How to run a 24x7 command center that detects early, triages fast, and keeps disruptions from hitting leadership
In peak shifts, a single missed alert can cascade into missed pickups, driver churn, and leadership firefighting. You need more than a demo—you need a repeatable, battle-tested playbook that keeps operations calm even when GPS drops or apps go down. This playbook groups questions into four operational lenses that translate vendor talk into on-ground procedures, with clear ownership, escalation paths, and auditable evidence that survives audits and leadership reviews.
Is your operation showing these patterns?
- Escalation ownership ping-pong between vendor, site, and HR creates delay at 3 AM
- Alerting fatigue with a flood of alerts and unclear ownership
- Vendor dispatch delays during night shifts despite available capacity
- No-shows or late substitutions trigger ad-hoc workarounds that bypass SOPs
- Platform outages or GPS gaps cause rider clusters and stranded drivers
- Audits require incident timelines but data isn’t readily exportable or tamper-evident
Operational Framework & FAQ
Command center governance, escalation ownership, and 24x7 coverage
Defines clear escalation ladders, single-owner accountability, and enforceable 24x7 coverage practices to prevent chaos during peak disruptions.
For our employee transport ops in India, what does a 24x7 command center actually handle day to day—what do they monitor, what do they do first when something goes wrong, and what’s not their job?
B1198 What a 24x7 command center does — In India’s corporate Employee Mobility Services (EMS) operations, what does a 24x7 mobility command center practically do minute-by-minute—what alerts does it watch, what triage steps happen first, and what problems are explicitly out of scope for the command center versus on-ground supervisors?
A 24x7 mobility command center in Indian EMS operations runs a continuous “control-room loop” of monitoring, alerting, triage, and escalation for shift-based employee transport. The command center focuses on data, exceptions, and coordination, while on-ground supervisors own physical interventions, driver handling, and site logistics.
What the command center watches minute‑by‑minute
The command center monitors real-time GPS feeds and trip dashboards for all active cabs. It watches on-time performance, route adherence, and geofence violations using alert supervision systems and command-centre dashboards. It tracks over‑speeding, device tampering, and IVMS or dashcam health as part of safety and compliance monitoring. It also supervises SOS triggers from employee apps and driver apps, including panic buttons and safety alerts. It keeps a live view on battery levels and charger status in EV fleets using EV command layers and telematics dashboards. It observes trip fill, dead mileage, and fleet uptime as leading indicators of capacity or reliability risk. It tracks ticket queues, complaint logs, and SLA timers on incident closure using transport command centre tools.
First triage steps when an alert fires
The command center first validates the alert against GPS traces, trip logs, and recent routing decisions. It checks whether the issue is technology-side, such as app downtime, GPS dropout, or telematics failure, versus field-side, such as driver deviation or traffic disruption. It contacts the driver or vendor via defined escalation matrices when route deviation, over-speeding, or device tampering is confirmed. It informs employees and security teams for SOS events and coordinates with safety cells or EHS where women-centric protocols apply. It triggers playbooks for business continuity when patterns suggest wider disruption, such as cab shortages, monsoon traffic, or political strikes. It logs every incident with time stamps and evidence for later audits and SLA reviews.
What is out of scope for the command center
The command center does not physically intervene in accidents, breakdowns, or law‑and‑order situations; these remain with on-ground supervisors, local security, and authorities. It does not perform vehicle maintenance or repairs, which fall under fleet owners and local workshops. It does not directly manage driver hiring, firing, or long-term coaching, which sit within driver management and HR-led training programs. It does not redesign fundamental site layouts, parking flows, or gate procedures, which remain a facilities and security responsibility. It does not unilaterally change contracts, tariffs, or commercial terms, which are governed by procurement and finance. It does not override company policies on women’s safety, escort norms, or shift eligibility; it executes these policies and routes exceptions into the proper governance forums.
How should we set up L1/L2/L3 escalation for late pickups, deviations, SOS, or app issues so it doesn’t become a WhatsApp mess between HR, vendors, and security?
B1199 Escalation matrix that avoids chaos — In India’s corporate ground transportation programs (EMS/CRD), how should a buyer define a clear escalation matrix (L1/L2/L3) so that a late pickup, route deviation, SOS trigger, or app outage doesn’t devolve into WhatsApp chaos and blame-shifting across HR, vendors, and security?
In India’s corporate EMS/CRD programs, a clear escalation matrix works when each incident type has a pre-defined owner, time-bound response, and an L1–L2–L3 path that runs through a command-center style workflow rather than informal WhatsApp groups. A robust matrix separates “who watches”, “who fixes”, and “who explains to leadership”, and links every incident to a ticket, not a chat thread.
An effective design starts by routing all first-line escalations to a single L1 operations desk or command centre rather than to individual vendor managers or HR. The L1 desk owns live monitoring, ticket creation, and immediate triage for late pickups, route deviations, SOS triggers, and app/GPS outages. The L1 team uses tools like alert supervision, geo-fence and over-speeding alerts, and real-time dashboards to spot issues early instead of waiting for employee complaints.
L2 should be defined as the accountable resolver by domain, not by seniority. For service failures such as recurrent late pickups or routing errors, L2 is the Transport / Facility Lead plus the vendor’s city operations manager under a documented SOP. For safety issues or SOS triggers, L2 automatically pulls in Security/EHS with clear rules about trip suspension, escort deployment, and incident documentation. For technology outages, L2 is the internal IT application owner plus the vendor tech SPOC, working from a joint playbook that covers fallback to manual rosters and SMS/voice communication.
L3 escalation is reserved for pattern and risk, not for individual trips. L3 is typically a joint forum of HR, Security/EHS, Procurement/Finance, and senior vendor leadership that reviews repeated SLA breaches, serious safety events, or systemic app failures. L3 owns corrective action plans, commercial penalties, vendor rebalancing, and any board- or audit-facing narrative.
To prevent WhatsApp chaos, the matrix must also specify channel, clock, and closure at each level. L1 receives incidents only via the official app, IVR, or command-centre hotline and acknowledges within a fixed window such as 2–5 minutes for SOS and 10–15 minutes for OTP deviations. L2 gets auto-escalated through a ticketing or alert system when defined thresholds are breached, for example two consecutive missed OTP SLAs on a route or any SOS that remains “open” beyond a defined time. L3 is invoked based on weekly or monthly deviation reports from the command centre rather than ad-hoc midnight calls.
For buyers, a practical checklist to define and enforce this matrix is:
- Define incident categories and severity bands in the contract and SOPs.
- Map a named L1, L2, and L3 owner for each category across client and vendor teams.
- Mandate use of a centralized command centre or dashboard as the only system of record.
- Set acknowledgement and resolution SLAs per level and tie them to vendor penalties and internal KPIs.
- Review escalation logs and closure quality in monthly governance and quarterly business reviews.
What MTTD/MTTR targets make sense for breakdowns, driver no-shows, GPS issues, and roster changes—and should night-shift women-safety trips have tighter targets?
B1200 MTTD/MTTR targets for disruptions — In India’s enterprise-managed employee commute operations (EMS), what are reasonable targets for mean time to detect (MTTD) and mean time to recover (MTTR) for common disruptions like vehicle breakdowns, driver no-shows, GPS dropout, and sudden roster changes—and how do these targets change for night-shift women-safety routes?
In enterprise-managed employee commute operations in India, most mature transport teams target detection of critical disruptions within a few minutes and recovery within one shift window at most. Tighter targets are expected for night-shift women-safety routes, where both detection and recovery windows are compressed and heavily governed by safety SOPs and audit expectations.
For routine EMS operations, mean time to detect is driven by the presence of a 24x7 command center, alert supervision systems, and real-time dashboards. Organizations using centralized monitoring, geofencing, and automated exception alerts can surface issues like vehicle breakdowns, driver no-shows, GPS failures, and major route deviations very early in the trip lifecycle. The collateral around transport command centers, alert supervision systems, and data-driven insights consistently positions real-time or near real-time visibility as “table stakes” rather than a differentiator.
Mean time to recover in EMS is shaped by buffer capacity, standby vehicles, and pre-defined business continuity playbooks. Business continuity plans in the material explicitly describe buffers of additional vehicles, use of associated businesses, and shift-time adjustments to sustain service during cab shortages, natural disasters, political strikes, or technology failures. Centralized command centers, rapid EV deployment models, and project planners are all designed to reduce recovery time from a disruption to a managed, predictable window, rather than leaving ops in reactive firefighting.
Night-shift women-safety routes sit under a stricter envelope. Safety collateral for women-centric protocols, escort policies, SOS infrastructure, and safety-and-compliance frameworks make clear that any deviation affecting a female employee at night is treated as a safety incident, not just an operational delay. In practice this means detection targets are aligned with immediate or near-immediate alerting from SOS buttons, geo-fencing violations, or route anomalies, and recovery expectations are governed by zero-incident postures and auditable proof of timely response.
To make these targets actionable at a control-room level, facility and transport heads can define internal thresholds along four dimensions:
- How quickly the command center must see a disruption on its dashboard or via automated alerts.
- How fast a fallback plan must be initiated using standby cabs, alternate drivers, or rerouted vehicles.
- How long it is acceptable for employees to remain at-risk or stranded before physical backup arrives, especially on women-only or night routes.
- What evidence (trip logs, GPS traces, SOS tickets) must be captured to demonstrate safe handling for HR, Security/EHS, and audit teams.
I do not have this information (please fix this gap).
How do we check that command-center alerts won’t be noisy—what thresholds and severity levels should we expect for late pickup risk, geo-fence breaches, deviations, and SOS?
B1201 Actionable alerting vs alert noise — In India’s corporate ground transportation command-and-control for EMS, how do buyers verify that alerting is actionable (not noise)—for example, what thresholds, deduplication rules, and severity levels should exist for late pickup risk, geo-fence breach, route deviation, and SOS events?
In Indian enterprise EMS command-and-control, buyers verify that alerting is “actionable, not noise” by enforcing explicit thresholds, severity tiers, and deduplication rules for each event type. Transport heads expect late-pickup, geofence, route-deviation, and SOS alerts to be tightly linked to shift windows, safety policies, and escalation matrices, with clear SOPs for who does what in the NOC when an alert fires.
For late pickup risk, most organizations set a predictive “risk” alert several minutes before contractual pickup time based on ETA models. A common pattern is a low‑severity alert when ETA exceeds a soft threshold, and a higher‑severity alert when it crosses the SLA breach limit or risks shift login. Command centers then link late‑risk alerts to rerouting or replacement-cab playbooks, and report OTP% and exception-closure times as governance KPIs.
For geofence breaches and route deviation, buyers treat perimeter exits near employee homes, campuses, and no‑go zones as higher‑severity than minor detours. Systems typically define distance or time thresholds before firing a full incident, and they suppress duplicate alerts when GPS jitter or small route corrections occur. Route adherence audits and random route checks are then used to validate that deviation alerts correlate with real non-compliance, not map noise.
For SOS events, buyers expect a strict highest-severity tier, with no rate‑limiting that could hide a real incident. However, they still configure validation steps such as mandatory callback, location verification, and linkage to driver and trip manifests. SOS alerts must integrate with safety escalation matrices, women‑safety protocols, and business continuity plans, so command centers can prove incident timelines and responses later to HR, Security, and auditors.
images: 
If the mobility platform goes down, what backup SOP should the command center follow for dispatching trips, handling attendance escalations, and keeping audit proof when apps/GPS are down?
B1202 Backup SOPs for platform outages — In India’s enterprise mobility programs (EMS/CRD), what backup SOPs should a command center run during a full platform outage—how are trips dispatched, attendance-impact escalations handled, and audit evidence preserved when mobile apps or GPS feeds are down?
A resilient command center treats a full platform outage as a pre-defined SOP event, not an ad-hoc crisis. During outages, trips are run on pre-approved offline rosters and fallback dispatch channels, attendance-impact risks are escalated through a clear call-tree, and all manual actions are captured in temporary logs that are later reconciled into the main audit trail.
Reliable EMS/CRD operations in India require a documented “technology failure” playbook that assumes loss of rider/driver apps, GPS, or core routing. Command centers keep printable rosters and route books for all major shift windows, with tagged vehicles, primary and backup drivers, and standard pickup sequences. Dispatch switches to voice and messaging using driver call lists, SMS or WhatsApp groups, and pre-agreed reporting checkpoints, while simple spreadsheet or paper-based trip sheets capture start/end times, route deviations, and passenger manifests.
Attendance and shift-impact escalations are managed through a separate, non-dependent channel. Command center teams update HR/transport stakeholders on “reduced visibility mode,” send early alerts for high-risk routes or sites, and agree on temporary policies such as extended grace periods for logins, staggered shift starts, or pooled pickups from common hubs. For women’s night-shifts, escort and safety rules are enforced manually through phone verification, cab-rotation controls, and security desk coordination until automated geo-fencing and SOS return.
Audit evidence is preserved by maintaining structured outage logs. Command centers timestamp the start and end of the outage, record all manual dispatch decisions, vehicle and driver assignments, route changes, and incident calls in a structured log, and attach supporting artefacts such as SMS screenshots, call records, and signed duty slips. After recovery, these records are reconciled with system data to rebuild the trip ledger, document SLA deviations with root-cause notes, and create a consolidated “outage incident report” that satisfies HR, Security/EHS, Finance, and internal or external auditors.
How can HR tell if the command center is actually improving the commute experience—not just closing tickets—using things like repeat incidents, escalation volume, and grievance closure quality?
B1203 Measuring command center impact on EX — In India’s corporate Employee Mobility Services (EMS), how can an HR head measure whether the command center is reducing employee pain—not just closing tickets—using indicators like repeat incidents per route, escalation volume by timeband, and grievance closure quality?
In India’s corporate Employee Mobility Services, an HR head can measure whether the command center is truly reducing employee pain by tracking repeat incident patterns, escalation intensity, and the quality of grievance closure as distinct, auditable KPIs that sit next to OTP and cost metrics. These indicators must focus on trend reduction and resolution depth, not just ticket counts or closure speed.
HR leaders should first insist on route- and timeband-level incident analytics rather than generic “issues closed” reports. Command center data should show repeat incidents per route and vendor, categorized by incident type, so HR can see whether problems on a given corridor or shift window are actually declining over weeks. A common failure mode is that the command center closes tickets quickly but the same driver, vehicle, or route keeps appearing in the logs.
Escalation volume is best monitored by timeband, day of week, and shift type. This helps HR distinguish chronic structural issues such as night-shift routing, driver fatigue, or EV charging gaps from random noise. If the command center is effective, the ratio of escalations to total trips in high-risk bands should trend down, especially for women’s night shifts and peak entry/exit windows.
Grievance closure quality should be measured by whether each case has a documented root cause, preventive action, and validation that the issue did not recur within a defined cool-off period. HR should ask for sampling-based “closure audits” where a subset of employees confirm if they feel the problem was actually fixed. This approach links command center operations, safety compliance, and commute experience into one integrated view of employee pain.
images:

For night-shift women-safety cases (SOS, escort not available, unsafe areas), what escalation path and response-time SLAs should we demand, and how do we keep audit proof without breaching DPDP privacy rules?
B1204 Women-safety escalation and audit proof — In India’s corporate ground transportation (EMS) night-shift operations, what escalation paths and response-time commitments should exist specifically for women-safety scenarios (SOS, escort non-availability, unsafe geo-zone), and how should those be evidenced for audits without violating privacy obligations under the DPDP Act?
In Indian EMS night-shift operations, women-safety escalation paths need a clearly tiered chain of responsibility, hard response-time commitments, and audit-ready but privacy-aware evidence. Escalations must be anchored in a 24x7 command center, integrated SOS, and geo-fencing, with incident data minimized and access-controlled under DPDP-compliant governance.
Escalation Path and Response-Time Commitments
Night-shift women-safety events should always enter a single, 24x7 command center or Transport Command Centre rather than ad-hoc calls to drivers or local supervisors. The Alert Supervision System and SOS control panel should generate immediate alerts for SOS triggers, escort non-availability, and entry into unsafe or non-approved geo-zones.
First-line response should sit with command-center executives who acknowledge an SOS or geo-fence breach in near real time and contact the employee and chauffeur. A defined escalation matrix should push unresolved or serious cases within minutes to shift leads, security or EHS leads, and then to senior operations or key account managers, following the structured escalation mechanism already used for service issues.
For women-safety scenarios, most organizations should define hard response-time bands. SOS alerts should be acknowledged within 60–90 seconds and have an action initiated (call, diversion, or dispatch of support) within 3–5 minutes. Escort non-availability or unsafe routing should be detected before trip start or at first routing deviation, so command-center and routing teams can correct the route or replace the vehicle before the employee is exposed.
Audit-Ready Evidence Without Breaching DPDP Obligations
Evidence for audits should rely on trip logs, GPS and geo-fence events, and SOS/ticket workflow data rather than full-content recordings of personal communications. Command-center dashboards and Alert Supervision Systems can provide immutable event timelines that show when an SOS was triggered, when it was acknowledged, what routing changes or vehicle actions were taken, and when the incident was closed.
Incident records should be pseudonymized or minimized after operational closure. Identifiers not required for compliance or legal retention should be stripped or masked, while retaining time stamps, location events, and action logs to support HSSE audits and ESG or safety reporting. Access to detailed logs should be restricted to defined roles such as security, HSSE, or internal audit, with role-based access controls and formal approval for case review.
Under DPDP-aligned practice, organizations should document lawful purpose, retention windows, and deletion routines for safety-related location data. They should also maintain chain-of-custody logs for who accessed trip and incident records, so auditors can verify integrity and due process without exposing unnecessary personal details.
When a vendor says “24x7 coverage,” what does that mean for staffing—how many incidents can a shift handle, what skills do agents need, and what happens during peak shift changes or city-wide disruptions?
B1205 What 24x7 coverage staffing means — In India’s corporate mobility command center setup for EMS/CRD, what does “24x7 coverage” really mean in staffing terms—how many concurrent incidents can one shift handle, what skills are required, and what happens during peak shift-changes or city-wide disruptions?
In an Indian corporate mobility command center for EMS/CRD, “24x7 coverage” means a continuously staffed control-room that can watch all trips in real time, triage safety and reliability alerts within minutes, and escalate according to pre-defined SOPs without gaps between shifts. It usually relies on staggered shifts, a small but multi-skilled night-core team, and surge playbooks for peak shift-changes and city-wide disruptions.
A properly designed command center uses layered staffing rather than only headcount. A base layer of controllers handles routine trip monitoring, GPS exceptions, OTP delays, geo-fence violations, and SOS alerts. A governance and data layer supports SLA tracking, reporting, and audits. A response layer owns incident escalation, BCP activation, and coordination with drivers, vendors, HR, Security/EHS, and local authorities.
Skills must cover live-ops coordination, familiarity with routing and telematics dashboards, understanding of HSSE rules, women-safety and night-shift protocols, and clear communication under pressure. Teams also need comfort with data-driven tools such as alert supervision systems, compliance dashboards, and CO₂ or EV-uptime monitoring where fleets are electrified.
During peak shift-changes, the command center workload increases sharply due to high trip volumes and tighter OTP expectations. A scalable model uses temporary staffing uplift, pre-validated rosters, dynamic route optimization, and pre-briefed drivers and supervisors to reduce “last-minute” decisions. During city-wide disruptions such as monsoon flooding, strikes, or technology failures, formally documented business continuity plans and contingency playbooks become active. These plans define alternative routing, buffer vehicles, backup communication channels, and revised shift timings so the same control-room can handle multiple concurrent incidents without losing overall control.
In practice, a 24x7 command center succeeds when it is treated as a governed, SOP-led operation with clear escalation matrices, not just a screen-watching function. It stabilizes daily EMS and CRD performance, reduces escalations to HR and leadership, and supports safety, compliance, and ESG reporting from a single operational nerve center.
How do we write escalation SLAs into the contract so exception handling is measurable—ack time, first action time, and resolution time by severity—instead of informal promises?
B1206 Contracting measurable escalation SLAs — In India’s corporate Employee Mobility Services (EMS), how should procurement and operations define escalation SLAs in the contract so that “exception handling” is measurable—e.g., acknowledgment time, time-to-first-action, and time-to-resolution by severity—and not left to informal promises?
In India’s corporate Employee Mobility Services, escalation SLAs become measurable when procurement and operations define explicit time-bound targets for each severity level and hard‑link them to reporting, audit trails, and commercial consequences in the contract. Contracts that only state “prompt” or “best effort” response create unmeasurable exception handling and persistent disputes.
Procurement and operations teams should first align on incident severity definitions for EMS, such as missed pickup affecting shift start, women-safety alerts, app/GPS failures, vehicle breakdowns, or vendor no‑shows. Each severity band should then carry three separately measured timers in the EMS operating model. One timer should capture acknowledgement time, another should capture time‑to‑first‑action, and a third should capture time‑to‑resolution, with clearly defined start and stop conditions based on trip logs, NOC records, and ticketing data.
A common failure mode is defining SLAs without tying them to the EMS command center workflow or to the mobility platform’s alert and ticket lifecycle. Exception handling remains informal when there is no integrated command center, no escalation matrix, and no centralized dashboard for OTA/OTD deviations, SOS triggers, or compliance alerts. In practice, measurable escalation SLAs require centralized command‑center operations, tech‑based measurable and auditable performance, and incident workflows that automatically capture timestamps for alerts, acknowledgements, actions, and closures as part of a continuous assurance loop.
Once timers and data sources are defined, procurement can embed outcome‑linked clauses that connect SLA adherence to penalties, earn‑backs, or performance guarantees, and can require periodic SLA reports as part of an indicative management report pack. Operations can then use these SLA metrics alongside on‑time performance, incident rate, and complaint closure SLAs within vendor governance, ensuring exception handling is governed like any other EMS KPI rather than left to subjective interpretations.
How do we link command-center performance to penalties/credits for high MTTR or missed response SLAs without encouraging the vendor to hide incidents?
B1207 Incentives without hiding incidents — In India’s corporate ground transportation operations (EMS/CRD), what is the right way to tie command-center performance to commercial outcomes—penalties or credits for high MTTR, chronic escalations, or missed response SLAs—without creating perverse incentives to under-report incidents?
Tying command-center performance to commercial outcomes works best when payouts are linked to response quality and evidence completeness, not just low incident counts or few escalations. Contracts that reward fast, well-documented closure and transparent reporting, while penalizing hidden or repeated failures, reduce the incentive to suppress incidents and increase the incentive to run a clean, honest NOC.
Most organizations in EMS/CRD achieve this by defining SLAs around observable behaviors in the command center. These behaviors include detection-to-acknowledgement time, acknowledgement-to-mitigation time, accuracy of communication to employees and HR, and the quality of the root-cause analysis and evidence trail. The SLAs are applied to all “valid incidents” that are actually logged, and not to a target of “having fewer incidents,” which would otherwise push the vendor to avoid logging issues.
A common failure mode is indexing penalties only to “number of incidents” and “escalation count.” This structure makes a vendor safer if they keep the dashboard quiet, delay logging, or downgrade severity. It also leaves the Facility / Transport Head with surprise failures during peak or night shifts and fragmented audit trails when HR, Security, or ESG teams later ask, “What really happened and when did you know?”.
To avoid these perverse incentives, organizations can define a small set of command-center KPIs that are explicitly pay-linked but incident-volume neutral, such as:
- SLA for incident acknowledgement time from first alert or complaint.
- SLA for first corrective action or mitigation step and communication to employees or HR.
- Closure SLA with documented root cause, evidence attachments, and prevention action.
- Repeat-incident rate on the same route, driver, vehicle, or site within a defined window.
- Audit trail integrity of GPS logs, trip data, and communication records for sampled incidents.
Penalties are then tied to chronic breach of these response and closure SLAs, or to high repeat-incident rates, rather than to the mere existence of incidents. Credits or earn-backs can be offered for quarters where the vendor meets high thresholds on on-time performance, command-center responsiveness, and audit readiness, while still maintaining a healthy level of incident logging and transparency.
A second safeguard is to explicitly reward transparent reporting and self-disclosure. Contracts can state that self-reported incidents detected by the vendor’s own monitoring and logged within a short window are treated more favorably than issues discovered first by employees or client leadership. This makes it commercially rational for the command center to surface problems early, which in practice reduces night-shift firefighting for the Facility / Transport Head and improves trust with HR and Security teams.
Organizations also benefit from establishing a joint governance rhythm where incident and escalation data is reviewed in structured forums. These forums can align HR, Transport, Security/EHS, and Finance around patterns such as chronic under-reporting from certain sites, gaps in women-safety protocols, or specific vendor clusters with higher repeat events. This governance can then adjust the commercial levers, for example, tightening penalties for repeat-incident rates or relaxing them when the data shows genuine improvement driven by better routing, driver training, or EV uptime management.
In India’s regulatory and ESG context, auditability is an important additional lever. Making the completeness and traceability of command-center evidence a scored and pay-linked KPI encourages vendors to maintain clean GPS trip logs, incident tickets, and communication records. This supports HR and ESG teams in demonstrating duty of care, commute emissions reporting, and women-safety compliance without depending on manually reconstructed stories after a failure.
Overall, command-center commercials in EMS/CRD are most effective when they:
- Index payouts to speed and quality of response, not low incident counts.
- Penalize repeat or systemic issues, not individual, well-managed events.
- Reward self-detection and transparent logging instead of silence.
- Include explicit KPIs for evidence quality and audit readiness.
- Are reviewed periodically in joint governance forums so thresholds and weights can evolve with operational maturity.
How do we decide what the system should auto-fix (reassign cab, reroute, backup vendor) vs what needs a human escalation so we’re not relying on 3 AM heroics?
B1208 Human vs automated remediation rules — In India’s enterprise mobility operations (EMS), how do IT and operations decide what gets escalated to humans versus auto-remediated—like reassigning a vehicle, re-routing, or triggering a backup vendor—so that the system is ‘self-healing’ rather than dependent on heroics at 3 AM?
In India’s enterprise mobility operations, self-healing EMS setups use explicit, jointly defined playbooks where high-risk or ambiguous events route to humans and well-understood, low-risk patterns trigger automated fixes. Escalation versus auto-remediation is not left to the app alone. It is governed by severity bands, data confidence, and the time left to protect shift start or safety SLAs.
IT and operations first classify incident types into safety-critical, service-critical, and cost/experience deviations. Safety-critical events such as SOS triggers, suspected assault, serious accidents, or repeated geofence violations are always escalated to humans with only assistive automation like alert fan-out or location pinning. This aligns with the emergence of centralized command centers, women-safety protocols, and HSSE accountability.
Service-critical issues like vehicle breakdowns, no-shows, or ETA breaches beyond a pre-set threshold typically follow auto-remediation rules if the routing engine and vendor pool have enough options. The system can auto-trigger reassignment, re-routing, or a standby cab when confidence in the data is high, residual travel time can still meet OTP thresholds, and contractual rules with vendors allow substitution. When capacity is tight or constraints such as guard-escort, night-shift policies, or EV range limits apply, the event is escalated to the control room.
Cost or experience deviations such as minor delays within a tolerance band or suboptimal seat-fill are usually handled by background optimization. These are addressed through route recalibration and next-cycle planning rather than live human intervention.
To keep this “self-healing” and not ad hoc, most mature EMS teams define for each alert type:
- The KPI or threshold that triggers the alert.
- Whether the first action is auto-remediation, human review, or a hybrid (auto-suggest plus human confirm).
- Data prerequisites such as GPS health, HRMS roster sync, and vendor availability that must be valid before automation acts.
- Maximum time the system can attempt auto-fix before mandatory escalation to a human in the NOC.
Over time, IT and operations refine these thresholds using NOC logs, SLA breaches, and route adherence audits. Automation is expanded from predictable patterns like recurring traffic bottlenecks or dead mileage reduction into more complex areas such as dynamic clustering, but safety and reputationally sensitive scenarios remain human-led with stronger observability and audit trails.
Before go-live, how can we test a vendor’s escalation readiness—what mock incidents or war-room drills are realistic and worth doing?
B1209 Testing escalation readiness pre go-live — In India’s corporate Employee Mobility Services (EMS), how should a transport head test a vendor’s escalation readiness during diligence—what tabletop drills, mock incidents, or ‘war-room’ simulations are realistic and worth doing before go-live?
In India’s Employee Mobility Services, a transport head should treat escalation-readiness as a testable operational capability. The most useful drills simulate the exact night-shift failures, tech glitches, and safety events that usually wake up the team at 2 a.m, and they measure response time, ownership, and communication quality across command center, drivers, and local supervisors before go-live.
