Routing & Rostering: a 3-lens playbook for daily reliability
This isn’t a demo. It’s an operational guardrail for the dispatch floor: guardrails, SOPs, and escalation paths that keep drivers, sites, and vendors aligned when weather turns or a gate blocks progress. It’s built for nights, weekends, and peak weeks when the risk of chaos is highest. The three lenses map to: stability-first guardrails for fast recovery, codified real-world constraints and inputs, and governance with clear ownership and measurable ROI. Use them to cut firefighting in half and give leadership an auditable, repeatable plan.
Is your operation showing these patterns?
- 3 a.m. escalations spike despite supposed stability
- Last-minute edits flood the desk and push night-shift workloads
- GPS outages or app downtime surface as chaos only after events
- Vendor response delays threaten night coverage during weather events
- Drivers report fatigue from an 'always-on' dispatch cycle
- Leadership asks for ROI proof that survives late changes and edits
Operational Framework & FAQ
stability-first routing & rostering governance
Guardrails that keep rosters and routes stable during peak shifts; define escalation paths, freeze policies, and graceful degradation when systems glitch.
For our employee commute program, what all comes under routing and rostering beyond just making routes, and why does it usually break in day-to-day operations?
B1125 What routing & rostering includes — In India-based Employee Mobility Services (EMS) for corporate ground transportation, what does “routing & rostering” actually include beyond making routes—specifically shift windowing, clustering, seat-fill targets, and day-of-operations recalibration—and why do these pieces fail in real operations?
Routing and rostering in India-based Employee Mobility Services include four tightly linked layers of control-room work. Each layer goes beyond drawing static routes on a map. Each layer tends to fail when data, SOPs, and vendor behavior are not aligned.
Routing and rostering start with shift windowing. Shift windowing groups employees by permissible pickup and drop bands around official shift times. It also applies policy rules for night shifts, women-first routing, and escort requirements. This layer fails when HRMS data is outdated, when actual login times differ from declared shift times, or when policy rules are not encoded into the routing engine and are left to manual judgment at the last minute.
The second layer is clustering. Clustering groups employees by geography, traffic corridors, and permissible detour limits before any vehicle assignment. It sets the base for dead mileage caps and time-on-road norms. This layer fails when address data is inaccurate, when frequent relocations are not updated, or when routing tools are not integrated with live traffic patterns. In those situations, transport teams are forced back into manual cluster adjustments every shift.
The third layer is seat-fill targets. Seat-fill targets define how many seats must be utilized per cab to meet cost-per-trip and cost-per-kilometer baselines. They also influence the fleet mix between sedans, MUVs, and shuttles. This layer fails when there is no clear policy on maximum ride time, when cancellation behavior is not modeled, or when targets are driven only by cost and not linked to employee experience and safety limits.
The fourth layer is day-of-operations recalibration. Day-of-operations recalibration responds to no-shows, last-minute bookings, breakdowns, and weather or traffic disruptions while protecting OTP and safety constraints. It depends on a command center, driver and rider apps, geo-fencing, and exception SLAs. This layer fails when GPS or apps are unstable, when vendor response is slow, or when there are no clear escalation matrices and playbooks for rerouting under stress.
A common failure pattern is that routing logic is treated as a one-time planning exercise instead of a continuous loop with live data and SLA feedback. Another frequent issue is that procurement, HR, and Transport set conflicting priorities across cost, safety, and experience, so routing and rostering teams operate with inconsistent signals.
Why do our pickup/drop time windows and cut-off times matter so much, and how can we tell our current rules are causing last-minute changes?
B1126 Why shift windows drive stability — In India corporate employee transport (EMS), why do shift window definitions (pickup/drop tolerances, grace periods, and cut-off times) matter so much for on-time performance and fewer last-minute roster edits, and what are common signs the shift-windowing rules are wrong?
Shift window definitions in Indian corporate employee transport determine whether routing can be planned as a stable “batch” or forced into continuous firefighting. Clear pickup/drop tolerances, grace periods, and booking cut‑offs allow routing engines and vendors to lock rosters, cap dead mileage, and protect on‑time performance (OTP), while loose or ambiguous rules push operations into last‑minute edits, unstable routes, and higher exception rates.
Shift windowing is the mechanism that converts hybrid attendance and variable demand into predictable shift windowing and route design. When windows are tight but clear, routing optimization, seat‑fill targets, and dead‑mile caps can be applied reliably. When windows are vague, every late request or exception becomes a manual override, which erodes OTP, increases command‑center load, and raises driver fatigue. Stable windows also enable outcome‑linked procurement, because OTP%, Trip Adherence Rate, and Cost per Employee Trip can be measured against consistent operating assumptions.
Misconfigured or “wrong” shift-window rules usually show up first as operational symptoms rather than policy debates. Typical signs include chronic last‑minute roster changes close to cut‑off times, persistent no‑shows clustered around specific timebands, and frequent ad‑hoc vehicle requests outside planned fleet capacity. Another signal is high exception latency in the command center because manual route recalculation is needed every time someone misses a cut‑off. Repeated driver complaints about unrealistic routing between back‑to‑back windows indicate that seat‑fill and travel times are not aligned with real traffic patterns. A widening gap between planned versus actual OTP% by shift, despite sufficient fleet, is often the clearest proof that the shift window logic, not the supply, is the underlying problem.
When vendors say “clustering logic,” what data should actually go into it for our commute, and what goes wrong when clustering is done badly?
B1127 Clustering logic inputs and failures — In India enterprise-managed employee commute programs (EMS), how should a buyer interpret “clustering logic” in routing—what inputs (home locations, site gates, shift bands, gender rules, traffic patterns) typically matter, and what failure modes create repeated escalations and employee complaints?
Clustering logic in Indian enterprise employee commute programs is the set of rules and inputs a routing engine uses to group employees into shared cabs within a shift window. Clustering determines who travels together, which route is chosen, and how pick-up and drop sequences are planned, so it directly affects on-time performance, women’s safety compliance, cost per trip, and daily escalation volume.
In practice, clustering logic usually combines several core inputs. Home locations define geo-clusters so employees in nearby neighborhoods are pooled. Site gates and entry points define where vehicles must report, including separate gates for security or gender-specific entries. Shift bands define pick-up and drop buffers around rostered login and logout times, including different windows for day, evening, and night shifts. Gender and escort rules define where women must be first pick-up or last drop, where escorts are mandatory, and which routes are approved at night. Traffic patterns define preferred corridors and blacklisted roads based on congestion, monsoon impact, and local risk, and they influence how the route is sequenced even for employees who live close together.
Repeated escalations often come from ignoring one of these inputs or applying them inconsistently. A common failure mode is clustering only by geography while ignoring shift bands, which causes early pickups, late drops, or missed logins. Another is violating women-safety or escort rules when trying to maximize seat-fill, which leads to HR and Security complaints even if OTP is high. Static routes that do not adapt to real traffic patterns or weather cause chronic delays on the same corridors, especially during monsoon or peak events. Over-aggressive cost optimization that pushes long detours and high ride times per employee creates perception of unfairness and fatigue complaints from specific pockets. Poor HRMS integration and stale rosters lead to incorrect manifests, no-shows, and repeated routing for employees who are on leave or working from home.
Signals that clustering logic is failing include the same routes and cabs appearing in daily complaint logs, recurrent late logins from one corridor or shift band, frequent exceptions raised by women employees on specific routes, and on-ground supervisors repeatedly asking for manual overrides. When these patterns appear, buyers should treat clustering rules and inputs as tunable policy parameters, not a black box, and insist on auditable routing criteria, route-level KPIs, and the ability for transport teams to adjust buffers, risk rules, and max ride-time limits without breaking the entire system.
What does a seat-fill target really mean for our routes, and how do we push utilization without hurting OTP, safety rules, or employee satisfaction?
B1128 Seat-fill targets vs experience — In India corporate ground transportation for shift-based EMS, what does “seat-fill target” mean operationally, and how do organizations balance seat-fill versus on-time pickups, women-safety constraints, and employee experience without triggering morale backlash?
Seat-fill targets in Indian shift-based employee mobility are route-level goals for how many available seats in each vehicle should be occupied on average, so that cost per employee trip comes down without increasing dead mileage or eroding service reliability. Seat-fill is treated as an operational KPI alongside On-Time Performance, Trip Adherence Rate, safety metrics, and experience indicators, not as a standalone cost lever.
Operations leaders typically define seat-fill within the broader routing and capacity strategy that also includes shift windowing, fleet mix policies, dead-mile caps, and dynamic route recalibration. Seat-fill targets are then enforced through the routing engine and rostering rules, but are bounded by safety and duty-of-care constraints for women’s night shifts, escort policies, and compliance with labor and transport norms. A common failure mode is treating seat-fill as a hard target without these constraints, which tends to push longer detours, tighter buffers, and higher fatigue for drivers.
Most mature EMS programs balance seat-fill against on-time pickups by giving OTP and Trip Adherence Rate primary status in procurement scorecards and vendor SLAs. Seat-fill is then optimized within a defined service envelope that fixes maximum route duration, maximum pickups per trip, and strict shift window constraints. This reduces the risk that aggressive optimization quietly converts into late logins and manager complaints, which HR and Transport heads then absorb as daily firefighting.
Women-safety constraints are usually encoded as non-negotiable routing rules, especially for night shifts. These rules can include female-first drop policies, escort compliance, geo-fenced no-go areas, and approvals for high-risk routes. Dynamic routing and geo-AI risk scoring are then used to route within these constraints, so that seat-fill improvements never require compromising escort rules or extended detours for lone female passengers. A common risk is manual overrides during peak-load pressure, which is where centralized command-center operations and real-time monitoring provide an additional governance layer.
Employee experience is protected by designing seat-fill policies around commute comfort thresholds rather than pure arithmetic averages. Operations teams typically specify maximum in-vehicle time, reasonable detour limits, and predictable boarding times as design constraints for the routing engine. HR and ESG stakeholders then link commute experience indices and complaint closure SLAs to the mobility governance board, so that any seat-fill push that triggers morale backlash is visible early through NPS, attendance deltas, and escalation patterns.
In practice, organizations that avoid backlash treat seat-fill as one KPI in an outcome-based commercial framework, alongside OTP%, safety incident rate, and complaint closure SLAs. Payments and penalties are indexed to this broader set of outcomes, which discourages over-optimization on utilization alone and encourages vendors to use data-driven routing, EV telematics, and predictive maintenance to reduce cost per employee trip without visibly degrading experience or safety.
images:

When our roster changes mid-day, how should dynamic re-routing work, what should stay locked, and how do we keep it from becoming chaos?
B1129 How dynamic recalibration should work — In India EMS routing & rostering for corporate employee transport, how does “dynamic recalibration” work during the day when rosters change—what triggers a re-route, what stays frozen, and how do you avoid chaos for drivers and riders?
Dynamic recalibration in Indian EMS works by tightly controlling what can change, and when, based on a few well-defined triggers and frozen “guardrails.”
It is not continuous reshuffling.
Most organizations limit recalculation to specific events, preserve core constraints like shift windows and safety rules, and push only a small set of clear, time-bounded changes to drivers and riders.
Dynamic recalibration is usually triggered by events like last-minute roster edits, employee cancellations or no-shows, new ad-hoc trip requests, vehicle or driver breakdowns, or major traffic or weather disruptions.
A routing engine or command center detects these events using HRMS-linked rosters, GPS/telematics, and exception alerts, then evaluates whether a recalculation will improve on-time performance and seat-fill without breaching safety or compliance rules.
Certain elements stay frozen to avoid chaos.
Shift start and end times remain fixed.
Night-shift women-safety rules, escort requirements, and geo-fence constraints cannot be violated.
Vehicle capacity and maximum duty hours stay locked, and a cutoff is enforced close to pickup time after which a rider’s stop is no longer moved.
These frozen components protect the Facility / Transport Head from constant micro-changes and preserve predictable patterns for drivers.
To avoid chaos for drivers, recalibration is constrained to limited re-sequencing within a route or controlled swapping between a small number of nearby routes.
Changes are batched and pushed at defined intervals rather than every few minutes.
Driver apps receive a new manifest with a clear “effective from” time, updated stop order, and turn-by-turn navigation, while the NOC monitors adherence via route-adherence audits and alerts for overspeeding, tampering, or missed geofences.
To avoid chaos for riders, organizations define hard communication and cutoff rules.
Riders receive route and pickup time only after a planning freeze for that shift window.
Post-freeze, only critical changes are allowed, such as swapping vehicles while keeping the pickup time and stop constant.
Employee apps show updated ETAs, driver details, and SOS options, and complaint closure SLAs ensure riders see issues resolved rather than ignored.
Most mature EMS operations also tie recalibration logic to outcome metrics.
On-time performance, no-show rates, trip fill ratio, and exception-closure time are monitored on a command-center dashboard.
Recalibration is considered successful only if these KPIs improve without increasing driver fatigue risk or breaching compliance and safety audit trails.
How do we measure the manual effort in our routing and rostering—edits, calls, Excel/WhatsApp work—so we have a clear baseline before we look at tools?
B1130 Measuring routing/rostering toil baseline — In India corporate employee commute operations (EMS), how can a Facility/Transport Head quantify “toil” in routing & rostering today (manual edits, exception calls, Excel dependence, WhatsApp coordination), and what baseline metrics are practical before evaluating new routing tools?
In Indian employee commute operations, a Facility/Transport Head can quantify “toil” in routing and rostering by directly measuring the human effort and failure-handling around every shift. Practical baselines focus on time spent, volume of manual interventions, and escalation patterns before any new routing tool is evaluated.
A Facility/Transport Head should first measure how much time the team spends each day on core routing and rostering tasks. A simple baseline is total planner hours per shift spent on building or editing rosters, reconciling Excel sheets, and manually sequencing routes. A second layer is micro-metrics, such as number of roster versions created per shift window and number of last-minute edits made after “final” routes are published.
Toil is most visible in exception handling and back-channel communication. A practical baseline is the count of exception calls and WhatsApp interventions per shift, including driver no-shows, vehicle swaps, location clarifications, and last-minute employee changes. Another useful metric is average time to resolve each exception from first alert to closure, which shows both stress on the control room and the effectiveness of current SOPs.
Spreadsheet and manual-tool dependence can also be quantified. A Facility/Transport Head can track how many active Excel files or manual trackers are used daily, how many times routing data is re-entered into different systems, and how often teams must manually reconcile trip data for billing, compliance, or reporting. These counts link directly to error risk and after-shift clean-up work.
Before evaluating any new routing tool, a minimal baseline set that most operations can capture is: - Planner hours per day spent on rostering and routing. - Number of manual route edits after first publish per shift window. - Exception calls/WhatsApp escalations per 100 trips. - Average exception resolution time during peak and night shifts. - Number of distinct spreadsheets/templates used daily for transport coordination.
These metrics give a Facility/Transport Head a grounded “before” picture of toil. They also align naturally with broader EMS KPIs such as On-Time Performance, Trip Adherence Rate, Vehicle Utilization Index, and No-Show Rate, which will be influenced once routing tools and command center practices start to automate more of the manual workload.
What usually causes the 2–5 a.m. roster blowups in employee transport, and how should we track root causes so they don’t keep repeating?
B1131 Root causes of night shift blowups — In India EMS routing & rostering for corporate ground transportation, what are the most common root causes behind 2 a.m.–5 a.m. schedule blowups (no-shows, vehicle mismatch, late roster freeze, wrong clustering, gate constraints), and how should an operations team instrument and track them?
In Indian EMS night-shift operations, most 2 a.m.–5 a.m. schedule blowups are caused by brittle rostering inputs, weak real-time visibility, and un-instrumented “last 500 meters” constraints. Operations teams reduce these failures when every failure mode is tagged, time-stamped, and linked to a small, standard root-cause taxonomy that is visible in the command center and in post-shift reports.
The most common root causes sit across three layers. At the planning layer, late or inaccurate HRMS rosters, last-minute shift changes, and manual clustering often create unrealistic routes and duty cycles. At the fleet and driver layer, thin buffers, driver fatigue, poor standby logic, and fragmented vendor supply cause no-shows, vehicle mismatch, and unplanned substitutions. At the ground-execution layer, campus gate rules, security checks, geo-fencing, and local disruptions like weather or political events convert small delays into complete route failures.
Operations teams should implement a single command-center view where every exception is captured as a structured event. Each event should record route ID, time band, vehicle, driver, location, and one primary root-cause code such as “Late roster freeze,” “Driver no-show,” “Vendor substitution,” “Gate hold,” “HR data mismatch,” or “Geo-fence / security delay.” Exceptions should be linked to KPIs like On-Time Performance, Trip Adherence Rate, dead mileage, and Vehicle Utilization Index, with filters for the 2 a.m.–5 a.m. window to detect patterns.
Effective instrumentation typically includes real-time GPS and geo-fencing alerts, IVMS-based fatigue and over-speeding indicators, automated roster ingest from HRMS, and a ticketing workflow from SOS and call-center inputs. Daily shift debriefs and route-adherence audits should use the same codes as the live system, so case studies, business continuity playbooks, and analytics on weather or city-specific challenges feed back into routing rules, standby buffers, and vendor tiering for night operations.
Where do routing decisions usually create fights between HR, Finance, and Facilities, and how do mature programs settle those trade-offs without daily escalations?
B1132 Resolving HR-Finance-Ops conflicts — In India employee mobility services (EMS), where do routing & rostering failures typically create political conflict between HR (employee experience), Finance (cost per trip), and Facilities (operational feasibility), and how do strong programs resolve these trade-offs without constant escalations?
In India employee mobility services, routing and rostering failures most often create conflict at three pressure points. These points are shift alignment versus cost, pooling efficiency versus employee experience, and last‑mile feasibility versus policy rigidity. Strong programs reduce conflict by making routing rules explicit, data‑backed, and jointly governed instead of leaving them to ad‑hoc nightly decisions by Facilities.
Routing and rostering tensions usually start when HR pushes for employee-friendly routing that protects attendance and safety, while Finance pushes for higher seat fill, lower dead mileage, and tighter cost per employee trip. Facilities then struggles to execute both under constraints of actual traffic, driver fatigue, and vehicle availability. A common failure mode is static routes that ignore hybrid-work variability, which drives low utilization and cost complaints, while also generating late pickups and NPS drops that HR cannot defend.
Another recurring conflict arises when pooling logic is optimized only for cost. High pooling can reduce cost per kilometer, but it often increases detours, travel time, and missed shift windows for some employees. HR then faces escalations around long rides and women’s night-shift routing, while Facilities deals with unworkable manifests during bad weather or roadblocks. Finance, meanwhile, sees only the monthly CET/CPK numbers and questions any deviation from pooling targets.
Strong EMS programs address these trade-offs by moving to outcome-based and rule-based routing rather than purely cost-based routing. Organizations define clear, cross‑functional guardrails such as maximum ride time by zone, hard cutoffs for first/last pickup, women‑safety route rules, and minimum seat‑fill targets by shift band. These rules are encoded into the routing engine and published as part of the EMS policy so that HR, Finance, and Facilities are aligned on when it is acceptable to break pooling for reliability or safety.
Effective programs also centralize observability through a 24x7 command center and agreed KPIs. On‑time performance, trip fill ratio, dead mileage, and complaint closure SLAs are tracked in one dashboard instead of fragmented spreadsheets. HR can see how routing choices impact commute experience metrics. Finance can see cost per trip trends tied directly to seat‑fill and dead‑mile data. Facilities gets early alerts on risk (driver shortages, route congestion, charging gaps) and can trigger predefined playbooks instead of improvising under pressure.
To avoid constant escalations, mature EMS setups use structured governance rather than one‑off exceptions. There is a documented escalation matrix and a quarterly review where HR, Finance, and Transport jointly review routing performance, exceptions, and cost. Policy changes, like adjusting pooling thresholds or adding standby vehicles for critical shifts, are decided in that forum and then codified into SOPs and the routing engine. This reduces nightly negotiation and shifts the debate to data and trends, not anecdotes.
Successful programs also accept that some cost is “protective spend.” For example, running buffer vehicles or allowing lower pooling in certain night windows can increase CET slightly but prevent service failures, safety incidents, and attrition. Finance is more likely to support this when there is a clear, quantified baseline and when these exceptions are transparent and capped by predefined rules rather than informal requests from Facilities.
Over time, this approach turns routing and rostering from a nightly political argument into a governed system. The core ingredients are explicit cross‑functional rules, integrated data, a central command center, and outcome‑linked contracts that balance OTP, safety, and utilization. These elements together reduce reactive firefighting and give each stakeholder a defensible position backed by shared evidence instead of conflicting narratives.
How do we set a roster freeze time and late-change policy that feels fair to employees but still keeps routes stable and on time?
B1133 Roster freeze and late-change policy — In India corporate EMS, how should HR and Facilities decide the “roster freeze” time and late-change policy (cutoffs, approvals, exception categories) so the program is fair to employees but doesn’t destroy routing stability and on-time performance?
In India corporate EMS, HR and Facilities should set roster freeze and late-change rules by working backward from shift start times and OTP targets, then layering exception categories, approval paths, and penalties or guardrails on top. The freeze time must protect routing stability and driver fatigue limits, while the exception policy must be narrow, auditable, and clearly communicated so employees see it as fair rather than arbitrary.
A practical pattern is to define a standard freeze window for all “normal” bookings and then a tighter, capped window for late requests and changes. Roster freeze needs to sit before the last routing and vendor distribution run, so dynamic routing engines and command centers can finalize manifests, seat-fill, and dead mileage control. If freeze is too close to shift start, route recalculation becomes reactive, which erodes OTP% and increases driver stress.
Late-change policy needs three elements. There should be explicit cutoffs by timeband (day vs night shifts), with anything beyond those treated as an exception rather than a right. There should be exception categories defined in HR policy (for example medical emergencies or critical business continuity cases) with specific approval owners, so command center staff do not have to negotiate edge cases on the fly at 2 a.m. There should be telemetry-backed review of exception volumes and their OTP impact so HR can refine rules without guesswork.
To make the policy feel fair, HR should link it to clear communication, visible data, and consistent enforcement. Employees need simple app workflows for regular bookings within the freeze window and transparent messaging when requests fall into “late change” buckets. Facilities teams need SOPs that explain who can override routing after freeze, what SLA still applies, and how these overrides are logged for later KPI and cost analysis. Shared dashboards that show OTP, no-show rates, and late-change trends help CHROs defend the policy to leadership and employees as a necessary guardrail for reliability, safety and driver well-being.
When we say the roster is editable, who should be allowed to change it, what approvals are needed, and how do we avoid edit wars and finger-pointing?
B1134 Editable roster governance and controls — In India corporate employee transport (EMS), what does “editable roster” mean in practice—who is allowed to edit what (HR, transport desk, vendor, NOC), what approvals are needed, and how do you prevent edit wars and blame-shifting when something goes wrong?
An “editable roster” in Indian corporate employee transport means the shift-wise pickup/drop list can be changed after it is first generated, but only within a controlled, role-based workflow with audit trails. The roster is not a free-for-all spreadsheet. It is a governed object where HR, transport desk, NOC, and vendors each have clearly defined permissions, cut-off times, and approval rules.
