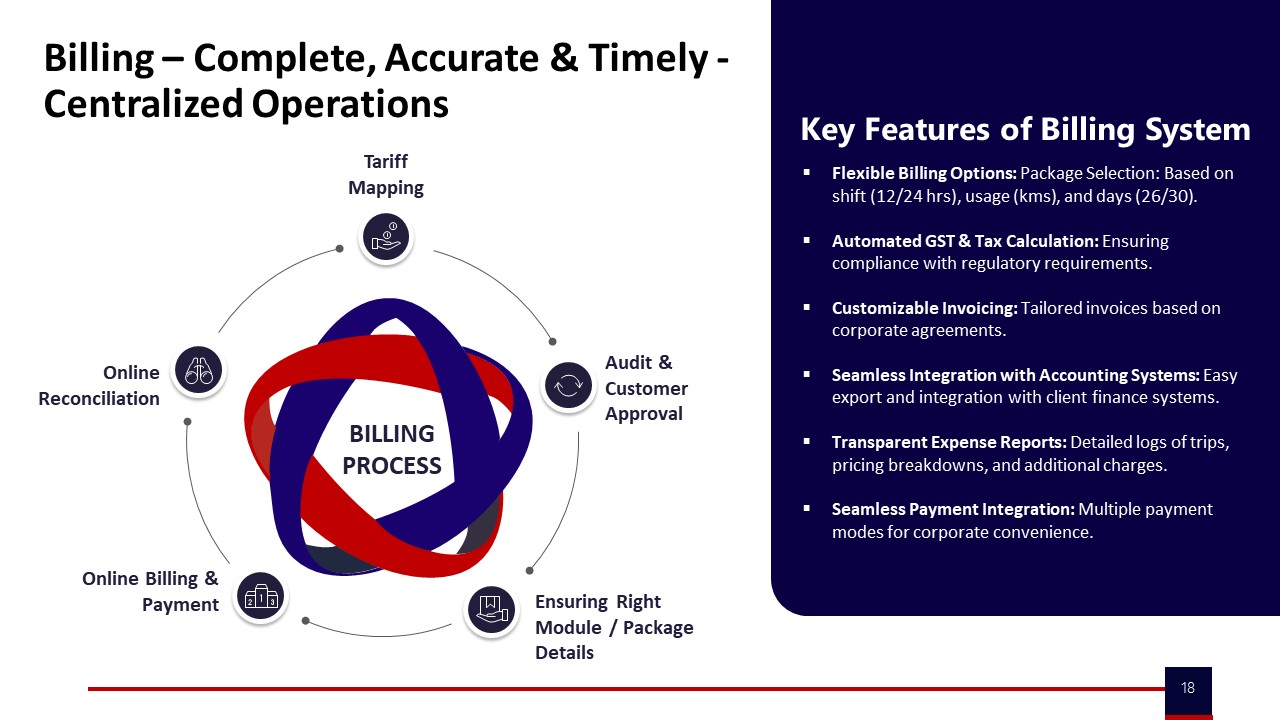

What controls stop vendors from using unapproved drivers/vehicles, but still let us scale during peak demand or events?
B1350 Prevent rogue subcontracting in surges — In India corporate Employee Mobility Services (EMS) multi-vendor operations, what driver & fleet governance controls prevent “rogue” subcontracting (unapproved vehicles/drivers) while still allowing surge capacity during peak demand or project events?
Most organizations prevent “rogue” subcontracting by making driver and fleet access entirely compliance‑gated and command‑center controlled, then using pre‑approved buffer vendors and vehicles for surge instead of ad‑hoc additions. The transport command center acts as the single gatekeeper for which driver, which vehicle, on which trip, with every exception traceable in audits and visible to HR, Security, and Finance.
A common failure mode in India EMS is allowing vendors to “manage shortages” informally. That breaks women‑safety protocols, invalidates insurance, and leaves HR with no audit trail when an incident happens. WTi‑style controls avoid this by enforcing a structured onboarding and compliance regime for every vehicle, driver, vendor, and site before they ever appear in the routing system. Only those assets can be scheduled, tracked, billed, or used for night‑shift or female‑first routes.
To retain flexibility for peaks or project events, capacity is created through pre‑inducted standby cars, project fleets, and tier‑2 vendors that have already cleared the same fleet and driver compliance checks and contract terms. Surge is then a commercial and rostering decision, not a safety compromise or informal substitution by the L1 vendor. The centralized command center and alert supervision system monitor live trips for deviations, letting transport heads see in real time if a plate number or driver ID does not match the roster.
Key governance controls that prevent rogue subcontracting yet allow surge include:
- Centralized compliance management for fleet and drivers. Vehicles undergo structured fleet compliance and induction with documented checks on age, condition, statutory documents, and a maker‑checker review process before activation. Drivers go through a defined Driver Assessment & Selection Procedure (DASP), background verification, health checks, and induction training before they receive trips. Unapproved assets never appear in the routing / dispatch layer.
- Vendor and statutory compliance as a contract discipline. Each vendor signs formal contracts with clear clauses against unauthorized subcontracting, supported by periodic audits and statutory compliance checks. Vendor & statutory compliance frameworks create a documented chain between the enterprise, the primary vendor, and any pre‑approved secondary vendors, making it risky and detectable for a vendor to insert unregistered vehicles or drivers.
- Command‑center‑based dispatch with GPS and driver/vehicle tagging. Trips are assigned only to pre‑tagged vehicles and drivers through the central command center or automated dispatch engine. The EV/transport command center dashboard, alert supervision system, and transport command centre views cross‑check live GPS, assigned driver IDs, and plate numbers. Any mismatch between planned and live assets triggers alerts (e.g., geofence violation, device tampering) that the operations team can escalate before or during trip start.
- Integrated driver, vendor, and employee apps with manifest locking. Driver and vendor apps show only assigned trips to approved drivers and vehicles. Employee apps display the confirmed vehicle and driver details, with QR or OTP‑based trip verification and live tracking. This creates a soft field‑level control because any last‑minute, unapproved swap is visible to the passenger and the command center, and will not reconcile in billing or reports.
- Business continuity and surge capacity playbooks using pre‑approved buffers. Business Continuity Plans and Guarantee for Uninterrupted Services collateral define buffer vehicles, alternate vendors, and cross‑support from associated businesses for shortages, strikes, or system failures. These buffers go through the same fleet and driver compliance induction as primary assets. During peaks or project events, the command center activates these pre‑cleared resources rather than allowing vendors to source unknown vehicles.
- Multi‑tier vendor framework and governance structure. A managed service provider governance structure uses a central command center plus location‑specific centers to tier vendors and allocate time bands or regions. Capability parameters, “How we are different,” and supplier solution USPs emphasize WTi’s role as operations‑backed aggregator, allowing multiple vendors but under one compliance and SLA umbrella. Rogue additions are minimized because every vendor sits inside a central visibility and escalation framework.
- Audit‑ready, tech‑based performance and compliance evidence. Tech‑based measurable and auditable performance flows, centralized dashboards, and indicative management reports tie trip manifests, GPS logs, driver IDs, and vendor codes into one data set. Any trip served by an unapproved asset shows up as a deviation in compliance, safety, or billing reports, which Procurement and Finance can act on with penalties or vendor tiering changes.
