How to build an evidence-driven, crisis-ready EMS vendor playbook that actually calms operations
Facility heads live the problem every shift—driver shortages, late pickups, and weather or traffic disruptions. This framework turns vendor proof into a practical, on-ground playbook that reduces firefighting and keeps the operation in control. You’ll see concrete, SOP-level steps and escalation plans designed for peak shifts and off-hours, so the team can act quickly without guessing or overengineering.
Is your operation showing these patterns?
- Escalations stall with no single owner, dashboard confusion
- Driver no-shows spike during night shifts
- GPS/app outages aren’t clearly reflected in reports
- Vendor-runbooks look perfect on paper but fail in practice during disruptions
- Site-level SLAs diverge and leadership questions data credibility
- Audit packs require heavy manual work under audit pressure
Operational Framework & FAQ
evidence foundations and verification
Defines minimum proof, audit artifacts, and data integrity checks that ground vendor evaluation and ongoing governance; guards against cherry-picking and bad data.
For our employee transport program, what proof should we expect from a vendor—data samples, audit reports, KPI improvements, and references—and what’s the minimum we should ask for before we pitch it to HR and Finance?
B0468 Minimum evidence set required — In India corporate employee mobility services (EMS), what does “proof and references” practically include during vendor evaluation—anonymized trip data packs, third-party audit reports, before/after OTP deltas, and customer references by city and timeband—and what’s a reasonable minimum evidence set before I take this to my CHRO and CFO?
In India EMS vendor evaluation, “proof and references” typically means concrete, auditable artifacts.
A reasonable minimum evidence set combines real operations data, independent validation, and like-for-like customer references across your cities and timebands.
Most organizations expect an anonymized trip-data pack with basic KPIs. This usually includes on-time performance percentages, trip adherence rates, no-show rates, and incident logs over at least 3–6 recent months. The data is typically sliced by city, shift window, and service vertical to mirror actual operating conditions for employee mobility services. This allows transport and HR teams to verify reliability claims against real-world peak and night-shift behavior.
Third-party or internal audit reports provide separate assurance on safety and compliance. These reports commonly cover driver KYC and PSV credential controls, vehicle compliance checks, women-safety protocol adherence, and GPS or route-audit integrity. Security or EHS teams use these documents to confirm that escort rules, incident response SOPs, and audit trails exist beyond marketing slides.
Before–after impact metrics are used as proof of improvement capability. Examples include OTP deltas after vendor transition, cost-per-trip trends, customer satisfaction scores, and case studies on difficult scenarios such as monsoon routing or night-shift operations. These metrics show whether the vendor can move a program from firefighting to stable performance.
Customer references by city and timeband are critical for comfort. Teams usually ask for at least one reference in the same city, one reference for late-evening or night operations, and one reference with comparable scale. Transport heads and CHROs often speak directly with these peers to validate escalation response, command-center behavior, and driver management in real conditions.
- For CHRO sign-off, the minimum set usually includes: a 3–6 month KPI pack with OTP and safety incident data, a women-safety or night-shift case study, and at least one HR or security reference call.
- For CFO sign-off, the minimum set usually includes: reconciled cost and utilization trends, billing or process documentation, and at least one finance or procurement reference confirming billing accuracy and dispute handling.
For night-shift and women-safety, what concrete reports or logs should we ask for (SOS response, escort compliance, incidents, RCAs) so Security isn’t caught short after an incident?
B0470 Safety audit artifacts checklist — In India employee mobility services (EMS) with women-safety and night-shift obligations, what specific artifacts should an EHS/Security Lead request as “audit-ready proof” (incident logs, SOS response timelines, escort adherence, geofence breaches, RCA trail) to feel confident they won’t be exposed during a serious incident review?
In India EMS programs with women-safety and night-shift obligations, an EHS/Security Lead needs audit-ready artifacts that reconstruct the full trip lifecycle and prove that policy, law, and SOPs were followed in real time. These artifacts must be time-stamped, tamper-evident, and easily retrievable for any serious incident window.
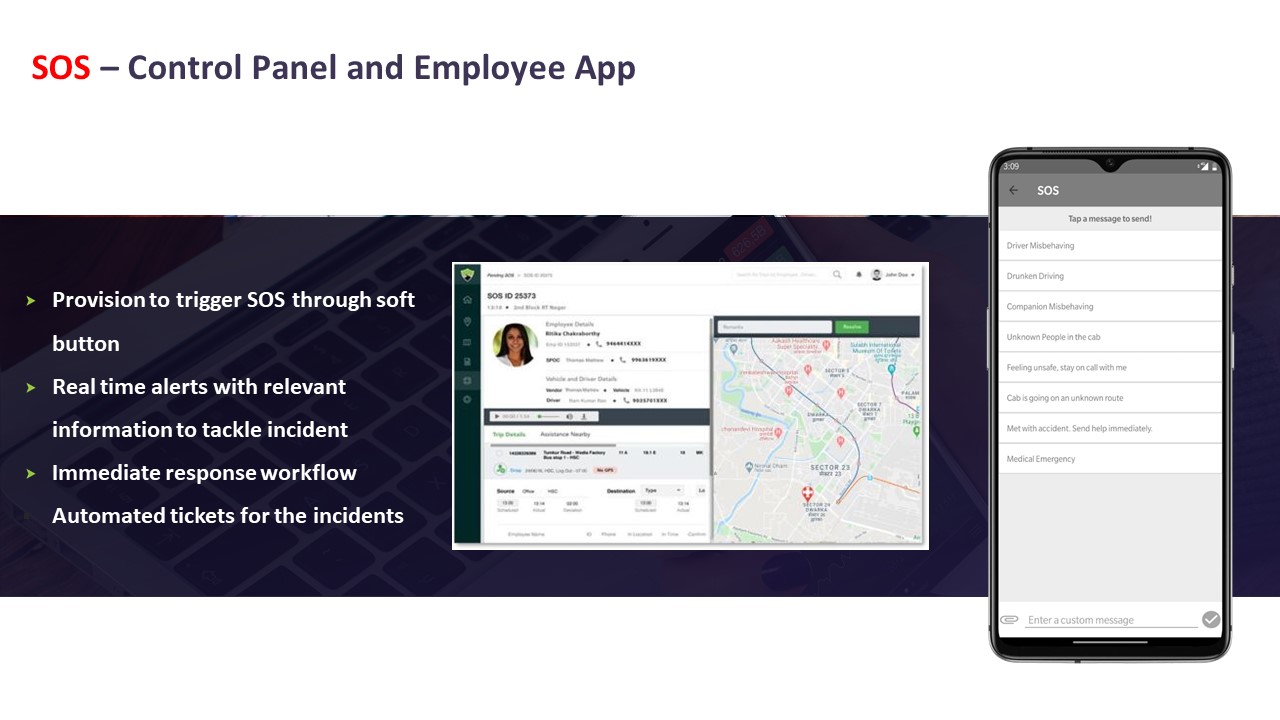
For incident management, an EHS/Security Lead should insist on a centralized incident log with unique IDs, time-stamped entries, and a complete escalation trail. The incident record should show the trigger source, the exact time of SOS activation from the employee app or driver device, acknowledgement time at the command center, intervention actions with precise timestamps, and closure notes that include whether the employee was safely handed over. This log should align with the SOS control panel evidence and call-center records that demonstrate 24/7 monitoring as described in the Alert Supervision System and SOS – Control Panel and Employee App materials.
For women-safety and night-shift compliance, the Lead should request trip manifests that prove female-first routing and escort rules, along with driver compliance records that include background checks, POSH training, and periodic refresher training. GPS trip logs must evidence route adherence, geofence configurations, and any geofence breach alerts generated by systems similar to the Transport Command Centre and Safety & Security dashboards. Each alert should map to a documented response action and, where relevant, a root-cause analysis that points to corrective and preventive measures.
For systemic defensibility, an EHS/Security Lead should also demand integrated safety and compliance dashboards showing on-time performance, incident rates, credential currency, and audit outcomes over time. These dashboards should be backed by raw trip, driver, and vehicle-level data that can be exported for independent verification, reinforcing the Safety and Compliances and Centralized Compliance Management approaches shown in the collateral.
If a vendor claims big OTP and safety improvements, how do we check it’s real and not because they changed definitions or excluded the hard routes/time slots?
B0471 Validate KPI delta credibility — In India corporate employee transport (EMS), how should a CHRO pressure-test a vendor’s claimed “before/after KPI deltas” (OTP/OTD, incident rate, seat-fill, closure SLA) to ensure the improvement isn’t just from changing definitions, excluding tough routes, or shifting timebands?
The CHRO should insist that any “before/after” KPI delta is calculated on a like-for-like basis using frozen definitions, identical route and timeband coverage, and auditable raw trip logs that can be re-run independently.
The first pressure test is KPI definition stability. The CHRO should demand written definitions for OTP/OTD, incident rate, seat-fill, and closure SLA that specify grace windows, what counts as a valid trip, and how cancellations and no-shows are treated. The CHRO should then require proof that these definitions were identical in the “before” and “after” periods, and that there was no silent change in grace minutes, exclusion rules, or thresholds during the reported improvement.
The second pressure test is scope continuity. The CHRO should verify that difficult routes, night shifts, women-first policies, and peak-load windows remain in-scope, and that the vendor has not quietly removed high-risk timebands, remote geographies, or escort-mandated routes from the denominator. Evidence should include route-level and shift-level OTP and incident rate, not only an averaged global number, so that critical corridors and night shifts can be checked separately.
The third pressure test is data lineage and auditability. The CHRO should ask for anonymized trip ledgers, GPS logs, and incident tickets for a sample period and confirm that every SLA metric can be reconstructed from those raw records. A common failure mode is when vendors present dashboards without consistent trip IDs, closure timestamps, or linkages between alerts and resolution actions.
The fourth pressure test is population comparability. The CHRO should confirm that seat-fill and OTP are being compared across similar attendance patterns, hybrid-work baselines, and fleet mixes, rather than before/after periods with radically different demand or EV penetration. The CHRO should also ensure that temporary buffers or standby vehicles used during pilot phases are disclosed so that structural vs tactical improvements can be separated.
The fifth pressure test is exclusion transparency. The CHRO should require a clear list of excluded trips and incidents, such as force majeure events or incomplete logs, and insist that exclusion criteria are symmetric across both baseline and improved periods. This prevents vendors from discarding politically sensitive incidents or “bad” days only in the after period while retaining them in the baseline.
- The CHRO can mandate a short joint audit with HR, Transport, and Security teams using live EMS data.
- The CHRO can ask to see KPIs broken down by route cluster, timeband, and gender mix rather than only as global averages.
- The CHRO can require that KPI formulas and raw data access are written into the contract as part of the SLA governance model.
When we review a vendor’s sample trip data, what red flags (missing fields, odd timestamps, too-good-to-be-true exception rates) should IT watch for?
B0473 Data pack red flags — In India corporate ground transportation (EMS/CRD), what are reasonable red flags in a vendor’s anonymized data pack (missing fields, inconsistent timestamps, suspiciously low exception rates, non-reconcilable trip IDs) that should make a CIO question data integrity and auditability?
In corporate ground transport, any pattern that weakens traceability, reconciliation, or replay of trips is a red flag for data integrity and auditability. A CIO should distrust anonymized data packs where trips cannot be tied to a consistent lifecycle, SLAs, or finance baselines, or where the “story” in the data looks cleaner than real-world EMS/CRD operations ever are.
Key warning signals usually cluster in four areas.
1. Identity, keys, and structural consistency
A serious red flag is non-reconcilable or recycled trip IDs. Each trip should have a unique, stable identifier across rider app, driver app, NOC tools, and billing exports. Missing primary keys, or IDs that change between files, prevent reliable Trip Lifecycle Management and weaken any future dispute resolution.
Datasets that omit basic trip lifecycle fields are also problematic. For EMS/CRD this includes missing booking timestamp, allocation timestamp, actual start/end times, and cancellation flags. If these fields are absent, the vendor cannot credibly support SLA claims on on-time performance, response times, or exception closure.
2. Time, location, and SLA plausibility
Inconsistent or impossible timestamps should trigger immediate concern. Examples include trips where end time is before start time, durations that are unrealistically short for known city pairs, or a high volume of rides with identical or rounded durations. These patterns suggest post-facto data massaging rather than streaming telematics feeding a mobility data lake and observability stack.
Red flags also include an absence of failed or partial trips in high-traffic or monsoon-affected cities, despite industry evidence that peak congestion, hybrid shift patterns, and weather routinely create delays and re-routing. Completely clean On-Time Performance across all timebands and regions is rarely credible in EMS.
3. Exceptions, incidents, and safety noise
Suspiciously low exception rates are a classic warning sign. In real EMS/CRD operations, geo-fence breaks, no-shows, last-minute roster changes, and SOS or incident flags do occur. A data pack that shows near-zero safety incidents, no route deviations, and perfect Trip Adherence Rate across months suggests that exceptions are either unlogged or filtered out, which undermines any “safety by design” posture and future EHS or DPDP-era investigations.
Similarly, if there is no trace of random route audits, driver fatigue indicators, or cancelled/aborted trips, the vendor likely lacks continuous assurance practices, despite industry movement away from episodic audits toward automated governance and audit trail integrity.
4. Commercial and cross-system reconciliation gaps
Data that cannot be reconciled to basic finance or HR reference points is a material red flag. For example, total trips and kilometers that do not align with representative Cost per Kilometer or Cost per Employee Trip benchmarks from billing summaries indicate weak integration with ERP or HRMS. If seat-fill or Trip Fill Ratio cannot be inferred at all, it is difficult to validate claims of route optimization or dead mileage reduction.
A CIO should also worry if raw data structures are opaque or proprietary with no clear schema, API-first integration pattern, or documentation for how SLA metrics are computed from events. Lack of clarity here tends to correlate with vendor lock‑in risks and fragile data governance later.
- Missing or unstable trip IDs undermine Trip Lifecycle Management and dispute handling.
- Impossibly “clean” timestamps and SLA metrics signal post‑hoc editing rather than streaming telematics.
- Near-zero exceptions or incidents in EMS/CRD contradict normal hybrid-work and urban-traffic realities.
- Inability to reconcile trips, km, and utilization with finance or HR baselines weakens auditability.
How do we ensure the SLA numbers in the dashboard actually match the invoice—penalties, incentives, dead mileage—so Finance doesn’t end up reconciling manually each month?
B0474 SLA-to-invoice traceability — In India employee mobility services (EMS), how can a Finance Controller verify that SLA metrics shown in the vendor’s dashboards can be tied back to invoice line items (penalties/bonuses, dead mileage, no-shows) without manual reconciliation every billing cycle?
In Indian employee mobility services, a Finance Controller can verify that SLA metrics tie cleanly to invoices by insisting on a single, governed data backbone where trip logs, SLA computation, and billing logic all come from the same auditable trip ledger rather than from separate, manually curated reports. The Finance Controller needs invoice line items to be machine-derivable from raw GPS and trip data, with transparent formulas linking SLA outcomes to penalties, bonuses, dead mileage, and no-shows.
A common failure mode is when vendors treat dashboards, MIS, and billing as separate products. This breaks traceability because SLA numbers cannot be reconciled to trip-level evidence. Finance leaders avoid this by requiring trip-level identifiers, timestamps, and route data to be stored in a mobility data lake with audit trail integrity, then mapped into billing models like per km, trip based, or pay-per-usage without re-keying. SLA penalties for OTP%, no-shows, or route adherence then become deterministic functions of these same records instead of judgment calls.
The Finance Controller should formalize this in contracts and RFPs by defining invoice readiness as an outcome of the platform’s trip lifecycle management. Clear rules for dead mileage calculation, no-show handling, and incentive ladders can be encoded upfront. This approach reduces manual reconciliation because exceptions, adjustments, and disputes are resolved in the platform’s governance layer before invoices are generated, rather than during audit or month-end firefighting.
Which third-party audits actually matter for employee transport—safety, compliance, security—and how do we verify the audit scope and how recent it is?
B0481 Meaningful third-party audits — In India employee mobility services (EMS), what kinds of third-party audits (safety/compliance, data security, process adherence) are meaningful versus “checkbox” audits, and how should a Risk or Internal Audit team validate the scope and recency?
In Indian employee mobility services, meaningful third‑party audits are those that test live operational reality, produce traceable evidence, and align with how EMS is actually delivered day and night. Checkbox audits stay at policy and paper level and avoid touching real trips, drivers, vehicles, apps, and data flows.
Meaningful safety and compliance audits validate current driver KYC/PSV, escort and women‑safety protocols, vehicle fitness, and route adherence with auditable trip logs. Checkbox audits only sample static documents without checking whether credentials are current, whether night‑shift escort rules are followed on actual routes, or whether geo‑fencing and SOS controls generate and close alerts through a command center or Transport Command Centre.
Robust data‑security audits map where commute data is stored and processed, test role‑based access and log retention, and align with India’s emerging data and privacy expectations. Superficial reviews only note that a mobility vendor claims app encryption or has generic ISO certificates, without tracing how trip, GPS, and employee identifiers move between EMS platforms, HRMS, and command‑center dashboards.
Process‑adherence audits that matter replay the full ETS Operation Cycle and Command Center operations. These audits follow bookings from employee app or desk, through rostering, routing, vendor allocation, live monitoring, incident handling, billing, and MIS, and then reconcile SLAs and exceptions with management reports and dashboards. Weak audits only verify that SOPs, Business Continuity Plans, and escalation matrices exist, without testing whether they are invoked during real disruptions such as cab shortages, monsoon traffic, political strikes, or technology failures.
Risk or Internal Audit teams should validate scope by insisting that audits explicitly cover end‑to‑end EMS flow, including driver and fleet compliance management, safety and women‑centric protocols, centralized compliance dashboards, and measurable performance indicators like OTP%, incident rates, and audit‑trail integrity. They should also validate recency by checking audit dates, sampling post‑audit trip logs and safety events, and confirming that non‑conformities led to documented corrective actions and updated SOPs rather than remaining as static findings.
images:


How do we confirm the sample data pack is the real production schema (not cleaned up) so we don’t discover HRMS/attendance integration issues after go-live?
B0485 Representative sample data validation — In India multi-site employee mobility services (EMS), how can an IT lead validate that anonymized data packs shared for evaluation are still representative (same schema as production, no manual ‘cleaning’) and won’t mask integration pain later with HRMS and attendance systems?
In India multi-site employee mobility services, an IT lead can validate anonymized evaluation data packs by insisting on using the same pipelines, schemas, and APIs as production and then technically verifying that structure and behaviour match HRMS and attendance integration needs. The goal is to test the real data model and integration friction, not a manually curated demo extract.
First, the IT lead should require that the vendor’s anonymization is pipeline-based, not Excel-based. The IT lead should ask for documented anonymization rules applied in the mobility data lake or ETL pipeline, such as deterministic tokenization of employee IDs, masking of phone numbers, and hashing of personally identifiable information. The IT lead should then confirm that these rules are applied on top of the production trip ledger schema, and not on a separate “demo” schema.
Next, the IT lead should demand a full schema export and compare it against what will be used in production integrations. The IT lead can request database DDL or JSON schema definitions for core entities such as trips, rosters, vehicles, drivers, and employees. The IT lead should verify that field names, data types, allowed values, and primary key and foreign key relationships in the evaluation pack match the stated production schema. Any missing fields that are required for HRMS mapping, such as employee code, cost center, and shift window identifiers, must be explicitly called out and justified.
The IT lead should also enforce API-first testing instead of offline file drops. The IT lead can insist on using the same REST or webhook interfaces that will be connected to HRMS, ERP, and attendance systems later. The IT lead should run test calls against the vendor’s staging API with anonymized data and confirm that pagination, filtering, and timestamp semantics are consistent with production documentation. This approach exposes potential performance and latency issues and reveals any undocumented transformations applied between storage and API responses.
To avoid hidden manual “cleaning,” the IT lead should request an end-to-end sample covering noisy edge cases. The IT lead should ask the vendor for data that includes cancelled trips, no-shows, partial shifts, GPS gaps, and manual overrides, because these situations are common in real EMS operations. If the evaluation data shows only ideal trips with perfect GPS and complete manifests, the IT lead should treat that as a signal of manual curation and request a raw slice from an actual multi-site operation, with PII still masked.
Finally, the IT lead should run a small, time-boxed integration spike with the enterprise HRMS and attendance systems. The IT lead can map anonymized employee identifiers to synthetic HRMS records and then test the full reconciliation logic from trip events to attendance outcomes. Any mapping gaps, inconsistent shift windowing, or timestamp mismatches that appear in this spike will likely reappear in production, so resolving them early prevents integration pain later.
images:

How can HR use exception and closure data to figure out if our daily escalations are mainly a vendor execution issue or something in our own roster/policy setup?
B0487 Diagnose vendor vs internal causes — In India employee mobility services (EMS), how can HR quantify whether recurring escalations are a ‘vendor execution problem’ versus an internal policy/roster problem, using evidence like exception latency, closure SLAs, and timeband-specific patterns from the vendor’s proof pack?
In India employee mobility services, HR can distinguish vendor execution failures from internal policy or roster issues by correlating each escalation with time-stamped operational evidence such as exception latency, closure SLA adherence, and timeband-specific patterns from the vendor’s proof pack. HR should treat every recurring complaint as a data point in a structured incident ledger that compares “what should have happened per SOP” versus “what actually happened per trip log and command-center evidence.”
HR can use exception latency as a primary discriminator. If GPS, driver app, or command center alerts show that delays or route deviations were detected early but not acted on within agreed SLAs, the issue is likely vendor execution. If there was no upstream exception at all because rosters were confirmed too late, pickup windows were unrealistic, or seat-fill policies forced impractical routing, the root cause sits with internal policies or roster design.
Timeband analysis helps reveal structural versus execution problems. If late pickups cluster in specific bands like heavy-traffic monsoon evenings or post-midnight windows, and vendor logs still show high fleet uptime and proactive rerouting (as in WTicabs’ monsoon case study with 98% on-time arrival), then escalation volume may indicate misaligned shift timing or buffer rules. If the same bands show frequent “no vehicle assigned,” last-minute cancellations, or repeated driver no-shows despite stable demand, vendor capacity planning or driver management is the likely gap.
HR should also compare closure SLAs and incident workflows. A consistent pattern where the command center opens tickets promptly, communicates ETAs, and closes incidents within agreed timelines points away from pure vendor negligence, especially if employees still escalate mainly about policy entitlements or rigid cutoff rules. Repeated breaches of closure SLAs, silent tickets, or inconsistent communication indicate vendor-side operational gaps regardless of policy quality.
Practically, HR can set up a recurring joint review with the transport head and vendor using a simple evidence-based split:
- “Supply-side” KPIs for vendor accountability such as OTP%, exception detection-to-action time, fleet uptime, driver compliance, and route adherence.
- “Demand and design-side” indicators for internal accountability such as late roster finalization, frequent last-minute additions, unrealistic reporting times, and chronic over- or under-subscription on certain routes or timebands.
When proof packs include CO₂ dashboards, EV utilization ratios, or business continuity logs, HR can further check whether sustainability or BCP decisions are constraining operations or whether the vendor is using these as excuses despite clear evidence of adequate infrastructure and buffers.
By insisting that every escalation is matched to auditable trip data, command center logs, and timeband trends, HR can move conversations from blame to design. The result is a defensible split of responsibility where vendor penalties focus on SLA and execution breaches, and internal improvements target roster logic, shift policies, and entitlement rules.
How should we document reference checks for employee transport so it’s audit-defensible later—who we spoke to, what we asked, and what they shared?
B0491 Audit-defensible reference documentation — In India employee mobility services (EMS), what’s the best way for Procurement to capture reference feedback so it’s audit-defensible later (who was contacted, what questions were asked, what evidence was provided) rather than informal notes that can be challenged?
Procurement teams in India EMS make reference checks audit-defensible when they treat them as a governed process with standard templates, logged channels, and preserved artefacts instead of informal calls and notes.
The core is a simple SOP. Procurement defines when references are required, which reference personas must be contacted for EMS (for example, HR, Transport Head, Security, or Finance at the client), and which minimum topics must be covered such as on-time performance, safety incidents, billing integrity, escalation responsiveness, and command-center behavior. This SOP is then tied to the mobility vendor governance framework so that no award can be issued without completed, filed reference packs.
Most organizations improve defensibility when they standardize a reference questionnaire. Each question is written down in a template and mapped to specific EMS concerns like women-safety protocols, night-shift reliability, BCP performance during disruptions, and billing or SLA dispute handling. The same question set is then used for all vendors. This reduces bias risk and makes later comparisons easier to defend in an audit.
Procurement usually needs a clear evidence trail. A practical pattern is to use only traceable channels such as official email IDs or recorded virtual meetings with consent. Teams log each interaction in a central repository, capturing reference contact identity, organization, role, and date along with the filled questionnaire and any supporting documents such as sample MIS reports, safety dashboards, or BCP playbooks that the reference client is willing to share.
To keep the process resilient, Procurement can define a short checklist of minimum reference artefacts that must be retained for each vendor. This often includes the completed questionnaire, a summary of call minutes, a simple scoring matrix across reliability, safety, cost discipline, and responsiveness, plus any documentary samples mentioned by the reference. This package can then be attached to the RFP evaluation file so that, if challenged later, the organization can demonstrate that reference feedback was collected systematically and used as one input to the final decision.
After rollout, what ongoing proof should we ask for—monthly scorecards by city/shift, RCAs, audit logs—so service doesn’t slip once the deal is done?
B0492 Prevent post-contract performance drift — In India corporate employee transport (EMS), after go-live, what proof should an operations head continuously demand from the vendor (monthly city/timeband scorecards, incident RCAs, audit trails) to prevent performance drift once the contract is signed?
In India EMS after go‑live, an operations head should insist on a fixed “evidence pack” every month that proves reliability, safety, compliance, and cost control in a way that can withstand internal and external audits. The goal is to convert a signed contract into a monitored, SLA-governed operation with no silent performance drift.
A core proof set is city– and timeband–wise performance scorecards. These should show on‑time performance, trip adherence, vehicle utilization, dead mileage, no‑show rates, and exception closure times for each location and shift window. Operations leaders can then catch pattern drift in specific cities, night bands, or vendor pools before it becomes a crisis.
Safety and compliance need their own continuous evidence. This includes driver KYC and PSV validity status, vehicle fitness and permit logs, women‑safety escort compliance, geo‑fence and over‑speeding alerts, and random route audit summaries. Incident logs with full root‑cause analyses and timestamped closure actions are essential for every safety event, even minor ones.
Data integrity is a separate proof stream. Vendors should provide GPS trip ledgers, roster vs actual run variance reports, and reconciled SLA dashboards that tie directly to billing. This reduces disputes with Finance and keeps Procurement and HR confident that service quality and cost per employee trip are not quietly degrading.
A practical monthly evidence pack usually includes:
- City/shift scorecards with OTP%, Trip Adherence Rate, utilization, and exception trends.
- Safety and compliance dashboards plus sample audit trails and incident RCAs.
- Billing‑linked MIS that reconciles trips, kilometers, and SLAs to invoices.
For our employee commute program, what hard proof should a vendor share (data packs, KPI improvement before/after, third-party audits) so HR can confidently show safety and reliability actually improved—especially for night shifts?
B0497 Proof pack for HR safety — In India corporate employee mobility services (EMS), what specific proof artifacts should a vendor provide—anonymized trip data packs, before/after on-time performance deltas, and third-party audit reports—so a CHRO can defend “women’s night-shift safety and reliability improved” without relying on vendor promises?
In India EMS programs, a CHRO can credibly defend “women’s night‑shift safety and reliability improved” only when vendors provide auditable artifacts that tie night‑shift trips to safety controls, outcomes, and closure quality. These artifacts must be time‑bound, anonymized, and reconstructable for any incident or board query.
The strongest base is a structured trip and incident data pack for women’s night shifts. This should include anonymized trip‑level logs with timestamps, origins/destinations, escort flags, SOS activations, GPS traces, and OTP outcomes segmented by gender and time band. Vendors should align this pack with internal HRMS data only through IDs or hashed keys so that CHROs can show incident rates, OTP%, and no‑show patterns for women in defined night windows.
CHROs also need clear before/after reliability and safety deltas specifically for women’s night shifts. Vendors should provide pre‑implementation and post‑implementation OTP% for night bands, safety incident counts per 10,000 trips, escort compliance rates, and women‑specific complaint volumes and closure SLAs. This lets a CHRO say that OTP improved and reported safety deviations fell after SOP and technology changes, supported by six‑month trend charts.
Independent assurance is essential for credibility beyond vendor claims. Third‑party safety and compliance audit reports should cover driver background‑check processes, route and escort compliance sampling, GPS tamper checks, and SOS response drills. These can be complemented by business continuity and risk‑mitigation playbooks that show how political strikes, technology failures, and cab shortages are handled without exposing women to added risk.
Finally, CHROs benefit from command‑center and alert‑system evidence. Dashboards from centralized command centers, alert supervision systems, and women‑centric safety protocols should show real‑time monitoring, escalation matrices, and closure timestamps for night‑shift alerts. Case studies that document measurable improvements in women’s late‑night safety and satisfaction, combined with internal commute‑NPS surveys for women employees, complete an evidence set that is defensible to leadership, auditors, and ESG stakeholders.
How do we check that the vendor’s KPI improvements aren’t cherry-picked, and what should we see in the anonymized data to trust the numbers?
B0501 Auditability of KPI deltas — In India corporate employee mobility services (EMS), how can Internal Audit validate that a vendor’s “before/after KPI deltas” for on-time pickup and incident reduction are not cherry-picked, and what minimum sampling or traceability should be visible in the supporting anonymized data pack?
Internal Audit can validate a mobility vendor’s “before/after” KPI deltas only when each trip and incident is traceable back to an auditable trip log, with a clearly defined universe, stable definitions, and sampling that covers whole timebands and high‑risk cohorts, not hand‑selected routes. Internal Audit should insist that the anonymized data pack allows reconstruction of OTP and incident rates from raw trip rows, with enough metadata to test completeness, consistency of definitions, and exclusion rules.
Internal Audit should first anchor on definitions and universes for EMS KPIs. On‑time pickup must have a fixed time window and rule for early/late arrivals, and incident reduction must be tied to a stable incident taxonomy over the comparison periods. The “before” and “after” datasets must cover the same sites, shift windows, and employee categories, or clearly disclose scope changes.