In practice, most organizations treat HR or line managers as owning who is eligible to travel and what shift they are on. HR or the HRMS feeds master shift data and eligibility flags into the transport platform. The transport desk or central NOC then owns operational routing. The desk can add or remove employees from a particular run, swap vehicles, and re-sequence routes within policy limits. Vendors usually only see the final driver manifest. They cannot unilaterally change who rides where. They may propose changes back to the desk when there is a breakdown or driver shortage, but the command center approves and publishes any change.
Edit rights are often tiered by risk. Low-risk changes like correcting a phone number, toggling a pickup landmark, or tagging an escort can be done by the transport desk without extra approvals. High-impact changes like adding a new woman employee to a night drop, changing escort rules, or overriding cut-off times usually require HR or Security/EHS approval, often via a short in-app workflow. The EMS system logs who initiated the change, who approved it, and when. This enables the Facility or Transport Head and HR to reconstruct exactly what happened on a problematic trip.
To prevent edit wars and blame-shifting, mature EMS setups rely on a few operating rules. There is a defined roster freeze or cut-off time per shift, after which only the NOC or duty manager can override the roster. Any override is visible to all parties on a single dashboard, with version history and change reasons captured. The vendor app receives read-only manifests linked to that version, so drivers are never improvising based on phone calls alone. Escalation matrices and SLAs define who can change a trip inside the “red zone” before departure, and any late edits trigger alerts rather than silent updates.
Most teams find it safer to keep eligibility and shift assignment editable by HR, operational routing editable by the transport desk and NOC, and vendor input constrained to exception signals such as “vehicle unavailable” or “driver no-show.” That division of control reduces scope for vendors to be blamed for decisions they did not take, and it protects transport heads from being blamed for HR-driven last-minute changes. The NOC acts as final arbiter during live operations. This structure also supports auditability and compliance, especially for women’s night-shift routing, escort compliance, and incident investigations.
How do we check if a vendor will actually cut down manual roster changes, not just show better-looking routes, and what should we demand in a pilot?
B1135 Proving toil reduction in pilot — In India EMS routing & rostering, how should a buyer evaluate whether a vendor’s system reduces manual roster edits (the real toil) rather than just producing nicer route outputs, and what should be demonstrated in a pilot to prove it?
In India EMS routing and rostering, buyers should evaluate vendors on how much they reduce real control-room toil per shift, not on how “smart” the routes look on slides. The core test is whether manual edits, last‑minute calls, and spreadsheet juggling drop sharply while OTP, seat‑fill, and compliance remain stable or improve.
A common failure mode is routing engines that optimize once on static data. Transport teams then spend hours fixing missed shift windows, wrong escort allocation, and HRMS mismatches. Systems that reduce toil ingest roster changes, hybrid-work patterns, and attendance updates continuously. Systems that do not reduce toil generate “optimal” routes that are constantly overridden by operators.
Buyers should insist on a pilot where the vendor runs live routing and rostering on a real site with real constraints, under joint supervision from Transport, HR, and Security. The routing engine should integrate with HRMS or roster sources, apply escort and women-safety rules, and expose a command-center interface for exceptions and SLA monitoring.
In the pilot, the buyer should track a small, explicit metric set:
- Manual interventions per shift. Count how many trips or routes the control room edits after auto-routing.
- Time to lock roster. Measure time from HRMS roster freeze to “routes final and shared with employees.”
- On-Time Performance and Trip Adherence Rate. Confirm OTP% and route adherence do not degrade as edits reduce.
- Seat-fill and dead mileage. Check that seat utilization and dead mileage move in the right direction.
- Exception latency. Measure detection-to-closure time for no-shows, cancellations, and last-minute shift changes.
A strong pilot demonstrates that, over a few weeks, manual edits per shift and total planning time trend down, while OTP and safety/compliance metrics remain stable or improve. A weak pilot shows “good looking” routes that still require heavy editing, with no measurable drop in control-room workload.
What real constraints usually break our routes—gates, security, escorts, vehicle rules, driver shift limits, weather—and how do we design routing so it doesn’t become daily exceptions?
B1136 Accounting for real-world constraints — In India corporate EMS, what practical “real-world constraints” typically break routing plans (site gate queues, security checks, escort availability, vehicle type rules, driver shift limits, monsoon disruptions), and how should routing & rostering processes account for them without daily exceptions?
In India corporate employee mobility services, routing plans usually fail when they ignore fixed on-ground constraints like gate queues, security protocols, escort rules, driver duty limits, and weather or traffic patterns. Routing and rostering need to treat these as inputs to the plan and as hard rules in the routing engine, not as exceptions that are “handled later” by the transport desk.
Real-world breakdowns usually come from non-negotiable steps at the site or on the road. Site-gate queues and security checks create predictable bottlenecks that stretch boarding and de‑boarding times. Women-escort availability, women-first policies, and night-shift safety protocols create rigid ordering and pairing rules for routing. Driver duty-hour limits and fatigue norms restrict maximum driving and shift lengths. Monsoon and festival traffic patterns create recurring corridor-level delays that make theoretical ETAs meaningless on certain routes and timebands.
If routing ignores these, operations teams end up “re-routing by phone” every day. This increases exception handling, stresses drivers, and erodes on-time performance and safety compliance. Transport heads then spend night shifts firefighting GPS failures, last-minute roster changes, and vendor response gaps instead of running a calm control room.
Routing and rostering processes work better when they encode these constraints upfront instead of treating them as afterthoughts. Boarding and security times must be modeled as time penalties per site and timeband. Escort constraints and vehicle-type rules must sit inside the routing logic as hard constraints that cannot be violated. Driver shift limits should drive maximum trip length and number of trips per duty cycle.
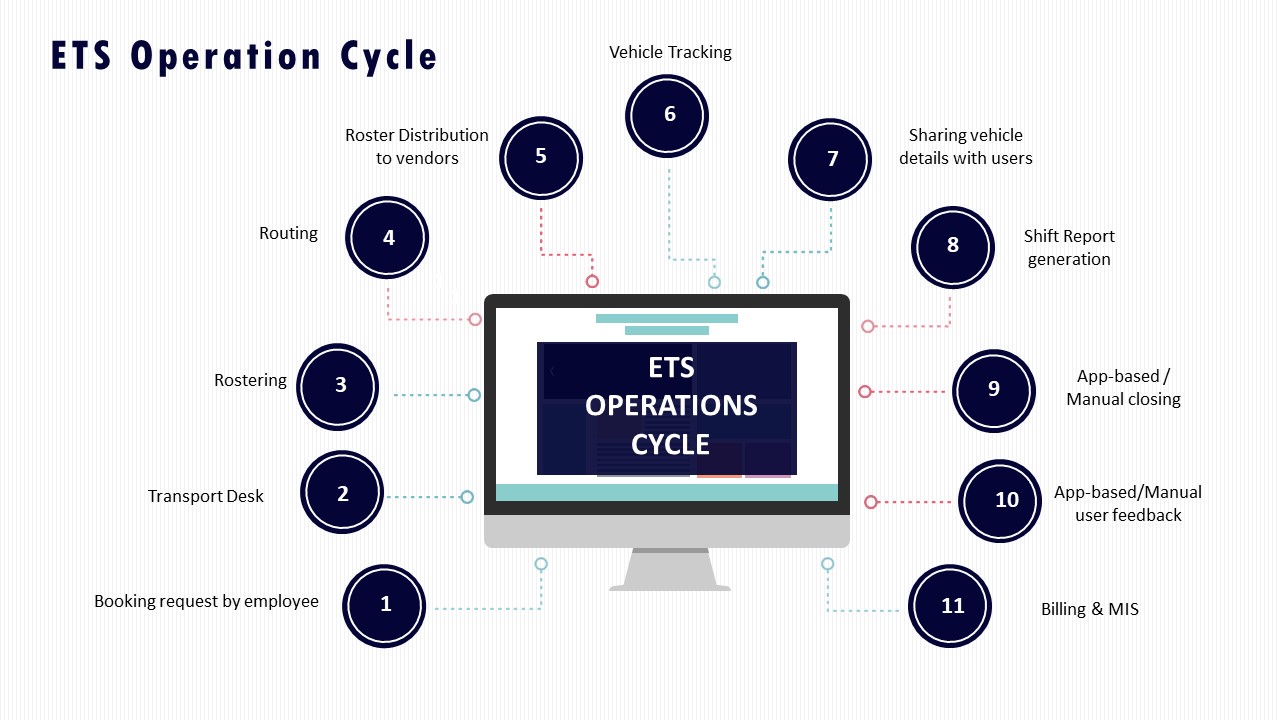
Operations teams benefit when the routing engine is tuned with monsoon-specific and corridor-specific travel times and when there is an agreed buffer policy by shift window. The ETS Operation Cycle and dynamic route optimization practices used during Mumbai monsoon management, which achieved a 98% on-time arrival rate and higher customer satisfaction, show that weather and traffic can be pre-encoded into route planning rather than managed as daily surprises.
To reduce daily exceptions, organizations can adopt a few clear practices in their routing and rostering playbooks. Transport and HR teams should lock site-specific rules such as gate opening times, minimum check-in lead times, and security slot capacities into master data. Safety and EHS teams should define explicit rules for women-centric routing, escort pairing, and night corridors, and these should be applied as non-editable constraints in the routing engine.
Driver duty and fatigue rules need to be translated into simple caps, such as maximum duty hours per shift and minimum rest periods before the next shift, and routing should be prevented from assigning trips that would break these limits. Seasonal playbooks, like those used for monsoon management, should define alternative routes, added buffers, and higher fleet buffers for high-risk corridors and timebands, so that the routing engine automatically switches profiles during those periods.
When these rules are embedded into centralized command-center operations and automated routing, the transport desk receives plans that are realistic and compliant by design. This reduces the volume of last-minute modifications, keeps on-time performance near targets, and cuts down escalations to HR and senior leadership.
With hybrid attendance changing daily, how do seat-fill goals affect routing, and what rules stop us from chasing utilization and hurting reliability or trust?
B1137 Seat-fill under hybrid demand swings — In India employee commute routing (EMS), how do seat-fill targets interact with hybrid demand elasticity (variable attendance, WFH swings), and what governance prevents the system from over-optimizing utilization at the expense of reliability and employee trust?
Seat-fill targets in Indian employee commute routing improve cost efficiency, but they must be explicitly subordinated to reliability, safety, and employee experience when demand is hybrid and attendance is elastic. Most mature EMS programs treat seat-fill as a constrained optimization outcome inside a governed routing and SLA framework, not as the primary objective.
In hybrid environments with variable WFH/WFO patterns, routing engines use shift windowing, dynamic clustering, and trip fill ratio (TFR) thresholds to pool employees. This reduces dead mileage and lowers cost per employee trip. However, the same elasticity creates higher volatility in no-show rates, last‑minute bookings, and shift changes. If algorithms chase maximum seat-fill without guardrails, a common failure mode is brittle routing. Employees experience tighter pickup windows, detours, and more frequent reassignments, which degrade on-time performance and trust.
Governance frameworks counter this by hard-coding reliability and safety as non-negotiable constraints. On-time performance (OTP%), trip adherence rate, maximum routing deviations, and night-shift escort or women‑first rules are set as policy boundaries within the routing logic. Central 24x7 command centers monitor real-time telematics, exceptions, and SLA dashboards, and they intervene when optimization begins to threaten adherence or safety norms. Penalty and incentive ladders are often tied to OTP, incident rate, and complaint closure SLAs rather than pure utilization, which discourages over-optimization of seat-fill.
Procurement and Finance teams increasingly adopt outcome-based contracts where payouts link to reliability, safety, and experience KPIs alongside utilization. This creates a multi-objective equilibrium in which high TFR and low dead mileage are rewarded only if they coexist with governed OTP, incident-free operations, and acceptable Commute Experience Index scores. HR, Security/EHS, and ESG leads then use audit trails, feedback data, and emission metrics to validate that routing policies respect employee trust, duty-of-care obligations, and ESG commitments rather than treating employees purely as capacity to be maximized.
How do we catch routing and rostering issues early—like infeasible routes or wrong manifests—before they turn into night-shift escalations?
B1138 Preventing silent routing failures — In India corporate ground transportation EMS, what are the most credible ways to detect and prevent “silent failure” in routing & rostering (routes generated but not feasible, bad ETAs, wrong manifests) before it becomes a night-shift escalation?
In Indian EMS operations, the most credible way to prevent “silent failure” in routing and rostering is to treat routes as hypotheses that must be stress‑tested by data and a command center before drivers and employees see them. Routes that are not validated against live traffic, shift windows, seat‑fill, and compliance rules tend to look fine on paper but fail on the road.
Silent routing failures usually appear where demand is volatile, data is fragmented, or vendors are managed manually. Unstable hybrid attendance, incomplete HRMS integration, and weak NOC observability mean the routing engine works in isolation. Most organizations only discover infeasible ETAs or wrong manifests when night‑shift employees start calling, which pushes Transport back into firefighting and escalations to HR.
Operations teams reduce this risk by building a pre‑shift “route assurance” layer in the command center. This includes automated checks on trip adherence risk, seat‑fill anomalies, dead mileage, female‑first routing, escort rules, and driver duty cycles before routes are locked. Command‑center tools that fuse telematics, HRMS rosters, and historical OTP% give early warnings on unrealistic ETAs or overloaded sequences while there is still time to fix them.
Pragmatic operators also run live pilots and case‑study style validations for new patterns. For example, some providers demonstrate 98% on‑time arrival in monsoon conditions through dynamic route recalibration, real‑time driver communication, and a dedicated command desk, which is strong proof that their routing engine and SOPs survive real‑world stress.
To keep silent failures from turning into 2 a.m. crises, facility heads typically rely on three control levers:
- Upstream data discipline from HRMS and attendance systems so the routing engine sees the real roster.
- A 24x7 command center with alert supervision, geo‑fencing, and escalation matrices for early intervention.
- Outcome‑linked KPIs such as OTP%, Trip Adherence Rate, and exception closure SLAs embedded in vendor contracts and dashboards.
When route design, command‑center oversight, and SLA governance work as a single loop, most routing and rostering failures are caught hours before the shift instead of during it.
If routing changes claim savings from higher seat-fill, what should Finance ask to uncover hidden costs like delays, escalations, extra cabs, or overtime?
B1139 Finance questions on seat-fill savings — In India EMS programs, how should Finance challenge routing & rostering changes that claim savings via higher seat-fill—what questions expose hidden costs like late pickups, escalations, extra vehicles, and overtime that don’t show up in per-seat math?
Finance teams should challenge “seat-fill driven savings” by forcing vendors to connect routing and rostering changes to full-trip economics, reliability KPIs, and downstream impact on shifts and overtime. Finance exposes hidden costs by asking for reconciled data across OTP, trip adherence, dead mileage, extra deployments, and escalations instead of accepting narrow per-seat or per-km math.
Finance should first insist that any new routing or pooling logic is evaluated at the level of cost per employee trip and total cost of ownership, not just cost per seat or per route. A higher Trip Fill Ratio can reduce nominal per-seat cost but often increases detours, dwell times, and risk of late pickups that erode value through productivity loss, night-shift penalties, or extra vehicles. Finance should require that vendors show route-level On-Time Performance, exception rates, and dead mileage before and after the change, and that these numbers reconcile with GPS logs and billing.
A common failure mode is when aggressive pooling mandates cause longer ride-times and more complex shift windowing. This typically drives more escalations to the Facility / Transport Head, more manual re-routing, and unplanned “backup” cabs that are not visible in headline seat-fill metrics. Finance should therefore ask specific questions that tie operations to cost and risk:
- “Show OTP%, Trip Adherence Rate, and exception closure time for these routes before and after the routing change.”
- “What was the change in dead mileage, average trip duration, and number of stops per trip after we increased seat-fill?”
- “How many extra vehicles, ad-hoc trips, or backup deployments were triggered due to missed or tight shift windows?”
- “Quantify overtime payout, extra shift allowances, and any additional guard/escort costs linked to delayed pickups after the new routing.”
- “How many safety or service escalations, especially for women’s night shifts, were logged in the same period, and what was their closure SLA?”
- “Did No-Show Rate, cancellation rate, or employee complaints increase for these optimized routes?”
- “Provide a route-wise comparison of Cost per Employee Trip and total monthly spend, including ad-hoc cabs and incident-driven trips, not only rostered trips.”
- “How does the routing engine respect shift windowing and female-first policies, and what guardrails prevent over-pooling or unsafe detours?”
- “What is the impact on Vehicle Utilization Index and fleet uptime—are we over-stretching a smaller fleet and increasing breakdown or downtime risk?”
- “Can we simulate a week of disruption (rain, strikes, events) under the new design and show how many extra vehicles or manual overrides would be required?”
These questions force vendors and internal teams to surface hidden overtime, buffer vehicles, and escalation handling that usually sit outside simple seat-fill reporting. They also align Finance with Operations and HR by linking routing decisions to reliable OTP, safety compliance, and employee experience, rather than accepting “paper savings” that increase night-shift firefighting.
What are the signs our transport desk is hitting change-fatigue from routing/rostering—too many edits and edge cases—and how do mature teams fix the process before adoption collapses?
B1140 Detecting change-fatigue in transport desk — In India corporate EMS, what operational behaviors indicate routing & rostering is creating change-fatigue for the frontline transport desk (too many edits, too many edge cases), and how do mature teams redesign the process so adoption doesn’t collapse?
In India corporate employee mobility, change-fatigue at the transport desk usually shows up as rising manual edits to routes and rosters, increasing exception volume per shift, and growing reliance on informal workarounds instead of the official routing engine. When routing and rostering rules change too often, or are over‑fitted to edge cases, frontline teams stop trusting the system and adoption quietly collapses into manual firefighting.
Operational stress becomes visible when rosters are re-run many times close to shift start. It also shows when command center staff frequently override the algorithm, reassign vehicles ad hoc, or bypass apps for calls and WhatsApp. A common failure pattern is routes that look optimal on paper but ignore driver fatigue, city‑specific traffic patterns, or EV charging realities. Another pattern is policy churn from HR or security that keeps adding micro‑rules for women-safety, escorts, and exceptions without simplifying how the desk executes them.
Mature teams stabilize routing by freezing core rules for defined review cycles and separating “policy” from “exceptions.” They use the command center as a control room that absorbs demand variability through capacity buffers and standby vehicles instead of constant re‑routing. They codify only a small set of exception types with clear SOPs and escalation paths, and keep the majority of trips on standard templates.
They also link the routing engine tightly with HRMS rosters so attendance changes flow automatically, reducing manual data entry. EV-using programs design fixed charging windows aligned to shift bands instead of ad hoc top-ups that cause last-minute route edits. Mature operations track OTP, trip adherence, driver fatigue, and re-route counts together, and use data-driven reviews to adjust fleet mix, shift windowing, and seat-fill targets rather than tweaking individual routes daily.
To protect the desk from burnout, leading operators define a simple “playbook per shift” that clarifies what must be handled by the system, what the desk can decide locally, and what goes to escalation. They treat new rules like change management, not just configuration, with short field pilots, daily shift briefings, and feedback loops from drivers and supervisors before scaling changes systemwide.
How do we set leadership expectations on what routing/rostering can realistically guarantee, so Ops isn’t set up to fail when exceptions happen?
B1141 Setting leadership expectations for routing — In India employee mobility services (EMS), how do you set realistic expectations with senior leadership on what routing & rostering can and cannot guarantee (OTP, seat-fill, fewer exceptions), so the Transport Head isn’t set up to fail politically?
In Indian employee mobility services, realistic expectations are set by converting routing and rostering from a “magic lever” into a governed, data-backed capability with clearly defined guarantees, preconditions, and failure modes. Leadership confidence comes from codified SLAs, visible constraints, and evidence-based reporting, not from blanket promises on OTP, seat-fill, and exception elimination.
Transport leaders need to frame routing and rostering as one layer in a broader operating model that also depends on driver availability, fleet mix, shift patterns, and command center responsiveness. Unrealistic promises emerge when leadership sees routing tools as standalone “AI” that can fix structural issues like under-sized fleets, chronic no-shows, or charging gaps in EV operations. A common failure mode is committing to near-perfect OTP without linking that target to shift windowing, dead-mile caps, and buffer capacity policies.
Realistic expectation-setting usually includes explicit operating bands for OTP and seat-fill linked to time bands, corridors, and attendance variability. It also includes a shared understanding of which exceptions can be predicted and contained by routing logic, and which are fundamentally external disruptions that require playbooks and buffers rather than punitive SLAs. Outcome-linked procurement helps here, because it ties payouts to specific KPIs under defined conditions rather than generic “best-effort” claims.
Transport Heads are politically protected when routing and rostering performance is monitored via a central command center with agreed KPIs, exception taxonomies, and closure SLAs. This structure makes it clear which breakdowns are process leaks versus vendor non-performance versus genuine force majeure. Structured governance, escalation matrices, and periodic performance reviews turn routing from a personal promise into an institutional contract that leadership can inspect and refine instead of blame.
When selecting a routing/rostering vendor, what proof should Procurement ask for so we don’t buy a great demo that fails with real constraints and late changes?
B1142 Procurement proof against demo-ware — In India EMS vendor selection for routing & rostering, what proof points should Procurement insist on to avoid over-promised “smart routing” (repeatable outcomes, constraints handling, late-change performance) rather than impressive demos?
Procurement teams shortlisting EMS routing and rostering vendors in India should insist on hard, repeatable proof of performance under real constraints rather than accepting generic “smart routing” demos. The most reliable proof points focus on outcome metrics over time, behavior under late changes and disruptions, and evidence that India-specific constraints and compliance rules are encoded into the routing engine rather than handled manually by ops teams.
Vendors should demonstrate sustained on-time performance for shift-based EMS across multiple sites and months, not just a few good days. Procurement should ask for anonymized historical OTP%, Trip Adherence Rate, and seat-fill data, plus evidence of dead-mileage control and fleet utilization. Repeatable outcomes become credible when supported by consistent on-time performance, stable exception-closure times, and verified reduction in route cost per employee trip after deployment.
Constraints handling is best validated by examining how the routing engine incorporates real-world India EMS rules. Procurement should request configuration evidence and sample route outputs that respect female-first policies, night-shift escort rules, cab capacity and pooling policies, rest-hour norms for drivers, geo-fencing of red-flagged localities, and security approvals for certain routes. A common failure mode is when “optimization” silently breaks safety or compliance rules to reduce kilometers, so Procurement should insist on explicit documentation of which business and safety constraints are hard-coded and which are operator overrides.
Late-change performance should be assessed through live or recorded scenarios rather than static demos. Procurement can ask vendors to replay real cases showing how the system handles last-minute roster changes, no-shows, cab breakdowns, sudden traffic disruptions, or weather events while preserving shift adherence. The quality of the SOPs, alerting, and escalation surrounding the routing engine often matters more than the UI, so documentation of command-center workflows, exception SLAs, and business continuity playbooks is as important as the algorithm itself.
To make these assessments practical and defensible, Procurement can convert them into evaluation criteria, such as:
- Provision of time-bound, multi-site historic KPI data with defined calculation methods.