A realistic starting point is to design 3–5 controlled “war-room” scenarios mapped to common Indian EMS risks. Typical patterns include monsoon-related gridlock on critical corridors, simultaneous vehicle no-shows at a major pick-up hub, app or GPS failure during a night shift, and a women-safety–sensitive delay that triggers escort or routing rules. Each scenario should have a clear trigger, an expected SLA for detection and response, and defined roles for the vendor’s centralized command center, local site team, drivers, and your own transport desk.
The most valuable drills resemble full trip lifecycles, not isolated events. A transport head can run mock peak-shift rosters, inject incidents mid-route, and then watch how the vendor’s NOC tools, alert supervision systems, escalation matrix, and business continuity playbooks behave in real time. A common failure mode is vendors talking about command centers and dashboards but failing to demonstrate 24/7 ownership, cross-city coordination, and clean handovers between centralized and local command centres when multiple routes start degrading at once.
Before production launch, escalation-readiness drills are most effective when they explicitly test four dimensions. They test early detection and alerting by using geo-fence violations, over-speeding, GPS/device tampering, and route deviation alerts to see if issues are caught before employees complain. They test multi-level escalation behaviour by walking through the documented escalation mechanism and matrix, and then verifying if each escalation level actually responds within its promised timeband. They test business continuity by simulating cab shortages, political strikes, system downtime, or severe weather, and then observing how the vendor’s Business Continuity Plan switches to buffers, alternate vendors, route changes, or manual workarounds without losing shift coverage. They also test evidence and reporting quality by checking whether, after each mock incident, the vendor can produce auditable logs, RCA, timeline of calls, and corrective actions that would satisfy HR, Security/EHS, and Internal Audit.
To keep drills grounded and repeatable, transport heads can formalize them as a pre–go-live SOP. During diligence and pilot, they can run at least one monsoon-routing simulation using the vendor’s routing engine and command center to see if promised on-time arrival rates under adverse traffic are realistic. They can run one women-safety scenario that combines escort/route rules, SOS or panic workflows, and night-shift compliance, and then ask Security to review the evidence trail. They can run one technology failure scenario, such as GPS or app unavailability, where operations must fall back to manual call-tree, paper duty slips, and telephonic confirmations while still maintaining route adherence and OTP. They can run one large-site disruption, like multiple no-shows or last-minute roster change at a major campus, to see how quickly the vendor can rebalance fleet, use standby cars, and update riders through apps, SMS, or call center.
Escalation-readiness simulations are most useful when the transport head defines success metrics in advance. Typical metrics include detection-to-escalation time, escalation-level response time, time to stabilize OTP on impacted routes, quality of communication to employees and HR during disruption, and quality of post-incident reporting and RCA. A common failure mode is treating BCP slides, command-center diagrams, or safety frameworks as sufficient proof. In practice, vendors who handle EMS well in India are the ones who can walk into a war-room simulation with clear SOPs, named escalation owners, and the ability to run through their Business Continuity Plan, alert supervision system, centralized compliance management, and command center operations under observation without adding noise or confusion.
images:
What incident data should the command center record—timestamps, call logs, GPS snapshots, decision notes—so RCA is credible and audit-ready?
B1210 Incident evidence for audit-ready RCA — In India’s corporate ground transport (EMS/CRD), what data should a command center capture per incident—timestamps, call recordings, GPS snapshots, decision logs—so that root-cause analysis is credible and audit-ready rather than anecdotal?
A command center needs a structured, time‑stamped “incident dossier” that ties together trip data, people, decisions, and evidence. Root‑cause analysis becomes credible and audit‑ready when every key event in the trip lifecycle is captured as a verifiable record rather than a memory or WhatsApp trail.
At the trip level, command centers should store a unique trip ID, employee and driver identifiers, rostered shift window, entitlement type, and SLA baselines. Each trip needs synchronized timestamps for booking, assignment, vehicle reporting at gate, employee boarding, departure, intermediate halts, and final drop, so investigators can reconstruct the full duty cycle and compare it with schedule and SLA commitments such as OTP%.
For spatial and telematics context, command centers should log GPS tracks and periodic geo‑tagged snapshots, route adherence versus the approved route, geo‑fencing violations, speeding or harsh‑driving events, and any device‑tampering or signal‑loss alerts. When EVs are involved, battery state, charger interactions, and range at key points in the journey should be included to separate infrastructure issues from planning or driver behavior.
For safety, security, and compliance, the incident file should contain SOS button activations, panic events, escort or women‑safety rule checks, driver credential status at trip start, vehicle compliance status, and any camera or IVMS event markers. Each incident should also link all two‑way communications: structured logs of calls to drivers and employees, call recordings where permitted, and key system notifications or app messages that influenced decisions.
For governance, a digital decision log is essential. Every manual override, route deviation approval, vehicle substitution, and escalation must be recorded with who acted, when, on what information, and under which SOP or BCP playbook. Closing the loop requires attaching investigation notes, RCA classification, corrective and preventive actions, and closure timestamps, so Finance, HR, Security, and ESG teams can trust the findings and reuse them in SLA reviews, safety audits, and EV or routing optimization.
With DPDP in mind, how do we check that the command center’s access to rider location/trip history is role-based, time-limited, and fully logged, especially when HR and security are involved?
B1211 DPDP-safe access for escalations — In India’s corporate mobility services under DPDP Act expectations, how should legal and IT evaluate whether command-center access to rider location and trip history is appropriately role-based, time-bound, and logged—especially when escalations involve HR and security teams?
Legal and IT should treat command-center access to rider location and trip history as a governed, audited “safety instrument,” with explicit roles, time-bounded access windows, and immutable logs that can be shown to auditors under the DPDP Act. Access that is not policy-linked, SLA-linked, and reconstructable as an evidence trail will be seen as surveillance risk rather than safety control.
They should first map personas and roles to minimum data needs. Command center operators, transport heads, and security teams should have real-time and historical location visibility strictly aligned to trip lifecycle management, incident response SOPs, and compliance dashboards. HR should not have open-ended map access and should instead see summarized, purpose-specific views for attendance, grievance handling, or investigation support.
Evaluation should then focus on three controls. Role-based controls must be implemented via identity and access management, where every user’s access level matches a defined function such as NOC operations, EHS incident handling, or HR grievance resolution. Time-bounded controls must restrict detailed location visibility to the active trip window plus a defined retention period required for safety, audit, and billing. Logging controls must capture who accessed which rider or trip records, at what time, for which declared purpose, and through which interface in the command center.
Legal teams should check that these controls align with stated purposes like safety, SLA governance, and auditability, and that consent language, privacy notices, and policy documents explicitly reflect those purposes. IT should validate that observability covers access logs, admin overrides, and data export events so that any HR or security escalation can be reconstructed without ambiguity and so that misuse can be detected and sanctioned.
What usually causes repeated escalations—driver no-shows, wrong pickup points, roster changes, GPS drift—and how do we confirm the command center is fixing root causes, not just closing tickets?
B1212 Proving root-cause fixes vs ticket closure — In India’s enterprise employee transport (EMS), what are the most common failure modes that create repeated escalations—driver no-show patterns, wrong pickup points, roster volatility, GPS drift—and how can a command center prove it is solving root causes rather than just closing incidents?
The most common failure modes in India’s enterprise employee transport are repeatable patterns in roster volatility, vehicle/driver availability, location accuracy, and weak closure discipline. A command center proves it is solving root causes when repeat incidents drop measurably, exception closure times shrink, and evidence is visible in audit-ready dashboards instead of only in call logs.
Persistent driver no-shows usually trace back to fatigue, poor incentive design, and last-minute rostering. Wrong pickup points and “vehicle not found” issues frequently come from inaccurate geo-tagged addresses, unvalidated employee locations, and GPS drift. High roster volatility stems from hybrid work, late approvals, and unmanaged cut-off times for bookings and cancellations. GPS drift and app failures are often symptoms of weak device policies, network gaps, and no fall-back SOP when tech misbehaves at 2 a.m.
A mature command center does not stop at answering the phone. It runs a continuous assurance loop with defined KPIs such as OTP%, Trip Adherence Rate, Vehicle Utilization Index, and exception detection-to-closure time. It links alerts like geofence violations, over-speeding, and device tampering from systems such as the Alert Supervision System to clear SOPs for rerouting, vehicle replacement, and safety escalation. It also integrates routing engines, driver apps, and HRMS rosters so that route changes, shift changes, and vendor allocations are controlled centrally rather than via ad-hoc calls.
To demonstrate root-cause control rather than ticket clearing, a command center should track and publish a small, stable set of signals over time. Examples include a fall in repeat incidents on the same route, a reduction in no-shows tied to specific drivers or vendors after targeted coaching, and decreased dead mileage after dynamic route recalibration. Evidence from dashboards like “Dashboard – Single Window System,” “Advanced Operational Visibility,” and “Transport Command Centre” shows that issues are predicted and prevented at the routing and planning stage. This creates operational calm for the Facility / Transport Head because fewer incidents ever reach escalation, and when they do, the command center can reconstruct what happened with tamper-evident trip data and compliance logs.
For airport trips, how should the command center manage flight delays and last-minute changes so we don’t miss pickups, but Finance also doesn’t get hit with messy waiting charges and disputes?
B1213 Airport delay escalations and billing control — In India’s corporate car rental and airport transfer operations (CRD), how should a command center handle flight delays and last-minute changes—what escalation logic prevents missed pickups while keeping Finance comfortable about waiting-time charges and billing disputes?
In corporate car rental and airport transfer operations, a command center should treat flight delays as a governed exception workflow with clear thresholds, automated triggers, and pre-agreed commercial rules. The core principle is that every minute of waiting or re-dispatch must be traceable to airline data and documented decisions, so Ops prevent missed pickups while Finance can defend waiting-time charges and avoid disputes.
A robust model starts with integration of flight-linked tracking into the booking and dispatch layer. The WTi platform already supports flight-linked airport tracking, 24/7 command-center monitoring, and automated alerts. The command center should subscribe to real-time airline status and set clear timebands for “normal”, “moderate delay”, and “severe delay” actions for each booking. Every status change should automatically update the trip in the command dashboard and the driver app, and log a time-stamped decision trail.
Escalation logic works best in short, predictable steps. For example, at a defined delay threshold the command center informs the driver and extends reporting time. If delay crosses a higher threshold, the command center can stand down the current vehicle and re-slot another closer to revised ETA, especially during peak hours or EV charging windows. This minimizes dead mileage and unnecessary waiting while preserving on-time arrival. The Alert Supervision System and Transport Command Centre collateral show how real-time alerts, geofencing, and centralized supervision reduce surprise failures.
Finance comfort depends on commercial rules that are visible, rule-based, and linked to auditable data. Waiting-time slabs and free buffers should be defined in the contract and encoded in the billing engine so that the system only charges waiting beyond the agreed free window and only when the GPS log and airline data align. WTi’s centralized billing, SLA-based models, and tech-based measurable performance framework demonstrate how OTA/OTP, delays, and billing can be tied together with audit trails. When invoices carry attached trip logs, airline delay proofs, and waiting-time calculations, disputes drop because every charge is explainable and repeatable.
images:
How do we prevent shadow escalations—senior leaders calling the vendor directly—and keep the escalation process consistent and defensible?
B1214 Preventing shadow escalations by leaders — In India’s enterprise mobility command center operations (EMS), what governance prevents ‘shadow escalations’ where senior leaders bypass the matrix—like calling the vendor owner directly—and how do buyers set expectations so the escalation process stays consistent and defensible?
In Indian enterprise EMS command-center operations, organizations prevent shadow escalations by hard‑wiring a visible governance spine around a central NOC, a published escalation matrix, and audit‑ready incident workflows. Buyers keep the process defensible by making escalation rules part of policy, contracts, and SLAs, and by giving senior leaders clean, real‑time visibility so they do not feel the need to bypass the matrix.
A central Transport Command Centre or Command Center is treated as the single source of truth for all incidents and SLAs. Command-center micro‑functions and MSP governance structures establish clear roles, from front‑line executives up to key account managers and leadership, with defined response times and documentation at each level. An explicit escalation mechanism and matrix sets who is called when OTP, safety, or technology issues breach thresholds, and it links those steps to measurable and auditable performance outcomes.
Shadow escalations are reduced when leaders trust the system’s observability. Centralized dashboards, data‑driven insights, and alert supervision systems surface exceptions early and show closure status, which lowers the impulse to “call the owner.” Buyers reinforce this with contracts that route all official communication and penalties through the command center, not informal channels. Business continuity plans and safety & compliance frameworks further require that every incident, including VIP calls, is logged, triaged, and closed through the same ticketing and RCA workflow.
To keep the escalation process consistent, transport heads and CHROs typically:
- Publish the escalation matrix and SLAs to internal stakeholders and vendors.
- Anchor it in vendor governance models and QBRs so deviations are visible.
- Tie vendor rewards, penalties, and renewals to adherence to the formal command‑center process rather than ad‑hoc interventions.
As IT, how do we check if command-center tooling has real observability (logs, alert history, post-incident reviews) instead of manual screenshots that won’t hold up in an audit?
B1215 Observability vs manual proof — In India’s corporate Employee Mobility Services (EMS), how can a CIO evaluate whether the command center tooling supports real observability—centralized logs, traces, alert history, and post-incident reviews—versus relying on manual updates and screenshots that won’t stand up during audits?
A CIO can test whether command center tooling delivers real observability by checking if events, metrics, and incident workflows are captured automatically in a queryable, time-stamped system of record instead of being reconstructed from manual logs, screenshots, and emails. Genuine observability in Employee Mobility Services requires centralized, immutable trip and incident data with audit-ready traceability from raw telemetry to SLA and safety outcomes.
A strong EMS command center platform exposes a single-window operations dashboard with real-time tracking, alerts, and historical reports. The platform should integrate GPS/telematics, driver and rider apps, SOS controls, and routing engines into one data pipeline, rather than relying on operators to manually update spreadsheets or chat groups. In practice, tools like WTi’s Transport Command Centre and EV Command Centre dashboards are positioned to give 24/7 visibility, SLA monitoring, and CO₂ tracking with structured logs and analytics, not just live maps.
A CIO should probe how alert supervision is implemented. A mature system uses automated rules for geofence violations, overspeeding, device tampering, and SOS triggers, with each alert stored as a time-stamped event linked to vehicle, trip, and user IDs. The Alert Supervision System collateral, for example, highlights specific alert types, implying that these should be generated and closed by workflow rather than free-text notes.
Post-incident reviews are a critical test. A robust setup allows reconstruction of a trip or incident timeline directly from the system: route playback from GPS logs, driver credentials from centralized compliance management, vehicle health and induction status from fleet compliance modules, and communication history from the command center’s ticketing or case log. Where vendors rely on screenshots from WhatsApp groups or ad-hoc Excel trackers, audit trail integrity and chain-of-custody are weak.
During evaluation, CIOs can use a short checklist to distinguish real observability from manual patchwork:
- Ask to see raw alert and trip event tables filtered by time, vehicle, and site, not just dashboards.
- Request a live reconstruction of a past incident from the platform, including who acknowledged it, when it was escalated, and when it was closed.
- Verify that safety features like SOS, women-centric protocols, and route deviations automatically open tickets in an incident or helpdesk module rather than generating only push notifications.
- Confirm that compliance dashboards for drivers and fleet (license, permits, checks, training) are fed by structured processes like DASP, driver compliance verification, and fleet induction—not manual uploads alone.
- Check that real-time and historical emissions, uptime, OTP, and seat-fill insights visible on sustainability and operational dashboards are backed by consistent, exportable data rather than static images.
If the vendor cannot demonstrate end-to-end traceability across the command center, alert supervision, compliance management, and safety tooling, then the EMS observability posture is still manual and will not hold up under serious audit or incident investigation.
During a live incident, how should the handoff work between the central command center and site security/facilities—who contacts whom, what gets shared, and how do we avoid delays from unclear authority?
B1216 Command center to site handoff — In India’s corporate employee transport (EMS) operations, what is the practical handoff between the central command center and site security/facilities during a live incident—who calls whom, what information is shared, and how do buyers avoid delays caused by unclear authority?
In Indian EMS operations, the command center is expected to act as the single incident nerve‑centre, while site security/facilities act as local first responders who execute on-ground SOPs. Buyers avoid delays by pre‑defining who triggers what, what data must be shared from telematics and apps, and which role has final authority in each incident type.
During a live incident, the central command center usually receives the first signal. The signal can come from SOS buttons in employee or driver apps, geo‑fence or over‑speed alerts from the alert supervision system, GPS tampering alarms, or calls to a 24/7 helpdesk. The command team validates the alert using the EV or cab command dashboard, trip manifest, and live GPS trail, and then opens a ticket with time‑stamped details.
Once validated, the command center must call site security or the client’s transport desk as the first escalation, not the other way around. The command team shares explicit fields such as vehicle number and GPS location, driver identity and compliance status, employee details and contact, trip ID and route, event timestamp and alert type, and immediate risk assessment. This information is then mirrored into email or incident logs to create an auditable trail for HR, Security/EHS, and Facilities.
To avoid delays from unclear authority, buyers define a simple matrix before go‑live. They define which incidents are controlled centrally, such as tech failures, routing deviations, and multi‑city disruptions, and which require site‑led authority, such as physical threat, medical emergencies, and gate‑entry conflicts. They specify who has final say on decisions such as trip continuation, replacement vehicle dispatch, escort deployment, or police escalation.
The most effective governance models link the command center and site security through a documented escalation mechanism and matrix. These models define named roles, time‑bound response SLAs, and call order for each severity band. They also connect to a business continuity plan that already covers cab shortage, strikes, disasters, and technology failures, and to HSSE tools that define who logs, audits, and closes each incident.
A robust setup also ensures that the command center has access to centralized compliance management data. That data includes driver background checks, vehicle fitness and induction status, and safety equipment checklists. Site security is then not asked to “re‑verify” what is already digital, which reduces duplication and confusion at the gate or during a night incident.
images:

How do we spot a vendor who claims 24x7 but doesn’t really deliver—what proof should we ask for like shift rosters, escalation logs, recent incident stats, and references for similar shifts?
B1217 Spotting fake 24x7 coverage — In India’s enterprise mobility services (EMS/CRD), how can procurement detect ‘24x7 in name only’ during vendor evaluation—what evidence should buyers ask for like shift rosters, escalation transcripts, last-30-days incident stats, and real customer references from similar timebands?
24x7 capability in enterprise mobility is proven through hard operational evidence across night shifts, not just a slide or a promise. Procurement teams should demand artefacts that show who was on duty, what actually went wrong, how fast it was handled, and what similar clients say about the vendor’s night and weekend performance.
Procurement teams can test “24x7 in name only” by pushing vendors for shift-wise operational proof rather than generic PPT claims. A reliable EMS/CRD operator will share documented command-center operations, business continuity playbooks, safety SOPs for women’s night shifts, and measurable on-time performance across timebands.
The most useful evidence bundles typically include: - Shift rosters and command-center coverage. Buyers should request anonymized last-3-month rosters for the centralized command center and location-specific command desks, including night, weekend, and holiday coverage. These should map roles like transport command center supervisors, escalation managers, and helpdesk agents to specific shifts, linking to the MSP governance structure or Transport Command Centre model.
-
Escalation matrix and real escalation logs. Procurement should ask for the live escalation mechanism and matrix with role names and response-time commitments. They should also request redacted incident or SOS transcripts from late-night shifts showing how an issue was detected, who responded, timestamps for each step, and how closure was confirmed against SLAs.
-
Incident and on-time performance statistics by timeband. A mature operator should present last-30–90-day metrics broken down by day vs night, including OTP%, exception count, safety incidents, and complaint closure SLAs. Evidence such as “98% on-time arrival during Mumbai monsoon” or command-center dashboards and alert supervision system screenshots helps separate marketing claims from live operational control.
-
Business continuity and contingency playbooks. Buyers should see the vendor’s business continuity plans for cab shortages, political strikes, tech failures, and natural disasters, with clearly assigned responsibilities and mitigation steps such as buffer vehicles, backup systems, and local authority coordination.
-
Real customer references from similar timebands and profiles. Procurement should insist on speaking with operational counterparts from current clients of similar size, city mix, and night-shift intensity, especially where women’s safety and EV operations are in scope. References are most credible when they confirm punctuality, escalation handling quality, and stability during crises.
If a vendor cannot provide timeband-sliced metrics, redacted incident logs, or concrete BCP documents, the 24x7 claim is likely marketing rather than a proven command-center capability.
What should Finance ask so disruption-related costs (backup cabs, towing, waiting, emergency substitutions) don’t turn into unbudgeted exceptions every month?
B1218 Controlling escalation-related exception costs — In India’s corporate mobility operations (EMS), what should a CFO ask to ensure escalation and disruption costs are predictable—like backup vehicle premiums, towing, waiting, and emergency substitutions—and that these don’t become ‘unbudgeted exceptions’ every month?
In Indian EMS operations, a CFO should insist that all escalation and disruption costs are defined as standard, pre-priced line items in the contract and tightly mapped to SLA breaches and exception codes in monthly MIS. The CFO should also demand trip-level data that reconciles every “extra” charge (backup vehicles, towing, waiting, emergency substitutions) back to a documented incident category, so nothing appears as an unexplained exception.
The first focus area is commercial structure. The CFO should ask how backup vehicle deployment, towing, peak-hour waiting beyond free limits, and emergency substitutions are priced, capped, and approved. The CFO should also ask whether these are covered via pre-agreed buffers, FTE-style standby, or explicit per-incident rates in the billing model. Every escalation cost should sit inside clear models such as monthly rental, per km, trip based, FTE, or pay-per-usage, not as ad-hoc line items.
The second focus area is data and reconciliation. The CFO should ask for an indicative management report that tags all escalations to specific trips, routes, and timebands and confirms that billing systems support centralized, timely, and accurate reconciliation. The CFO should also insist that the billing process flow, from duty slip to invoice, contains checkpoints for tariff mapping, customer approval, and online reconciliation, so exceptions cannot bypass controls.
The third focus area is governance and BCP. The CFO should ask to see the business continuity plan for cab shortages, technology failures, strikes, and disasters and how cost treatment is defined in each scenario. The CFO should also ask for a clear escalation matrix showing who can approve emergency substitutions or waiting extensions and how those approvals are logged for audit.
Operational risk is the final focus area. The CFO should ask how on-time delivery is managed through routing, traffic trend analysis, and buffer vehicles, because better OTP reduces emergency use of backup vehicles and waiting. The CFO should also demand periodic reviews where vendor, transport, and Finance jointly analyse exception patterns, convert recurring ones into revised SOPs or commercials, and document any residual discretionary spend as an agreed contingency line in the budget.
How do HR and operations agree on what’s a reportable incident vs a normal service issue so leadership reporting is consistent and employees don’t feel brushed off?
B1219 Defining reportable incidents consistently — In India’s corporate employee transport (EMS), how should HR and operations align on what constitutes a ‘reportable incident’ versus a routine service issue, so that leadership reporting is consistent and employees don’t feel issues are being minimized?
In India’s corporate employee transport, HR and operations need a shared, written incident taxonomy that clearly separates “safety and compliance incidents” from “service-quality issues,” and they must route, log, and report them through different but connected workflows. A common failure mode is mixing late pickups with women-safety or driver-misconduct cases in the same bucket, which dilutes leadership focus and makes employees feel serious issues are being downplayed.
HR and operations should first agree that anything touching physical safety, women’s night-shift security, legal compliance, or reputational risk is always “reportable.” Routine delays, routing changes, or vehicle swaps remain “service issues,” even if they cause dissatisfaction. Business continuity events like cab shortages during strikes or floods also need a separate “disruption” category, with clear BCP playbooks and ownership defined.
A practical alignment method is to co-design a transport incident matrix in the command center environment. Each incident type gets a severity band, mandatory escalation path, and evidence requirement based on safety SOPs, women-centric protocols, and HSSE expectations. HR, Security/EHS, and the Transport Head should review this matrix quarterly, using data from alert supervision systems, safety dashboards, and audit trails to refine what is tracked as “reportable.”
For leadership, only aggregated safety, compliance, and disruption metrics should appear in formal dashboards, supported by auditable trip logs and route data. Service issues should surface as operational KPIs like on-time performance and customer satisfaction, not as “incidents.” This separation keeps reporting consistent, preserves seriousness for true incidents, and reassures employees that safety concerns are never hidden inside routine service noise.
Measurement, alerting discipline, triage, and observability
Sets early-warning targets, actionable alert thresholds, and observable dashboards so teams triage consistently and leadership sees real reliability gains.
What post-incident review rhythm works in practice (daily review, weekly RCA, monthly governance), and how do we make sure actions actually get done so issues don’t repeat?
B1220 Post-incident reviews with follow-through — In India’s enterprise-managed mobility programs (EMS), what is a realistic post-incident review cadence and format—daily ops review, weekly RCA, monthly governance—and how do buyers ensure follow-through so repeat issues don’t erode trust in the command center?
In India’s enterprise employee mobility programs, most mature buyers converge on a three-layer cadence for post‑incident review. Daily operations huddles handle quick triage, weekly reviews close root causes, and monthly governance forums track patterns and enforce accountability. This layering keeps the Transport Head’s command center stable in real time while still giving CHRO, Security, and CFO the audit-ready view they need.
Daily reviews are usually run inside the command center or transport desk. The focus is fresh incidents, SLA breaches, women-safety exceptions, and GPS/app failures in the last 24 hours. The discussion stays tactical. The command team validates facts from trip logs and telematics, checks interim fixes, and decides which cases need structured RCA instead of ad‑hoc firefighting.
Weekly reviews work best as a short but formal RCA clinic. Operations, Security/EHS, and sometimes HR go through a limited set of “priority incidents,” for example repeat late pickups on a route or recurring driver non-compliance. Each case is tied to a specific cause category such as routing logic, driver fatigue, vendor gaps, or tech instability. The output is a written action owner, due date, and a measurable check like improved OTP on that route or zero reoccurrence over a week.
Monthly governance closes the loop at a leadership level. CHRO, Transport, Procurement, Security, and the vendor review aggregated trends rather than individual trips. They look at OTP%, incident rates, safety escalations, complaint closure SLAs, and any women-safety or night-shift deviations. Decisions here typically include route policy changes, vendor tiering, contract-level penalties or incentives, and if needed, changes in fleet mix such as more EVs or dedicated standby cabs.
Buyers ensure follow‑through by insisting that every incident and RCA lives in a single, auditable system rather than scattered emails. Command centers log each case with time-stamped trip data, GPS traces, driver details, and closure notes. This log feeds monthly dashboards that surface repeat patterns, for example the same corridor repeatedly breaching escort rules or the same vendor cluster driving most SLA failures.
Strong governance frameworks also tie incident outcomes directly into vendor SLAs and commercial levers. A common approach is to link payouts or penalties to on-time performance, safety incident counts, and complaint closure timelines. This creates an operational and financial reason for vendors and internal teams to close actions, not just discuss them.
A practical discipline is to limit weekly RCA to a small, highly visible “top 5 issues” list. Each item stays on the list until data proves it has been resolved for multiple weeks, such as through OTP recovery or zero recurrence. This prevents issues quietly resurfacing and eroding trust in the command center’s assurances.
When incident review is integrated with centralized command-center tooling, the same platform that monitors trips in real time can also generate end‑to‑end evidence packs for audits and governance. That alignment lets Transport Heads move from purely reactive firefighting towards predictive operations supported by clear SOPs, measurable KPIs, and stable review cadences.
How should we communicate escalations to employees during disruptions so updates are timely and respectful, but we don’t create panic or expose sensitive location details?
B1221 Employee communication during escalations — In India’s corporate ground transportation command center setup (EMS/CRD), how do buyers design escalation communications so employees receive timely, respectful updates during disruptions without increasing anxiety or exposing sensitive location data?
In India’s corporate ground transportation command centers, buyers design escalation communications as tiered, SOP-driven workflows that give employees short, factual, and low-anxiety updates, while keeping GPS and personal data inside the command stack and not exposed in raw form. Command centers use alert supervision systems, routing engines, and HRMS‑linked rosters to generate templated messages that describe impact and next steps, but they avoid sharing precise coordinates, other riders’ details, or internal risk flags.
Most organizations route disruption signals first into a 24x7 command center or Transport Command Centre rather than directly to riders. The command center aggregates GPS, IVMS, and driver app status, applies business continuity playbooks for strikes, monsoon traffic, or tech failures, and then pushes only necessary information out via employee apps, SMS, or calls. This pattern protects observability and evidence trails for OTP, safety, and compliance, while preventing real-time internal chatter about raw incident feeds.
A common failure mode is over-notifying with technical jargon or unfiltered alerts, which increases anxiety and escalations. Another is under-notifying, which forces employees to call the transport desk repeatedly and overwhelms night-shift teams. Command centers work best when they define clear “what to tell the employee” playbooks for delays, reroutes, escort changes, or vehicle swaps and keep a single-window contact route through the mobility app, call center, or helpdesk.