The anonymized data pack should expose row‑level trip data with unique trip IDs, date–time stamps, route or site tags, OTP flag based on a documented rule, incident flags, and a field that shows whether a trip was included or excluded in KPI calculations with a coded reason. Internal Audit can then recompute OTP% and incident rates, test that exclusions are rule‑based rather than outcome‑based, and look for breaks in continuity.
Sampling should prioritize risk rather than convenience. Internal Audit should draw full‑period samples for at least one full month pre‑change and one full month post‑change, and within those periods test 100% of trips for one or two critical shifts such as night and early‑morning windows. Additional stratified samples should cover different locations, vendors, and days of week, with particular focus on night‑shift women‑safety cohorts where duty of care is highest.
Traceability expectations should include the ability to tie sampled trips back to immutable trip logs, GPS or telematics traces, and any associated SOS or safety events as described in the command center and alert supervision collateral. Audit should see that OTP and incident metrics reconcile to what is shown on mobility dashboards and in management reports such as the indicative management report and single‑window dashboards, and that no alternative “shadow” dataset was used to generate marketing figures.
Red flags for cherry‑picking include missing high‑risk timebands, unexplained drops in trip counts between raw and reported numbers, period boundaries chosen to avoid known disruption events, and KPI improvements confined to narrow, low‑risk cohorts rather than overall EMS operations. A defensible vendor will be able to show consistent KPI computation across EMS, CRD, and project shuttle services, and will align its evidence pack with the same SLA and observability structures that support billing, safety compliance, and business continuity documentation.
If an auditor asks tomorrow, what should the vendor be able to produce instantly—trip logs, escort compliance proof, incident RCA—and how do we test that before signing?
B0505 One-click audit pack readiness — In India corporate employee mobility services (EMS), what does a “panic button” compliance pack look like for auditors—such as immutable trip logs, escort compliance evidence, and incident RCA artifacts—and how should a buyer test that the vendor can generate it quickly under audit pressure?
A panic button compliance pack in Indian employee mobility services is a complete, audit-ready evidence bundle for any SOS-triggered trip. It must reconstruct who travelled, when and where the panic was raised, what the system did in real time, and how the incident was closed and learned from. Auditors look for traceable trip logs, escort compliance, and structured RCA artefacts that stand up to legal and internal scrutiny.
A robust pack usually includes the following categories of evidence, each tied to a unique trip/incident ID.
-
Trip and routing evidence
• Immutable trip ledger with timestamps. There should be a system-generated trip record showing booking creation, roster allocation, vehicle assignment, start/stop times, route, and status changes.
• GPS trace and geo-fence logs. The vendor should provide a time‑stamped route trace, with any deviations and geo-fence violation alerts clearly marked.
• OTP/boarding proof. Logs of employee check-in (OTP, QR, app check-in) to prove who was in the vehicle at each point.
• Command center view. Screenshots or exports from the command-center dashboard showing the trip status before, during, and after the panic event. -
Panic/SOS activation trail
• SOS trigger details. Time, location, trigger channel (employee app SOS, IVMS, hardware button), and the user/vehicle ID that raised it.
• Alert fan-out. Evidence that the alert reached the transport command center and any escalation contacts (e.g., security, HR, vendor supervisor) with exact timestamps.
• Response SLAs. System logs showing when the call-back was initiated, when the driver was contacted, when security or local authorities were informed, and when the incident was marked “under control.”
• In-ride safeguards. If available, IVMS or dashcam event markers, over-speeding or harsh-brake alerts, and any accompanying notes by the command center. -
Escort and women-safety compliance
• Policy linkage. The relevant women‑safety or night‑shift policy showing when escort is mandatory and the defined routing/stop rules.
• Escort assignment proof. Roster or manifest showing escort name, ID, and duty times for the trip.
• Presence evidence. Check‑in/check‑out records for the escort (e.g., app attendance, RFID, manual duty slip scanned into the system).
• Route approval records. Pre-approved route details and any route change approvals stored in the system.
• Special protocols. Evidence of women‑centric safety controls such as “last‑drop female” rules, call masking, and safe‑reach‑home confirmation logs where applicable. -
Driver, vehicle, and compliance state at time of incident
• Driver profile snapshot. Current KYC/PSV validity, background verification status, and completion of POSH/safety training modules.
• Duty and fatigue metrics. Driver duty hours for that day/week to demonstrate adherence to rest‑period norms.
• Vehicle compliance status. Fitness, permit, insurance, and other statutory documents marked “valid” as on the incident date, ideally from a centralized compliance dashboard.
• Pre‑trip checks. Evidence from any digital or logged pre-trip safety inspection for that specific duty (e.g., “Safety Inspection Checklist for Vehicle”). -
Incident handling and RCA artefacts
• Incident ticket history. A ticket ID with full timeline of updates, attached notes, and role-based actions (who did what, when).
• Communication records. Call logs, SMS/app notifications, and email alerts related to the incident, redacted only for privacy but preserving metadata.
• RCA document. A structured root cause analysis describing the trigger, contributing factors, immediate containment, and preventive actions.
• Corrective and preventive actions (CAPA). Evidence that specific measures were implemented, such as driver re‑training, route changes, geo-fence tuning, or policy updates.
• Closure confirmation. Records showing employee acknowledgement (where appropriate), HR/Security sign‑off, and final closure status with date. -
Data integrity and chain-of-custody
• Audit trail integrity. System logs proving that core trip and incident records cannot be edited without trace, and that any changes are versioned with user IDs and timestamps.
• Access logs. Evidence of who accessed the incident data and when, to satisfy internal controls and data‑protection expectations.
• Retention policy. Documentation of how long panic/incident data is stored and how it aligns with corporate policy and emerging DPDP requirements.
To test whether a vendor can actually deliver this under audit pressure, buyers should move beyond presentations and run practical drills.
Key buyer tests and checks
• Live incident drill. Ask the vendor to pull the complete evidence pack for a real, recent SOS event (with identifiers anonymized). Set a strict time limit, such as 2–4 hours, and observe how many teams they need to involve.
• Simulated audit request. During evaluation, provide a random past date and trip ID and request: trip logs, GPS trace, panic logs, driver/vehicle compliance snapshot, and the RCA document. Measure completeness, response time, and consistency of timestamps across systems.
• Walk-through at the command center. Visit the centralized command center or NOC and ask operators to show, on their live system, how an SOS alert appears, how they acknowledge it, and where the resulting incident record is stored.
• Evidence export demo. Ask them to export a “panic button compliance pack” as a single bundle (e.g., zipped PDF set or structured report) while you watch, rather than stitching it manually in slides.
• Cross-check against policies. Share your own night-shift and women-safety policies. Ask the vendor to map, in writing, exactly which logs and artefacts they will provide to prove compliance for each clause.
• Data-integrity probing. Request to see audit logs and version histories for one sample incident to confirm that edits and deletions are traceable.
• Multi-stakeholder review. Have HR, Security/EHS, IT, and Internal Audit jointly review the sample pack and confirm whether it answers their standard questions about “what happened, were we compliant, and what changed after.”
Common failure signals during testing
• Reliance on manual collation using emails, WhatsApp, and Excel rather than a unified system of record.
• Gaps between trip logs and GPS data, such as inconsistent timestamps or missing segments.
• Inability to show escort presence beyond a static roster.
• No formal RCA template or CAPA tracking for closed incidents.
• Delayed response (e.g., taking days instead of hours) when asked for a complete evidence bundle.
In practice, a panic button compliance pack is credible when it is system-generated, time‑aligned across trip, device, and command-center logs, and directly tied to policies on escort and safety. Buyers should validate this by forcing the vendor to reproduce a full incident story on demand, under time pressure, before awarding any contract.
images:

How do we write the contract so the vendor’s KPI claims must be backed by verifiable evidence and not just slides—especially around OTP, incident rates, and closure SLAs?
B0506 Contracting for claims substantiation — In India corporate ground transportation contracting for employee mobility services (EMS), how should Legal and Procurement structure reference verification and claims substantiation so a vendor’s promised KPI outcomes (OTP, closure SLA, incident rates) are tied to verifiable evidence rather than marketing statements?
In India EMS contracting, Legal and Procurement should convert vendor KPI claims into auditable obligations by hard-wiring definitions, data sources, and evidence packs into the contract and RFP, rather than accepting narrative promises or marketing dashboards.
Most organizations treat KPIs like OTP, incident rates, or closure SLAs as numeric targets but do not define how trips are counted, which system is the “source of truth,” or what evidence must be produced during disputes. This allows vendors to showcase selective data or unverifiable reports. Reference verification fails when buyer and vendor use different baselines, when telematics logs are not preserved, or when HRMS and transport data do not reconcile.
Legal and Procurement can reduce this risk by locking three elements into EMS contracts. First, they should define KPI semantics in operational language. For example, OTP should be defined per trip against rostered shift time, based only on trips with valid manifests, and measured across all locations, not pilot clusters. Second, they should mandate system-of-record and auditability. The contract should specify that GPS or NOC trip logs, panic/SOS records, and closure timestamps will be retained as an immutable audit trail for a defined period under Indian audit norms, and that HRMS or access-control data can be used to cross-check attendance-linked metrics.
Third, they should make claims substantiation a precondition to award and renewal. Reference checks should require concrete proof such as prior client OTP%, incident rates, seat-fill, and CO₂ reductions that align with the same KPI definitions, not just testimonials. Vendors should be required to share sample anonymized trip ledgers, command-center escalation logs, and SLA compliance reports that reflect central command-center operations, safety and compliance controls, and business continuity playbooks.
Effective structures usually include a short set of enforceable mechanisms. These mechanisms include RFP annexures that define KPI formulas and data fields, contract clauses that require full data access and export in case of audit or exit, and quarterly joint reviews where HR, Finance, and Transport teams reconcile vendor-reported KPIs with internal HRMS and finance data. They also include penalty or earnback ladders linked to KPIs that can only be triggered when supported by trip-ledger evidence, incident reports, and closure SLAs. These approaches make EMS performance review a data-governed process instead of a debate about marketing claims.
How do we validate ‘zero-incident’ claims in employee transport—what incident definitions, near-miss reporting, and RCA proof should we ask for in data packs and reference calls?
B0514 Validating zero-incident claims — In India corporate employee mobility services (EMS), how can an EHS/Security lead verify that “zero-incident” claims are meaningful—what incident taxonomy, near-miss reporting, and RCA evidence should appear in anonymized data packs and reference customer discussions?
In corporate employee mobility services in India, “zero-incident” claims are only meaningful when they are backed by a clear incident taxonomy, consistent near-miss capture, and traceable RCA evidence across time and routes. An EHS/Security lead should treat the vendor’s anonymized data packs and reference discussions as an audit artefact, not a marketing narrative.
First, the incident taxonomy must be explicit and consistently applied. It should separate at minimum: security incidents during trips, safety incidents or accidents, women-safety specific events, compliance breaches, and technology failures that impact safety (e.g., GPS outage during night-shift EMS). Each category should have sub‑severities defined and mapped to closure SLAs and escalation matrices. A common failure mode is a vendor reporting “zero incidents” only because they classify everything below a high severity threshold as “service deviation” rather than “safety incident”.
Second, meaningful performance evidence requires near-miss reporting as a separate, high-volume layer. An EHS/Security lead should expect anonymized counts and trends for near‑miss events such as geofence violations, overspeeding alerts, fixed device tampering, escort-rule drops, SOS activations without injury, route deviations, and repeated night‑shift routing through red‑flag zones. A vendor that shows flat “zero incidents” and near-zero “near‑miss” numbers usually has weak telemetry or poor reporting culture rather than an exceptionally safe operation.
Third, RCA evidence needs to demonstrate a complete chain of custody from detection to closure. For a sample period, an EHS/Security lead should request redacted RCAs that show the original alert or incident log, time‑stamped data from GPS/IVMS and apps, escalation path through the command center, corrective actions taken (driver retraining, route change, escort policy enforcement), and how these fed back into SOPs. The strongest vendors also align RCA outputs to their continuous assurance loop, business continuity plans, and HSSE culture reinforcement programs.
images:
In the RFP itself, what’s the minimum proof we should demand upfront—documents and sample data—so we don’t evaluate vendors who can’t be audit-ready later?
B0518 Minimum evidence threshold in RFP — In India corporate employee mobility services (EMS) RFPs, what is a practical minimum “evidence threshold” (documents and sample datasets) to require at bid stage so Procurement doesn’t waste cycles on vendors who can’t produce audit-ready proof later?
A practical minimum evidence threshold in Indian EMS RFPs is a compact “proof pack” that demonstrates real operations, audit readiness, and data discipline before shortlisting. Procurement should ask for a standard set of documents plus at least one anonymized data extract that can be inspected like an audit sample.
At bid stage, most organizations can filter vendors effectively using four evidence buckets. The first bucket is compliance and safety governance. Typical asks include sample driver KYC and PSV documentation, a snapshot of centralized compliance dashboards, and written SOPs for women safety, night-shift escort rules, incident response, and Business Continuity Planning for cab shortages, strikes, tech failures, and disasters. Vendors who cannot show current, structured compliance artifacts usually fail later during audits.
The second bucket is command-center and observability proof. Procurement can require screenshots or redacted reports from a live 24x7 command center, including alert supervision (geofence violation, device tampering, overspeeding), escalation matrices, and sample shift-level OTP and incident reports. This connects directly to the Facility / Transport Head’s need for early alerts instead of firefighting.
The third bucket is sample operational data and billing traceability. A minimal dataset should include a one-week anonymized trip ledger with trip IDs, route details, timestamps, GPS-derived OTP%, no-show flags, and closure times, plus a linked sample invoice and MIS summary for the same period. This lets Finance and Procurement check whether SLAs, trips, and billing line items reconcile without manual patchwork.
The fourth bucket is ESG and EV-readiness evidence where relevant. For EMS programs that carry sustainability targets, vendors should provide a sample emissions dashboard, methodology for commute CO₂ calculations, and an example of EV utilization reporting. This supports ESG leads who must defend emission numbers with traceable data.
A simple way to operationalize this threshold is to make submission of these artefacts mandatory for technical evaluation. Procurement can specify that bids lacking: 1) formal safety and compliance SOPs, 2) live command-center reporting samples, 3) an auditable trip-to-invoice dataset, and 4) where applicable, an emissions sample, will not proceed to commercial opening. This reduces wasted cycles on vendors who look impressive in presentations but have no audit-ready backbone behind their claims.
How do we check that the vendor’s third-party audit is actually about their EMS operations (NOC, driver KYC, trip logs) and not just a generic certificate?
B0519 Relevance check for third-party audits — In India corporate employee mobility services (EMS), how should a buyer validate that a third-party audit report is relevant to the actual operating model—NOC processes, driver KYC cadence, and trip log integrity—instead of being a generic certification that doesn’t reduce real risk?
In India EMS, a buyer should only treat a third-party audit report as meaningful if it maps directly to the live operating model for NOC processes, driver KYC cadence, and trip log integrity, rather than just naming high-level certifications. The audit must test how daily shift operations, command-center workflows, and compliance checks actually run in production across cities and timebands.
A practical first filter is scope matching. The report should explicitly cover employee mobility services, not just generic fleet or ISO-style system audits. It should describe sampled routes, shifts, and locations, and reference elements like centralized or site-based NOC monitoring, escort rules for night shifts, and SLA governance for OTP and safety incidents.
The next check is operational traceability. A useful audit describes how driver KYC and PSV verification are sampled over time, how often re-checks are done, and how non-compliance is handled. It should test driver onboarding processes such as background verification, license validation, and periodic revalidation, rather than just listing there is a “policy.” Evidence such as sampling from AVD checks, driver compliance dashboards, and Driver Fatigue Index controls is a strong signal of depth.
For NOC and command-center processes, the report should document how real-time monitoring is performed, how alerts are triaged, and what escalation matrices exist. It should reference actual NOC tools like geo-fencing, SOS handling, and command center operations, and show sample incident tickets with timestamps and closure SLAs. If the report cannot trace a sample incident from detection to closure, it is likely too generic to reduce real risk.
Trip log integrity must be verifiable. A robust audit traces trips from booking and routing to trip completion and billing, and checks for GPS tampering controls, route adherence audits, and audit trail integrity. The report should confirm that trip ledgers, GPS logs, and billing entries reconcile, and that exceptions such as no-shows or diversions are captured and closed with a reason code.
Buyers can further validate relevance by asking the auditor or vendor to walk through a few real, de-identified cases end-to-end. For example, they can request a sample of night-shift trips for women employees, including manifests, driver credentials, route approval, SOS readiness, and closure of any deviations. If the vendor cannot produce this chain-of-custody on demand, the audit is unlikely to reflect the live EMS operating model.
Finally, the buyer should check how often audits are repeated and how findings are tracked. An audit that feeds into a continuous assurance loop, with corrective actions and re-testing, provides more real risk reduction than a one-time certification. Reports that tie findings to specific KPIs like OTP%, incident rates, and SLA breaches show tighter coupling between audit and daily EMS performance.
Before a large rollout, what proof should we ask for that grievance tickets actually get resolved—ticket aging, closure SLAs by shift, and what reference customers say about escalations?
B0520 Proof of grievance closure performance — In India corporate employee mobility services (EMS), what proof should HR and Facilities ask for to confirm grievance closure works in practice—like ticket aging distributions, closure SLA adherence by timeband, and reference customer feedback on escalations—before rolling out to thousands of employees?
In Indian employee mobility services, HR and Facility heads should demand hard, operations-grade evidence that grievance closure is real, repeatable, and auditable before scaling to thousands of employees. They should focus on data that proves how fast issues are detected, how reliably they are closed across timebands, and how employees rate the outcome after escalations.
They should first ask for a live or redacted view of the vendor’s command-center tooling and alert supervision layer. This includes evidence of real-time alerts for geofence violations, device tampering, overspeeding, SOS triggers, and no-show patterns, along with associated escalation workflows and closure tracking. They should verify that the Transport Command Centre or equivalent has 24/7 coverage, clear escalation matrices, and structured dashboards that show open tickets, pending actions, and closure SLAs.
They should evaluate historical ticket and escalation data across at least one or two reference accounts. This should include ticket aging distribution by severity, adherence to closure SLAs by timeband (day vs late-night), and exception-to-closure timelines for safety-related incidents. HR and Facilities should insist on audit-ready reports that map grievances to root-cause analysis, corrective actions, and recurrence trends.
They should also ask for reference customer feedback specifically on escalations and incident handling. This includes client testimonials and satisfaction surveys that highlight responsiveness, reliability during crises, and improvements in on-time performance and employee satisfaction after implementing the grievance and command-center model. Evidence of improved OTP, reduced complaints during adverse conditions, and high CSAT or user satisfaction scores are strong signals that grievance closure works in practice.
Finally, they should verify that the grievance and closure process is embedded into a broader governance and BCP framework. That means there are documented business continuity plans, safety and security protocols, women-centric safety measures, and periodic audits. These should all feed into dashboards and management reports that HR and Facility heads can use to monitor performance without relying solely on vendor assurances.
After go-live, what proof cadence should we expect—monthly KPI packs, quarterly audits, periodic checks—so we catch performance drops early and stay audit-ready?
B0524 Post-go-live proof cadence — In India corporate employee mobility services (EMS) post-purchase governance, what ongoing evidence cadence—monthly KPI delta packs, quarterly audits, and periodic reference check-ins—helps HR and Finance stay audit-ready and avoid being blindsided when performance quietly degrades after the first 90 days?
In corporate employee mobility services in India, HR and Finance stay audit-ready by enforcing a fixed evidence cadence that combines monthly KPI delta packs, quarterly deep-dive audits, and semi-annual reference or market check-ins. This cadence keeps reliability, safety, cost, and ESG trends visible before complaints or audits surface, and it creates a defensible paper trail when performance drifts after the first 90 days.
A monthly rhythm works best when vendors deliver standardized KPI “delta packs” rather than raw dumps. These packs typically include On‑Time Performance, exception latency, incident and safety logs, Trip Fill Ratio, dead mileage, Cost per Employee Trip, and basic EV/ESG metrics if relevant. HR uses this to link commute reliability to attendance and complaints. Finance uses it to reconcile billed trips with system data and to flag leakage or unexplained cost movement.
Quarterly, organizations benefit from a heavier governance cycle with structured route adherence and safety audits, sample billing and tariff verification, and compliance checks on driver and vehicle documentation. This audit layer catches slow degradation in routing quality, fatigue management, or women-safety protocol adherence that monthly snapshots may not reveal. It also gives Procurement and Internal Audit defensible evidence if contracts need penalty triggers or course-corrections.
On a slower cadence, HR and Finance should also run periodic external reference or benchmark check-ins. These can include independent customer satisfaction baselines, cross‑site comparisons, and limited external benchmarking against similar enterprises using end‑to‑end services. This protects against a single-vendor view, surfaces silent dissatisfaction, and gives CFOs a narrative if rebids or EV-transition changes are proposed.
During a pilot, how can Ops quickly check if the vendor’s ‘proof’ actually reduces day-to-day firefighting—like fewer escalations and manual follow-ups—without building heavy analytics?
B0525 Pilot measurement of operational drag — In India corporate employee mobility services (EMS), how can a Facilities/Transport manager measure whether “proof and references” translate into less operational drag—fewer escalations, lower manual follow-ups—during a pilot, without needing a full analytics rebuild?
In Indian corporate employee mobility, a Facilities or Transport manager can test whether a vendor’s “proof and references” actually reduce operational drag by running a tight pilot that tracks a few manual, operations-facing indicators before and after, without building a new analytics stack.
The most reliable signal set comes from the control-room workload and escalation noise. Operational drag reduces when night-shift calls drop, WhatsApp/SMS chasing reduces, and exception tickets close faster with less manual intervention. These patterns can be captured using simple logs, spreadsheets, and existing email or ticket trails rather than new dashboards.
A practical approach is to define a short pilot window, lock 4–6 low-friction metrics, and compare them against a baseline from a similar shift pattern. Facilities or Transport teams can count vendor references and case studies as “claims” but treat these pilot numbers as the real validation of those claims.
Key metrics the manager can track with minimal tooling are: - Number of transport-related calls to the control room per 100 trips. - Number of escalations to HR, Security, or senior leadership per week. - Manual roster or route changes per shift due to vendor-side failures. - Average time to close incidents or exceptions using existing ticket or email trails. - No-show or missed-pickup incidents per 100 trips, especially in night shifts. - GPS or app-failure workarounds where manual tracking or calling was required.
If the vendor’s “proof” is real, the pilot should show a visible drop in calls, escalations, and manual patchwork, even if core analytics or HRMS integrations remain unchanged during the test.
For our employee transport program, what proof should we ask for besides a presentation—like anonymized trip data and OTP improvements—so HR isn’t left defending the decision after a night-shift issue?
B0527 HR-ready proof beyond demos — In India corporate Employee Mobility Services (EMS) for shift-based employee transport, what specific proof artifacts should a CHRO require beyond vendor slideware—such as anonymized trip data packs, incident logs, and before/after on-time pickup (OTP) deltas—to feel confident the program will hold up during night-shift escalations and leadership scrutiny?
A CHRO who wants EMS decisions to withstand night-shift incidents and leadership scrutiny should insist on concrete proof packs across five areas. Each artifact must be exportable, auditable, and tied to shift-based operations, not just marketing narratives.
First, CHROs should require operational reliability evidence. This includes anonymized, time-banded OTP and Trip Adherence Rate reports by site, shift window, and gender split, with before/after deltas for any “optimization” claims. It should include dead mileage and Trip Fill Ratio data for pooled routes, plus exception latency reports showing how fast missed/late pickups were detected and closed. Case-study style summaries of challenging conditions, such as monsoon routing with quantified OTP and customer satisfaction uplift, strengthen this pack.
Second, CHROs should demand safety and compliance artifacts. These include redacted incident and near-miss logs covering SOS triggers, route deviations, and escort or women-first protocol breaches, with time-stamped escalation chains and closure notes. They should also see driver and fleet compliance packs, including documented KYC/PSV verification, background check steps, medical fitness, and structured training calendars, plus vehicle compliance checklists and pre-induction audit records. A documented night-shift SOP bundle that covers routing rules, escort logic, and rest-hour observance is critical.
Third, CHROs should ask for command-center and governance proof. This means sample dashboards or screenshots from the 24x7 command center showing live route tracking, geo-fencing alerts, and SLA breach views, together with escalation matrices and business continuity playbooks that cover cab shortages, technology failures, political strikes, and extreme weather. Evidence of periodic route adherence audits and management reports, such as indicative MIS or single-window dashboards, reinforces governance maturity.
Fourth, CHROs should require employee-experience and grievance closure evidence. This includes commute satisfaction or NPS survey outputs and methodology, complaint and ticket logs with age, severity, and closure SLA performance, and examples of women-centric safety protocols in action, such as dedicated fleets, safety cells, and POSH-linked driver training. Redacted employee app screenshots showing SOS capabilities, live tracking, and feedback loops can demonstrate that EX is embedded in the trip lifecycle.
Fifth, CHROs should insist on data integrity and auditability proof. This includes descriptions of how trip data, GPS logs, and incident records are stored, for how long, and in what format for audits, as well as confirmation of role-based access and tamper-evident audit trails. Demonstrable integration with HRMS or attendance systems, and the ability to produce exportable, investigator-ready bundles for a single route, date, and employee cohort, will increase confidence that any future investigation or leadership review can be handled with evidence instead of anecdote.
For executive/airport trips, how do we ask for KPI improvements in a way that’s credible and not cherry-picked—punctuality, cancellations, and complaint closure?
B0529 Interpreting before/after KPI deltas — In India corporate Corporate Car Rental (CRD) for executive and airport travel, what is a credible way to request and interpret before/after KPI deltas (e.g., pickup punctuality, cancellation rate, complaint closure time) so a Travel Desk and Admin team can distinguish genuine service improvement from cherry-picked reporting?
In corporate car rental for executives and airport travel in India, the most credible way to request and interpret before/after KPI deltas is to standardize definitions and time windows upfront, demand raw trip-level extracts aligned to Finance and HR systems, and compare performance across the entire eligible population rather than only “managed” or “priority” trips. This approach reduces cherry-picking and forces vendors to prove that improvements in pickup punctuality, cancellation rate, and complaint closure time are consistent, auditable, and finance-reconcilable.
A common failure mode is accepting percentage improvements on a subset of routes or VIP users. Travel Desk and Admin teams should insist that KPI baselines and post-change numbers are computed for all CRD trips in scope, over the same day-of-week and timeband mix, and explicitly tagged with inclusions and exclusions. They should also align reported trip counts and spend with Finance billing data to ensure that no adverse trips are silently dropped from the analysis.
A practical guardrail is to treat each KPI as a contract-grade metric. For pickup punctuality and cancellation rate, teams should request trip-level logs with timestamps, SLA thresholds, and exception codes, then validate random samples against GPS data or duty slips. For complaint closure time, they should demand ticket-level data with open/close timestamps and categorize issues by severity so that fast closure of minor issues does not mask slow resolution of serious complaints.
To distinguish genuine improvement from noise, Travel Desk and Admin can compare pre-and post-implementation KPIs over at least one full quarter each, segmented by city, vendor, and customer persona. They can then examine whether gains in on-time pickup coincide with side effects such as higher no-show charges or increased dead mileage, which would shift cost or risk elsewhere rather than delivering true service enhancement.
How do we make sure the vendor’s data pack ties back to billing—trip IDs, exceptions, cancellations—so Finance isn’t doing manual reconciliations every month?
B0533 Data pack ties to invoicing — In India enterprise ground transportation outsourcing for Employee Mobility Services (EMS), how can a CFO validate that a vendor’s anonymized data pack is reconciliable to invoice logic (trip IDs, route IDs, exceptions, cancellations) so Finance isn’t trapped in monthly manual reconciliation and audit risk?
In enterprise EMS outsourcing, a CFO can validate that a vendor’s anonymized data pack is reconciliable to invoice logic only if every billed rupee can be traced to a unique trip record, with explicit handling of exceptions, cancellations, and manual overrides. Finance gains control when trip-level telemetry, EMS process flow, and billing models share the same IDs, timestamps, and business rules, and those rules are documented and testable in a repeatable SOP.
A practical starting point is to insist on a canonical trip ledger. Each ride in Employee Mobility Services needs a single trip ID that appears identically in the driver app, employee app, command center dashboard, and billing system. Route IDs, roster batches, and vendor-allocated vehicles should be stable keys that link operational logs to commercial models such as per-km, trip-based, or per-seat billing. An anonymized data pack remains auditable when sensitive employee fields are masked but all technical identifiers and timestamps are preserved.
Finance leaders should require a clearly documented mapping between the EMS operation cycle and the billing pipeline. That mapping should show how booking, routing, dispatch, completion, no-show, cancellation, and exception events flow into chargeable or non-chargeable line items. A common failure mode is when exceptions are tracked in the command center or alert supervision system but never flow through to automated tariff mapping or centralized billing features, forcing manual intervention. Another failure mode is when route optimization or re-routing during monsoon or disruption changes trip geometry but does not update the commercial basis, creating unreconciled dead mileage.
To reduce monthly manual reconciliation, CFOs can define a small set of regression checks as part of vendor onboarding. These checks include verifying that the count of completed trips in the EMS operation cycle matches the count of billed trips, that total billed distance matches the sum of GPS or odometer distance within an agreed tolerance, and that cancellations and no-shows appear both in the operational logs and in credit notes or zero-value invoice lines. Finance should also test whether outcome-linked metrics like on-time performance, seat-fill, and SLA breaches can be independently recomputed from the anonymized pack and tied to any incentives or penalties in the contract.
When we call references, how do we validate that low complaints and fast closures are real—and based on logs, not hidden escalations?
B0537 Validating complaint and closure claims — In India enterprise Employee Mobility Services (EMS), how should an HR Operations manager structure a reference call to validate whether employee experience claims (low complaint volume, fast grievance closure) are backed by traceable logs and not suppressed escalations?
An HR Operations manager should structure an EMS reference call to move from generic satisfaction talk to specific, verifiable evidence about complaints and closure logs.
The most reliable calls follow a simple structure. The structure begins with clarifying what “good employee experience” means in that organization in terms of complaints per 1,000 trips, typical issues by shift band, and expected closure SLAs. The structure then moves into how the reference client captures, tags, and reports complaints across channels, and closes with questions about failure modes, suppressed escalations, and how issues are surfaced to leadership.
A practical way to run the call is to chunk it into four sections.