- Evidence of encoded safety and compliance rules specific to Indian EMS operations.
- Demonstrated ability to re-route and re-roster within defined time limits after late changes.
- Audit logs and trip ledgers that show how routes were generated, overridden, and executed.
These proof points reduce the risk of over-promised “AI routing” and anchor selection on verifiable performance under the same constraints that the buyer’s transport and HR teams face every night.
From an IT angle, how do we judge if a routing/rostering setup will create long-term workarounds and operational debt even if the initial rollout looks fine?
B1143 IT assessment of operational debt risk — In India corporate employee transport (EMS), how should a CIO assess whether routing & rostering workflows will create long-term operational debt (manual workarounds, brittle integrations, spreadsheet side-processes) even if the first rollout seems successful?
A CIO should assess routing and rostering workflows for long-term operational debt by stress‑testing how they behave when demand, policies, and integrations change, not just whether the first rollout works. Operational debt usually appears where platforms cannot absorb hybrid-work variability, HRMS changes, multi-vendor realities, or new safety/ESG rules without manual side-processes, spreadsheets, or ad‑hoc scripts.
Early in evaluation, routing and rostering should be reviewed as part of a broader EMS stack that includes the routing engine, driver and rider apps, HRMS integration, and the 24x7 command-center workflow. Long-term stability depends on whether routing rules, shift windowing, seat-fill targets, and escort policies are configurable in the system or repeatedly “fixed” by manual overrides in the NOC. A CIO should look for clear API-first integration patterns into HRMS and ERP rather than flat-file exchanges that will proliferate reconciliation work later.
A common failure mode is when hybrid attendance, changing shift patterns, and EV/ICE mix require ongoing parameter changes that only the vendor can do. This often leads to cloned spreadsheets, shadow routing, and alternate trip ledgers. Another red flag is when the platform cannot expose canonical trip and roster data into a governed mobility data lake, which prevents automated KPI tracking for OTP, Trip Adherence Rate, dead mileage, and seat-fill.
Practical signals that routing and rostering will not create operational debt include: admin users can change routing constraints without code, HRMS and approval workflows are integrated via stable APIs, the command center runs primarily from a single dashboard instead of Excel, and all trip lifecycle events feed into auditable logs and analytics without re-keying.
images:
After go-live, what weekly/monthly routine should Ops run to keep routing and rostering stable—rule tuning, RCA, guardrails—so we don’t slip back into firefighting?
B1144 Post-go-live governance for stability — In India EMS post-go-live, what operating rhythm should a Facility/Transport Head run to keep routing & rostering stable (weekly rule tuning, exception RCA, seat-fill guardrails) without drifting back into constant firefighting?
An effective EMS operating rhythm for a Facility/Transport Head in India combines a tight daily command-centre routine with one structured weekly review and a lighter monthly reset. This rhythm keeps routing and rostering stable, protects seat-fill economics, and pushes exceptions into predictable review slots instead of 2 a.m. firefighting.
The daily backbone is a control-room style routine anchored on the command centre and dashboards. Transport teams should use tools like real-time GPS tracking, alert supervision, and compliance dashboards to monitor OTP, no-shows, over-speeding, and SOS events in-shift. Exceptions such as geofence violations, app downtime, EV low-battery alerts, or driver shortages should follow clear SOPs and escalation matrices, so decisions are playbook-driven rather than improvised.
The weekly cadence should be a fixed “routing and rostering clinic” with Transport plus HR/ Security representation. This forum reviews route-level KPIs like OTP%, Trip Adherence Rate, Trip Fill Ratio, dead mileage, and incident logs. The team should tune rules such as seat-fill thresholds, buffer vehicles, night routing for women, EV vs ICE mix by shift, and vendor allocation using data from dashboards and management reports. Root-cause work on late trips, repeat driver or route issues, and recurring safety alerts should close with explicit corrective actions and owners.
A light monthly cycle should recalibrate policies against hybrid-attendance patterns, seasonal disruption (e.g., monsoon) and ESG/EV goals. This is where leaders can adjust fleet mix, long-term rental versus on-demand share, and update BCP scenarios for strikes, tech failures, or infrastructure disruptions. The Facility/Transport Head protects their own bandwidth by insisting that ad-hoc changes feed into these weekly or monthly slots, so continuous improvement happens systematically and the command centre operates in a calm, predictable way rather than permanent crisis mode.
How can we handle last-minute roster changes fairly without pushing the transport team into endless edits and 3 a.m. calls?
B1145 Fair late-change handling without chaos — In India corporate EMS, how do you handle late roster changes (employee cancellations, shift swaps, WFH toggles) in a way that feels fair to employees but prevents the transport team from getting dragged into endless manual edits and 3 a.m. calls?
In Indian corporate EMS, late roster changes are best handled by codifying clear cut-off rules in policy, enforcing them in the transport system, and giving employees self-service tools with transparent consequences so operations is not editing rosters manually at 3 a.m.
A practical pattern is to define tiered cut-off windows for each shift and lock routing after that point. Any change before the cut-off is auto-accepted and re-routed by the system. Any change inside the “late window” is either disallowed or allowed with defined conditions, such as loss of guaranteed pickup or a nominal charge-back to the cost centre. This keeps rules consistent across sites and vendors and removes subjective case-by-case negotiation.
Transport heads avoid manual firefighting when employee apps, driver apps, and the command center all work off the same live roster and routing engine. In many EMS stacks like Commutr, employees can mark WFH, cancel, or request ad-hoc trips directly in the app, while the routing engine automatically recalculates routes, seat-fill, and ETA where still feasible. The command center only intervenes on genuine exceptions or safety cases rather than every minor change.
For fairness, organizations usually align roster cut-offs with HRMS shift rules and communicate them as part of employee mobility policy, not as a “transport rule.” HR broadcasts SOPs, uses in-app notifications, and publishes what is guaranteed versus “best-effort” after cut-off. When outcome-linked contracts and SLAs are in place, OTP and seat-fill targets are protected because last-minute volatility is bounded by design rather than absorbed by the transport team.
images:
What are the warning signs we’re over-optimizing routing—seat-fill, clustering, freeze times—and building in reliability risk that will later blow up?
B1146 Warning signs of over-optimization — In India EMS routing & rostering, what are practical indicators that the organization is “over-optimizing” (too aggressive seat-fill, too tight clustering, too late freeze) and creating hidden reliability risk that will eventually surface as incidents and escalations?
In employee mobility routing and rostering, over‑optimization shows up as rising operational friction even when dashboards still look “efficient.” The most practical indicators are patterns of stress in OTP, drivers, and exception handling that repeat across shifts instead of one‑off bad days.
One clear sign is when seat‑fill and dead‑mile metrics improve, but on‑time performance starts to fluctuate by shift or corridor. Another is when the routing engine keeps recomputing till the last minute, so manifests and vehicle details reach employees and drivers very close to pickup. Operations heads then rely on manual calls and WhatsApp to “stabilize” each shift, which means the algorithm is pushing beyond what the field can safely execute.
Hidden reliability risk also shows up as over‑tight clustering in difficult geographies or timebands. In India this typically means routes that look optimal on paper but ignore local congestion, monsoon patterns, security requirements, or escort rules. Facility and Transport Heads then see more near‑misses: drivers rushing to cover unrealistic legs, escort or guard rules bent to save one more seat, and informal rerouting without traceable approval. These do not break SLAs every day, but they accumulate into eventual incidents and escalations.
Common practical signals that routing and rostering are over‑optimized include:
• OTP% is still within contract, but variance between best and worst routes or shifts is widening.
• Exception closure time during night or monsoon shifts is rising, despite “better” route KPIs.
• Drivers report fatigue, missed breaks, or repeated requests to “adjust just this one trip” to accommodate late additions.
• The command center spends more time manually overriding or splitting “perfect” routes than monitoring and learning from data.
When these patterns persist, most organizations are trading short‑term cost and seat‑fill gains for higher safety, incident, and business‑continuity risk that will surface later as women‑safety escalations, audit gaps, and visible service failures.
How should we explain routing and rostering changes to employees—pooling changes, pickup time shifts—so trust stays intact and complaints don’t flood HR?
B1147 Employee communication for roster changes — In India corporate employee transport (EMS), how should the Transport Head communicate routing & rostering trade-offs to employees (why pooling changed, why pickup time moved) to preserve trust and adoption instead of triggering complaints and escalations to HR?
In corporate employee transport in India, Transport Heads preserve trust during routing and rostering changes by explaining decisions in simple operational language, linking them to clear safeguards on OTP, safety, and fairness, and backing every change with predictable SOPs for exceptions and feedback closure. Employees accept pooling and pickup shifts more easily when they see that route logic is rule-based, not arbitrary, and when they know how issues will be fixed before they have to escalate to HR.
Transport teams should avoid presenting pooling or time changes as “system decisions.” They should frame them as part of a governed EMS operation that balances three explicit constraints. These constraints are shift adherence and OTP, safety and compliance rules such as women-first routing or escort norms, and practical limits like fleet availability and dead mileage. Each message to employees should name which constraint is being protected. For example, a 10-minute earlier pickup should be explained as necessary to keep the entire route within OTP and statutory duty cycle limits.
A common failure mode is silent or last-minute change communication. This failure mode pushes frustrated employees straight to HR. To avoid this, routing changes should be accompanied by three predictable elements. These elements are advance notification with a reason in plain language, a simple option path for edge cases such as medical or childcare constraints, and a visible loop that shows complaints are converted into route reviews or exception approvals. When employees see that feedback drives periodic roster optimization, they are more likely to stay on pooled routes instead of opting out or escalating.
For our employee transport ops, how do we confirm that routing/rostering is what’s causing the 3 a.m. escalations (not vendor or GPS issues), and what logs or proof should we pull to show leadership?
B1148 Proving routing as root cause — In India corporate Employee Mobility Services (shift-based employee transport), how can a Facility/Transport Head tell whether routing and rostering problems are the real root cause of 3 a.m. escalations versus issues like vendor behavior or GPS gaps, and what evidence should they collect from shift windowing, clustering, and late-change logs to prove it internally?
In shift-based employee transport, a Facility/Transport Head can distinguish routing/rostering failures from vendor or GPS issues by tying every 3 a.m. escalation back to time-stamped, route-level evidence across the full trip lifecycle. Routing and rostering are usually the root cause when the pattern shows structurally bad shift windowing, poor clustering, or unmanageable last-minute changes rather than isolated vehicle or device failures.
Routing and rostering are likely at fault when recurring delays cluster around specific shift windows or routes. Patterns such as pickups scheduled too close to shift start, over-long routes across high-traffic corridors, or under-filled vehicles generating dead mileage indicate a planning problem rather than vendor behavior. If the Vehicle Utilization Index and Trip Fill Ratio are poor while vendor fleet uptime is acceptable, routing logic and capacity planning need correction.
Vendor behavior is more likely the driver when planned ETAs and routing look reasonable but actuals show repeated no-shows, vehicle breakdowns, or driver cancellations on otherwise healthy routes. GPS or app gaps usually show up as short, localized blackouts where driver and rider apps fail simultaneously despite stable route plans and historical OTP on those corridors.
To prove the root cause internally, Facility/Transport Heads should build a basic evidence pack drawn from three specific data streams: • Shift windowing: planned vs actual pickup times by shift, OTP% by shift band, and average buffer between last pickup ETA and shift start. • Clustering and routing: route distance vs actual travel time, seat-fill per route, dead mileage between first and last pickup, and repeated “problem routes” with low Trip Adherence Rate. • Late-change logs: time-stamped roster edits within defined cut-off windows, frequency of last-minute add/drops, and correlation of these edits with exception spikes.
A simple SOP can make this repeatable:
• Tag every escalation to a specific trip ID, route, and shift window.
• Pull the planned route manifest (roster, sequence, timings) and compare with GPS/telematics traces.
• Overlay vendor fleet uptime and driver behavior records to check whether the plan was operationally feasible.
When planned ETAs are unrealistic even under normal conditions, the evidence supports a routing/rostering root cause. When plans are sound but exceptions correlate with specific vendors, drivers, or GPS failures, the evidence supports targeted vendor governance or tech remediation. This approach reduces blame noise and allows the Facility/Transport Head to walk into internal reviews with auditable proof instead of anecdotal explanations.
In our routing and rostering, which real-world constraints usually break an otherwise ‘good’ roster, and how do we pressure-test those before we blame drivers or vendors?
B1149 Constraints that break rosters — In India corporate Employee Mobility Services routing and rostering, what are the most common real-world constraints (shift windowing, pickup sequencing rules, guard/escort constraints, location clustering, vehicle-type mix) that cause ‘perfect-looking’ rosters to fail in execution, and how should operations teams pressure-test those constraints before blaming drivers or vendors?
Most routing and rostering failures in Indian employee mobility look like driver or vendor issues, but usually come from unrealistic constraints in the roster design itself. Operations teams need to pressure-test shift windows, pickup rules, escort policies, clustering, and vehicle mix against real traffic, driver duty cycles, and charging or fueling realities before holding vendors accountable.
The most common constraint patterns that break “perfect” rosters in execution are timing-related. Shift windowing is often set to theoretical login/logout times without realistic buffers for gate security, elevator time, and known congestion corridors, which pushes even a single delayed pickup into a cascading OTP failure. Pickup sequencing rules that enforce strict “ladies first / last drop” or fixed first-pickup locations can conflict with live traffic patterns and one-way or no-parking zones, so a route that is optimal on a map becomes impossible on road.
Escort and women-safety constraints introduce additional fragility. Night-shift requirements for guard or escort pairing, female-first policies, and “no single woman alone in cab” rules can fail when attendance fluctuates, last-minute cancellations occur, or escort rostering is not synchronized with vehicle routes, leading to either non-compliance or forced last-minute rerouting. Location clustering also creates problems when micro-clusters ignore real choke points, construction, seasonal disruptions such as monsoon flooding, or campus gate rules, so geographically tight routes still run late.
Vehicle-type mix is another hidden failure source. EV deployment without matching charging windows to shift bands, high-mileage routes, and charger availability can produce “range anxiety” and unplanned swaps, while overuse of small sedans on high-load corridors drives dead mileage and re-routing. These problems increase when hybrid work patterns cause volatile seat-fill and when routing engines are tuned for average conditions rather than worst-case peaks.
Operations teams should pressure-test constraints through simple but disciplined checks before escalating to vendor blame. They should run dry-run drive tests on critical routes during actual shift bands, measure door-to-desk times instead of only gate-to-gate, and compare planned ETAs with historical telematics or GPS data from similar days, traffic, and weather patterns. They should simulate common disruptions such as one or two no-shows, a late escort, or a vehicle breakdown and see whether the roster still respects safety rules and shift windows.
Practical pressure-tests often include: - Validating that guard/escort rosters are generated from the same source data and time bands as cab rosters. - Checking EV or specific vehicle allocations against route length, known charger locations, and predicted dwell times. - Reviewing night-shift women’s routes jointly with Security/EHS to confirm policies can be met without impossible detours.
A common failure mode is designing constraints in isolation. HR defines safety rules, Security defines escort norms, Finance defines cost caps, and Transport is left to “make it work” on a live map. Operations leaders reduce firefighting when they insist on joint reviews of constraint sets, use data-driven route performance analysis, and feed back real exceptions into the routing logic, so constraints are adjusted before the next roster cycle rather than after the next escalation.
real-world inputs, constraints & boundary rules
Codified shift windows, clustering inputs, seat-fill targets, and real-world constraints; test against edge cases like weather disruptions and vendor delays to prevent chaos.
How do we set seat-fill targets that save money but don’t create fairness complaints—like longer ride times or forced pooling—especially on night shifts and women safety routes?
B1150 Seat-fill vs perceived fairness — In India shift-based Employee Mobility Services, how should HR and Facilities define seat-fill targets in routing and rostering so they reduce cost without triggering employee backlash about fairness (longer ride times, forced pooling, perceived ‘punishment’ routes), especially for night shifts and women safety protocols?
In India shift-based employee mobility, HR and Facilities should define seat-fill targets as banded ranges linked to explicit guardrails on ride time, detours, and safety rules, not as a single “maximize pooling” number. Seat-fill should be optimized only after hard limits are set for maximum ride duration, wait time, and women-safety protocols, and these limits must be coded into routing, contracts, and SOPs so employees never feel pooling is a punishment for speaking up or working unpopular shifts.
Seat-fill targets work best when they are contextual rather than uniform. Higher ranges suit dense, safe corridors and day shifts, while lower ranges are appropriate for sparse routes, late-night windows, and women-first routing that may require escorts, restricted pickups, or “door-to-door” patterns. A common failure mode is to push uniform 90–100% pooling on all routes, which lowers cost on paper but increases ride time, route zig-zags, and perceived unfairness, particularly for women on night shifts.
Cost reduction is more sustainable when seat-fill is one variable in a broader routing policy that includes dead-mile caps, shift windowing, and vehicle-mix rules. Contracts and routing engines should prioritize compliance and duty of care first, then optimize seat-fill within those non-negotiable boundaries. HR can protect experience by tracking commute complaints and attrition correlations, while Facilities watches OTP, dead mileage, and Trip Fill Ratio, and both functions jointly adjust seat-fill bands only where service-level and safety KPIs remain green.
What’s a practical way to measure how much manual roster work we do (edits, exceptions, re-routes) and turn that into a finance-friendly automation ROI case?
B1151 Quantifying rostering toil for ROI — In India corporate employee transport routing and rostering, what is a practical way to measure ‘toil’ for the roster team (manual edits, exception handling, re-clustering, last-minute cancellations) and translate it into a business case that a CFO will accept beyond generic ‘automation’ claims?
A practical way to measure roster-team “toil” is to time‑stamp every manual intervention in the routing lifecycle, convert it into a per‑shift “intervention minutes per 100 trips” metric, and then translate those minutes into fully loaded payroll cost, error/leakage cost, and escalation cost that the CFO can audit. This approach converts vague “automation saves time” claims into a defensible before/after unit‑economics story at the route and trip level.
A useful starting point is to align toil measurement with the actual ETS / EMS operation cycle that most Indian enterprises already recognize, such as the 10–11 step ETS Operation Cycle covering booking, rostering, routing, vendor allocation, tracking, closure, and billing. Each point where planners override system output, do manual re‑clustering, handle last‑minute cancellations, or patch GPS / app failures can be logged as a discrete “intervention event”. The Transport Command Centre or command‑center tooling can then report on count and duration of such events per shift, per 100 trips, and per planner.
A common failure pattern is to track only SLA outcomes like OTP% and ignore the hidden operational load required to maintain them. Measuring toil directly exposes how many FTEs are needed in the command center or transport desk to sustain current OTP and safety standards, especially under hybrid work and high exception environments such as monsoon conditions or night‑shift women‑safety routing. That makes it possible to compare a manual model versus a platformized EMS model that uses routing engines, alert supervision systems, and automated compliance checks.
To make this acceptable to a CFO, the roster‑team toil metrics should be linked to three cost buckets that map to familiar finance levers rather than technology jargon:
Direct labor cost. Use intervention minutes per 100 trips multiplied by fully loaded cost per planner hour to quantify how many planner FTEs are consumed just to keep the system stable.
Operational leakage and rework. Attribute billing disputes, dead mileage from ad‑hoc changes, and vendor penalties caused by manual errors to “toil‑driven” interventions within the ETS Operation Cycle and CRD / ECS workflows.
Risk and escalation cost. Link late‑night manual route fixes, non‑compliant driver or fleet substitutions, and missed safety protocols to quantified incident probability and potential financial exposure under HSSE, vendor & statutory compliance, and Business Continuity Plan scenarios.
Once a baseline is established over a few weeks, organizations can run a controlled pilot using their commute automation stack, command center tools, or EV‑fleet management platform and measure the delta in intervention minutes, planner FTE requirement, dead mileage, and dispute volume. Framing the result as “cost per employee trip including planning FTE + leakage + risk buffer” gives the CFO a clean comparison between status quo and an automated, command‑centered model, without relying on generic automation narratives.
With hybrid attendance changing daily, how do we manage dynamic re-routing so it adapts but doesn’t change routes so often that employees and drivers lose trust?
B1152 Governance for hybrid-demand recalibration — In India Employee Mobility Services, when hybrid work causes attendance volatility, how should shift windowing and dynamic recalibration be governed so the routing engine isn’t ‘thrashing’ routes every day and destroying predictability for employees and drivers?
In Indian employee mobility programs with hybrid work, shift windowing and dynamic recalibration should be governed by fixed timebands and explicit “recalculation rules” so the routing engine only optimizes within controlled windows and does not continuously reshuffle routes. Governance must cap how often routes change, which inputs can trigger recalculation, and how far before shift start any route can be altered, so employees and drivers retain predictability while still absorbing attendance volatility.
A common failure mode is allowing the routing engine to respond to every roster change in real time. This creates “route thrashing,” where pickup times and sequences keep shifting, which in turn damages On-Time Performance, driver morale, and employee trust. Most organizations avoid this by defining hard shift windows, cut-off times for bookings and cancellations, and a limited number of optimization runs per window that the command center can execute.
Stronger governance also links recalibration rights to the central command center and clear SOPs. Command center operations teams can run dynamic route recalibration only at pre-agreed milestones, such as after HRMS roster lock or after a defined cancellation cut-off, and they must preserve core constraints like guard/escort allocation, women-safety routing, and maximum duty cycles. This protects safety and compliance even when attendance is variable.
For the Facility / Transport Head, a workable pattern is: - Fix shift timebands and booking cut-offs so the routing engine sees “frozen” inputs at predictable times. - Allow micro-adjustments (single-seat swaps, dead-mile trimming) closer to shift start, but block full re-optimization. - Monitor KPIs such as Trip Adherence Rate, Trip Fill Ratio, and exception-closure time in the command center dashboard to tune these rules over time.
This approach treats dynamic routing as a scheduled, governed process inside each shift window, not a continuous reaction to every roster fluctuation, which significantly reduces night-shift firefighting and escalations.
images:
For last-minute roster changes, what workflows reduce chaos the most—cutoffs, approvals, exception queues—and where do they usually break during peak hours or weather disruptions?
B1153 Late-change workflows that prevent chaos — In India shift-based corporate employee transport, what late-change handling workflows in routing and rostering reduce operational chaos the most (e.g., cutoff times, approval rules, exception queues), and where do these workflows typically fail during peak shifts or bad weather?
In India shift-based employee transport, late-change handling works best when organizations formalize strict “windows” for changes, tie them to clear approval rules, and run all exceptions through a visible queue in the command center. These workflows reduce chaos when they protect routing and driver duty cycles from last‑minute churn, while still allowing controlled flexibility for genuine business or safety needs.
The most stable setups define roster cutoffs by shift windowing. Transport teams usually freeze rosters and routes 2–3 hours before shift start for night and early‑morning bands. Any change after cutoff is tagged as an exception and handled through a separate exception queue. This separation keeps the routing engine and fleet planning focused on a stable base load, which directly improves on-time performance and lowers dead mileage.