- Strict safety and women‑centric protocols bound to approved assets. Women‑centric safety protocols, safety & security frameworks, and chauffeur excellence programs are linked to vetted drivers and vehicles only. Escort rules, women‑only or female‑first routing, and SOS workflows rely on known identities and training history. This makes it operationally impractical and contractually risky for vendors to push unknown drivers onto sensitive night or female routes.
These controls shift the role of the Facility / Transport Head from reactive policing of vendors to running a predictable command‑center with clear SOPs. Surge capacity is not denied but is front‑loaded into the design: buffer vehicles in BCP, project commute services with dedicated fleets, flexible package options, and scalable EV/project fleets are all pre‑approved. This keeps OTP stable during festivals, monsoon disruptions, or large events without letting ad‑hoc subcontracting creep back in.
images:
What weekly/monthly governance routines actually reduce firefighting for the transport team, instead of adding more admin?
B1351 Governance rituals that reduce firefighting — For India corporate ground transportation (EMS), what practical weekly and monthly governance rituals (driver performance huddles, audit sampling, coaching loops, penalty waivers) actually reduce operational firefighting rather than creating more admin work for Facilities/Transport teams?
Effective governance rituals in Employee Mobility Services reduce firefighting when they are short, data-fed, and tied to clear SOP actions rather than generic meetings. The most effective patterns in India EMS use command-center style observability, light-touch samples, and tightly scoped huddles that convert alerts into fixes for routing, drivers, and vendors.
Weekly rituals that reduce noise
Weekly reviews work best when rooted in Command Center and Alert Supervision System data, not manual spreadsheets. Transport heads should receive a single, automated weekly pack from the mobility platform or NOC covering OTP%, exception logs, safety alerts, and driver fatigue proxies for the last 7 days.
Short driver performance huddles are effective when limited to flagged outliers only. A 20–30 minute weekly briefing with the small set of drivers breaching speed, route deviation, or repeated late reporting uses telematics, GPS, and Alert Supervision System evidence to agree individual corrective actions instead of lecturing the full pool.
Weekly route and roster sanity checks prevent last-minute chaos. Reviewing only the top 5–10 problem routes by delay or complaints and cross-checking against monsoon, political events, or infrastructure changes keeps routing and shift windowing aligned without reworking the entire plan.
Operations teams benefit from a weekly vendor and fleet compliance spot-audit. A small, rotating sample drawn from centralized compliance dashboards and vehicle induction logs is enough to catch drift on documentation, fitness, and chauffeur credentials before they trigger escalations.
Coaching loops should be anchored to specific case studies from the week. Using real trips where safety rules, women-centric protocols, or SOS handling worked or failed creates targeted micro-training instead of generic toolbox talks.
Monthly rituals that stabilize the system
Monthly governance works when it behaves like a QBR for transport, not a blame session. A structured one-hour review across HR, Facilities, Security, and the primary vendor uses single-window dashboards on OTP%, incident logs, CO₂ metrics, and Commute Experience Index inputs to agree 3–5 concrete fixes.
Driver performance should be linked to a formal monthly scorecard. Combining incident-free operation, on-time adherence, feedback scores, and training attendance allows targeted rewards and early identification of high-risk or fatigued drivers without daily micro-management.
Audit sampling should follow a clearly defined monthly pattern. Pulling a statistically small but representative set of trips, routes, and billing entries from centralized billing and compliance systems verifies audit trail integrity and reduces end-of-quarter surprises for Finance and HSSE.
Penalty and waiver decisions are best handled in a monthly SLA and commercial review. Facilities, Procurement, and the vendor can review SLA breaches, dead mileage, and genuine force majeure events together and agree structured waivers, preventing ad-hoc fights on every shift while still enforcing discipline.
Monthly change-control on routing, fleet mix (ICE vs EV), and capacity buffers should be backed by Command Center analytics and seasonality. Using data-driven insights rather than ad-hoc requests reduces rushed interventions during peaks, monsoon, or city-wide disruptions.
Design principles so rituals do not become extra admin
- Every ritual must start from platform dashboards and command-center reports, not manual collation.
- Participants should be limited to the roles that can act on the outcome, such as driver supervisors, vendor leads, and Facilities heads.
- Each ritual should end with a short, written action list with owners and due dates, feeding back into the Command Center and compliance systems.
Rituals that follow these principles convert continuous monitoring, safety frameworks, and centralized billing into fewer night-shift calls and fewer senior escalations instead of more paperwork for transport teams.
How can we tell if declining commute NPS is really due to driver churn, versus routing or app issues, before we consider switching vendors?
B1352 Diagnose driver churn vs NPS — In India corporate EMS shift transport, how can HR measure whether driver churn is the real root cause of declining commute NPS versus routing changes or app issues, before pushing for a vendor switch that may not fix morale?
In Indian corporate EMS shift transport, HR can separate driver churn from routing or app issues by building a simple, evidence-based view that links commute NPS with three data streams. The three streams are driver stability, routing changes, and tech reliability, each measured over the same time window and mapped to complaint patterns.
HR teams gain clarity when they first tag every commute complaint and low NPS response to a primary cause. The primary causes are driver behavior, punctuality, routing or detours, and app or tracking problems. Complaint tagging works best when it uses the existing EMS feedback tools and helpdesk tickets. This approach exposes whether negative feedback clusters around specific drivers, around certain routes or shifts, or around app failures.
Driver churn needs its own basic set of operational metrics. Useful signals include monthly driver attrition rate on EMS routes, percentage of trips run by new or temporary drivers, and repeat complaints per driver ID. HR can request these from the transport head or vendor using existing ETS or Commutr dashboards and driver management reports. Rising churn usually shows up as more new drivers on night shifts, higher incident or OTP deviations on new-driver trips, and location-wise gaps in standby coverage.
Routing and app issues have different signatures. Routing problems often correlate with shift or route changes, monsoon periods, or new site start-ups, and they show up as clustered OTP failures regardless of driver identity. App issues show up as spikes in tickets referencing booking failures, live-tracking gaps, OTP mismatches, or SOS/app downtime within narrow time windows. These patterns are visible in command center logs, alert supervision systems, or technology MIS from the EMS platform.
HR can then run a simple side-by-side comparison over 4–8 weeks. HR compares routes or shifts with stable drivers versus those with frequent driver changes and checks the difference in NPS, OTP, and complaint rate. HR also compares weeks with major routing or roster changes against periods with stable routing. Finally, HR overlays app uptime or incident logs from IT or the vendor over the same time period. The strongest correlation in this three-way comparison usually points to the dominant root cause.
Before escalating for a vendor switch, HR can set a short, controlled trial with specific guardrails. Example guardrails are stabilizing driver assignments on critical shifts, freezing routing for a few weeks on problem corridors, and enforcing tighter app monitoring with defined incident-reporting SLAs. If NPS improves primarily when driver stability improves, driver churn is likely the main root cause. If NPS shifts mainly when routing is adjusted or app incidents reduce, then routing design or technology reliability is the more important target than vendor replacement.