- Context and scale. The HR Operations manager should ask the reference to quantify daily trips, city mix, shift mix, and tenure with the vendor. This anchors any “low complaint” claim against actual EMS volume.
- Complaint intake and logging. The HR Operations manager should ask which channels employees actually use to complain, such as app, call center, email, or security desk. The manager should ask if all these channels feed into a single ticketing or command-center system, and whether every incident receives a unique ID and time-stamped log.
- Closure and governance. The HR Operations manager should ask what formal closure SLA exists for transport complaints by severity, and whether the vendor publishes weekly or monthly reports showing open, in-progress, and closed grievances. The manager should ask who reviews these in the client organization, such as HR, Security, or Transport, and how often.
- Suppression and escalation culture. The HR Operations manager should ask if employees bypass the vendor and go directly to HR or leadership for commute issues. The manager should then ask whether those direct escalations are back-entered into the same log, and whether any pattern of “quiet” dissatisfaction was discovered only through surveys or floor connects.
To validate traceability, the HR Operations manager should request that the reference describe one or two real night-shift incidents end-to-end from first complaint to closure. The manager should listen for whether timestamps, channel transitions, and actions taken are clear and consistent with a centralized command-center or NOC model. The manager should also ask if HR has self-service access to historic complaint logs and not only curated MIS sent by the vendor.
The HR Operations manager should interpret red flags carefully. Red flags include a reference that cannot quote even approximate closure SLAs, that relies only on informal WhatsApp or phone resolutions, or that reports “no complaints” despite high trip volume or challenging geographies. Signals of maturity include alignment with centralized command-center operations, presence of a documented escalation matrix, and linkages between complaint reports, HRMS integration, and user satisfaction or NPS dashboards.
What’s a reasonable minimum bar for third-party audits in mobility, and how do we check the audit scope is current and meaningful?
B0539 Minimum bar for third-party audits — In India corporate ground transportation vendor evaluation (EMS/CRD), what is a reasonable minimum bar for third-party audits (safety, compliance, security) and how should a buyer verify the audit scope isn’t superficial or outdated?
A reasonable minimum bar for third‑party audits in Indian corporate ground transportation is that vendors undergo independent, recurring audits that cover driver and fleet compliance, safety processes (especially women’s safety and night shifts), statutory adherence, data/security practices, and business continuity readiness, with traceable documentation that can be tied to daily operations and command‑center workflows. Buyers should verify that the audit scope is recent, evidence‑backed, and aligned to actual EMS/CRD operations, not just a one‑time or generic certification exercise.
A robust baseline usually includes continuous driver and fleet compliance checks, not only onboarding checks. Vendors should be able to show structured frameworks like detailed driver verification flows, periodic medical fitness and training records, and vehicle compliance and induction processes that reference fitness, documentation, and mechanical condition over time. Buyers should look for centralized compliance management processes with automated reminders, maker–checker controls, and vehicle/driver document repositories rather than static PDFs.
Safety and women‑safety controls need their own auditable trail. A reasonable minimum is clearly documented SOPs for women‑centric safety protocols, SOS response handling, alert supervision systems, and escort or route rules for night shifts. Vendors should be able to produce incident logs, closure SLAs, and examples of how the command center intervenes during breaches, not just policy slides. Safety inspection checklists for vehicles and records of shift‑wise driver briefings and training are practical proof points.
Security and business continuity should be part of the same assurance story. Buyers should ask for business continuity plans that explicitly cover cab shortages, natural disasters, political strikes, and technology failure, including mitigation steps and assigned responsibilities. Evidence of transport command centre operations, escalation matrices, and 24/7 monitoring capacity is a minimum operational check, especially for EMS and critical CRD.
To ensure the audit scope is not superficial or outdated, buyers can apply a few practical tests: - Check recency and cadence. The buyer should insist on seeing when the last external or internal audit was performed across driver, fleet, safety, and command‑center processes, and what the audit cycle is. One‑time audits or very old reports are a red flag. - Demand sample evidence chains. For at least a few recent trips or incidents, buyers should request anonymized trip logs, GPS traces, compliance checks, and incident resolution records that map back to the claimed processes. If the vendor cannot connect policy slides to concrete trip‑level artefacts, the audit is likely shallow. - Validate governance and escalation design. Vendors should be able to show an operational governance structure with defined roles, escalation matrices, and committee or review cadences for safety, compliance, and performance. A functioning command‑center governance model with micro‑functioning steps and service‑improvement loops suggests audits are embedded in operations. - Look at training and culture, not only forms. Buyers should ask to see driver assessment and training programs, rewards and recognition for safe driving, and HSSE culture reinforcement tools. Regular briefings, documented trainings, and DEI or women‑safety initiatives indicate that safety and compliance are lived, not just audited. - Cross‑check with dashboards and reports. A mature vendor can surface management reports, single‑window dashboards, and data‑driven insights that show real‑time compliance visibility, safety metrics, and deviation tracking. If dashboards and audit claims are misaligned, the underlying audit is suspect.
In practice, the most reliable indicator that audits are meaningful is when safety, compliance, and security controls show up consistently in live command‑center operations, driver and fleet lifecycle management, and business continuity playbooks, rather than existing only as standalone certificates or policy documents.
How can Internal Audit check that trip logs and GPS traces are tamper-evident and traceable, so we’re not relying on unverifiable data during audits?
B0541 Tamper-evident trip log validation — In India Employee Mobility Services (EMS) across multiple vendors, how should an Internal Audit lead test whether the vendor’s trip logs and GPS traces have tamper-evident controls and chain-of-custody, so audit findings don’t hinge on unverifiable data?
Internal Audit teams should validate tamper‑evidence and chain‑of‑custody for EMS trip data by testing how raw GPS and trip events are generated, stored, altered, and reported across the full trip lifecycle. The controls are credible only when auditors can independently trace a sample trip from device telemetry to final invoice or MIS without unexplained gaps or editable “black boxes.”
Auditors should first map the complete trip lifecycle for each key vendor. This includes trip creation, driver acceptance, roster sync from HRMS, GPS start/stop, SOS or incident flags, route adherence checks, and trip closure and billing. Each transition in this lifecycle should have a time‑stamped record, and the vendor should demonstrate how those records are technically and procedurally protected from retroactive alteration.
GPS tamper‑evidence can be tested by comparing live or near‑real‑time feeds from the telematics or IVMS layer with stored trip logs for the same period. A common failure mode is where historical tracks can be bulk‑overwritten or deleted inside the vendor platform without leaving an immutable audit trail. Internal Audit should attempt, under controlled conditions, to edit or delete sample trips using standard operations roles to see whether the system blocks changes, logs them with before/after values, or silently accepts them.
Chain‑of‑custody testing should follow a data‑lineage approach. Auditors select a stratified sample of trips across shifts, vendors, and cities. For each trip, they trace data from the source (vehicle GPS, driver app) through intermediate systems (routing engine, command center tools) into MIS, billing, and ESG reporting. At each hop, they verify that the vendor can export raw, time‑stamped records, show system clocks alignment, and explain any transformations such as aggregation or rounding.
Role‑based access and maker‑checker patterns are critical adjacent controls. Internal Audit should review user‑role matrices to confirm that operations users cannot both execute trips and edit core telemetry or trip outcomes, and that any override (for example, manual trip closure when GPS fails) requires dual authorization and generates a clearly labeled exception record. The “Centralized Compliance Management” and “Alert Supervision System” collateral show the kind of centralized, role‑segregated environments that support this.
To avoid findings based on unverifiable data, Internal Audit should document and test:
- Whether raw GPS and trip events are retained for a defined period with restricted, logged access.
- Whether there is a consistent, exportable trip ledger for all vendors that aligns with HRMS rosters and billing runs.
- Whether incident and SOS records from command centers can be tied back to underlying trip and GPS events without gaps.
If any vendor cannot provide end‑to‑end, time‑aligned, and exportable evidence for sampled trips, Internal Audit should flag the associated KPIs and ESG numbers as non‑assurable and recommend minimum technical requirements for future EMS contracts.
For airport trips, what reference proof can we ask for to confirm flight delays won’t lead to inflated waiting charges and billing disputes?
B0543 Flight delay handling and billing proof — In India enterprise Corporate Car Rental (CRD) for airport transfers, what reference evidence should a Finance Controller ask for to confirm the vendor handles flight delays and schedule changes without inflating wait-time charges or creating billing disputes?
Finance Controllers in India evaluating Corporate Car Rental (CRD) for airport transfers should insist on evidence that the vendor’s flight-handling logic, dispatch SOPs, and billing systems are tightly integrated. This reduces discretionary wait-time charges and makes disputes rare and easy to resolve.
The most reliable evidence combines three elements. The first element is technology proof. The Finance Controller should ask for screenshots or a live demo of flight-linked tracking and dispatch rules. The vendor should show how airport pickups are tied to live flight status, how the system auto-adjusts reporting time after delays, and how wait-time starts only after a defined grace window post-actual landing. The Finance Controller should also ask to see trip logs from the transport dashboard that show timestamps for “vehicle at airport,” “flight actual arrival,” “passenger onboard,” and “trip start,” because these logs anchor any wait-time computation.
The second element is billing governance proof. The Finance Controller should ask for a documented airport SLA and commercial policy that codifies free wait-time slabs, maximum chargeable wait-time, and conditions under which wait-time is waived. The Finance Controller should request a sample invoice pack from an existing client, including the tariff mapping sheet, the trip-wise billing extract, and the reconciliation report that links SLA rules to actual charges. Centralized billing process documentation with clearly defined steps for tariff mapping, online reconciliation, customer approval, and credit notes provides assurance that exceptions do not silently inflate invoices. Evidence of flexible billing configurations and automated tax calculations is also relevant, because these features reduce manual edits that tend to create disputes.
The third element is outcome and dispute-history proof. The Finance Controller should ask for an indicative management report or dashboard view showing historical airport OTP, wait-time patterns, and SLA-breach rate for similar accounts. Case studies or testimonials that mention “minimal billing disputes,” “transparent airport billing,” or “smooth reconciliation” are useful, especially when backed by centralized billing system screenshots. Finance leaders should also request an explanation of the vendor’s escalation matrix for billing disputes, including approval thresholds, credit note turnaround times, and the role of account management and the command center in resolving airport-related claims before they reach Finance.
images:
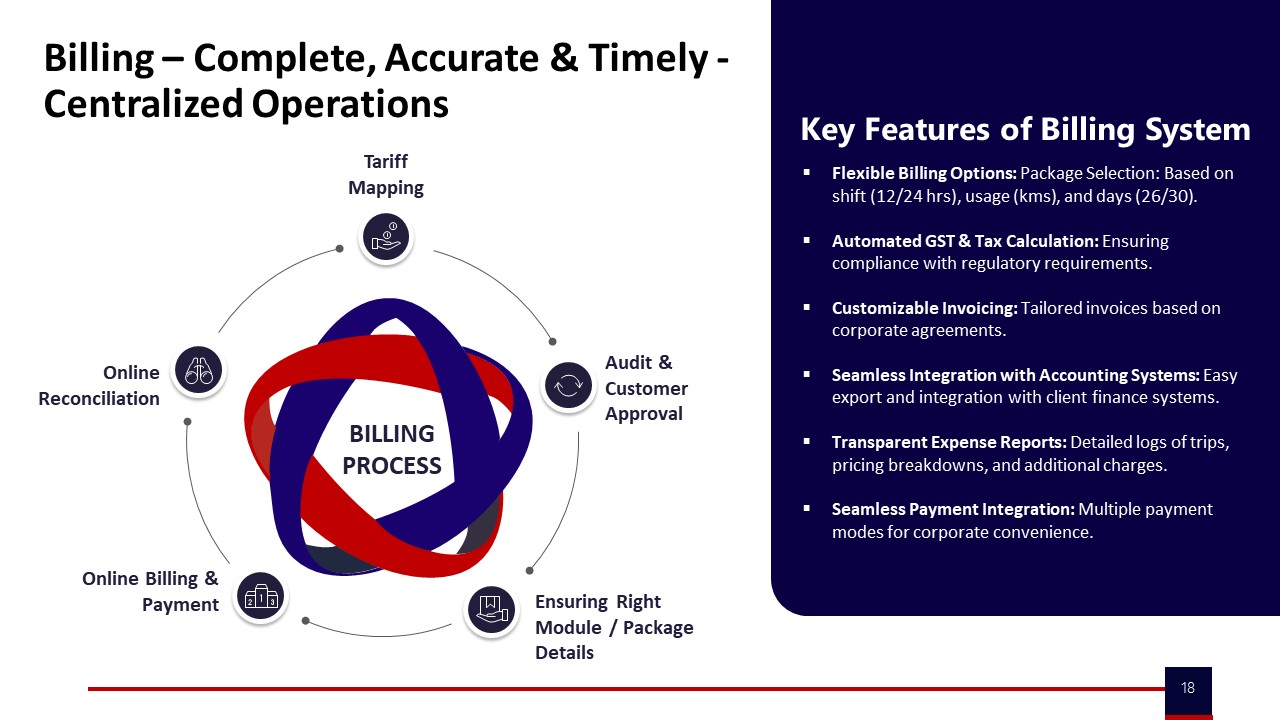
HR wants to go fast but IT needs security checks—what proof and references help us agree on a realistic go-live plan so nobody gets blamed if timelines move?
B0548 Using proof to align HR and IT — In India corporate EMS deployments where HR wants rapid rollout but IT insists on security gates, what proof and references can be used to align both sides on a realistic go-live plan without turning the project into a political blame game if timelines slip?
In Indian corporate EMS deployments, HR and IT usually align best when the go-live plan is anchored on pre-agreed evidence, staged milestones, and externally validated references rather than optimistic dates or generic promises. A realistic plan uses proof from prior EMS/EV programs, codified BCP and security artefacts, and live dashboards to show progress week by week, so timeline slips become managed risk, not personal failure.
HR can ground urgency using real EMS case studies and user-experience evidence. The Mumbai monsoon routing case with 98% on-time arrival and 10% higher satisfaction, the female-safety night-shift case with 98% on-time performance and a 15% satisfaction lift, and the 97% satisfaction survey in ETS testimonials all demonstrate that structured command-centre operations and women-centric safety protocols stabilize EX when deployed with discipline, not shortcuts.
IT can protect security baselines by insisting on an explicit pre-go-live “security and resilience pack”. This should include centralized compliance management for vehicles and drivers, safety-and-compliance frameworks, business continuity plans for tech failures and political or climate events, and insurance coverage for cyber, crime, and liability. These artefacts demonstrate continuous-assurance thinking and reassure IT that EMS is not a shadow-IT deployment.
The two sides can then co-own a phased, week-wise transition plan. The indicative transition and project planner collaterals already map 6–10 weeks of pre-transition, manpower deployment, tech implementation, and fleet rollout. HR can point to these as “industry-normal” lead times rather than arbitrary delays. IT can insert explicit security gates into the same plan: HRMS integration checks, API and data-flow validation, role-based access configuration on the transport command centre and dashboards, and DPDP-aligned user onboarding flows.
To prevent a political blame game when timelines move, governance must be as explicit as the technology. The MSP governance structure, escalation matrix, and engagement model show how leadership, senior management, and service-delivery executors share accountability, with defined review cadences. The command centre micro-functioning collateral further clarifies which KPIs are monitored, how exceptions are escalated, and how incident closure is audited. When these structures are adopted, slippages are discussed as “risk items against plan” in joint HR–IT–Transport reviews, not as one function blocking another.
Two kinds of proof help both sides accept staged go-live instead of “big bang” rollouts. First, operational outcomes from live EV and EMS programs: 86–93% fleet uptime, 6.8→8.2 satisfaction gains, 10–15% idle-time reduction, and 25–30% cost and emission reductions, all achieved with centralized tech platforms, route planners synced to HRMS, and real-time CO₂ and trip dashboards. Second, safety and compliance evidence: chauffeur assessment and training procedures, nine-step driver compliance verification, fleet compliance and induction checks, women-centric safety protocols with 24/7 safety cells and SOS control panels, and alert supervision systems for geofence and tampering events.
A realistic and blame-resistant go-live plan in this context usually has three clearly documented layers:
- Phase 1 — Controlled Pilot. Limited sites or shifts, full tech stack (employee, driver, and admin apps; command centre; compliance dashboards), with HR and IT jointly defining success metrics such as OTP%, incident-free nights, and clean HRMS integration.
- Phase 2 — Scale-Out with Guardrails. Additional locations and shifts, but only after BCP drills (for system downtime, cab shortages, strikes), security sign-off on integrations, and verification that billing data reconciles with Finance.
- Phase 3 — Optimization and Automation. Introduce more automation (dynamic routing, EV optimization, analytics dashboards, automated billing) only when Phase 1–2 KPIs are stable and IT is comfortable with data flows and observability.
Throughout, both HR and IT should commit in writing to a shared measurement language. Using the indicative management reports and dashboards, they can agree which KPIs define “ready to scale”: on-time performance, incident rate, user app adoption, complaint closure SLA, audit-trail completeness, and system uptime. When these metrics are visible in a single-window dashboard and in CO₂ and safety dashboards, executive reviews focus on numbers rather than narratives about who delayed what.
This approach reframes “slipped timelines” as controlled extensions to satisfy mutually defined gates. HR retains a credible story on employee safety and EX uplift backed by case studies, while IT retains a defensible posture on security, DPDP alignment, and resilience. Both can point leadership to the same proof set, governance structure, and transition plan, reducing the space for personal blame and framing EMS rollout as a joint enterprise initiative with traceable, auditable progress.
If an auditor asks today, what audit pack should the vendor be able to generate quickly—driver KYC, permits, manifests, SOS events, and escalation timelines?
B0549 One-click audit pack expectations — In India corporate employee transport (EMS), what 'audit pack' should a Compliance officer expect the vendor to produce on demand—covering driver KYC/PSV status, permits/fitness, trip manifests, SOS events, and escalation timelines—when an auditor asks for evidence the same day?
An effective “same-day” audit pack in Indian EMS should be a pre-assembled, timestamped evidence bundle that links each trip, vehicle, and driver to clear compliance records and incident handling timelines. The key principle is traceability: every pick-up and drop must be reconstructable with auditable proof of driver KYC/PSV, vehicle permits/fitness, trip manifests, SOS events, and escalation actions.
A robust vendor typically maintains a centralized compliance dashboard with document repositories for driver KYC/PSV, vehicle fitness/permits, and route adherence logs. The compliance officer should be able to request a defined date range, site, or incident, and receive a structured pack rather than raw, fragmented exports. A common failure mode is vendors sending unlinked spreadsheets and PDFs that auditors cannot reconcile to specific trips or incidents.
For EMS, the audit pack should minimally include:
- Driver & KYC/PSV Evidence: Active driver master list for the audit period. For each driver used on the selected trips, a snapshot showing KYC completion, PSV badge validity, background verification status, training completion, and expiry dates as of the trip date.
- Vehicle Compliance & Permits: Vehicle master for all cabs used, with fitness, registration, insurance, and permit validity mapped to the trip date. Pre-induction checklist records and any periodic compliance audit logs.
- Trip & Manifest Logs: Trip-level ledger for the period, with unique trip IDs, vehicle and driver tags, route and shift window, employee manifests, OTP/boarding confirmations, and trip start–end timestamps.
- Safety, SOS, and Escalation Trail: Register of all SOS or safety events in that window, including trip ID, timestamps for trigger, acknowledgment, escalation levels, and closure, plus narrative or ticket logs showing actions taken.
- Route Adherence & Geo-Fence Evidence: GPS traces or summarized route adherence reports for sampled trips, highlighting any deviations or geofence violations and their resolution notes.
- Governance & SLA Summary: Incident and SLA dashboard extract for the period, covering on-time performance, incident counts, closure SLAs, and any non-compliances with documented corrective actions.
In practice, auditors also look for immutability signals such as system-generated timestamps, maker–checker logs on document updates, and consistency between trip, billing, and compliance data. Vendors who can generate this pack from a single command center or mobility platform, rather than manual collation, reduce audit friction and strengthen the compliance officer’s position.
operational resilience and incident reality checks
Translates proofs into action during peak shifts and off-hours, detailing 2 a.m. response, escalation, outages, and post-incident learnings.
From reference calls, what should we ask to confirm the vendor’s NOC really responds at 2 a.m. and closes incidents fast—so Ops isn’t firefighting nightly?
B0478 2 a.m. operational responsiveness proof — In India multi-vendor corporate ground transportation (EMS), how can an operations head validate “who answers at 2 a.m.” from references—what specific questions about NOC responsiveness, escalation adherence, and incident closure times actually predict real operational calm?
Operations heads can validate “who answers at 2 a.m.” by asking reference customers for very specific, time-bound evidence on NOC behavior, escalation discipline, and closure SLAs rather than generic satisfaction statements.
The most predictive questions focus on real night-shift breakdowns and how the centralized command center or Transport Command Centre actually responded. References should be asked for concrete examples of GPS failures, app downtime, cab shortages, or monsoon disruptions, and whether the vendor’s command center gave proactive alerts, arranged standby vehicles, and followed the documented escalation matrix without the client chasing them. Questions that demand numbers on on-time arrival percentages, exception-to-closure times, and night-shift incident logs help separate marketing claims from governed operations.
To forecast real operational calm, an operations head can ask references questions such as:
- “Describe the last serious night-shift disruption you had. Who contacted whom first, and in how many minutes did the command center acknowledge and assign an owner?”
- “Between midnight and 5 a.m., what percentage of critical calls to the NOC in the last quarter were picked up or called back within five minutes, and how do you know?”
- “Share one example where GPS or app failures occurred. Did the vendor’s team shift smoothly to manual SOPs and still meet your on-time performance expectations?”
- “Walk me through a recent women-safety or SOS alert. How quickly did the NOC escalate, which levels were involved, and how long did it take to close with documented proof?”
- “What is the typical time from a no-show or vehicle breakdown alert to a confirmed replacement vehicle during night shifts, and how consistently is that achieved?”
- “How often do you get consolidated deviation and service reports from their command center, and do those reports align with what you and your employees experienced on the ground?”
- “When escalation to senior ops or the key account manager is required at 2 a.m., do they actually respond within the agreed window, and how many times have they failed in the last six months?”
Answers that include specific incidents, timestamps, and reference to command center dashboards, alert supervision systems, or NOC-generated MIS are strong signals that the vendor’s night operations, safety controls, and business continuity playbooks deliver real-world calm rather than additional firefighting.
If an auditor shows up suddenly, what proof should we ask for that the vendor can generate the right compliance reports immediately, without Excel firefighting?
B0483 Panic-button compliance reporting proof — In India employee mobility services (EMS), what evidence should a buyer ask for to confirm the vendor can produce “panic button” compliance reporting on demand (auditor-in-the-lobby scenarios) without scrambling across vendors and spreadsheets?
In India EMS, buyers should demand hard evidence that panic/SOS events flow into a single, auditable trip ledger with timestamps, geo-tags, and closure details that can be produced in minutes from a command-center dashboard. Panic-button compliance is credible only when incident data is captured automatically from rider/driver apps, routed through a centralized command center, and exposed via ready-made reports rather than ad-hoc spreadsheet compilation.
Buyers should first ask to see the live or dummy view of a centralized command center or Transport Command Centre dashboard. The dashboard should display real-time alerts, including SOS incidents, with fields such as trip ID, employee ID, vehicle/driver details, geo-fence status, and escalation timestamps, matching the kind of 24/7 oversight described in the Transport Command Centre and Alert Supervision System collaterals. The vendor should show how incidents move through a defined escalation matrix, as outlined in incident and safety frameworks such as Safety & Security for Employees and SOS – Control Panel and Employee App.
A strong vendor will present indicative management or “single window” reports that already consolidate safety alerts, deviations, and closure SLAs in one place, similar to the Dashboard – Single Window System and Indicative Management Report assets. Buyers should verify that panic-button events appear as a distinct category with count, response time, and resolution status, and that these can be filtered by date range, site, shift window, and gender-sensitive routing rules referenced in women-centric safety protocols.
Evidence also needs to prove that panic-button controls are embedded into the driver and employee apps. Buyers should ask to see the SOS button and emergency workflow in the Employee/Driver App Features collateral and then trace a test SOS through to the command center and into a report. The vendor should demonstrate automatic ticket creation, time-stamped updates, and integration with safety frameworks such as Safety and Compliances and Women-Centric Safety Protocols. The buyer should then request a sample “auditor pack” for the past 3–6 months showing a list of all SOS events, raw log extracts, and how each incident was closed in line with an escalation mechanism and HSSE tools.
An additional proof point is the presence of data-driven insights dashboards that cover safety metrics and compliance, such as Data Driven Insights, where panic/SOS can be treated as a monitored KPI alongside route deviations, over-speeding, and geofence violations. Buyers should check that these safety KPIs align with command center roles, HSSE responsibilities, and centralized compliance management artefacts, ensuring that panic-button data is part of continuous assurance rather than a separate, manual workflow.
How can we verify the vendor really handles issues at 2 a.m.—can they show escalation logs, response times by shift, and real incident examples from similar customers?
B0504 2 a.m. incident response proof — In India corporate employee mobility services (EMS) with a 24x7 command center, what operational evidence should a Facilities/Transport Head ask for to verify “who answers at 2 a.m.”—including escalation logs, response-time distributions by timeband, and real incident timelines from reference customers?
A Facilities or Transport Head should ask for hard, timeband-specific operational evidence that proves the command center actually runs EMS reliably at night, not just during office hours. The most useful evidence makes 2 a.m. behaviour visible through real escalation records, response-time distributions, and fully reconstructed incident timelines from similar reference customers.
They should first request anonymized escalation logs filtered by night bands. The logs should show date and time of alert, source of alert, alert type, command-center owner, escalation path, and closure timestamp. Patterns in these logs reveal whether the 24x7 command center and Transport Command Centre are actively supervising or only reacting when someone calls. A consistent trail of geofence violation alerts, speeding alerts, SOS tickets, and BCP-related escalations during night shifts also validates that tools like the Alert Supervision System and SOS control panel are actually used.
They should then ask for response-time distributions by timeband. The provider should provide separate metrics for peak, off-peak, and late-night windows, with median and percentile response times for ticket acknowledgment and for issue closure. Evidence tied to on-time performance maintenance, dynamic route recalibration in events like Mumbai monsoon operations, and management of on-time service delivery near 98% OTP indicates reliable night control. Distributions that degrade sharply at night are a red flag.
Finally, they should demand at least two or three real incident timelines from similar reference customers. Each should reconstruct an adverse event from first alert through detection by the command center, escalation through the escalation matrix, actions taken (rerouting, replacement vehicle, driver change, or BCP invocation), and final closure with proof shared to HR or Security. Case studies that show live command-center intervention during weather disruptions, women-safety situations, or technology failures are especially valuable.
Useful artefacts include:
- Exported escalation and alert logs with timestamps and owners for night bands.
- Timeband-sliced response-time and OTP reports from the command center dashboards.
- Incident post-mortems or RCA documents with exact timelines and screenshots from the command center tools.
- BCP activation records showing how shortages, strikes, or tech failures were handled in real time.
- Reference letters or testimonials where clients explicitly mention night-shift responsiveness and command-center support.
For an upcoming event commute program, what proof should we ask for—runbooks, hourly SLA performance, escalation examples—to be sure they can manage peak loads?
B0509 Event peak-load proof and references — In India project/event commute services (ECS), what evidence should an event operations lead request to confirm the vendor can handle time-bound peak movement—such as prior event runbooks, SLA performance by hour, and escalation outcomes—and not just claim “we’ve done big events”?
An event operations lead should insist on granular, time‑stamped operational evidence for project/event commute services, not generic claims of “big event experience.” The most useful proof focuses on how the vendor has run high‑volume, time‑bound movements under control‑room governance, with clear SLAs, contingency playbooks, and post‑event reporting.
Vendors should share prior project or event runbooks that describe rapid fleet mobilization, temporary route design, and dedicated project control desks. The runbooks should specify shift windowing, peak‑load handling, and on‑ground supervision methods, aligned to an ETS/ECS operation cycle with steps from booking to MIS and billing. Strong evidence includes macro and micro transition or project planners showing week‑by‑week readiness for manpower deployment, technology implementation, and fleet deployment.
An operations lead should request SLA performance sliced by timeband, such as on‑time performance percentages and exception‑to‑closure times during peak entry and exit windows. Case studies that show measurable outcomes under stress conditions, such as maintaining a 98% on‑time arrival rate during Mumbai monsoon disruptions or delivering 98% on‑time performance and a 15% satisfaction uplift for late‑night female employee commutes, are particularly relevant. These should be backed by dashboards or single‑window systems that provide real‑time operational visibility, route adherence, and deviation reports.
It is also important to see escalation mechanisms and command‑center governance in action. The vendor should show an escalation matrix with named roles, 24x7 command or transport command centre screenshots, and micro‑functioning workflows describing alert supervision, risk mitigation, and SLA governance. Business continuity plans detailing responses to cab shortages, political strikes, technology failures, and natural disruptions demonstrate whether the vendor can protect time‑bound events from external shocks.
Evidence of driver and fleet readiness is another critical signal. The vendor should provide documented driver assessment and selection procedures, training calendars, and safety and compliance frameworks, including driver and fleet compliance checklists and safety inspection protocols. Where events involve women or night movements, women‑centric safety protocols, escort compliance frameworks, and SOS control‑panel evidence are essential for both operational and reputational risk control.
Finally, the operations lead should ask for post‑event or project MIS samples that correlate SLAs, exception logs, and billing. This confirms that time‑bound peak handling is not only planned but measured, auditable, and commercially aligned with outcome‑based expectations.
What should we ask reference customers about how the vendor performs during disruptions—monsoons, driver shortages, app outages—so we know their real resilience?
B0517 Disruption resilience questions for references — In India corporate employee mobility services (EMS), what reference-based questions should a Transport Head ask specifically about vendor behavior during disruptions—like monsoon flooding, driver shortages, app outages—so operations can predict real resilience rather than “best day” performance?
Transport Heads evaluating employee mobility vendors in India should ask disruption-focused, reference-based questions that expose how vendors behaved during real monsoon flooding, driver shortages, or tech outages. These questions should force concrete examples, numbers, and SOP evidence instead of “we handle it” claims.
Effective questions isolate vendor behavior in three zones. The first zone is on-ground continuity. Transport Heads should ask references how many standby vehicles and drivers were committed during monsoon peaks, and what the actual on-time performance was in bad weather versus normal days. They should ask who took final route and go/no-go decisions during waterlogging or protests, and whether location command centers and central command centers stayed staffed 24/7. They should probe whether business continuity plans with buffers, alternate vendors, and rapid fleet mobilization were actually used, not just documented.