Effective late-change workflows also rely on graded approval rules. Normal bookings and cancellations follow standard HRMS-linked rules before cutoff. After cutoff, new joins, cancellations, or address changes typically require manager or process-owner approval, and sometimes HR or Security approval for night shifts or women employees. This rule-based gating prevents employees from casually reshuffling rides once routing is locked, which protects seat-fill ratios and reduces driver fatigue.
A functioning exception queue in the command center is the third stabilizer. All post-cutoff changes, no-shows, and real-time disruptions are funneled to a single operational view. Command-center staff then apply playbooks such as dynamic route recalibration, redeployment of standby vehicles, or controlled ride merges. This queue-centric approach allows teams to triage by impact on shift adherence, safety risk, and available buffers rather than reacting ad hoc to every call or message.
These workflows regularly fail during peak shifts or bad weather for predictable reasons. The most common pattern is informal override of cutoffs under pressure from business teams, which leads to continuous re-routing, longer driver duty cycles, and a spike in missed pickups. Another failure mode occurs when the routing engine and rostering tools are not tightly integrated with the HRMS or attendance systems. In these cases, headcount assumptions diverge from reality, and late changes expose hidden data mismatches during the busiest windows.
A second typical breakdown point is the absence of sufficient buffer capacity and pre-tagged standby vehicles. During heavy rain or traffic disruptions, even a well-governed exception queue will flood if there are no standby cabs or flexible fleet mix policies to absorb delayed trips. This often pushes command-center staff into manual workarounds, such as off-platform bookings and ad hoc pooling, which then erode audit trails, safety controls, and cost visibility.
A third area of failure is escalation and decision latency. If late-change approvals depend on unreachable managers, or if the command center lacks clear authority to make trade-offs between cost and reliability, exceptions pile up without resolution. That backlog translates directly into operational firefighting, with transport heads forced to intervene manually, reassign drivers, and placate site managers—especially during hybrid-work peaks, when attendance is more volatile.
Organizations that cope best during peak or bad-weather scenarios typically do three things well. They enforce non-negotiable cutoffs but define a small, clearly governed band of “critical exceptions.” They maintain pre-approved playbooks for weather and traffic disruptions that specify how to rebalance routes, use standbys, and relax seat-fill targets. They also ensure that all stakeholders—including HR, Security, and line managers—understand these rules so they do not unintentionally bypass the system when pressure rises.
How do we check that a vendor’s clustering and routes aren’t hiding issues like dead miles, unrealistic ETAs, or driver overtime, and what red flags should we look for in route plans and edit history?
B1154 Detecting hidden debt in routes — In India corporate Employee Mobility Services, how can a Transport Head validate that a vendor’s clustering logic and routing outputs are not hiding operational debt (dead miles, unrealistic pickup ETAs, driver overtime risk), and what red flags should they ask to see in route plans and roster edit histories?
In Indian corporate employee mobility, a Transport Head validates vendor clustering and routing by stress-testing routes against real shift realities, then interrogating the underlying data for dead mileage, ETA realism, and duty-cycle impact. A reliable vendor exposes trip-level telematics, roster edit histories, and exception logs that make dead miles, overtime risk, and failures visible rather than burying them inside “optimized” clusters.
First, routing outputs should be checked against on-ground constraints. Route plans must align with actual shift windows, known choke points, monsoon or festival patterns, and campus entry rules. In practice, most operations teams validate by comparing planned ETAs with historical GPS logs, on-time performance, and case studies from similar conditions such as heavy-rain clusters, where dynamic route optimization still delivered ≥98% on-time arrival and higher satisfaction. Any route that looks perfect on paper but repeatedly misses OTP under predictable traffic conditions indicates model overfitting and hidden operational debt.
Second, operational debt usually shows up in “edges” of the data. Transport Heads should insist on route-level and vehicle-level views that include dead mileage segments, duty hours per driver, trip adherence rate, and no-show or re-route events. A good vendor dashboard surfaces telematics for each vehicle, including battery or fuel use, route deviations, and utilization, so overtime risks and fatigue patterns can be spotted early instead of being discovered only when drivers start refusing duties.
Red flags become visible when vendors share full route plans and roster edit histories. Common signals include frequent last-minute route recalculations before each shift, unusually tight pickup sequences with minimal buffer, repeated manual overrides to squeeze in extra seats, and patterns of multiple reassignments of the same driver across overlapping routes. Heavy reliance on manual adjustments to “fix” algorithmic outputs is a warning that clustering logic is not stable under real demand.
Transport Heads should also examine how well the vendor’s routing integrates with HR rosters and shift patterns. A stable system synchronizes with HRMS for real-time roster updates, uses command-center tools to supervise routes, and maintains an auditable trip ledger of all changes. When roster changes lead to repeated ad-hoc trips, driver swaps, or high dead-mile repositioning, the clustering model is likely offloading its problems onto operations and driver duty cycles.
Practical checks that Transport Heads can use include:
• Comparing planned vs actual first-pickup and last-drop times at driver level.
• Requesting incident and exception reports that link delays to route design choices.
• Reviewing random days’ route edit histories to see how often “final” plans were changed.
A vendor that refuses to provide trip-level history, edit logs, or clear dead-mile metrics is a strong red flag. Hidden or opaque data almost always correlates with higher driver fatigue, rising overtime, and more calls to the control room during night shifts, even when headline KPIs look acceptable.
From an IT angle, how do we make sure editable rosters and dynamic re-routing don’t create multiple ‘truths’ or messy overrides that later break HRMS/attendance and audit trails?
B1155 Editable rosters vs data integrity — In India employee transport routing and rostering, how should a CIO evaluate whether editable rosters and dynamic recalibration features will create data integrity issues (multiple sources of truth, manual overrides, inconsistent timestamps) that later break auditability and integration with HRMS/attendance?
In employee transport, CIOs should treat editable rosters and dynamic recalibration as high‑risk change points for data integrity, and only accept them when every override is fully versioned, time‑stamped, and tied to a single authoritative trip/roster ID that remains consistent across HRMS, attendance, billing, and audit logs. Any routing or roster feature that allows silent edits, undocumented manual changes, or parallel export/Excel workflows will eventually create multiple sources of truth and break auditability.
A CIO should first insist on a clearly defined “system of record” for roster and trip truth. The mobility platform must expose a canonical trip and roster object with immutable primary keys, and all dynamic recalculations should update state on that object rather than creating disconnected copies. HRMS and attendance integrations should consume only this canonical object via APIs, not spreadsheets or side-loaded CSV uploads.
Data integrity risk rises sharply when operations teams can adjust manifests, pickup times, or routes without enforced workflows. A robust platform will force all manual overrides through structured actions such as “re‑route,” “re‑assign vehicle,” or “swap employee,” each generating an event with actor ID, timestamp, reason code, and pre/post state. This audit trail is what Security, HR, and Finance later rely on for incident reconstruction, SLA disputes, and billing reconciliation.
CIOs should evaluate vendors against a few concrete signals:
- Whether there is strict role‑based control on who can edit rosters or routes and within what time windows.
- Whether every change produces a non‑editable event log that is visible in command‑center dashboards and exportable for audits.
- Whether employee check‑in/OTP, GPS trace, and finalized roster all align on the same trip and roster IDs.
- Whether there is a clear precedence model when HRMS shift data, transport rosters, and last‑minute changes disagree.
A common failure mode is “Excel-in-the-middle,” where dispatchers export a roster, fix issues offline, and then re‑upload or operate from WhatsApp and phone calls. This pattern destroys HRMS alignment and makes complaint or incident investigations extremely hard to defend. CIOs should explicitly test how the platform behaves under late changes, network issues, and driver no‑shows, and confirm that the recovery flow still preserves a single authoritative record.
In practice, dynamic recalibration becomes safe when the routing engine, command center, and HRMS integration are all wired to the same live data model, and when observability is built in. That means the CIO can see which fields are editable, how often manual overrides occur, who performs them, and how those changes propagate into attendance, billing, and CO₂ or ESG reporting. Without that level of transparency, “flexible” rosters usually translate into fragmented truth and long‑term integration debt.
What change approach works when roster planners prefer Excel and worry they’ll be blamed if the algorithm messes up—how do we get adoption without revolt?
B1156 Driving adoption beyond Excel — In India corporate Employee Mobility Services, what change-management approach actually works to get roster planners and on-ground coordinators to adopt new routing and rostering tools when they are emotionally attached to Excel and fear being blamed if the algorithm fails?
A change-management approach that works for roster planners and on-ground coordinators treats the new routing tool as “decision support with guardrails,” not a replacement for their judgment, and protects them explicitly from blame during a defined transition period. Adoption improves when planners keep visible control, can override the system with simple SOPs, and see early proof that the tool reduces their night-shift firefighting instead of adding scrutiny.
The most common failure mode is rolling out routing automation as a top‑down mandate tied directly to OTP% and cost KPIs from day one. Planners then experience the tool as a surveillance layer. They fear every algorithm miss will surface as an SLA breach, while their Excel skills and local knowledge are devalued. In India EMS environments with volatile attendance and political or weather disruptions, any single high‑visibility miss can reset trust for months.
Successful teams phase adoption and change the risk equation for planners. They start with a shadow period where Excel remains the official system and the new engine runs in parallel only for comparison. They publish a clear SOP that reads “no planner will be performance‑measured on algorithm output alone” for an initial window, and they log where human overrides improved results so planners feel recognized as experts, not obstacles.
In practice, three patterns help:
- Define simple, planner-centric controls such as “lock this cluster,” “hard‑fix this pickup,” or “pin this escort rule,” so local realities are honored.
- Use the command center to surface early alerts on likely failures and give coordinators a playbook for manual corrections, rather than exposing them to post‑fact blame.
- Share quick, concrete wins focused on planners’ pain: fewer last‑minute cab shortages, less manual rework after no‑shows, and cleaner shift reports that reduce escalation calls from HR and leadership.
How should we write routing/rostering requirements in the RFP so vendors can’t sell ‘dynamic routing’ and then dump manual work back on our team after go-live?
B1157 RFP language to prevent overpromising — In India shift-based Employee Mobility Services, how should Procurement write routing and rostering requirements so vendors can’t over-promise on ‘dynamic routing’ while later pushing manual operations back onto the buyer’s transport team?
In India shift-based employee mobility, Procurement needs to write routing and rostering requirements as specific, testable obligations tied to SLAs, artifacts, and data access rather than accepting generic “dynamic routing” claims. Vendors should be contractually bound to own the routing engine, daily roster generation, and exception handling end‑to‑end, with clear limits on when manual intervention is allowed and who performs it.
Procurement should require that the vendor provides a documented routing and rostering process. The process should cover shift windowing, roster optimization, vehicle allocation, seat-fill targets, and dead mileage caps. The RFP should demand that vendors submit sample route plans, rosters, and Command Center workflows for representative shifts, including night windows and hybrid-work variability. This reduces the chance that a vendor hides behind vague “AI routing” narratives while planning to revert to spreadsheets.
A common failure mode is leaving “who does what at 10 p.m.” undefined. The RFP should specify that routing and roster generation are vendor responsibilities, that escalation and exception handling sit in the vendor’s command center, and that the buyer’s transport desk plays an approval and monitoring role only. It should also require a 24x7 command or control-center capability for EMS, with defined SLAs for route recalculation and exception closure, so manual fallback does not silently shift to the buyer.
Procurement can reduce over‑promise risk by tying commercials and performance to measurable routing outputs. Typical examples include OTP%, Trip Adherence Rate, Trip Fill Ratio, dead mileage, and exception detection‑to‑closure time. Vendors should be required to surface these as live KPIs in dashboards, not only in monthly PPTs. This aligns with centralized NOC and observability trends and ensures routing is judged on data, not promises.
To prevent post‑award reversion to manual operations, Procurement should encode explicit technical and process capabilities. The RFP can require a routing engine integrated with HRMS for roster sync, driver and rider apps supporting manifests and trip verification, and command-center tooling for alerts, triage, and escalation workflows. It should demand proof of production use in comparable EMS environments rather than demo‑only features.
Clear boundaries for manual vs automated handling are critical. Procurement should specify which scenarios may be handled manually (for example, declared system downtime or disaster conditions) and require that such events are logged with root-cause analysis and recurrence limits. This aligns with resilience and continuity playbooks and makes any sustained manual mode a contract‑visible deviation, not a quiet default.
Finally, Procurement should insist on auditability and data portability for routing and rostering. The contract should mandate retention of GPS/trip logs, route versions, and change histories, along with API‑level access or exports. This supports continuous assurance, enables route adherence audits, and gives the buyer leverage to challenge performance or switch vendors without losing routing intelligence.
When HR wants shorter ride times but Finance wants more pooling, how do we set clear routing guardrails—like max ride time and pooling thresholds—so we stop debating it every day?
B1158 Resolving HR vs Finance guardrails — In India corporate Employee Mobility Services, when HR pushes for shorter ride times and Finance pushes for higher pooling/seat-fill targets, how can leadership set routing and rostering guardrails (max ride time, max detour, pooling thresholds) that stop daily arguments and create a defensible policy?
Routing and rostering guardrails stop HR–Finance arguments when leadership fixes a small, non‑negotiable set of parameters that are tied to clear outcomes (safety, EX, cost) and are backed by data from the mobility platform. These parameters define maximum ride time, detour limits, and pooling thresholds by shift, gender, and location, so daily decisions become policy-driven instead of opinion-driven.
A practical pattern in India EMS is to start from employee safety and experience for night and long shifts, and then let Finance optimize pooling within those boundaries for day shifts and low‑risk corridors. Leadership can use Employee Mobility KPIs such as On‑Time Performance, Trip Fill Ratio, and Cost per Employee Trip as the shared scoreboard for HR and Finance, with the command center enforcing these limits in real time through the routing engine and rostering rules.
Guardrails become defensible when they are:
- Defined per persona and timeband. For example, stricter max ride times and detour caps for women on night shifts, and more aggressive pooling rules on day shifts and dense routes.
- Encoded in the EMS platform’s routing engine. The command center and routing tools should not permit routes that breach max ride time, detour percentage, or seat‑fill ceilings, so operations is not negotiating every exception manually.
- Linked to auditable evidence. Trip logs, GPS trails, and roster data should show compliance with these guardrails for HR audits, transport reviews, and Finance scrutiny.
- Reviewed on a fixed cadence. Leadership should revisit thresholds quarterly using data on OTP, complaints, incident rates, and CET to adjust guardrails rather than reopening the debate ad hoc after every escalation.
If routing/dynamic recalibration goes down (app outage or data feed failure), what fallback plan keeps the night shift running without reverting to WhatsApp chaos?
B1159 Fallback plan for routing failures — In India employee transport routing and rostering, what is a realistic ‘graceful degradation’ plan when dynamic recalibration or routing services fail (app outage, data feed issues) so the night-shift roster doesn’t collapse into WhatsApp coordination?
A realistic graceful degradation plan for India night-shift employee transport keeps the last confirmed roster and routes usable offline, shifts the command-center to a pre-defined “manual but structured” mode, and limits change to only safety‑critical and SLA‑critical interventions. The goal is controlled fallback, not improvisation, with clear SOPs, paper or Excel backups, and pre-agreed communication rules so operations never default to chaotic WhatsApp groups.
A strong plan starts from “offline-first” assumptions. The routing system should cache next-shift rosters, route sheets, driver manifests, pickup order, and contact lists locally before each shift. Command center teams should have printable or exportable trip-sheets and zone-wise driver lists that can be activated instantly during an app or data outage. This aligns with industry practice where ETS operation cycles and command centres already run on pre-defined rosters, indicative management reports, and macro transition plans rather than pure real-time optimization.
The second layer is a defined “manual control-room mode.” This uses call-center infrastructure, escalation matrices, and alert supervision systems to manage changes by phone and SMS, not ad-hoc WhatsApp. Transport teams rely on static route templates, zone-wise buffers, and standby vehicles similar to business continuity plans for cab shortages, strikes, and technology failures. Only exceptions such as no-shows, replacement vehicles, and safety incidents are manually rerouted, while all non-critical optimizations are deferred.
The third layer is governance and evidence. Even in fallback, trip details, attendance, and incidents should be logged using simple tools like spreadsheets, duty slips, and call logs. These records later sync back into the main system to preserve auditability and HSSE compliance. This approach supports on-time performance, safety protocols, and data-driven insights, while protecting the facility or transport head from blame when tech fails, because the degradation path is documented as part of the compliance, safety, and BCP plan.
How can Finance verify that routing optimization savings will really show up in the monthly invoice, especially when late changes and manual overrides can wipe out savings?
B1160 Verifying savings survive exceptions — In India corporate Employee Mobility Services, how can a CFO test whether routing optimization claims (dead-mile reduction, better clustering, higher seat-fill) will actually show up in monthly bills, given that late changes and manual overrides can erase the savings?
A CFO can test routing optimization claims only by forcing a tight link between the “smart routing” outputs, the live trip log, and the final invoice, and then checking whether OTP, dead mileage, and seat-fill improvements show up as lower CET/CPK over several billing cycles. Any optimization that cannot be traced from route plan to audited trip ledger to bill line item will usually dissolve under late changes and manual overrides.
The first control is to demand a clear baseline. The CFO can lock a pre-implementation view of cost per kilometer, cost per employee trip, dead mileage share, Trip Fill Ratio, and OTP% over at least one full roster cycle. This baseline needs to be built from reconciled trip data already used in billing, not from vendor slideware.
The second control is invoice–telemetry reconciliation. The CFO can insist that every billed kilometer and trip exist in a trip ledger with time-stamped GPS traces, route IDs, and employee manifests that reflect the routing engine’s decisions. Spot audits can compare a sample of “optimized” routes against actual paths, seat-fill, and any mid-shift manual re-routing.
The third control is to separate “designed plan” from “executed reality.” The vendor should expose both the optimized roster (planned trips, planned seats, planned km) and the executed roster with exception tags. The CFO’s team can then quantify how much cost leakage comes from last-minute changes, manual overrides, or vendor-side non-adherence versus genuine demand volatility.
To prevent savings erosion, the CFO can push for outcome-linked commercials. Contracts can index a portion of payouts to achieved Trip Fill Ratio, dead mileage caps, and cost per employee trip rather than pure per-km billing. When OTP and safety SLAs are protected, but seat-fill or dead-mile targets are missed without client-driven changes, penalties or non-billable km can apply.
A practical CFO test usually includes three checks:
• A pilot or A/B window where a subset of routes uses optimization while a control group stays on legacy routing.
• A monthly variance report that explains any gap between “model savings” and “actual savings” by cause code.
• A data-access clause that guarantees Finance and Audit read access to the mobility data lake or report layer, so internal teams can recompute key KPIs independently.
If the vendor cannot expose this chain of evidence, if “optimized” routes still show high dead mileage under random audit, or if CET/CPK does not move meaningfully after normalizing for volume and fuel rates, the routing optimization is not operationally real, regardless of algorithm claims.
How do we define what ‘stable operations’ means in routing/rostering, and what daily early-warning indicators should we watch so we prevent the next firefight?
B1161 Defining calm and leading indicators — In India shift-based employee transport routing and rostering, how should operations leaders define what ‘predictable calm’ looks like (fewer roster edits, fewer escalations, stable routes) and what leading indicators they should monitor daily to prevent the next firefight?
Operations leaders should define “predictable calm” as a state where shift operations run with minimal manual intervention, route plans remain largely unchanged across the shift window, and exceptions are detected and contained early through the command center rather than through employee or HR escalations. Predictable calm in shift-based routing and rostering is characterized by high on-time performance, low last-minute roster edits, and a stable core of recurring routes that only need controlled, rules-based adjustments as hybrid attendance fluctuates.
In practice, predictable calm exists when the 24x7 command center is managing by exception instead of building routes manually for every shift. Command center operations become a filter that turns real-time GPS, trip logs, and safety alerts into early warnings for route adherence issues, driver fatigue, and geo-fence or escort non-compliance. Dynamic routing and seat-fill optimization are still used, but they are governed by shift windowing rules, dead-mileage caps, and vendor SLAs so that changes remain inside pre-agreed thresholds and do not create new firefighting.
Daily leading indicators for predictable calm are drawn from reliability, utilization, and safety telemetry. Operations leaders can track on-time performance percentage at the route and shift-window level to spot patterns before HR hears about them. Leaders can monitor trip adherence rate, vehicle utilization index, and trip fill ratio to see when capacity and routing are drifting from plan. Safety and compliance signals like incident rate, geo-fence violations, and credential currency serve as early warnings that tomorrow’s firefight will be about safety, not timing.
Command center teams should also watch operational load indicators that signal rising chaos such as number of manual roster overrides, count of last-minute vendor or vehicle substitutions, and average exception detection-to-closure time. Monitoring no-show rate together with complaint or SOS patterns helps correlate attendance volatility with commute reliability. When these leading indicators are surfaced on a single dashboard and tied to SOP-based escalation and response, operations leaders gain the early alerts and control-room stability required to keep shift mobility from escalating into HR, security, or leadership crises.
What risks come from letting each site freely edit rosters, and how do we keep central control without slowing down urgent last-minute changes?
B1162 Local overrides vs central control — In India corporate Employee Mobility Services, what are the political and practical risks of allowing too much ‘editable roster’ freedom to site admins (local overrides), and how can a central transport governance team keep control without slowing down urgent late changes?
In Indian corporate employee mobility, excessive “editable roster” freedom for site admins creates both political and practical risk. Local overrides improve short‑term flexibility but often erode central governance over safety, cost, compliance, and data integrity if they are not tightly bounded and observable.
Politically, uncontrolled local edits shift blame upwards when something goes wrong but leave Transport, HR, and Security without audit-ready evidence. A common failure mode is a night-shift incident where the employee, HR, and leadership assume the central team “approved” a route that was actually altered locally. This weakens trust in Employee Mobility Services, creates friction between HR, Procurement, and the Facility/Transport Head, and makes it hard to defend decisions during internal investigations or external audits.
Practically, free-form overrides damage route optimization, inflate dead mileage, and break SLA measurement. Local changes outside the routing engine reduce seat-fill, disturb shift windowing, and can undermine EV utilization and uptime if EVs are in the fleet. Manual last-minute swaps also bypass automated checks on driver KYC/PSV, fatigue norms, escort rules for women on late shifts, and geo-fenced risk controls, increasing real safety exposure while destroying the integrity of trip logs and KPI dashboards.
A central transport governance team can retain control without blocking urgent changes by designing a tiered override model and embedding it into the platform and SOPs rather than banning edits outright. One pattern is to define which fields are locally editable, which require time-bound approval, and which are locked, and then implement this in the EMS routing and rostering tools with role-based access and clear audit trails for every override. Another is to allow site admins “rapid-change slots” within a defined buffer window before shift start, where changes are permitted but automatically re-run through the routing engine so OTP, seat-fill, and escort rules are preserved.
Governance improves when overrides generate structured events into the command center, instead of silent spreadsheet edits. Central NOC teams can then see deviation counts by site, correlate them with OTP, incident rates, and CET, and intervene with coaching where override patterns indicate systemic issues. This preserves the Facility/Transport Head’s ability to handle real-world disruptions like driver no-shows, weather, or security alerts, but keeps the Integrated Mobility Command Framework intact.