Typical SOP elements include:
- Strict role separation where only the command center and call center see detailed telematics, while employees see time estimates, vehicle identity, and high-level reasons for delay.
- Use of standardized, non-alarming templates that say what happened, what is being done, and what the employee should do now.
- Escalation matrices that govern when to move from in-app notifications to live calls, especially for women’s night shifts or safety-related deviations.
What should we ask to make sure the command center can run even with poor connectivity—offline workflows, fallback calling, and caching—especially in tier-2 cities or weak network areas?
B1222 Connectivity-resilient escalation operations — In India’s corporate Employee Mobility Services (EMS), what questions should a transport manager ask to ensure the command center can operate during connectivity issues—offline-first workflows, fallback calling trees, and local caching—especially for tier-2 cities or poor network pockets?
A transport manager should treat connectivity loss as an expected condition and probe whether the command center has clear offline SOPs, local data caching, and voice-based fallback so OTP, routing, safety, and escalations still run in tier‑2 cities and weak‑network pockets. The questions should test how rostering, trip monitoring, SOS handling, and reporting continue when apps, GPS, or data links partially fail.
Key question areas include command-center operations, field workflows, safety/compliance, and data integrity.
Command-center / NOC operations - How does the command center continue shift operations when the mobility platform or internet link is partially or fully down? - What are the defined offline-first workflows for rostering, routing, and vehicle assignment during outages? - Is there a documented playbook for “technology failures” in the Business Continuity Plan, with roles and timelines for activation? - What visibility does the NOC retain if live GPS feeds are delayed or missing for part of the fleet?
Fallback calling trees and communication - What is the fallback calling tree when apps or data connectivity fail for drivers or employees? - Are drivers, escorts, and local supervisors given printed or SMS-based escalation matrices with 24/7 numbers? - How is two-way confirmation (pickup, drop, last-mile arrival) handled via voice/SMS when app check-ins do not work? - Who is accountable at 2 a.m. for coordinating calls across drivers, security, and local site teams if the command center screens are frozen?
Driver and field SOPs in poor coverage - What SOPs are given to drivers for routes with known poor network pockets in tier‑2/3 cities? - Are route manifests, trip sheets, and employee lists cached locally on the driver app or shared in advance (PDF/WhatsApp/printed)? - Can drivers navigate and complete trips if the app cannot refresh mid-route? - How are no-shows, diversions, and unscheduled stops captured when live geo-fencing alerts are not available?
Safety, women’s security, and SOS handling - How are SOS and panic workflows handled if the SOS API cannot fire due to low data coverage? - Is there an alternate “voice-SOS” protocol, such as a dedicated emergency helpline or speed-dial from the employee app? - How are women-centric safety protocols (escort rules, home-drop confirmation, call-back on late-night trips) enforced without real-time tracking? - What evidence is retained for incident reconstruction if GPS trails are incomplete due to connectivity gaps?
Local caching, data sync, and audit trails - What specific trip data (roster, route, contact numbers, check-in/out status) is cached offline on driver and employee apps? - When connectivity is restored, how does the system backfill trip logs and ensure audit trail integrity for compliance and ESG reporting? - How are discrepancies between manual duty slips and system trip records reconciled after an outage? - Can the vendor demonstrate that CO₂ reporting and SLA dashboards remain defensible even with intermittent data loss?
Business continuity and redundancy - What redundancy exists for the command center itself (dual links, backup NOC, mirrored dashboards)? - How often are “technology failure” drills conducted that simulate app downtime, GPS loss, or network cuts in target cities? - What were the last major connectivity incidents in similar EMS accounts, and how were OTP, safety, and escalations protected?
These questions help a transport manager validate that EMS operations are not app-dependent only, but backed by offline-ready SOPs, BCP documents, and real 24/7 command-center muscle memory.
How can IT confirm incident logs are tamper-evident and timestamps match across GPS, app events, and call logs so the evidence stands up in disputes or audits?
B1223 Tamper-evident, consistent incident logs — In India’s enterprise mobility command center operations (EMS), how should IT validate that incident logs are tamper-evident and time-synchronized (for example, consistent timestamps across GPS, app events, and call logs) so that evidence holds up in disputes or audits?
In India’s enterprise mobility command center operations, IT should validate tamper‑evidence and time‑synchronization by treating trip and incident logs as governed evidence objects with a single time base, controlled write paths, and independent cross‑checks across systems such as GPS, apps, and telephony.
IT teams should first enforce a common time standard across all EMS systems. The routing engine, driver and employee apps, GPS/telematics units, NOC tools, and ticketing or SOS systems should all use a synchronized source such as NTP‑backed server time. Command center dashboards and mobility data lakes should store this server time alongside any device‑reported timestamps, so that cross‑system comparisons during route adherence audits, incident reconstruction, or women‑safety investigations are based on a single canonical clock.
IT should then ensure that incident and trip records are append‑only and traceable. The mobility platform, panic/SOS API, IVMS, and command center workflow tools should log each state change as a new event rather than allowing in‑place edits. Update actions such as re‑routing, manual trip closure, or escort assignment changes should generate fresh events, with the earlier state retained for audit trail integrity. Access to alter trip and incident records should be locked behind role‑based controls, and any administrative overrides should themselves be logged as explicit events that are visible on compliance dashboards.
Independent corroboration is critical when evidence is later challenged. IT should design data pipelines so that GPS traces, app telemetry, and call‑center logs feed into a mobility data lake or reporting layer without manual re‑entry, and can be queried together for a given trip ID, driver ID, or SOS case. During validation, IT should periodically sample incidents and compare times between geo‑fencing alerts, NOC actions, and voice calls to confirm that exception detection–to–closure timelines and escalation matrix steps can be proven. For higher‑risk areas such as night‑shift women‑safety or political‑event disruption, IT and Security can agree specific route adherence audit and incident reconstruction SOPs that always pull this correlated data set.
Finally, IT should embed these checks into continuous assurance rather than one‑off projects. The command center operations stack should expose integrity metrics such as audit trail completeness, SLA breach rates where evidence is missing, and the proportion of trips that pass random route adherence audits. These metrics can be reviewed in mobility governance boards or QBRs alongside reliability KPIs like OTP% and Vehicle Utilization Index, giving Security, HR, and Finance confidence that safety, compliance, and billing data will withstand disputes or external audits.
When multiple fleet vendors are involved, who owns the incident end-to-end, and how do we avoid handoffs and finger-pointing during escalations?
B1224 Single-owner accountability in multi-vendor — In India’s corporate mobility services (EMS/CRD), what should a facilities head ask about escalation ownership when multiple vendors or fleets are involved—who has the ‘single throat to choke’ during an incident, and how is accountability tracked without endless handoffs?
In multi-vendor corporate mobility, the facilities head should insist on a clearly named “primary mobility integrator” or command-center owner who is accountable end-to-end for incidents, regardless of which fleet or sub-vendor is involved. Accountability should sit with one entity that operates a 24x7 command center, owns the escalation matrix, and maintains the unified incident log, while other vendors are treated as governed suppliers under this umbrella.
The operational failure mode in India is fragmented responsibility where each fleet owner blames “the other vendor” or “the app” during night-shift breakdowns. A facilities head should therefore ask who runs the centralized NOC or command center, who triggers SOS and safety workflows, and whose KPIs are tied to on-time performance, incident rate, and closure SLAs across all EMS and CRD trips. Escalation ownership should be embedded in a documented escalation matrix that defines time-bound response and resolution per level, with the primary integrator accountable for coordination with all sub-vendors.
Facilities leaders should also demand a single incident and trip ledger. This ledger should capture GPS data, driver credentials, route adherence, and escalation timestamps so that every safety, OTP, or service complaint is traceable to one accountable owner. This approach reduces endless handoffs, because the integrator’s contract and SLA scorecard reflect unified KPIs like on-time performance percentage, incident closure time, driver compliance status, and audit trail integrity, regardless of how many fleets are plugged into the system.
How do we measure if the command center is reducing workload for our transport team—fewer manual calls, fewer spreadsheets, and fewer escalations going to leadership?
B1225 Quantifying reduced operational drag — In India’s corporate Employee Mobility Services (EMS), how can a buyer quantify whether the command center is actually reducing operational drag for the transport team—like fewer manual calls, fewer ad-hoc spreadsheets, and fewer escalations reaching senior leadership?
A buyer can quantify whether a command center is reducing operational drag by tracking a small set of before‑and‑after metrics that sit directly on the transport desk workload, not just on-time performance or app “features.” The core principle is to measure manual effort, exception volume, and escalation depth across shifts, and to link those trends to command center processes and tooling.
The most reliable signals come from how the NOC / command center handles daily exceptions like rerouting in monsoon traffic, night‑shift safety alerts, GPS gaps, driver shortages, and BCP scenarios such as strikes or tech downtime. A well-run command center uses real-time dashboards, alert supervision systems, and escalation matrices to absorb these shocks early. That reduces the number of ad‑hoc calls, WhatsApp groups, and emergency rosters the internal transport team has to manage. Case studies that show 98% on‑time arrivals during severe weather, or dedicated command centers that act as client auditors, are evidence that real-time supervision and routing actually remove pressure from the facility transport head and shift supervisors.
To make this quantifiable and defensible, buyers can set up a simple operational scorecard.
- Track inbound contact load to the transport desk per 1000 trips. Count calls, emails, and chats related to delays, driver location queries, and no‑show confusion.
- Measure the number of manual interventions per shift. Count manual roster edits, last‑minute route changes done in spreadsheets, and trips assigned outside the platform.
- Record escalation volume and depth. Track how many issues reach senior leadership, HR, or security versus being closed within the command center escalation matrix.
- Compare exception resolution time. Measure the time from alert (e.g., GPS loss, over‑speeding, geofence violation) to closure when handled via the alert supervision system.
- Audit tool usage versus parallel processes. Check how many routes, trip sheets, and incident reports originate from the command center dashboard versus side channels.
A common failure mode is to focus only on high-level OTP% and CO₂ dashboards and ignore whether the transport team is still maintaining side spreadsheets, manual duty slips, or informal WhatsApp routing groups. Another failure mode is to deploy rich dashboards without clear SOPs for who picks which alert, what the escalation ladder is, and how BCP playbooks are triggered during cab shortages or technology failures. In those environments, command centers look impressive but do not reduce the operator’s 2 a.m. workload.
The most pragmatic buyers define a “control-room health” baseline before implementation, including contact volume, manual roster effort, and number of red‑flag escalations per week. They then run a 8–12 week comparison after the command center, alert supervision system, and mobile apps for drivers and employees are stabilized. If manual calls and spreadsheets drop, if weather or strike scenarios are handled largely within the command center, and if senior‑level escalations become rare, then the facility / transport head can say with evidence that the command center is reducing operational drag rather than adding another screen to watch.
What reporting should the command center share—daily incident summary, MTTR dashboard, recurring causes, action tracker—so leadership feels in control without too much detail?
B1226 Executive reporting from command center — In India’s corporate ground transportation operations (EMS), what are the practical governance artifacts a command center should produce—daily incident digest, MTTR dashboard, top recurring causes, and open action items—so executives get confidence without drowning in detail?
A well-run EMS command center in India should produce a small, repeatable set of governance artifacts that summarize risk, reliability, and action status in a few screens. Executives gain confidence when they see clear OTP and safety trends, root causes, and closure discipline, not raw trip logs.
A daily incident digest works best as a one-page view. The artifact should list total trips, OTP%, exceptions raised, and incidents segmented by severity and type. The digest should highlight female night-shift trips, SOS triggers, geofence or route deviations, and escort compliance breaches as distinct categories. Each incident should carry a unique ID, timeband, site, and current status so Security, HR, and Transport can triage quickly.
An MTTR dashboard should focus on exception detection-to-closure time. The dashboard should separate operational issues such as delay, no-show, breakdown, and app downtime from safety and compliance issues. It should track median and 90th percentile MTTR, show which sites or vendors drive the longest closures, and flag breaches against defined SLAs.
A top recurring causes view should use the same taxonomies every day. The view should rank the top 5–10 causes by frequency and impact on OTP and safety, such as driver shortage, routing errors, charging delays for EVs, or GPS failures. It should link each cause to a responsible owner, affected shift windows, and whether a structural fix is already in progress.
An open action items tracker should function as the cross-functional to-do list. The tracker should map each issue to an accountable owner in Transport, Vendor, Security, or IT, along with due dates and risk ratings. It should distinguish containment actions already live from preventive actions that change SOPs, routing rules, or vendor SLAs so leadership can see progress toward fewer escalations.
HR wants quick escalations for safety, Finance wants tight control on exceptions and costs—what escalation rules and reporting can keep both aligned?
B1227 Balancing HR urgency and cost control — In India’s corporate Employee Mobility Services (EMS), how should a buyer handle the internal conflict where HR wants ‘zero-incident, escalate fast’ while Finance wants ‘control exceptions and costs’—what escalation rules and reporting keep both sides aligned?
In India’s corporate Employee Mobility Services, buyers keep HR and Finance aligned by defining a common, written escalation and reporting playbook where safety incidents escalate immediately and automatically, while commercial exceptions are tiered, capped, and reviewed on a schedule. The core rule is simple. Any safety, women-safety, or compliance risk is “escalate first, cost later.” Any pure service or cost exception is “log first, analyze and control via dashboards and reviews.”
A practical approach is to classify every event into three buckets. Bucket one is safety and HSSE incidents, including women’s night-shift issues, SOS triggers, escort lapses, or serious route deviations. These go to HR, Security/EHS, and the Transport Head in real time from the command center, with a short, fixed SLA for acknowledgement and containment. Finance only sees these later as part of monthly or quarterly risk and ESG reporting, with minimal debate on spend.
Bucket two is reliability and SLA issues. These include late pickups, missed cabs, or routing failures that impact attendance but are not safety-critical. These go to the Transport Head and vendor operations first, with clear OTP%, trip adherence, and closure-time SLAs. HR gets trend and NPS-style reports, not every ticket, so they can protect employee experience without living in daily noise.
Bucket three is commercial and billing exceptions. These include dead mileage disputes, out-of-policy trips, and billing mismatches. These are not escalated in real time. The transport command center and vendor consolidate them into auditable logs, linked to trip and GPS data, and surface them to Finance and Procurement through centralized billing reports and periodic reviews.
To keep both sides aligned, the buyer should define in the EMS governance model:
- Clear, written thresholds for what counts as a safety-critical incident versus a service failure versus a cost anomaly.
- Time-bound escalation SLAs for each bucket, with the command center owning triage and routing events to HR, Security/EHS, Operations, or Finance.
- Common dashboards and MIS that show HR safety and user-satisfaction metrics alongside Finance’s cost-per-trip, dead mileage, and exception volumes.
- Outcome-linked contracts where penalties and incentives are based on OTP, incident rate, and audit trail integrity, which both HR and Finance can defend in front of leadership and auditors.
If an auditor asks on the spot, what ‘one-click’ compliance report should we be able to generate from command-center data—incidents, response times, and closure proof?
B1228 One-click compliance reporting for audits — In India’s corporate mobility programs (EMS/CRD), what does “panic button compliance reporting” look like for command-center and escalation data—what can be produced in one click for an auditor about incidents, response times, and closure evidence?
In mature Indian corporate mobility programs, “panic button compliance reporting” means the command center can pull a one‑click, audit‑ready incident report that shows every SOS trigger, the full response timeline, and closure evidence with intact audit trails. The report is structured so an auditor can see what happened, how fast the system and people reacted, and whether SOPs and women‑safety norms were followed, without additional manual reconstruction.
A typical one‑click panic/SOS report for EMS or CRD includes:
-
A time‑bounded incident log.
Each SOS event is a row with fields such as trip ID, employee ID (pseudonymized if required under DPDP), vehicle/driver details, GPS coordinates, date/time of trigger, and channel used (rider app SOS, driver app SOS, IVR, or command‑center override). -
Response‑time and escalation chain stamps.
The log captures system detection time, first human acknowledgement time in the command center, first outbound contact attempt, successful contact, and escalation hops (L1 → L2 → Security/EHS, etc.).
Command centers use this to prove SLA adherence on “time to acknowledge” and “time to first action.” -
SOP linkage and policy compliance fields.
For each SOS, the record shows whether the case matched women‑safety or night‑shift protocols, whether escort rules applied, and which pre‑defined response playbook was invoked.
This helps Security/EHS demonstrate compliance with internal HSSE rules and state night‑shift norms. -
Narrative and categorical root‑cause data.
Each closed incident carries a short narrative field plus standardized tags such as “vehicle breakdown,” “route deviation,” “harassment concern,” or “geo‑fence breach,” which are essential for pattern analysis and HSSE reporting. -
Closure evidence attachments.
The report links to call logs, chat transcripts, GPS route replays, driver and employee statements, and any corrective action records.
This chain‑of‑evidence is critical for both internal investigations and external audits.
Well‑designed systems expose this as a single‑window dashboard export.
The same underlying data also feeds safety KPIs like incident rate, average SOS response time, and complaint closure SLA, which are commonly monitored by Security/EHS, HR, and the command center leadership.
For our employee commute operations, what does your 24x7 command center coverage look like day-to-day—who’s watching, what alerts get raised, and how does escalation work during night shifts?
B1229 What 24x7 coverage means — In India corporate Employee Mobility Services (EMS), what does “24x7 command center coverage” actually mean in practice—who monitors live trips, what triggers alerts, and what are the escalation steps from first alert to resolution during night shifts?
In India corporate Employee Mobility Services, 24x7 command center coverage means there is a dedicated operations team continuously watching live trips, handling alerts in real time, and following predefined escalation steps until each issue is closed and documented. The command center functions as a centralized control room that tracks GPS feeds, trip status, safety events, and SLA performance across all shifts, with special focus on night operations and women’s transport.
In practice, live monitoring is usually done by transport executives or controllers working in shifts in a centralized Command Centre or Transport Command Centre. They use a single-window dashboard for real-time trip visibility, vehicle/battery status (for EVs), route adherence, and compliance metrics. Alerts are typically generated by the Alert Supervision System or equivalent tooling for events such as geofence violations, fixed device tampering, overspeeding, SOS triggers, no-shows, and major delays. Safety-specific controls for women include dedicated women-safety cells, GPS-based tracking, call masking, and panic/SOS buttons integrated into employee and driver apps.
When an alert fires at night, the first-level action is taken by the command center executive who validates the alert, contacts the driver and employee, and tries to resolve it immediately through rerouting, replacement vehicle dispatch, or coordination with on-ground supervisors. If the issue threatens safety, SLA breach, or service continuity, it escalates through a predefined escalation matrix from executive to shift lead, Key Account Manager, and then to senior operations or client stakeholders. Parallel engagement with Security/EHS, women-safety cells, or local authorities is triggered for safety incidents. Each case is tracked as a ticket with time-stamped actions, and post-resolution it feeds into deviation reports, management dashboards, and continuous improvement reviews so that on-time performance, safety compliance, and business continuity commitments are auditable.
How do we define MTTD and MTTR for commute issues like late pickup, breakdowns, and app/GPS failures so the numbers are meaningful and not just dashboard math?
B1230 Defining MTTD/MTTR for EMS — In India corporate ground transportation command-and-control for EMS, how should a transport head define and measure MTTD and MTTR for commute disruptions (late pickup, no-show driver, vehicle breakdown, GPS/app outage) so the metrics reflect operational reality and not just reporting cosmetics?
In India EMS command-and-control, MTTD and MTTR only become useful when they are defined around the true start and end of operational pain, not around when someone logs a ticket or clicks a button.
Define MTTD (Mean Time To Detect) from the moment the disruption becomes “operationally real”.
For commute operations, detection should start when the first hard signal appears in telematics or the roster, not when someone raises a complaint.
- Late pickup. Start clock at scheduled pickup time + defined grace (e.g., 3–5 minutes) if the vehicle has not crossed a geo-fenced “approach” or “at pickup” zone, or has not updated GPS for a defined interval.
- No-show driver. Start clock at driver duty start if the driver app has not come online or the vehicle has not left the garage by a defined margin before first pickup window.
- Vehicle breakdown. Start clock at first abnormal telematics or manual breakdown flag, whichever is earlier, with GPS speed=0 on a live trip beyond a defined time threshold treated as potential breakdown.
- GPS/app outage. Start clock at last good signal + monitoring buffer when multiple vehicles or a whole cluster drop off, indicating a platform issue rather than a single-car glitch.
Detection stops when the disruption is visible in the command center dashboard as an actionable alert with an owner assigned, even if the fix is still pending.
Define MTTR (Mean Time To Resolve) as the time until the employee’s commute is back on a reliable track.
For operations, “resolved” should mean the risk to shift-start or drop safety is removed for that employee or batch.
- Late pickup / no-show. Start at detection. Stop at actual boarding time or confirmed alternate allocation with ETA inside an agreed SLA window for that shift band.
- Vehicle breakdown. Start at detection. Stop when all impacted employees are either boarded onto a replacement vehicle or safely handed over to another mode under EMS control, and updated ETAs are within SLA.
- GPS/app outage. Start at detection. Stop when location and trip state are reliably visible again for affected vehicles and the command center is no longer in blind mode for routing and safety decisions.
Make the metrics robust against “cosmetic” manipulation by tying them to raw system events.
Command-center tools, driver apps, and employee apps should generate immutable event logs and time stamps for scheduled times, GPS updates, login status, trip state changes, and alert creation and closure.
- Base MTTD on the gap between the *first abnormal system signal* and the *creation of a mapped incident in the command center*, not on when someone manually tags it later.
- Base MTTR on the gap between *incident creation* and the *system state change* that shows the commute risk is cleared (boarding confirmed, replacement vehicle assigned and moving, or platform uptime restored).
- Flag and separately report incidents where detection relied only on employee complaints or calls rather than telemetry, as these represent blind spots in monitoring.
Anchor MTTD/MRTR to EMS reality with a small, stable scorecard.
Most transport heads get value when MTTD and MTTR sit alongside OTP%, no-show rate, and route adherence on a single command-center dashboard, sliced by site, shift band, vendor, and route complexity.
- Use shorter MTTD as evidence that the command center, alert rules, and data-driven insights are doing their job by catching issues early.
- Use shorter MTTR as proof that SOPs, standby fleet buffers, driver management, and business continuity plans (for strikes, tech failures, weather) are working on the ground.
- Treat spikes in MTTD/MTTR as triggers for SOP reviews, driver retraining, vendor escalation, or route and buffer redesign, rather than as numbers to be “managed down” for reports.
From your experience, what usually causes those 3 AM escalations in employee transport, and how do stronger command centers prevent missed alerts or vendor non-response?
B1231 Preventing 3 AM escalations — In India enterprise-managed EMS, what are the most common escalation failure modes that create 3 AM calls (missed alerts, wrong severity, unclear ownership, vendor non-response), and how do mature command centers design escalation matrices to prevent them?
The most common 3 a.m. escalation failures in India enterprise EMS come from gaps in alert design and ownership. Mature command centers reduce night-time firefighting by standardizing what gets alerted, who owns each step, and how long any alert is allowed to stay “unseen” before it auto-escalates.
The first failure mode is missed or late alerts. This happens when GPS or apps fail, when transport desks rely on manual monitoring, or when there is no 24x7 command center. In mature setups, a Transport Command Centre or Centralized Command Centre runs 24/7 with live dashboards, automated alerts (geofence violations, overspeeding, device tampering, SOS), and defined monitoring shifts. Alert dashboards and an Alert Supervision System ensure no single person’s absence can cause a missed critical event.
The second failure mode is wrong severity classification. Low-priority issues trigger noise, while high-risk issues (night-shift women’s safety, breakdowns with multiple employees) do not get elevated. Mature command centers use pre-defined severity codes linked to specific triggers such as SOS activation, women travelling alone at night, repeated route deviations, or prolonged vehicle halt. Safety & Security for Employees and Women-Centric Safety Protocols are encoded into routing, SOS workflows, and command center SOPs, with clear treatment for high-risk scenarios.
The third failure mode is unclear ownership and vendor non-response. Issues fall between vendor operations, internal transport, and security because no one knows “who moves first.” Mature command centers implement a documented escalation mechanism and matrix that defines:
- First responder by alert type (driver, local supervisor, vendor control room, internal command center).
- Time-bound response SLAs for each severity level.
- Next-level escalation (N1, N2, KAM, senior leadership) if response is missing or incomplete.
- Parallel notification to Security/EHS for safety incidents and to HR for sensitive employee cases.
Another failure mode is fragmented data, which makes it hard to verify what actually happened. Mature command centers treat data as evidence. They maintain centralized trip logs, GPS trails, SOS event timelines, driver credentials, and call records through tools like centralized compliance management, safety dashboards, and CO₂ / KPI dashboards. This supports both live decision-making and post-incident audits.
Finally, there is the human failure mode: fatigue and improvisation on the night shift. Mature operations design micro functioning of the command centre with checklists, daily shift briefings, business continuity plans, and HSSE reinforcement tools. They train staff on SOPs for monsoon disruptions, strikes, technology failures, and cab shortages, backed by a Business Continuity Plan, so responses at 3 a.m. follow a playbook rather than ad-hoc decisions.
In practice, an effective escalation matrix in EMS combines four elements. It defines critical event types and severity. It assigns single-point ownership per event type with backup roles. It sets time-based auto-escalation logic. It anchors everything in a 24x7 command center with clear HSSE and compliance oversight. This design prevents missed alerts, reduces blame-shifting, and gives Facility/Transport Heads predictable control instead of night-long firefighting.
For night-shift women safety incidents like SOS or route deviation, what should the escalation matrix look like so HR, security, and the vendor know what to do in the first 5/15/60 minutes?
B1232 Matrix for night-shift safety — In India corporate EMS operations, what should an escalation matrix include for women’s night-shift safety incidents (SOS triggered, route deviation, unauthorized stop) so HR, security/EHS, and the vendor each know exactly what they own in the first 5, 15, and 60 minutes?
An effective escalation matrix for women’s night-shift safety incidents in Indian corporate EMS must define minute-by-minute ownership, decision rights, and evidence capture for HR, Security/EHS, and the transport vendor. The matrix should bind specific triggers (SOS, route deviation, unauthorized stop) to who acts in the first 5, 15, and 60 minutes, with clear handoffs to avoid gaps and blame-shifting.
In the first 5 minutes, the vendor command center and driver operations should own stabilization and verification. The vendor should acknowledge the SOS or deviation alert immediately, contact the driver on priority, and confirm employee status through the driver app or IVR. Security/EHS should receive an automatic alert with live location and trip details, and the system should auto-log the incident in an auditable trail. HR’s role in this window should be passive notification only, avoiding parallel instructions that can confuse on-ground response.
By 15 minutes, Security/EHS should own risk control and external coordination. Security/EHS should decide on escalation to company security at site, local police, or escorts based on location and severity, using real-time GPS and geo-fencing data. The vendor should execute instructions, dispatch backup vehicles if required, and maintain continuous communication with the driver and employee. HR should own internal communication to the employee’s manager if shifts or attendance will be affected, while ensuring no pressure is put on the employee to continue the trip.
By 60 minutes, HR should own employee welfare and documentation, and Security/EHS should own incident closure and root cause framing. HR should confirm safe arrival at a verified location, offer counseling or support if needed, and ensure no retaliation or attendance penalty. Security/EHS should lead a documented incident review with vendor participation, locking trip logs, GPS traces, and call records as evidence. The vendor should submit a written incident report and corrective actions that can be linked to driver compliance, training refreshers, route approvals, or vendor penalties.
For operational clarity, the escalation matrix should explicitly map for each trigger and time band: who is primary owner, who is backup, what exact actions are mandatory, what information must be captured, and which SLAs apply (for example, vendor response within 2–3 minutes, Security/EHS risk decision within 10–15 minutes). The matrix should integrate with the SOS control panel, command center dashboards, and women-centric safety protocols so the control room can follow a single SOP at 2 a.m. without improvisation.
If the app or GPS data goes down, how do you keep pickups running—what are the backup SOPs for manifests, OTP checks, and driver-rider communication?
B1233 Backup SOPs for app/GPS outage — In India corporate ground transportation for EMS, how do command centers handle partial outages—like rider app downtime or GPS feed gaps—while still keeping pickups moving, and what backup SOPs should exist for manifests, OTP verification, and driver-rider communication?
In Indian corporate EMS operations, resilient command centers keep pickups moving during partial outages by switching from app-first workflows to pre-defined manual and semi-manual SOPs. Command centers treat rider app downtime, GPS loss, or telematics gaps as “degraded mode,” not “stop operations,” and rely on alternative manifests, independent communication channels, and paper or spreadsheet-based controls to protect OTP, safety, and auditability.