The second zone is technology and command-center reliability. Transport Heads should ask references how long the mobility app, GPS, or routing engine was down during the last serious outage, and what manual fallback SOPs were activated. They should request examples of dynamic route recalibration used in floods or traffic collapses, and ask who answered the phone at 2 a.m. when apps or dashboards failed. Questions should cover whether the vendor’s Transport Command Centre or Alert Supervision System issued early alerts for geofence violations, over-speeding, and diversions, and how quickly incidents were acknowledged and closed.
The third zone is driver availability, safety, and fatigue control. Transport Heads should ask how vendors retained drivers during fuel price spikes or festival seasons, and what minimum notice they gave before cancelling vehicles. They should request details on driver buffers, fatigue limits, and replacement rules, and ask references if women-safety protocols, escorts, and SOS response times held up during night-shift disruptions. They should check if post-incident reviews led to changed SOPs and training, or if the same patterns kept repeating.
For a large event commute program, what proof should we ask for—past runbooks, on-ground staffing, delay metrics—so we don’t take the blame if transport fails on event day?
B0538 Event commute proof to reduce blame — In India corporate Project/Event Commute Services (ECS) for high-volume events, what evidence should an Events/Projects lead request—such as past event runbooks, on-ground supervision proof, and before/after delay metrics—to reduce personal career risk if the event transport fails publicly?
For large Project/Event Commute Services in India, an Events or Projects lead should insist on transport evidence that proves the vendor has executed similar high‑volume, time‑bound operations with documented SOPs, real runbooks, and auditable performance metrics. The priority is to obtain artefacts that can be shown to leadership or auditors later to demonstrate due diligence if anything goes wrong.
They should first request past event or project runbooks that cover full ETS/ECS operation cycles. These runbooks should include stepwise flows from booking, rostering, routing, vendor distribution, vehicle tracking, and shift report generation to billing and MIS closure, similar to the ETS Operation Cycle and Project Planner / Indicative Transition Plan materials. The runbooks should show how the vendor has handled temporary high-volume routing, peak-load movements, and on-ground control desks.
They should then ask for on-ground supervision proof. This includes evidence of dedicated command or transport control centers, documented roles and responsibilities (such as TCC – Roles & Responsibilities and Team Structure), daily shift briefing photos or logs, and the micro functioning of command centre diagrams. Evidence of a dual command model, with a centralized command centre plus location-specific desks, further reduces risk for multi-site events.
They should require quantitative before/after delay and reliability metrics from prior events. Useful artefacts include case studies that show on-time arrival improvements during adverse conditions, such as the Mumbai monsoon case with 98% on-time arrival and 10% uplift in customer satisfaction, as well as Management of on Time Service Delivery collateral that demonstrates achieving ≥98% OTP with traffic trend analysis and local authority coordination. For credibility, they should ask for raw OTP%, exception closure times, fleet uptime, and customer satisfaction scores tied to specific events or time-bound projects instead of generic KPIs.
They should also demand clearly written business continuity and contingency evidence. This includes Business Continuity Plan documents that cover cab shortages, political strikes, natural disasters, and technology failures, plus Guarantee for Uninterrupted Services by Management of COB collateral that shows redundancy, monitoring, and data recovery measures. The focus should be on specific ECS scenarios like high‑volume arrivals, late‑night dispersals, and VIP movement windows.
Key proof items to request include:
- End-to-end event runbooks and ETS/ECS operation-cycle diagrams for comparable scale and city profiles.
- Evidence of dedicated command-center operations, TCC roles, escalation matrices, and daily briefing routines.
- Hard performance numbers from similar events: OTP%, delay distributions, exception resolution times, and satisfaction scores before and after vendor engagement.
- BCP and COB documentation specific to events, showing fallback fleets, alternate routing, and tech failure playbooks.
- Data-driven insights dashboards and indicative management reports that show how real-time analytics and route optimization were used for peak management.
This mix of documented process, real on-ground governance, and event-specific performance metrics gives an Events/Projects lead defensible proof that they selected a transport partner based on prior operational evidence, not marketing claims.
What proof can IT ask for to confirm resilience—NOC staffing, postmortems, uptime history—so we aren’t blamed if the app goes down and pickups are missed?
B0540 Resilience proof for app outages — In India corporate employee transport (EMS), what evidence should a skeptical CIO ask for to confirm operational resilience—like NOC staffing proof, incident postmortems, and uptime/latency history—so IT isn’t blamed when an app outage causes missed pickups across sites?
In India EMS, a skeptical CIO should insist on hard evidence of operational resilience before endorsing any transport platform. The CIO’s objective is to prove that uptime, failover, and incident handling are engineered and governed, not assumed, so IT is not blamed when missed pickups follow an app or backend issue.
The CIO should ask for documented NOC and command-center operations. This includes 24x7 or shift-wise staffing rosters, escalation matrices, and samples of real alert supervision dashboards used for EMS, CRD, and EV fleets. Evidence of a centralized command centre plus location-specific command centres, with defined roles and SLAs for exception handling, directly strengthens the case for resilience.
The CIO should also demand historical uptime and latency data for the EMS stack. This includes committed SLOs, monthly uptime histories, and proof of observability across routing engines, driver/employee apps, and telematics dashboards. Prior incident postmortems for app downtime, GPS failures, and integration breaks are crucial, including root-cause analysis and the preventive changes implemented in routing, APIs, or command-center SOPs.
Resilient vendors can show business continuity and contingency plans for technology failures. This includes written BCP playbooks covering app/backend outages, telecom disruptions, and HRMS or ERP integration failures. The CIO should see how routing, trip closure, and SOS processes fall back to manual or semi-manual modes, how employee and driver communications are handled, and what evidence is retained for audits.
Additional signals include data and integration readiness. The CIO should ask for architecture diagrams, API documentation for HRMS and ERP integration, and examples of real-time dashboards for CO₂ reductions, EV telemetry, and compliance reporting. These artifacts indicate whether the platform is built as an observable, integrated system instead of a black box that fails silently under load.
If there’s a major night-shift incident, what proof shows the vendor’s incident response is real—escalation matrix, response-time logs, and past RCAs—so we don’t get vague answers?
B0551 Incident response proof under pressure — In India corporate Employee Mobility Services (EMS), if a serious night-shift safety incident occurs, what reference-backed evidence should a CHRO and EHS Lead demand to confirm the vendor’s incident response is real—like documented escalation matrices, response-time logs, and prior incident RCAs—so leadership isn’t left with vague assurances?
In India corporate Employee Mobility Services, a CHRO and EHS Lead should insist on hard, reconstructable evidence across governance, real-time response, and post-incident learning. Vague “handled as per SOP” narratives should never be accepted without matching logs and documents.
They should demand the following categories of proof from the EMS vendor and internal transport team.
- Governance & Escalation Design (pre-incident proof)
CHRO and EHS should see signed, version-controlled artefacts that existed before the incident. Each document must clearly show ownership and dates.
- Approved escalation matrix for safety incidents. This must name roles, levels, time-bands (day / night), and response SLAs for each step.
- Documented Target Operating Model or command-center design. This should describe 24x7 NOC coverage, shift handovers, and integration with security and HR.
- Written Incident Response SOPs covering women’s night-shift transport, SOS handling, escort rules, and interaction with local authorities.
- Vendor Governance Framework with safety SLAs and penalties. This must show how SLA breaches on response time and incident closure are contractually enforced.
- Training and communication records. Attendance logs, content decks, and acknowledgement records for drivers, operators, and internal teams on safety and incident SOPs.
- Real-Time Incident Handling Evidence (during-incident proof)
For a serious night-shift event, leadership must be able to replay “who knew what, when, and what they did.”
- Command center alert logs. Time-stamped records from the Transport Command Centre or equivalent NOC showing when the first alert was raised (SOS, geo-fence breach, route deviation, panic button, or phone escalation).
- Escalation trail. Tickets or communication logs that show how the incident moved through the escalation matrix: which person was notified at each level, at what exact time, and via which channel.
- Response-time metrics. Extracts from the alert supervision or ticketing system proving detection-to-acknowledgement time, acknowledgement-to-action time, and time to incident stabilization.
- Trip and telematics evidence. GPS route history, speed, stops, geo-fence events, duty slip data, and SOS activation history for the vehicle and shift in question.
- Call/SOS handling records. IVR or helpdesk logs showing call durations, agent notes, and disposition codes relevant to the incident.
- Post‑Incident RCA, Corrective Actions, and Assurance (after-incident proof)
After immediate safety is restored, the CHRO and EHS Lead should require a structured, auditable closure trail.
- Formal Root Cause Analysis (RCA). A written RCA that is consistent with trip data, escalation logs, and telematics. It should separate root causes (systemic or process gaps) from contributing factors and one-off anomalies.
- Action plan with owners and timelines. A documented corrective and preventive action (CAPA) plan assigning specific owners in vendor operations, internal transport, EHS, and HR, with deadlines and measurable outcomes.
- Policy or SOP changes. Updated SOPs, routing rules, escort policies, or women-centric safety protocols, with version history and distribution logs to prove they were rolled out.
- Follow-up training and coaching records. Evidence of driver retraining, command-center refresher sessions, or new safety drills linked specifically to the incident learning.
- Audit trail and governance review. Minutes from governance or safety review forums where the incident, RCA, and CAPA were tabled, challenged, and formally closed.
- Continuous Assurance & Prior Track Record
To avoid “one clean story in isolation,” CHRO and EHS Leads should also request pattern-level evidence.
- Historical incident register. Anonymized log of prior safety events with severity, response times, RCA summaries, and closure status.
- SLA compliance reporting. Periodic reports on safety-related SLAs such as incident-rate trends, SOS closure SLAs, escort-compliance checks, and random route audits.
- Route adherence and audit outcomes. Results from route adherence audits, women-safety compliance checks, and any external EHS or safety audits.
- Business continuity and emergency drills. Records from mock drills or business continuity exercises relevant to night-shift transport and women’s safety.
A common failure mode is accepting narrative explanations without cross-checking against command-center logs, telematics, and ticketing data. Robust EMS governance links every serious night-shift incident back to a traceable digital and documentary footprint that an auditor, board member, or regulator can independently follow.
global standardization and multi-site governance
Assesses cross-site SLAs, consistent KPI definitions, and local operational realities to avoid metro-only success stories while maintaining reliability.
How can a vendor prove they can deliver reliably in Tier-2/3 cities (not just metros)—by city and shift/timeband—so Ops feels safe rolling out?
B0472 Tier-2/3 reliability proof — In India multi-site employee mobility services (EMS), what’s the most credible way to demonstrate Tier-2/3 city reliability—separate OTP distributions by city and timeband, variance bands, exception latency, and escalation adherence—so an operations head doesn’t feel they’re betting their career on metro-only performance?
In India multi-site EMS, the most credible way to prove Tier‑2/3 reliability is to show city-wise, timeband-wise OTP and exception data on the same governance rail as metros, backed by a command-center led escalation SOP and live evidence from existing Tier‑2/3 deployments. This reduces perceived “metro bias” and lets an operations head see that smaller cities run on the same playbook, with the same early-warning and backup controls.
The strongest proof point is a real command-center view that already tracks city-level OTP, exception latency, and escalation closure across locations. WTi’s Transport Command Centre and EV fleet command dashboards are examples of this model, with 24/7 monitoring, alert supervision, and a single-window system for deviations and service reports. When Tier‑2/3 routes are visible in the same dashboard as metros, reliability looks governed, not improvised.
For Tier‑2/3 credibility, operations teams respond best to:
- Separate OTP distributions for each city and timeband, with clear bands for peaks, night shifts, and monsoon/holiday periods.
- Variance bands and RCA tags on outliers, linked to route optimization changes or Business Continuity Plan triggers.
- Exception latency tracking, showing how quickly no-shows, GPS loss, or vehicle failures were detected and contained by the command center.
- Escalation adherence evidence from an actual escalation matrix, including when N1/N2/N3 were invoked and how issues were closed.
- Case studies where Tier‑2/3 operations sustained 98%+ OTP during adverse conditions, using dynamic routing and local control desks.
A macro “Current EV Operation” or “Our Presence” style map that highlights existing Tier‑2/3 city operations, combined with city-specific OTP and incident dashboards, is far more reassuring than a single blended national figure. It shows the operations head that the vendor already runs structured EMS in comparable markets, with on-ground teams, fleet buffers, and BCP playbooks instead of metro-only heroics.
images:
images: 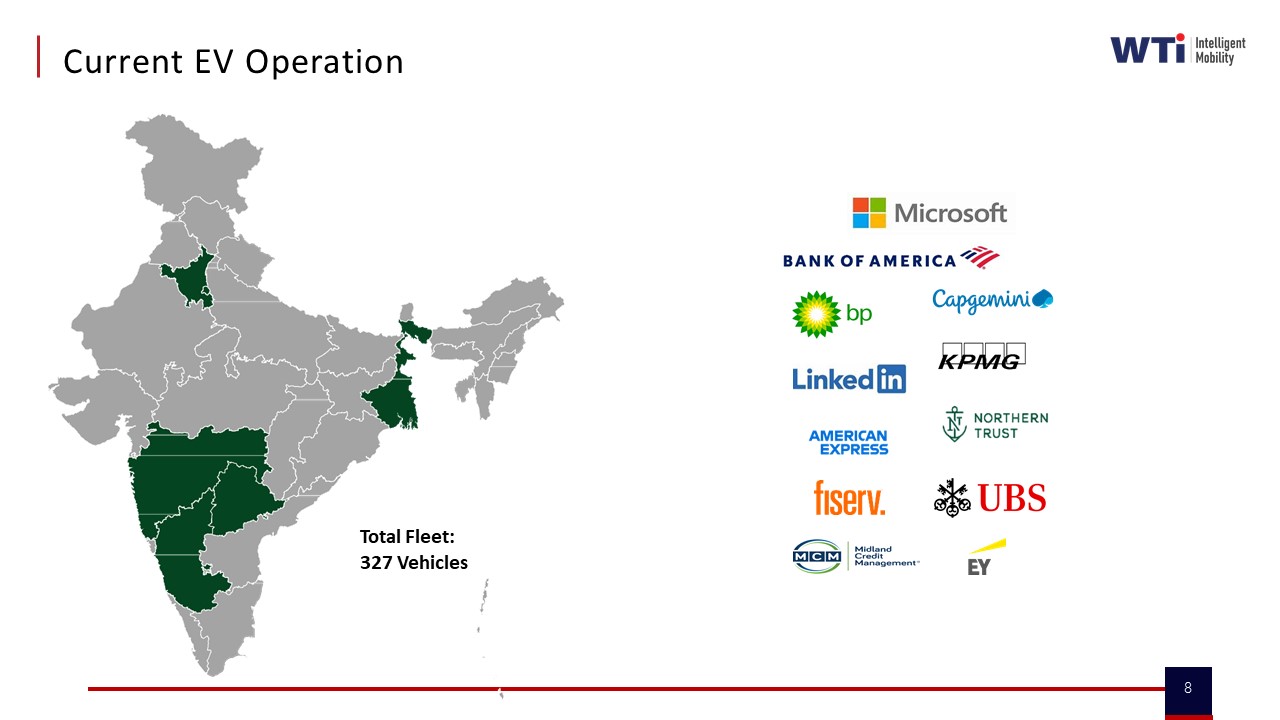
images: 
If we want one standard SLA across all our sites, how do we judge whether a vendor can keep it consistent across cities while still handling local issues without endless exceptions?
B0482 Global SLA standardization reality-check — In India corporate ground transportation (EMS/CRD), how should a Strategy or COO-level stakeholder evaluate a vendor’s ability to standardize SLAs across multiple sites while still handling local realities (permits, supply fragmentation, Tier-2/3 variability) without constant exceptions?
In corporate ground transportation in India, a Strategy or COO-level stakeholder should evaluate a vendor’s SLA standardization capability by testing whether a single, governed model can run across sites while the “local adjustments” are absorbed inside the vendor’s operating model rather than as constant client-side exceptions. The most reliable vendors standardize governance, command-center operations, compliance, and data while localizing fleet, routing, and permits behind the scenes.
A strong vendor operates a central 24x7 command centre with location-specific control rooms. This structure allows standardized OTP, safety, and escalation SLAs, while local teams deal with regional traffic patterns, monsoon disruptions, political events, or permit nuances. Evidence includes documented MSP governance structures, daily shift-wise briefings, and micro-functioning SOPs for the command centre.
Standardization is credible only if compliance and safety are centrally managed and auditable. Vendors should show a centralized compliance management system covering driver KYC, vehicle induction, women-safety protocols, and HSSE tooling, along with business continuity plans for strikes, tech failures, and natural disasters. This reduces the need for site-wise SLA exceptions because risk is managed through pre-defined playbooks.
Data-driven visibility is essential to avoid “local excuses.” A vendor should provide a single-window dashboard for OTP, route adherence, safety alerts, CO₂ metrics, and exception closure, with clear linkages to billing and MIS. When every site is measured on the same KPI set, local realities are handled operationally through routing adjustments, buffer fleets, or EV/ICE mix changes, not by diluting SLAs.
The most practical evaluation checks for four things:
- One SLA framework mapped to clear, measurable KPIs applied uniformly across sites.
- Dual command model: central governance plus local control rooms with defined roles and escalation matrices.
- Documented continuity and contingency plans that anticipate region-specific disruptions and supply gaps.
- Technology that unifies rosters, routing, compliance, safety alerts, and billing across Tier-1 and Tier-2/3 cities.
When these elements exist and are backed by live case studies and auditable reports, a COO can hold one set of SLAs across locations while the vendor quietly absorbs local complexity without pushing constant exceptions back to the enterprise.
What proof shows the vendor measures SLAs the same way across all cities—same OTP rules, exception types, and shift/timeband cutoffs—so leadership can compare sites fairly?
B0490 Standardized SLA definitions proof — In India multi-site employee mobility services (EMS), what evidence should a buyer ask for that SLA measurement is standardized across locations (same OTP definition, same exception taxonomy, same timeband cutoffs) so a COO can compare apples-to-apples across sites?
In Indian multi-site employee mobility services, a buyer should insist on hard, system-generated evidence that every site is using the same definitions and clocks for SLAs. Without this, OTP and exceptions from different cities cannot be compared reliably and the COO loses true control.
The most useful evidence sets usually fall into four buckets:
- Documented SLA & Taxonomy Standards
- A signed SLA definition document that lists:
- The exact OTP formula (e.g., pick-up considered on-time if within X minutes of scheduled time as per system time).
- The timeband grid for shifts and service windows (e.g., 18:00–22:00 = evening, 22:00–06:00 = night) and how “night shift” is defined.
- A standard exception taxonomy with codes and descriptions (no-show, vehicle breakdown, employee delay, security hold, weather, etc.).
- A governance note that confirms these are enterprise-wide standards, not city-specific variations.
-
Evidence that these standards are part of the ETS Operation Cycle or equivalent documented operation cycle, not just a presentation promise.
-
Platform Configuration & Central Dashboard Proof
- Screenshots or a live demo of a centralized command center / dashboard where:
- OTP% is shown per site, but calculated from a single global rule set.
- Exception categories are selectable from the same drop-down list across locations.
- Timebands are configured in one master table and applied to all cities.
- Evidence from tools like:
- A single window system dashboard that shows compliance, operational analysis, and deviation reports across branches using common fields.
- A transport command centre or command centre micro-functioning diagram that shows central SLA monitoring, not city-by-city spreadsheets.
-
Proof that trip timestamps and status changes come from an integrated system (driver and employee apps + NOC tools), not manual edits.
-
Sample Reports Showing Cross-Site Consistency Ask for real, anonymized artefacts where multiple sites appear on the same report:
-
A monthly or quarterly SLA pack where:
- OTP, Trip Adherence Rate, exception counts, and complaint closure SLAs are laid out per site, on one template.
- Footnotes show the same OTP definition and timebands for all sites.
- An Indicative Management Report or equivalent that:
- Pulls safety, operations, technical issues, billing, and feedback into a unified format for all locations.
- A centralized billing report where:
- Trip-level data, exceptions, and penalties share the same codes across branches.
- SLA breaches and credits are calculated by system logic, not locally defined rules.
-
Any data-driven insights or “Single Window” dashboards that show:
- One KPI library (OTP, TFR, NSR, incident rate) applied identically across sites.
-
Audit Trails, SOPs, and Governance Evidence To ensure it is not just configured but enforced:
-
SOPs for command center operations that state:
- How OTP is measured.
- Who can change SLA parameters or timebands.
- How exceptions are classified and approved.
- Evidence of centralized compliance management where:
- Fleet and driver compliance dashboards use the same checklists and expiry logic across all locations.
- Sample Route Adherence / OTP audit reports for two or more cities showing:
- The same sample methodology.
- The same “pass/fail” thresholds for OTP and route adherence.
- Minutes or decks from governance reviews / QBRs where:
- Different sites are compared on a single scoreboard using shared definitions.
- Business continuity and on-time delivery management documents showing:
- OTP targets (for example, 98% on-time) that are set at a central level and applied to all cities with one measurement method.
When validating a vendor, a COO or Transport Head can use a simple test set:
- Ask the vendor to show OTP and exception performance for three different cities on a single screen or report.
- Ask them to open the underlying definitions: what exactly counts as “on-time,” and what the exception codes mean.
- Ask who can change these definitions and how those changes are logged and approved.
If the vendor needs different spreadsheets, different formulas, or different exception codes per city to answer these questions, then SLA measurement is not standardized and “all-India” comparisons will not be apples-to-apples.
If a vendor says they deliver ‘global standards’ everywhere, what proof should we ask for that SOPs, escalations, and NOC monitoring are actually consistent across our regions?
B0495 Validate global standards locally — In India multi-site corporate ground transportation (EMS/CRD), how should a buyer validate that a vendor’s ‘global standard’ claims hold in local execution—what proof should exist for site-level SOP adherence, escalation matrices, and uniform NOC monitoring across regions?
In multi-site corporate transport in India, buyers should treat “global standard” claims as unproven until there is hard, site-level evidence of SOP adherence, escalation readiness, and uniform NOC monitoring across regions. Validation depends on documented SOPs mapped to India-specific risks, live or recorded proof of command-center operations, and audit-ready artefacts from actual locations, not just central templates.
Most organizations first insist on written SOPs that show shift-wise playbooks for EMS and CRD, India-relevant safety and women’s-night-shift controls, and city-specific Business Continuity Plans for cab shortages, political strikes, natural disasters, and technology failures. Buyers then ask vendors to prove that these documents are operationalized through daily shift briefings, driver induction and training records, and compliance logs for fleets and chauffeurs that reference real registration numbers and driver IDs per site.
A common failure mode is glossy “command center” decks without a clear escalation matrix and micro functioning steps that link alerts to named roles and time-bound response SLAs. Robust vendors provide a transport command centre model showing a central NOC plus location-specific control rooms, supported by screenshots or demos of live dashboards that monitor OTP, geo-fence violations, SOS triggers, and CO₂ or EV telemetry in real time across cities.
Uniform NOC monitoring is best validated through sample incident trails from different regions that include timestamps, alert classification, escalation to the right level, and closure notes aligned to a documented escalation mechanism and matrix. Buyers should request periodic management reports and single-window dashboards that consolidate compliance, deviation, service, and financial KPIs by location, since fragmented or inconsistent reporting is a strong signal that “global standard” processes are not truly harmonized on the ground.
Across our locations, what evidence should we ask for to prove the vendor can deliver the same SLA standards—even in Tier-2/3 cities where supply is harder?
B0499 Proof of multi-site SLA consistency — In India multi-site corporate employee mobility services (EMS), what does “global SLA standardization” proof look like across locations—especially when Tier-2/3 cities have different fleet availability—and what evidence should an operations head demand to confirm the vendor can actually deliver consistent on-time pickup and escalation handling?
In India multi-site employee mobility, credible “global SLA standardization” means the vendor runs one common SLA framework and evidence model across all locations, while allowing for local fleet and route realities to be encoded in that framework. Proof is visible as a single, governed operations model with command-centre oversight, standard KPIs like OTP and incident closure SLAs, and city-wise performance reports that use the same definitions and thresholds, including Tier‑2/3 cities with thinner supply.
A strong vendor shows a Target Operating Model with a central 24x7 command centre plus location-specific control rooms. The command centre collates live GPS data, alerts, and exception tickets into one dashboard, as shown for EV and ETS operations where centralized command and transport command centres supervise compliance, safety, and OTP across regions. This model is backed by documented escalation matrices, business continuity plans for cab shortages and disruptions, and standardized engagement and governance structures.
To confirm that consistent on-time pickup and escalation handling are real, not promised, an operations head should demand concrete artefacts and data, not just PPTs.
Key things to insist on include:
- Command-centre artefacts. Ask for screenshots or live demo of their single-window command dashboards that show trips, delays, alerts, and escalations across cities, like the Transport Command Centre and EV Command Centre views, plus micro-functioning SOPs for alert handling and exception triage.
- Standardized SLA definitions. Request written SLA documents showing uniform OTP%, maximum exception closure time, and safety escalation timelines applied to every city, with clear deviation reasons where Tier‑2/3 constraints exist.
- City-wise performance history. Demand anonymized OTP, fleet uptime, and incident-closure reports split by metro vs Tier‑2/3 for at least 6–12 months, similar to their measurable outcome dashboards and management report packs.
- Business continuity and COB plans. Ask for BCP decks that explicitly cover cab shortages, tech failures, strikes, monsoon or disaster scenarios, plus proof they maintained operations under such conditions (e.g., the Mumbai monsoon case with 98% on-time arrival).
- Escalation matrix and governance cadence. Request the formal escalation matrix for operations, safety, and technology issues, and the engagement model that defines leadership, senior management, and service delivery review meetings.
- Alert supervision and safety systems. Verify existence of an Alert Supervision System with geofence, device tampering, overspeeding alerts, and SOS panels, and ask to see how alerts from Tier‑2/3 fleets appear and are closed.
- Data-driven insight reports. Ask for samples of their indicative management reports and single-window dashboards that combine compliance, operational analysis, deviations, and financials by site.
- Driver and fleet induction SOPs. Inquire about Driver Assessment & Selection, Driver Compliance & Induction, Fleet Compliance & Induction, and safety checklists to ensure driver and vehicle standards are consistent in smaller cities.
- Business continuity execution examples. Request concrete examples where they used their Business Continuity Plans and COB management to keep EMS stable during disruptions in non-metro locations.
- Real client references and contracts. Ask for references from enterprises using them across multiple Indian locations, including Tier‑2/3, plus evidence of long-tenure contracts and testimonials mentioning reliability and incident handling.
If the vendor cannot show live or recent dashboards, city-wise SLA reports, BCP playbooks, and a functioning escalation matrix that includes Tier‑2/3 sites, then “global SLA standardization” is likely a claim, not an operational reality.
Before we expand to Tier-2/3 cities, what proof should we ask for on reliability by shift—acceptance, cancellations, and escalation closure performance?
B0515 Tier-2/3 reliability evidence — In India corporate employee mobility services (EMS), what evidence should a buyer require to confirm Tier-2/3 reliability—such as timeband-wise driver acceptance, cancellation rates, and escalation closure SLAs—before expanding beyond metro pilots?
In India EMS, buyers should insist on hard, timeband-wise operational evidence from Tier-2/3 cities before scaling beyond metro pilots. The minimum proof should cover driver supply stability, trip acceptance vs cancellation, on-time performance, and how fast escalations are detected and closed in each non-metro location.
Buyers should require location- and timeband-wise data for at least one full quarter from Tier-2/3 operations. Evidence should include driver acceptance and cancellation rates by shift window, OTP% and exception latency during night and peak bands, and NOC or command-center logs showing alert handling, including geofence violations, over-speeding, device tampering, and SOS actions. This evidence becomes more credible when supported by a live command-center view, such as the centralized dashboard in the Transport Command Centre and Command Centre collaterals, and by case studies demonstrating 98% on-time arrivals under stress conditions, as in the Mumbai monsoon routing example.
A robust Tier-2/3 reliability pack also links performance to governance and continuity. Buyers should see a documented escalation matrix with roles and response SLAs, backed by closure timestamps from tools like the Alert Supervision System and SOS control panel. They should ask for Business Continuity Plans that explicitly address political strikes, tech failures, and cab shortages in non-metros, plus actual incident logs that show how those plans worked in practice. Evidence of driver and fleet compliance processes, including DASP, driver compliance verification, and fleet pre-induction checks, further de-risks Tier-2/3 expansion because it stabilizes supply quality and reduces mid-shift failures.
Useful buyer checks include: - Timeband-split KPIs for at least 3–6 months in comparable Tier-2/3 cities. - Command-center screenshots or demos showing live alerts, deviations, and closure workflows. - Real incident and escalation samples with measured closure SLAs. - Proof of BCP execution and continuity during recent disruptions. - Driver and vehicle compliance dashboards tied to each Tier-2/3 location.
This level of evidence reduces the risk of hidden fragility that only appears after scale-up and helps ensure metro-like reliability before committing to wide EMS rollout.
images:

What proof shows the vendor can standardize SLAs across our sites without imposing a rigid model that won’t work in smaller cities?
B0522 Evidence for scalable SLA standardization — In India multi-site corporate employee mobility services (EMS), what proof should a strategy leader ask for to validate that a vendor can standardize SLAs across regions without forcing a one-size-fits-all model that breaks local operations in smaller cities?
In India multi-site employee mobility services, a strategy leader should ask for proof that the vendor runs on one governance spine with region-tuned execution. The vendor must show that SLAs, data, and controls are standardized, while routing, fleet mix, commercials, and SOPs flex by city, shift pattern, and demand profile.
The most useful validation is an explicit target operating model that combines a central 24x7 command center with regional hubs. The central node should own a single SLA framework, common KPIs like OTP%, Trip Adherence Rate, and Incident Response SLAs, and a unified escalation matrix. The regional hubs should own local routing, driver deployment, and on-ground supervision for smaller cities and tier 2/3 locations.
A strategy leader should ask for three categories of evidence: - Operating model proof: documented command-center operations with integrated mobility command frameworks, micro functioning workflows, and MSP governance structures that show how exceptions are handled differently by region while still being measured uniformly. - Technology and data proof: presence of a single routing and dispatch engine, common driver and rider apps, and a unified data layer with standardized KPIs for reliability, safety, and utilization across all cities, including satellite locations. - Governance and commercial proof: vendor governance frameworks and outcome-based contracts that define city-agnostic KPIs but allow city-specific fleet policies, EV penetration levels, and cost baselines.