To keep this process operationally light, HR can work with the facility or transport head to define three or four standard monthly checks. These checks include a driver stability and attrition snapshot by shift band, a route-level OTP and detour summary, an app uptime and incident summary, and a commute NPS cut by shift, route, and driver tenure band. These checks create a repeatable SOP so that HR can answer leadership questions with data rather than intuition and avoid triggering large vendor changes for problems that sit in driver management, routing logic, or app performance.
images:
What controls make driver incentives and penalties fully traceable to trip logs so Finance doesn’t face billing disputes during audits?
B1353 Traceable incentives and penalties — For India corporate ground transportation billing governance in EMS/CRD, what controls ensure driver incentive payouts and penalties are traceable to trip logs so Finance can avoid disputes and protect audit credibility?
For India corporate ground transportation in EMS/CRD, driver incentives and penalties become audit-safe only when every rupee is algorithmically linked to an approved trip log, governed tariff, and documented exception workflow. Finance teams gain dispute protection when billing systems use standardized trip data, rule-based earnings engines, and reconciled summaries that tie directly into centralized, time-stamped mobility records.
A robust model starts with complete, tamper-evident trip logs. Each trip requires unique IDs, GPS-backed start–end time, distance, route adherence, roster linkage, and OTP or manifest verification. Command-center tools and alert systems such as over-speeding or geofence violations feed into this record so exceptions are structured data, not narrative claims. This mirrors centralized compliance management and alert supervision practices described in the collateral, where every deviation generates a traceable event.
On top of those logs, the earnings engine must use predefined, version-controlled tariff mapping and incentive/penalty rules. The system should compute base pay, incentives (e.g., high OTP, night-belt performance, EV uptime support), and penalties (e.g., no-show after reporting, non-compliance) automatically. This aligns with the “tariff mapping, online reconciliation, and customer approval” approach used in billing–centralized operations collateral. Finance can then validate that any additional payout or deduction is formula-driven and parameterized, not manual.
Finance protection depends on multi-level reconciliation. First, trip-level outputs roll into driver-wise statements for the pay period that can be cross-checked against centralized dashboards and indicative management reports. Second, those driver statements aggregate into vendor invoices through a centralized billing system with automated tax calculations and flexible billing models (per km, trip, FTE, pay-per-usage). Third, customer approval workflows for billing, as seen in WTi’s billing process diagrams, confirm that the client agrees with the underlying trip counts, SLAs, and exceptions before Finance processes payments.
Governance needs clear maker–checker controls and audit trails. Centralized operations collateral emphasizes maker–checker for document uploads and compliance; the same principle should apply to incentive and penalty overrides. Any manual adjustment must require dual authorization, reason codes, and attachment of supporting evidence (e.g., command-center screenshots, incident reports). This creates an immutable chain-of-custody from trip log to final payout.
To make this operationally stable rather than reactive, organizations typically embed these controls into their EMS/CRD platforms and dashboards. Command centers and transport desks use a single-window reporting layer, like the dashboards and data-driven insights collateral, so HR, Transport, and Finance see the same KPIs: OTP%, trip adherence, exceptions, and driver performance indicators. This reduces finger-pointing because disputes can be traced back to a shared system-of-record.
From an audit and Finance standpoint, the critical controls are:
• Trip log integrity. GPS + OTP-based closure, route adherence audits, and incident tags stored centrally for the statutory retention period.
• Rule-based computation. Incentive and penalty slabs codified in the system, referenced to service-level metrics such as OTP, safety compliance, and EV utilization.
• Centralized billing linkage. Automated mapping from trip and driver statements to invoices, with customer approval checkpoints and online reconciliation.
• Maker–checker and override governance. Dual control on exceptions, with reason capture and attachments.
• Standardized reporting. Periodic MIS and management reports that show variance between planned vs. actual trips, payouts vs. contracts, and historical trend lines for driver incentives and penalties.
Most Finance teams also expect clear data-extract capabilities from mobility platforms. Centralized dashboards such as “Customized Dashboard” and “Billing – Complete, Accurate & Timely” collateral show how raw trip and billing data can be exported with consistent schemas. This allows Finance and Internal Audit to run independent spot checks, re-perform calculations, and verify that incentive and penalty logic is applied consistently across vendors and cities.
A common failure mode is relying on vendor-side spreadsheets or manually edited PDFs to calculate driver earnings. Those approaches break the traceability from trip log to payout and invite disputes. In contrast, when EMS/CRD billing is anchored on central trip data, formal tariff mapping, and online reconciliation with client approval, Finance can defend every number during internal and statutory audits with confidence.
What thresholds should auto-trigger retraining or removal (complaints, deviations, harsh braking, no-shows), and who should own that decision—HR, EHS, or Ops?
B1354 Auto-triggers for retraining or removal — In India corporate Employee Mobility Services (EMS), what escalation thresholds in driver & fleet governance (e.g., repeat complaints, route deviations, harsh braking flags, no-show patterns) should automatically trigger retraining or removal, and who should own the decision—HR, EHS, or Operations?
In Indian corporate Employee Mobility Services, escalation thresholds for driver and fleet governance work best when they are objective, low-latency, and tied to automatic actions like retraining or removal from duty. These thresholds should be owned operationally by Transport/Operations, safety-governed by EHS/Security, and policy-backed by HR, with clear SOPs and audit trails.
For driver behavior and service quality, most organizations treat a small cluster of repeat events as the trigger point. A common pattern is 2–3 similar complaints on conduct or service quality for the same driver within a defined window leading to mandatory coaching and monitoring. A higher threshold such as 4–5 validated complaints or any single serious safety complaint usually results in temporary suspension from duty pending investigation and HR/EHS review. This approach reduces subjective arguments and gives the Transport Head a clear playbook at shift level.
For telematics-led risks like harsh braking, over-speed alerts, or route deviations, thresholds are usually defined as combinations of frequency and severity. A small number of mild deviations in congested Indian traffic is expected, but repeated or extreme events flagged by GPS, IVMS, or geo-fence violations are treated as risk indicators. When the same driver crosses a pre-set count of harsh-braking or speeding flags within a month, Operations should trigger retraining and closer monitoring. If route deviations coincide with night shifts or women passengers, even a single unexplained deviation is treated as a serious incident and escalated immediately to EHS/Security for investigation.
For reliability failures such as no-show patterns, OTP misses, and repeated late arrivals, most mature programs use automated thresholds linked to SLAs. A pattern like 2–3 no-shows or recurring late pickups in a short period for the same driver or vehicle leads to temporary removal from priority rosters and a corrective meeting with the Transport team. Higher patterns or impact on critical shifts can justify replacing the driver or reallocating vehicles under vendor-governance rules. This ties driver governance directly to on-time performance and reduces day-to-day firefighting for the Facility/Transport Head.
Decision ownership is most stable when it follows a tiered governance model with clear roles. Transport/Operations should own first-line decisions such as immediate de-allocation from a shift, temporary removal from roster, and scheduling of retraining, because they live the operational impact and answer the phone at 2 a.m. EHS/Security should own decisions where safety, escort compliance, night routing, or incident risk are involved, including whether a driver returns to duty after a serious or repeated safety flag. HR should own the policy, documentation, and any employment or contractor consequences, ensuring fairness, escalation handling, and audit readiness.