During rider app downtime, command centers usually shift to an operator-driven dispatch mode. They use pre-generated rosters and route plans from the last synchronized data pull to brief drivers and verify assignments. They activate IVR, SMS, call-center, or WhatsApp-based communication so employees still receive vehicle details, reporting times, and escalation contacts. This reduces dependence on live app UX while sustaining shift adherence.
When GPS or live location feeds fail, command centers fall back to call-based check-ins and time-stamped status logging. Supervisors capture “departed from hub,” “employee boarded,” and “dropped” events via phone or radio and update a central log or dashboard once connectivity permits. Route adherence audits and incident reconstruction later use this log as a compensating evidence trail.
Backup SOPs for manifests, OTP, and communication should be explicit, drilled, and auditable. Key elements typically include:
- Manifests: Pre-cut, timeband-wise trip manifests exported before peak shifts. Copies kept at the command center and with drivers. Changes (adds/drops) recorded through a controlled ticket or call process with time stamps.
- OTP / identity verification: A fallback verification rule, such as last four digits of registered mobile, employee ID, or pre-shared numeric code sent via SMS or email if in-app OTP fails. Command center logs each manual verification for audit and women-safety compliance.
- Driver–rider communication: Masked calling via telephony gateway or centrally dialed three-way calls when in-app calling is unavailable. Clear rules on who calls whom, how often, and what is allowed to be shared, to stay DPDP-compliant and avoid ad-hoc number sharing.
- Escalation and safety: A parallel SOS/escalation path through the command center phone lines and security desk, with incident tickets created manually if in-app SOS flows are unavailable.
Most mature EMS programs also define reversion triggers and “all-clear” procedures. That includes a threshold for declaring degraded mode, assigning additional command center staff during outages, and backfilling missing GPS or trip data into the trip ledger once systems recover. This preserves audit trails for safety, compliance, and billing, even when real-time systems fail temporarily.
What’s a realistic 24x7 NOC staffing plan for employee transport, and what signs tell us the command center is under-resourced and will turn into daily firefighting?
B1234 24x7 NOC staffing reality — In India enterprise EMS, what is a realistic staffing model for a 24x7 mobility NOC (shift patterns, skill mix, supervisor-to-agent ratio), and what warning signs indicate the command center is underpowered and will become a firefighting bottleneck?
A 24x7 mobility NOC in Indian enterprise EMS typically runs on three shifts with a blended team of routing planners, trip controllers, incident handlers, and a lean leadership layer. A realistic structure keeps supervisor‑to‑agent ratios around 1:6–1:10 on busy shifts and ensures at least minimal dual coverage (operations + tech/dispatch) even on thin night bands. Persistent reactive calls, growing manual workarounds, and rising escalation volume are reliable early signs that the command center is underpowered and heading toward firefighting mode.
For a mid–large EMS program, most organizations stabilize around three 8‑hour shifts. Peak office commutes need heavier staffing. Night shifts need smaller but more experienced teams with clear women‑safety and incident SOPs. A healthy mix usually includes command center executives for roster and routing execution, dispatchers for live-trip control, an incident or safety desk for SOS and geo‑fence breaches, and a duty manager or shift lead accountable for decisions and escalations. Centralized dashboards and alert supervision systems reduce load per agent and keep ratios sustainable.
A common failure mode is loading the NOC only with junior call handlers. That pattern breaks when hybrid rosters, EV range issues, or weather disruptions demand real routing decisions rather than just answering phones. Underpowered NOCs show specific warning signals such as increasing SLA breaches with no root‑cause analysis, frequent “all hands” nights after predictable events like monsoon or political rallies, rising dependence on manual spreadsheets despite having a platform, and growing complaint loops where the same issues reappear every week.
Clear indicators that a command center will become a bottleneck include:
- Escalations jumping straight from drivers or employees to HR or leadership because NOC closure is slow.
- Safety alerts, geo‑fence violations, or women‑centric protocols monitored only “when free,” not with dedicated coverage.
- No documented BCP playbooks for cab shortages, tech downtime, or city‑wide disruptions, forcing ad‑hoc decisions on every incident.
- Supervisors covering more than 10–12 agents on peak shifts, which quietly pushes them into ticket chasing instead of forecasting and prevention.
How should we set Sev1–Sev4 levels for commute incidents so we don’t escalate everything, but we also don’t miss the issues that later blow up to leadership?
B1235 Right-sizing severity levels — In India corporate EMS vendor governance, how do you structure severity levels (Sev1–Sev4) for commute incidents so the command center doesn’t either over-escalate everything or ignore issues that later become leadership escalations?
In corporate employee mobility in India, commute incidents are best structured into four severity levels by tying each level to impact on safety, continuity of service, and audit visibility, not just “how loud the complaint is.” A clear Sev1–Sev4 grid gives the command center a script to follow at 2 a.m. so they neither flood leadership with noise nor miss patterns that later explode.
A common failure mode is defining severity purely by who is complaining or which site is involved. A better approach is to classify incidents by objective signals like physical harm or threat, number of employees affected, shift adherence risk, and whether statutory or women-safety protocols are breached. This keeps vendor governance and escalation decisions defensible to HR, Security, and auditors.
A practical structure that aligns with EMS operations, safety, and BCP is:
- Sev1 – Critical safety or mass disruption. Any physical assault or credible threat, serious accident, missing employee, major women-safety breach, or outage that blocks a full shift (for example, systemic app failure or large fleet breakdown). Command center triggers emergency SOP, notifies Security/EHS and HR immediately, invokes Business Continuity Plan buffers and backup vendors, and starts an audit-ready incident log.
- Sev2 – High impact, time-bound risk. No physical harm yet, but high risk to safety or operations. Examples include breakdowns on unsafe stretches, repeated geo-fence violations, chronic OTP failure on a critical site, or partial app or GPS failure affecting a cluster of routes. Command center reroutes or replaces vehicles in real time, informs transport and vendor management, and creates a ticket that must close with RCA and corrective actions.
- Sev3 – Contained operational failure. Localized issues like a single no-show driver, wrong routing for a small group, non-critical breakdown with safe waiting area, or app glitches where manual fallback is working. These are handled at the shift level by the command center and vendor, captured in daily shift reports and route adherence audits, and only escalated if they repeat beyond a defined threshold.
- Sev4 – Noise, defects, and early-warning signals. Individual complaints on driver behavior without safety breach, minor ETAs within SLA buffers, app usability issues, or isolated vehicle condition concerns. These feed into weekly vendor scorecards, driver coaching, and compliance checks, and they only move up the stack if they cluster by route, driver, or timeband.
To stop over-escalation, organizations need a single command-center playbook that maps incident types to Sev levels, required responders, and closure SLAs. To stop under-escalation, they need data-driven triggers that auto-promote patterns, such as “X Sev3 OTP failures on the same route in a week become Sev2,” or “any repeat women-safety complaint against the same driver becomes Sev1 for that driver and vendor.”
As IT, how can we confirm the alerting/escalation setup is truly resilient—redundant channels, no single point of failure—and won’t collapse during peak incidents?
B1236 Validating escalation system resilience — In India corporate ground transportation for EMS, what’s the best way for a CIO to validate that the command center’s alerting and escalation system is resilient (no single point of failure, redundant channels, graceful degradation) rather than a fragile workflow that collapses under peak incidents?
In corporate employee mobility in India, a CIO validates command-center alerting resilience by treating it as a production-grade critical system and demanding observable, tested behaviour under failure and peak-load conditions, not just architecture diagrams. The command-center stack is resilient when alerts still reach the right people, within defined time limits, even if one application, network path, or notification channel fails.
A fragile workflow usually reveals itself when GPS feeds drop, apps glitch, or multiple SOS or incident tickets fire at once and the NOC reverts to manual calling trees. A resilient alerting and escalation setup shows consistent closure SLAs, auditable incident trails, and no material rise in exception latency during storms, political strikes, or tech outages that affect Employee Mobility Services (EMS) at scale.
For validation, most CIOs insist on end-to-end tests that simulate real EMS scenarios rather than unit tests. Typical scenarios include device tampering alerts, geofence violations, over-speeding, night-shift SOS events, and routing failures that impact on-time performance. The CIO checks whether these events automatically create tickets, follow a documented escalation matrix, and reach both command-center operators and on-call transport or security leads through redundant channels such as in-app notifications, SMS, voice, and email.
A practical CIO review usually focuses on four areas. The first is architecture and topology, checking that the alert engine, notification gateway, and ticketing or ITSM are logically separated and that there is no single point of failure such as one cloud region, one SMS provider, or one database node for all signals. The second is integration behaviour, confirming the routing engine, GPS/telematics, HRMS integration, and SOS APIs can fail or degrade without stopping alerts altogether.
The third area is observability and metrics. A resilient system exposes latency and failure rates for alerts, escalation success ratios, and exception detection-to-closure times in real time. It also maintains immutable audit logs so Security and EHS can reconstruct any incident against EMS SLAs and duty-of-care obligations. The fourth area is operational drill evidence. Here, the CIO looks for scheduled failure and load drills during peak EMS windows, such as shift changes or monsoon disruptions, with documented outcomes and corrective actions tracked over time.
Without these architectural separations, multi-channel notification paths, and rehearsed failure drills, a command-center alerting workflow is effectively a fragile script. It works on quiet days but collapses when EMS operations face the very conditions—storms, strikes, or system failures—where command-center resilience matters most.
If a vendor says their system is ‘self-healing’ and cuts night escalations, what should we test in a pilot—auto reassignment, fallback dispatch, automated calling—to prove it reduces 3 AM calls?
B1237 Proving “self-healing” in pilots — In India corporate EMS, when a vendor claims “self-healing” operations that reduce night escalations, what specific behaviors should operations test in a pilot (auto-reassignment, automated IVR, fallback dispatch rules) to ensure it genuinely reduces 3 AM calls?
In India corporate EMS, “self-healing” operations only reduce 3 a.m. escalations when the platform consistently auto-detects common failure patterns and executes predefined fallback rules faster than a human can react. Operations teams should therefore test very specific real-world behaviors during pilot, rather than accepting generic automation claims.
The first focus area is auto-reassignment. Operations should simulate driver no-shows, app logouts, and GPS drops during night shifts and observe whether the system automatically reassigns trips from a standby pool without manual intervention. Teams should check if reassignment respects roster rules, women-safety constraints, and duty-cycle limits so that “fixed” trips do not create new compliance breaches. A critical behavior is how quickly the system updates riders, drivers, and the command center with new ETAs and vehicle details.
The second focus area is automated IVR and notification flows. Operations should deliberately trigger delayed ETAs and route deviations to see if the system auto-dials or messages affected employees, drivers, and floor managers. The pilot should validate that IVR messages are shift-aware, language appropriate, and integrated with escalation matrices, rather than dumping all calls on one transport SPOC.
The third focus area is fallback dispatch and routing rules. Teams should test how the system behaves under partial tech failure, such as app downtime or GPS instability, and confirm there is a documented manual override mode. Command center staff should verify that NOC alerts, exception dashboards, and business continuity playbooks (including buffer vehicles and alternate vendors) are automatically kicked in and that all actions retain an auditable trail tied to OTP, incident SLAs, and safety protocols.
images:
images:
How do we design escalation so there isn’t back-and-forth between vendor, NOC, security, and HR when a late pickup is going to cause attendance issues?
B1238 Avoiding escalation ping-pong — In India corporate EMS, how should a transport head design escalation pathways that avoid ‘telephone tag’ between fleet vendor, command center, site security, and HR when a late pickup risks attendance and manager complaints?
Transport heads in Indian corporate EMS avoid “telephone tag” by predefining a single command pathway, time-bound escalation tiers, and clear role ownership that all parties follow during any late-pickup risk. A working pattern is to make the transport command center the single source of truth, automate alerts from the mobility platform, and assign fixed SLAs for response and communication at each escalation level.
The command center should receive the first signal. The trigger can be automated ETA variance from the routing engine or a rider/driver app alert. The command center then validates GPS, driver status, and roster details using tools like the Transport Command Centre dashboard, Alert Supervision System, and centralized compliance views. This avoids parallel calls from HR, site security, and vendors to the same driver.
Once validated, a time-boxed escalation ladder is required. In the first few minutes, the command center coordinates only with the vendor operations contact and the driver. If resolution fails within a defined threshold, the issue moves up to the vendor’s duty manager and the internal escalation matrix (transport shift lead, then transport/Facility Head). HR and site security are notified through standard templates only after mitigation steps are in motion, not as additional “callers.”
Clear information channels reduce noise. Employees should receive all updates via the employee app SMS or notifications. Managers should receive only exception summaries when attendance risk is real. HR and Security should see issues in a shared dashboard or daily exception report instead of ad hoc calls. Most organizations use SOPs aligned with Business Continuity Plans and Command Center micro-functioning charts so that late pickups follow the same playbook as weather or strike disruptions.
A practical design includes:
• One escalation matrix for EMS, shared with vendor, HR, and Security.
• Defined ownership per minute-band (0–5, 5–15, 15+), tied to OTP and incident SLAs.
• Command-center-led communication to employees and managers, never driver-led.
• Post-shift review using indicative management reports to refine thresholds, vendor performance, and routing rules.
From an HR standpoint, what proof should we ask for that the NOC can produce an audit-ready incident timeline—actions, timestamps, call logs/recordings, and trip data—after a safety escalation?
B1239 Audit-ready incident timelines — In India corporate Employee Mobility Services (EMS), what evidence should HR ask for to be confident the command center can produce audit-ready incident timelines (who acted when, call recordings or logs, trip telemetry snapshots) after a safety escalation?
In corporate Employee Mobility Services in India, HR should insist on concrete, system-level evidence that the command center can reconstruct an incident as an audit-ready timeline. HR should not rely on verbal assurances. HR should ask to see how trip telemetry, alerts, and human actions are captured, time-stamped, and stored in one place.
HR leaders should demand proof that the command center maintains a unified trip ledger. This trip ledger should link rider and driver identity, vehicle details, route plan, GPS trace, SOS or panic events, and all deviations. The ledger should show pre-trip checks, trip start, intermediate geo-fence crossings, and trip close-out as separate, time-stamped events. This is essential for reconstructing what actually happened for a specific employee and shift.
HR should verify that there is a real 24/7 command center or Transport Command Centre (TCC). HR should ask for a walk-through of live dashboards that show trip-level status, alerts, and escalation queues. HR should confirm that every escalation creates a ticket in an alert supervision or incident management system, with status changes and owner reassignment captured in logs. Each ticket should retain the chain of custody from first alert to closure.
HR should check that call handling is integrated into this command framework. HR should ask whether the command center can produce call records or logs that show who called whom, at what time, and for how long. If full recordings are not available, HR should at least require structured call-log entries attached to trip or incident IDs. These call logs should include reason for call, action taken, and resolution notes.
HR should test if trip telemetry snapshots are available on demand. HR should ask for a demonstration where the vendor pulls up a past trip and shows the route, speed, stoppages, and time-stamped deviations. This test should include SOS activation, geo-fence violation, or over-speeding alerts where applicable. HR should check that these snapshots can be exported in a form suitable for investigations and compliance reviews.
HR should ensure that safety events for women and night shifts are specifically tagged. HR should confirm that the system distinguishes female-first routing, escort compliance, and night-shift trips. This tagging should allow filtered reports for women-safety audits and rapid retrieval of evidence if a gender-specific incident is escalated.
HR should ask about data retention and audit policies. HR should verify how long trip logs, GPS traces, and incident records are retained. HR should look for defined retention schedules that align with internal policies and regulatory expectations. HR should ask how the vendor protects the integrity of these logs against tampering or deletion.
HR should request sample redacted incident reports from other clients. These samples should show timestamped sequences of events, including alerts, command center actions, driver interactions, and final closure. HR should evaluate whether these reports would satisfy internal audit, legal, and EHS requirements if a serious incident occurred.
HR should also check for alignment between the command center and other governance structures. HR should confirm that escalation matrices, safety and compliance dashboards, and user satisfaction indices are connected to the same underlying incident and trip data. This alignment improves traceability and reduces the risk of fragmented records during investigations.
images:
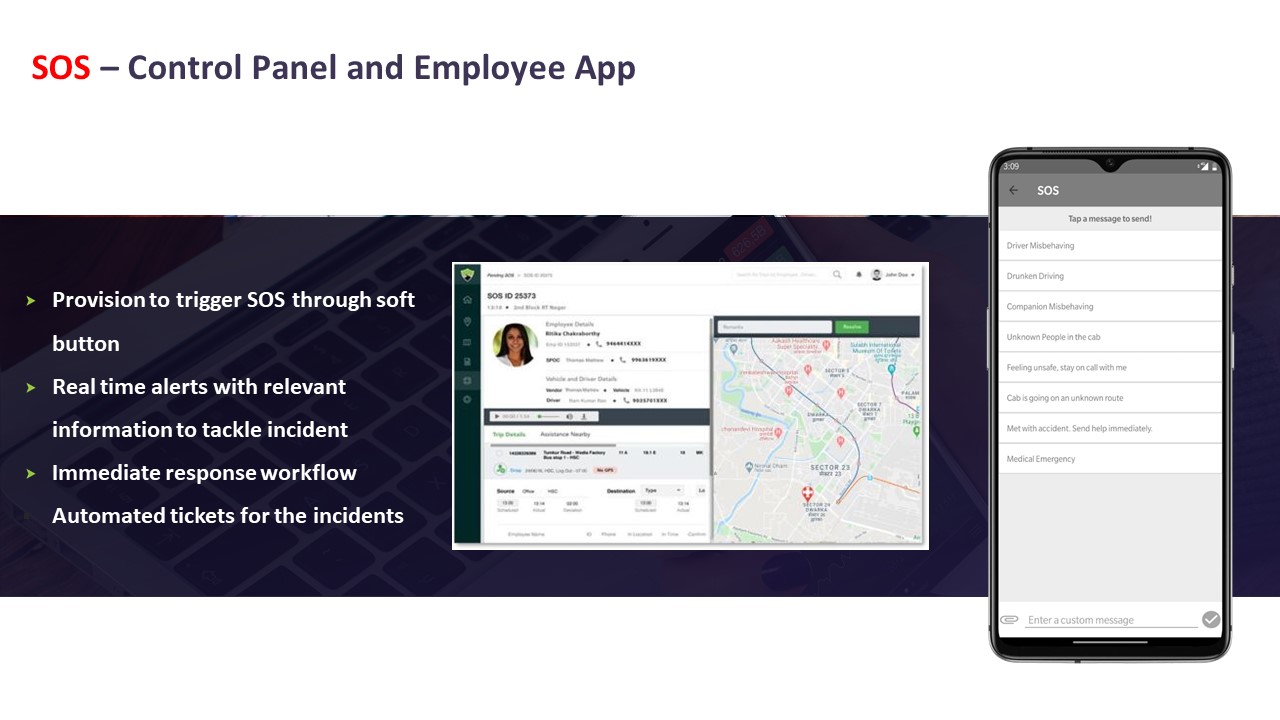
Resilience, outages, backup SOPs, and multi-vendor accountability
Outlines backup procedures, cross-vendor escalation clarity, and audit-proof recovery steps to keep moving during platform or feed outages.
With DPDP in mind, what should legal and IT check about what the NOC can view and store during escalations—location data, call recordings, SOS info—so we don’t over-collect but still meet duty of care?
B1240 DPDP limits for escalation data — In India corporate EMS under DPDP expectations, how should legal and IT evaluate what the command center is allowed to see and store during escalations (live location, call recordings, SOS metadata), and how do you prevent over-collection while still protecting duty of care?
In Indian corporate employee mobility programs, legal and IT should allow command centers to see and store only what is strictly necessary for safety, SLA governance, and incident response during escalations, and they should time‑box and role‑limit that visibility. Over‑collection is prevented when every data element (live location, call audio, SOS metadata) has a documented safety purpose, a defined retention period, and is shielded behind role‑based access with audit logs under a written DPDP‑aligned policy.
A practical approach is to treat the command center as a controlled “processor” for safety and service operations. Live location and trip status are justified for duty of care, OTP, and emergency routing, but recording and long‑term storage are not justified unless they support a defined incident workflow. SOS events can surface enhanced data for a short escalation window, after which visibility reverts to minimal trip history. Call recordings and detailed incident notes should be explicitly classified as “evidence,” with strict need‑to‑know access and clear destruction timelines.
Legal and IT should co‑design a simple decision matrix for each data type that specifies lawful purpose, who can see it during normal operations versus an SOS, how long it is retained, and how it is anonymized for reporting. Over‑collection is further reduced when dashboards focus on KPIs and exceptions instead of raw feeds, and when vendor systems support role‑based views, central audit trails, and exportable evidence packs only for genuine incidents, not routine monitoring.
What would a one-click ‘panic button’ report look like for our commute command center—what fields should we be able to pull instantly for auditors or leadership (incidents, response times, closure proof)?
B1241 One-click compliance reporting needs — In India corporate ground transportation for EMS, what does a ‘panic button’ compliance report look like for the command center—what fields must be instantly retrievable when auditors or internal leadership ask for incident counts, response times, and closure proof?
A panic-button compliance report for EMS command centers in India must reconstruct every SOS event end-to-end in an auditable, time-stamped trail. The report must let leadership and auditors see how many incidents occurred, how fast the system and team responded, what actions were taken, and how each case was closed and verified.
At minimum, each panic-button event record should expose four groups of fields in a single view or drill-down.
1) Incident identity and context
These fields anchor the SOS in time, place, and shift context.
They should include:
• Unique incident ID and trip ID.
• Date and exact timestamps for trip start and SOS trigger.
• Employee ID, name masked as per policy, department, and gender flag.
• Vehicle ID, registration number, and driver ID.
• Route details, including origin, destination, planned route, and geolocation of SOS trigger.
• Shift band and whether it was a women-only or women-first trip.
2) Detection and response timing
These fields prove system responsiveness and human reaction time.
They should include:
• System detection timestamp for SOS raised in the app or IVMS.
• Command center acknowledgement timestamp.
• First outbound action timestamps, such as call-to-driver, call-to-employee, alert to security, or escalation to local supervisor.
• SLA benchmarks configured for SOS response and actual response time deltas.
3) Actions taken and escalation path
These fields show the playbook in action and chain-of-custody.
They should include:
• List of actions taken in chronological order, with timestamps and operator IDs.
• Contact attempt logs for employee, driver, and any escort, including outcome status.
• Escalation ladder used, for example site security, EHS, HR duty officer, or external agency.
• Any route change, vehicle stop, replacement vehicle dispatch, or police notification, with corroborating GPS traces.
4) Outcome, evidence, and closure
These fields provide closure proof and support post-incident analysis.
They should include:
• Final outcome status, such as false alarm, resolved on-call, trip completed safely, or incident escalated.
• Closure timestamp and closure owner in the command center or security function.
• Brief root cause and incident category coding for analytics.
• Links to retained evidence, including GPS trail snapshots, audio call logs if policy allows, and internal tickets or case notes.
• Whether HR, Security/EHS, or leadership were notified and when.
• Whether corrective or preventive actions were created, such as driver coaching, route restriction, or policy update.
At a portfolio level, the panic-button compliance report should also aggregate and filter these incident records by site, shift band, vendor, route cluster, and month, so leadership can see counts, average response times, SLA breaches, and repeat-risk patterns without losing drill-down access to the underlying trip and incident logs.
How can procurement turn NOC performance into practical SLAs—like MTTD/MTTR and acknowledgment times—without creating a contract that’s unmeasurable or causes monthly disputes?
B1242 Contracting escalation SLAs — In India corporate EMS, how should procurement translate command-center performance into enforceable SLAs (MTTD/MTTR thresholds, escalation acknowledgment times, outage SOP adherence) without creating a contract that is impossible to measure or disputes every month?
In India corporate EMS, procurement should translate command‑center performance into enforceable SLAs by tying only a few clearly defined time‑bound metrics (MTTD, MTTR, escalation acknowledgment, outage playbook steps) to data that already exists in the mobility platform and NOC tools and by standardizing how those metrics are measured and sampled. Procurement avoids monthly disputes when every SLA clause has an explicit data source, unambiguous start/stop triggers, and a limited set of penalties that are only applied after joint validation.
Procurement teams should first define what the EMS command center owns in the trip lifecycle and incident lifecycle. Each SLA should map to a discrete stage such as alert detection in the NOC, first response to an SOS, re‑routing after a vehicle breakdown, or communication to HR and security during an outage. A common failure mode is bundling OTP, routing, and safety into a single vague “command‑center SLA,” which becomes impossible to audit consistently.
Command‑center SLAs work best when they are grounded in the existing observability stack. Data sources should include telematics dashboards, SOS and alert supervision systems, ticketing or ITSM tools, and centralized command‑center logs. These tools already capture timestamps for alert creation, acknowledgment, assignment, and closure, so MTTD and MTTR can be calculated from system events rather than from emails or spreadsheets. Automated audit trails, as seen in centralized dashboards and alert supervision collateral, reduce arguments about “who knew what when.”
To keep contracts measurable and practical, procurement should limit command‑center SLAs to a small core set and avoid over‑engineering. Typical examples are:
• Mean Time To Detect (MTTD) for critical incidents based on system alerts.
• Mean Time To Respond/Recover (MTTR) against pre‑defined incident types such as missed pickup, GPS loss, or vehicle breakdown.
• Escalation acknowledgment time to HR, security, or facility heads for safety‑classified events.
• Adherence to documented outage and business continuity SOPs, evidenced by logs and BCP reports.
Dispute risk drops when the contract specifies sampling rules and tolerance bands. Procurement should define monthly measurement windows, minimum incident counts needed for SLA evaluation, and grace thresholds where minor deviations trigger joint RCA instead of automatic penalties. A common failure mode is applying penalties on very small samples, which creates volatility and friction. Setting performance bands that distinguish between green, amber, and red performance states allows procurement and operations to reserve financial penalties for persistent or material deviations while using governance meetings for marginal misses.
Contracts should also embed a clear governance cadence instead of pushing all disagreement into legal language. Procurement can require monthly or quarterly SLA review meetings where command‑center dashboards, incident reports, and BCP execution evidence are jointly reviewed. This aligns with integrated command‑center and business continuity collateral that emphasize structured governance, escalation matrices, and management reporting. Disputes are reduced when the vendor and client agree on the numbers during these sessions before any penalties are applied.
Finally, procurement should explicitly separate non‑negotiable safety and compliance triggers from performance‑optimization metrics. Safety‑critical failures, such as SOS non‑response or women‑safety protocol breaches, can have stricter MTTR thresholds and direct escalation to senior stakeholders. Operational metrics such as minor routing exceptions or short app outages can sit in improvement plans and benchmarking. This layered approach keeps the contract enforceable and audit‑ready while avoiding a situation where every variance in command‑center behavior becomes a commercial dispute.
If we have multiple fleet vendors across sites, how should the central NOC run escalations so accountability stays clear—even when a subcontractor caused the issue?
B1243 Accountability with multi-vendor escalations — In India corporate EMS operations, when multiple fleet vendors serve different sites, how should the central command center run escalations so accountability is clear (single throat to choke) even when the root cause sits with a subcontractor?
In India EMS operations with multiple fleet vendors, a central command center should own a single, standardized incident and escalation workflow, but map every step to named roles, SLAs, and evidence so vendor‑side accountability is traceable and enforceable. The command center must act as the single operational owner toward HR and leadership, while its tooling, SOPs, and governance isolate which subcontractor failed, when, and how often.
A centralized Transport or Mobility Command Centre typically runs 24/7 monitoring, triage, and escalation across all vendors. The command center uses a unified dashboard, geo-fencing, alert supervision, and incident ticketing to capture each exception in one system instead of fragmented vendor logs. Each ticket is tagged with vendor ID, driver, vehicle, route, timeband, and site, which creates an audit trail that survives vendor disputes and leadership queries.
Clear escalation matrices are essential for “single throat to choke” without ambiguity. The command center should maintain a documented escalation mechanism that defines Level 1–N2 roles across both its own team and each vendor, with response and resolution SLAs tied to OTP, safety, and compliance outcomes. The matrix needs to specify who answers at 2 a.m., what the maximum response time is, and when the issue is pulled from the vendor and handled directly via standby cars, backup partners, or BCP buffers.
To prevent blame-shifting when root cause sits with a subcontractor, the master contract and vendor governance model should be outcome-based. The enterprise recognizes one primary managed mobility provider or one consolidated EMS governance layer, which is responsible for vendor onboarding, driver and fleet induction, centralized compliance checks, and business continuity plans. That primary provider then flows penalties, retraining, or vendor rebalancing downwards based on performance data from the command center, such as OTP%, incident rate, and audit scores.