The leader should also request sample dashboards and management reports that display performance side-by-side for metro and smaller-city sites. Any vendor that cannot produce comparable OTP, safety, and cost metrics across diverse regions usually lacks real standardization. Any vendor that can show only city-specific, non-harmonized reporting usually cannot support multi-site SLA governance.
images:
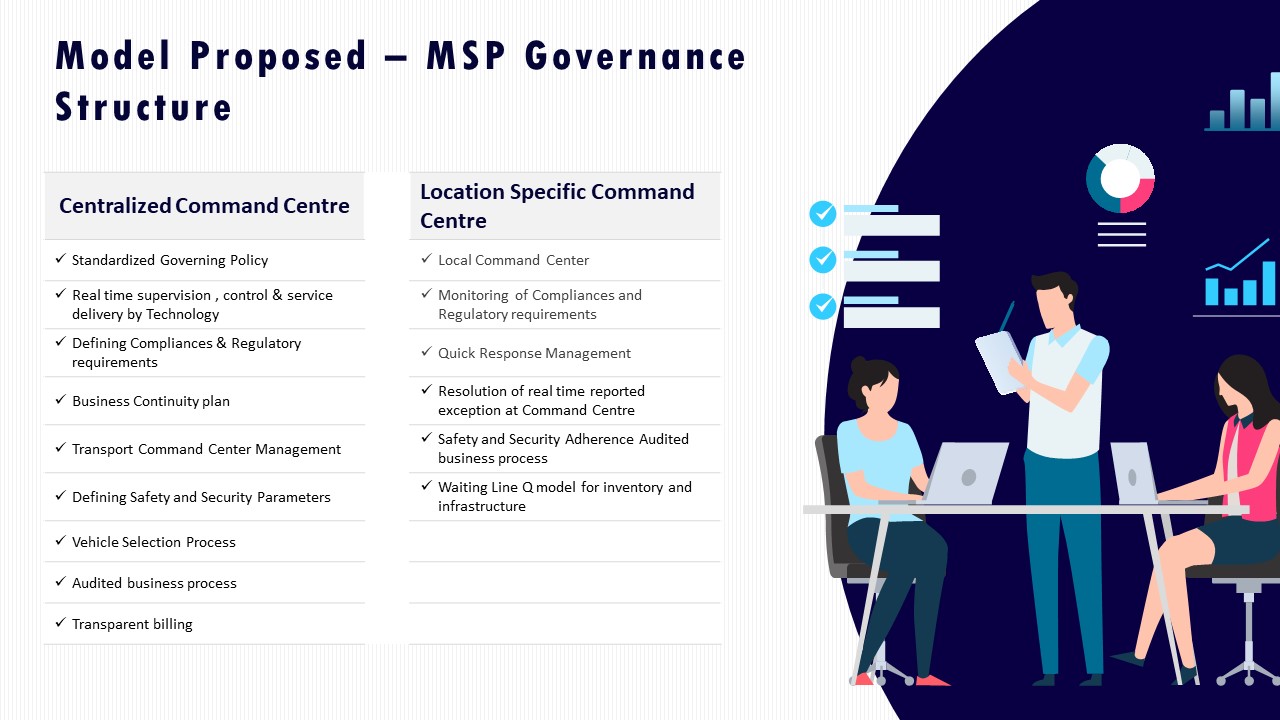
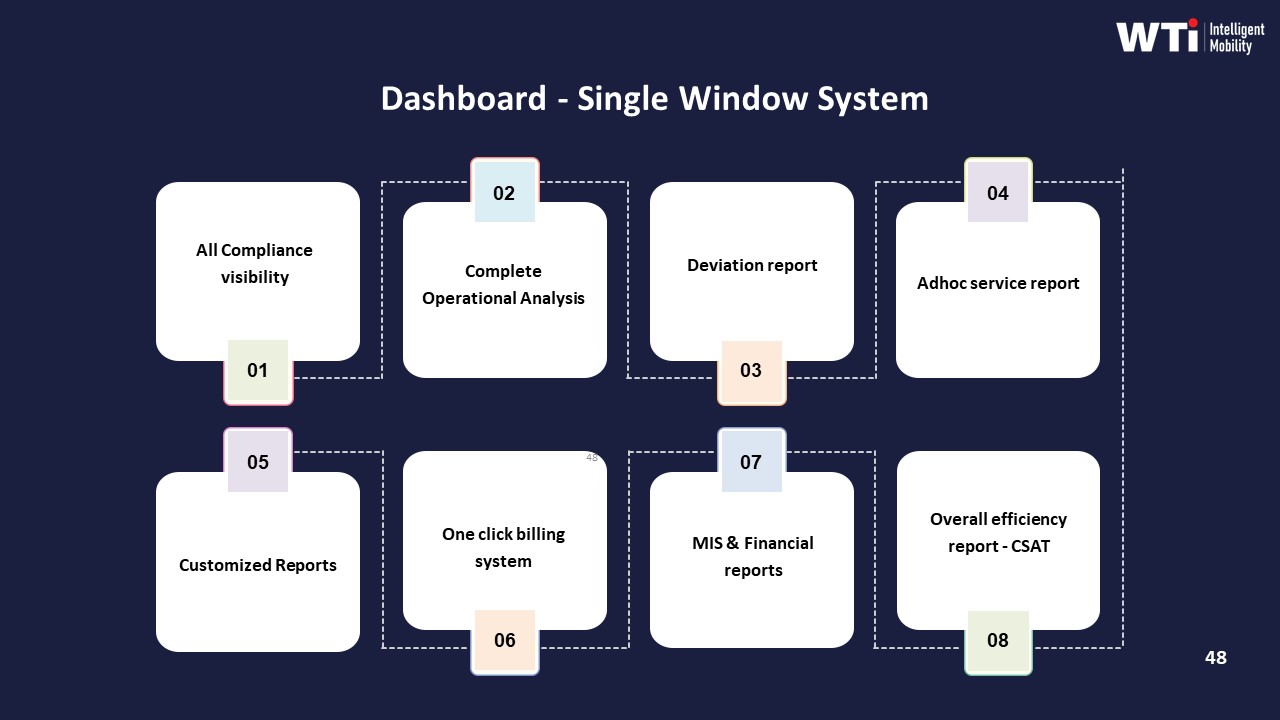
How can we check that a vendor can actually deliver in Tier-2/3 cities and night shifts, not just in metros—what references and data should we ask for?
B0528 Tier-2/3 reliability verification — In India corporate ground transportation (Employee Mobility Services) across multiple cities, how should a Facilities/Transport Head verify that a vendor’s claimed service reliability in Tier-2/3 cities is real—using city/timeband references, sample SLAs, and exception heatmaps—rather than a metro-only success story?
In multi-city Employee Mobility Services, a Facility / Transport Head should verify a vendor’s Tier-2/3 reliability by demanding city-wise, timeband-wise evidence, not just generic “pan-India” claims or metro case studies. A practical check is to insist on sample SLAs, exception heatmaps, and references that explicitly cover the Tier-2/3 locations and night-shift bands that matter to the operation.
A strong starting point is to ask for a list of current EV and ICE operations with city names and fleet counts that include Tier-2/3 locations, not just metros. Vendors who show active deployments in multiple non-metro cities, supported by a central command centre and location-specific control centres, usually have the ground network and governance needed for reliable service beyond Tier‑1. A Facility Head should then map that declared footprint against internal demand clusters and peak shift windows.
The next step is to obtain SLAs that are segmented by city and timeband. For example, the vendor should be willing to commit to defined on-time performance in smaller cities, backed by buffers, standby vehicles, and a documented business continuity plan for cab shortages, political strikes, or technology failures. A sample SLA that looks identical for Mumbai and a Tier‑3 city is a red flag, because it suggests the vendor has not modelled local constraints like limited fleet depth or weaker backup options.
Exception heatmaps and management reports are the most concrete way to see whether “reliability” is metro-limited. The Facility / Transport Head should ask for anonymized heatmaps that show, by city and by timeband, where geofence violations, GPS dropouts, no-shows, and late pickups occur, and how quickly they are closed. A mature vendor will have alert supervision systems, central dashboards, and route-deviation reports that expose these patterns, along with an escalation matrix that shows who responds at night in smaller cities.
Before awarding volume across multiple cities, the Facility Head can run a controlled pilot in 1–2 Tier-2/3 locations that mirror the hardest conditions, such as monsoon-affected or remote industrial clusters. During this pilot, the Facility Head should track OTP, exception closure times, and driver availability by shift, using the vendor’s dashboards and their own spot audits. Vendors who have already handled severe-weather routing or high-volume project commute in challenging geographies usually have ready SOPs and BCP artefacts for those scenarios.
Key verification checks a Facility / Transport Head can use include: • City/timeband references from existing clients in similar Tier‑2/3 locations with contract duration and SLA metrics. • Sample SLAs showing differentiated commitments, standby logic, and penalties for each city category. • Exception heatmaps and management reports with city-level, timeband-level breakdowns of incidents and resolutions.
This structured evidence approach helps a Facility / Transport Head filter out metro-only success stories and select vendors whose reliability is proven where it is hardest to deliver, reducing night-shift firefighting and unplanned escalations.
If we want consistent SLAs across all our sites, what should we ask references to confirm the vendor can standardize delivery across cities and business units?
B0534 Proving global SLA standardization — In India multi-site corporate mobility (EMS + CRD) with global SLA standardization goals, what questions should a Strategy or PMO leader ask customer references to confirm the vendor can deliver consistent SLA governance across cities and business units, not just one flagship site?
In India multi-site corporate mobility, a Strategy or PMO leader should use customer reference calls to stress‑test whether a vendor can run EMS + CRD as a governed program across cities, not just as a “hero site” story. The questions need to probe command‑center operations, multi‑city vendor governance, technology consistency, and how SLAs are enforced when things go wrong.
1. Multi-site rollout, stability and replication
How many locations does the vendor manage for your organization today for employee mobility services and corporate car rental services.
Did the vendor start with one flagship site and then scale to other cities, or were multiple locations transitioned in parallel.
What was the actual transition timeline per site versus what was committed in their transition plan or project planner.
Were there cities or business units where the model that worked at HQ did not work as‑is.
How did they adapt their operating model, such as routing, fleet mix, or on‑ground supervision, without breaking global SLAs.
How frequently do you see instability during expansion phases, such as cab shortages, driver churn, or missed shift go‑lives.
2. Central command center and local control
Is there a single 24x7 transport command centre or MSP governance structure overseeing all your sites.
What exactly is monitored centrally, such as OTP, route adherence, SOS, and what is left to local teams.
When there is a disruption, like monsoon, strike, or tech outage, who actually takes charge, the centralized command centre or the local command centre.
Can you recall a multi‑city disruption and explain how quickly the command center surfaced early alerts and drove corrective action.
Do escalation matrices work consistently at night and on weekends across all locations, or only at your primary campus.
3. SLA design, enforcement and evidence across cities
Are SLAs and KPIs such as OTP percent, incident closure SLA, seat‑fill, and cost per trip defined uniformly across your business units or customized city by city.
Does the vendor provide a single SLA dashboard or “single window” view of operations that lets you compare performance across cities.
How often are SLA breaches formally recorded, and are penalties or earnbacks actually applied in invoices, or do issues get handled informally.
Have you ever challenged their numbers on OTP or incident rates, and how robust were the audit trails, trip logs, and GPS evidence they provided.
Can local managers see the same SLA and compliance data that the central stakeholder sees, or do they work off manual reports.
4. Technology consistency, uptime and integration
Are the same apps and dashboards, like employee, driver, and admin apps, used across all cities, or do some sites still run on manual or semi‑manual processes.
How reliable is the platform in your toughest conditions, such as night shifts, Tier‑2 or Tier‑3 cities, and heavy rain or network congestion.
Have you experienced GPS failures, app downtime, or routing glitches that affected multiple locations at once.
How did the vendor handle failover, manual backups, or offline workflows to keep vehicles moving.
Is the transport system cleanly integrated with your HRMS, approvals, and billing systems across regions, or only at headquarters.
When you add a new site, how long does it take to onboard it onto the same tech stack with rosters, route optimization, compliance, and CO2 dashboards.
5. Vendor, fleet and driver governance at scale
Does the vendor run with a single fleet ecosystem nationwide or a multi‑vendor aggregator model under centralized governance.
Have you seen quality or compliance variance where smaller cities get weaker vehicles or less trained drivers than metros.
How rigorously are driver compliance, background verification, and training standards enforced outside flagship locations.
Are fleet and driver compliance dashboards available per city, and does the central team actually act on non‑compliance alerts.
What does driver retention and fatigue management look like on high‑stress routes or plants outside main hubs.
Have you had any safety incidents or near misses in smaller locations, and how did the vendor manage investigation, RCA, and preventive actions.
6. Business continuity, risk and exception handling
Have you seen the vendor’s business continuity plan play out in real events such as natural disasters, political strikes, or sudden cab shortages in more than one city.
Did the contingency playbooks, such as standby fleet, alternative routing, or shift rescheduling, get applied consistently across sites.
When technology failed, like server downtime or telecom outage, did they execute a documented COB plan, and did all cities move to the same fallback mode.
Are emergency protocols for women’s safety, SOS, and incident management run uniformly, or do they depend heavily on individual local managers.
7. Cost governance, billing and commercial discipline
Do you receive centralized billing with site‑wise breakups, or separate invoices by city or vendor.
Have they delivered year‑on‑year cost optimization or route efficiency improvements across regions, or only in one or two showcase sites.
When disputes arise on billing, dead mileage, or waiting charges, is the underlying trip and GPS data available and consistent across all cities.
Have outcome‑linked commercials, like incentives or penalties tied to OTP or safety, been operationalized at scale or only piloted at one site.
8. Experience, safety and stakeholder satisfaction
Do your HR, Security, and Facility teams in secondary locations feel they get the same level of support and responsiveness as your main campus.
How does employee satisfaction with commute compare between metros and Tier‑2 or Tier‑3 locations, and does the vendor share location‑wise NPS or CEI.
Are women safety protocols, such as escort rules, route approvals, and 24x7 safety cells, enforced uniformly across all cities.
Can you describe a serious incident or escalation from a non‑flagship site and how the vendor’s command center, local teams, and leadership responded.
9. Governance cadence and continuous improvement
What is the governance rhythm, such as weekly ops reviews and quarterly business reviews, and are all cities covered in a structured way.
Do they bring data‑driven insights, like route optimization opportunities, fleet mix changes, or EV adoption roadmaps, across regions, or only per site when asked.
Have they successfully standardized policies, SOPs, and KPIs across your business units while still allowing for local nuances.
Would you describe them as a strategic mobility partner managing a governed program, or as a collection of city‑level vendors loosely coordinated.
10. Reference’s overall risk and recommendation view
If you had to expand today into three new cities at once, would you be confident using the same vendor under the same global SLA framework.
Where do you still see gaps in consistency, for example certain cities, time bands, or service lines like EMS versus CRD.
If you were in my role aiming for global SLA standardization, what specific caveats or guardrails would you put into the contract and governance model with this vendor.
These lines of questioning help a Strategy or PMO leader test whether the vendor operates with a mature, command‑center‑driven model, with standardized SLAs, compliance, and reporting, or whether performance is still personality‑driven and site‑specific.
What proof shows SLA governance is truly standardized across sites—same KPI definitions, timeband rules, and dashboards—so we don’t fight over whose numbers are right?
B0547 Standardized KPI definitions across sites — In India multi-site Employee Mobility Services (EMS), what should a Transport Head ask for as proof that SLA governance is standardized—like common KPI definitions, consistent timeband rules, and comparable dashboards—so site leaders aren’t arguing over whose numbers are 'real'?
In multi-site EMS, a Transport Head should ask for hard, cross-location artefacts that prove KPIs, timebands, and dashboards are defined once and applied everywhere with the same logic. Standardization is real only when definitions, data sources, and calculation methods are identical and auditable across all sites.
The first proof point is a written SLA and KPI dictionary that is signed off centrally. This dictionary should define each metric in operational language. It should specify formulas for OTP, Trip Adherence Rate, seat-fill, no-show, incident rate, and EV utilization where relevant. It should also lock timeband definitions for day, evening, and night shifts so regions cannot redefine windows to make their numbers look better.
The second proof point is a single EMS operation cycle and command-center SOP applied to every branch. This includes one documented ETS/EMS operation cycle, a micro-functioning-of-command-centre playbook, and a common escalation matrix. These documents should show that incident closure SLAs, routing rules, and safety protocols are identical for all sites.
The third proof point is a single-window dashboard with role-based views where every site’s numbers come from the same backend. The dashboard should show OTP, exceptions, safety incidents, and CO₂ impact per site with drill-down to trip logs. It should use the same data pipeline for all cities so local teams cannot modify raw files before reporting.
Additional proof signals include a centralized compliance management system, a common business continuity plan, and a standard indicative management report pack. These should show that compliance status, BCP triggers, and governance reviews follow the same templates and are comparable across locations.
privacy, data portability, and auditability
Frames DPDP-aligned privacy controls, data ownership, and fast, audit-ready data packs with tamper-evident logs and clear exit provisions.
What security and DPDP privacy proof should IT ask for—audits, pentest summary, IR process, retention controls—so we’re covered if something goes wrong?
B0477 Security and DPDP proof — In India employee mobility services (EMS) governed by DPDP Act expectations, what should a CIO ask for as third-party security and privacy proof (audit reports, penetration test summary, incident response process evidence, retention controls) to reduce personal “career-ending event” risk from a data breach?
A CIO evaluating an employee mobility services platform in India should insist on independent, repeatable security and privacy evidence that maps to DPDP expectations and can be shown to auditors without interpretation. The goal is to verify that the vendor’s controls, logging, and incident playbooks are real, current, and DPDP-aligned, not just promised in slideware.
Core audit and certification artefacts
The CIO should ask for recent third-party audits that prove a functioning ISMS and operational discipline.
- Formal audit reports or certificates for controls frameworks such as ISO 27001 for information security management.
- Certificates for ISO 9001 and ISO 45001 where they exist to evidence broader process and safety governance, because these often correlate with disciplined operations.
- Scope statements that explicitly include EMS applications, driver and rider apps, command-center platforms, and hosting environments.
- Confirmation of surveillance, compliance, and command-center governance structures that demonstrate continuous control, not annual box-ticking.
Penetration testing, vulnerability and app security evidence
The CIO should demand concrete proof that the EMS platform is regularly attacked and hardened by independent specialists.
- Executive summaries of recent external penetration tests that cover web dashboards, mobile apps, APIs, and cloud infrastructure.
- Documented remediation cycles that show how high and medium findings are tracked, fixed, and retested.
- Evidence that production apps and APIs are protected by role-based access, encryption, and tamper-evident logging, as indicated in the industry brief.
Incident response, BCP, and command-center operations
The CIO should request living documents and logs that prove the vendor can detect, respond, and recover from security incidents.
- Incident response runbooks that define detection, triage, escalation matrices, and customer notification flows.
- Business continuity and contingency plans that cover technology failures, app downtime, and data-center disruptions, with clear RTO/RPO objectives.
- Evidence of drills or actual incidents with timelines, root cause analysis, and corrective actions taken.
- Descriptions of 24x7 command-center monitoring, alert supervision, and escalation practices, since EMS is shift-critical.
Data lifecycle, retention, and DPDP-aligned controls
The CIO should insist on clear, documented data-handling practices that map to DPDP principles of purpose limitation and storage limitation.
- Data-flow diagrams identifying what personal data is collected from employees and drivers, where it is stored, and which subprocessors are involved.
- Retention and deletion policies for GPS traces, trip logs, SOS events, and identity documents, including configurable retention periods and automated purge processes.
- Assurances on role-based access control, encryption at rest and in transit, and audit logs for all administrative access and data exports.
- Documented consent and lawful-basis UX for rider apps, especially for location, trip history, and safety telemetry.
Contractual assurances and exit safety
The CIO should capture these controls in enforceable contract language to reduce “career-ending event” exposure.
- Data-processing addendums that define data ownership, DPDP roles, breach notification SLAs, and cooperation duties during investigations.
- Clauses guaranteeing data portability, secure deletion on exit, and access to raw trip and security logs during the relationship.
- Clear allocation of liability for security incidents, with minimum insurance coverages aligned to cyber and professional liability.
When a CIO can point to external audits, tested incident playbooks, explicit retention controls, and contractual DPDP alignment, the personal risk from an EMS-related data breach is significantly reduced and is defensible in front of boards, regulators, and auditors.
What should we lock in for data ownership and exports of trip logs and evidence—formats, frequency, termination help—so we can exit without losing our audit trail?
B0484 Data portability for audit trails — In India corporate employee transport (EMS), what should Legal and Procurement insist on regarding data ownership and portability of trip/event logs used as evidence (formats, export frequency, termination assistance) so the organization has a clean exit path without losing audit trails?
In India EMS programs, Legal and Procurement should hard-wire clear data ownership, open evidence formats, regular exports, and structured termination assistance into contracts so the organization never loses control of trip/event logs or audit trails at exit.
They should first make data ownership explicit. Contracts should state that all trip logs, GPS traces, SOS events, incident tickets, compliance records, and CO₂ data generated under the EMS program are owned by the client organization, not the vendor. Vendors should be defined as processors or custodians only, with no right to restrict access, charge punitive fees for exports, or delete data before client-approved retention periods tied to HR, EHS, and regulatory needs.
They should then insist on portable, audit-ready formats and predictable export schedules. Trip and incident data should be exportable in standard machine-readable formats such as CSV or JSON, with clear data dictionaries so Finance, HR, Security, and ESG teams can reconcile records. Export cadence should be defined in the SLA, for example daily or weekly dumps to a client-controlled storage or integration with a mobility data lake. This reduces dependence on vendor dashboards and protects against fragmented data, which is a known pain point.
Finally, Legal and Procurement should define a structured exit and termination assistance package. Contracts should include a detailed data handover plan covering final full exports of all trip/event logs, configuration metadata, and compliance evidence, along with a specified support window to validate integrity and resolve discrepancies. Clauses should prevent vendors from using proprietary schemas or closed APIs to block portability, and should link final payments or bank guarantees to successful completion of data transfer and verification. This approach aligns with emerging expectations around auditability, outcome-based contracts, and resilience in EMS operating models.
images:
If a vendor won’t share trip-level data even in anonymized form, how do IT and Procurement tell whether it’s a valid constraint or a warning sign of lock-in or poor visibility?
B0493 Interpreting refusal to share data — In India employee mobility services (EMS), when a vendor refuses to share raw or anonymized trip-level data as proof, how should a CIO and Procurement interpret that—what are legitimate constraints versus signs of lock-in or weak observability?
In enterprise employee mobility services in India, a vendor’s refusal to share raw or anonymized trip‑level data is a material risk signal. It usually indicates weak observability, immature data architecture, or deliberate lock‑in, rather than a reasonable constraint. CIO and Procurement teams should treat this as a governance red flag unless the vendor can point to a clearly defined, limited, and legally grounded restriction with compensating controls.
Legitimate constraints are usually narrow and explicit. Vendors might restrict certain direct identifiers to comply with India’s DPDP Act. They might require data‑processing agreements for long‑term storage in the enterprise data lake. They might throttle real‑time APIs for performance reasons but still provide periodic exports. In a mature EMS platform, these constraints are documented, policy‑driven, and accompanied by alternative mechanisms such as aggregated mobility data, pseudonymized trip ledgers, and role‑based access to streams from routing engines, telematics dashboards, and HRMS‑linked integrations.
Problematic behavior looks different. A vendor that only offers PDF reports or static dashboards, refuses API access to the trip ledger, and cannot map SLAs like OTP, Trip Adherence Rate, and Cost per Employee Trip back to underlying trips is signaling poor data models and fragile internal systems. A vendor that cites “IP protection” or “confidential algorithms” to block any export of telemetry, GPS logs, or routing outputs is likely trying to prevent benchmarking, multi‑vendor governance, or future migration to another MaaS provider.
CIO and Procurement teams can use a few practical tests. They should insist on contract language that affirms client data ownership, API‑first access, and export rights for trip, billing, safety, and compliance logs. They should ask vendors to demonstrate how streaming telematics feeds reach a mobility data lake, how audit trails are retained for incident response, and how outcome‑based contracts could be supported without trip‑level observability. They should also verify how easily data can be reconciled with HRMS, ERP, and finance records for SLA compliance and billing audits. Vendors who support these requests generally have stronger command‑center operations, better integration fabric, and lower long‑term lock‑in risk.
In the EMS contract, what exit clauses should we lock in—data export timelines, transition support, pricing—so we can switch vendors without losing compliance evidence?
B0496 Contract exit terms for evidence — In India corporate ground transportation vendor contracting for EMS, what specific exit terms should Legal insist on (data export windows, assistance hours, transition pricing, retention of evidence logs) so the organization has ‘divorce terms’ that don’t jeopardize compliance reporting?
In corporate EMS vendor contracts in India, Legal should hard-code detailed “divorce terms” that guarantee complete data export, defined transition support, and retention of auditable logs. These terms protect compliance reporting for safety, labour, tax, and ESG long after the vendor exits.
Contracts should mandate full export of all trip, routing, GPS, SOS, driver, and billing data in open, documented formats. Legal should insist that exports cover the entire contract period and include HRMS-linked identifiers for employees and routes to support labour, safety, and ESG audits. The agreement should define a clear export window after termination, such as 60–90 days, with at least one full dry-run export before go-live to validate structures and fields. Legal should require that mobility data schemas are documented and that APIs or bulk-download mechanisms remain available up to the end of the exit window.
Legal should define minimum evidence-retention periods for GPS traces, incident logs, SOS activations, and compliance checks. These periods should align with enterprise policies for OSH, labour, motor vehicle, and data protection requirements. The vendor should commit to immutable storage of safety and compliance evidence for a defined duration, even post-termination, with guaranteed access for the client during investigations. Contracts should specify where evidence is stored, how integrity is protected, and how chain-of-custody is preserved for incident reconstruction.
Transition assistance should be quantified in hours and roles. Legal should specify a structured transition support package that includes configuration handover, knowledge transfer on routing and rostering logic, and help with reconnecting to HRMS and ERP systems. The contract should define a fixed transition period, for example 30–60 days, with pre-agreed man-days from key vendor staff like solution architects and NOC leads. Legal should protect against punitive pricing during this period by capping transition support rates and defining a standard rate card valid through exit. The agreement should also prohibit data-holdback or service degradation as leverage during disputes.
- Mandate open-format, complete data exports for all EMS trip, safety, and billing records.
- Set explicit post-termination export windows and one validated test-export before full deployment.
- Define evidence-log retention periods and integrity guarantees for GPS, SOS, and incident data.
- Quantify transition support hours, roles, timelines, and rate caps to prevent last-minute lock-in.
Before we roll this out widely, what proof should IT ask for to ensure we can export our trip data cleanly and have a clear exit plan if we change vendors?
B0502 Exit plan and data portability proof — In India corporate ground transportation platforms for employee mobility services (EMS), what evidence should a CIO request to prove data portability and an exit path—such as raw trip/event logs export format, API access, and termination data handover timelines—before approving a large multi-site rollout?
In enterprise employee mobility platforms, CIOs should insist on concrete, testable evidence of data portability and exit-readiness before approving a large, multi-site rollout. Data portability must be proven through documented export formats for raw trip and event logs, live API access that is not commercially gated, and clear termination data handover SLAs that are contractually binding.
CIOs should ask for explicit documentation of what raw data can be exported. The vendor should describe schemas for trip and event logs, including identifiers, timestamps, GPS traces, roster links, billing references, safety and SOS events, and compliance status. The documentation should clarify whether exports are available in standard machine-readable formats and whether these exports include the full audit trail needed for HR, Finance, and ESG stakeholders. This directly impacts downstream integration with HRMS, ERP and ESG reporting.
Evidence of sustained API access is critical. CIOs should require an API catalog that shows endpoints for trip lifecycle data, roster and employee mapping, GPS/telematics, billing and invoice metadata, and safety or incident events. The vendor should state whether these APIs remain available for bulk extraction during and after contract, and how rate limiting, authentication and role-based access are handled. This ensures that central command centers, data lakes and analytics stacks can ingest mobility data reliably.
Clear exit path evidence must be requested upfront. CIOs should push for termination clauses that define data handover timelines, formats, and responsibilities for verification. The contract should specify how long historical data remains accessible, how ESG and compliance datasets will be preserved, and how the vendor will support transition to another EMS, CRD or EV platform without service disruption. These clauses protect against lock-in while supporting governance requirements for auditability and regulatory reporting.
What security and privacy proof should IT/security insist on from an employee transport vendor so we’re protected if there’s ever a breach?
B0503 Security evidence for IT sign-off — In India corporate employee mobility services (EMS), what third-party security and privacy evidence (e.g., audits, pen-test summaries, DPDP-aligned controls) is reasonable for a CISO/CIO to demand so they can say, “I won’t get fired for this,” if a mobility data breach happens?
In India corporate employee mobility services, a CISO/CIO is reasonable to demand third‑party evidence that proves the EMS platform is securely designed, independently tested, and DPDP‑aligned across data lifecycle and command‑center operations. The minimum defensible bar is a mix of mature certifications, independent security assessments, and auditable privacy controls that map to how EMS actually works (driver/rider apps, GPS, HRMS integration, and 24×7 command centers).
A CISO or CIO gains real defensibility when mobility vendors show that security is embedded in their broader operating model. This includes evidence of centralized command center practices, continuous monitoring, and business continuity planning that ensures uptime and controlled incident handling. It is also reasonable to expect that vendor documentation explains how safety systems like SOS, geofencing, IVMS, and compliance dashboards are protected from misuse and secured against data leaks. The most credible vendors can show how they align command center operations, fleet telemetry, and app data flows with India’s DPDP obligations such as minimization, access control, and breach readiness.
Reasonable third‑party evidence typically includes:
- Security certifications that demonstrate mature quality and safety management in mobility operations. These certifications usually sit alongside evidence of operational governance, centralized command centers, and safety/compliance frameworks.
- Independent assessments of business continuity and contingency planning. These should show how EMS operations will continue securely during cab shortages, technology failures, or political and weather disruptions, and how data integrity is preserved in those conditions.