A practical approach is to codify thresholds and actions in a joint SOP signed by HR, EHS/Security, and Transport. The SOP should define specific numeric or pattern-based triggers, such as complaint counts, telematics scores, and OTP thresholds, and map them to pre-agreed actions like coaching, probation, or removal. It should also specify which events require immediate cross-functional review, particularly for women-safety, night shifts, and high-severity route deviations. This reduces ambiguity, protects all stakeholders in audits, and creates operational calm for the Facility/Transport Head.
images:
What minimum data and audit trail do we need for driver onboarding and performance actions so IT and Audit are comfortable if we’re reviewed later?
B1355 Audit trails for driver actions — For India corporate ground transportation IT governance supporting EMS, what minimum data and audit trail should exist for driver onboarding and performance actions (who approved, when, evidence attached) so the CIO is comfortable under DPDP-style scrutiny and internal audit reviews?
For a CIO to be comfortable under DPDP-style scrutiny and internal audit, driver onboarding and performance actions need a complete, queryable “who did what, when, on what basis” record. The minimum standard is a structured driver master record plus an immutable activity log that links every key decision to evidence and approvers.
At onboarding, each driver should have a unique driver ID, mapped to only the minimal personal data needed for EMS operations. The system should store verified KYC and licensing status, medical and background verification outcomes, and induction/training completion, not raw documents in ad‑hoc folders. Evidence such as address checks, criminal records, licence verification, and medical certification should be referenced as controlled artefacts with version and expiry dates, as reflected in the detailed checks described in the Driver Compliance and Fleet Compliance collaterals.
Every compliance-relevant change must generate an audit event. Each event needs timestamp, actor ID or system process ID, action type (e.g., “onboarded,” “suspended from night shifts,” “training completed”), driver ID, location or branch, and the business reason code. The record should point to supporting artefacts such as training attendance records, refresher-safety modules, or incident reports, similar to the structured driver management and training flows shown in the “Driver Management & Training” and “Driver Training & Rewards (RNR) Sessions” materials.
For performance and disciplinary actions, the system should maintain links between the driver, the triggering data (e.g., speeding alerts, SOS-related incidents, geofence violations from the Alert Supervision System), the reviewer, and the final decision. Each step requires a captured approver identity, decision timestamp, and reference to any investigation notes. This enables reconstruction of why a driver was warned, retrained, or removed from certain routes and proves that safety and HSSE-related controls, like those in the “Safety and Compliances” and HSSE culture reinforcement materials, were actually enforced.
From a DPDP perspective, the platform must also log data-access and data-change events for driver records. Each read, update, or export of personal or sensitive data needs an entry that records who accessed it, when, for which workflow, and under which role. This aligns with continuous-assurance expectations and supports both internal audit and external scrutiny on data minimization and purpose limitation in EMS operations.
How should the contract define a qualified substitute driver/vehicle so Ops can keep service running without later being accused of compromising safety or compliance?
B1356 Define qualified substitute driver/vehicle — In India corporate Employee Mobility Services (EMS) operations, how should the vendor contract define “qualified substitute driver” and “approved substitute vehicle” so Facilities can keep service running without later being accused of compromising safety or compliance?
In India EMS operations, a “qualified substitute driver” and “approved substitute vehicle” should be defined in the contract as pre-validated, pre-documented assets that meet the same compliance, safety, and service standards as the primary assignment, with every substitution captured in an auditable trail. Contract language should make clear that substitutions are allowed only from this pre-cleared pool and must be visible to the command center in real time.
A qualified substitute driver should be defined through objective criteria. The contract should require full driver compliance verification such as address and criminal checks, driving licence verification, identity checks, court record checks, and medical certification, as shown in WTi’s driver compliance and induction processes. The agreement should mandate completion of initial and periodic training, including defensive driving, POSH and customer handling, women-safety protocols, and any client-specific SOPs that are already applied to primary drivers. The vendor should be required to keep driver documentation and training records current, with automated alerts and random audits through a centralized compliance management process.
An approved substitute vehicle should be defined via fleet compliance standards. The contract should insist on adherence to fleet induction criteria such as vehicle age and condition limits, statutory documentation, mechanical and electrical checks, and safety-equipment verification, as outlined in WTi’s fleet compliance and induction collateral. The agreement should require all substitute vehicles to pass the same safety inspection checklist and upload documents into the centralized compliance system before they can be dispatched.
To protect Facilities from blame, the contract should require that any substitution be logged in the operational system with time stamps, driver and vehicle IDs, and linkage to the trip. The service provider’s command center should monitor substitutions, trigger alerts if a non-approved driver or vehicle is assigned, and maintain an auditable record aligned with safety and compliance dashboards. Facilities should be given access to periodic reports summarizing all substitutions, their compliance status, and any exceptions closed, so they can demonstrate that service continuity never meant relaxing standards.
For project/event commute runs, what fleet governance practices prevent last-minute vehicle failures when delays aren’t acceptable?
B1357 Event fleet readiness governance — For India corporate Project/Event Commute Services (ECS), what fleet governance practices help prevent last-minute vehicle failures (maintenance readiness checks, standby ratios, replacement time SLAs) when there is zero tolerance for delays and reputational fallout is immediate?
For India corporate Project/Event Commute Services, fleet governance prevents last‑minute vehicle failures by enforcing pre-defined maintenance readiness checks, explicit standby ratios, and strict replacement-time SLAs that are monitored from a command centre. These controls shift ECS from ad‑hoc vendor dependence to a predictable, auditable operating model where time-bound delivery is protected even when individual vehicles fail.
Effective ECS governance starts with structured pre-induction and ongoing readiness checks for every vehicle. Operators use checklists similar to WTi’s fleet compliance and safety inspection artefacts to verify statutory documents, mechanical and electrical health, and safety equipment before a vehicle is tagged to an event or project. Governance improves when these checks follow a maker–checker process and are supported by centralized compliance dashboards that surface any expired permits, missing documents, or recent defect reports before allocation.
Standby ratios need to be defined by route cluster and timeband, not at a generic project level. Most operations teams maintain a buffer pool, as described in WTi’s Business Continuity Plans, where additional vehicles and associated partners can be activated quickly during shortages, weather disruptions, or breakdowns. A clear rule of thumb is to maintain dedicated standby vehicles for peak windows and high-risk routes and to tag which vendor or partner supplies each standby asset so there is no ambiguity at dispatch time.
Replacement-time SLAs must be explicit, measurable, and linked to penalties and escalation. ECS contracts work better when they define maximum allowed time to push a replacement vehicle from breakdown confirmation to wheels-on-ground at the pickup location. These SLAs are enforced through a 24x7 command centre that monitors real-time GPS, incident alerts, and driver calls, and that can trigger predefined contingency actions, including rerouting nearby vehicles or activating additional vendors as described in WTi’s transition and continuity materials.
Useful governance signals include: percentage of vehicles passing pre-event readiness checks, number of last-minute substitutions per 100 trips, average replacement time vs. SLA, and the share of trips protected by standby capacity. Facilities and transport heads rely on these metrics, alongside centralized dashboards and alert supervision systems, to reduce on-ground firefighting and avoid reputational fallout during high-visibility events.
What are common ways driver incentive plans hurt morale for drivers and the transport coordinators, and how can we spot that early?