In practice, a resilient model usually includes: - A standard, locked “master roster” cut-off each cycle, after which only specific override types are allowed. - A small catalog of override reasons (e.g., medical emergency, security alert, last-minute shift extension) selectable in the tool, not free text. - Automated re-validation of compliance rules and escort policies whenever a change is made, with the system blocking unsafe combinations by design. - Live visibility for HR, Security/EHS, and central Transport into all deviations via dashboards, so no site operates as a black box. - Quarterly or monthly reviews where frequent local overrides feed into route redesign, capacity buffers, or vendor changes, rather than tolerated as permanent firefighting.
This approach treats editable rosters as a controlled safety valve inside a governed EMS operation cycle, not as an unmanaged escape route from the routing engine and command center controls.
If our clustering logic keeps giving longer rides to certain areas or timebands, how do we make that fair and defensible, and what review process prevents reputational issues?
B1163 Fairness risk in clustering logic — In India corporate Employee Mobility Services routing and rostering, how should Legal/Compliance think about fairness and defensibility when clustering logic systematically assigns longer rides to certain neighborhoods or timebands, and what internal review process prevents reputational blowback?
In India corporate employee mobility routing, Legal and Compliance should treat systematic assignment of longer rides to certain neighborhoods or timebands as a potential discrimination and duty‑of‑care risk that must be explicitly governed, logged, and reviewable. Fairness is defensible only when routing rules are policy‑driven, safety‑aligned, applied consistently across employees, and supported by transparent evidence on why specific clusters and travel times were chosen.
Legal and Compliance teams should insist that the routing engine’s clustering logic is expressed as clear, human‑readable rules. These rules should reference operational constraints such as shift windowing, seat‑fill targets, dead‑mile caps, women‑safety requirements, and EV range or charging limits, instead of opaque “black box” decisions. Systematic patterns like one area always getting longer routes should trigger automated flags for review, with route adherence audits and exception reports feeding back into governance.
An internal review process should operate like a mini mobility governance board. Legal, HR, Transport, and Security should receive periodic dashboards that highlight route and trip adherence patterns, on‑time performance gaps by geography and timeband, and complaint or escalation clusters. Any persistent bias pattern should lead to a documented change in routing policy, an updated SOP for the command center, and a traceable rationale in the mobility risk register, so the organization can show regulators, auditors, or media that decisions were safety‑ and efficiency‑led, not arbitrary or discriminatory.
images:
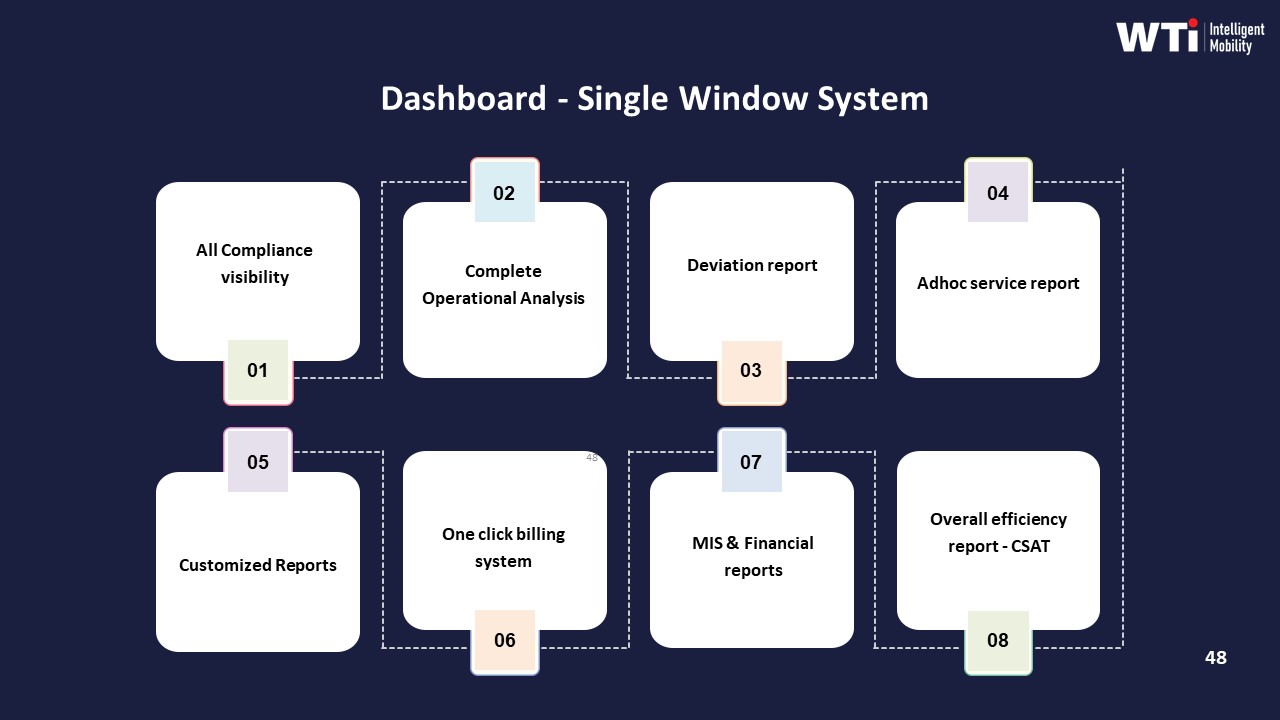
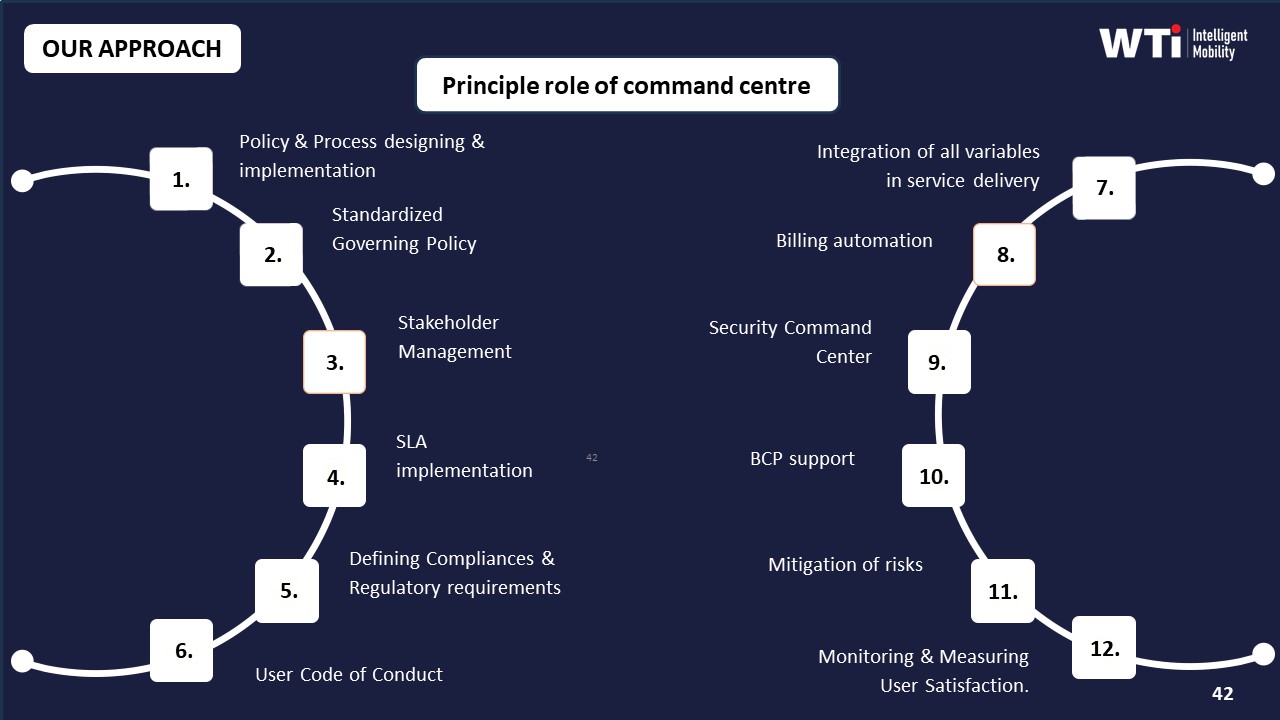
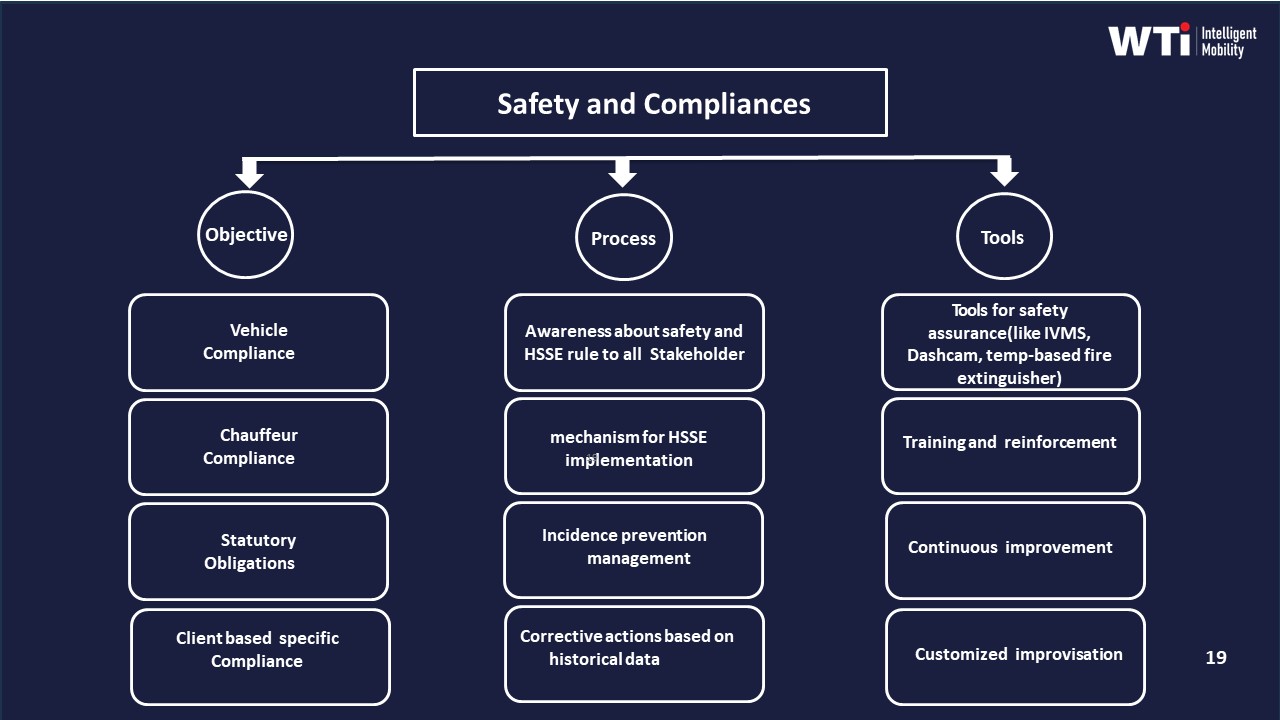
If a routing/rostering rollout causes missed pickups and chaos, what should we ask in the post-mortem to separate bad input data, bad constraints, and bad overrides—and protect the ops lead’s credibility?
B1164 Post-mortem for failed rollout — In India shift-based Employee Mobility Services, when a routing and rostering rollout goes wrong (missed pickups, chaotic recalibration), what post-mortem questions should an operations leader ask to distinguish bad data inputs (rosters/shifts), flawed constraints, and human override behavior—and to protect their credibility with leadership?
In a failed routing and rostering rollout, an operations leader should separate three things very clearly. Those are the quality of upstream data (rosters and shifts), the routing constraints and configuration, and human overrides during live operations. Each bucket needs its own fact-finding questions and its own evidence so leadership can see where control broke down and where it did not.
1. Questions to isolate bad data inputs (rosters, shifts, master data)
Post-mortem analysis should first verify whether the routing engine was fed clean, frozen inputs. Operations leaders should ask for concrete evidence, not assumptions.
- Data readiness. Were employee rosters, shift timings, and pickup/drop addresses frozen by a clear cut-off time before routing started.
- Change churn. How many roster changes, shift swaps, and new joiners or leavers were processed after the routing cut-off but before shift start.
- Source-of-truth. Did the routing engine pull from the HRMS or attendance system as the single source, or were there parallel Excel sheets and manual edits.
- Data quality. What percentage of records had missing or invalid address geocodes, incorrect gender or escort flags, or wrong home-office location tags.
- Timeband accuracy. How many employees had overlapping or ambiguous shift windows that the engine could not logically satisfy.
- Lock-in governance. Who had authority to change rosters after cut-off, and were those changes logged with time stamps and reasons.
These questions connect directly to hybrid-work elasticity, HRMS integration, and demand volatility. They protect credibility by showing whether Transport was working with stable inputs or fighting late and dirty data.
2. Questions to test routing constraints and optimization logic
If inputs were unstable, routing may have been blamed unfairly. If inputs were stable, the next layer is whether constraints, SLAs, and policies were configured correctly in the routing engine.
- Objective function. What exactly was the routing engine optimized for on this rollout, such as lowest cost per km, highest seat fill, or maximum on-time performance.
- Constraint realism. Were hard constraints like shift start windows, maximum ride time, escort rules, and female-first drop policies encoded to match actual policies.
- Fleet assumptions. Did vehicle capacities, EV range assumptions, and dead-mile caps in the engine match the real fleet available at that timeband.
- Scenario testing. Was the routing configuration tested on historical data or a pilot shift with measured OTP%, Trip Adherence Rate, and Trip Fill Ratio before full cutover.
- Failure patterns. Did missed pickups cluster around specific depots, timebands, or certain EV routes, indicating constraint misconfiguration or unrealistic route density.
- Recalculation latency. How long did re-optimizations take when last-minute changes arrived, and did that delay propagate into late dispatch.
These questions anchor the discussion in routing engine behavior, not in generic “AI failed” narratives. They show leadership that configuration, constraints, and EV-specific limits were examined against OTP and utilization KPIs.
3. Questions to separate human override behavior from system design
Even with good data and correct constraints, on-ground behavior can introduce chaos. Operations leaders should make override decisions explicit and auditable.
- Override volume. How many routes or allocations were manually changed after the engine produced its plan, and what proportion of total trips did that represent.
- Override reasons. Were overrides driven by driver shortages, no-shows, VIP or executive priorities, or local security concerns not modeled in the system.
- Escalation discipline. Did dispatchers and night-shift controllers follow defined SOPs and escalation matrices when overriding, or did they act ad hoc.
- Tool reliability. Were there GPS failures, app downtime, or communication gaps that forced manual workarounds from the command center.
- Training and readiness. Had dispatchers, routers, and transport desk teams been fully trained on the new routing workflow and exception handling before go-live.
- Pattern analysis. Did routes that remained untouched by human overrides perform better or worse on OTP and missed pickups than heavily edited routes.
These questions highlight the role of the 24x7 command center, escalation mechanisms, and business continuity playbooks. They allow an operations leader to show where the system performed as designed and where human interventions increased risk.
4. Questions to frame accountability and protect credibility with leadership
Leadership expects clarity about where controls failed, how often, and what will change. The operations leader should explicitly connect findings to governance, not personalities.
- Control mapping. For every major incident, was the root cause data quality, configuration, or human override, and which control failed to catch it earlier.
- Evidence packs. Can the command center produce trip-level audit trails, GPS logs, roster versions, and override logs for the worst-affected shifts.
- Guardrail gaps. Which controls or dashboards (such as early warning on under-capacity routes or high change-churn rosters) were missing at the time.
- Improvement plan. What specific changes will be made to cut-off rules, pilot scope, training, or routing parameters before the next rollout.
These framing questions align with outcome-linked procurement, centralized NOC observability, and data-driven operations. They help an operations leader present a disciplined post-mortem that separates structural issues from execution lapses and preserves trust by being precise about what will be fixed and how.
What should a routing/rostering pilot include to prove it handles late changes and hybrid demand for real, and not just because the vendor added extra people behind the scenes?
B1165 Pilot design to expose manual work — In India corporate employee transport routing and rostering, what does a realistic pilot look like that proves the system can handle late changes and hybrid demand elasticity—without the vendor quietly staffing extra people behind the scenes to make it ‘look automated’?
A realistic pilot for employee transport routing and rostering in India proves late-change handling and hybrid elasticity by exposing the system to real rosters, real disruptions, and measurable KPIs with tightly controlled manual intervention. A credible pilot makes automation observable, caps human overrides, and links outcomes to data trails instead of vendor narratives.
A robust pilot usually starts with a clearly scoped zone of operations and shift windows. The pilot uses actual hybrid attendance patterns and live booking behavior rather than synthetic data. The routing engine is tested on real Employee Mobility Services use cases like shift-based rostering, pooled routing, and escort or women-safety rules for night shifts. The system must integrate with HRMS or roster sources and ingest changes in near real time.
A well-designed pilot defines explicit KPIs for on-time performance, trip adherence, seat-fill ratio, dead mileage, and exception closure time. These KPIs are tracked in a transparent dashboard rather than through manual reporting. Outcome-based measurement demonstrates if dynamic routing, traffic-aware sequencing, and seat-fill optimization are working under changing demand. Data-driven observability makes it difficult to hide manual patchwork.
To prevent vendors quietly adding extra people, organizations set hard rules for manual overrides and log every intervention. Command center operations are run with a fixed headcount and a defined escalation matrix. Each override is tagged in the trip lifecycle data so exception volumes can be audited against SLA breaches, late changes, or app or GPS failures. This makes the balance between algorithmic planning and human supervision measurable.
A realistic pilot also includes deliberate stress tests. These tests inject late bookings, last-minute cancellations, and weather or traffic disruptions into shift windows. The organization evaluates whether dynamic route recalibration, hybrid capacity flexing, and exception workflows maintain OTP and cost baselines. Failure modes such as GPS downtime or vendor non-response are part of the test, not excluded from scope.
A credible pilot agreement explicitly links commercial discussions to these metrics. The enterprise evaluates cost per employee trip, route cost reduction, and vehicle utilization alongside safety incidents and complaint closure SLAs. The pilot does not rely on long-term lock-in or opaque contracts. Instead, it uses outcome-based evaluation and preserves data portability so the same KPIs can be applied to another vendor or internal benchmark if needed.
How should we train junior roster planners to handle exceptions in the tool—no-shows, last-minute adds, vehicle swaps—so they don’t fall back to spreadsheets in peak hours?
B1166 Training juniors for exceptions — In India shift-based Employee Mobility Services, how should a junior roster planner be trained to handle exceptions (no-shows, last-minute add-ons, vehicle swaps) inside a routing and rostering tool so they don’t panic and revert to manual spreadsheets during peak hours?
A junior roster planner should be trained to treat exceptions as predefined workflows inside the routing tool, not as ad-hoc crises, with clear SOPs for no-shows, last-minute add-ons, and vehicle swaps that can be executed in a few clicks and audited later. The goal is to build “control-room reflexes” so the planner trusts system alerts, escalation rules, and re-optimization instead of defaulting to manual spreadsheets during peak hours.
They should first learn the normal ETS operation cycle in the tool. The training should cover how the platform converts bookings into rosters, pushes trips to driver apps, and surfaces real-time status via the command center or dashboard. A clear mental model of how routing, GPS tracking, driver allocation, and SOS features connect reduces panic when anything changes. Hands-on sandboxes using simulated shifts, including night-shift routing and women-safety constraints, make the workflow familiar before live use.
Exception handling training should be scenario-based. For no-shows, the planner should learn to trigger a standard flow. They acknowledge the alert, cancel or mark the seat, re-calculate route in the system, and log the reason for MIS and billing. For last-minute add-ons, they should practice using the route optimization engine to insert employees into existing trips while watching utilization and detour limits instead of guessing in Excel. For vehicle swaps, they should learn to use tagged backup vehicles and the fleet compliance view, ensuring replacement vehicles meet contractual and safety standards before reassigning trips.
To prevent reversion to spreadsheets, training should emphasize tool capabilities that reduce cognitive load during peaks. These include live trip status, geofencing and alert supervision, driver and fleet compliance dashboards, and integrated SOS or safety workflows. Planners should be taught to rely on standardized routing rules, dead-mileage caps, and seat-fill targets already encoded in the system, instead of trying to re-optimize manually under pressure. Regular drills and refreshers using case studies, such as monsoon disruption scenarios with maintained 98% on-time arrival, help move behavior from reactive to predictable and audit-ready operation.
How can we run a lightweight daily route-quality check—clusters, seat-fill vs ride-time, late-change volume—so we catch issues early without adding more bureaucracy?
B1167 Lightweight daily route-quality review — In India corporate Employee Mobility Services routing and rostering, how can a Facility/Transport Head set up a simple daily ‘route quality’ review (cluster integrity, seat-fill vs ride-time tradeoffs, late-change volume) that catches issues early without creating another layer of bureaucracy?
A Facility or Transport Head can run a daily “route quality” review as a short, control-room style huddle that uses a fixed metric snapshot and a simple exception log instead of a long meeting. The review should focus on three levers: how stable each cluster was, how well seats were filled versus ride-time limits, and how many late changes forced manual firefighting.
The most practical pattern is to drive this review off a single-window dashboard that already exists in many EMS setups. That dashboard can expose OTP, route adherence, seat-fill, and exception counts so transport teams do not manually compile data. A daily 10–15 minute huddle can then run on a fixed script, where the shift supervisor or command center executive reports yesterday’s cluster breaks, routes breaching ride-time norms, and high late-change routes, and logs only those as “exceptions to fix.”
This type of review works best when it pushes issues into small corrective tickets, not discussions. For example, a cluster that keeps breaking could be tagged for routing rule change, vendor allocation change, or driver coaching. A route with high seat-fill but long ride-time might be split, while routes with persistent low seat-fill might be merged or shifted to a smaller vehicle type. High late-change volume can be traced back to HRMS sync delays, roster cut-off times, or specific teams that need firmer booking discipline.
To avoid bureaucracy, the Facility or Transport Head can define three or four hard thresholds and automate alerts against them, so the huddle only talks about routes that cross those thresholds. Over time this converts routing and rostering from reactive, manual firefighting to a predictable, exception-led routine anchored in existing EMS dashboards, command center monitoring, and escalation matrices.
Where do things usually break when routing/rostering depends on HR shift and attendance feeds, and how do HR and IT fix data discipline together without a blame game?
B1168 Fixing upstream HR data discipline — In India corporate Employee Mobility Services, what are the typical failure points when routing and rostering depend on HR shift rosters and attendance feeds (late updates, wrong locations, contractor lists), and how do HR and IT jointly fix the upstream data discipline without blaming each other?
In India corporate employee mobility, routing and rostering usually fail when HR shift and attendance data is late, incomplete, or inconsistent. The most common failure points are delayed or wrong rosters, incorrect pickup locations, and unmanaged vendor/contractor lists, which directly degrade on-time performance, increase dead mileage, and trigger safety and compliance risks. HR and IT typically stabilize this by treating rosters and attendance as governed “systems of record,” with API-based integration, clear cut-off rules, and shared SLAs, instead of informal Excel and last-minute manual edits.