- Documented command center and governance models that show clear segregation of roles, escalation matrices, and continuous monitoring. This structure reduces the risk of uncontrolled access to trip, location, and identity data in daily operations.
- Evidence of centralized compliance management for drivers, vehicles, and vendors. Automated notifications, maker–checker checks, and audit trails strengthen the CISO’s argument that regulatory and safety duties are being systematically discharged.
- Independent validation of safety and HSSE controls, including how driver background checks, women‑safety protocols, and SOS handling are embedded into technology and processes, and how these controls are monitored by command centers.
For privacy and DPDP‑aligned controls, a CISO/CIO is justified in asking vendors to show how mobility data is minimized, access‑controlled, and made auditable. In an EMS context, this means clear explanations of what data is collected in employee, driver, and vendor apps; how long trip and location records are retained for SLA, safety, and ESG reporting; and how data can be exported or deleted in line with enterprise policy. It is also reasonable to expect visibility into how ESG and emissions dashboards are fed from trip data without exposing identifiable employee information beyond what is contractually agreed.
images:

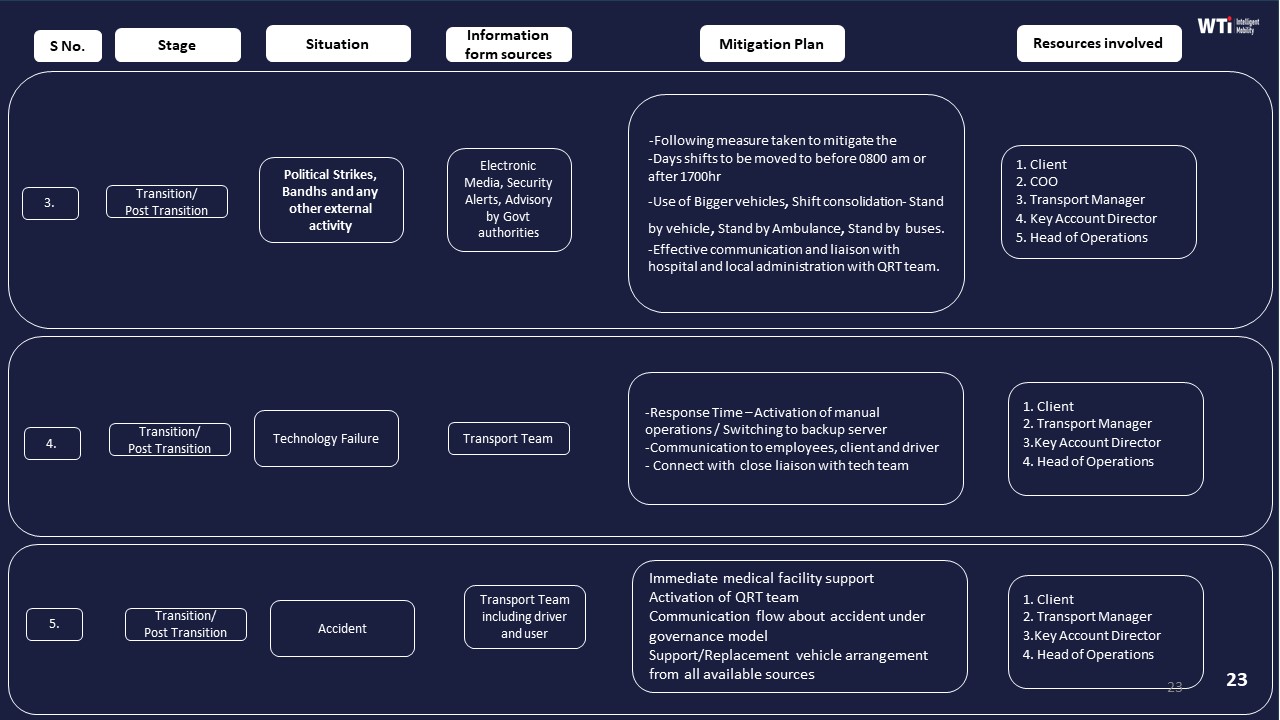
When we speak to references, what should we ask about how privacy is actually handled—consent, retention, breach response—so IT doesn’t get surprises later?
B0513 Privacy behavior checks via references — In India corporate employee mobility services (EMS) under DPDP Act expectations, what should a buyer ask reference customers about real-world privacy handling—like consent UX, data retention, and breach response behavior—so IT isn’t surprised after go-live?
In India corporate employee mobility services, buyers should ask reference customers very specific, experience-based questions about how privacy is handled in day‑to‑day operations so that IT is not surprised after go‑live. The focus should be on what actually happens in the apps, logs, and command center under the DPDP Act, not only what the contract claims.
Buyers should first probe how consent is implemented in the rider and driver apps in real usage. They should ask reference customers whether employees clearly see what is being collected, for what purposes, and for how long, and whether consent flows are granular or bundled. They should ask if there have been complaints about “forced GPS tracking” or lack of opt‑out options for non‑essential features. This helps surface whether consent UX aligns with DPDP expectations on lawful basis, transparency, and minimization.
The next set of questions should focus on data retention and access. Buyers should ask how long trip logs, GPS traces, and SOS records are actually retained in the live system and archives, and who inside the vendor and client can access them. They should ask whether reference customers have ever requested bulk data deletion, anonymization, or exports and how quickly that was executed. These questions reveal whether the vendor has a practical retention policy, role‑based access, and workable data‑portability paths, as expected in a governed EMS environment.
Finally, buyers should explicitly ask about real incident and breach behavior. They should ask reference customers if there has ever been a data exposure, misdirected report, leaked manifest, or unauthorized use of location data. They should request details on how quickly the vendor notified IT and security teams, what evidence was provided, and what corrective controls were implemented. They should also ask how incident response integrates with the client’s own security and audit workflows. These conversations help IT validate that breach response, audit trails, and chain‑of‑custody around trip and telematics data match DPDP‑aligned expectations before contracts are signed.
How do we ensure the vendor’s anonymized data is still detailed enough (city/site/shift/exception reasons) to evaluate performance, while staying privacy-compliant?
B0521 Useful anonymization without DPDP risk — In India corporate ground transportation for employee mobility services (EMS), how should a buyer verify that anonymized data packs still preserve enough granularity—city, site, timeband, exception reason codes—to be decision-useful without violating privacy expectations under DPDP?
In employee mobility services, anonymized data packs are decision-useful when they retain operational dimensions like city, site, shift window, and exception reason codes but remove or mask any link back to an identifiable employee. Buyers should verify this by testing the data against re-identification risks while confirming that key EMS KPIs and route-level analytics remain computable.
A practical approach is to request sample anonymized datasets from the EMS provider and run a joint validation with IT, Security/EHS, and Transport teams. The buyer should confirm that fields for city and site are present, that time is at least grouped into shift-aligned timebands, and that exception reason codes still distinguish between categories like no-show, routing deviation, safety incident, or GPS failure. The same dataset should no longer contain employee names, phone numbers, exact addresses, or unique device identifiers, and trip IDs should be pseudonymous.
A common failure mode is over-scrubbing, where vendors aggregate everything to such a high level that Transport cannot use it for routing improvement, shift windowing, or dead mileage reduction. Another failure mode is pseudo-anonymization that still allows cross-joining trip logs with HRMS data to pinpoint individuals. Under India’s DPDP expectations, buyers should test whether a reasonable internal adversary with access to HR or attendance data could re-identify a person from the mobility dataset.
To keep data both safe and useful, buyers can define clear acceptance criteria such as:
- Granularity: city, site, and shift-band fields must be retained, along with trip-level timestamps rounded to appropriate intervals.
- Safety and exception analytics: coded fields for incident types and SLA breaches must remain intact for audit and continuous improvement.
- Privacy controls: direct identifiers removed, quasi-identifiers minimized or bucketed, and role-based access enforced through the EMS platform or command center.
This balance allows centralized command-center operations, SLA governance, and EMS optimization to continue, while aligning with privacy expectations and auditability under DPDP.
Before IT signs off on employee tracking and trip data, what security/privacy proof should we ask for—audits, IR process, retention, and access controls?
B0531 Security evidence for DPDP mobility data — In India corporate Employee Mobility Services (EMS) under DPDP Act constraints, what third-party security and privacy evidence (e.g., audit reports, incident-response runbooks, data retention and access controls) should a CIO/CISO demand before allowing employee location tracking and trip telemetry into the enterprise environment?
In India EMS deployments under the DPDP Act, CIOs and CISOs should insist on third-party security and privacy evidence that proves lawful basis, technical hardening, and operational discipline across the full trip lifecycle. The core requirement is auditable proof that employee location and trip telemetry are collected minimally, processed securely, and can be defended during regulatory, HR, or legal scrutiny.
CIOs and CISOs should first demand independent security attestations and governance evidence. They should obtain recent infrastructure and application security assessments, with penetration test and vulnerability assessment reports that cover routing engines, driver and rider apps, telematics dashboards, and command-center tooling. They should require documented information-security policies that address encryption standards, key management, and role-based access controls across NOC tooling, HRMS integrations, and mobility data lakes.
They should then focus on data protection and DPDP-aligned privacy controls. They should ask for written data-classification and data-retention policies that distinguish identity data from GPS and telematics streams, with clear retention windows for raw trip logs, GPS traces, and incident records. They should review access-control matrices that define which roles can see live location, historical trip ledgers, and incident evidence, together with audit logs that show who accessed which employee or route data and when.
CIOs and CISOs should also require structured incident-response and business-continuity artefacts. They should obtain incident-response runbooks that explicitly handle mobility data breaches, app compromise, telematics tampering, and command-center outages. They should review business continuity and disaster recovery plans for GPS and routing systems, including playbooks for technology failures and fallback modes for manual operations that still respect privacy obligations.
Finally, they should insist on integration, vendor-governance, and data-portability assurances. They should ask for documented API specifications that support secure, minimal, and auditable data exchange with HRMS, ERP, and security systems. They should require a vendor-governance framework that covers periodic capability and compliance audits, SLA breach tracking, and exit procedures, including commitments around data export, deletion, and audit-trail preservation. This evidence allows CIOs and CISOs to admit EMS telemetry into the enterprise environment while preserving control, traceability, and DPDP-aligned accountability over employee location data.
For women’s night-shift safety, what proof should we ask for—audits, SOS/escort logs, geofence breaches—so we can pull a compliance pack fast if something happens?
B0532 Women-safety evidence and audit packs — In India corporate employee transport (EMS) for women’s night-shift safety and duty-of-care, what evidence should an EHS/Security Lead ask for—such as third-party audits, escort/SOS event logs, and geo-fencing breach trails—to feel confident the vendor can produce 'panic button' compliance reporting when an incident is escalated?
For an EHS/Security Lead to be confident about “panic button” and night‑shift duty‑of‑care compliance in India EMS, the vendor must prove that safety controls are real, continuously monitored, and audit‑ready. The most reliable signal is whether the vendor can reconstruct any SOS journey end‑to‑end with time‑stamped evidence, not just show a generic dashboard.
The EHS/Security Lead should ask for concrete artefacts in four buckets.
First, the lead should request samples of SOS event logs that include trip ID, vehicle, driver, passenger details, exact GPS coordinates at alert time, route trace before and after the alert, response time stamps, and the escalation path followed through the command center or Transport Command Centre. These logs should be backed by a central dashboard view that shows how alerts are triaged, which mirrors the SOS control panel collateral showing real‑time updates and automated ticket creation.
Second, the lead should ask for geo‑fencing and route‑adherence breach evidence. This includes reports of geofence violation alerts, route deviation flags, and fixed device tampering alerts, similar to what is described in the Alert Supervision System collateral. The vendor should demonstrate that breach trails are preserved with immutable time stamps and that service desks can show closure actions for each deviation.
Third, the lead should demand proof of women‑safety specific controls. This means evidence of women‑centric safety protocols, including driver background verification artefacts, POSH and gender‑sensitivity training records, and clear women‑only or escort‑compliant routing rules as shown in the women‑centric safety protocols and women safety & security collateral. The vendor should show that the employee app exposes SOS, safe‑reach‑home confirmations, GPS tracking, and call‑masking, with sample reports of how often these features are used and how quickly responses are triggered.
Fourth, the lead should review third‑party or internal audit reports that cover safety and compliance. These should link to centralized compliance management dashboards, HSSE role charts, and safety inspection checklists, demonstrating periodic audits of vehicles, drivers, and incident‑handling SOPs. The vendor should be able to show how the command center operations, as depicted in the command center and Transport Command Centre materials, produce measurable outcomes like SLA compliance and incident‑closure SLAs that can be shared with clients during escalations.
What should we lock into the contract on data ownership, export formats, and termination support so we can exit cleanly and still keep audit trails if we switch vendors later?
B0536 Contract terms for data exit — In India corporate ground transportation (EMS/LTR) contracts, what should Legal and Procurement ask for regarding data ownership, data export formats, termination assistance, and referenceability clauses so the company has a clean exit strategy and can still produce audit trails after termination?
Legal and Procurement in India EMS/LTR contracts should hard-code data ownership, export, termination assistance, and referenceability so that mobility operations remain auditable even after vendor exit. A clean exit strategy depends on contractually securing raw trip data, standard export formats, time-bound post-termination support, and clear rules on mutual publicity and case-study use.
Data ownership
Contracts should state that all operational and personal data generated under the EMS/LTR program belongs to the client organization.
Legal should require that vendor systems act as processors or custodians, not owners, of trip, GPS, driver, and employee data.
Clauses should cover command-center logs, routing decisions, SOS triggers, exception handling, and compliance checks as part of client-owned records.
The contract should mandate that vendors maintain audit trail integrity for the whole tenure.
Data export formats
Procurement should specify that all historical data is exportable in open, non-proprietary formats.
Contracts should name formats such as CSV, JSON, and PDF for operational logs and reports.
Exports should include full trip lifecycle data, OTP/OTP-equivalents, GPS traces, incident logs, and billing linkages.
The agreement should require schema documentation so internal systems can map fields cleanly.
Termination assistance & audit continuity
Legal should define a termination assistance period with clear timelines and responsibilities.
The vendor should be obligated to provide bulk data exports covering the full contract period before system access is cut.
Clauses should require continued read-only access or archived data delivery for a defined time to support audits and investigations.
The contract should specify that logs must remain tamper-evident and time-stamped for regulatory and internal reviews.
Referenceability and case-study rights
Procurement should insist on mutual consent before use of the client’s name or logo in marketing or case studies.
Legal should separate operational data rights from referenceability rights so that withdrawal of marketing consent does not affect data access.
Clauses should permit the client to reference the engagement and its metrics in internal and external reporting without vendor restriction.
Any ESG or safety outcomes used publicly should be derivable from the same auditable data sets controlled by the client.
HR wants strong safety tracking, but Legal worries about privacy—what proof should we ask for on consent, lawful basis, and minimization while still meeting night-shift safety needs?
B0542 Balancing safety telemetry and privacy — In India corporate Employee Mobility Services (EMS) where HR wants maximum safety telemetry but Legal worries about privacy overreach, what proof should be requested to demonstrate lawful basis, consent UX, and minimization—without weakening night-shift safety evidence requirements?
In Indian corporate Employee Mobility Services, HR and Legal should jointly demand explicit, documentary proof that safety telemetry is collected on a clear lawful basis, with narrow purpose and retention, and that consent and notice flows are designed to withstand DPDP-era scrutiny while still preserving audit-ready night-shift evidence. The proof should show that data used for women-safety, incident reconstruction, and SLA governance is strictly minimized to what is operationally necessary, time-bounded, and access-controlled.
Vendors should evidence a defined lawful basis for each data flow in the EMS stack. They should map which data is processed under consent and which under legitimate purpose or legal obligation linked to duty of care, OSH, and night-shift safety norms. They should provide written policies that tie GPS, trip logs, escort rules, SOS data, and route approval telemetry directly to safety and compliance outcomes, not to open-ended monitoring or productivity surveillance.
Consent UX should be demonstrated through actual employee app screens and flows. These flows should show layered notices, clear purpose statements for commute safety and night routing, and explicit call-outs for sensitive telemetry like live GPS, SOS tracking, and audio or in-vehicle monitoring systems where used. Vendors should be able to show how employees can view what is collected, how long it is stored, and what recourse exists, without giving them the ability to disable mandatory safety telemetry during active night-shift trips.
Data minimization and retention should be proven through a documented data schema and retention schedule. The schema should show that only trip-relevant fields are stored, that continuous background tracking outside duty windows is blocked, and that high-granularity location data is downsampled or deleted after defined windows once SLA, billing, and safety investigations are closed. Night-shift and women-safety evidence requirements should be preserved through tamper-evident trip ledgers and GPS logs that are locked for a defined period for audit and incident response, but not retained indefinitely or reused for unrelated analytics.
To balance HR’s safety needs and Legal’s privacy constraints, organizations can require:
- Policy and architecture documents that map each telemetry element to lawful basis, purpose, and retention, aligned with DPDP and Motor Vehicles / OSH obligations.
- Screen-level consent and notice UX artifacts from rider and driver apps, evidencing clarity, voluntariness where applicable, and non-ambiguous safety messaging for night-shift operations.
- Role-based access controls and audit-log samples from the command center that show who can view live locations, SOS events, and historical trip data, and under what SOPs.
- Evidence-pack templates for incidents and night-shift audits that demonstrate sufficiency of GPS, route adherence, and escort-compliance data without excessive intrusion beyond the trip lifecycle.
This combination allows HR to maintain a zero-incident, audit-ready posture for women’s night shifts and escort compliance, while giving Legal defensible proof that EMS telemetry is governed by lawful basis, minimization, and observable controls rather than unchecked surveillance.
reference hygiene, vendor viability, and selection discipline
Guard against cherry-picked references; validate comparable city/timeband performance; and ensure vendor viability signals reflect real end-to-end accountability and continuity.
How do we check that a vendor’s references are genuinely similar to us—same cities, volumes, and night shifts—so we don’t get misled by a best-case customer?
B0469 Reference comparability screening — In India corporate ground transportation procurement for EMS/CRD, how can a Procurement Category Manager validate that a vendor’s customer references are truly comparable (same industry, city mix, employee volumes, night-shift ratio, and timebands) rather than “showcase” accounts that won’t predict our operational reality?
In corporate EMS/CRD procurement, a category manager can only trust vendor references when each reference is forced into a comparable “operating profile” template and then cross‑checked against objective evidence, not just narrative claims. The core discipline is to translate your own commute pattern into hard filters (industry, city tier mix, employee volume bands, night‑shift exposure, and timebands) and insist that every reference be mapped against those same filters with verifiable data and SLAs.
A common failure mode is accepting generic logos or marquee accounts that are in different industries, different city profiles, or largely day‑shift EMS, which do not predict performance in heavy night‑shift, Tier‑2/Tier‑3, or multi‑city EMS contexts. Another failure mode is relying on anecdotes instead of metrics like OTP%, incident rate, EV uptime, fleet utilization, and complaint closure SLAs that reflect real EMS or CRD operational stress. Procurement should therefore ask for reference packs that include city lists and site counts, shift windows served, employee base size and active ridership, service mix (EMS vs CRD vs ECS vs LTR), and night‑shift and women‑safety exposure.
Better practice is to predefine comparability criteria and use them as a go/no‑go screen. Procurement can specify minimum criteria such as presence in comparable cities and timebands, similar employee volumes per site, and similar mix of EMS and CRD. Procurement should then require contactable references where HR, Transport, and Security stakeholders confirm on‑time performance, safety, escalation behavior, and business continuity during disruptions like monsoon, strikes, or tech outages.
To avoid “showcase only” bias, category managers can ask for at least one challenging reference: for example, an EMS account with high night‑shift ratio, women‑centric routing, or rapid scale‑up/down events. They can also ask to see anonymized dashboards or MIS extracts that demonstrate real‑time monitoring, SLA tracking, and audit trails, which are central in this industry’s command‑center and compliance‑led operating models.
Useful validation steps include:
• Defining a short checklist that maps each reference against your industry, city mix, shift profile, and governance expectations.
• Requiring evidence of centralized command‑center operations and safety/compliance controls, not just basic fleet supply.
• Probing how the vendor handled specific issues such as driver shortages, late pickups, or weather disruptions, and how quickly exceptions were detected and closed.
If a vendor claims cost savings, what should be in the before/after data pack—seat-fill, dead miles, cancellations, timebands—so Finance can tell if it’s real and sustainable?
B0475 Cost-savings proof requirements — In India corporate employee transport (EMS), what should an anonymized “before/after” data pack include (route density, seat-fill, dead miles, cancellations, timeband distribution) so a CFO can judge whether claimed savings are structural or just a short-term crackdown?
An anonymized before/after data pack for employee transport in India should let a CFO compare unit economics, reliability, and utilization over comparable periods, with enough granularity by route and timeband to see if savings come from structural changes or one-time enforcement. The pack should pair trip-level operational metrics with billing and commercial views so Finance can reconcile stories about optimization against CPK and CET trends.
Core volume and mix context
The pack should first establish workload comparability. It should show total trips, total employees served, and total kilometers by month in the before and after windows. It should break these into peak and non-peak timebands and into major route clusters or zones. It should explicitly flag any policy changes that reduced demand, such as fewer entitled employees or fewer working days.
Unit economics and cost visibility
The CFO will look for cost per kilometer and cost per employee trip for both windows. The data pack should link these unit costs to actual invoiced amounts and verified kilometers, not just planned kilometers. It should separate base transport charges from surcharges or penalties to show whether savings are from rate negotiation, reduced dead mileage, or suppressed service.
Utilization, seat-fill, and dead mileage
The pack should provide Trip Fill Ratio, with distributions by timeband and route cluster instead of only an overall average. It should show dead mileage as a percentage of total kilometers, again by timeband and city or zone. It should include vehicle utilization indicators such as number of trips per vehicle per shift and average duty duration.
Reliability, cancellations, and exceptions
A CFO will want to see that savings did not come from degraded reliability. The data pack should therefore include on-time performance percentages for pickups and drops. It should present employee-side cancellations, vendor-side cancellations, and no-show rates, split by timeband and location. It should also show exception-to-closure times and any changes in escalation volume.
Timeband and shift-window analysis
Because cost drivers and risk differ across the day, the pack should slice all key metrics by defined shift windows and night versus day bands. It should show route density per timeband, including average route length and number of employees per route. It should highlight whether night-shift routes were shortened, merged, or reduced in frequency in the after period.
Safety, compliance, and ESG guardrails
To distinguish healthy optimization from unsafe cutbacks, the pack should include safety incident rates and compliance status indicators, such as credential currency and escort compliance where relevant. It should add EV utilization ratio and emission intensity per trip if EV adoption is part of the savings story. It should confirm that no safety-critical KPIs deteriorated while costs fell.
Structural-change signals vs crackdown artefacts
The pack should explicitly separate structural levers, such as routing changes, vendor rationalization, or fleet mix shifts, from one-off actions, such as short-term caps on ad-hoc trips. It should therefore include:
- Route and cluster list before and after, with counts of active routes and average seat-fill.
- Vendor count and share of trips or kilometers by vendor tier.
- Fleet mix ratios across sedans, MUVs, shuttles, and EVs.
It should also flag any temporary process changes, such as manual approvals or travel freezes, so the CFO can see whether improved metrics depend on unsustainable controls.
For airport/intercity trips, what should our travel desk ask in reference calls to confirm the vendor handles delays, late-night arrivals, and surge periods well?
B0476 Airport disruption reference checks — In India corporate car rental services (CRD) with airport and intercity SLAs, what reference checks should an Admin/Travel Desk lead run to validate “punctuality under disruption” (flight delays, late-night arrivals, surge periods) rather than standard weekday performance?
Admin and Travel Desk leaders should run reference checks that specifically probe how a CRD provider performs during disrupted, late, or high-stress conditions rather than on normal weekdays. The most reliable references focus on airport-linked SLA behavior, night operations, escalation discipline, and evidence of past disruption handling for similar enterprise clients.
They should speak to existing enterprise clients whose use-cases match their own airport and intercity patterns. References should be asked for specific examples of performance during late-night arrivals, multi-hour flight delays, and festival or monsoon peaks. The goal is to understand whether the vendor maintained on-time performance and predictable SLAs when traffic, weather, or flight schedules were abnormal, as highlighted in WTicabs’ monsoon case study that still reported 98% on-time arrivals and a 10% customer satisfaction increase.
A useful reference check goes beyond “Are you happy?” and looks for four concrete dimensions. Admin and Travel Desk leaders should probe how the vendor’s command center monitored flight-linked trips and adjusted dispatch, how quickly alternate vehicles were arranged when a vehicle or driver failed, how the vendor communicated proactively with both the travel desk and passengers, and how billing and SLAs were treated during disruptions. References should be asked whether no-shows, last-minute cancellations, or missed airport pickups are logged, investigated, and reported as part of a measurable, auditable performance framework.
Key questions to use with references include: - “Describe a recent flight-delay or weather-disruption day. How many airport pickups were impacted, and how many were still on time or within SLA?” - “When a driver or vehicle failed close to pickup time, what did the vendor’s command center do in the next 15–30 minutes?” - “How often do you see unplanned gaps at peak hours or late nights, and how does the vendor escalate and close these exceptions?” - “Do you get regular MIS or dashboards showing SLA performance by time-band, including nights and peak travel periods?”
A strong CRD vendor will have documented business continuity plans for cab shortages, technology failures, and natural disruptions, as well as a live alert supervision or command-center system. Reference checks should therefore confirm that these BCP elements and alert systems are actually used in day-to-day operations, especially for airport and intercity trips, rather than being only proposal-stage promises.
How do we ask for city- and shift-specific references without letting the vendor only share their best-performing locations and time slots?
B0479 Prevent cherry-picked references — In India employee mobility services (EMS), what is a fair way for Procurement and HR to demand city/timeband-specific references (for example, Hyderabad night shift vs Pune day shift) without letting the vendor cherry-pick only their strongest lanes?
In Indian employee mobility services, the fairest way to demand city/timeband-specific references is to standardize the ask as a structured evidence pack. Procurement and HR should define the exact lanes, timebands, KPIs, and proof formats up front and then require vendors to disclose both strengths and gaps against that grid, rather than allowing open-ended, cherry-picked case studies.
Procurement and HR teams gain control when they move from “share references” to a clear reference template that mirrors real EMS operations. The template can separate Hyderabad night shifts, Pune day shifts, or other priority lanes and ask for site-wise client names, contract tenure, scope (EMS vs CRD vs ECS), and volume bands. It can also ask for outcome metrics that are already standard in the category, such as on-time performance, incident rate, and escalation handling, along with whether women-safety protocols and command center monitoring were in scope.
A fair model also requests lane-level or timeband-level references across a mix of conditions. For example, buyers can specify at least one similar night-shift IT/ITES program, one mixed-shift industrial or project site, and one city outside the vendor’s strongest base. This ensures vendors surface comparable operations rather than only their flagship locations shown in client-logo or “Our Clients” collateral. Where the vendor has no direct match, the template can require the nearest adjacency and a short explanation of how they would de-risk the new lane.
To prevent over-reliance on narrative testimonials, buyers can ask for anonymized governance artefacts instead. These may include a sample ETS operation cycle snapshot, indicative management reports used with existing EMS clients, or command center dashboards showing EMS OTP and exception closure trends. Procurement can then cross-check these artefacts against the vendor’s broader value proposition, such as their centralized command center, business continuity plans, safety and compliance frameworks, and EV operations where relevant.
Finally, HR and Procurement can frame these requirements as part of standard EMS governance rather than a one-time RFP hurdle. The same lane/timeband reference grid can evolve into a live vendor-governance matrix, aligned with centralized command-center observability, business continuity planning, and data-driven insights. Vendors that are comfortable operating under this level of transparency are typically better suited to EMS environments that demand predictable OTP, safety assurance, and audit-ready evidence across cities and timebands.
If HR/Ops like a vendor because ‘everyone uses them,’ what extra proof should Finance ask for to confirm billing control and low dispute/leakage—beyond customer logos?
B0480 Separate social vs financial proof — In India corporate employee transport (EMS), when HR and Operations are pushing for a “safe” vendor with lots of references, how can a CFO separate social proof from financial proof—what evidence should exist beyond logos to show the vendor can control leakage and disputes?
In corporate employee transport in India, a CFO should treat logos and references as hygiene and insist on traceable financial and operational evidence. Financial proof in EMS comes from how a vendor measures, governs, and reconciles cost, not from how many clients are on a slide.
Concrete signals that separate social proof from financial proof include:
- Billing design linked to operations. There should be a clearly documented ETS / EMS operation cycle with trip-level data flowing into an automated, centralized billing system. Evidence includes tariff mapping, online reconciliation, and SLA-linked billing steps rather than manual spreadsheets.
- Transparent billing models and levers. The vendor should show standard models (per km, trip-based, FTE, monthly rentals, pay-per-usage, custom) with clear rules for dead mileage, waiting, cancellation, and night charges. Leakage risk rises when these rules are opaque.
- Centralized, auditable billing platform. Look for demonstrable features such as flexible billing options, automated tax calculations, customizable invoicing, real-time invoice tracking, and integration with ERP or accounting systems. This reduces disputes and manual reconciliation effort.
- End‑to‑end process maps. A documented process from booking → trip execution → GPS/trip logs → approval → invoice should exist. Each handoff should be defined so auditors can trace any charge back to trip evidence.
- Outcome-linked SLAs tied to commercials. SLAs for on-time performance, exception closure, and safety or compliance should be written into contracts with clear incentives/penalties rather than informal “best-effort” promises.
- Management reporting and dashboards. There should be standard MIS showing cost per trip, cost per km, no‑show rates, dead mileage, and vendor performance. CFOs should test whether these reports align with invoices and can be sliced by cost center or location.
- Dispute-handling workflow. The vendor should have a defined escalation matrix, ageing reports for open disputes, and proof that billing issues are resolved within agreed SLAs, not rolled over month after month.
- Compliance and audit trail integrity. Centralized compliance management, documented maker–checker policies, and automated alerts for missing documentation help prevent post‑facto disputes over invalid trips, drivers, or vehicles.
When these elements are present and demonstrable, logos and testimonials become supporting context. Without them, heavy “social proof” usually indicates that financial control, leakage prevention, and dispute hygiene are weakly governed rather than structurally assured.
What should we ask reference customers about failures—driver no-shows, GPS/app issues, last-minute roster changes—and how the vendor handled them in real life?