B1358 Detect incentive-driven morale issues — In India corporate EMS shift transport, what are the most common ways driver incentive plans backfire on team morale—both for drivers and for internal transport coordinators—and how do leaders detect those signals early?
In India corporate EMS shift transport, driver incentive plans most often backfire when they reward narrow metrics like trip count, kilometers, or OTP in isolation. These designs can erode driver morale through perceived unfairness and fatigue, and they can burn out internal transport coordinators who must keep the system running despite distorted behavior.
Poorly structured incentives often push drivers to chase more trips or stringent OTP without regard to rest norms, safety protocols, or route adherence. This undermines fatigue management, increases incident risk, and can conflict with women-safety or night-shift policies that EMS programs must uphold under Indian OSH and transport norms. When incentives ignore hybrid-work volatility and daily roster shifts, drivers see rewards as luck-based rather than effort-based, which weakens trust and loyalty.
For internal transport heads and coordinators, incentive schemes that focus only on high-level OTP or cost per km can increase daily firefighting. Coordinators face pressure to “hit numbers” despite driver shortages, weather, or fragmented vendor performance, which can harm relationships with both drivers and HR. When incentives are not aligned with centralized command-center data, SLA governance, and compliance dashboards, transport teams end up reconciling conflicting priorities manually, driving frustration and attrition.
Leaders can detect backfiring incentives early by monitoring a few specific signals:
- Safety and compliance drift. Rising incident reports, geofence violations, or escort-rule breaches alongside improved OTP or trip volumes indicate unhealthy pressure.
- Fatigue and churn patterns. Higher driver attrition, more sick days around peak shifts, or deteriorating Driver Fatigue Index values signal over-incentivized output.
- Data mismatches. Growing gaps between rostered demand and actual seat-fill, dead mileage, or route adherence suggest incentives are driving gaming rather than efficiency.
- Escalation noise. More night-shift complaints to HR or Security, and more last-minute escalations to the command center, show coordinators are absorbing incentive distortion.
- Morale feedback. Negative feedback in driver training sessions, RNR meetings, or floor-connect forums indicates perceived unfairness or opaque rules.
Most EMS leaders benefit from linking incentives to balanced KPIs such as OTP, safety compliance, Trip Adherence Rate, and audit-ready behavior, instead of single-point metrics. Transport heads can then use command-center dashboards, incident logs, and driver feedback loops to tune incentive rules before they damage trust or operational stability.
images:
%20Sessions.JPG)
How do we stop vendors from quietly swapping in downgraded vehicles, while still allowing flexibility when availability is tight?
B1359 Prevent vehicle downgrades in rotation — For India corporate ground transportation (EMS/CRD), how do procurement and operations prevent vendors from quietly rotating different vehicles than contracted (model downgrades, missing safety features) while still keeping dispatch flexible when fleet availability is tight?
For Indian corporate EMS/CRD programs, procurement and operations prevent silent vehicle downgrades by making vehicle specification and compliance auditable at trip level, and they preserve flexibility by defining clear “equivalent class” rules and exception SOPs rather than rigid plate-level commitments.
Procurement teams typically lock specifications into contracts using fleet-compliance and induction requirements. They define acceptable vehicle age, model category, and mandatory safety and comfort features, and they back this with pre‑induction checks, maker–checker documentation and centralized compliance management. Operations then enforce these rules through command-center monitoring, GPS-linked fleet tagging, and periodic route adherence and vehicle audits instead of relying only on vendor assurances.
To avoid “quiet rotation” of inferior cars, organizations use structured onboarding and compliance processes for vehicles and drivers. They register every inducted vehicle with documentation, fitness, and safety checklists, and they use tools such as centralized compliance management dashboards, vehicle deployment and quality assurance workflows, and safety inspection checklists. A common failure mode is allowing ad‑hoc substitutions during peaks without logging them, so leading programs mandate that any substitute vehicle must already be in the compliant fleet pool and that substitutions are visible to the command center and to employees through apps.
Flexibility under tight availability is preserved by contracting at the model-class level and by defining exception bands. Contracts can specify a primary model set with a clearly defined “equivalent or higher” model list that is allowed without pre‑approval, and a separate “lower class only under exception” rule tied to explicit approvals and commercial adjustments. Dispatch remains dynamic, but only among pre‑approved, fully inducted vehicles that meet compliance and safety standards, including women-safety and HSSE requirements.
Practical guardrails that procurement and operations combine include:
- Contracted fleet-compliance and induction criteria for age, documentation, and safety equipment.
- Centralized command centers and dashboards that show which tagged vehicles are serving which trips.
- Random audits and maker–checker policies that compare contracted classes to live trip logs.
- Clear SOPs for peak-time exceptions, where any downgrade is pre‑approved, recorded, and commercially reconciled.
For long-term rentals, what fleet governance metrics should Finance track to keep costs predictable and avoid surprise downtime/substitution charges?
B1360 LTR metrics for cost predictability — In India corporate Long-Term Rental (LTR) programs, what fleet governance metrics should Finance insist on (uptime, preventive maintenance compliance, replacement lead times) to keep monthly rentals predictable and avoid surprise costs from downtime substitutions?
Finance teams in India should insist on a small, non-negotiable set of fleet governance metrics for Long-Term Rental programs that directly anchor uptime, continuity, and substitution risk to predictable monthly rentals. These metrics must cover vehicle availability (uptime), preventive maintenance discipline, and replacement timelines so that any downtime or substitutions are visible, measured, and commercially governed.
Finance should require a clearly defined uptime metric for each dedicated vehicle under LTR. This metric should be expressed as Fleet Uptime percentage over the billing cycle. It should be tied to contract clauses that link penalties or credits to uptime thresholds. This protects against hidden revenue leakage from frequent unplanned downtime.
Preventive maintenance needs its own compliance metric. Finance should insist on documented preventive maintenance schedules for all LTR vehicles. Finance should also insist on a Maintenance Cost Ratio and a record of on-time versus delayed maintenance tasks. These records should be auditable and linked to vehicle fitness and utilization reports.
Replacement continuity must be tracked separately from uptime. Finance should define a maximum Replacement Lead Time for any vehicle that goes off-road for more than an agreed duration. This metric should measure the time from incident or breakdown logging to like-for-like replacement being deployed. Finance should insist this is part of the Service Level Compliance Index.
Finance should connect these operational metrics to commercial protections. Monthly rentals should assume a minimum Fleet Uptime percentage with clearly defined credits whenever uptime drops below that floor. Contracts should cap chargeable dead mileage during replacements to prevent unexpected cost per kilometer spikes. Trip Adherence Rate and On-Time Performance can be used as secondary indicators to ensure that “available” vehicles are actually usable without degraded service.
A basic LTR finance checklist can include: - Fleet Uptime % per vehicle per month. - Preventive maintenance schedule adherence rate. - Replacement Lead Time for off-road incidents. - Dead mileage cap and reporting. - Maintenance Cost Ratio trends across the fleet.
If we’re launching a new site, what’s the minimum governance we need for drivers and fleet without overwhelming the coordinator but still avoiding predictable failures?
B1361 Minimum viable governance for new sites — For India corporate Employee Mobility Services (EMS), what is a practical ‘minimum viable governance’ setup for a new site launch (driver onboarding, reviews, incentives, substitutions) that avoids overwhelming a junior transport coordinator but still prevents predictable failures?