Typical failure points include late or changing shift rosters that arrive after routing has run. This failure creates rework for the transport team, increases exception handling, and leads to employees missing cabs. Wrong or outdated employee addresses or work locations cause misrouted pickups and longer routes. This fuels driver fatigue, dead mileage, and unpredictable arrival times. Poorly governed contractor or vendor staff lists often lack approval flags or escort rules, which creates ambiguity about who is entitled to transport and under what safety conditions.
HR and IT usually fix upstream data discipline by defining a single canonical source for each data element. HRMS becomes the master for identity, entitlement, and shift assignment, while the mobility platform consumes this via APIs on a timed schedule. Jointly agreed cut-off times and change windows are essential so that routing engines work on frozen data for each shift. HR and IT also align on auditability so that every roster change and location update is logged for later traceability and continuous improvement.
A practical joint approach is to treat commute data like payroll or attendance data. HR owns the business rules for who is eligible and when, and IT owns the pipelines, validation checks, and access controls that keep the feeds clean and secure. A shared KPI set that includes on-time performance, exception rate from bad inputs, and incident-free compliance helps both HR and IT see data quality as a common operational outcome rather than a source of blame.
When leadership is angry about late logins, how should we decide whether to prioritize seat-fill savings or on-time performance in routing and rostering?
B1169 Seat-fill versus OTP under pressure — In India shift-based employee transport routing and rostering, how should an executive sponsor decide between optimizing for seat-fill targets versus optimizing for on-time performance when leadership pressure spikes after a month of late logins and escalations?
In shift-based employee transport in India, an executive sponsor should prioritize on-time performance over seat-fill when late logins and escalations spike, then re-introduce seat-fill optimization only after on-time performance is stable and predictable. On-time performance failures directly hit production, HR trust, and leadership confidence, while suboptimal seat-fill mainly affects unit cost and can be corrected later once operational control is restored.
When escalation pressure is high, most organizations regain control by simplifying the routing objective for a period. Operations teams shift from aggressive cab pooling and extreme route compression to conservative buffers and simpler, more direct routing. This reduces dead mileage and seat utilization efficiency in the short term but lowers exception rates and last-minute firefighting in the control room. In practice, this is closer to how facility and transport heads actually create “operational calm” under stress.
A common failure mode is trying to simultaneously tighten seat-fill and recover on-time performance in the same window. This usually increases driver fatigue, route brittleness, and exposure to traffic or weather variability, which creates more night-shift escalations and further erodes trust in both HR and transport. Leadership then experiences a double loss: higher noise and no visible cost win.
A practical decision pattern is to set a clear phasing logic:
- Phase 1: Reset to a minimum acceptable OTP threshold with conservative routing and clear exception handling, even if this temporarily relaxes seat-fill targets.
- Phase 2: Once OTP stabilizes and escalations drop, use routing and data insights to gradually increase pooling and seat-fill, with guardrails that prevent OTP from falling below the new baseline.
This approach aligns with how centralized command centers, SLA governance, and hybrid-work routing are designed to work in the Indian EMS context. It treats reliability and safety as the non-negotiable foundation and cost optimization as a controlled, data-led second step rather than a competing first priority.
For adoption, what usability features are non-negotiable—like Excel-style bulk edits and clear change diffs—and how do we test them with real planners, not just in a demo?
B1170 Usability checks for planner adoption — In India corporate Employee Mobility Services routing and rostering, what ‘non-negotiable’ usability features matter most for frontline adoption (e.g., Excel-like bulk edits, fast search, clear diff views for late changes), and how can operations leaders validate usability with real planners instead of a polished demo?
In India corporate employee mobility, routing and rostering tools only get adopted when planners can work at “control-room speed.” Non‑negotiable usability features are those that reduce clicks, support bulk changes, and preserve planner trust in the plan under constant last‑minute change pressure. Operations leaders need to validate these features through live war‑room style trials with real planners, not static demos.
Frontline planners need bulk operations that feel as fast as Excel. Planners typically manage large rosters and route plans under tight shift windows, so they need bulk upload from CSV, bulk seat reassignment, and multi‑row edit for vendor changes, escorts, and vehicle swaps. Real‑time routing and re‑routing must apply quickly across a whole shift window. This aligns with the documented focus on optimized routing, ETS operation cycles, and dynamic route optimization for conditions like monsoon disruptions.
Fast, reliable search and filtering is essential for handling exceptions. Planners need instant search across employee name, ID, route, shift time, hub, and vendor, plus filters for “unassigned,” “at‑risk for OTP,” or “escort required.” This supports centralized command‑center operations, live tracking, and SLA governance mentioned across the command centre and dashboard collateral.
Clear visualization of changes is critical for trust. Planners need a clear “before/after” view when late changes are applied. They need to see which employees moved routes, which vehicles changed, and how seat fills, dead mileage, and OTP risk are affected. This mirrors the emphasis on audit trails, ETS operation flows, deviation reports, and data‑driven insights.
To validate usability with real planners, operations leaders should avoid generic UI walkthroughs and instead run scenario‑based validations:
- Recreate one full live shift: Import yesterday’s roster, then apply today’s known changes (no‑shows, last‑minute overtime, new hires) while timing how long planners take to stabilize routes.
- Run stress tests around known pain windows: Night shifts for women, monsoon days, or days with political events, mirroring the case study on monsoon routing and the business continuity plans.
- Observe actual command‑centre workflows: Sit planners at the console during peak rostering hours and track how many actions stay digital versus reverting to side Excel sheets, calls, or manual notes.
- Check error recovery: Deliberately inject bad data or simulate GPS downtime and see how quickly planners can detect and correct routes using the interface alone.
A system that passes these tests will usually reduce escalations, lower manual override, and better support the centralized command‑center, BCP, and safety frameworks described in the context.
images:
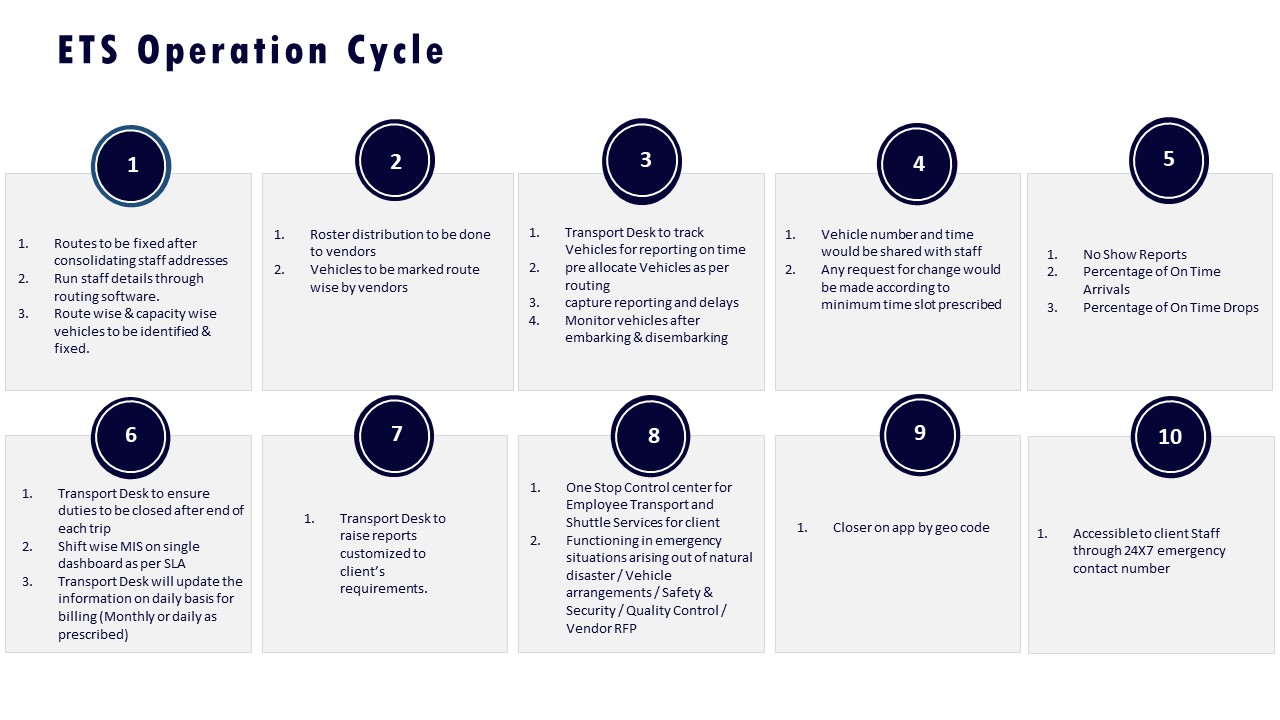
How do we stop exception creep—where every last-minute change is treated as urgent—so routing doesn’t become nonstop manual triage and burn out the team?
B1171 Preventing exception creep and burnout — In India shift-based Employee Mobility Services, how can an operations manager prevent ‘exception creep’ where every late change becomes ‘urgent’ and routing and rostering turns into constant manual triage, undermining dynamic recalibration and exhausting the team?
In shift-based employee mobility in India, operations managers prevent “exception creep” by codifying what counts as a true exception, enforcing windowed cut‑offs in the EMS platform, and routing all changes through a governed command-center workflow with clear SLAs and consequences. This converts constant ad‑hoc requests into a predictable queue that dynamic routing can absorb, instead of letting manual triage become the default operating mode.
Exception creep usually starts when hybrid attendance, last‑minute shift changes, and VIP requests bypass the standard EMS operation cycle. Operations teams then override the routing engine, push manual rosters, and abandon seat‑fill and dead‑mileage controls, which destroys On‑Time Performance (OTP%) and burns out dispatchers. A centralized command center and Transport Command Centre model helps here by acting as a single window for change requests, with alert supervision, escalation matrices, and clear ownership for approvals and denials.
To keep control while remaining flexible, most high‑maturity teams hard‑wire a few guardrails into their EMS/Commutr stack and SOPs:
• Define exception categories and approval rights in advance.
• Set time‑band cut‑offs for roster changes and ad‑hoc trips, visible in the employee app.
• Lock routing after a defined “freeze” time, with only safety‑critical overrides allowed by a higher role.
• Measure and publish exception volume, OTP%, and Trip Fill Ratio by business unit to create accountability.
This approach protects dynamic route recalibration, keeps the routing engine in charge rather than WhatsApp calls, and lets the operations manager move from 2 a.m. firefighting to early‑warning and data‑led planning.
images:


What visibility do managers need to explain route or pooling changes to employees, so they don’t escalate every complaint to HR or transport?
B1172 Manager visibility for route changes — In India corporate Employee Mobility Services routing and rostering, what kinds of reporting or transparency do middle managers need so they can confidently explain to employees why a route or pooling decision changed—without escalating every complaint back to HR or the transport desk?
In Indian corporate employee mobility, middle managers need simple, defensible visibility into routing logic, SLA performance, and safety/compliance constraints so they can explain “why this route looks like this today” without reopening the design every time someone complains. They do not need the full routing engine, but they do need human-readable reasons, trend views, and clear exception channels.
Middle managers gain control when each trip or route has an accessible “decision story” attached. That story should show the shift window, seat-fill and pooling logic, guard or escort rules for women, and EV or diesel allocations if ESG rules shaped the route. When managers can point to these explicit rules, complaints become conversations about policy, not arguments about favoritism or “bad planning.”
The most useful transparency is operational and pattern-based, not raw data dumps. Managers need OTP and exception dashboards at team or process level, with clear flags such as chronic late pickups, repeated address-change requests, or employees repeatedly declining pooled cabs. This aligns with centralized NOC monitoring and route-adherence audits, but at a “manager view” that translates technical KPIs like Trip Adherence Rate into simple, people-facing explanations.
To avoid every complaint bouncing to HR or the transport desk, middle managers also need a clear, narrow lane for what they can and cannot change. That lane is defined by simple SOPs: when they may request a routing override, how many days’ notice is required for a permanent stop change, and which issues must go back to the command center because they touch safety, compliance, or women’s night-shift rules.
Useful reporting and transparency elements for middle managers typically include:
- A per-shift roster view that shows which employees are pooled together, which vehicle is allocated, and the planned ETA at each stop.
- A “why this route” summary that lists core constraints considered by the routing engine, such as shift start cut-off, seat-fill targets, dead-mile caps, female-first routing rules, and any EV utilization or emission target, presented in plain language.
- Simple EX-focused metrics at team level, such as OTP, no-show rates, and complaint closure SLAs, tied to each route cluster, so managers can distinguish systemic issues from isolated incidents.
- Named safety and compliance indicators, such as whether a guard or escort is scheduled, whether driver credentials and vehicle fitness are current, and whether a given route has any geo-fencing alerts or incident history that justify stricter rules.
- Clear exception workflows, with ticket numbers and timestamps, that show when an employee request has been logged with the transport command center, the expected resolution time, and the final decision.
When these elements are exposed through a manager-friendly dashboard or periodic roster report, middle managers can answer most “why did my route change?” questions with evidence instead of escalation. This reduces noise for HR and the transport head, and it reinforces a sense of predictable, policy-driven governance for employees who are living with daily routing and pooling decisions.
For our shift commute routing and rostering, how can we tell if the real problem is the way we build routes/rosters (shift windows, clustering) rather than driver issues or vendor shortages?
B1173 Diagnose rostering vs supply issues — In India corporate Employee Mobility Services (EMS) shift-based routing and rostering, how do I diagnose whether our current shift windowing and clustering logic is the real cause of daily "fire-fighting" (late pickups, missed drops, constant manual edits), versus vendor capacity or driver behavior?
In corporate Employee Mobility Services in India, organizations can separate routing logic issues from vendor capacity or driver behavior by correlating patterns in late pickups, missed drops, and manual overrides with route design metrics, shift-window assumptions, and fleet utilization indicators. The core diagnostic principle is that routing and shift-windowing failures show up as structural, repeatable patterns across routes and days, while vendor or driver issues appear as localized, capacity or behavior-driven exceptions.
Routing and shift-windowing are usually at fault when delays cluster around specific shift start and end times, fixed route patterns, or particular campuses or zones. Daily “fire-fighting” indicates routing gaps when manual roster edits become the default for particular timebands, when dead mileage is consistently high, or when trips frequently violate realistic travel times under known traffic conditions, especially in congested or monsoon-affected cities. In the Mumbai monsoon case, dynamic route optimization with real-time communication enabled a 98% on-time arrival rate and a 10% increase in customer satisfaction, which demonstrates that smarter routing and realistic ETAs can materially reduce firefighting even under adverse conditions.
Vendor capacity or driver behavior are more likely to be the primary causes when OTP degradation maps to specific vendors, depots, or driver cohorts despite stable routing assumptions. This includes recurring no-shows by certain drivers, vehicle uptime problems within a particular fleet, or capacity shortfalls during specific projects where rapid fleet mobilization was promised but not delivered. Organizations can use fleet uptime, Vehicle Utilization Index, Trip Adherence Rate, and no-show reports to see whether vehicles and drivers are actually available and compliant when and where the routing engine expects them to be.
A practical diagnostic SOP that supports the transport head and centralized command center is to review OTP%, Trip Adherence Rate, Trip Fill Ratio, and exception-closure times by: shift window, route cluster, vendor, and driver. If problems are strongly correlated with particular time windows, seat-fill targets, or unrealistic buffer times, the shift windowing and clustering logic need redesign. If problems are instead concentrated around specific suppliers, garages, or driver groups under otherwise stable routes, then vendor governance, driver training, and fleet compliance need deeper intervention.
In our commute routing, what are the quick signs that our seat-fill targets are unrealistic and causing longer routes and more complaints?
B1174 Spot bad seat-fill targets — In India corporate employee transport (EMS) routing and rostering, what are the simplest, operator-friendly signals that our seat-fill targets are set wrong and are creating avoidable detours, longer ride times, and employee complaints?
Most operators can tell seat-fill targets are set wrong when on-time performance drops, routes start to look “illogical” on the map, and floor-level complaints spike even though fleet size and demand have not changed. High seat-fill targets usually create avoidable detours and long ride times, while very low seat-fill targets create too many vehicles and cost pushback, so the earliest signals show up in basic ops and employee behaviour long before in dashboards.
A common early signal is when trips still meet average seat-fill goals on paper, but trip-level routing becomes convoluted. Operators see cabs looping back, zig-zagging between distant clusters, or mixing early and late shift windows in the same route. This usually coincides with rising average ride times for a subset of employees who are consistently first pick-up or last drop. Those employees start complaining to managers or skipping the official transport, which shows up as higher no-show rates or ad-hoc cab claims, even though rostered headcount is stable.
Another operator-friendly signal is a divergence between command-center observability and what the shift floor reports. The command center might see acceptable Trip Fill Ratio and cab utilization, but site teams report more exceptions, reactive rerouting, and last-minute driver or escort fatigue issues. In practice, EMS operations that push seat-fill too hard tend to see dead mileage fall only slightly, while exception-handling workload and escalation frequency rise sharply. When routing and rostering are calibrated correctly, central NOC teams spend more time on predictive adjustments and less time firefighting detours or manually splitting overloaded routes.
Operational teams should watch a few simple patterns together rather than in isolation: - OTP for first and last trips in each shift band starts slipping, even if mid-band trips look fine. - A small but persistent cluster of routes shows ride times that are much longer than the median for that origin–destination pattern. - Extra buffer vehicles are being dispatched more often to “rescue” over-packed or delayed routes, despite nominally high seat-fill metrics. - Employee satisfaction with transport drops in specific locations or timebands, not uniformly across the program, suggesting over-aggressive pooling in those windows.
When these patterns appear together, most operators can safely assume that seat-fill thresholds and routing rules are too aggressive for current traffic, attendance variability, and safety constraints. Adjusting seat-fill targets by shift window and by location, rather than chasing a single global number, usually restores balance between utilization, detours, and commute experience in Indian EMS environments.
How can we measure and show the time wasted on manual roster changes so Finance and Procurement take it seriously?
B1175 Quantify manual rostering toil — In India corporate Employee Mobility Services (EMS) routing and rostering, how should a Facilities/Transport Head quantify "toil" from manual roster edits (last-minute adds/drops, address changes, no-shows) in a way that is credible to a CFO and Procurement during evaluation?
Quantifying routing/rostering “toil” is most credible when the Facilities/Transport Head converts manual edits into a small set of repeatable, auditable operational KPIs, then links those KPIs to cost, risk, and service impact. Toil becomes a measurable volume of exception-handling work, not a vague complaint about being “overloaded.”
A practical approach is to treat every manual roster intervention as an exception event and to log it systematically. Each exception log entry should capture the trigger type such as last-minute add or drop, address change, or no-show, the time-band such as peak shift or night shift, the handling time in minutes, and the operational outcome such as extra km, vehicle swap, late pickup, or driver overtime. Over a few weeks, the exception log can be summarized into an “exception rate per 100 trips” and “average handling time per exception” which are both defensible and comparable.
The Facilities/Transport Head can then derive a small metrics pack for CFO and Procurement. One metric is incremental labor hours spent on exception handling per month, which ties directly to additional FTE or overtime cost in the transport desk or command center. A second metric is incremental dead mileage or extra km driven due to re-routing and vehicle reassignment, which translates into measurable cost per kilometer increases and higher fuel or EV energy spend. A third metric is the impact on on-time performance and service reliability, expressed as the share of late pickups or drops triggered by last-minute manual changes.
To keep this credible in evaluation discussions, the Transport Head should present before-and-after snapshots around any routing automation. One snapshot can show trips per planner per shift, exception events per 100 trips, and average exception handling time when rostering is mostly manual. The comparative snapshot can show the same KPIs after introducing automated routing and HRMS-linked rostering, highlighting reductions in exception counts, dead mileage, and overtime exposure. This ties directly to buyer priorities like cost per employee trip, on-time performance, and SLA breach rate.
A short supporting narrative can then explain how high exception rates amplify fatigue and error risk at the command center, especially in night-shift operations. This connects manual toil to safety, compliance, and business continuity concerns that matter to Procurement, HR, and Security, but without relying on soft arguments. The combination of exception logs, derived unit-cost impact, and changes in on-time performance gives the CFO and Procurement a hard, repeatable view of toil that fits into outcome-linked procurement and SLA design.
With hybrid attendance changing daily, how do we balance stable routes with the need to adjust capacity without hurting on-time performance?
B1176 Stability vs hybrid elasticity — In India corporate employee commute programs (EMS), when hybrid attendance changes daily, what routing and rostering practices help avoid overreacting (constant reroutes) while still handling real demand elasticity without breaking shift OTP?
In Indian EMS programs with volatile hybrid attendance, the most effective practice is to lock routing and rostering into clear “decision windows” per shift and only allow controlled recalculation inside those windows based on defined thresholds. This stabilizes daily operations while still absorbing real demand changes and protecting OTP.
A stable shift backbone works best when transport teams design route plans around fixed shift windows, seat-fill targets, and dead-mileage caps, then treat employee bookings and cancellations as inputs to those windows instead of live, continuous triggers. Dynamic route recalibration is then reserved for exceptions that breach pre-agreed thresholds, such as sudden no-show spikes on a hub, safety-related rerouting, or EV range and charging constraints on specific corridors.
Command centers gain control when they combine three elements. They use hybrid-work-aware rostering rules linked to HRMS so that default rosters and minimum guaranteed capacity per site are known 12–24 hours ahead. They enforce playbooks on when to re-route (for example, time cut-offs before shift start, maximum allowed change per vehicle, and escalation to on-ground supervisors for last-minute manual adjustments). They monitor OTP%, Trip Adherence Rate, and Vehicle Utilization Index in real time, but trigger routing changes only when these KPIs indicate a genuine pattern, not isolated noise.
The trade-off is clear. Tighter, algorithmic routing with aggressive continuous recalculation can improve seat-fill and cost per employee trip, but it increases operational volatility and driver fatigue. A windowed approach with explicit buffers, escalation matrices, and dynamic routing only for threshold-breaching events slightly relaxes theoretical optimization but sharply reduces control-room firefighting, protects OTP in peak and night bands, and keeps the system predictable for drivers and employees.
What real on-ground constraints usually break the ‘perfect’ clustering, and how do teams bake those into rosters without making them unmanageable?
B1177 Encode real-world routing constraints — In India corporate EMS routing and rostering, what are the real-world constraints that typically break "optimal" clustering (gated communities, security checkpoints, one-way roads, pickup punctuality windows), and how do experienced operators encode them without making the roster impossible to manage?
In India corporate employee mobility routing and rostering, “optimal” clustering usually breaks on hyper-local ground constraints that a pure VRP algorithm does not understand. Experienced operators keep routing stable by explicitly encoding these constraints as simple, rule-based inputs to the routing engine and command-center SOPs, and by limiting how many such rules are allowed per cluster or shift window.