B0486 Reference questions on failure handling — In India corporate ground transportation vendor selection for EMS, what are the most revealing questions to ask a reference about operational edge cases—driver no-shows, GPS failures, app downtime, sudden roster changes—and how the vendor behaved during those failures?
In India EMS vendor selection, the most revealing reference questions focus on how the vendor behaved during failures, not just average performance. References should be asked about specific operational edge cases such as driver no-shows, GPS failures, app downtime, and sudden roster changes, and how quickly and transparently the vendor restored control for the transport team.
The strongest questions isolate a concrete incident and then probe for timelines, communication, and who actually took ownership. References can be asked to describe a recent night-shift breakdown or weather disruption and to specify whether the vendor’s command center, alert supervision system, or transport command centre took proactive action or waited for escalations. It is useful to ask whether buffer vehicles, standby cars, or business continuity plans were actually deployed, as described in structured BCP and “Guarantee for Uninterrupted Services” playbooks.
References should be pressed on how the vendor handled GPS or app failures. A direct question is whether the vendor had a manual fall-back SOP and whether trips continued using phone-based coordination, command-center routing, or alternate tools. Another critical probe is whether SLA and billing were adjusted automatically after outages or if Finance and Transport had to fight to correct invoices, given the emphasis on centralized billing, complete and timely operations, and SLA-linked performance.
For driver no-shows and last-minute roster changes, references can be asked whether the vendor’s routing and command-center teams re-routed in minutes or left the facility head to self-manage. It is important to ask if the vendor escalated internally using clear matrices and governance structures, and how fast employees received updated ETAs or app notifications. A revealing follow-up is whether these incidents reduced over time, indicating that data-driven insights and route optimization were used to prevent recurrence.
Questions about edge cases should also explore safety and women-centric scenarios. References can be asked whether women-safety protocols, SOS workflows, and escort rules held up when routes changed late or when technology glitched. A key test is whether command-center dashboards, alert systems, and centralized compliance management provided audit-ready evidence after an incident or if the client had to reconstruct events manually.
Finally, references should be asked whether the vendor’s behavior in crises matched their proposals. It is useful to ask how often senior operations leaders or key account managers joined calls during disruptions, whether root-cause analyses were shared through dashboards or management reports, and if any process changes, training, or driver rewards and recognition programs were implemented based on those failures. This checks whether the vendor’s promise of operational excellence, BCP, and measurable performance is real or only visible in marketing collateral.
What should we ask to get comfortable with a vendor’s financial stability and continuity—so we’re not stranded mid-contract with unsupported systems or dependencies?
B0488 Vendor viability and continuity proof — In India corporate employee transport (EMS), what proof should a buyer request about vendor financial stability and continuity (runway, support commitments, subcontractor dependencies) so Procurement and the CIO aren’t stuck with unsupported tooling mid-contract?
For employee mobility services in India, buyers should demand concrete, auditable evidence of a vendor’s financial stability, business continuity, and support capacity before awarding EMS contracts. Procurement and CIO teams reduce the risk of “tooling abandonment” when they treat financial viability, operational continuity, and subcontractor control as hard pre-conditions, not soft promises.
Vendors should provide recent, signed financial statements and evidence of external validation. Buyers should request audited financials, proof of credit lines or insurance cover, and, where relevant, IPO or rating documents that signal long-term solvency. Procurement should also ask for details of any revenue concentration risk, such as over-reliance on a single client, and how this is managed.
A clear business continuity and contingency framework is equally important. Buyers should insist on documented Business Continuity Plans that cover cab shortages, natural disasters, political strikes, and technology failures, with specific mitigation steps, responsible roles, and recovery time objectives. Evidence of buffer fleets, backup systems, and emergency playbooks demonstrates that operations can continue even under stress.
Support commitments must be backed by structure, not intent. Organizations should require a defined 24/7 command center model, escalation matrices with named roles, ticketing SLAs, and proof of an adequately staffed helpdesk or call center. CIO teams should map these commitments to integration and uptime expectations so that fleet management platforms, apps, and dashboards have clear operational ownership over time.
Subcontractor and vendor dependency risk needs explicit disclosure. Buyers should ask for a vendor and statutory compliance framework that covers fleet partners, technology providers, and energy or EV infrastructure partners, along with audit and replacement mechanisms. This ensures that if a subcontractor fails, the primary EMS vendor has contractual levers and operational options to maintain service.
images:
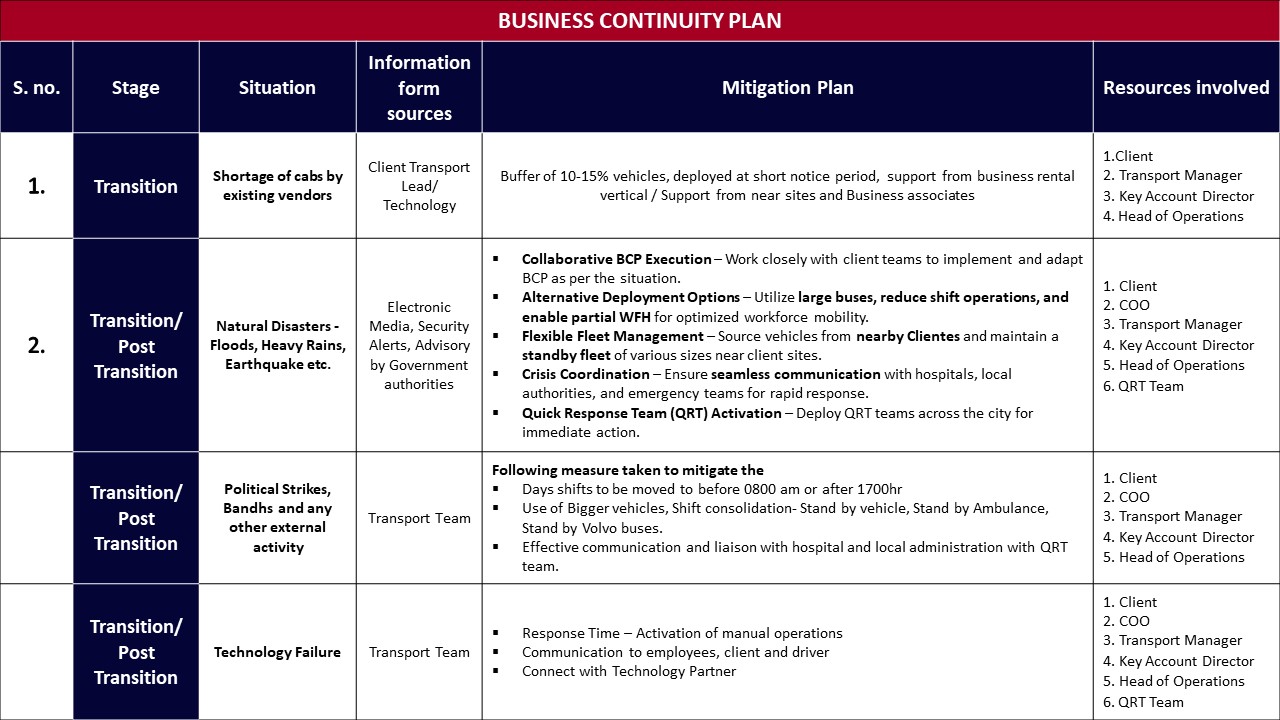
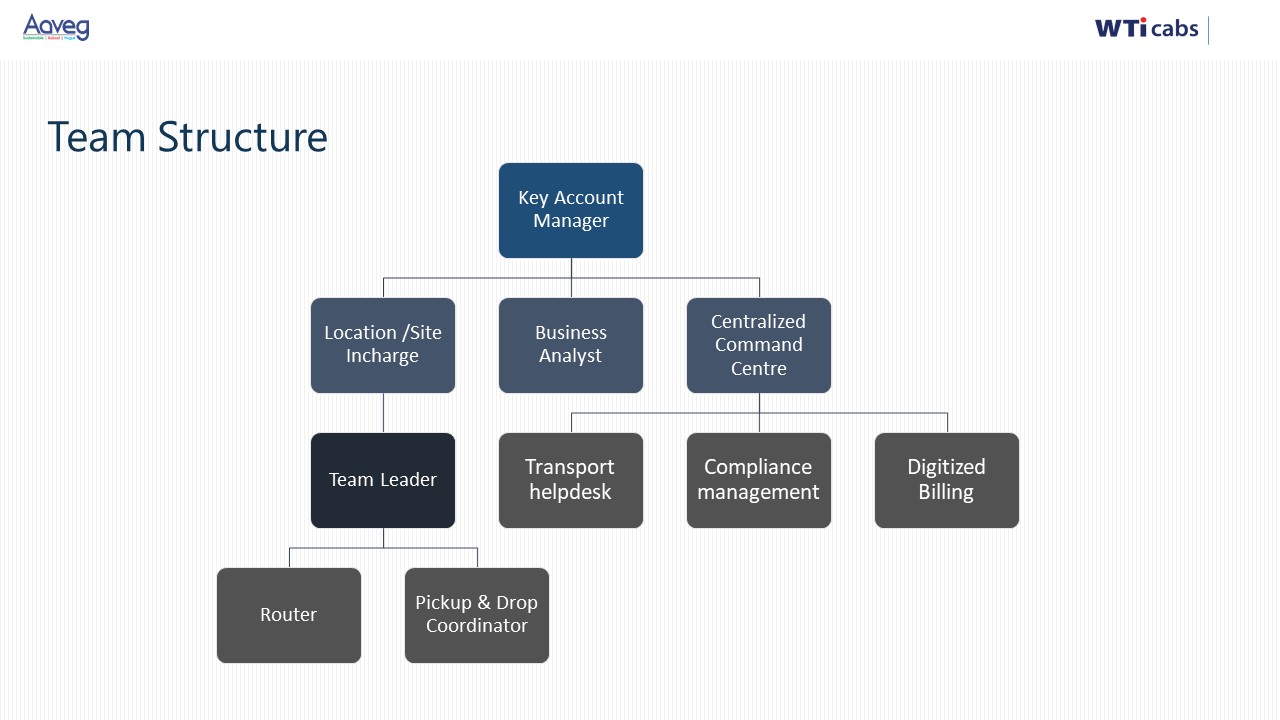
For executive car rentals, what proof should we ask for to ensure consistent vehicle standards and substitutions—so leadership doesn’t face unpleasant surprises?
B0489 Executive experience consistency proof — In India corporate car rental services (CRD), what should an Executive Admin ask for as proof of vehicle standardization and service consistency (vehicle class adherence, substitution rules, complaint rates) when leadership expects a premium experience without surprises?
In Indian corporate car rental (CRD) programs, an Executive Admin should insist on hard, recurring evidence for vehicle standardization and service consistency, not one-time assurances. The proof should make it easy to show leadership that every trip for senior executives will match agreed vehicle standards, that substitutions are controlled, and that complaints are measured and reducing over time.
The starting point is a clear vehicle standardization policy shared in writing. This policy should define approved vehicle classes for different executive tiers, and it should link those classes to actual models in the vendor’s fleet. A robust vendor will back this policy with documented fleet compliance checks and pre-induction vehicle assessments that verify age, mechanical condition, and statutory documentation for every car before it enters service for the client.
For day-to-day control, the Executive Admin should demand a live dashboard or periodic report that shows vehicle allocation against these standards. This evidence should list how many trips used the correct class, how many required substitutions, the reason for each substitution, and whether the client’s approval or SOP was followed before the change. Vendors who already run centralized command centers and single-window dashboards typically have these trip-level records and route adherence reports available as standard outputs.
Service consistency must be visible in complaint and incident data. The admin should ask for a monthly or quarterly “User Satisfaction Index” style pack summarizing complaint volumes, top complaint types, resolution times, and trend lines. This report should connect feedback analysis, complaint closure SLAs, and floor-connect initiatives with measurable changes in NPS or satisfaction scores. Evidence of a 97% satisfaction rate or similar survey outcomes is useful only when paired with how the vendor maintains that level through ongoing audits and quality assurance processes.
To close the loop, the Executive Admin should request samples of vehicle deployment and quality assurance checklists, chauffeur training and assessment proof, and route or trip audit results. These artifacts demonstrate that pre-trip inspections, driver briefings, and post-trip audits are not theoretical, but are actually happening in a repeatable way. Vendors who already practice systematic vehicle deployment, safety inspection checklists, and command center monitoring can usually share anonymized examples without difficulty.
images: 
images: 
From references, what should we ask about employee adoption and grievance handling after rollout, so HR knows the day-2 operational workload and isn’t surprised?
B0494 Reference checks on day-2 ops — In India corporate employee mobility services (EMS), what should a buyer ask a reference customer about change management realities—employee adoption, grievance closure, and day-2 operations—so HR isn’t surprised by hidden operational drag after rollout?
In India EMS buying, reference calls should probe how the vendor handled day‑2 realities in practice, not just go‑live ceremonies. Buyers should ask specific, incident-focused questions on employee adoption, grievance closure, and ongoing operations so HR does not inherit hidden operational debt after rollout.
For employee adoption, buyers should ask how long it took to reach stable usage after launch. They should ask what percentage of employees actively used the app versus manual workarounds in the first 30, 60, and 90 days. They should probe what resistance patterns appeared in different segments such as night-shift women, field staff, or senior managers. They should ask what non-technical effort HR and Transport had to invest such as floor walks, townhalls, or manual roster corrections.
For grievance closure, buyers should ask how complaints were actually logged and tracked in day‑2 operations. They should ask typical closure times for missed pickups, routing disputes, and driver-behaviour complaints. They should probe how many issues still bypass the system and come as direct calls to HR or the Facility Head. They should ask whether the vendor’s command center really drives resolution or only forwards information back to the client team.
For ongoing operations, buyers should ask what changed in the transport desk workload after stabilization. They should ask whether manual rostering, Excel tracking, or WhatsApp coordination still continue behind the system. They should probe how often escalation to senior HR or leadership is still required for routine failures. They should ask how the vendor handled driver shortages, GPS or app downtime, monsoon traffic, and EV charging issues without pushing constant firefighting back to HR and Transport.
When we ask for references, how do we make sure the vendor gives us references that match our real operating conditions—same city and same shift timebands—so we don’t get a misleading success story?
B0498 Reference matching by city/timeband — In India corporate ground transportation vendor selection for employee mobility services (EMS), how should Procurement evaluate the credibility of customer references by city and timeband (e.g., Bengaluru 10pm–6am) to avoid being misled by “sunshine” references that don’t match Tier-2/3 operating realities?
Procurement should treat customer references in employee mobility services as operating-condition evidence, not generic testimonials, and must explicitly match each reference to the same city, timeband, and risk profile where service is being bought.
Most organizations in India see very different operating realities between metros and Tier‑2/3 cities, and between daytime and 10pm–6am shifts. A common failure mode is accepting “sunshine” references from easy corridors or daytime operations while buying high‑risk night‑shift EMS in cities with weaker supply, heavier weather disruption, or stricter women‑safety expectations. Procurement avoids this by demanding references that are tagged by city, timeband, and shift pattern, and by probing how the vendor handled driver availability, safety incidents, and escalation in those exact conditions.
Credible references for EMS should cover regulated night‑shift operations, women‑centric safety protocols, and central command‑center oversight, not just generic OTP claims. References from metros like Bengaluru or Mumbai for 10pm–6am should be evaluated separately from Tier‑2/3 city references because fleet availability, traffic patterns, and enforcement differ. Procurement should pressure‑test vendor claims about centralized command centers, business continuity plans, and on‑ground supervision against reference feedback, including how the vendor performed during disruptions such as weather, strikes, or technology failures.
Stronger evaluation also links references to measurable KPIs such as on‑time performance, incident rates, fleet uptime, and complaint closure SLAs, rather than qualitative satisfaction alone. References that can speak to EV fleet performance, safety and compliance automation, and central alert supervision during night shifts in similar cities are more predictive of success. References limited to airport CRD or daytime shuttles in Tier‑1 locations are weak predictors for Tier‑2/3 EMS and should be weighted accordingly or discounted.
- Prioritize references that match city, timeband, and shift‑type risk.
- Probe for specific examples of disruption handling and escalation.
- Demand KPI‑linked evidence, not just narrative satisfaction.
- Downgrade references that only reflect “easy” metro daytime use cases.
What should Finance ask to judge whether the mobility vendor is financially stable and won’t disappear mid-contract and leave us scrambling?
B0500 Vendor viability due diligence — In India corporate ground transportation procurement for employee mobility services (EMS), what due-diligence questions should a CFO ask to assess vendor viability and continuity risk, so Finance isn’t blamed if the vendor exits and the enterprise is stranded mid-contract?
The most important due‑diligence questions for a CFO in India evaluating EMS vendors are those that expose financial resilience, operational depth, compliance discipline, and exit readiness. These questions protect Finance from blame if a vendor fails or exits mid‑contract because they create a defendable audit trail that vendor continuity was rigorously assessed.
1. Financial Strength, Guarantees, and Business Model
Ask how the vendor’s revenue is distributed across EMS, CRD, ECS, and LTR so concentration risk is visible. Request audited financials and details of banking lines, and then ask what explicit performance or bank guarantee they will provide and how exposure caps (for example, up to a given escalation level) are structured. Clarify whether they can commit to no base‑price increase for the contract tenure and how year‑on‑year cost reduction or benchmarking is operationalized.
2. Fleet, Supply Chain, and Multi‑City Redundancy
Ask how many vehicles the vendor controls directly versus through partners and in which cities they already run EMS at scale. Request their buffer capacity policy for shift operations and how they handle cab shortages, driver absenteeism, or surges, including links to formal Business Continuity Plans that cover strikes, natural disasters, and technology failures. Probe how they tier and rotate vendors in a fleet‑aggregator model so a single operator’s exit does not break service.
3. Command Center, Governance, and Escalation
Ask whether they run a 24x7 centralized command center plus local hubs and what SLAs govern exception detection to closure for OTP, safety, and compliance. Request their escalation matrix, meeting cadences for QBRs, and how service performance is measured via OTP%, Trip Adherence Rate, and SLA Breach Rate. Clarify who answers the phone at 2 a.m. and how many concurrent EMS accounts their NOC can realistically supervise.
4. Compliance, Safety, and Auditability
Ask for the vendor’s compliance and induction frameworks for drivers and fleet, including credentialing cadence, HSSE responsibilities, and random route or compliance audits. Request sample compliance dashboards and evidence packs showing chain‑of‑custody for GPS and trip logs, incident response SOPs, and women‑safety protocols for night shifts. Confirm how they maintain audit trail integrity and what happens if an incident requires reconstruction months later.
5. Technology Reliability, Data Ownership, and Lock‑In Risk
Ask about their uptime SLOs for rider/driver apps, NOC tools, and routing engines and how they handle graceful degradation or offline‑first operation when GPS or networks fail. Require clarity on data ownership, raw trip‑log access, and API‑level integration with HRMS and ERP so Finance is not dependent on opaque reports. Probe exit paths by asking how quickly they can hand over the mobility data lake, schemas, and dashboards if the contract is terminated.
6. EV and ESG Resilience (If EMS Includes EV Fleets)
Ask what proportion of their EMS fleet is electric today, what Fleet Electrification Roadmap they follow, and how they de‑risk charging gaps and range constraints for night shifts. Request measurable EV uptime, EV utilization ratios, and carbon abatement indices tied to EMS, plus how these numbers are calculated and auditable for ESG and investor reporting.
7. Transition, BCP, and Replacement Playbooks
Ask for a macro‑level transition plan showing pre‑transition, tech rollout, fleet deployment, and steady‑state timelines with clear responsibilities. Request formal Business Continuity Plans that cover cab shortages, political actions, disasters, and technology outages, and insist on seeing how replacement vendors would be onboarded under a Mobility Governance Board or Vendor Governance Framework. Clarify commercial protections if the vendor exits early, including notice periods, support obligations, and penalties tied to business continuity failure.
What reference checks help us confirm the vendor can own end-to-end performance as the primary provider—not just as a subcontractor in someone else’s setup?
B0507 Prime-vendor accountability validation — In India multi-vendor corporate employee mobility services (EMS), what reference and evidence checks help Procurement avoid awarding to a vendor that performs well only as a subcontractor but fails when they are prime and accountable for end-to-end SLA governance?
In Indian multi-vendor employee mobility (EMS), Procurement avoids “good subcontractor, poor prime” outcomes by checking for direct evidence of end-to-end SLA ownership, not just participation in someone else’s program. The most reliable signals are live governance artefacts, command-center maturity, and proof that the vendor has actually run large EMS programs as prime with measurable OTP, safety, and compliance outcomes.
Procurement teams typically look for whether a vendor operates a 24x7 centralized command center with real-time alerts, escalation matrices, and on-ground control. They also verify if the vendor has implemented complete ETS operation cycles, including rostering, routing, vendor distribution, tracking, feedback and billing, rather than only supplying cars into another integrator’s system. Evidence like a documented MSP governance structure, micro functioning of command centre, and principle role of command centre diagrams reinforces that the vendor can manage multi-location EMS, not just fleet supply.
A strong filter is whether the vendor provides structured Business Continuity Plans for cab shortages, political strikes, tech failures, and natural disasters. Vendors whose BCPs only cover their own fleet but not end-to-end EMS workflows are usually still playing a subcontractor role. Procurement can ask for incident reports and case studies that demonstrate 98%+ on-time performance under stress conditions, such as adverse weather or night-shift operations, as shown in the Mumbai monsoon case study.
Another reference check is the existence of a formal account management and operational excellence model. Documentation on governance committees, performance metrics, risk registers, and engagement models across leadership, senior management, and service delivery levels gives Procurement confidence that the vendor is used to being accountable at policy and SLA levels. Capability comparison tables that position the vendor against “Tech Co.” and “FM Co.” also highlight whether their strengths lie in pure logistics and transport management versus just tech or facility add-ons.
Evidence of centralized compliance management for vehicles and drivers, HSSE role definitions, and detailed driver and fleet induction frameworks indicate readiness to own safety and statutory responsibility. Vendors that can show centralized compliance dashboards, driver assessment procedures, women-centric safety protocols, and alert supervision systems have already internalized prime-vendor obligations for duty-of-care and auditability.
Finally, Procurement can use client lists, contract tenures, and testimonials that explicitly reference the vendor as the sole or lead mobility partner for EMS. Long-running contracts with major enterprises, combined with user satisfaction indices around 97% and EV transition success stories, show that the vendor can carry full EMS accountability over multiple years, including ESG-linked performance and measurable CO₂ reductions.
For executive and airport trips, what references and proof should we ask for to trust the vendor on punctuality, vehicle standards, and handling flight delays—beyond testimonials?
B0508 Executive travel reliability references — In India corporate car rental and executive travel ground transportation (CRD), what customer reference evidence best predicts executive experience reliability—like airport delay handling, vehicle standardization adherence, and response-time SLAs—and how should an Admin/Travel Desk validate it beyond curated testimonials?
In corporate car rental and executive ground transportation in India, the most predictive evidence of executive experience reliability is operational data and process artefacts that link airport delay handling, vehicle standardization, and response-time SLAs to measurable outcomes over time. Curated testimonials alone are weak predictors, because they do not expose SLA discipline, exception handling, or consistency across locations and peak periods.
The strongest reference evidence usually combines multi-year enterprise client rosters, live or recent dashboards of SLA performance, and case studies tied to specific CRD use cases such as airport transfers, intercity trips, and VIP movements. Collateral that shows centralized command centers, alert supervision systems, and single-window dashboards for trip tracking and exception management indicates that the provider runs a governed operations model rather than a purely ad-hoc vendor network. Evidence of standardized chauffeur assessment and training, vehicle compliance and induction processes, and centralized compliance management is particularly predictive for vehicle standardization and safety-critical executive travel.
An Admin or Travel Desk should validate this evidence by asking for specific, auditable artefacts rather than accepting summary slides. The Travel Desk can request anonymized SLA reports for airport pickups, including on-time performance percentages and documented handling of flight delays. It can review billing and invoicing process flows to confirm that response-time SLAs and no-show policies are implemented as rules, not promises. It can also ask for copies of vehicle safety inspection checklists and fleet compliance logs to confirm age, condition, and documentation requirements for executive-class vehicles.
To go beyond curated testimonials, Admin teams should prioritize three forms of validation. They should review quantitative performance dashboards that show trip volumes, OTP, and incident rates by city or branch over at least several quarters. They should inspect operational workflow diagrams, such as ETS or CRD operation cycles and command center micro-functioning charts, to confirm that exception management and escalation matrices exist in practice. They should also validate safety and driver-management artefacts, like driver compliance and induction procedures or driver management and training frameworks, because these directly influence the reliability and consistency of executive experience in late-night airport runs and long intercity journeys.
Useful checks for an Admin or Travel Desk include the following. They can match reference client lists and tenure tables to see if major enterprises have stayed 3–5 years with the vendor, which signals sustained reliability. They can examine case studies where on-time arrival improved under adverse conditions, since these demonstrate resilient routing and command-center control. They can also insist on seeing data-driven insight dashboards and indicative management reports to confirm that the provider continuously measures and improves CRD performance rather than relying on reactive fixes.
images:
images:
For long-term rentals, what evidence should we ask for on uptime—maintenance logs, replacement timelines, downtime history—so Finance is comfortable with a multi-year contract?
B0510 LTR uptime and continuity proof — In India long-term rental (LTR) corporate fleet programs, what proof should Finance ask for on uptime continuity—like replacement vehicle timelines, maintenance compliance logs, and historical downtime distributions—so they can justify a multi-year commitment without fear of being locked into poor service?
In India long-term rental (LTR) corporate fleet programs, Finance teams should insist on quantitative, audit-ready uptime evidence before signing multi‑year contracts. They should demand structured proof on actual fleet uptime, how quickly vehicles are replaced during breakdowns, and whether maintenance and compliance are governed through traceable logs over time.
Finance needs to see uptime as a governed lifecycle metric, not a promise. Uptime continuity in LTR depends on preventive maintenance schedules, replacement planning, and clear downtime playbooks across the contract tenure. A common failure mode is a vendor committing “95–98% uptime” verbally but lacking historical distributions of downtime per vehicle, no-show tracking, and root‑cause analysis for breakdowns.
To justify a multi‑year commitment without lock‑in fear, Finance should ask for concrete artefacts and measurement baselines, such as:
- Historical uptime and downtime distributions by vehicle type and city.
- Documented replacement vehicle SLAs with actual past performance against those SLAs.
- Maintenance and compliance logs mapped to OEM schedules and statutory norms.
- Command‑center or NOC reports showing how incidents were detected, escalated, and closed.
- Business continuity and contingency playbooks for cab shortages, strikes, tech failures, and disasters.
This level of proof links directly to key Finance concerns like predictable cost per kilometer, enforceable SLAs, and audit‑ready defensibility of mobility spend.
1. Uptime and Replacement SLAs: What to Demand in Writing
Finance should first anchor on measurable uptime KPIs for the LTR fleet. Uptime in this context is the percentage of calendar time that a dedicated vehicle is available and fit for duty under contract. Uptime continuity is particularly critical because LTR is designed for service continuity, assured availability, and long‑term budget alignment rather than day‑to‑day vendor juggling.
The following evidence helps Finance differentiate between marketing claims and governed performance:
- Historical uptime metrics. Finance should request at least 12–24 months of historical Fleet Uptime data for similar LTR clients, broken down by:
- Vehicle category (sedan, MUV, EV, etc.).
- City or region, since road and infrastructure conditions differ.
- Client type (e.g., EMS vs CRD vs project fleets, where duty cycles vary).
- Downtime distributions, not just averages. Finance should ask for distributions of downtime events:
- Number of downtime events per vehicle per quarter.
- Typical duration bands: <2 hours, 2–6 hours, 6–24 hours, >24 hours.
- Breakdown vs scheduled maintenance vs compliance holds.
- Replacement vehicle SLA and performance. LTR continuity often hinges on how quickly a replacement vehicle is deployed when the primary vehicle goes down.
- Finance should insist on a written SLA that defines maximum allowed time to provide a replacement vehicle in each city and timeband.
- They should request historical adherence data: percentage of breakdowns for which a replacement met the defined SLA.
- They should check whether replacement vehicles meet the same vehicle category, compliance, and chauffeur standards.
- Buffer fleet / standby plan. Vendors with a credible LTR model usually maintain a buffer of standby vehicles.
- Finance should ask for the documented standby ratio (for example, 5–10% buffer) and where those vehicles are physically based.
- They should request case examples where the buffer was used to maintain service during peak breakdowns or disruptions.
When Finance sees clear uptime baselines and replacement performance tied to SLAs, the perceived risk of multi‑year lock‑in reduces significantly.
2. Maintenance and Compliance Logs: Evidence That Uptime Is Managed, Not Lucky
Uptime continuity in LTR is not just about reacting to breakdowns. It depends on structured preventive maintenance and rigorous compliance management over the vehicle lifecycle.
The context brief specifies that LTR is characterized by preventive maintenance / uptime management, lifecycle governance, and vehicle performance tracking over contract tenure. Finance teams should therefore ask for:
- Preventive maintenance schedules and adherence logs.
- OEM‑aligned maintenance plans by vehicle type and usage profile.
- Actual maintenance execution logs: dates, odometer readings, nature of work done.
- Variance reports where maintenance was delayed and the impact on uptime.
- Compliance dashboards and document currency.
- Evidence of a Centralized Compliance Management system tracking permits, fitness certificates, tax tokens, and insurance.
- Compliance dashboards showing document expiry alerts and closure times.
- Proof that no vehicle is deployed when critical documents have lapsed.
- Fleet induction and quality checks.
- Pre‑induction checklists covering mechanical, electrical, and safety systems.
- Maker–checker processes for fleet onboarding and periodic audits.
- Sample Safety Inspection Checklists for vehicles, including brakes, tyres, seat belts, and emergency tools.
- Driver readiness and fatigue controls.
- Driver compliance and induction frameworks covering licensing, background verification, and health.
- Training logs around safe driving, defensive techniques, and seasonal risk (e.g., monsoon training).
- Evidence of duty‑cycle controls aligned with labor and OSH norms.
When maintenance and compliance logs are systematic and auditable, Finance can treat uptime as an engineered outcome, not a stochastic risk.
3. Command Center, Incident Handling, and Business Continuity Proof
LTR programs benefit from the broader governance patterns used across Employee Mobility Services and corporate car rental. A centralized command center or transport command centre offers real‑time monitoring, alerts, and escalation management. Finance should treat this as part of the uptime proof pack.
Useful artefacts include:
- Command center dashboards.