A minimum viable governance setup for a new EMS site in India should standardize a few critical controls for drivers, reviews, incentives, and substitutions, and run them through a simple, repeatable cycle anchored in a basic command-center style view. This kind of setup reduces predictable failures such as unsafe drivers, absent backups, and silent SLA breaches, without flooding a junior transport coordinator with complex processes or tools.
A practical approach is to define a narrow, non-negotiable checklist for driver onboarding and induction that covers licensing, background verification, basic training, and safety orientation. The collateral describes structured driver assessment and training processes, including VIVA assessments, written tests, practical driving evaluations, medical checks, and criminal record verification. A minimum viable version should retain the essential risk controls like license validation, address and criminal checks, vehicle documentation, and a short induction module on traffic laws and soft skills.
Regular but lightweight reviews help maintain standards without overloading operations. The driver compliance and induction material shows how audits, periodic feedback reviews, and health reassessments can maintain quality. A minimum viable governance model can rely on short shift-wise briefings, basic performance tracking on on-time performance and incident-free trips, and occasional audits of trip logs, while using centralized compliance dashboards only for exception monitoring.
Incentives and substitutions should be defined as simple SOPs tied to visible metrics. The training and rewards collateral shows that safe driving, customer handling, and seasonal training can be linked to recognition and morale. A minimal system can reward drivers for clean safety records and consistent punctuality, while a basic business continuity plan manages substitutions through a buffer fleet, associated businesses’ support, and predefined responses to strikes, technology failures, and disasters. This combination creates early alerts, predictable escalation paths, and a quiet, stable operation for the junior coordinator.
images:

How do we enforce strict driver governance without making OTP worse because we lose capacity during driver shortages?
B1362 Balance strict governance and shortages — In India corporate EMS operations, how should leadership balance strict driver governance (removals, penalties) against the reality of driver shortages, so OTP stability improves rather than collapsing due to capacity loss?
In Indian corporate EMS operations, leadership stabilizes OTP when driver governance is strict on safety and compliance but flexible on remediation and capacity planning. Strict, one‑strike removals used without buffers and coaching usually degrade OTP because they shrink already constrained capacity and raise driver attrition.
Leadership needs to define a tiered governance model that separates non‑negotiables from coachable gaps. Irrecoverable violations like alcohol, deliberate harassment, major fraud, or repeated document forgery should trigger immediate removal and permanent vendor escalation. Operational lapses like minor route deviations, soft behavioral issues, or first‑time tardiness should trigger graded actions such as counseling, retraining, and monitored probation before any removal decision.
Driver governance should be backed by proactive workforce planning. EMS operators who rely only on “paper SLAs” without supply buffers typically see OTP collapse when 5–10% of drivers are suspended at once. A more robust model maintains standby capacity, multi‑vendor aggregation, and a pipeline of pre‑screened drivers that can be inducted quickly under a documented onboarding process. Business continuity plans and duty‑cycle monitoring help prevent burnout, which otherwise feeds further attrition and unreliability.
Data‑driven governance improves this balance. Leadership should track metrics like Driver Fatigue Index, incident rate by driver, and Vehicle Utilization Index rather than reacting only to escalations. Command centers and alert supervision systems can surface early warning signals such as recurring geofence violations or overspeeding so that supervisors can intervene with targeted coaching. Over time, this reduces the need for mass penalties while still lifting safety and route adherence.
A practical pattern is to link vendor SLAs to outcomes such as OTP, incident‑free trips, and credential currency, while allowing vendors internal flexibility in how they coach, rotate, or reward drivers. Leadership then enforces “what” must be achieved, not “how” every infraction is handled day‑to‑day. This reduces operational firefighting for the transport head, controls risk for HR and Security, and avoids the capacity shocks that come from reactive mass driver removals.
What should our ‘right to reject a driver’ policy include so HR can protect employees but decisions aren’t arbitrary or biased?
B1363 Right-to-reject driver policy design — For India corporate ground transportation vendor governance in EMS, what should the ‘right to reject’ policy look like for drivers (clear reasons, evidence standards, appeal process) so HR can protect employees without creating arbitrary or biased decisions?
A “right to reject” policy for drivers in Indian employee mobility programs works best when it is rule-based, evidence-backed, and gives drivers a clear appeal path. The policy should define specific rejectable behaviours, link each to objective evidence sources (trip logs, GPS, app data, CCTV, formal complaints), and mandate a graded response and review process rather than instant blacklisting. This protects employees and HR while reducing accusations of bias or arbitrariness.
The most defensible reasons for driver rejection align with safety, compliance, and service reliability. Typical categories include failure of background checks or licence verification, repeated safety violations, tampering with GPS or IVMS devices, harassment or misconduct (especially with women or night-shift riders), non-adherence to route and escort protocols, substance use, and chronic SLA breaches such as repeated late reporting or no-shows. WTi’s collateral already describes deep driver vetting and training, women-centric safety protocols, driver compliance verification, and alert supervision systems, which can be used as objective baselines for these rules.
Evidence standards should rely on systems, not opinions. HR and Transport can use background verification reports, DV/PSV checks, GPS and geofencing logs, alert dashboards, SOS event records, vehicle and driver compliance dashboards, and written complaints with time stamps as primary evidence. Random route audits, safety inspection checklists, and command-centre monitoring outputs further strengthen decisions and reduce disputes.
To avoid bias and ensure fairness, the policy should separate automatic disqualifiers from performance-managed issues and build in a structured appeal. Automatic disqualifiers typically cover failed criminal checks, forged documents, proven harassment, or intoxication on duty. Other issues, such as single OTP dispute, one-off delay, or minor service complaints, should trigger graded actions like counselling, retraining, or monitored probation. A small internal review panel (HR, Transport, Compliance/Security, and vendor representative) should review serious cases, record reasons, and allow the driver (or vendor) to submit a written explanation within a defined timeframe.
In practice, HR can insist that vendors adopt a documented Driver Assessment & Selection Procedure (DASP), ongoing Driver Compliance & Induction processes, and a Driver Management & Training program, as shown in the collateral. The right to reject then operates as a governance overlay: HR may refuse or offboard any driver who falls short of these pre-defined standards, provided the decision is logged, reason-coded, and linked to verifiable evidence. This gives HR defensible control over employee safety while signalling to vendors that decisions are predictable, auditable, and not personality-driven.
What early warning signs show driver governance is failing (cancellations, deviations, late first pickup, complaint patterns) before it becomes a leadership escalation?
B1364 Early warning signs of governance failure — In India corporate EMS shift transport, what operational indicators tell a Facilities/Transport Head that driver governance is failing (rising cancellations, repeat route deviations, late first pickup, complaint themes) before it turns into leadership escalation and personal blame?
Early warning indicators of failing driver governance in Indian corporate EMS are visible in trip data and complaint patterns before leadership escalations begin. A Facilities or Transport Head should treat persistent small deviations in OTP, routing, and behavior metrics as governance failures in progress, not isolated incidents.
Rising driver-side cancellations on confirmed rosters are a primary signal. These cancellations usually appear as last-minute trip drops, repeated “no-show” duty slips or frequent reassignment of vehicles on the same routes. They indicate weak contractual discipline with vendors and poor control of driver attendance and fatigue, which then cascades into missed first pickups and unstable shift coverage.