The central command center must also link escalations to continuous improvement, not only firefighting. Exception reports, management dashboards, and periodic QBRs should aggregate which vendors, routes, or timebands generate the most escalations. Those insights then feed into vendor tiering, capacity buffers, EV/ICE fleet mix decisions, and safety or driver training interventions. Over time, this tight loop makes accountability evident in measurable trends rather than post‑factum arguments.
images:
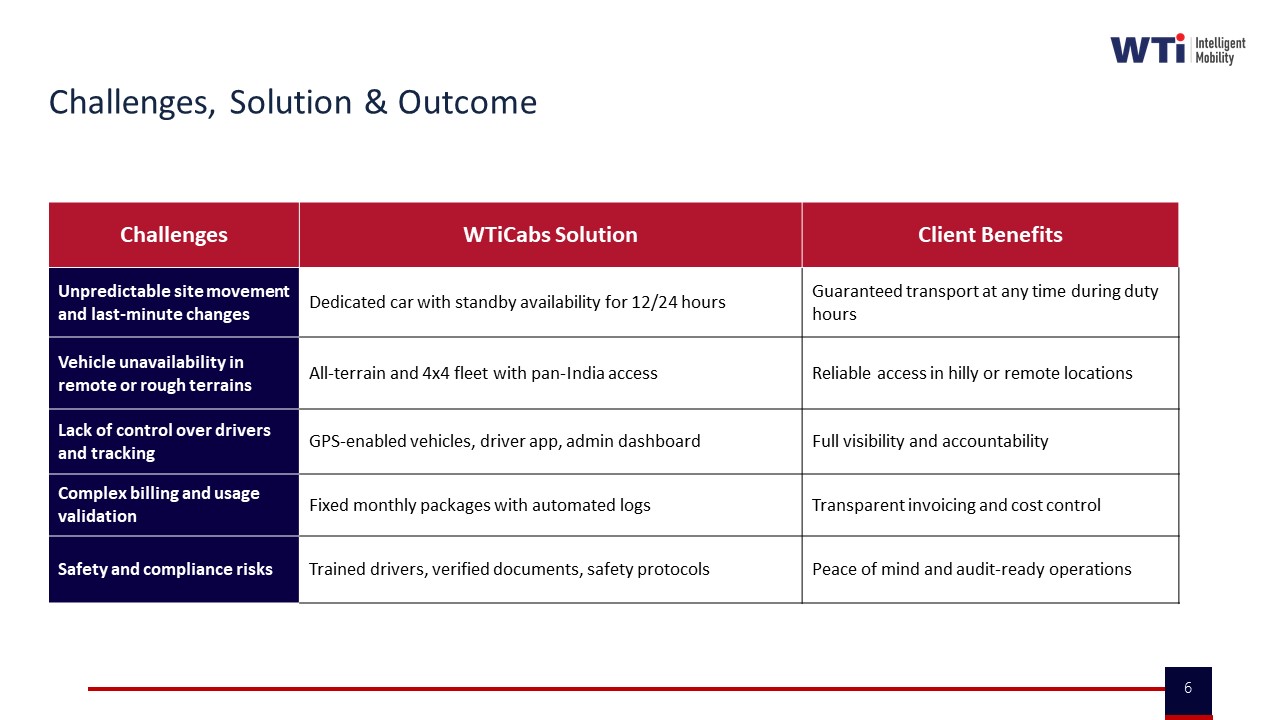
After a major commute incident, what should the RCA process include—evidence retention, tamper-proof logs, corrective actions—so we actually prevent repeats instead of just blaming someone?
B1244 RCA that prevents repeats — In India corporate ground transportation for EMS, what should a post-incident RCA process include (evidence retention, tamper-evident logs, corrective actions, follow-up audits) so escalations result in fewer repeats rather than a recurring blame cycle?
A post-incident RCA process in Indian EMS works best when it is evidence-led, tamper-evident, and explicitly tied to corrective actions, re-training, and follow‑up audits that are tracked by the command center and vendor governance. A strong process converts every escalation into structured learning, instead of a recurring blame loop between HR, Transport, vendors, and drivers.
A robust RCA process in EMS usually starts with immediate evidence capture. Transport command centers and NOCs should lock GPS traces, trip manifests, SOS and alert logs, IVMS data, and call-center recordings for the entire duty cycle. Systems should preserve original trip and routing data in a tamper-evident form so audit trail integrity stays defensible for HR, Security/EHS, and Internal Audit. Driver and vehicle compliance snapshots, including KYC/PSV currency and escort or women-safety compliance status, should be frozen against the time of incident.
Structured analysis needs to separate root causes across routing, fleet, driver behavior, and governance. Centralized dashboards and data-driven insight tools should be used to quantify factors like route adherence, OTP impact, dead mileage, and prior exception history for the same route, driver, or vendor. Security and EHS teams should map the incident to applicable HSSE roles, duty-hour norms, and women-safety policies to identify policy or execution gaps.
Corrective actions should be logged as specific, dated commitments. These often include driver coaching or re-induction, route or shift-window changes, vendor performance flags, or changes to safety controls such as escort rules and geo-fencing thresholds. EMS buyers typically expect these actions to feed back into governance structures like MSP command-center models, business continuity playbooks, and centralized compliance management programs.
Follow-up audits are critical to ensure the RCA does not remain on paper. Random route audits, spot checks on driver fatigue and credentialing, and targeted reviews of high-risk corridors or timebands should be scheduled and monitored. Command centers should maintain a continuous assurance loop, tracking whether similar exceptions reduce over time for that site, vendor, or shift pattern. HR, Transport, and Security leaders gain trust when they can show leadership not just a narrative of what went wrong, but trend lines demonstrating fewer repeats and improving service-level compliance after each incident.
As HR leadership, how do we test whether a vendor’s escalation process will protect us in a high-visibility safety incident—especially for women’s night shifts and internal social media blow-ups?
B1245 Escalations that protect employer brand — In India corporate EMS, how can a CHRO pressure-test whether a vendor’s escalation handling will protect employer brand during a high-visibility safety incident, especially around women’s night shifts and internal social media escalation?
In India corporate EMS, a CHRO can pressure-test a vendor’s escalation handling by treating “one serious women’s night-shift incident” as a live-fire drill and demanding proof of how the vendor detects, escalates, documents, and closes that incident end-to-end with audit-ready evidence. The CHRO should not accept generic “we have SOPs” but insist on walking through a concrete, time-stamped scenario that touches command-center operations, safety protocols, data trails, and communication flows to HR and leadership.
A common failure mode is that vendors describe escalation in abstract terms but cannot show a working safety escalation matrix, 24x7 command-center staffing, or how alerts move from driver app or SOS to Transport, Security/EHS, and HR in real time. Escalation handling often fails when there is no centralized command center, no predefined women-centric safety protocols for night shifts, and no ability to reconstruct the incident later for internal forums or investigations. Most organizations protect employer brand better when escalation is governed through a command-center model with clear roles, automated alerts, and business continuity plans, rather than ad-hoc vendor phone trees.
A CHRO can use a short, repeatable pressure-test checklist:
- Ask for a detailed escalation matrix specific to women’s night-shift transport, including names, roles, and time-bound SLAs for each level of escalation.
- Demand a live demo of the command center or Transport Command Centre view handling a mock SOS from a woman employee at night, including geofencing alerts, driver response, and escalation to security and HR within defined minutes.
- Review written safety and women-centric protocols, including driver selection and training, escort rules, route approvals, and how exceptions are logged and closed with root cause analysis.
- Verify the existence of a documented business continuity plan that covers political strikes, technology failures, natural events, and cab shortages during night shifts, and check who owns which mitigation actions.
- Insist on sample incident reports and audit trails from prior clients (with identifiers masked) that show timestamps, actions taken, communication to the employer, and closure notes.
- Check how employee apps and SOS features integrate with escalation: what an employee sees, how they trigger help, and how HR can later see a trace of what happened.
- Align with internal Security/EHS and IT teams to review whether incident data is centralized, tamper-evident, and retrievable for internal investigations and social media risk management.
A vendor whose escalation handling will genuinely protect employer brand usually demonstrates three characteristics. The vendor runs a 24x7 centralized command center with clear service-level targets for on-time response, safety monitoring, and incident handling. The vendor operates with codified safety frameworks that include women-centric safety protocols, driver compliance and induction, continuous training, and structured HSSE role-mapping across leadership, managers, associates, and drivers. The vendor has mature business continuity and contingency planning documents that map specific disruptions (from cab shortages to tech failures) to predefined mitigations and escalation responsibilities.
A CHRO can also scrutinize how the vendor turns escalation into measurable governance. Strong vendors provide dashboards for safety and compliance, centralized compliance management for vehicles and drivers, and user protocols and safety measures that explicitly define how women’s safety and night-shift obligations are handled. They also maintain structured tools for HSSE culture reinforcement and safety and compliance frameworks that define objectives, processes, and tools like IVMS, dashcams, and panic/SOS mechanisms. Weak vendors often cannot show this level of integration between safety operations, technology, and governance.
To protect employer brand during internal social media escalation, the CHRO should ensure that the vendor’s escalation model can support rapid, evidence-backed internal communication. This requires that all safety-related trips, alerts, and escalations are logged in a centralized system with clear timestamps, actions, and closure notes that HR can access quickly when leadership or employees raise questions. It also requires that user satisfaction and feedback mechanisms are integrated so that patterns of near-misses or repeated complaints are visible and can drive preventive action, not just reactive responses after something goes viral internally.
images:

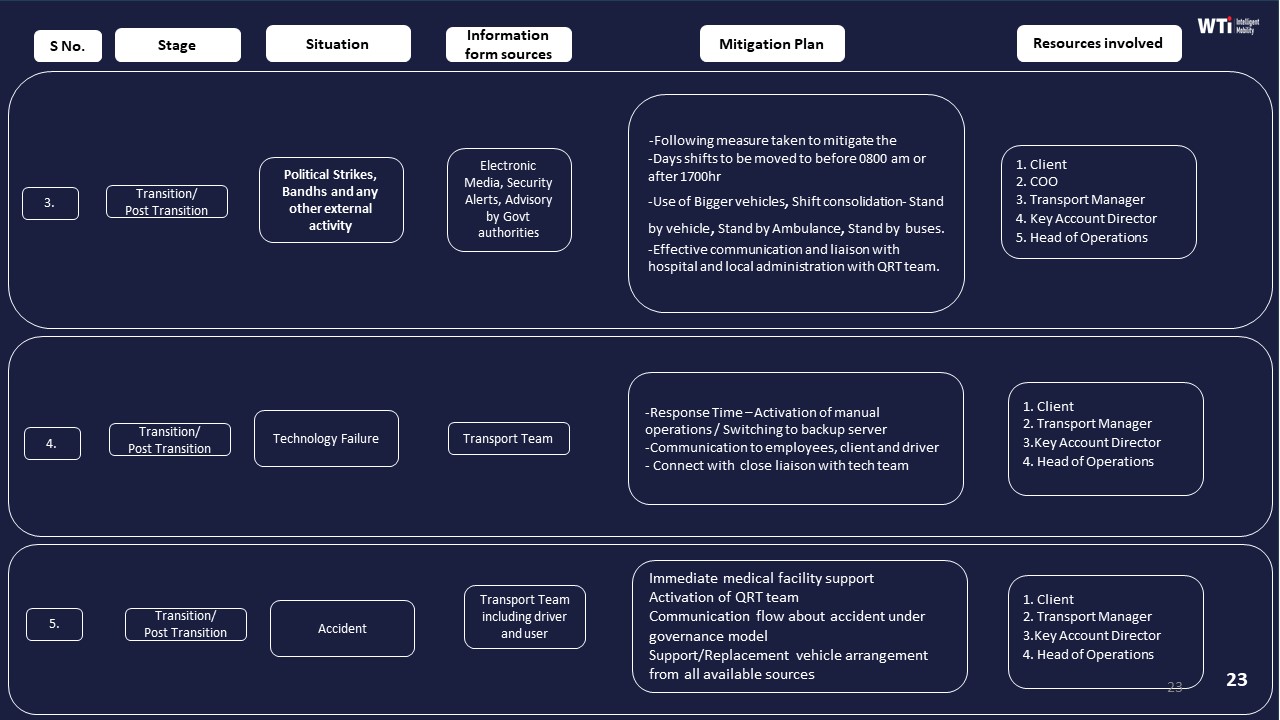
What are the real trade-offs between using the vendor’s 24x7 NOC vs running our own command center—cost, control, auditability—and where do these models usually fail under stress?
B1246 Vendor NOC vs enterprise NOC — In India corporate Employee Mobility Services (EMS), what are the operational trade-offs between a vendor-run 24x7 NOC versus an enterprise-owned command center (cost, control, auditability, escalation speed), and where do these models typically break under stress?
In India EMS, a vendor-run 24x7 NOC usually lowers direct cost and setup complexity but weakens deep control and auditability, while an enterprise-owned command center strengthens governance and evidence quality but raises fixed cost and internal overhead. Vendor NOCs typically stress-break on complex, multi-stakeholder incidents and policy nuance, while in-house centers often fail under scale, night-shift intensity, and technology upkeep if under-resourced.
Vendor-run NOC improves cost and speed of rollout because the operator reuses its command-center tooling, staff rosters, and playbooks across many clients. This model improves day‑to‑day escalation speed for routine issues but reduces client-side visibility into how decisions are made. Most organizations report better OTP% and fewer calls when vendor NOC is tightly integrated with routing engines, driver apps, IVMS, and SOS workflows. The main trade-off is reduced independence in SLA verification, women-safety compliance checks, and root-cause analysis.
Enterprise-owned command centers increase control, governance, and auditability because trip logs, alert trails, and SLA dashboards sit inside the enterprise data estate. This improves defensibility for HR, Security/EHS, ESG, and Internal Audit, especially around night-shift safety, DPDP-aligned data handling, and incident reconstructions. The trade-off is higher capex/opex, the need for 24x7 staffing, and more complex integration with routing engines, telematics, and EMS/CRD/ECS workflows.
A vendor NOC typically breaks under stress when there are overlapping crises across multiple clients, when city-wide disruptions demand client-specific BCP choices, or when escalation requires fast alignment with HR, Security, and Facilities. Failure modes include slow information flow to the client, generic playbooks that ignore local escort or shift rules, and weak, audit-ready documentation for serious incidents.
An in-house center typically breaks when attendance patterns and city footprints expand faster than staffing and process maturity. Common failure patterns include fragmented data from multiple vendors, inconsistent use of routing and alert tools, slow exception triage during monsoon, strikes, or app downtime, and operator fatigue during continuous night operations.
For Facility / Transport Heads seeking operational calm, a hybrid model is often most stable in practice. The vendor runs its own NOC for driver coordination, routing, and telematics, while the enterprise maintains a lighter governance command center that focuses on observability, safety exceptions, BCP triggers, and evidence packs for HR, Security, ESG, and Audit.
images:
How do we structure escalation updates so managers get clear ETAs and next steps without the NOC flooding everyone with inconsistent messages?
B1247 Clean communication during escalations — In India corporate EMS, how do you design escalation communications so frontline managers get accurate ETA and resolution updates without the command center creating more noise through inconsistent messaging?
In Indian corporate EMS, escalation communications stay accurate and low-noise when every incident follows one standard, command-center–driven workflow with clear roles, fixed message templates, and a single source of truth for ETAs and resolution status. The command center must act as the only “official channel,” pulling live data from routing, GPS, and vendor systems, and pushing structured updates on a defined cadence until closure.
Frontline noise usually comes from ad-hoc calls, multiple WhatsApp groups, and different people giving different ETAs. A centralized command center with an alert supervision system and escalation matrix stops this when each alert automatically opens a ticket, assigns an owner, and timestamps every status change. The same platform should feed a single dashboard for transport teams and supervisors, like the TCC and command centre models described in the collateral, so everyone sees the same trip status, ETA, and incident notes.
To keep messages consistent and useful instead of chaotic, most organizations standardize three things:
• A short set of severity levels with matching SLAs for first response and final resolution.
• Pre-approved message templates for each stage of the trip incident lifecycle (delay detected, ETA change, vehicle swap, resolved).
• A strict rule that only the command center (or defined local control desk) communicates official ETAs to frontline managers, HR, and security, with time-stamped updates.
This design improves OTP and reduces escalations because frontline managers stop chasing multiple sources for updates and instead rely on predictable, audit-ready communication tied to the same data that powers routing, safety, and compliance dashboards.
images:
What alert channels and acknowledgment tracking should we insist on—SMS/WhatsApp/email/voice—so escalations don’t fail if one channel goes down or someone misses a notification?
B1248 Redundant alert channels and ack — In India corporate ground transportation for EMS, what should IT and operations require around alerting channels (SMS, WhatsApp, email, in-app, voice) and acknowledgment tracking so escalations don’t fail due to a single tool outage or missed notification?
In India EMS programs, IT and operations should define multi-channel, stateful alerting with explicit acknowledgment tracking so that no single app, network, or person can silently drop a critical escalation. Every high-severity alert should fan out across at least two independent channels and require a logged “who saw what, when, and what they did” trail that can be audited later.
Operations leaders should insist that safety and service alerts from the command centre route simultaneously to in-app notifications, SMS or WhatsApp, and email for critical roles in the escalation matrix. Voice calling should be reserved as an automatic fallback for high-severity events or when digital acknowledgments are not received within a defined SLA window. This reduces dependency on a single channel and mitigates app downtime, data outages, or device issues.
IT should require the platform to maintain an internal alert state machine with explicit acknowledgment and escalation rules. Each alert should record creation time, delivery status per channel, first-viewed timestamp, and named user acknowledgment, with automatic escalation to the next level (e.g., supervisor, central command centre) if not acknowledged. These logs should feed the command centre dashboard and management reports so leadership can see mean time to acknowledge and close.
To keep night shifts calm rather than chaotic, organizations should define simple SOPs that link alert severity to required channels, response SLAs, and who is on the hook at each escalation level. This combines real-time observability from the command centre with clear human accountability, so no one has to rely on a single mobile app notification in the middle of the night.
How do we prevent alert fatigue in the NOC—deduping and correlating alerts, tuning thresholds—and how can we test this during peak-hour disruptions?
B1249 Preventing alert fatigue in NOC — In India corporate EMS, what operational controls should exist to prevent alert fatigue in the command center (deduplication, correlation, threshold tuning), and how do you verify those controls during peak-hour disruptions?
In India corporate EMS, command centers need tightly-tuned alert controls that suppress noise and surface only actionable, time‑bound risk. These controls include deduplication of repeated GPS and SOS events, correlation of multi-source signals into a single incident, and threshold tuning for speed, geo‑fence, and SLA breaches. Verification during peak‑hour disruptions depends on drill-based testing, real-time dashboards for deviations, and post‑event audits that compare alert streams to actual incidents and SLA outcomes such as OTP and safety metrics.
Alert fatigue usually arises when GPS pings, minor delays, or transient network glitches all raise the same priority alerts. Command centers that use structured alert supervision with geofence violation, device‑tampering, and over‑speeding alerts reduce noise when they define clear severity bands and escalation matrices. Effective controls correlate alert patterns with routing, driver behavior, and compliance status so that supervisors see one consolidated ticket per issue rather than multiple raw signals. Data-driven insights platforms and transport command centres provide single‑window visibility into deviations, safety events, and CO₂ metrics, which helps distinguish genuine risk from background noise.
Verification during peak congestion or weather disruptions requires defined SOPs. Teams should run scenario drills, simulate monsoon‑like traffic, and confirm that dynamic route optimization still maintains high on‑time arrival rates without flooding operators with warnings. During live disruptions, leaders should track alert volumes per hour, incident closure SLAs, and exception‑to‑ticket ratios on dashboards. After the peak, operations should run a short audit comparing trip logs, alert logs, and customer complaints to see how many alerts were duplicated, how many were missed, and whether escalation steps matched the business continuity and safety plans.
images:

From a finance view, how do we weigh spending on a stronger NOC/escalation setup against the cost of repeated OTP failures—productivity loss, attrition risk, penalties, and leadership time?
B1250 Business case for escalation investment — In India corporate EMS under tight budgets, how should a CFO compare the cost of investing in stronger command-center escalations versus the financial exposure of repeated OTP failures (lost productivity, attrition risk, penalties, and leadership escalation time)?
A CFO should treat command-center escalation investment as a risk hedge and compare its cost directly to the recurring, quantifiable losses from OTP failures. The decision turns on whether the fixed spend on stronger 24x7 command-and-control reduces variable losses in productivity, attrition-linked costs, SLA penalties, and leadership time more than it adds to the EMS budget.
A disciplined comparison starts with hard baselines. Organizations should quantify current OTP%, exception closure times, and the volume of missed or delayed trips in their existing Employee Mobility Services. Finance teams can then assign cost to each failure mode. Lost productivity links to late logins and shift slippage. Attrition risk links to commute dissatisfaction and night-shift fatigue. Penalties and credits link to SLA breaches in existing contracts. Leadership escalation time converts to cost using senior management hourly rates.
A common failure mode is under-pricing OTP risk by only counting visible penalties and ignoring second-order effects. Lost seat-fill on routes, elevated no-show rates, and manager time spent on daily firefighting are all recurrent costs. Higher driver churn and ad-hoc fixes such as last-minute spot bookings inflate per-trip cost and mask leakage.
Command-center escalation capabilities add cost but improve predictability. Structured escalation matrices, real-time alerts, and centralized NOC operations typically reduce exception latency and improve OTP, which lowers SLA breach rate and stabilizes cost per employee trip. Stronger observability also improves auditability, which lowers financial exposure in disputes with vendors and in internal or external audits.
For CFOs operating under tight budgets, the decision can be framed as a threshold test:
- Estimate annualized cost of a strengthened command center and escalation model.
- Estimate current annual financial exposure from OTP failures across productivity loss, penalties, attrition-linked rehiring costs, and leadership time.
- Require a conservative improvement assumption in OTP and exception closure, and project resulting savings.
If even modest OTP improvement and reduction in exception volume offset the command-center spend, the investment is financially defensible and also improves governance, ESG disclosure stability, and reputational resilience.
If our escalation matrix says one thing but the vendor dispatcher acts differently on the ground, what should our site supervisor do, and how do we prevent this ‘two command centers’ situation?
B1251 Resolving two-command-centers conflict — In India corporate ground transportation for Employee Mobility Services (EMS), what should a site transport supervisor do when the escalation matrix says one thing but the vendor’s on-ground dispatcher does another, and how do mature programs prevent this ‘two-command-centers’ problem?
In Employee Mobility Services in India, a site transport supervisor should treat conflicting instructions from the vendor dispatcher as a control-room risk, not a personal tussle, and anchor decisions on the client-approved SOP, escalation matrix, and safety rules. Mature programs prevent this “two-command-centers” problem by running a single governance model with a central command center, clear role boundaries, and vendor routing tightly aligned to enterprise-approved processes and SLAs.
In the moment, the supervisor should first freeze the live-risk. The supervisor should prioritize safety, women’s night-shift rules, and shift start-times over vendor convenience or cost. The supervisor should explicitly reference the agreed escalation matrix and service-level expectations that define who decides route changes, vehicle swaps, and no-show handling. The supervisor should log the conflict as an incident in a trackable ticket or shift report so HR, Security/EHS, and Procurement have evidence. The supervisor should escalate to the vendor’s account manager or central command center if the on-ground dispatcher continues to override SOP.
The underlying issue is fragmented control between the enterprise’s command room and the vendor’s local control. Mature EMS programs define a target operating model where a central 24x7 command center governs route approval, dynamic routing, and exception handling, and vendor dispatch tools work under those rules. Mature programs use documented engagement models, escalation matrices, and governance committees so disputes between matrices are resolved at QBRs, not at 2 a.m.
To prevent this pattern, organizations align vendor roles under a Managed Service Provider governance structure or equivalent model. The central command center sets single-source rosters, routes, and cut-off times, and site-specific desks execute within that framework. Vendor dispatchers are treated as an execution layer with defined decision rights and limits. Compliance dashboards, alert supervision systems, and transport command centers provide one version of truth on trips, OTP, and deviations.
Mature programs run daily shift briefings so supervisors, drivers, and dispatchers share the same instructions before each shift. They adopt transport operation cycles where every step from booking to billing is mapped and owned. Business continuity and on-time delivery plans pre-define who can override routes during disruptions. Vendor governance models, vendor and statutory compliance frameworks, and centrally managed KPIs give Procurement and HR the leverage to correct behavior when vendor teams drift from agreed SOP.
Well-run EMS operations use a single-window dashboard and command center as the authoritative control room. They design escalation matrices, HSSE tools, and safety and compliance processes so all on-ground actors answer to the same playbook. This reduces conflicting commands, protects the supervisor from blame, and turns daily firefighting into predictable, audited exception management.
What review cadence should we run for NOC performance—daily, weekly, monthly—so leadership feels in control and we stop doing ad-hoc explanations after every disruption?
B1252 Governance cadence for NOC KPIs — In India corporate EMS, what governance cadence should exist for command-center performance (daily standups, weekly incident reviews, monthly SLA governance) so leadership sees control without demanding ad-hoc explanations after every disruption?
In India corporate EMS, command-center performance is best governed through a fixed three-layer cadence. Daily standups handle live reliability and safety risks. Weekly reviews close incidents and systemic gaps. Monthly governance boards align SLAs, cost, and ESG outcomes with leadership expectations. A stable cadence reduces ad-hoc explanations because issues have pre-agreed forums, owners, and timelines for closure.
Daily, the command center should run short ops standups focused on upcoming shifts, route risks, driver availability, tech health, and open incidents. The goal is to catch OTP and safety risks early and to give the Facility / Transport Head a clear picture before night and peak shifts. Daily summaries should be visible to HR or Security in a simple dashboard so they never feel “surprised” the next morning.
Weekly, there should be structured incident and deviation reviews owned by Transport and Security/EHS. These meetings should examine safety flags, SOS events, GPS/app failures, repeated route issues, and driver fatigue or absenteeism. The output should be concrete corrective actions, updated SOPs for routing or escorts, and tickets for tech or vendor fixes, with clear owners and due dates.
Monthly, a formal SLA and governance review should take place with HR, Finance, Procurement, and ESG where relevant. This forum should focus on OTP%, incident rate, complaint closure SLAs, cost metrics like cost per employee trip, EV utilization, and carbon indicators. The command center should present a concise pack showing trends, root causes, and what changed in operations, so leadership sees control and progress rather than point-in-time excuses.
When HR and ops disagree on whether an escalation was handled properly, what objective evidence should the NOC provide—timelines, logs, actions—so it doesn’t turn into blame?
B1253 Aligning HR and ops on proof — In India corporate EMS, when HR and operations disagree about whether an escalation was handled ‘well enough,’ what objective artifacts and timelines should the command center provide to create shared understanding instead of personal blame?
In India corporate employee mobility, a well-run command center reduces blame by providing a fixed, documented “incident story” instead of opinions. The command center should expose timestamped artifacts that show what happened, when it was seen, what was done, and when it was closed, mapped to clear SLA timelines for acknowledgement, mitigation, communication, and closure.
The command center needs to anchor every escalation to a unique incident ID. It should tie that ID to the trip ledger, GPS route, driver and vehicle compliance status, and alert streams from systems like the Alert Supervision System, SOS panel, or geo-fence violation monitors. This helps HR see duty of care evidence, and helps operations show traffic, weather, or vendor constraints without hand-waving.
For shared understanding, most organizations benefit from a simple fixed structure:
- Detection. Trip ID, incident ID, trigger source (employee app SOS, HR call, NOC alert), and exact detection timestamp.
- Acknowledgement. First human acknowledgement time from command center, with SLA (for example, “within 2–5 minutes for SOS, 15 minutes for service complaints”).
- Stabilization. Concrete actions with timestamps. Examples include driver contacted, alternate cab dispatched, police or site security informed, escort added, or shift manager notified.
- Communication. Time and content of messages to the employee, HR, and local transport team. This includes what was promised, such as ETA for replacement cab or revised pickup.
- Resolution. Actual closure time and outcome type. Examples include employee reached safely, ride cancelled with standby arranged, or incident escalated to Security/EHS.
- Evidence. GPS trace and route deviations, call and chat logs, SOS screenshots, and driver or guard statements. These should be stored in an audit-ready format.
- Post‑incident. Ticket categorisation, root cause, and committed corrective action. Examples include routing rule change, driver coaching, or vendor penalty.