Common real-world breakers include gated communities with long gate-in times, park-and-walk campuses, one-way or no-entry stretches, recurring choke points, and security checkpoints near SEZs or tech parks. Night-shift women-safety rules, escort requirements, and strict pickup punctuality windows add another layer, especially for hybrid rosters where attendance changes late. In practice, these issues surface as OTP drops, dead mileage spikes, and driver fatigue if they are not codified up front in the ETS Operation Cycle and command center playbooks described in the context.
Experienced EMS operators in India handle this by treating each such constraint as a small, tagged rule in the routing layer and in the transport desk SOP, rather than as ad-hoc exceptions. For example, they pre-tag high-friction locations with minimum buffer times and fixed approach routes, define timeband-based no-go roads and diversions, and mark female-first, escort-mandatory, or high-risk stops for special sequencing. They then use a centralized command centre or Transport Command Centre to enforce seat-fill targets, dead-mile caps, and on-time performance while still allowing dispatchers manual override when GPS, apps, or local conditions fail.
To keep the roster manageable, mature operators put hard boundaries around complexity. They cap maximum stops per route and maximum spread of a cluster, define a limited set of standard route archetypes per shift, and restrict manual edits to late-stage tweaks, not full redesign. They also push some complexity into commercial models and SLAs, using buffers in promised pickup windows and outcome-based KPIs like OTP%, Trip Adherence Rate, and Trip Fill Ratio, instead of chasing mathematically perfect but operationally brittle plans.
images:
If pooling and clustering make some employees travel longer to fill seats, how do we define fairness and avoid HR blowback?
B1178 Fairness trade-offs in pooling — In India corporate Employee Mobility Services (EMS) routing and rostering, how do HR and Operations decide what "fair" means when clustering logic increases some employees’ ride time to improve seat-fill, and what questions should HR ask to avoid a morale backlash?
In Indian corporate employee mobility, “fair” routing is usually defined as a balance between three non‑negotiables: safety compliance, shift adherence, and a reasonably consistent commute burden across comparable employees. Clustering logic that improves seat‑fill is treated as acceptable only if it does not create systematic disadvantage for specific groups, does not breach safety norms, and is transparent and explainable to employees.
HR and Operations typically converge on fairness by looking at shift windows, maximum allowable ride time bands by zone, and duty‑of‑care rules for women’s safety and night shifts. Fairness tends to fail when routing decisions are seen as purely cost‑driven, when some employees repeatedly get the “long tail” rides, or when there is no clear escalation path to correct chronic routing pain points.
To avoid morale backlash when adopting more aggressive clustering and seat‑fill optimization, HR should explicitly ask:
- Ride‑time limits and consistency
- What is our maximum acceptable in‑cab time by zone and shift, and how often will we breach it to improve seat‑fill?
- Which employees or locations are consistently in the top decile of ride duration, and how will we correct patterns where the same people always bear the longest routes?
- Safety and compliance guardrails
- Does the routing engine ever trade off women‑safety protocols, escort rules, or approved route corridors in order to increase seat‑fill?
- Are night‑shift women employees getting materially longer detours than day‑shift peers, and is this visible in a compliance or safety dashboard?
- Policy clarity and communication
- Is there a written commute policy that defines acceptable ride‑time ranges, priority rules (e.g., women‑first at night), and how optimization works in simple language?
- How will we explain longer routes to employees in ways that feel transparent rather than arbitrary, and who owns that communication—HR or Transport?
- Data, grievances, and course‑correction
- What reports do HR and Transport review jointly (OTP, average ride time by route, complaint patterns) to detect when “optimization” is turning into perceived unfairness?
- Is there a documented grievance and escalation path specific to routing discomfort, and how quickly do we commit to re‑routing when the same employee raises repeated concerns?
- Equity across personas and locations
- Are certain bands (junior staff, BPO floors, contract workers) seeing systematically longer pooled routes than senior or core employees on the same shift?
- How are we handling employees in remote or low‑density areas—are they always first pick‑up/last drop, and do we have alternatives (feeder points, allowances) for them?
When HR and Operations define these thresholds up front, convert them into routing rules and dashboards, and keep a clear employee‑facing narrative, they can improve seat‑fill and cost without eroding trust or commute experience.
What cutoff times and approval rules for late changes actually reduce roster chaos without making teams feel we’re saying ‘no’ all the time?
B1179 Late-change governance rules — In India corporate EMS routing and rostering, what late-change handling policies (cutoff times, approval rules, exception categories) reduce last-minute roster churn without making business teams feel blocked?
In India EMS routing and rostering, late-change handling works best when organizations define clear time cutoffs by shift window, a small set of business-justified exception categories, and a visible approval/escalation path that operations can actually execute at night. Policies that reduce last-minute churn usually combine earlier default cutoffs for auto-scheduling with a tightly-governed “late change corridor” that remains open for real business needs, rather than a hard lock.
A stable pattern in mature EMS programs is to fix a roster-freeze time per shift window and align it with routing and vendor dispatch cycles. Earlier freezes improve route optimization, driver allocation, EV charging and guard planning, but they also increase pressure on business teams. The gap is typically bridged by keeping a controlled late-change window with smaller seat-pools and explicit trade-offs on OTP and vehicle pooling.
Late-change handling policies are most effective when they distinguish between a short, named list of exception types and generic “convenience” changes. Common exception categories include urgent business continuity needs, security or women-safety led routing changes, medically-justified changes, and system or vendor failures. Everything outside these categories is processed after a defined cutover, so the routing engine and command center are not constantly destabilized.
Approval rules work best when simple, role-based, and time-banded. Routine changes before roster-freeze can be self-service for employees and managers. Changes inside the late-change corridor usually require manager or functional approval logged in the EMS platform, and changes inside a final “red zone” before shift start often need CHRO, Security, or business continuity sign-off. This protects transport teams from blame when they enforce cutoffs and provides audit trails for HR and EHS.
Transport heads benefit when the NOC and routing engine are configured to show late-change load separately from base demand. This separation allows them to defend OTP and cost metrics by showing what was planned versus what was injected after cutoffs. It also supports outcome-based contracts with vendors, so penalties are not unfairly applied for late-approved roster churn.
To make these policies feel enabling rather than blocking, organizations typically communicate them as part of shift and attendance policy, link them to measurable benefits like higher OTP and safer routing, and give business teams dashboards that show the impact of late changes on cost and reliability. Regular reviews with HR and line managers help refine cutoffs and exception thresholds so the system remains firm enough for operations but flexible enough for genuine business urgency.
governance, ownership & ROI validation
Clear ownership and governance for editable rosters, cross-functional trade-offs, and proof of toil reduction; ensure leadership has a defensible, auditable plan.
When business teams demand exceptions that break routes, how do we set approvals so the roster doesn’t collapse and ops isn’t blamed?
B1180 Control VIP-driven exceptions — In India corporate employee transport (EMS) routing and rostering, when a VIP or critical team requests exceptions that break clustering logic, how should Operations structure exception approvals so the roster stays coherent and frontline coordinators don’t get blamed?
In enterprise employee transport in India, VIP and critical-team exceptions need a formal exception-approval lane with clear rules, not ad-hoc overrides into daily routing. A structured, tiered approval flow, codified in SOPs and visible in the routing tool, keeps the roster coherent and prevents frontline coordinators from being blamed for last-minute deviations.
Operations teams benefit when exceptions are treated as a defined “policy object” in EMS, similar to escort rules or women-first policies, rather than as manual favors. Exception requests should be raised in a standard format, tagged with reason and timeband, and approved only by designated stakeholders such as HR or business leaders, not by shift coordinators. A key protection is that routing engines and rostering logic should surface the cost and impact of each exception in real time, including dead mileage, seat-fill loss, and risk to on-time performance, before it is granted.
A simple three-lane model can reduce firefighting for the Facility or Transport Head:
- Pre-approved exception windows. Certain VIP teams, critical functions, or project phases get pre-defined entitlement rules that routing respects automatically, so coordinators are following policy, not improvising.
- Controlled real-time overrides. Same-day VIP exceptions require approval at a clearly defined level, and the routing or command center logs the decision with a traceable audit trail.
- Post-facto visibility. Every exception appears on a daily EMS command-center dashboard as an exception flag with its operational and cost impact, so leadership sees the trade-offs behind “special” trips.
When exception paths are explicit, logged in the NOC or command center, and integrated with EMS routing tools, daily rosters remain algorithmically coherent. Frontline coordinators can point to an auditable chain of decisions instead of absorbing blame for VIP-driven breaks in clustering logic.
On a bad day with absences and delays, what should an editable roster let us do quickly—and still keep a clean record instead of WhatsApp chaos?
B1181 Editable rosters for bad days — In India corporate EMS routing and rostering, what does an "editable roster" need to support on a bad day (multiple late logins, sudden absenteeism, traffic disruption) so changes are fast and auditable instead of ad hoc WhatsApp instructions?
An editable roster in Indian corporate EMS must support controlled, role-based “live edits” with full audit trails, so transport teams can reassign vehicles, resequence pickups, and add or drop employees in minutes without resorting to informal channels. The same roster must stay tightly linked to HRMS attendance, driver apps, and command-center monitoring so every change is visible, timestamped, and SLA-accountable rather than buried in WhatsApp chats.
On a bad day with late logins, no-shows, and traffic disruptions, the editable roster needs structured change actions instead of free-form edits. Each action should be a defined operation like “swap cab,” “merge route,” “add backup vehicle,” or “shift employee to next slot,” with the system recalculating ETAs, cost per trip, and seat-fill. Command-center tools like WTi’s centralized dashboards and alert supervision models show how live route changes and exception handling can be driven from a single window rather than fragmented communication.
Every modification should generate an audit record that captures who changed what, when, and why, with links to trip logs, GPS traces, and SOS or safety conditions. This aligns with continuous assurance expectations, SLA governance, and compliance dashboards described in the industry brief. Visibility for HR, Security, and Finance depends on this auditability, because it ties real-time firefighting back to OTP, safety compliance, and billing accuracy.
To reduce 2 a.m. firefighting, an effective editable roster will also surface decision support signals such as predicted delays, buffer vehicle availability from business continuity plans, and EV battery or charging status where fleets are electrified. These signals allow the transport head to act early using SOP-backed options rather than improvising changes that cannot be reconstructed later during audits or incident reviews.
How can Finance check that changes to routing/rostering are truly cutting cost per trip, not just creating more exceptions and hidden manual work?
B1182 Finance validation of routing ROI — In India corporate employee mobility (EMS), how can a CFO validate that routing and rostering changes (seat-fill, shift windowing, clustering) are actually reducing cost-per-trip rather than just shifting costs into more exceptions and manual coordination?
A CFO can validate EMS routing and rostering savings only by tying every “optimization” (seat-fill, shift windowing, clustering) to a stable, auditable cost-per-trip baseline and to exception metrics that sit in the same data model. Cost claims are credible when reductions in Cost per Employee Trip (CET) and Cost per Kilometer (CPK) move in the right direction while dead mileage, exception volume, and manual interventions do not silently rise.
A defensible approach starts with a frozen baseline period. Finance teams should lock CET, CPK, Trip Fill Ratio (TFR), Vehicle Utilization Index, and dead mileage using reconciled trip logs and billing. This baseline must be traceable from vendor GPS data and ETS/EMS reports into the billing system, not just vendor spreadsheets, so later comparisons survive audit scrutiny.
Routing and rostering changes should then be introduced as time‑boxed experiments. Each change must be tagged in the ETS operation cycle and in the mobility data lake as a dated “policy version” so Finance can compare before/after windows. The CFO can insist that every optimization be evaluated against a small, fixed KPI set: CET, CPK, dead mileage, Trip Adherence Rate (TAR), On‑Time Performance (OTP%), and exception→closure times.
A common failure mode is that aggregated savings mask operational stress. A CFO should therefore watch three red-flag patterns alongside cost: rising no-show rates, increased manual rerouting by the Transport Command Centre, and growth in ad‑hoc or off‑platform trips. If total trip volume and seat‑fill improve but off‑contract usage or manual overrides rise, the program is shifting cost, not reducing it.
In practice, the CFO’s best safeguards are standardized, tech-based, measurable, and auditable performance reporting, plus outcome‑linked contracts. Payments should be indexed to OTP, seat‑fill, and CET, with clear rules that disallow billing for trips lacking GPS-backed trip ledgers or deviating beyond dead-mile caps. This keeps routing and rostering optimization from turning into an unseen increase in exceptions, vendor negotiation, and back-office effort.
What are the usual ways seat-fill or clustering KPIs get dressed up in reports, and what evidence should we ask for to keep it honest?
B1183 Prevent KPI gaming on seat-fill — In India corporate EMS routing and rostering, what are the most common ways vendors "game" seat-fill targets or clustering KPIs in reports, and what should Procurement ask for so the measurement reflects operational reality?
Most EMS vendors in India game seat-fill and clustering KPIs by redefining what counts as a “seat,” a “trip,” or a “route” so that the math looks efficient even when operations are wasteful. Procurement needs to lock definitions, link KPIs to raw trip and roster data, and insist on audit-ready evidence from the routing engine and NOC so reported ratios match how employees actually travel.
Vendors often inflate seat-fill by merging short segments or partial overlaps into one “route” on paper. Vendors also create micro-routes with very small detours so each cab looks “clustered,” while dead mileage and under-filled runs still exist but sit outside the reported KPI definition. Another pattern is counting cancelled or no-show bookings as “planned seats” in the denominator, which makes the algorithm look efficient although employees did not ride.
A common failure mode is reporting route or cluster KPIs aggregated over a day or month without exposing shift-window-level data. This hides peak-shift underutilization and masks routing that is manually overridden by supervisors. Vendors also cherry-pick time bands or geographies to publish only high-performing windows, which breaks comparability across locations.
Procurement should demand clear definitions for seat, seat-km, trip, rostered employee, and route. Procurement should also require access to anonymized trip-level logs with timestamps, GPS traces, and roster IDs so seat-fill and clustering can be recomputed independently. It is important to insist that outcome-linked commercials (like payments indexed to seat-fill) use these standard definitions, are calculated per shift window, and are subject to periodic route adherence audits with random samples. This approach aligns EMS KPIs with actual employee movement patterns, fleet utilization, and dead mileage, and it reduces the scope for vendors to manipulate seat-fill metrics in isolation from operational reality.
How should IT test that dynamic rerouting works during peak shifts without lag or mismatched rosters for different users?
B1184 Test peak-time recalibration reliability — In India corporate Employee Mobility Services (EMS) routing and rostering evaluations, how should IT test whether dynamic recalibration can run reliably during peak shift times without lag, app timeouts, or partial updates that create inconsistent rosters across users?
IT teams should test EMS dynamic recalibration under controlled peak-load simulations that mirror real shift windows, while instrumenting latency, failure, and consistency metrics across the routing engine, command-center tools, and driver/employee apps. The objective is to prove that route recalculation, manifest sync, and notifications complete within agreed SLAs and that every stakeholder view (NOC, driver, rider, HRMS) converges to the same trip state without manual correction.
IT should first define “peak” technically. This definition should include concurrent shift windows, maximum expected booking changes, and worst-case traffic conditions that trigger dynamic route recalibration. IT can then construct synthetic but realistic loads using test users, dummy routes, and staging integrations to HRMS and vendor systems. A stable routing engine must handle bursty roster changes without causing app timeouts or long ETA computation stalls.
A critical test dimension is observability across the trip lifecycle. IT should verify that the NOC dashboard, driver app, and employee app all receive the new roster and pickup sequence after a recalculation. Any mismatch here indicates partial updates. Consistency checks should include OTP validity, manifest alignment, and route adherence audit readiness.
IT should also inject controlled failures during tests. These failures can include brief network drops, degraded GPS signals, or delayed HRMS roster feeds. A robust EMS setup will degrade gracefully. It will queue or retry recalculations and prevent users from seeing half-updated routes. Recovery behavior is as important as happy-path performance.
Key practical test criteria include: - Maximum recalculation time per batch of route changes during peak windows. - End-to-end time from recalculation trigger to all apps reflecting the new roster. - Rate of stale or conflicting trip states detected in route adherence audits. - Command-center ability to override or lock routes when instability is detected.
Images:

What checklist can we use to confirm the system handles multiple sites and shift timebands cleanly—no overlapping manifests or driver confusion?
B1185 Multi-site shift windowing checklist — In India corporate EMS routing and rostering, what operational checklist should a Transport Head use to evaluate whether the system supports shift windowing across multiple sites and timebands without creating overlapping manifests and driver confusion?
A Transport Head should use an operational checklist that tests how the EMS routing and rostering system handles shift windowing, site segregation, and manifest clarity across all timebands, and that verifies whether command-center visibility, compliance controls, and driver tools prevent overlap and confusion.
Shift windowing and site logic
The checklist should confirm that shift configurations allow distinct windows per site and business unit. It should verify that the routing engine respects those shift windows when clustering employees and assigning vehicles. It should check that routes do not mix incompatible sites or plants in a way that breaks shift adherence.
Manifest generation and change control
The Transport Head should verify that each trip has a unique ID, a single, final manifest, and clear version control. The checklist should include checks that last-minute roster edits trigger controlled re-routing rather than creating duplicate or overlapping trips. It should confirm that exception handling and no-show handling are visible in a centralized dashboard.
Driver-facing controls and command-center visibility
The checklist should include verification that driver apps show only one active duty slip at a time. It should confirm that the system enforces route adherence through GPS tracking, geo-fencing, and command-center alerts. It should ensure that the central command center and location-specific control desks see all trips by site, timeband, and vehicle, which reduces conflicting instructions.
Compliance, safety, and reporting
The Transport Head should confirm that women-safety routing rules, escort policies, and night-shift limits are enforced within each shift window. The checklist should include audit trail integrity checks for trip logs, deviation reports, and incident response. It should also ensure that indicative management reports and dashboards can surface overlapping allocations, dead mileage, and Trip Adherence Rate to support continuous improvement.
If there’s a big disruption during night shift (rain, closures), what should the routing/rostering system let us do to stabilize fast without rebuilding everything?
B1186 Disruption handling without reroster — In India corporate employee transport (EMS), when a sudden weather event or citywide disruption hits during night shifts, what should routing and rostering support look like so Operations can stabilize the plan quickly without restarting the whole roster?
In India EMS night shifts, routing and rostering support should enable partial, real-time recalibration of affected routes and cabs while preserving the rest of the roster unchanged. The transport command center needs tools and SOPs that allow dynamic re-clustering, rerouting, and resequencing only in impacted zones, backed by live GPS, traffic, and alert feeds so operations can stabilize within minutes instead of rebuilding the shift plan from scratch.
A practical model keeps a pre-optimized baseline roster and uses a 24x7 command center as the control room. When monsoon flooding, political bandh, or infrastructure failure hits, the command center relies on dynamic route optimization and real-time communication, as shown in the Mumbai monsoon case with 98% on-time arrival and 10% satisfaction lift. The system should support rapid reallocation of vehicles, insertion of standby cars, and localized diversion rules while locking “green” routes that are still viable so the entire shift does not collapse.
A common failure mode is all-or-nothing re-routing, where dispatch tries to rebuild every route, creating new delays and confusion. A more resilient approach uses pre-defined playbooks and tech that supports zone-based overrides, escort and women-safety rules, and automatic ETA recalculation. Alert supervision, geo-fence violation monitoring, and SOS channels must stay active so security and HR have evidence and can communicate realistic ETAs, rather than escalating blame to the transport head.
Key capabilities that make life easier for Operations include: - Zone or cluster-level rerouting instead of global re-plan. - Standby fleet buffers and pre-approved alternate pickup points. - Command-center dashboards that overlay live disruption data on existing rosters. - Integrated driver and employee apps for instant trip updates, with audit trails for OTP, route adherence, and incident logs.
How can HR judge if new clustering will actually reduce escalations, not just change the type of complaints we get?
B1187 HR escalation risk from clustering — In India corporate EMS routing and rostering, how should a CHRO evaluate whether the proposed clustering logic will reduce HR escalations (complaints, grievance tickets) or just move them from "late pickup" to "unfair routing" complaints?
A CHRO should treat EMS clustering logic as a hypothesis that must be tested against HR‑type outcomes, not just routing efficiency, and should demand data that links the proposed clusters to on‑time performance, seat‑fill, safety rules, and grievance patterns. The key test is whether the clustering model can be tuned and governed using HR‑visible metrics like OTP%, complaint types, and women‑safety compliance, instead of being a fixed “black box” that only optimizes kilometers.
A common failure mode is when clustering minimizes distance and fleet cost but ignores employee experience signals. This often improves late‑pickup metrics while creating new “unfair routing” complaints, longer in‑vehicle times for some cohorts, or anxiety around night‑shift drop sequences. Most organizations see this when clustering logic is designed purely by transport or tech teams without CHRO‑aligned guardrails and grievance feedback loops.
To avoid this, CHROs should push for a few concrete checks before sign‑off:
- Ask for side‑by‑side simulations that show, for representative shifts, how many employees get earlier departures, longer ride times, or changed first/last drop positions under the new clustering versus current practice.
- Insist on explicit policy constraints inside the routing engine, such as maximum ride time by route, women‑first or last‑drop rules by timeband, escort requirements, and caps on re‑routing frequency per employee over a given period.
- Require that clustering outputs feed into a central command center with real‑time monitoring and incident readiness, where HR can see OTP%, no‑show rates, and route‑adherence audits correlated with complaint and grievance data.
- Demand a pilot phase where HR tracks complaint categories before and after the new logic, using structured tags like “late pickup,” “long route,” “safety concern,” and “unfair routing,” and makes continuation contingent on net reduction in total escalations, not only in one category.
- Ensure that routing logic integrates with HRMS rosters so last‑minute shift or hybrid‑work changes do not disproportionately impact certain employees or demographics, which can otherwise trigger fairness and bias concerns.
In practice, clustering reduces HR escalations when it is governed by a clear target set that includes OTP%, safety compliance, and complaint mix, and when the command center can dynamically adjust clusters based on live issues. It tends to fail when the only success metric is kilometers or fleet utilization, and when HR cannot see or veto routing rules that affect perceived fairness and duty of care.
How do we set and communicate roster change cutoffs so employees don’t feel punished but ops still gets predictable inputs?
B1188 Communicate roster change cutoffs — In India corporate EMS routing and rostering, what is the best way to set and communicate change cutoffs (e.g., T-2 hours) across business units so employees don’t feel punished while Operations gets predictable inputs?
In India corporate EMS, the most effective way to set and communicate routing/rostering change cutoffs is to define a small, fixed set of SLA-backed time windows by scenario, then hard‑code them into both policy and apps, with clear exceptions and feedback loops. This protects operational predictability while making the rules feel fair and transparent for employees.
A common failure mode is treating all changes the same. Operations needs different cutoffs for scheduled bookings, late roster changes, and true emergencies. Organizations often stabilize when they define 2–3 standard windows, for example “T‑2 hours for normal shift changes” and a tighter window for night shifts or low-density routes. Transport teams then align routing engines, vendor SLAs, and driver duty cycles around these windows to avoid last‑minute manual firefighting.