Repeat route deviations on the same drivers or routes are another critical indicator. These show up as frequent geo-fence violations, low Route Adherence Audit scores, or GPS trails that do not match approved routing. Consistent deviations usually mean drivers are ignoring SOPs, taking personal detours, or gaming distance and time, which erodes both safety governance and cost control.
Late first pickup is a high-leverage leading indicator. Even a small rise in first-pickup delays across specific drivers, depots, or timebands will propagate through the entire shift window, damaging On-Time Performance and triggering HR and manager complaints. When those delays correlate with extended duty cycles or back-to-back shifts, they often point to unmanaged driver fatigue and weak roster planning.
Complaint themes from employees provide qualitative confirmation. Repeated mentions of rude behavior, unsafe driving, unauthorized breaks, skipped escort protocols, or drivers bypassing safe pick-up points show that training, DASP, and compliance checks are no longer translating into on-ground behavior. A pattern of night-shift women employees reporting discomfort, even without a severe incident, is especially important and indicates that women-centric safety protocols and enforcement are weakening.
Additional operational signals often appear together with these core indicators. A Facilities or Transport Head should monitor concentration of incidents on a small driver subset, sudden spikes in GPS or IVMS tampering alerts, unexplained dead mileage increases, and a widening gap between vendor self-reported performance and command center trip logs.
- Monitor driver-linked OTP and first-pickup punctuality by route and timeband.
- Track driver-level route adherence and geo-fence violations with periodic Random Route Audits.
- Correlate complaint tags (behavior, safety, route issues) with specific drivers and vendors.
- Review driver fatigue risk through duty-cycle duration, back-to-back shifts, and night-shift load.
When two or more of these indicators trend negatively at the same time, most organizations see them evolve into HR escalations, safety fears, and ultimately leadership-level questions about transport reliability and personal accountability for the Facilities or Transport Head.
event/peak operations and executive mobility safeguards
Addresses event-driven surges, VIP/exec transport, and night-shift safety with surge-ready substitutions, guardrails, and audit trails during high-stress periods.
How should we handle driver performance reviews for executive trips when plans change last minute, so drivers aren’t unfairly penalized and don’t quit?
B1365 Fair reviews in executive CRD — For India corporate Corporate Car Rental (CRD) programs, how should driver performance reviews account for executive behavior and last-minute itinerary changes so drivers aren’t unfairly penalized and retention doesn’t suffer?
For corporate car rental programs, driver performance reviews should separate controllable driving behavior from executive-driven changes, and they should use trip data plus simple SOPs to flag when delays or deviations were caused by the client, not the driver. Reviews stay fair when every trip has a clear, auditable record of requests, approvals, and itinerary changes linked to timestamps and roles.
A common failure mode is treating every late pickup, route deviation, or extra wait time as a driver fault. This creates resentment and attrition among good drivers who are accommodating last-minute executive requests. A better pattern is to capture cause codes in the system, such as “client ready late,” “itinerary changed in-trip,” or “additional stop requested,” and to lock these against the trip record via the dispatcher panel or corporate booking tools. Command center or transport desk teams can then exclude such trips from SLA breach counts and negative performance scoring.
Executive behavior should be encoded into policy. Organizations can define what counts as acceptable flexibility for executives and how that flexibility is billed and tracked. Driver KPIs can then focus on safe driving, compliance, and professionalism, while a separate set of service-level metrics covers responsiveness to executive changes at a commercial level rather than as a personal fault.
Practical safeguards include: - Mandatory logging of last-minute changes and delays against the rider or booking, not the driver. - A clear dispute window where drivers can contest trip flags with supporting GPS and app data. - Weighting driver reviews more heavily toward safety, compliance, and attitude than toward raw OTP on trips marked with client-induced exceptions.
If the driver app or GPS fails mid-shift, what’s the escalation and substitution playbook so we keep OTP but still know exactly who drove which trip?
B1366 Substitution during app/GPS failure — In India corporate EMS vendor governance, what should be the escalation and substitution playbook when a driver app or GPS fails mid-shift, so Operations can maintain OTP without losing auditability of who drove which trip?
An effective escalation and substitution playbook for mid‑shift driver app or GPS failures must preserve OTP through predefined fallbacks and preserve auditability through manual but structured trip logging and reconciliation. The playbook should treat app/GPS failure as an operational exception, not a service outage, by shifting from automated telemetry to command‑center–driven control with clear SOPs, roles, and evidence capture.
The Transport Command Centre or NOC should be the first escalation point for any app or GPS failure. The driver should report via voice or SMS using registered numbers. The command center team should verify driver identity against the Driver KYC/PSV and current roster. The command center should then decide whether to continue the trip with the same vehicle under manual supervision or trigger substitution based on ETA, safety rules, and shift impact.
For continuity, the NOC should move into a “manual tracking mode” for the affected trip. The team should log start time, location, rostered employees, and planned route in a trip ledger. The NOC should run periodic voice check‑ins with the driver and, where necessary, with one designated employee in the cab. The NOC should record all deviations, delays, and safety incidents in the same ledger for later audit.
When substitution is required, the playbook should define pre‑approved standby vehicles and drivers by timeband and zone. The NOC should dispatch a standby vehicle using a Smart Dispatch Module or its manual equivalent and record the handover point, new driver ID, and vehicle number. The employees should receive updated details of the replacement vehicle and SOS numbers via SMS or alternative channels to maintain duty of care.
To protect auditability, every manual intervention should be captured in a structured incident record. The record should link driver ID, vehicle ID, employee manifest, timestamps, and reasons for fallback. The billing and ETS operation cycle should include a reconciliation step where manual trip logs are matched with HRMS rosters and vendor invoices. This preserves Cost per Employee Trip visibility and supports dispute‑free billing.
A robust playbook will also define triggers for root‑cause analysis and vendor governance. The command center should track app/GPS failure frequency as a SLA metric and feed it into vendor performance reviews and route adherence audits. Repeated failures on specific devices, vehicles, or regions should trigger corrective actions such as device replacement, driver retraining, or vendor tier rebalancing.
For safety and compliance, especially for women’s night shifts, the playbook should mandate that any loss of live tracking automatically elevates the trip’s risk level. The NOC should initiate more frequent check‑ins, record geo‑fence milestones manually, and, where policy requires, dispatch an escort or security follow vehicle for sensitive routes. These controls ensure that a technology failure does not become a safety failure.
Over time, organizations should use data from these exceptions to improve reliability and observability. Patterns in app downtime or GPS gaps can inform routing engine improvements, device standards, and integration with HRMS and telematics. This keeps employee mobility resilient under real‑world conditions while maintaining a complete and auditable record of who drove which trip under which controls.
How do we resolve the tension between Ops needing flexible substitutions for OTP and HR wanting consistent drivers to protect employee trust?
B1367 Resolve HR vs Ops substitution conflict — For India corporate Employee Mobility Services (EMS), how do HR and Operations resolve the conflict when Operations wants flexible substitution to protect OTP, but HR wants consistency to protect employee trust and reduce complaints?