Timelines must map to pre-agreed categories such as safety-critical vs service-quality issues. Safety events usually require near‑real‑time acknowledgement and escalation, while service issues often use slightly longer acknowledgement and closure SLAs. HR and operations align best when these categories and SLA bands are agreed in advance and shown on the same dashboard that tracks on-time performance, incident rates, and complaint closure SLAs.
images:
During selection, what should procurement ask to confirm the vendor won’t go silent during disruptions—named escalation contacts, clear ladders, response commitments, and enforceable penalties?
B1254 Ensuring vendor responds under stress — In India corporate EMS, what should a procurement lead ask during selection to confirm the vendor will not ‘go silent’ during major disruptions (named escalation contacts, escalation ladders, response time commitments, and penalties that are actually enforceable)?
Procurement leads in Indian corporate EMS should ask targeted questions that force vendors to expose how they behave when operations are under stress, not just on normal days. The most reliable signals come from concrete escalation structures, 24/7 command-center capability, written response-time commitments, and penalties tied to measurable SLAs with clear audit trails.
They should probe the escalation structure in detail. Procurement leaders can ask for named escalation contacts with designations, backup owners, and time-band coverage. They should request the vendor’s formal escalation matrix, including levels from ground supervisor through key account manager to leadership, as described in the “Escalation mechanism and matrix” collateral. They should confirm whether escalations are routed through a centralized command centre or Transport Command Centre that operates 24/7, as shown in the “Transport Command Centre” and “Command Centre.png” materials.
They should validate operational governance and real-time visibility. A robust vendor will maintain a Centralized Command Centre plus Location-Specific Command Centres for quick local response, as in the “Model Proposed – MSP Governance Structure” and “CC detail” collaterals. Procurement leads should ask how incidents are monitored using alert systems like the “Alert Supervision System,” and how exceptions such as geofence violations, over-speeding, or technology failures are surfaced and closed with documented SOPs.
They should lock in enforceable response times and penalties. Selection conversations should include specific questions about guaranteed on-time arrival rates (for example, 98% OTP mentioned in “Management of on Time Service Delivery”), maximum acknowledgement and resolution times for high-severity incidents, and how these are tracked via dashboards like the “Dashboard – Single Window System” and “Indicative Management Report.” Penalty and earnback clauses should be explicitly linked to these KPIs with auditable evidence, leveraging tech-based measurable and auditable performance as in the “Tech Based Measurable and Auditable Performance” collaterals.
They should also interrogate business continuity readiness. Vendors should be asked to walk through their Business Continuity Plan for cab shortages, political strikes, severe weather, and technology failures, referencing collaterals such as “Business Continuity Plan 1,” “Business Continuity Plan 2,” and “BUSINESS CONTINUITY PLAN.” Questions should cover availability of standby fleet buffers, multi-city support, and how the command centre activates contingency routing and communication in such events.
To make penalties enforceable, procurement leads should insist on: clear ownership (who signs off on root-cause analysis), transparent, tech-backed reporting (trip logs, alerts, CO₂ and OTP dashboards), and periodic governance cadences like QBRs and management reviews outlined in the “Account Management & operational excellence Model” series. Vendors that can show integrated command-centre processes, data-driven insights, and structured engagement models are far less likely to “go silent” during disruptions, because their operating model is built around continuous supervision, escalation discipline, and audit-ready performance evidence.
If there’s a city-wide disruption like flooding or protests, how should the NOC run the continuity plan so escalation is structured and not improvisation?
B1255 Continuity plan for city disruptions — In India corporate ground transportation for EMS, how should the command center document and execute a continuity plan during city-wide disruptions (flooding, curfew, large protests) so escalations don’t become improvisation and panic?
A continuity-ready command center in Indian EMS treats city-wide disruptions as pre-modeled scenarios with written playbooks, pre-agreed decision rights, and data-backed triggers, not as ad-hoc emergencies. The command center documents these playbooks in simple, shift-usable SOPs and then drills them, so that when flooding, curfew, or protests hit, operations switch mode in minutes with clear roles, rerouting rules, and communication templates already defined.
A common failure mode is that command centers only log incidents but do not have pre-approved transition states for operations. A resilient EMS command center maintains scenario-wise Business Continuity Plans that combine routing logic, fleet buffers, escort and women-safety rules, and HRMS-linked roster changes under a single governance structure. These plans reference business continuity artefacts such as buffer vehicles, alternate vendors, and pre-cleared exception policies for attendance and shift timing. The plans also define how alerts, SOS, and safety protocols will run when GPS is patchy or when parts of the city are inaccessible.
Operationally, most command centers need three written layers. One layer defines “who decides what” during disruptions, including escalation matrices to HR, Security, and Facility heads. Another layer defines “how service runs in degraded mode”, including dead-mile caps to keep cost visible, routing relaxations, EV versus ICE deployment choices, and seat-fill and OTP targets that are realistic under stress. A third layer defines “how evidence is captured”, so that every exception, missed trip, or escort deviation has an auditable trail for HR, Security, and ESG reporting.
For a Facility or Transport Head, the practical checklist is short but strict:
- Pre-define disruption scenarios and the exact trigger points for switching from normal to continuity mode.
- Map alternate routes, staging hubs, and rendezvous points in advance for key clusters.
- Maintain a live roster of standby vehicles, partner fleets, and driver pools with contact and compliance status.
- Establish clear SOPs for night-shift and women employees, including safe-drop rules when regular routing fails.
- Align HRMS, payroll, and attendance rules with disruption exceptions so supervisors are not improvising policy on calls.
- Standardize message templates and channels to inform employees, HR, and leadership within fixed SLAs.
When such documentation is in place and rehearsed, the command center can operate as a calm, rules-driven control room even under curfew, flooding, or protests. This reduces 2 a.m. improvisation, protects OTP where possible, and gives HR and leadership the confidence that every exception is controlled, recorded, and defensible.
After go-live, what signs show the NOC tools are slowing us down—manual updates, switching between systems, inconsistent incident status—and how do teams fix it without replatforming?
B1256 Spotting and reducing NOC drag — In India corporate EMS, what post-purchase signals indicate the command center’s tooling is creating operational drag (too many manual updates, swivel-chair across systems, inconsistent incident states), and how do teams typically fix this without a full replatforming?
In Indian corporate employee mobility services, a command center tool starts creating operational drag when controllers spend more time feeding systems than managing trips, when incident states cannot be trusted, and when supervisors must swivel between apps, sheets, and calls to get a single view of a shift. These signals show that NOC tooling is not acting as an observability layer but as an extra workload, so most organizations respond with layered fixes around process standardization, light integration, and targeted automation rather than a full platform replacement.
Post-purchase drag tends to appear first as rising manual effort and noise. Controllers re-enter the same trip or roster data into multiple tools. Teams maintain parallel WhatsApp groups and spreadsheets because the system view lags reality. Exception handling becomes ticket-by-email plus phone plus app, and there is no single reliable source for the “current state” of a delay, no-show, or safety trigger. Escalation matrices on paper diverge from what is actually used during night shifts, which increases stress for facility and transport heads who already operate as de facto “always on” command centers.
Mature EMS operators usually address this through incremental, governance-driven changes that sit on top of existing tooling. Transport heads standardize shift operating procedures so that the command center supports a single, agreed trip lifecycle and escalation path. Integration teams expose data via APIs or light ETL into a mobility data lake or consolidated dashboard, which reduces swivel-chair behavior and re-keying. Vendors introduce automated alerts for OTP breaches, geo-fence violations, or SOS, so controllers act on prioritized exceptions instead of raw feeds. Outcome-linked KPIs such as OTP%, Trip Adherence Rate, and exception closure time are made visible to HR, Security, and Finance, which reduces ad hoc reporting and fragmented incident narratives while avoiding the disruption of a full replatforming.
For our employee transport program, what does real 24x7 command center support actually look like—who monitors alerts, who triages, and who owns escalations at night so it doesn’t just bounce back to our team?
B1257 True 24x7 coverage definition — In India-based corporate employee mobility services (EMS) operations, what does “24x7 command center coverage” practically mean in terms of alerting, triage tiers, and escalation ownership—and how do you verify it’s not just a phone line that forwards to the same overloaded transport manager at night?
In India-based employee mobility operations, genuine 24x7 command center coverage means there is a staffed, tooling-backed control room that continuously monitors trips, generates automated alerts, runs defined triage tiers, and follows an escalation matrix that does not collapse back to a single transport manager at night. It is evidenced by a central Transport Command Centre (or equivalent) with clear roles, SOPs, dashboards, and audit logs for alerts, responses, and closures.
A real command center runs as the operational “nerve system” for EMS. It monitors GPS, route adherence, battery/fuel levels for EVs, geofence violations, over-speeding and device tampering, and safety triggers like SOS. It uses an Alert Supervision System or similar to raise rule-based alerts for exceptions such as late departures, ETA breaches, unsafe driving, night-shift deviations, and technology failures. These alerts are not handled ad-hoc. They follow an internal process that includes triage, ownership allocation, and defined response SOPs.
Triage tiers normally separate routine noise from real risk. Low-severity alerts (minor ETA slips or one-off GPS drops) are handled at the front-line operator level in the command center. Medium-severity events (recurring delays on a route, repeat geofence violations, early signs of driver fatigue or non-adherence to women-safety protocols) are routed to supervisory staff or the Location-Specific Command Centres for intervention. High-severity incidents (SOS, serious safety concerns, accidents, natural-disaster disruptions, political unrest) are escalated to defined leads under a Business Continuity Plan, and can trigger buffer-fleet activation, route reconfiguration, shift-time changes, or coordination with local authorities.
Escalation ownership is distributed and role-based. Governance models described in the collateral show a dual-command structure. A Centralized Command Centre standardizes policy, supervises operations in real time, and watches overall SLA, safety, and compliance. Location-Specific Command Centres or ground teams handle local issues and emergency responses. An explicit escalation mechanism and matrix defines who acts at Level 1 (command center executive or dispatcher), Level 2 (shift lead, location supervisor, or Key Account Manager), and Level 3 (senior operations leadership, HR, Security, or client stakeholders for major incidents). Business Continuity Plan documents map specific disruption types—cab shortages, natural disasters, political strikes, technology failures—to concrete mitigation steps and named roles.
To verify that “24x7 command center coverage” is not just a marketing label or a call-forwarded mobile, a facility or transport head can look for several concrete signals:
-
There should be a documented command center design, including micro-functioning steps, roles, and processes. Materials such as the “Transport Command Centre,” “Micro functioning of command centre,” and “Principle role of command centre” collaterals demonstrate structured workflows, not just a helpline. A genuine provider can walk through these steps showing who does what per shift.
-
There must be a visible Alert Supervision System with specific alert types (geofence violation, device tampering, over-speeding, etc.) and a way to show historical alerts, response timestamps, and closure status. This goes beyond “we get a call when something happens” and indicates automated detection and managed triage.
-
Escalation matrices and engagement models need to be written and shared. The “Escalation mechanism and matrix” collateral lays out levels, response timelines, and responsibilities. A valid 24x7 operation will map common scenarios like GPS failure, driver no-show, vehicle breakdown, and SOS to specific escalation ladders and SLAs.
-
Business Continuity Plan documentation should exist and refer explicitly to transport disruptions. The BCP and related collaterals show dedicated buffer vehicles, support from associated businesses, and playbooks for strikes, disasters, or tech failures. This proves that the night shift is not improvising every time there is a disruption.
-
A real command center has an observable technology stack. Dashboards for real-time trip states, CO₂ reduction tracking, safety and compliance, or EV fleet status (as shown in various dashboards and EV command centre visuals) demonstrate that operators are not flying blind. The Commutr platform, administration and transport management apps, and centralized dashboards for CO₂ or operational KPIs collectively support continuous observability.
-
Centralized Compliance Management artefacts and HSSE tools should integrate with the command function. These documents show automated compliance checks, safety toolkits, and HSSE culture reinforcement, which only work if someone is actively monitoring and acting round the clock.
-
Vendor must be able to produce historical management reports and audits. Indicative Management Reports, tech-based measurable and auditable performance diagrams, and outcome-measurement workflows show that alerts, escalations, and resolutions are logged and later analyzed for SLA and safety performance. A call-forwarded phone cannot generate that level of audit trail.
In practice, an operations-focused buyer can run a simple verification playbook before believing a “24x7 command center” claim:
-
Ask for the actual shift roster for the command center. There should be names and roles for all 24 hours, including weekends and holidays, not just “on-call” notes.
-
Request to see live dashboards and alert queues during an off-peak or night slot. A vendor with a real command center can show active trips, alerts, and SLA counters even at 1 a.m.
-
Walk through two or three edge-case scenarios—night-shift SOS from a woman employee, monsoon-related gridlock on a key corridor, and GPS/network failure on a busy route—and insist on seeing the written SOPs and escalation paths that the command center uses in each case.
-
Verify that there is a separation between command-center staff and the buyer’s own transport manager. The provider should have its own operators, supervisors, and governance structures (sometimes reflected in team-structure diagrams and MSP governance models) that handle first-line triage and escalation before involving client-side managers.
-
Check for integration with route optimization, EV monitoring, and safety tooling. Case studies on monsoon routing performance, EV fleet dashboards, and safety & security frameworks indicate that the command center is stitched into dynamic routing, safety protocols, and sustainability reporting, not just basic call-handling.
When these artifacts, roles, and systems are present and demonstrable, “24x7 command center coverage” means a genuinely managed, technology-backed control-room function. It functions as a continuous assurance layer for on-time performance, safety, compliance, and ESG tracking, rather than a single night-shift manager juggling calls from drivers, employees, and HR.
For incidents like no-show cabs, app issues, or GPS gaps, what MTTD/MTTR targets are realistic—and how do we write them so they can’t be gamed?
B1258 MTTD/MTTR targets for mobility — In corporate ground transportation command-center operations for India (EMS/CRD), how should a buyer set realistic targets for mean time to detect (MTTD) and mean time to recover (MTTR) for incidents like no-show vehicles, app downtime, GPS gaps, and driver non-responsiveness, without creating SLAs that vendors can game?
In Indian corporate ground transportation command centers, buyers should set MTTD and MTTR targets by incident category and by trip phase, and then tie payouts to aggregated outcome metrics like OTP and closure quality rather than to isolated second-by-second timers that vendors can game. Targets should be aggressive enough to reduce firefighting for the Facility / Transport Head but allow for degraded modes and manual overrides during tech or network failures.
A common failure mode is setting uniform, very low MTTR numbers without distinguishing between issues like a no-show cab before shift start and GPS gaps during an already-moving trip. Vendors then over-bias to “cosmetic fixes” such as marking trips as completed in the system or suppressing alerts, which erodes trust and breaks auditability. Realistic targets start from actual operations baselines and are refined via quarterly reviews using command-center logs, not from generic RFP checklists.
MTTD should be shortest for high-impact EMS events. Examples include missing vehicles at shift start, female night-shift routing exceptions, and widespread app downtime that affects boarding. Longer MTTD can be accepted for non-critical CRD exceptions like minor GPS jitter, provided Trip Adherence Rate and On-Time Performance remain inside agreed bands. MTTR should prioritize restoring safe, working alternatives for employees rather than purely restoring the primary system, with clear SOPs for fallback dispatch, manual rostering, and call-center interventions.
To avoid SLA gaming, buyers can define a small set of transport-wide outcome KPIs that embed MTTD/MTTR behavior. Examples include OTP%, Trip Adherence Rate, exception detection-to-closure SLA adherence, and incident re-open rates. Penalties and incentives should apply to rolling-period aggregates for these KPIs, with spot audits of trip and incident logs for audit trail integrity. This keeps vendors focused on observable reliability at the command-center level instead of manipulating individual timestamps.
For our night-shift escalations, what are the usual root causes in employee transport, and what checklist can my transport team use to find patterns instead of firefighting daily?
B1259 Night-shift escalation root causes — In India corporate employee transport command centers (EMS), what are the most common failure modes that trigger repeated night-shift escalations (e.g., roster changes, driver churn, geofence issues), and what diagnostic checklist should the facility/transport head use to identify root causes instead of treating every shift as a fresh fire?
In India EMS command centers, repeated night-shift escalations usually trace back to a small set of recurring failure modes in rostering, fleet/driver stability, tech reliability, and safety governance rather than “random daily chaos.” A structured diagnostic checklist helps a Facility / Transport Head see patterns across OTP, driver churn, geo-fence alerts, app/GPS failures, and compliance gaps so each shift is a controlled variation of a known playbook, not a new fire.
A common failure mode is fragile rostering and routing logic. Dynamic shift attendance and hybrid work often sit on manual rosters or poorly tuned routing engines. This causes under-filled routes, last‑minute re-clubbing, and dead mileage that push pickups into delay. Repeated no‑shows, manager-driven late roster changes, and weak cut‑off enforcement compound this problem. Command centers that lack a clear ETS Operation Cycle or route optimization discipline tend to operate reactively rather than through stable SOPs.
Driver and fleet instability is another root driver of night escalations. High driver attrition, loose onboarding, and weak compliance enforcement increase last‑minute dropouts and safety incidents. When Driver Assessment & Selection Procedure, driver compliance checks, and driver training and rewards are not embedded, drivers are less invested in night duties and more likely to churn or refuse difficult routes. Fleet compliance and induction gaps also show up as breakdowns, low uptime, and last‑minute vehicle substitutions that the control room has to patch.
Technology and visibility breakdowns often convert manageable variance into escalations. GPS failures, inconsistent app usage by drivers, or partial adoption of driver and vendor apps and employee apps remove the command center’s early-warning capability. If alert supervision systems, transport command centre dashboards, and data-driven insights are underutilized, the team spots delays and geofence violations only when employees call, not via proactive alerts. Fragmented data between HRMS, routing, and billing systems further obscures chronic patterns like low Trip Adherence Rate or recurring hot-spot routes.
Safety and compliance governance failures amplify every operational slip at night. Weak enforcement of women-centric safety protocols, driver KYC and background checks, or centralized compliance management create escalations that involve HR, Security, and leadership. When safety and compliance frameworks, escort rules, and SOS workflows exist only as documents, not as live command center playbooks with alert supervision, the same types of incidents repeat without clean root-cause closure.
To move from firefighting to diagnosis, a Facility / Transport Head can use a practical checklist across five lenses. This checklist should be reviewed weekly in the command center, using dashboards, alert logs, and shift reports rather than anecdotal complaints.
- Roster and Routing Integrity
- Cut-off discipline. Are roster freeze cut‑offs defined, communicated, and enforced, or are late additions and changes routinely accepted during live shifts?
- Seat-fill and dead mileage. Are average seat-fill ratios and dead miles monitored by route and timeband to detect poor routing or excess buffers?
- Pattern of delays. Do late pickups cluster around specific hubs, shifts, or client locations, indicating structural route design or buffer issues?
- Hybrid-work volatility. Are attendance and hybrid patterns integrated into route planning, or is routing still based on static assumptions?
- Driver and Fleet Stability
- Driver churn signals. What is the night-shift driver attrition rate, and do recurring escalations correlate with shifts staffed by new or substitute drivers?
- Duty cycles and fatigue. Are duty hours, rest periods, and night-shift rotations tracked to prevent fatigue-related incidents and refusals?
- Compliance and induction. Are driver compliance, induction training, and refresher sessions current for all night drivers, or are exceptions tolerated to “fill shifts”?
- Fleet uptime and standby capacity. Is fleet uptime adequate, and are standby vehicles planned for high-risk timebands to absorb breakdowns without cascading delays?
- Technology Reliability and Command-Center Control
- App and GPS health. How often do driver apps, GPS devices, or the EMS platform drop during peak night windows, and what is the typical time to restore?
- Alert coverage. Are geofence violation, over-speeding, and SOS alerts enabled and monitored 24/7, or are they noisy and often ignored by the command center?
- Single-window visibility. Does the team operate from a unified dashboard for trips, vehicles, and CO₂ metrics, or juggle multiple un-synced tools?
- Integration with HRMS and rosters. Are employee rosters and shift changes synced into the routing/command center system, or keyed in manually from emails and sheets?
- Safety, Compliance, and Night-Shift Protocols
- Women-safety SOP adherence. Are women-centric safety protocols, escort rules, and home-drop rules enforced and evidenced in trip logs for every relevant route?
- Incident closure quality. For each night incident, is there a documented root cause, corrective action, and follow-up audit, or just reactive resolution?
- Audit trail completeness. Can the team reconstruct trips—GPS logs, driver identity, SOS events—cleanly for any escalated night shift?
- Training cadence. Are safety briefings, driver training, and refresher sessions for night operations conducted and recorded regularly?
- Governance, Vendor Management, and Commercial Signals
- SLA vs reality. Do contracted SLAs on OTP, safety incidents, and fleet uptime match observed performance, or are penalties and incentives not enforced?
- Vendor tiering. Are underperforming vendors identified through comparative KPIs and either coached, re-tiered, or substituted, or do they remain in rotation indefinitely?
- Business continuity readiness. Are BCP playbooks for strikes, floods, and technology failures tested in nights, or only documented on paper?
- Feedback loop. Are recurring employee complaints and NPS patterns systematically analyzed and translated into route, driver, or vendor changes?
When this checklist is applied with data from transport dashboards, alert supervision systems, and management reports, most “random” night-shift escalations resolve into a set of 3–5 chronic gaps. Addressing these at the level of routing rules, driver and fleet policies, tech reliability, and safety governance produces a calmer command center, with early alerts and predictable behavior instead of nightly surprises.
How should we set up triage so incidents are classified the same way every time (severity, safety risk, SLA risk), regardless of who’s on duty?
B1260 Consistent triage classification model — In corporate ground transportation operations in India, how do mature command centers run triage so that employee mobility incidents are classified consistently (severity, safety risk, SLA breach risk) and don’t depend on whichever supervisor is on duty that night?
Mature transport command centers in India standardize triage by running every employee-mobility incident through predefined categories, thresholds, and workflows instead of relying on individual supervisor judgment. Incident severity, safety risk, and SLA breach risk are encoded as rules, checklists, and system-driven tags that sit inside the command-center tools and SOPs.
Command centers treat triage as a repeatable process linked to OTP, safety, and compliance KPIs. A central NOC or Transport Command Centre monitors GPS feeds, alert streams, and SOS inputs in real time, and uses an Alert Supervision System and compliance dashboards to surface events like geofence violations, device tampering, overspeeding, missed pickups, or escort non-compliance as standardized alert types. Each alert type maps to a pre-agreed severity band and a fixed escalation path instead of ad-hoc decisions.
Classification quality improves when transport teams blend technology and SOPs. Driver and employee apps with SOS buttons, live tracking, and geo-fencing ensure that potential safety issues are captured uniformly and time-stamped, while centralized compliance management ensures that missing documents, expired permits, or non-compliant vehicles appear as compliance incidents rather than being ignored. Mature setups layer business continuity plans on top of this, so technology failures, weather disruption, or cab shortages are tagged as continuity risks with their own playbooks and buffers.
To keep triage consistent across shifts, organizations use playbooks, training, and audits. Command-center micro-functioning diagrams, escalation matrices, and safety-and-compliance frameworks define what constitutes a critical safety event versus a service deviation, who is informed within what time, and what evidence must be logged. Regular audits, data-driven insights dashboards, and user satisfaction indexes then verify that similar incidents receive similar classifications and responses, regardless of which supervisor is on duty.
When pickups start failing during shift change, how should the escalation matrix be designed so we don’t get bounced between dispatcher, supervisor, and our desk?
B1261 Stop escalation ownership ping-pong — In India employee mobility services (EMS), what escalation matrix design prevents ‘ownership ping-pong’ between the vendor dispatcher, the on-ground supervisor, and the client transport desk when pickups are failing during peak shift changes?
In India EMS operations, an escalation matrix prevents “ownership ping‑pong” only when a single command center owns the incident end‑to‑end, with pre‑defined timebound tiers, named roles, and clear decision rights across vendor, on‑ground, and client transport desks. The matrix must route every missed or at‑risk pickup through one Transport Command Centre or Centralized Command Centre that supervises vendors, not alongside them.
A common failure mode is triage starting at the wrong place. Dispatchers, site supervisors, and client transport desks all call each other while the cab and employee wait. A centralized command center with 24/7 monitoring, as shown in the WTi Alert Supervision System and Transport Command Centre collateral, avoids this by ingesting GPS, roster, and alert data into one console and triggering SOP-driven actions and escalations.
Escalation design that reduces firefighting usually includes: - Tier‑0: Automated alerts for ETA slippage, geofence breach, or device tampering sent to the command center, not directly to line staff. - Tier‑1: Vendor dispatcher and driver contacted by the command center with a strict response SLA and defined remedies such as rerouting or backup deployment. - Tier‑2: On‑ground supervisor engaged only when Tier‑1 actions cannot stabilize within the SLA, with authority to reassign vehicles or re‑sequence routes. - Tier‑3: Client transport desk involved for policy decisions, communication to employees, and exception approvals, not for basic coordination.
An MSP governance structure with a Centralized Command Centre plus Location-Specific Command Centres, as depicted in the MSP Governance and CC detail collateral, helps keep ownership with the operator until resolution. Client transport teams then receive structured updates and post‑incident reports instead of real-time blame transfer. This reduces escalations reaching senior leadership and supports measurable OTP improvement, safety compliance, and calmer peak‑shift operations.
People safety, readiness, and day-to-day execution
Centers on safety escalations, HR/finance alignment, and practical runbooks that reduce burnout while maintaining service reliability.
If the booking or driver app goes down, what should our backup SOP include so operations continue without messy WhatsApp coordination?
B1262 Backup SOP for app outages — In corporate car rental and employee mobility operations in India (CRD/EMS), what should be included in an outage/disruption backup SOP so the business can keep moving when the booking app, driver app, or tracking feed fails—without relying on ad-hoc WhatsApp groups?
In corporate car rental and employee mobility operations, an effective outage or disruption backup SOP must define clear manual processes, pre-approved tools, and named responsibilities so shift operations can continue when booking apps, driver apps, or tracking feeds fail. The SOP should convert all critical CRD/EMS workflows—roster intake, trip allocation, trip verification, safety checks, and billing evidence—into predictable, low-tech procedures that the command center and on-ground teams can run without improvisation on WhatsApp.
The strongest SOPs start from the command-center model described in the collateral and industry brief. A 24×7 transport command centre or NOC should own incident declaration and communication, with a documented escalation matrix similar to the “Escalation mechanism and matrix” and “Transport Command Centre” collaterals. A clear trigger is required for “tech outage mode” such as system alerts, repeated driver-app failures, or loss of GPS or routing visibility.
For CRD and EMS, the SOP should provide manual alternatives for every step of the ETS/CRD operation cycles shown in the “ETS Operation Cycle” and “CRD Process” collaterals. Manual roster and trip capture should use structured templates that mirror app data fields including employee ID, shift times, routes, and vehicle assignments. Dispatch rules should fall back to pre-validated fleet and driver pools built from “Driver Compliance,” “Fleet Compliance,” and “Centralized Compliance Management” frameworks so safety is not diluted under pressure.
A robust backup SOP also needs defined communication channels and formats. The command centre should use recorded phone lines and email or a simple ticketing tool rather than informal chats so there is an auditable trail, aligning with “Alert Supervision System,” “Safety & Security,” and tech-based measurable performance collaterals. Standard call scripts, SMS templates, and email formats for employees, drivers, and client stakeholders should be prepared in advance to explain disruptions, new pickup instructions, and safety checks.
Safety and women-centric protocols cannot rely on app features alone. The SOP should hard-code manual checks inspired by “Women Safety & Security,” “Women-Centric Safety Protocols,” and “Employee Safety,” such as verbal authentication, safe-drop confirmation calls, and time-bound callbacks from the command center. Escorts, route restrictions for night shifts, and SOS escalation to security or EHS must have phone-based equivalents with clear time thresholds and documentation requirements.
For tracking and trip verification, the backup process should specify how to log trip start and end times, route adherence, and incidents when GPS feeds or dashboards like “Commutr Screen” or “Customized Dashboard” are unavailable. This can include duty slips, driver phone check-ins at defined waypoints, and post-trip phone verifications with a sample of employees. The goal is to preserve enough evidence for OTP%, incident analysis, and billing integrity, in line with the “Billing – Complete, Accurate & Timely” and “Tech Based Measurable and Auditable Performance” materials.