Employees feel punished when cutoffs are invisible or arbitrary. Most organizations reduce this friction by embedding cutoffs directly in the employee app (with countdown timers and clear “after this time, request will be best‑effort only” messaging), mirroring the same rules in HR policy and induction, and reinforcing them via daily briefings and floor connects. EMS command centers and alert supervision systems can then focus on genuine exceptions, supported by escalation matrices and documented business continuity playbooks rather than ad‑hoc overrides.
To keep change cutoffs workable across business units, transport heads usually agree a simple, SOP-style framework:
- Define default cutoffs by site, timeband, and gender-safety rules, approved jointly by HR, Security/EHS, and Operations.
- Tag certain changes as “guaranteed” before cutoff and “best-effort” after cutoff, and ensure billing, vendor obligations, and OTP KPIs are aligned only to guaranteed changes.
- Use the EMS platform for automated enforcement and audit logs, with exception tagging for genuine emergencies, site outages, or BCP events.
- Publish a one-page “Change & Cutoff Charter” for employees and managers, showing examples (roster change vs sick leave vs critical incident) and how each is treated.
This approach turns T‑minus rules from a perceived penalty into a predictable part of the operating model. It also gives Facility / Transport Heads fewer last‑minute surprises, clearer data for route optimization, and defensible evidence for HR and leadership when escalations do occur.
After go-live, what daily/weekly routines should we run so routing and rostering don’t drift back into manual fixes?
B1189 Post-go-live rostering operating rhythm — In India corporate employee mobility (EMS), what post-go-live operating rhythm should Facilities run (daily standups, exception reviews, seat-fill vs ride-time trade-off checks) to keep routing and rostering from slowly degrading into manual work again?
A post-go-live EMS operation in India stays healthy when Facilities run a predictable, light-weight command-centre rhythm that separates daily exception control from weekly structural tuning and monthly governance. Daily checks prevent drift into chaos. Weekly reviews prevent routing logic from being overridden by ad-hoc manual fixes.
Daily rituals should focus on keeping today’s shifts clean and visible. Transport teams typically run a 20–30 minute start-of-shift standup around the routing engine’s output. They review late roster changes, high-risk routes, women night-shift clusters, and vehicles or drivers that are repeatedly breaching OTP or route adherence. They lock a “no last-minute manual route rebuild” cut-off, and treat anything after cut-off as an exception ticket, not a spreadsheet exercise.
A short mid-shift exception huddle helps avoid firefighting. Facilities review live NOC data for geofence violations, repeated ETA slippage, driver fatigue signals, and any escorts or SOS-related alerts. They decide targeted interventions such as swapping a vehicle, rerouting a specific cluster, or escalating to the vendor. This keeps the routing engine as the default source of truth and uses manual action only for documented exceptions.
Weekly, Facilities should run a structured “routing and rostering health” review. They track seat-fill, average ride-time by corridor, dead mileage, OTP%, incident logs, and no-show patterns. They explicitly discuss the seat-fill vs ride-time trade-off by corridor, and document which bands are allowed longer rides in exchange for higher pooling, and which must stay tighter because of employee profile, safety rules, or business SLAs.
Monthly, the team should hold a governance review with HR and vendors. They align on trendlines in OTP, complaints, women-safety compliance, and Route Adherence Audits. They decide changes to routing policies, fleet mix, and buffer capacity rather than allowing operators to tweak routes manually shift after shift. This formal loop prevents slow erosion back to driver-led routing.
To stop reversion to manual work, Facilities should enforce a few hard guardrails. All changes that bypass the routing engine must be logged as exceptions with reasons. Any recurring pattern of exceptions is addressed in the weekly review, not patched ad hoc. Rosters should be frozen at defined cut-off times, with clear SLAs for how late bookings or cancellations are processed. NOC dashboards should remain the single source of truth for trip status, rather than parallel WhatsApp groups or spreadsheets.
Clear SOPs for night-shift routing, women-first policies, and escort deployment should be embedded into the routing configuration. Facilities should avoid “one-off” overrides that break these rules, because each exception becomes a precedent. Driver and vendor performance discussions should use the same KPI set the routing engine optimizes for, such as OTP%, Trip Adherence Rate, and Trip Fill Ratio, so operators have no incentive to bypass the system.
Over time, this operating rhythm lets Facilities move from firefighting to early-warning mode. Real-time analytics and the command centre’s observability tools can surface anomalies before they turn into 2 a.m. escalations. When the daily standup and mid-shift huddles are disciplined, routing and rostering remain algorithmic, and manual action is reserved for genuine edge cases instead of becoming the default behaviour.
If our coordinators push back because the tool isn’t like Excel, what rollout and setup choices improve adoption without breaking the routing rules?
B1190 Adoption tactics for Excel-minded users — In India corporate EMS routing and rostering, when frontline coordinators resist a new tool because it "doesn’t look like Excel," what rollout and configuration choices typically improve adoption without compromising the integrity of shift windowing and clustering rules?
In India corporate EMS, adoption improves when the new routing tool is made to behave like Excel for coordinators while the engine quietly enforces shift windowing and clustering rules in the background. Organizations that succeed usually do not fight the “Excel habit.” They mirror its workflows, retain manual override where it is safe, and move critical constraints into locked configuration rather than day‑to‑day human judgment.
First, most teams preserve the control‑room rhythm. They keep a “roster grid” view in the tool that visually resembles an Excel sheet. They map columns to familiar fields like employee ID, shift start/end, gender, zone, and vendor, and they enable quick filters and sort. They ensure bulk actions work like copying ranges in Excel, with CSV import/export so coordinators can start in their comfort zone but land in a rules‑driven engine.
Second, routing integrity is protected by hard rules in the configuration layer. Shift windowing, seat caps, women‑first routing and escort requirements are encoded as non‑editable system policies. The tool may allow manual trip edits, but it blocks or flags any change that violates window, capacity, or compliance rules. This retains operational flexibility without re‑opening the risk of ad‑hoc Excel logic.
Third, rollout focuses on low‑risk co‑existence before cut‑over. Teams run Excel and the platform in parallel for a few weeks, compare OTP and dead mileage, and then lock the platform as the “source of truth” while still allowing exports for reporting. Coordinators are given clear SOPs: when to trust auto‑routes, when manual adjustments are allowed, and how exceptions are escalated to the command center rather than patched silently on a spreadsheet.
- Use grid‑style views, CSV import/export, and Excel‑like filters to lower resistance.
- Keep shift windows, clustering, and safety rules as locked engine policies, not editable fields.
- Permitted manual overrides must be logged, time‑stamped, and checked against compliance.
- Run parallel operations briefly, then declare the platform as the single system of record.
- Train coordinators on concrete failure scenarios (monsoon, no‑shows) using the new tool, so they see it as a faster way to do what they already do in Excel.
How should we write contract acceptance criteria for dynamic rerouting so the vendor can’t declare victory while ops still gets 3 AM calls?
B1191 Contract acceptance for dynamic rerouting — In India corporate Employee Mobility Services (EMS) routing and rostering, how should Procurement structure acceptance criteria in the contract for "dynamic recalibration" so vendors can’t claim success while Operations still gets 3 AM breakdown calls?
Procurement should define “dynamic recalibration” as a measurable, time-bound, command-center process tied to night-shift stability KPIs, not as a vague “smart routing” feature. Vendors should only be deemed successful when specific recalibration triggers, response times, and outcomes are consistently met and evidenced through auditable logs and dashboards.
Dynamic recalibration in Employee Mobility Services routing and rostering is essentially dynamic route recalibration plus exception handling under real-world disruptions. Procurement needs to hard-code when recalibration must happen (trigger conditions), how fast it must happen (SLA), and what quality bar it must hit (OTP, seat-fill, and escalation control). This constrains vendors from calling static re-routing or manual juggling “dynamic” while Transport still manages 3 AM chaos.
Practical acceptance criteria can be framed around a few clusters: - Trigger definitions. Define mandatory recalibration triggers such as last‑minute roster changes, no-shows, vehicle breakdowns, or severe traffic/weather events within defined shift windows. Each trigger should require an automated or command-center initiated recalibration event. - Response SLAs. Set maximum times from trigger detection to issuance of new routes or reassignment (for example, “within X minutes for intra-shift events”). Link these to command center operations and exception management SLAs. - Outcome KPIs. Tie payout and acceptance to night-shift OTP%, Trip Adherence Rate, and exception closure time specifically in disrupted conditions, not just on average days. If OTP collapses under defined trigger scenarios, dynamic recalibration is considered failed. - Evidence and observability. Require a route adherence audit capability, trip-level recalibration logs, and a mobility data lake or dashboard view where all recalibration events, timestamps, and outcomes are visible for audits and QBRs. - Operational integration. Specify that recalibration must be compatible with hybrid-work elasticity, HRMS-linked rosters, escort and women-safety routing rules, and business continuity playbooks, so safety and compliance are preserved during changes.
By embedding these criteria into outcome-linked procurement and Service Level Compliance, Procurement ensures that “dynamic recalibration” is only accepted when it demonstrably reduces exception latency and protects OTP and safety during real disruptions, not just when routing engines run in ideal conditions.
After implementation, what signs show our clustering and shift windows are too rigid and are causing exceptions that exhaust the night team?
B1192 Detect brittle parameters post go-live — In India corporate EMS routing and rostering, what are the operational warning signs after implementation that our clustering and shift windowing parameters are too brittle, causing frequent exceptions that burn out the night team?
In India corporate EMS operations, brittle clustering and shift-windowing usually show up as rising exception volume on night shifts, even when overall headcount and demand are stable. The core signal is that the routing engine “looks optimal” on paper, but controllers are constantly forced into manual overrides to keep OTP and safety intact.
Frequent last‑minute trip edits are a primary red flag. Transport teams see constant re‑clustering, ad‑hoc cab additions, or repeated “unmerge” of pooled routes when employees request small timing changes or when hybrid WFO/WFH patterns shift. This indicates that shift windowing is too tight around static assumptions and cannot absorb routine variability in attendance or traffic.
Another warning sign is escalating command‑center workload without a matching increase in employee volume. Night NOC teams spend more time in exception handling, escalations, and vendor calls than in proactive monitoring. Exception→closure times increase, and controllers begin bypassing automation to build manual routes they “trust,” which undermines route adherence audits and SLA governance.
Brittle parameters also surface in KPIs such as rising no‑show and partial‑fill rates on specific routes, growing dead mileage as controllers reassign vehicles mid‑shift, and more frequent safety overrides like forced escort reallocation or last‑minute driver swaps. These patterns show that clustering logic does not respect real shift windowing, guard/escort constraints, or city‑specific traffic behaviour.
Operations teams should track a few concrete signals:
- Night‑shift exception count per 100 trips rising over time despite similar demand.
- Share of routes edited or rebuilt within 60 minutes before shift start consistently high.
- Dead mileage and re‑routed kilometers growing faster than total trips.
- Controller intervention rate (manual overrides per shift) trending up, with increasing complaint and escalation volume.
How should leadership choose the main goal for routing and rostering when Finance wants higher seat-fill but HR wants shorter rides and fewer complaints?
B1193 Resolve Finance vs HR trade-offs — In India corporate employee transport (EMS), how should a senior leader decide the "north star" for routing and rostering when Finance pushes seat-fill and dead-mile reduction but HR pushes shorter ride times and fewer complaints?
The “north star” for EMS routing and rostering in India should be a reliability‑and‑safety first target, with cost (seat‑fill, dead miles) optimized under that constraint. A practical way to encode this is to fix minimum service levels for OTP, maximum ride time, and women‑safety rules, then use seat‑fill and dead‑mile reduction as secondary optimization levers inside those boundaries.
A pure seat‑fill north star often increases detours and ride times. That reduces employee satisfaction and raises safety and fatigue risks for late and night shifts. It also pushes more escalations to HR and Transport, which erodes trust in the program even if the finance metrics look good. A complaints‑only north star, on the other hand, usually leads to under‑pooled routes, higher dead mileage, and poor cost per trip, which Finance will see as leakage.
In practice, most mature EMS programs treat three objectives as “non‑negotiable rails” for the routing engine. These are on‑time performance, safety and compliance (escort rules, route approvals, women‑centric protocols), and a reasonable ride‑time cap per corridor or shift window. Once these thresholds are set, routing, rostering, and vendor allocation are tuned for higher trip‑fill and lower dead‑miles within each shift band.
A senior leader can align HR and Finance by agreeing a small set of shared KPIs. Examples are OTP%, average ride time by route type, complaint rate, trip‑fill ratio, and cost per employee trip. The command center and dashboards described in the collateral show how reliability, safety alerts, and utilization can be monitored together, with escalation matrices and BCP plans handling disruptions before they become HR incidents or Finance surprises.
What controls stop last-minute edits from turning into a shadow process that ruins the planned routes?
B1194 Prevent shadow rostering processes — In India corporate EMS routing and rostering, what practical controls help prevent constant last-minute roster edits from becoming an unofficial "shadow process" that undermines the planned clustering logic?
Practical controls that limit “shadow” last‑minute roster edits in Indian corporate EMS are those that force all late changes back into a governed, tech-visible workflow and tie them to clear cut-off rules, approval paths, and SLAs. Controls work when rostering, routing, command-center operations, and HRMS integration run off a single platform with auditable logs instead of ad-hoc calls and WhatsApp.
A common failure mode is fully optimized clustering being overridden by manual exceptions that are never recorded in the system. That failure mode is reduced when daily shift rosters come from HRMS, feed a single routing engine, and any post–cut-off change can only be raised as a structured “ad-hoc request” in the employee app or transport desk module. Shadow edits drop when the platform enforces hard time-bands for roster freeze, highlights late changes on the command-center dashboard, and routes them through a dispatcher or supervisor approval path.
Command-center supervision is critical to prevent silent manual overrides. Real-time dashboards, exception alerts, and micro command-centre workflows ensure that every late addition, cancellation, or reroute generates a visible event, updated route, and trail. Driver and vendor apps aligned to that same trip manifest, with OTP or QR-based boarding, make it harder for trips to run on unapproved routes or rosters.
To keep controls practical rather than punitive, operations leaders usually combine them with simple SOPs and metrics. Typical elements include:
- Published roster cut-off times per shift with differentiated handling rules for pre- and post–cut-off changes.
- Role-based access in the admin and dispatcher panels that limits who can edit rosters and routes after optimization.
- Automated flags for repeated late-change patterns by team, location, or shift, feeding into a management report.
- Trip fill ratio, dead mileage, and OTP% tracked alongside “late-change count” so Transport, HR, and business units see the operational cost of shadow changes.
When these controls sit inside one EMS platform that also handles compliance, safety (SOS, women-first policies, escort logic), and billing/MIS, operations teams gain enough predictability to reduce firefighting without losing the flexibility needed for genuine last-minute needs.
How do we check the system can handle small real-time delays (gate-pass, security holds) without triggering big reroutes that confuse drivers?
B1195 Handle micro-delays without chaos — In India corporate EMS routing and rostering, how should an Operations manager validate that the tool can handle real-time constraints like last-minute gate-pass delays or security holds without forcing full reroutes that confuse drivers?
In India EMS operations, an operations manager should validate real‑time routing tools by running controlled simulations and live pilots that inject realistic last‑minute constraints and then observing whether the system localizes changes instead of triggering full reroutes. The tool should preserve route stability for most vehicles and drivers while only re‑sequencing affected trips within the defined shift window and SLA bands.
The validation needs to mimic real gate‑pass delays, security holds, and last‑minute roster changes that Indian facilities routinely face. Operations leaders should test how the routing engine behaves when HRMS rosters update late, when access control systems delay specific employees, and when security teams hold vehicles at specific gates. The EMS platform is expected to support dynamic route recalibration and geo‑fencing without breaking trip adherence, shift windowing, and overall on‑time performance.
A common failure mode is a “global re‑optimize” behavior that overwrites all duty slips when a single constraint changes, which confuses drivers and increases exception handling. A more mature dispatch module will constrain optimization to a subset of vehicles, protect already‑started trips, and retain driver manifests that are already communicated via driver apps. Command center teams should also confirm that the NOC dashboard surfaces constraint breaches as structured exceptions with recommended actions, instead of silently rewriting routes.
Practical validation steps for an operations manager include:
- Injecting test events such as individual gate‑pass delays into the routing engine and confirming that only the impacted route segment changes.
- Verifying that driver and rider apps receive limited, clear updates rather than completely new manifests mid‑shift.
- Checking SLA and trip adherence reporting to ensure that exception handling remains auditable and does not corrupt OTP and route adherence metrics.
How should we run a pilot for routing/rostering so it’s not just a ‘best week’ demo and also covers bad-day situations like absences and sudden changes?
B1196 Pilot design for bad-day realism — In India corporate employee mobility (EMS) routing and rostering, what is the right way to run a pilot so the results aren’t biased by "best week" routing—i.e., how do we include bad-day scenarios like high absenteeism or sudden roster changes in the evaluation?
The right way to run an EMS routing/rostering pilot in India is to design it as a multi-week, shift-windowed trial that deliberately spans bad-day conditions, with outcome-linked KPIs and auditable trip data. A pilot that only covers a “quiet week” or a single stable shift pattern will almost always overstate routing performance and understate operational risk.
A robust EMS pilot usually runs across multiple roster cycles so that hybrid-work variability, peak traffic days, and roster churn are naturally captured. Transport heads get more realistic results when they insist on including at least one week with known stress patterns such as festival-season absenteeism, monsoon traffic, or planned shift restructuring. This aligns with industry practice where shift windowing, dynamic routing, and dead-mile caps are tested under real volatility rather than static rosters.
Most organizations define pilot success in terms of clearly measurable KPIs such as on-time performance, Trip Adherence Rate, Trip Fill Ratio, dead mileage, and Cost per Employee Trip. These metrics need to be tracked separately for normal days and disruption days so that decision-makers can see how the routing engine behaves when faced with sudden no-shows, last-minute bookings, and mid-shift changes. Pilot governance improves when these KPIs are tied to outcome-based evaluations instead of only feature demos.
A common failure mode is to freeze rosters at the start of the pilot and prohibit manual changes. This hides the true complexity of Indian EMS operations where hybrid attendance and last-minute swaps are routine. A better approach is to require the vendor’s routing and command-center tools to handle live roster changes and still meet agreed thresholds for OTP, safety compliance, and exception-closure time. This tests whether the routing engine and NOC processes can support real command-center operations instead of only optimized lab conditions.
It is also important to ensure that bad-day scenarios are not simulated only on paper but are observable in trip and incident logs. Organizations can do this by selecting pilot windows where high-risk factors are predictable, such as heavy rain, political events, or known roadwork, and by examining route adherence audits and incident tickets raised during those periods. This creates an audit-ready evidence trail that supports later procurement and governance decisions.
What should we ask about permissions so junior users can make fast roster edits but we still prevent major mistakes and escalations?
B1197 Roster permissions to avoid mistakes — In India corporate EMS routing and rostering, what questions should a Facilities/Transport Head ask about user permissions and approvals so junior operators can edit rosters quickly while preventing high-impact mistakes that trigger escalations?
In India EMS routing and rostering, a Facilities/Transport Head should define user permissions by asking very specific questions about who can touch what, how fast, and with what guardrails, so junior operators can move rosters at 10 p.m. without creating 2 a.m. escalations or compliance breaches.
Key questions to ask about roles, rights, and guardrails:
-
Role design and scope
• What exact actions can a junior transport executive perform in the system without any approval (add/remove employee, swap vehicle, change pick-up time, override route)?
• Which actions must always require a second-level checker or supervisor approval (e.g., changing shift window, disabling SOS, removing escort, assigning non-compliant vehicle/driver)?
• Can we define different roles for night-shift controller, vendor desk, and central command center with separate limits? -
Risk-based limits on changes
• Can we configure hard limits on how much an operator can change a trip (max km deviation, max time shift from roster, maximum seat overbooking)?
• Does the system block routing that violates women-safety or night-shift policies (no last drop for female alone, mandatory escort on specified routes, hard cut-off times)?
• Are there geo-fence or “red route” rules that junior staff cannot override on their own? -
Approval workflows and maker–checker
• For which events does the platform support a maker–checker flow with configurable approvers (HR, Security, central NOC)?
• Can urgent changes be auto-applied but still pushed for post-facto approval and review by a supervisor or command center?
• How are approval SLAs defined and surfaced so urgent roster fixes do not stall in queues? -
Audit trails and accountability
• Does every roster and route change carry a user ID, timestamp, before/after snapshot, and reason code that can be pulled in seconds during an escalation or audit?
• Can I see a shift-wise “change log” to detect risky behavior, such as repeated last-minute manual overrides or frequent route deviations by the same operator or vendor desk?
• Are alerts generated when high-risk overrides happen (escort removed, female drop order changed, night-shift route extended beyond policy)? -
Policy and HRMS linkage
• Are user permissions tied to HRMS roles and transport policy, so an operator cannot exceed rules defined by HR, Security, or Compliance?
• When HR changes eligibility or shift rules in HRMS, do roster permissions and constraints update automatically or rely on manual coordination?
• Can certain sensitive actions (e.g., adding a non-whitelisted employee, shifting between sites) be restricted to central transport or HR only? -
Safety and compliance gates
• Does the system automatically prevent assignment of non-compliant vehicles or drivers (expired license, PSV, fitness, night-shift restriction) even if the operator tries to force-assign?
• Are there non-editable safety fields in a trip (escort flag, SOS enablement, geo-fence) once the roster is published, or at least requiring Security/EHS approval to change?
• Can female-night trips or critical routes be locked so that only central command center can modify sequence or alone-drops? -
Exception handling and escalation paths
• When a junior operator hits a permission limit, what exactly happens in the tool: clear error, auto-escalation to supervisor, or silent failure?
• Can we configure escalation rules so high-impact exceptions (mass cancellation, route delete, charger/EV constraint override) immediately notify central NOC and Transport Head?
• Is there a way to mark certain changes as “high-risk” so they are always reviewed next day in a shift debrief? -
Operational resilience when tech is down
• If the app or routing engine is partially down, what are junior operators still allowed to do manually, and how is that governed and logged?
• Is there an offline or “manual override” mode with temporary permissions and a forced reconciliation log so that ad-hoc fixes do not disappear from records?
• Who can authorize switching into and out of manual mode, and is that decision itself logged and reportable? -
Reporting and early-warning signals
• Can I get daily or shift-level reports on number of roster edits, overrides, and rejected changes by user role to spot training issues or misuse?
• Are there thresholds where the system auto-flags unusual activity, such as a spike in manual re-routing or repeated policy-limit hits by one operator?
• Can I drill from a 2 a.m. escalation back to the exact edit, user, and reason that created that trip configuration? -
Training alignment with permissions
• Does the vendor provide SOPs and simulator-style training tailored to each permission level, so junior controllers know exactly what they can and cannot do during live shifts?
• Is there a sandbox or test environment where new operators can practice routing and roster edits without touching live trips?
• Can we periodically review and tighten permissions based on incident analysis and change logs, rather than leaving roles static?
By asking these permission and approval questions in advance and encoding the answers into role profiles, maker–checker flows, and hard policy gates, a Facilities/Transport Head can let junior operators move fast on day-to-day roster fixes while containing the blast radius of any mistake and keeping safety, compliance, and OTP under control.