In India EMS programs, HR and Operations resolve the “flexibility vs consistency” conflict by agreeing that every substitution must be governed, visible, and auditable rather than ad-hoc. Operations still gets the ability to swap vehicles or drivers to protect OTP, but HR gets stable rules, clear communication, and data to reassure employees and leadership.
The most workable pattern is to codify substitution in policy and SOPs. Operations defines when substitutions are allowed, such as breakdowns, no-shows, or surge demand, and links these to command-center playbooks and escalation matrices. HR locks in non-negotiables around women-safety protocols, driver KYC/PSV, and route approvals, so no “emergency substitution” is allowed outside the compliance envelope.
Centralized command-center and NOC tools then act as the neutral control tower. Command operations log every substitution at trip level, capture GPS/trip ledgers, and keep OTP% and incident data visible by vendor, route, and timeband. HR gets dashboards on complaints, Commute Experience Index, and women-safety exceptions, while Ops watches OTP, Trip Adherence Rate, and vehicle utilization.
Common failure modes occur when substitutions are invisible to HR and employees. Employees feel “random cabs” are being pushed, and HR only hears about it through complaints. Outcome-linked contracts reduce this tension. OTP, safety incidents, and complaint closure SLAs become shared KPIs, so both HR and Operations are rewarded for maintaining on-time performance without eroding trust.
images:
What contract clauses and checks help prevent ‘paper compliance’ in driver onboarding without slowing down mobilization?
B1368 Prevent paper compliance in onboarding — In India corporate ground transportation contracting for EMS, what governance clauses best protect against ‘paper compliance’ in driver onboarding (documents submitted but not verified), and how can Procurement operationalize checks without slowing down mobilization?
The most effective protection against “paper compliance” in driver onboarding is to hard-code verification responsibility, evidence standards, and audit rights into the EMS contract, then back that with simple, repeatable checks that Procurement can trigger without touching day-to-day ops. Governance works when driver documents are never “trusted by default,” when verification is auditable, and when non-compliance is directly linked to payment and allocation rights.
Procurement can require a documented Driver Assessment & Selection Procedure that includes VIVA, written, and practical tests, plus a defined background-check package covering address, criminal, license, credit, database checks, court records, and medical fitness. The driver compliance collaterals indicate a nine-step verification stack and a DASP framework, which can be converted into annexures and minimum onboarding standards. Contracts can mandate that no driver is rostered until all checks are marked “clear” in a centralized compliance management system with maker–checker controls and document upload logs.
To avoid slowing mobilization, Procurement can push verification into parallel, tech-led workflows. Centralized Compliance Management and Alert Supervision tooling already exist in the ecosystem, with automated notifications, status dashboards, and audit reports. A practical model is to define service-level expectations for onboarding turnaround, allow pre-approved “driver pools” cleared in advance, and reserve the right to perform random driver audits or third-party re-verification. Non-compliant hits can trigger removal from the active pool, penalties, or temporary trip-withholding, while keeping overall fleet mobilization intact. This approach prioritizes continuous assurance over one-time file collection.
What fatigue management rules (duty cycle, rest, exceptions) should we set so EHS can defend decisions after an accident without hurting capacity too much?
B1369 Fatigue management governance rules — For India corporate EMS operations, what should be the governance approach for driver fatigue management (duty cycle limits, rest compliance, exception approvals) so EHS can defend decisions after an accident without crippling capacity?
For India corporate EMS operations, driver fatigue must be governed as a hard safety control with clear duty-cycle limits, enforced rest rules, and auditable exceptions, rather than as an informal scheduling guideline. EHS can defend decisions after an accident only if every trip can be linked to verifiable duty-hour data, documented rest compliance, and a traceable exception-approval trail that shows conscious risk acceptance.
A practical pattern is to embed fatigue controls into the same governed stack that runs rostering, routing, and compliance. The Industry Insight brief highlights Driver Fatigue Index (DFI), cab duty cycle, and command center operations as core constructs, which means fatigue should be treated like any other critical KPI. Most organizations do this by linking the routing engine and driver app stack to a Mobility Data Lake, so every assignment references prior hours, shift windows, and recent trips, and any breach of policy generates an alert into the command center and escalation matrix.
A common failure mode is leaving fatigue management to local supervisors without system guardrails. That improves short-term capacity but destroys auditability and exposes EHS after incidents. A better approach is to let the central command center run automated checks on duty duration and rest gaps, while location teams handle local substitutions and buffers. This preserves capacity through dynamic routing, multi-vendor aggregation, and peak/non-peak buffers, while keeping fatigue limits non-negotiable in the core algorithm.
To avoid crippling capacity, organizations use structured exceptions with controls rather than blanket overrides. Exceptions are restricted to predefined scenarios in the mobility risk register. Each exception requires an electronic approval in the trip ledger, time-bounded limits, and compensatory rest rules that are visible in the compliance dashboard. EHS can then show an investigator not only that a rule was exceeded, but also that it was identified, escalated, and controlled within a documented framework.
Operationally, the governance model works best when fatigue KPIs sit alongside OTP and safety metrics in the command center, and when driver duty-cycle data is integrated with vendor governance frameworks and quarterly reviews. This shifts decisions from ad-hoc, last-minute juggling to data-led planning of fleet mix, buffers, and shift windowing, which preserves operations while giving EHS a defensible story after any accident.
How can Finance verify OTP improvements came from driver governance changes, not just temporary overstaffing or short-term firefighting?
B1370 Validate OTP gains from governance — In India corporate Employee Mobility Services (EMS), how can a CFO validate that improvements in OTP stability are truly driven by driver governance changes (reviews, incentives, substitutions) rather than temporary overstaffing or short-term vendor firefighting?
In India EMS programs, a CFO can validate that OTP stability is truly driven by driver governance changes only when OTP trends, unit-cost trends, and driver-related KPIs improve together without a parallel spike in capacity or spend. The core test is simple. OTP should rise while cost per trip, dead mileage, and spare capacity ratios stay flat or reduce across multiple roster cycles.
A common failure mode is “OTP by brute force” where vendors add extra cabs, relax route optimization, or push short-term firefighting. In that pattern, CFOs see better OTP but also rising Cost per Employee Trip, falling Trip Fill Ratio, and inconsistent vehicle utilization indices. Governance-led improvement shows the opposite signature.
CFOs should insist on a measurement design that separates driver governance levers from fleet capacity levers. This requires trip-level data, driver-level performance logs, and visibility into substitution rules, fatigue management, and routing policies. Finance teams can then run before–after comparisons at constant capacity, timeband, and site mix.
Practical validation steps include:
- Baseline a 4–8 week “pre-change” window for OTP%, CET, CPK, TFR, and Vehicle Utilization Index.
- Implement governance changes like structured driver reviews, fatigue norms, and substitution SOPs without altering fleet size.
- Track a 4–8 week “post-change” window where OTP improvement must coincide with stable or improved CET, TFR, and dead mileage.
- Require vendors to flag any temporary buffers or event-specific overstaffing as separate, auditable exceptions.
Most CFOs gain confidence when OTP gains are repeatable across shift windows and locations, survive seasonal peaks, and remain visible after any temporary buffers are rolled back. When OTP stability persists under a flat or optimized cost curve, the evidence strongly supports driver governance—not firefighting—as the real driver of improvement.