Finally, the SOP should assign roles and staffing similar to the “Team Structure” and “TCC – Roles & Responsibilities” collaterals. Specific people per shift must own roster capture, manual routing, driver calling, safety callbacks, and data entry back into systems once they come online. There should be explicit handover and close-out steps so that offline records are reconciled into the main platform without gaps or duplicates once normal operations resume.
images:
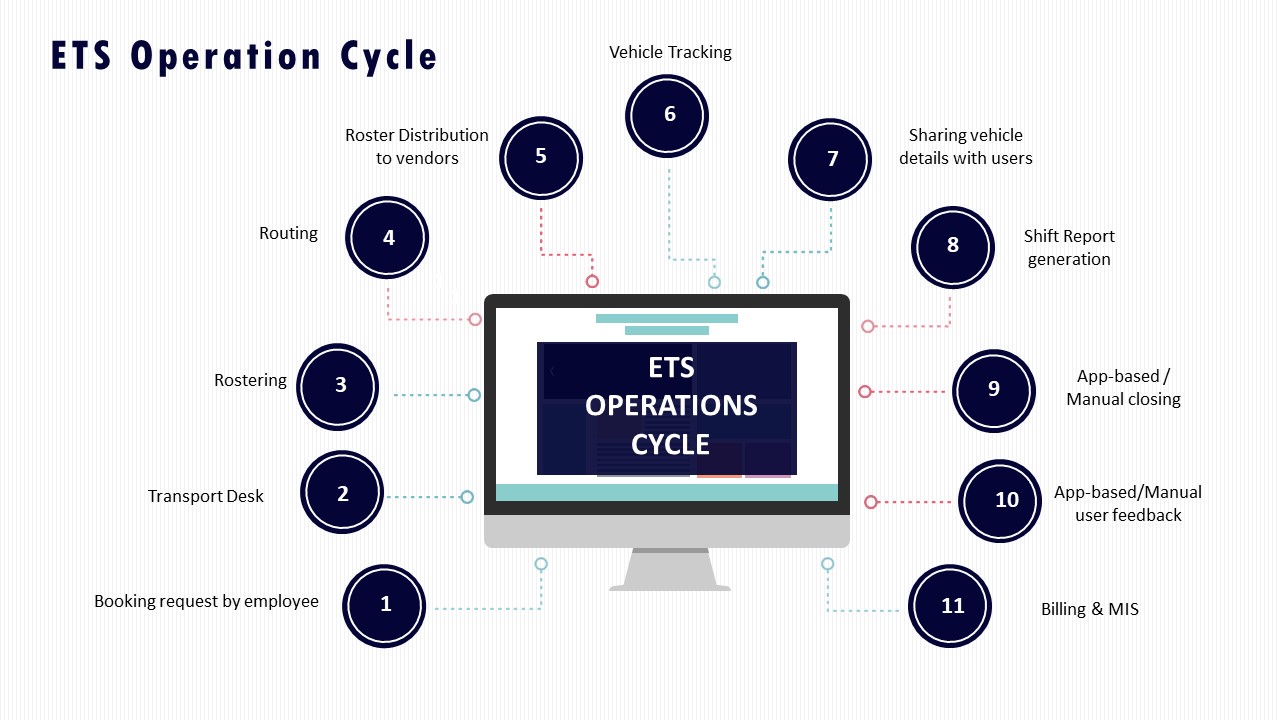
How can we prioritize women’s night-shift trips for faster escalation without overwhelming the team with too many alerts?
B1263 Priority escalation for women safety — In India corporate employee transport (EMS), how do you design command-center escalation rules so women’s night-shift trips automatically get higher-priority triage and faster escalation without creating alert fatigue or false positives for the NOC team?
In India EMS programs, women’s night-shift trips should move through a clearly defined “safety-priority lane” in the command center. The rules must combine objective risk filters (gender, time-band, route risk, SOS/route deviation) with tiered escalation and rate-limiting so that the NOC sees fewer, higher-quality alerts instead of more noise.
Women’s trips need explicit tagging in the routing and trip manifest systems. Each trip record should carry fields for rider gender, time-band, escort requirement, and route risk category. The command-center platform should then auto-classify “women + night-shift + no-escort + medium/high route risk” as a high-priority cohort before the trip starts. This enables pre-trip checks, such as confirmation of driver credentials, vehicle compliance, GPS health, and active SOS capability, which reduces downstream incident probability.
Escalation rules should be multi-stage rather than single-trigger. The NOC can treat “soft anomalies” like minor ETA slip within tolerance as low-priority alerts for silent monitoring. It can reserve high-priority alerts for compound signals such as “night + woman passenger + route deviation beyond threshold” or “SOS + no movement for defined minutes.” This compound logic reduces false positives. It also ensures that high-priority alerts always include contextual data like location, driver identity, and trip stage, which speeds triage.
To avoid alert fatigue, rate-limiting and suppression logic are critical. The system should suppress repeated alerts for the same underlying issue after the first acknowledgment while still logging all events for audit trails. The NOC view should show one consolidated “incident card” per affected trip instead of multiple independent pop-ups. This card can track alert state, escalation path, and resolution, aligning with integrated command-center operations and incident SOPs.
Clear SOPs must map alert type to response and escalation path. For example, an SOS on a women’s night trip should immediately trigger a scripted sequence: NOC calls driver, then passenger, then security/EHS, within strict time SLAs. Lower-level anomalies like marginal ETA slips can stay within the NOC team with dashboard monitoring and only escalate if they cross a second threshold. This tiering aligns with safety governance and reduces unnecessary 2 a.m. calls to senior stakeholders.
Data-driven tuning should be continuous. The NOC should periodically review incident logs, closed tickets, and “false alarm” rates to recalibrate triggers and thresholds. This review can incorporate safety KPIs such as incident rates, women-safety protocol adherence, and audit trail integrity. Over time, organizations can refine which combinations of time-bands, geographies, vendors, and drivers justify higher sensitivity, while relaxing rules where real-world risk is demonstrably lower.
After a serious incident, what proof should we ask for (timestamps, alerts, acknowledgements, actions, comms) so we’re not relying on verbal claims?
B1264 Incident evidence package expectations — In India corporate ground transportation programs, what evidence should HR and EHS demand from the mobility command center after a serious incident (timeline, alerts fired, who acknowledged, actions taken, communications) to avoid ‘we responded’ claims that can’t stand up to internal investigations?
In Indian corporate ground transportation programs, HR and EHS should demand a complete, time-stamped incident dossier from the mobility command center that reconstructs the trip and the response sequence from planning to closure. This dossier must turn “we responded” into verifiable evidence across routing, alerts, acknowledgements, actions taken, and communications.
They should first insist on full trip lifecycle data from the command center and transport platform. This includes the original roster and route plan, GPS trip logs with time-stamped locations, route-adherence or deviation reports, vehicle and driver compliance status at dispatch, and any geofence or policy rule that applied to that trip, especially for women’s night-shift transport and escort requirements. This establishes whether the operation was compliant even before the incident.
They should then require machine-generated alert and escalation timelines from the centralized NOC. This should show exactly which alerts fired, at what time, for which trip or vehicle, and via which rule (for example geo-fence violation, panic/SOS trigger, fixed-device tampering, speeding or route deviation). Each alert must be linked to an acknowledgement log that records who in the command center received it, when they acknowledged it, and what action code they selected.
They should demand an auditable action and decision trail that ties each acknowledgement to concrete steps. This includes outbound calls or messages to the driver, employee, security, or local authorities, escort deployment where applicable, and any routing changes pushed to the driver app. The dossier should hold call records or ticket IDs from the alert supervision or SOS system, along with time-stamped notes on risk assessment and decisions taken.
They should also request a structured communications log covering all stakeholder-facing messaging. This should capture employee notifications, HR and security updates, and any broadcast to site leadership, with exact timestamps and message content. For women’s safety cases, it should show when the safety cell or dedicated helpline was engaged and how the employee was monitored until safe closure.
Finally, they should require a formal incident report and closure pack from the command center governance framework. This should combine a root-cause summary, SLA or SOP breaches, corrective and preventive actions, and links to supporting evidence such as GPS traces, app screenshots, and compliance dashboards. HR and EHS can then test this pack against internal HSSE policies, labour and transport norms, and women-safety protocols to ensure the response is defensible in internal investigations and external audits.
If we have a central command center plus city teams, how do we avoid blind spots in escalations during weather issues or strikes?
B1265 Central vs city escalation gaps — In India-based enterprise mobility command centers (EMS/CRD), how do you prevent escalation blind spots when operations are split across a central NOC and multiple city/site teams, especially during weather disruptions or bandh/strike scenarios?
In India-based enterprise mobility command centers, escalation blind spots are best prevented by running a single, governed incident framework across the central NOC and all city/site teams, with predefined triggers, playbooks, and evidence-based reporting that do not depend on individual discretion. A common failure mode is allowing each city or vendor to “own” its own escalation logic, which hides early warning signs and leads to late-night surprises during weather disruptions or bandh/strike scenarios.
Centralized control has to start with a clear NOC-led governance structure. The central command center should own standard incident categories, threshold-based alerts, and an escalation matrix that is common across EMS and CRD. Location-specific command centers then execute within that framework and feed back real-time data. Collateral on MSP governance structures, transport command centers, and the “principle role of command centre” all emphasize this dual model. The central NOC operates as the auditor and orchestrator. Local teams act as first responders and information originators.
Weather or bandh scenarios require pre-built business continuity plans. The BCP material and “Management of on Time Service Delivery” collaterals show that well-run operators codify route diversions, shift re-timing, capacity buffers, and authority coordination in advance. During monsoon, strikes, or natural events, central NOC should push a scenario playbook, adjust routing and capacity via the routing engine, and continuously compare real-time OTP, route adherence, and exception closures against expected targets like 98% on-time arrival. Case studies show that dynamic route optimization and real-time driver–command communication can sustain high OTP and improve satisfaction even under monsoon stress.
To avoid blind spots, alerts must be technology-driven, not manually curated. The Alert Supervision System and EV command centre collaterals describe geofence violations, device tampering, overspeeding, and other events surfaced centrally. Similar logic should extend to bandh/weather: specific triggers like clustered delays on certain corridors, high no-show rates, or repeated re-routing should automatically flag to NOC dashboards, not just local teams. Centralized compliance and safety dashboards, plus indicative management reports and “Dashboard – Single Window System,” provide the observability layer. This enables the NOC to see where multiple city teams are under stress simultaneously.
Command centers also reduce blind spots through structured roles and SOPs. The “Micro functioning of command centre,” TCC roles, team structure, and escalation mechanism collaterals show that responsibilities must be explicit: who acknowledges an alert, who informs client stakeholders, who reconfigures routes, who handles women-safety exceptions, and who logs evidence. When operations are split across sites, blind spots appear if no one is explicitly responsible for cross-city pattern recognition or for reconciling site dashboards with the central view.
Standard operating procedures should encode how local deviations are shared upward. For example, when a city team alters shift times due to bandh/strike, the BCP and Business Continuity Plan materials suggest that they must simultaneously update central NOC, which then updates HR and Security with a unified narrative. This avoids conflicting stories from different locations and protects the Facility/Transport Head from being blamed for decisions made ad hoc. The “Guarantee for Uninterrupted Services” and COB management collateral reinforces the need for redundancy planning and regular monitoring.
Data-driven insights and measurable performance frameworks close the loop. Tech-based measurable and auditable performance slides emphasize outcome measurement, visibility, verification via audits, and CSAT tracking. When disruptions occur, continuous measurement of OTP, trip adherence, and complaint closure time across all cities helps identify where escalation is lagging. The central NOC should run periodic route adherence audits, compare exception closure SLAs between sites, and use standardized reports (as per the Indicative Management Report collateral) to identify systemic blind spots.
From an on-ground operator’s perspective, this reduces firefighting. A facility/transport head benefits when the central NOC detects early signs of stress (for example, repeated delays on a monsoon-affected corridor) and triggers contingency resources or rerouting before employees and HR start escalating. The Business Continuity Plan materials show that buffer vehicles, associated-business support, and alternative routing can be activated at the central level, while city teams focus on execution and communication.
Safety and HSSE frameworks also help prevent escalation gaps. Collaterals on Safety & Security, Safety and Compliances, HSSE contribution, women-centric safety protocols, and Safety & Security for Employees stress that escort rules, SOS handling, and women’s night-shift policies must be centrally governed but locally enforced. During bandh/strike or curfew-like conditions, the NOC should have additional women-safety playbooks: escort prioritization, route whitelisting, and real-time monitoring via SOS control panels. This ensures that a local team does not quietly downgrade safety to “keep trips moving,” which can later turn into high-profile escalations.
Finally, command centers must maintain an evidence trail. Centralized compliance management, trip logs, GPS data, and alert supervision all support audit-ready reconstructions of what happened during a disruption. This protects HR, Security, and the Facility/Transport Head when leadership asks, “Where did this break?” If every incident has a digital trail—from alert trigger through escalation steps to closure—escalation blind spots become detectable patterns instead of untraceable anecdotes.
In practice, operators avoid blind spots when they combine four elements: a central NOC with clear authority, local command centers with defined execution roles, scenario-specific BCP playbooks for weather and bandh events, and technology-led observability that spans all cities and vendors. When these are in place, disruptions surface as managed exceptions with early warnings and unified responses, rather than as scattered escalations that overwhelm the night shift.
Besides OTP, what command center metrics should we track to spot a bad night early—like response latency or escalation backlog?
B1266 Leading indicators for bad shifts — In India corporate employee mobility services (EMS), what operational metrics beyond OTP should a facility/transport head track in the command center to predict a bad night before it spirals—such as vendor response latency, driver acknowledgment time, and escalation backlog?
In Indian EMS operations, a facility or transport head should track a compact set of command-center metrics that predict stress on the system before OTP visibly collapses. These metrics should expose latent risk in vendors, drivers, routing, safety, and systems so the team can intervene early instead of firefighting later in the shift.
Leading operators use command centers and alert supervision systems to surface issues such as geofence violations, GPS tampering, and overspeeding in real time. They combine these with routing KPIs like route adherence and trip fill ratio to understand where traffic, weather, or monsoon disruptions are likely to cause service degradation. This allows dynamic routing or resequencing of trips before employees experience delays.
Vendor and driver responsiveness are critical early-warning indicators for night operations. Metrics such as vendor response time to allocation requests, driver trip acceptance latency, and driver acknowledgment time for roster changes reveal whether supply is actually available, even when the roster looks green. A growing pool of “unacknowledged” or “at-risk” trips in the next 60–90 minutes signals likely missed pickups.
A well-run command center also watches the escalation pipeline itself. Monitoring open alert count, escalation backlog by age, and incident closure SLA helps identify when the control room is falling behind. If safety alerts, SOS triggers, or compliance deviations (like missing chauffeur documents or failed vehicle checks) remain unresolved close to shift windows, the risk of operational breakdown and reputational damage increases sharply.
To keep the dashboard usable during peak or night shifts, facility heads should prioritize:
- Real-time routing and capacity health, including route deviation alerts and live vehicle locations.
- Driver and vehicle compliance status, using centralized compliance management views.
- Safety and SOS events, especially for women-centric and night-shift trips.
- System reliability indicators, such as GPS uptime and app connectivity issues that can mask deeper problems.
How should alert thresholds be set so we catch real issues (missed pickup, route deviation, SOS) without drowning in false alarms from GPS/network problems?
B1267 Alert threshold tuning realities — In corporate ground transportation operations in India, how do you design alerting thresholds so the command center catches real exceptions (route deviation, missed pickup window, SOS triggers) while avoiding constant false alarms caused by GPS jitter and mobile network gaps?
Alerting thresholds in a transport command center should be tuned around trip SLAs and real-world GPS behaviour, not raw coordinates. A well-designed system filters location noise first, then raises alerts only when a deviation clearly risks on-time performance, safety, or compliance.
Command centers that act as the “operations brain” rely on stable telematics, driver apps, and NOC tooling to supervise OTP, route adherence, and SOS. GPS jitter and mobile gaps are normal in Indian conditions, so operators need SOPs and tech filters that treat them as noise until they affect SLAs. Alert Supervision Systems and Transport Command Centres typically use geofencing, fixed device tampering checks, and route adherence rules, combined with manual oversight when apps or GPS fail.
The most practical pattern is to define exception thresholds as time and distance windows instead of single-point events. Route deviation is flagged only when a vehicle remains outside the approved corridor beyond a buffer, missed pickup is raised only after the delay crosses the agreed pickup window, and network loss is escalated only if the command center cannot recover visibility within a defined period. SOS events are the exception and must fire immediately, with a command-center workflow for verification and escalation.
Command centers that succeed generally standardize these thresholds in their operating model and BCP. They use centralized dashboards and alert consoles to prioritize high-severity safety alerts and SLA-impacting delays, while relegating transient GPS or network issues to low-priority queues or periodic health reports. They combine automated alerts with shift-wise briefings, driver training, and compliance dashboards so that routing engines, driver apps, and human supervisors work as a single system rather than relying on raw telemetry alone.
images:
During a major disruption like flooding or an app outage, what comms protocol should we follow so employees and leaders get consistent updates and HR isn’t left alone handling it?
B1268 Disruption comms protocol to stakeholders — In India enterprise mobility services (EMS), what is a practical escalation communication protocol to employees and business leaders during major disruptions (city-wide flooding, platform outage), so HR isn’t left managing reputational damage with inconsistent updates?
A practical escalation communication protocol in Indian enterprise mobility services defines clear triggers, ownership, message templates, and channels before a disruption occurs so that employees and business leaders receive consistent, time‑bound updates directly from the transport command centre instead of ad‑hoc HR messaging. The protocol works when it is embedded in the EMS operating model, tied to the command centre, and linked to measurable SLAs for detection, notification, and closure.
The core principle is that the 24x7 command centre or Transport Command Centre (TCC) owns first information and outbound communication during floods, political strikes, or platform outages. HR and business leaders then amplify and contextually interpret those updates, rather than originate them. This reduces contradictory narratives and keeps HR out of real‑time fact‑finding.
A robust protocol typically includes:
- Explicit incident tiers and triggers. A city‑wide flood, monsoon gridlock, or critical app outage is defined as a major incident with pre‑approved playbooks and communication steps.
- Named roles and time‑bound SLAs. The command centre issues an initial “situation acknowledged” update within a fixed window. Follow‑up updates are sent at defined intervals until closure.
- Standard message templates. Templates cover service impact, safety guidance, interim work arrangements, and escalation contacts. These templates reduce improvisation in the middle of a crisis.
- Channel hierarchy. Operational updates flow via apps, SMS, and email to employees, while summary incident briefs go to HR, Facilities, and leadership dashboards.
- Audit and evidence. All notifications are logged in the command centre system to create an audit trail for HR, Security/EHS, and ESG narratives.
Most failures occur when communication is triggered late, delegated informally to HR, or varies by site or vendor. A command‑centre–led protocol stabilizes expectations, ensures one version of truth across EMS, CRD, and project commute services, and gives HR a defensible, evidence‑backed story for employees, leadership, and auditors.
For ‘no cab arrived’ situations, how should playbooks be set so the command center can act fast—replacement cab, pooling change, supervisor—without waiting on approvals?
B1269 Fast decisions for no-show cabs — In India corporate employee transport (EMS), how do you structure escalation playbooks for ‘no cab arrived’ cases so the command center can make fast decisions (replacement dispatch, pooling change, supervisor intervention) without waiting for client approvals that slow everything down?
In India EMS operations, effective “no cab arrived” escalation playbooks give the command center pre-approved decision rights, clear time-based triggers, and fixed fallbacks so replacement dispatch or pooling changes are executed immediately without client-by-client approvals. Most organizations define a short sequence of detection, verification, autonomous corrective action, and post-facto reporting, with boundaries tied to SLAs, safety rules, and commercial limits.
A common failure mode is treating every “no cab” as an ad-hoc exception. Command centers then wait for HR or facility sign-off and lose critical minutes. A better pattern is to codify three elements in the SOP. First, define objective detection rules by timeband. For example, “cab not at geofence by T–10 minutes” or “no GPS heartbeat plus unreachable driver for 5 minutes” is auto-classified as an impending “no show risk.” Second, empower the command center to take pre-approved actions within guardrails. These actions include auto-triggering standby vehicles, re-sequencing pooled routes, merging low-load routes, or upgrading vehicle type for specific critical shifts or personas, as long as safety constraints and maximum cost deltas are respected.
Third, link the escalation ladder to time thresholds and risk level. For example, if risk is flagged at T–15 minutes, the NOC can switch the trip to a predefined standby fleet pool. If still unresolved by T–5, the shift supervisor can authorize pooling overrides or tactical changes like reassigning nearby vehicles from lower-priority trips. If the incident crosses shift start, an on-ground supervisor or transport head is alerted with authority to invoke Business Continuity Plan measures such as alternate vendors, manual pick-ups, or temporary ad-hoc bookings.
To keep this defensible for HR, Finance, and Procurement, playbooks usually specify.
- Clear SLA bands for OTP and acceptable deviation per site or shift.
- Pre-approved cost and distance buffers for standby use, re-routing, or upgrades.
- Hard safety limits, such as no removal of escorts from women’s night cabs to fix another failure.
- Automated logs for every action taken, tied to the trip ledger and incident reports.
Centralized command-center governance, escalation matrices, and Business Continuity Plans, as described in the collateral on command centers and BCP, provide the framework for these autonomous decisions. When implemented correctly, the command center executes fast, controlled corrections during “no cab arrived” scenarios and informs the client through dashboards and post-incident reports instead of asking permission in the middle of the crisis.
For executive travel with flight delays or sudden changes, what escalation model gives predictable resolution without upsetting other teams or policies?
B1270 Executive escalation without backlash — In India corporate car rental services (CRD), what escalation model ensures executives get predictable resolution during flight delays or last-minute itinerary changes, without breaking fairness policies or causing backlash from other business units?
An effective escalation model for corporate car rental in India gives executives priority handling through a clear tiered SOP and outcome-based rules, while keeping the policy common and transparent for all business units. The escalation model works when priority is linked to role, trip criticality, and SLA tiers defined in the travel policy, not to “who shouts the loudest” during a disruption.
The most stable approach separates three layers. The first layer is a 24/7 command center or transport desk that owns all flight monitoring, ETA updates, and re-assignments for airport and intercity CRD trips. The second layer is a documented escalation matrix from front-line coordinators up to a Key Account Manager, with defined response-time SLAs for re-routing, vehicle replacement, and driver changes. The third layer is a governance layer that uses management reports and dashboards to review SLA breaches and pattern of escalations across business units.
Fairness is protected when the policy defines which designations or trip types get “executive SLA” (for example, tighter response time and guaranteed backup vehicles), and when these rules are published in the CRD operating model and communicated via the travel desk and apps. This prevents perceived favoritism between functions. It also allows Procurement and Finance to link these differentiated SLAs to specific commercial models, cost benchmarks, and vendor penalties or earnbacks, so that higher priority does not mean uncontrolled spend.
images:
What staffing and handover practices help avoid 3 AM single points of failure and reduce burnout for both our transport desk and the vendor NOC?
B1271 Shift handover and on-call design — In India corporate mobility command-center operations, what are the practical staffing and shift-handover controls (runbooks, on-call rotation, escalation coverage) that reduce 3 AM single-points-of-failure and prevent burnout in the client transport desk and vendor NOC teams?
Effective corporate mobility command centers in India reduce 3 a.m. single-points-of-failure by pairing minimum staffing baselines with explicit runbooks, rotation rules, and an escalation matrix that is tested, not just documented. Burnout is prevented when every night-shift decision has a defined SOP, a backup owner, and clear limits on what must be escalated rather than “handled somehow” by the transport desk.
Most resilient setups mirror the MSP-style governance and command-centre models used in employee transportation services. Central 24×7 command centres or Transport Command Centres (TCC) monitor operations continuously, while location-specific desks handle local routing, driver coordination, and emergency response. Staffing patterns typically ensure at least two roles per shift in the central command centre for segregation of duties. One person focuses on live monitoring, alerts, and incident triage. Another handles vendor coordination, routing changes, and communication with client stakeholders.
Runbooks usually codify end-to-end ETS and CRD operation cycles. They define pre-shift checks, live monitoring rules, safety and compliance triggers, and standard reactions to common failure modes such as cab shortages, technology failures, monsoon disruption, or political strikes. Business Continuity Plans and COB management documents add explicit fallbacks, including buffer vehicles, backup systems, and coordination with local authorities.
Escalation matrices and engagement models distribute accountability across tiers like service delivery teams, key account managers, and leadership. These are paired with Alert Supervision Systems and SOS workflows so that geofence breaches, tampering, over-speeding, or safety incidents automatically open tickets with defined closure SLAs. Responsibility for night operations is rotated across supervisors and command-centre staff according to project planners and transition plans, with structured daily shift-wise briefings to ensure clean handovers, shared situational awareness, and early detection of fatigue or overload.
Before go-live, how do we test command center readiness (SOS drills, mass no-shows, app outage simulations) so leadership isn’t betting their job on it?
B1272 Readiness testing before go-live — In India enterprise mobility (EMS/CRD), how do you test command-center readiness before go-live—such as tabletop exercises for SOS events, mass no-shows, and platform outages—so the CIO and HR head aren’t taking a career risk on an unproven escalation process?
In India enterprise mobility, command-center readiness is best tested through structured pre–go-live simulations that replay high-risk scenarios end-to-end, generate real evidence, and expose gaps in escalation, data, and decision rights before real employees are at risk. Readiness tests must explicitly stress SOS events, mass no-shows, and technology outages, and they must be observed and signed off jointly by Transport, HR, Security/EHS, IT, and the vendor command center team.
A common failure mode is treating the command center as “configured” once dashboards and alerts exist. Command centers only work in practice when escalation matrices, on-call rosters, and playbooks have been rehearsed under time pressure. Most organizations that skip dry-runs discover missing contacts, unclear responsibilities, and fragmented logs only during a real incident.
A practical readiness program usually has three elements. First, design 3–5 realistic “tabletop” scenarios for SOS, monsoon traffic disruption, and app/GPS downtime, with clear start triggers, expected SLAs, and closure criteria. Second, run controlled live drills on limited test routes or dummy rosters while the centralized command center, location-specific hubs, and Transport Command Centre dashboards handle alerts and escalations in real time. Third, capture evidence packs for each drill, including alert timelines, call recordings, route changes, and closure notes, and review them in a joint war-room with CIO, HR, Security/EHS, and Finance.
Teams should score drills against OTP impact, incident detection and closure time, audit trail completeness, and ability to keep operations running in manual mode when apps fail. Organizations can then decide go/no-go or require another drill round. This approach reduces perceived career risk for CIO and HR leadership, because the escalation process is no longer “unproven” but documented, replayable, and governed through standard operating procedures that have already been tested like a business continuity exercise.
What should our team own vs what the vendor command center owns—for triage, dispatch decisions, and employee updates—so there’s no blame game after issues?
B1273 RACI for mobility escalations — In India corporate employee transport (EMS), what should be the division of responsibilities between the client’s facility/transport team and the vendor command center for triage, dispatch decisions, and employee communications—so escalations don’t become political blame games after a bad week?
In Indian corporate employee transport, triage, dispatch, and employee communication work best when the vendor command center owns real-time operations and the client facility/transport team owns policy, exceptions, and governance. Clear division of “who decides” and “who informs” reduces gray zones that turn bad weeks into blame games.
In most EMS programs, the vendor’s command center should run 24/7 operational control. The vendor command center should own live GPS monitoring, routing and re‑routing, driver allocation, SOS handling, alert supervision, and immediate employee notifications through apps or SMS. The vendor should also manage business continuity playbooks for cab shortages, tech failures, political strikes, and weather disruptions, and then push concise incident and resolution summaries to the client team.
The client facility or transport team should own the operating rules rather than the joystick. The client should define SLA thresholds, women-safety protocols, escort rules, routing constraints, and escalation matrices using documented SOPs, then let the vendor execute within those guardrails. The client should approve planned changes such as shift pattern revisions, fleet mix changes, and EV rollout pace, and should chair periodic governance reviews using vendor dashboards, management reports, and audit trails.
Escalation handling should follow a two-layer model. The vendor should handle first-line triage and employee calls for delays, no-shows, and driver issues as per a documented matrix. The client team should step in only for policy decisions, chronic pattern failures, or reputationally sensitive events such as serious safety incidents. Jointly agreed business continuity plans and command-center governance structures are strong signals that roles are clear and that accountability will be evidence-based, not political.
What should Procurement put in the contract to make 24x7 escalation support enforceable—like response/ack SLAs, named roles, and penalties?
B1274 Make 24x7 support enforceable — In India corporate mobility programs, what contractual language should Procurement include to make 24x7 escalation coverage enforceable (response time, acknowledgment SLAs, named roles, penalties), rather than a vague promise that becomes untestable after award?
In Indian corporate mobility contracts, 24x7 escalation coverage becomes enforceable when it is written as a measurable service obligation with defined timelines, roles, and remedies, rather than as a generic “round-the-clock support” statement. The contract must specify response and acknowledgment SLAs, name accountable roles and escalation levels, and link non-compliance to documented penalties or service credits that show up in billing and performance reviews.
The most robust language treats 24x7 escalation as part of the SLA framework for the centralized command center or Transport Command Centre. The contract should define which channels are in scope, such as command-center hotline, app-based SOS, and email or ticketing, and require continuous availability for all employee mobility, corporate rentals, project commute, and EV operations. It should fix clear, auditable timers for initial acknowledgment and for action start, with separate bands for critical safety incidents, service outages like GPS or app failures, and routine operational queries. Each incident should be logged in a system that can be shared in periodic Indicative Management Reports.
Procurement teams typically gain the most control when they tie 24x7 coverage to concrete definitions of escalation matrices and command roles. The contract can require the vendor to publish and maintain a named escalation mechanism and matrix that covers site coordinators, command-center supervisors, key account managers, and senior leadership exposure up to a defined level. It can also mandate that this matrix be tested through drills under the Business Continuity Plan and documented in the MSP governance structure for centralized and location-specific command centers.
Penalties are most enforceable when they are anchored to measurable breaches of the defined SLAs. Contracts can link repeated failure to meet acknowledgment or response timelines, or recurring non-availability of the command center, to SLA breach rates and financial consequences within the billing model. This might include service credits applied to monthly invoices, performance guarantee exposure, or additional review obligations under the account management and operational excellence model, instead of generic statements about “best efforts” or “reasonable support.”
To make coverage auditable, Procurement can require that every escalation create a ticket with time stamps for creation, acknowledgment, first action, and closure, and that this data be retained as part of the tech-based measurable and auditable performance framework. Quarterly governance reviews and mobility dashboards can then include escalation statistics alongside on-time performance and safety incidents. This shifts 24x7 escalation from an informal promise into a recurring, testable KPI within the broader governance, safety, and business continuity obligations.
How do we define which escalation actions can be billed as exceptions (replacement cab, escort, dead mileage) so Operations can act quickly but Finance doesn’t fight the invoice later?
B1275 Exception billing vs fast recovery — In India employee mobility services (EMS), how do Finance and Operations align on what counts as an ‘exception’ eligible for extra charges during escalations (replacement vehicle, additional guard/escort, dead mileage), so the command center can act fast without triggering end-of-month invoice wars?
In Indian employee mobility services, Finance and Operations align on “chargeable exceptions” by defining a narrow, pre-approved catalog of scenarios, triggers, and rates in advance, and wiring these rules into command-center SOPs, rather than debating each case at billing time.
In practice, most organizations first separate operational exceptions from commercial exceptions
To avoid end‑of‑month disputes, enterprises typically codify three elements. They define a short list of eligible scenarios, for example vendor-side vehicle breakdowns requiring replacement dispatch, mandated escort additions on specific night routes under security or women-safety policy, and dead mileage incurred solely due to client-approved roster changes or last-minute additions. They specify objective triggers and caps for each, like minimum distance, time windows, or prior-approval conditions, and they standardize how these get logged in the mobility platform, including reason codes, timestamps, and approval IDs. The command center then operates under a clear playbook. When an exception occurs, the operator can act immediately under the predefined rule, raise an incident or ticket in parallel, and tag the trip with the agreed reason code. Finance later receives an exception summary that reconciles directly to those codes, so invoices, MIS, and SLA reports all tell the same story. This approach preserves operational speed for night shifts and disruptions, while giving Finance predictable, auditable logic for when “extra” becomes “payable.”
During disruptions, how can the command center reroute or reassign vehicles quickly while still following HR policies like women-safety routing and shift rules?
B1276 Speed vs compliance in escalations — In India corporate employee transport operations, how do you design escalation rules so the command center can reroute or reassign vehicles during disruptions while staying within policy constraints set by HR (e.g., gender-sensitive routing, shift rules), instead of choosing speed over compliance?
In corporate employee transport in India, escalation rules must encode HR policies as hard constraints first and only then optimize for speed or rerouting flexibility. Command centers should never treat gender-sensitive routing, escort rules, or shift-hour norms as tradeable for on-time performance, but instead design playbooks where every operational fallback still respects these constraints.
Escalation design works best when command center actions are mapped to a clear rulebook that combines service SLAs with safety and compliance conditions. Command centers rely on predefined incident categories such as traffic gridlock, vehicle breakdown, driver no-show, tech outage, or weather disruption. Each category links to permitted actions like rerouting, vehicle substitution, or shift change. HR policies on women’s night-shift travel, escort requirements, and route approvals sit as non-negotiable guardrails for all such actions. This prevents a dispatcher from assigning an unescorted car or sending a lone woman through an unapproved route in the name of recovery.
A common failure mode is giving the NOC “full discretion” for OTP recovery without clear policy-encoded constraints. That often leads to ad hoc routing, fragile vendor workarounds, and elevated safety risk when pressure is high. A more robust design gives the control room a decision tree that explicitly states which combinations are allowed, such as only substituting with a vehicle that already meets fleet compliance, driver KYC, and escort criteria. The command center then uses technology like routing engines and SOS systems only inside those policy boundaries.
Well-structured escalation rules typically define four things in advance. These are escalation thresholds, authorized decision-makers at each level, allowed recovery actions by timeband and gender mix, and mandatory documentation and audit logs. This structure allows operations teams to react quickly during disruptions while still satisfying HR, Security, and ESG demands for traceability, duty of care, and audit-ready evidence.
If an auditor asks today, what should ‘one-click’ reporting include for escalations—incident logs, acknowledgements, and actions—so we don’t scramble?
B1277 Audit-ready escalation reporting — In India enterprise mobility command centers, what does ‘panic button’ reporting for a compliance audit look like for escalations—such as instant export of incident logs, acknowledgments, and recovery actions—so HR and Legal aren’t scrambling when auditors ask for evidence the same day?
In an Indian enterprise mobility command center, audit-ready panic-button reporting means every SOS event is captured as a structured “case file” that can be exported on demand with time-stamped evidence of detection, acknowledgment, and recovery actions. The command center must be able to pull this evidence the same day for HR, Legal, and external auditors without manual reconstruction from call logs or WhatsApp chats.
A mature setup treats every panic-button press like an incident ticket. The SOS from the employee app triggers an alert in the Transport Command Centre with GPS coordinates, trip ID, vehicle and driver details, and passenger manifest. The Alert Supervision System or SOS control panel then records who in the command center first viewed the alert, when they acknowledged it, which escalation level was engaged, and what actions were taken, such as calling the driver, contacting the employee, rerouting, or dispatching standby support. Each step is time-stamped and bound to the trip record, so there is a single source of truth instead of fragmented data.
For compliance audits, HR or Legal should be able to request an “incident pack” for a defined period or a specific case. The command center exports a report that includes the original trip details, panic-button trigger time, geo-fence or speed alerts, call/SOS handling history, and closure notes, along with any corrective actions like driver suspension, retraining, or route changes. This same structure underpins women-centric safety protocols, safety and security frameworks, and HSSE culture tools, so audits are about reviewing a consistent, traceable process rather than firefighting to prove what happened after the fact.
What meeting cadence and reviews should we run (daily incidents, weekly RCA, monthly SLA) so reliability actually improves and doesn’t reset every month?
B1278 Governance cadence for reliability — In India corporate ground transportation (EMS/CRD), what governance cadence should exist between the command center and senior leadership—daily incident reviews, weekly trend RCA, monthly SLA governance—so reliability improves over time rather than resetting every month?
The most effective governance cadence links a 24x7 command center’s daily incident control to weekly trend reviews and monthly SLA governance, with each layer owning different decisions and evidence. Daily reviews keep shifts stable, weekly reviews correct patterns before they turn into “chronic issues,” and monthly governance locks improvements into contracts, SOPs, and commercials.
Daily, the command center should run shift-wise dashboards focused on OTP%, exception queues, safety/SOS events, and vendor response, with clear escalation matrices. This keeps the Facility / Transport Head in proactive mode, reduces night-shift firefighting, and creates auditable trip-level data for Safety/EHS, HR, and Finance. A common failure mode is treating incidents as one-offs, without tagging root causes, locations, vendors, and timebands in a structured way.
Weekly, Transport, HR, Security/EHS, and key vendors should review trend RCAs driven by data from the NOC, routing engine, and compliance dashboards. These reviews should explicitly link recurring failure patterns to routing rules, fleet mix, driver fatigue, or infrastructure gaps, and then update SOPs and routing or capacity policies. Reliability improves when these weekly changes are treated as controlled experiments with clear before/after KPIs.
Monthly, senior leadership (CHRO, CFO, Procurement, ESG, CIO, Security) should run a formal SLA and risk-governance forum. This should use standardized KPIs such as OTP, incident rate, seat-fill, dead mileage, CET/CPK, and EV utilization, and then adjust vendor tiers, penalties/incentives, EV roadmaps, and business continuity plans. Reliability stops “resetting every month” when this forum tracks cumulative improvements and ties payouts and renewals to multi-month SLA and safety performance, not isolated billing cycles.
How do we know the command center is actually reducing workload—fewer night calls and fewer manual interventions—instead of just logging the same chaos as tickets?
B1279 Prove reduced ops cognitive load — In India employee mobility services (EMS), how do you measure whether the command center is genuinely reducing cognitive load for the facility/transport head—fewer night calls, fewer manual interventions, fewer ‘where is my cab’ escalations—rather than just documenting the same chaos in a ticketing tool?
In Indian employee mobility services, a command center is genuinely reducing cognitive load only when operational noise drops in measurable ways such as night-shift call volume, manual overrides, and “where is my cab” escalations. A command center that only adds dashboards and tickets, but does not change these volumes, is just documenting chaos rather than absorbing it.
The most direct signal is the pattern of human intervention. Transport heads should track total inbound contacts per 100 trips segmented by channel and time-band. Command-center success is indicated by fewer late-night calls from security desks, managers, and employees, and a higher share of issues auto-resolved within the NOC using pre-defined SOPs. If escalation volume to the facility head is flat or rising after go-live, the command center is not absorbing cognitive load.
Another key lens is “how often do we break the SOP.” Organizations should measure manual roster edits, last-minute route changes outside the routing engine, ad-hoc vehicle requests, and manual driver reassignment per shift. A working command center plus routing platform reduces these interventions through better shift-windowing, buffer policies, and proactive alerts from traffic, weather, or EV charging status.
Escalation characteristics reveal whether the system is preventative or reactive. Metrics such as “where is my cab” queries per 1,000 trips, average time to locate a vehicle, and repeat incidents per route should decline when live GPS, IVMS, and geo-fencing alerts are working through a 24x7 command center. If the same patterns repeat and only the ticket count grows, the command center is functioning as a logging layer, not an operational stabilizer.
A further check is leadership visibility versus on-ground pain. If the facility head’s subjective load score, measured through periodic surveys, remains high despite strong SLA and ticket reports, there is a misalignment between reported performance and real cognitive load.
How should we set escalation timeouts so if a dispatcher doesn’t respond quickly, the system escalates to an alternate fleet and we’re not depending on personal contacts?
B1280 Escalation timeouts and auto-substitution — In India corporate mobility operations, what’s the best way to define and enforce escalation ‘timeouts’—for example, if a vendor dispatcher doesn’t respond in 5 minutes, the command center auto-escalates to an alternate fleet—so service continuity doesn’t depend on personal relationships?
In Indian corporate mobility operations, escalation “timeouts” work best when they are defined as explicit SLA thresholds with auto-triggered actions in the command center and are tied to vendor governance and billing, not to individuals or relationships. Each timeout needs a clear metric, a fixed clock start, a system-driven escalation step, and an auditable log so it can be enforced shift after shift by any team.
Timeouts fail when they are informal or person-dependent. Operations teams often rely on WhatsApp groups, personal phone calls, or “bhai, please manage this trip,” which breaks down in night shifts and during disruptions. A more reliable pattern is to anchor timeouts to objective events in the ETS/CRD operation cycle, such as trip creation, roster freeze, driver acceptance, vehicle reporting, and gate-out, with countdowns running inside the transport command center or mobility platform.
Escalation thresholds should be differentiated by stage and criticality. For example, a dispatcher non-response to a new trip request may get 5–10 minutes, whereas a no-show at pickup in a night shift for women employees should escalate in 2–3 minutes with SOS-ready coverage. Each timeout should map to a predefined action such as “auto-offer ride to alternate vendor pool,” “trigger standby car,” or “alert supervisor plus security.” These rules should be pre-approved in SOPs and Business Continuity Plans, not improvised under stress.
To move escalation from relationship-based to system-based, organizations should embed timeouts into the central command center workflow and escalation matrix. The Alert Supervision System, geofencing alerts, and 24/7 command-center tools described in the collateral can be used to auto-generate tickets when an SLA threshold is crossed, and route them to the next level in the matrix. Vendor contracts and billing models should then reference these SLA timers explicitly, linking penalties or reallocation of volume to breach counts rather than subjective opinions.
Practical configuration signals include: • A single, command-center–maintained escalation matrix per site with named roles and backup contacts. • System clocks that start when a triggering event hits the platform (booking logged, route published, driver assigned) and stop only when the required status is reached. • MIS and dashboards that show “timeout-based escalations” as a KPI alongside OTP% and exception-closure time, so transport heads can tune thresholds. • Integration with Business Continuity Plans so that when timeouts coincide with broader issues (strikes, tech failures, weather), pre-agreed contingency playbooks take over instead of ad-hoc calls.
Timeouts that are too aggressive can cause churn, overuse of standby cars, and unnecessary cost, while loose timeouts push the burden back on night-shift teams. Most operators therefore calibrate thresholds by route type, time band, and persona (e.g., stricter for women’s night shifts and airport trips, more flexible for non-critical daytime drops), and they revisit them in quarterly governance reviews with HR, security, and vendors.
images:
After an incident, how should the RCA be written so it leads to real fixes—SOPs, thresholds, staffing—instead of a blame document that HR and Ops don’t trust?
B1281 RCA that drives real fixes — In India corporate employee transport (EMS), how do you structure post-incident RCA outputs from the command center so they drive real process fixes (SOP changes, threshold tuning, staffing changes) instead of producing blame-heavy narratives that HR and Operations both distrust?
In India EMS operations, post-incident RCA coming out of the command center only drives real fixes when it is structured as a factual “trip lifecycle reconstruction + control gap analysis + action log” rather than a narrative of who failed. The RCA must separate data facts from judgment, link each finding to a specific control or SOP, and end with time-bound owners for changes to routing, thresholds, training, or staffing that the command center can track in its dashboards and QBRs.
A practical pattern is to mirror how EMS command centers already think in terms of trip lifecycle and control points. Command center tooling, alert supervision systems, and transport command centre dashboards generate time-stamped GPS traces, geofence events, SOS triggers, and escalation logs. An effective RCA first reconstructs the incident timeline from this telemetry and app logs. The RCA then maps each “miss” to a concrete control category such as routing logic, driver compliance, fleet readiness, or staffing coverage in the NOC.
To avoid blame-heavy output, the template should force neutral, single-fact statements. One section lists “What happened” in time order using command centre and app data. A second section lists “Control gaps” as failed or missing controls such as geofence not configured for a new site, SOS not acknowledged within the intended SLA, or driver non-adherence despite valid briefings. A third section lists “Design changes” like SOP edits for monsoon routing, new alert thresholds, or minimum night-shift staffing requirements for the command center.
The RCA must also carry a small, auditable “action register”. Each action links to a process lever that the command center can influence. Examples include revised routing rules for heavy-rain corridors, additional IVMS or dashcam coverage on specific routes, driver refresher modules drawn from existing training and DASP frameworks, or modifications to women-centric safety protocols and escort rules. The business continuity and on-time service delivery plans can supply pre-agreed playbooks that the RCA can “pull” rather than inventing fixes from scratch.
To keep HR and Operations trust, governance needs one more structural element. The RCA format should explicitly differentiate between:
- Design fail where SOPs, thresholds, or tools were inadequate for the scenario.
- Execution fail where a trained person or vendor did not follow the agreed SOP.
- External constraint such as sudden political strike or infrastructure failure that triggered the business continuity plan.
This classification prevents every incident from being turned into personal blame for the facility head or HR. It also creates clear inputs for continuous improvement cycles in the command center. Design fails translate into SOP and threshold changes. Execution fails feed driver management, refresher training, or vendor compliance audits. External constraints are used to refine business continuity triggers, buffers, and emergency routing or standby car policies.
Finally, the structure of RCA outputs should align with existing dashboards and management reports. Command center and transport command centre artifacts already track OTP, geofence violations, SOS response, and incident closure SLAs. The RCA should reference these same KPIs and show pre- and post-change trends in monthly or quarterly reviews. When HR, Security, and Transport see that a specific SOP change or staffing adjustment following an RCA reduced repeat incidents or improved OTP, the RCA becomes a trusted improvement tool rather than a retrospective blame document.
images:
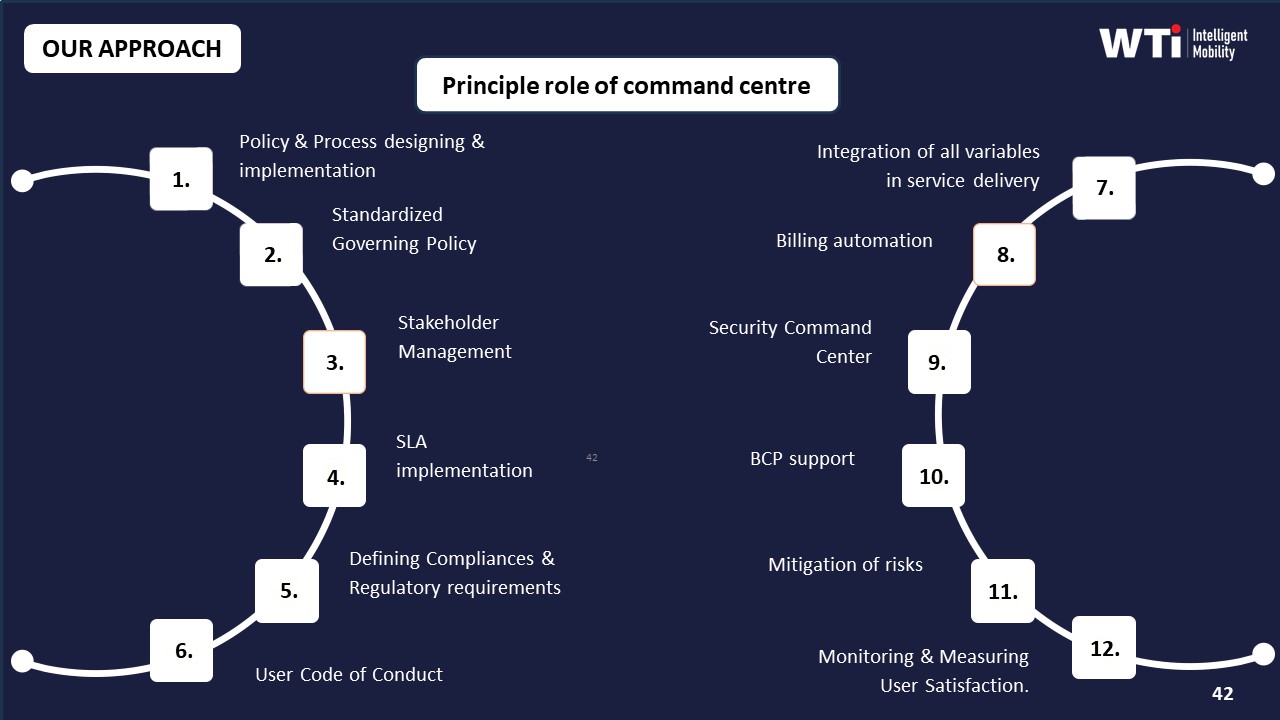
What controls make sure escalation logs can’t be changed later—timestamps, acknowledgements, action history—so Audit/Finance can trust SLA credits and penalties?
B1282 Tamper-resistant escalation logs — In India corporate mobility command centers, what safeguards ensure escalation data can’t be edited after the fact (timestamps, acknowledgments, action logs), so Internal Audit and Finance can trust incident-linked SLA credits and penalties?
In Indian corporate mobility command centers, incident and escalation data is protected mainly through immutable trip logs, system-generated timestamps, and audit-focused dashboards, so Internal Audit and Finance can treat SLA-linked credits and penalties as reliable and defensible. Command centers use real-time NOC tooling with tamper-evident GPS/trip logs and automated alerts, which prevents post‑fact editing by operations staff.
Trip and escalation records are typically created by the platform itself rather than by manual entries. The WTicabs collateral describes centralized command centers, alert supervision systems, and SOS panels that generate geofence, device-tamper, speeding, and SOS alerts automatically. This reduces the risk that a local supervisor can adjust “when” something happened or “whether” it was acknowledged. Driver, rider, and admin apps in solutions like Commutr and WTI’s mobility platform also sync manifests, check‑ins, and SOS actions in real time, which strengthens the chain of custody for incident data.
Controls also rely on role-based access and structured workflows. Centralized compliance management, billing systems, and command-center dashboards are designed so that users can add comments or close tickets but cannot overwrite system timestamps or raw telemetry. Any changes go in as new actions in the action log. Platforms emphasize measurable and auditable performance, with outcome measurement, audit verification, and CSAT all driven from system data rather than editable spreadsheets, giving Finance and Internal Audit a consistent reference for SLA breaches, credits, and penalties.
I do not have detailed information on specific database-level immutability mechanisms or cryptographic controls (please fix this gap).
How should we split alerts between the mobility NOC and our IT on-call/ITSM so outages don’t fall through the cracks at night?
B1283 Alert routing between NOC and IT — In India enterprise mobility services (EMS/CRD), how do IT and Operations agree on alert routing—what goes to the mobility NOC vs the enterprise ITSM/on-call—so critical outages don’t fall between teams at 2 a.m.?
In enterprise mobility programs, IT and Operations avoid 2 a.m. gaps by classifying alerts at design time into “business-service events” owned by the mobility NOC and “platform/infra incidents” owned by enterprise ITSM, and then hard‑wiring routing rules, SLAs, and escalation paths for each class. Critical outages are prevented from falling between teams only when both sides co‑design a single runbook, share telemetry from the routing engine and apps, and test joint on‑call flows through drills rather than relying on ad‑hoc coordination.
Most organizations start from the target operating model where a 24x7 mobility command center supervises day‑to‑day operations. The command center monitors trip lifecycle events, GPS and IVMS feeds, routing exceptions, women‑safety SOS triggers, and compliance deviations, because these are tightly coupled to OTP, safety, and vendor SLAs. Enterprise ITSM owns core platform SLOs instead, including app/API availability, authentication failures, integration with HRMS/ERP, and cloud or network incidents that can break booking or dispatch.
The two domains need a clear taxonomy mapped to tools. Mobility NOC alerts are usually raised in the fleet dashboard or command‑center tooling and escalate via an operations escalation matrix. IT‑class incidents are raised and tracked in the corporate ITSM, with severity definitions tied to user impact such as “no bookings possible,” “location tracking unavailable,” or “payment or billing integration down.” Joint incidents share a single parent ticket in ITSM with a linked child record in the NOC system.
To keep outages from falling between teams, leading buyers define a small set of joint patterns. Typical patterns include “app up but trips failing,” “GPS/telco degradation,” “EV telematics delay,” and “HRMS integration broken for roster sync.” Each pattern has a named owning function, a secondary resolver, and a strict handover rule that states when control transfers between mobility NOC and IT on‑call. These patterns form part of the business continuity plan and are validated in scenario drills.
Practical routing rules often follow a few explicit signals:
- Any alert originating from telematics, routing, OTP deviations, or safety sensors routes first to the mobility NOC with a notification copy to Security/EHS for severe cases.
- Any alert originating from identity, integration, cloud infrastructure, or core application failure routes into ITSM as the system of record, with the NOC informed for user communication and workarounds.
- For ambiguous alerts, such as widespread app timeouts during peak shifts, the default owner is ITSM, but the mobility NOC is required to open a parallel operational incident.
Operations stability improves when KPIs such as OTP%, incident closure time, and SLA breach rate explicitly depend on joint incident handling. IT and Operations leadership should review a shared incident log in regular governance forums, tuning alert thresholds, ownership rules, and runbooks based on real‑world 2 a.m. behavior, not just design assumptions.
For junior operators on our transport desk, what should the escalation workflow look like—guided steps and clear actions—so success isn’t dependent on one experienced person?
B1284 Runbook-guided escalations for juniors — In India corporate employee transport operations, what escalation experience should a junior transport desk operator have in the tool—guided runbooks, next-best actions, and clear escalation buttons—so outcomes don’t depend on tribal knowledge held by one senior supervisor?
In India corporate employee transport operations, a junior transport desk operator needs a tool that converts every common failure mode into a guided, button-driven workflow with pre-defined runbooks, next-best actions, and an explicit escalation path. The system must replace ad-hoc judgement with SOP-backed prompts, so any operator can stabilize a shift at 2 a.m. without relying on a single senior supervisor’s “tribal knowledge.”
The command-center or transport desk view should expose a real-time exception queue that classifies issues such as vehicle delays, no-shows, GPS loss, safety alerts, and app failures. Each exception type should open a structured playbook that lists required checks, communication templates, and decision branches. The tool should reduce cognitive load for the operator by sequencing tasks one at a time and logging every click as auditable evidence for HR, Security, and Procurement.
A robust escalation experience usually includes the following elements.
- Clear incident cards with severity tags and SLAs for closure, not just free-text complaints.
- Contextual next steps such as “trigger backup cab,” “notify employee and manager,” or “reroute nearest available vehicle,” driven by configured rules.
- One-click contact and escalation buttons that surface who to call or notify at L1/L2/L3, with on-screen phone numbers and roles.
- Pre-defined templates for SMS/app notifications and email updates to employees, security teams, and HR, reducing free-typing under pressure.
- Safety-specific flows for SOS, women’s night-shift incidents, and escort breaches with mandatory fields, geo-fence data, and time-stamped actions.
- Automatic linkage to business continuity playbooks for events like political strikes, extreme weather, or system downtime, with alternate routing or manual handover steps.
- Integrated alert supervision features such as geofence violation or overspeeding alerts that create tickets and prompt action rather than relying on passive dashboards.
- Role-based views so junior operators see guided tasks, while supervisors can override, reprioritize, and close incidents with reasons.
- Post-incident tagging for root-cause categories, allowing Transport Heads and HR to review patterns and refine SOPs and vendor governance.
A system with this escalation experience creates operational stability, because it standardizes what happens when vehicles are late, EVs are low on charge, GPS fails, or employees raise safety concerns. It also supports central command-center models by ensuring every location-specific desk follows the same runbooks, and by providing the CHRO, Security, and CFO with traceable incident histories tied to SLAs, safety compliance, and business continuity plans.
What red flags show a vendor command center is underpowered, and what should we ask in reference calls so we don’t find out after signing?
B1285 Spot weak command centers early — In India corporate mobility services, what are the signs that a vendor’s command center is underpowered (high escalation backlog, slow acknowledgments, vague updates), and what due-diligence questions should a buyer ask during reference checks to avoid learning this after contract signature?
In India corporate mobility services, an underpowered vendor command center usually shows up as slow, noisy operations and poor closure discipline rather than a single visible failure. Buyers can detect this early by looking for operational lag, weak observability, and thin governance during evaluation and reference checks.
Underpowered command centers often show three clusters of symptoms. The first is handling capacity and responsiveness issues. These include long queues of open tickets, delayed acknowledgment of SOS or incident alerts, and frequent excuses about “traffic,” “network,” or “app issues” instead of clear root-cause timelines. The second is weak real-time observability and control. This looks like inconsistent GPS visibility, poor SLA governance, and a reliance on manual calls and WhatsApp groups instead of a 24x7 NOC with defined escalation SLAs and dashboards for OTP, route adherence, and exception closure. The third is governance and continuity gaps. This shows as limited business continuity playbooks, ad-hoc night-shift staffing, and a lack of audit-ready evidence for safety, compliance, or EV uptime.
During reference checks, buyers should probe both daily reality and worst-day behavior. Key questions include how fast the command center acknowledges different alert types, which metrics are monitored 24x7, and what percentage of exceptions are closed within agreed timelines. Buyers should ask who physically staffs the NOC at night and weekends, how many clients share the same team, and what escalation matrix is actually used when trips fail, women-safety incidents arise, or EV charging issues occur. It is also important to ask existing clients how often leadership or HR hears about transport problems, how many tools they must open to understand an incident, and whether they receive consistent, audit-ready reports on OTP, safety incidents, and CO₂ reductions. These questions expose whether the vendor’s command center can support centralized control, business continuity, safety compliance, and EV operations at scale, or whether the buyer will end up firefighting after go-live.