- Screenshots or demos of real‑time fleet tracking, vehicle health, and route adherence.
- Views showing exception alerts for breakdowns, delays, or geofence violations.
- Alert supervision and closure logs.
- Logs from alert supervision systems showing types of alerts (overspeeding, tampering, geofence violations) and mean time to acknowledge/resolve.
- Incident ticket histories that trace from detection → escalation → resolution.
- Business continuity and contingency plans specific to fleet availability.
- Documented Business Continuity Plans covering cab shortages, political strikes, natural disasters, and technology failures.
- Mitigation strategies such as additional buffer vehicles, support from associated businesses, and manual failover SOPs during app or GPS downtime.
- Role‑based escalation matrices showing who decides replacement deployment and how quickly.
This command‑center and continuity evidence reassures Finance that outages are contained and managed, not allowed to cascade into repeated service failures.
4. Historical KPI Packs and Case Studies for Pattern Confidence
Finance teams are data‑first and skeptical. They should move beyond vendor brochures to actual KPI packs and case studies relevant to long‑tenure, SLA‑bound operations.
They can ask for:
- Consolidated KPI reports.
- On‑Time Performance percentages for LTR and comparable fixed fleets.
- Trip Adherence Rate and incident‑to‑closure times.
- Fleet uptime and breakdown frequency over multiple quarters.
- Specific case studies of continuity under stress.
- Examples of maintaining 98% on‑time arrival during adverse conditions such as monsoon traffic disruptions.
- Examples where high fuel or maintenance costs were controlled without impacting uptime.
- Examples of EV LTR programs showing uptime improvement and maintenance reliability, if EVs are part of the roadmap.
- Management and analytics reports.
- Sample Indicative Management Reports that include safety, operations, billing, and technical issue categories.
- Data‑driven insights dashboards showing performance monitoring, predictive maintenance triggers, and route optimization outcomes.
These packs allow Finance to benchmark the vendor’s operational maturity and anticipate likely behavior over the multi‑year horizon.
5. Commercial Guardrails to Avoid Lock‑In on Poor Service
Even with strong proof, Finance needs contractual guardrails that tie money to uptime and continuity outcomes. Outcome‑linked procurement is a core trend in this sector, and LTR should not be exempt.
Finance can reduce lock‑in risk by demanding:
- Outcome‑linked SLAs.
- Explicit uptime targets with thresholds for penalties or earnbacks when performance drops below agreed levels.
- Linking portions of monthly rental to On‑Time Performance and Trip Adherence Rate.
- Transparent billing and reconciliation.
- Centralized billing systems with trip‑level reconciliation and online approval workflows.
- Evidence of flexible billing and automated tax calculations that support clean audits.
- Exit and substitution mechanisms.
- Contractual provisions allowing fleet right‑sizing, vehicle replacement, or vendor substitution if uptime falls below a defined threshold for a sustained period.
- Data portability clauses ensuring access to trip logs, compliance data, and performance history if Finance chooses to re‑bid later.
These commercial instruments convert uptime from a soft commitment into an enforceable, financially‑visible obligation.
6. Practical Checklist for Finance Before Signing an LTR Agreement
Before approving a multi‑year LTR fleet program, Finance teams in India can run a structured evidence check that aligns with their own accountability to auditors and leadership.
Key items to verify include:
- Documented historical uptime and downtime distributions for similar fleets and routes.
- Written replacement vehicle SLAs, plus proof of past adherence in live projects.
- Maintenance and compliance logs with clear cadence, evidence, and closure tracking.
- Command center capabilities, including real‑time tracking, alerts, and incident workflows.
- Business continuity plans that specifically address cab shortages and systemic disruptions.
- Quarterly KPI reporting formats with clear mapping to cost per kilometer and cost per employee trip.
- Contract clauses tying rental payments to uptime, OTP, and safety/compliance metrics.
When these proof points and guardrails are in place, Finance can defend a multi‑year LTR decision as disciplined, data‑backed, and resilient, rather than a risky bet on vendor promises.
When Finance doubts vendor references, what combination of evidence usually closes the gap so HR and Finance can align—data packs, third-party audits, and references that match our city and shifts?
B0511 Resolving HR–CFO proof conflict — In India corporate employee mobility services (EMS), how should a CHRO handle internal skepticism when Finance says, “references are not proof,” and what evidence format (anonymized data pack + third-party audit + comparable city/timeband references) typically resolves the HR–CFO trust gap?
In India EMS decisions, a CHRO usually cuts through Finance’s “references are not proof” objection by shifting from testimonials to an evidence pack that looks like an internal audit file. The most effective format combines an anonymized data pack, independent or audit-style validation, and like‑for‑like references from comparable cities and timebands.
The anonymized data pack works when it mirrors the company’s own KPIs. Industry collateral shows Finance teams respond to trip-level analytics, CO₂ reduction tables, billing flowcharts, and centralized dashboard screenshots that tie OTP, cost per km, and incident rates into a single window. A CHRO can lean on this pattern by asking vendors for before/after OTP%, CET/CPK, incident rates, and SLA breach rates from similar EMS programs, with client names masked but parameters and timeframes explicit.
Finance skepticism usually softens when numbers are backed by audit-style artifacts. Materials such as centralized compliance management diagrams, business continuity plans, billing and invoicing workflows, and tech-based measurable and auditable performance flows demonstrate that reported KPIs are traceable, not marketing claims. The CHRO should position these exactly like an internal control set: “Here is how incidents, trips, and invoices are logged, checked, and reconciled.”
Finally, comparable city and timeband references close the gap between “their context” and “our context.” Case studies from Indian metros with monsoon constraints, late‑night women safety programs, or EV fleets on shift-based operations give Finance a direct mental benchmark. When OTP, safety incidents, and cost trends are shown for a similar headcount, city traffic pattern, and night-shift mix, the HR–CFO trust gap typically narrows because the debate moves from belief in references to scrutiny of clearly structured, auditable evidence.
What are the typical ways references mislead in employee transport (wrong shift, wrong city, different operating model), and how should we run reference calls to catch that early?
B0512 Avoiding misleading reference traps — In India corporate employee mobility services (EMS), what are the most common “reference traps” that cause bad selections—like references from different timebands, different fleet models, or different governance maturity—and how can a buyer structure reference calls to surface those gaps early?
In Indian employee mobility services, the most common reference traps come from talking to the “wrong kind of customer” for your context. References from different timebands, different fleet mixes (EV vs diesel), and different governance maturity often sound positive but hide conditions that do not match your own risk, volume, or shift profile.
A frequent trap is relying on daytime or limited-shift references when the buyer’s real risk is night-shift EMS with women-safety requirements. Day-only operations do not test escort rules, SOS workflows, geo-fencing, night-time OTP under low supply, or business continuity under curfews or monsoon conditions. Another trap is taking EV-transition references at face value without checking charger topology, shift windows, and uptime data, even though EV feasibility is tightly linked to route length, idle windows, and local infrastructure.
Governance maturity mismatches are equally damaging. A reference with a centralized command center, tight HRMS integration, and defined escalation matrices experiences very different reliability and incident behavior than a site still doing manual rostering and phone-based dispatch. The same vendor can perform well under one governance model and poorly under another because of missing SOPs, fragmented visibility, and weak NOC involvement.
To surface these gaps early, buyers can structure reference calls around a few explicit axes.
- Timeband alignment. Ask, “What percentage of your trips are night-shift EMS, and how many involve female employees?” and “Have you tested their BCP playbooks during monsoon, strikes, or technology failures?”
- Fleet and EV alignment. Ask, “What is your current EV vs ICE mix for EMS?” and “What uptime and cost-per-km numbers are you actually seeing on EV routes similar to ours?”
- Governance and tooling alignment. Ask, “Do you use a centralized command center and HRMS integration, or is it mostly manual rostering and WhatsApp coordination?” and “How are OTP, safety incidents, and SLA breaches reviewed—do you receive structured dashboards or ad-hoc excel?”
- Continuity and escalation behavior. Ask, “Describe the last serious disruption. Who answered the phone at 2 a.m., and how fast was it stabilized?” and “Have you used their business continuity plan for cab shortages or tech downtime in the last 12 months?”
- Data and auditability. Ask, “Can you reconstruct a specific incident end-to-end from trip logs, GPS, and alert history?” and “Have you tested their billing vs trip data reconciliation with Finance or Audit?”
Buyers should also insist on speaking to at least one reference whose profile matches their own high-risk band. That means similar city tier, similar shift pattern, comparable employee count, and similar expectations on women-safety and ESG/EV commitments. If a vendor cannot provide a close operational match, that gap is itself a strong signal.
How should we balance big-name customer logos versus hard evidence like audits and data packs—especially when leadership wants the safest, most ‘standard’ vendor choice?
B0516 Logos vs evidence quality — In India corporate ground transportation sourcing for employee mobility services (EMS), how should Procurement balance “safety in numbers” social proof (big-name logos) versus evidence quality (audits, raw data packs), especially when leadership wants the ‘standard’ choice to reduce career risk?
Procurement in India EMS should treat big-name logos as a qualification filter, but make actual vendor selection decisions on the strength of evidence quality, auditability, and data transparency. Social proof can de-risk internal optics, but only auditable evidence protects Procurement when incidents, cost overruns, or audits occur later.
Procurement leaders sit between HR’s urgency, Finance’s skepticism, and Transport’s on-ground realities. Leadership often prefers the “standard” vendor with recognizable logos to reduce perceived career risk. However, the real personal risk for Procurement arises when a vendor with strong branding but weak evidence fails on women-safety compliance, OTP, billing integrity, or DPDP-aligned data handling. Social proof reduces perceived uncertainty, but it does not answer the core defence question during an investigation or audit.
A practical balance is to use logos and existing client lists only as an initial hygiene threshold, and then score vendors primarily on verifiable artefacts. These artefacts include trip-level audit trails, SLA-to-invoice linkage, incident logs, safety and compliance dashboards, and raw mobility data access aligned with HRMS and Finance systems. Vendors that provide structured business continuity plans, escalation matrices, command-center workflows, and measurable OTP and safety outcomes offer stronger protection than vendors who rely on awards or market-share claims alone.
Procurement can reduce internal backlash while still choosing the right partner by framing selection criteria explicitly around evidence. Useful criteria include demonstrable command-center operations, continuous driver and fleet compliance processes, auditable women-safety protocols, and the ability to support Finance, ESG, and Security with data-backed reports. When leadership asks why a “standard” vendor was not chosen, Procurement can point to documented evaluations showing superior SLA performance, safety governance, and data quality from the selected provider.
What are the biggest red flags to watch for in reference calls—like dodging incident questions or changing OTP definitions—that should make us slow down even if pricing looks good?
B0523 Reference red flags that matter — In India corporate employee mobility services (EMS) vendor evaluation, what are the top red flags in customer references—like evasiveness on incident rates, refusal to share timeband performance, or inconsistent definitions of OTP—that should cause a buyer to pause despite attractive commercials?
In enterprise employee mobility services in India, the most serious red flags in customer references are gaps that break trust, traceability, or operational control, even if commercials look attractive. Any sign that a vendor cannot give clean, consistent answers on safety incidents, on-time performance, compliance, or data access should trigger a pause in evaluation.
A critical signal is evasiveness around safety and incident history. A concerning pattern is when reference customers cannot clearly state incident types, frequency, or closure SLAs, or when women-safety protocols, escort compliance, GPS tampering controls, or SOS handling are described only in generic terms. This usually indicates weak incident logs, fragmented command-center practices, or a paper-only safety framework, which undermines duty of care and audit readiness.
Another red flag is inconsistent or selectively presented OTP and reliability metrics. Buyers should be cautious if references talk about “overall” OTP but cannot break it down by timeband, route type, city tier, or monsoon and disruption periods. A worrying sign is when on-time performance excludes cancellations, diversions, or vendor-caused no-shows, or when fleet uptime and trip adherence are claimed, but there is no link to route optimization, dead mileage control, or driver fatigue management.
A further warning sign is the absence of auditable, technology-backed evidence. References that cannot describe how GPS trip logs, CO₂ dashboards, command-center alerts, or compliance dashboards are actually used in daily operations suggest that platforms are more for demos than for real control. If they cannot explain how roster data, HRMS integration, and billing reconcile trip-by-trip, then outcome-based commercials and ESG claims are hard to defend later.
Buyers should also pause when references report frequent manual overrides and firefighting. Signals include heavy reliance on WhatsApp groups instead of defined escalation matrices, repeated last-minute roster changes without routing support, and night-shift operations that depend on individual heroes in the transport team rather than on standard operating procedures. This usually correlates with higher burnout risk for internal teams and fragile service continuity during disruptions.
Suspiciously smooth, zero-problem narratives from references are also a risk marker. Serious EMS operations that handle monsoons, political strikes, tech downtime, or cab shortages will have had issues. A credible reference can explain specific failures and how business continuity plans, standby fleets, or dual command centers handled them. A lack of concrete examples often suggests under-reporting, weak observability, or immature governance.
On the commercial and data side, a key red flag is opacity around data portability and billing integrity. If references cannot confirm that they receive raw trip data, clear SLA-to-invoice linkage, and flexible billing models that match utilization and seat-fill, then attractive rates may mask hidden dead mileage, inconsistent application of tariffs, or vendor lock-in. Difficulty in exiting previous vendors or consolidating fragmented systems is another signal to probe harder.
To operationalize this in evaluation, buyers can use reference calls to test for:
- Specific, quantified answers on incident rates, OTP by timeband, fleet uptime, and customer satisfaction.
- Clear descriptions of daily command-center routines, alerts, routing changes during disruptions, and BCP activations.
- Evidence that HR, Transport, Finance, and Security teams trust the vendor’s data for audits, billing, and ESG reporting.
How can we ask for ‘similar customer’ references without pushing confidentiality limits, and what other proof should we accept if direct references aren’t possible?
B0526 Similar-customer references without confidentiality breach — In India corporate employee mobility services (EMS) vendor selection, what’s a fair way to ask for “people like us” references (industry, employee count, shift mix, and city footprint) without forcing vendors to breach confidentiality, and what alternative evidence should be accepted if direct references are restricted?
A fair approach is to ask EMS vendors for “people like us” evidence in anonymized, pattern-based form rather than named client lists, and to treat structured case data, audited KPIs, and governance artefacts as acceptable substitutes when direct references are restricted by NDAs. The goal is to validate fit on industry, scale, shift mix, and city footprint without pushing vendors to breach confidentiality or expose sensitive relationships.
A facility or transport head can anchor the ask around context and outcomes instead of logos. Buyers can specify the reference profile they care about. Buyers can define industry segment, employee count bands, shift windowing pattern, women-night-shift proportion, and city tier mix. Vendors can then respond with 2–4 anonymized scenarios that map clearly to those parameters. Vendors can include indicative ranges for fleet size, routes, OTP, safety incidents, and satisfaction scores rather than client names. This keeps evaluation focused on operational similarity and reliability.
Vendor confidentiality constraints are common in EMS because transport programs sit under high-sensitivity areas such as women’s safety, ESG disclosures, and hybrid-work policies. For high-risk categories like night-shift women’s transport, buyers should explicitly acknowledge NDAs. Buyers can offer to accept named references only after down-selection and execution of a mutual NDA. Buyers should avoid demanding open-ended “all clients” lists or copies of existing contracts because these typically violate vendor commitments and erode trust.
If direct named references are restricted, buyers can still insist on robust alternative evidence. Buyers can ask for redacted case studies that show industry, city and approximate scale, along with quantified KPIs such as OTP, incident rates, and seat-fill. Buyers can accept evidence of real deployments like EV transition case studies and monsoon-routing performance where OTP and customer satisfaction improvements are stated. Buyers should value structured program evidence over logo slides.
Operational governance artefacts can often substitute for live reference calls. Buyers can request standard operating procedures for night-shift routing, women-safety protocols, complaint escalation matrices, and business continuity plans. Buyers can ask to see how command center operations are structured, including real-time alerting (geofence, overspeed, device tamper) and escalation workflows. These documents show whether the vendor has a repeatable model or is improvising.
For scale and footprint validation, buyers can accept maps and dashboards showing total vehicles, states covered, and city types served. Vendors can show EV and ICE fleet presence by region and live dashboards summarizing trips, employees served, and revenue spread, with client names redacted. This lets the facility head test whether the vendor has depth in similar cities and timebands without naming specific accounts.
Certifications and awards provide independent signals of maturity. Buyers can consider ISO quality and safety certifications such as ISO 9001 and ISO 45001 as baseline hygiene for EMS vendors. Recognition such as “leading SME” listings or successful IPO listing can reinforce that the provider is financially stable and audited. These credentials won’t replace client references but they do reduce downside risk.
ESG and sustainability validation for mobility and EV programs can also be reference-like. Buyers can ask for emission dashboards or sustainability collateral showing CO₂ reductions, EV kilometers logged, and number of electric rides completed. Vendors can share carbon reduction calculations that compare ICE versus EV emissions per 100 km or gCO₂ per ride. This is particularly relevant if the buyer’s EMS scope includes EV adoption and Scope 3 reporting.
To approximate “people like us” without a name, buyers can define what evidence they need in advance. Buyers can list minimum expectations for shift complexity, such as multi-window operations, high night-shift density, monsoon or festival disruption experience, and women-centric safety protocols. Vendors can respond with specific examples where they achieved 98% on-time arrival in severe weather or delivered 15% employee satisfaction improvements on late-night routes. This keeps the conversation about operational resemblance.
When buyers do require direct reference conversations, it is fair to limit these to late-stage evaluation. Buyers can specify that they expect 1–2 reference clients after shortlisting and signing a mutual NDA. Buyers can offer to keep questions focused on vendor behavior, outage handling, and governance responsiveness rather than commercial terms. This reduces the peer client’s risk of sharing sensitive information and respects the vendor’s relationship.
As alternatives or complements to references, buyers can lean on observable customer signals. Buyers can review curated client rosters and testimonials that have been explicitly approved for sharing, such as letters praising punctuality, responsiveness during crises, or EV project delivery. Buyers can also weigh satisfaction survey metrics that show high transport user satisfaction percentages across existing EMS programs.
For control-room oriented stakeholders, live demonstrations of tooling can partially replace references. Buyers can request a guided walkthrough of the vendor’s transport command center screens, alert supervision system, compliance dashboards, and SOS response console. Buyers can ask vendors to replay anonymized real incidents and show detection, escalation, and closure timelines. This helps test whether the vendor’s “2 a.m. behavior” matches their slideware.
In procurement documentation, buyers can codify these expectations to avoid ad-hoc pressure on vendors. RFPs can include a section for “Comparable Program Evidence” that allows anonymized case summaries, redacted dashboards, and KPIs as primary proof, and “Named References Post-Shortlist” as optional and NDA-bound. This sets a transparent, fair bar for all EMS bidders and reduces the temptation to favor vendors willing to bend confidentiality rules.
For facility and transport heads, the practical test is whether the evidence reduces operational uncertainty. If anonymized cases, governance artefacts, dashboards, and third-party credentials collectively answer predictable questions about OTP, escalation handling, women’s safety, EV robustness, and business continuity, then lack of a public logo should not automatically disqualify a vendor. The emphasis should remain on verifiable patterns of performance that match the buyer’s own risk profile and shift mix.
When we speak to references, what should we ask to validate the real 2 a.m. support—escalations, no-shows, GPS/app issues, and SLA handling?
B0530 Reference checks for 2 a.m. ops — In India enterprise employee transport (EMS) with a centralized command center/NOC model, what should an Operations leader ask customer references to confirm about '2 a.m. reality'—including escalation responsiveness, driver no-show handling, app/GPS outages, and whether the vendor actually meets exception-management SLAs by timeband?
In enterprise EMS with a NOC/command-center model, an Operations leader should probe customer references with precise, time-bound questions that expose how the vendor performs during real disruptions at night. These questions should focus on escalation responsiveness, exception handling, and whether timeband-specific SLAs are met under stress rather than on average.
For escalation responsiveness, references should be asked who actually answers the phone at 1–3 a.m. and at what level. They should be asked what the guaranteed response and resolution times are by timeband and whether the NOC follows a documented escalation matrix for night shifts. References should be asked for a real incident example where a serious issue occurred at night and how long it took for first response, decisioning, and closure, along with whether the client was kept informed in real time.
For driver no-shows and last‑minute drops, references should be asked what percentage of night-shift trips typically require backup vehicles and how fast those backups are dispatched. They should be asked whether there is a contracted buffer fleet and standby drivers per shift window and whether the vendor shares exception logs that show each no‑show, its root cause, and closure time. The Operations leader should confirm if women‑only or critical routes have stricter no‑show and backup rules and whether those are consistently honoured.
For app and GPS outages, references should be asked what standard operating procedures exist for manual fallback when apps or GPS fail during a shift. They should be asked how often such outages have happened in the last year and how many trips were moved to manual mode without losing trip-level auditability. It is important to confirm whether the vendor’s command center can reroute, track via alternate telematics, and close trips with OTP or paper logs when the primary stack is down.
For exception‑management SLAs by timeband, references should be asked if the vendor reports SLA compliance split by day, evening, and night, not just as a single blended number. They should be asked to share recent examples where OTP% or incident‑closure SLAs were missed in a specific night window and how the vendor reported and corrected those misses. The Operations leader should also confirm whether the provider runs a centralized command center with defined night-shift staffing, alert supervision, and business continuity playbooks for strikes, weather events, or fleet shortages.
To assess whether this “2 a.m. reality” is consistently managed, Operations leaders can ask references the following focused questions:
- “When something breaks at 2 a.m., who calls you first: your employees or the vendor’s command center?”
- “In the last serious night‑shift incident, how long did it take from alert to a concrete action on ground?”
- “How many times in the last quarter did you have to bypass the vendor and manually intervene to save a shift?”
- “Do you receive exception reports with timestamps that match what your employees experienced on the ground?”
During the RFP, what references and proof should Procurement insist on—by city and shift timing—so we don’t pick a vendor that over-promises and under-delivers?
B0535 Procurement proof to prevent overpromising — In India Employee Mobility Services (EMS) procurement for a multi-vendor commute ecosystem, what reference types and proof points should a Procurement Head require (by city/timeband) to reduce the risk of awarding to a vendor that over-promises during the RFP and under-delivers after go-live?
For Employee Mobility Services in India, a Procurement Head should insist on city- and timeband-specific references plus hard, auditable proof points from live operations. Vendors who have real, governed EMS programs can evidence reliability, safety, and cost control with traceable data, not just testimonials.
Procurement leaders reduce RFP over-promise risk when they demand references that mirror their own operating reality. This means references by metro or tier-2 city, by night vs day timeband, by shift pattern, and by multi-vendor coordination complexity. References work best when they are backed by verifiable KPIs on on-time performance, safety incidents, fleet uptime, and complaint closure rather than generic satisfaction statements.
Stronger assurance comes from asking for proof of centralized command-center operations, documented business continuity plans, and compliance automation. These elements demonstrate that EMS delivery is governed by SOPs and continuous monitoring instead of ad-hoc fixes. Procurement mitigates under-delivery risk further when it requires evidence of dynamic routing performance in adverse conditions such as heavy monsoon traffic or night shifts for women employees.
Key reference and proof-point categories a Procurement Head should require include:
- City and timeband references with named client contacts and tenure that match the buyer’s locations and shift windows.
- Documented performance KPIs for those references, including on-time performance, fleet uptime, safety incidents, and complaint closure SLAs.
- Evidence of command-center capability such as screenshots of live dashboards, alert supervision systems, and escalation matrices.
- Compliance and safety frameworks covering driver vetting, women-centric night routing, and audit trail integrity.
- Business continuity and contingency playbooks used for cab shortages, technology failures, and political or weather disruptions.
- EV and sustainability references, where relevant, including carbon reduction metrics and EV uptime in similar routes and shifts.
- Governance and account-management models that show how multi-site, multi-vendor EMS is controlled through structured committees and reporting.
For long-term rentals, what proof should we ask for to validate uptime—maintenance adherence, replacement turnaround, and monthly availability—before signing a long contract?
B0544 LTR uptime proof before lock-in — In India Long-Term Rental (LTR) corporate fleets, what proof should an Operations manager request to validate uptime claims—such as preventive maintenance adherence, replacement vehicle turnaround history, and real availability by month—before committing to a 12–36 month contract?
In India Long-Term Rental (LTR) corporate fleets, an Operations manager should insist on hard, time-stamped evidence for uptime, not just assurances. The most useful proof combines historical uptime data, preventive-maintenance logs, and documented replacement-vehicle performance, broken down month by month and site by site.
Vendors should provide a historical uptime track record for comparable LTR contracts. This evidence should show monthly fleet uptime percentages, exception counts, and how often vehicles were off-road versus in use, ideally aligned to SLA definitions in similar industries or shift patterns. This helps an Operations manager see if the claimed uptime is repeatable under real working conditions, not just a target.
Preventive maintenance adherence must be evidenced through service schedules and closed-job logs. Operations managers should ask for samples of pre-induction vehicle compliance checks, periodic mechanical and electrical assessments, and audit reports that show how often preventive maintenance was done on time. Documents such as fleet compliance and induction checklists, safety inspection checklists, and vehicle deployment and quality assurance records are useful, because they demonstrate that the vendor runs a disciplined lifecycle-governance process instead of reactive repairs.
Replacement-vehicle turnaround performance should be visible in historical incident and fleet-deployment reports. A manager should request data on how many breakdowns or unplanned outages occurred, how quickly replacement vehicles were dispatched, and whether SLAs for continuity were met. Business continuity plans, buffer-fleet policies, and escalation matrices give further proof that the vendor can sustain availability during cab shortages, political strikes, technology failures, or weather events.
Finally, Operations managers should ask for dashboard screenshots or indicative management reports that reflect real availability by month. These should show active vs. standby vehicles, utilization, and on-time performance for long-tenure deployments, so they can tie uptime claims directly to operational reality rather than marketing statements.
When shortlisting, how much should we rely on references from companies like us—same size and night-shift mix—versus generic case studies, so the decision is defensible?
B0545 Weighting 'people like us' references — In India corporate Employee Mobility Services (EMS) vendor shortlisting, how much weight should a CHRO place on 'people like us' references (same industry, similar employee count, similar night-shift mix) versus generalized case studies to reduce personal career risk if the decision is challenged internally?
A CHRO in India shortlisting Employee Mobility Services (EMS) vendors should place significantly higher weight on “people like us” references than on generalized case studies when thinking about personal career risk. Peer references from the same industry, with similar employee scale and night-shift exposure, give far stronger protection if a decision is later challenged by leadership, auditors, or after an incident.
Peer references reduce risk because they are context-matched. A transport program that works for a small, day-shift office may fail in a large, 24x7, female-heavy workforce. In practice, CHROs are judged on whether they chose a vendor proven in comparable hybrid-work, women-safety, and SLA-governed environments. References from organizations with similar shift patterns, geography, and regulatory exposure give defensible evidence that “this model works under conditions like ours.”
Generic case studies still matter, but mainly as secondary proof. They demonstrate that the EMS provider can run centralized command centers, automate routing and rostering, manage compliance, and sustain high on-time performance. They are useful for Procurement, Finance, and IT to understand maturity and technology depth. They are weaker, however, when a board member or internal auditor asks, “Who else exactly like us is using this?”
A practical weighting approach for a CHRO focused on personal career safety is:
- Prioritize 60–70% on “people like us” references that match industry, headcount band, night-shift/women-safety profile, and city mix.
- Rely 30–40% on generalized case studies that show breadth, scale, EV/ESG capability, and command-center led operations.
This mix improves internal defensibility. It lets the CHRO say, “We selected a vendor already trusted in comparable environments, and we checked that their broader playbook, governance, and technology are robust,” which is the posture most aligned with reducing personal career risk.
What financial stability questions should we ask so we don’t end up stranded mid-rollout with an unsupported platform and failing SLAs?
B0546 Vendor viability and runway checks — In India corporate ground transportation sourcing (EMS/CRD), what due-diligence questions should Procurement ask about the vendor’s financial stability and support runway—so the company isn’t stranded mid-rollout with unsupported apps and broken SLAs?
Procurement teams in India evaluating EMS/CRD vendors should treat financial stability and support runway as hard gating criteria. The most useful questions convert “we’ll be fine” assurances into verifiable signals about balance sheet strength, funding visibility, and the ability to keep platforms and fleets supported across multi-year SLAs.
Key questions should probe three areas. The first area is financial health and runway. The second area is support capacity and continuity for operations, apps, and command-center coverage. The third area is contractual and governance safeguards if things start to deteriorate. Each area should be tested with specific documents, data points, and escalation scenarios rather than verbal comfort.
On financial health and runway, Procurement should ask for:
- Audited financials for the last 3 years, including revenue from EMS/CRD versus other business lines.
- Breakdown of client concentration to understand dependence on a few anchor accounts.
- Disclosure of current debt obligations, major covenants, and any recent restructurings.
- Forward visibility of committed funding or internal capex to maintain fleets, EV infrastructure, and technology platforms over the contract term.
On support capacity and continuity, Procurement should ask for:
- Documented 24x7 support model, including team size, roles, and command-center coverage by time band.
- Historical uptime and SLA performance for apps, routing engines, and NOC operations.
- Business continuity plans covering technology failures, app downtime, and sudden demand spikes during rollout.
- Evidence of previous large-scale implementations and how support was scaled across cities and vendors.
On contractual safeguards, Procurement should ask for:
- Clear step-in and exit clauses if the vendor misses financial or operational covenants.
- Data ownership and portability terms to avoid being locked into a failing platform.
- Performance guarantees, including any bank guarantees aligned to critical SLAs.
- Governance cadence for reviewing financial and operational health, such as quarterly business reviews with shared KPIs.
How do we ensure the references aren’t curated—can we speak to customers in the same cities/shifts and see KPI distributions instead of best-month snapshots?
B0550 Detecting curated references and cherry-picking — In India corporate ground transportation (EMS/CRD), what proof should a buyer request to confirm customer references are comparable and not curated—such as allowing reference calls for specific cities/timebands and sharing anonymized KPI distributions rather than best-month snapshots?
In Indian corporate ground transportation, a serious buyer should insist on reference proof that is cross-checked, time-bound, and sample-based, not just curated success stories or a single best month. The buyer should push vendors to expose how they perform across cities, timebands, and service types (EMS/CRD), and to back this with anonymized KPI distributions and live-like references.
1. Reference Scope: Match Your Reality, Not Their Best Site
Buyers should request references that mirror their own operating context. They should ask for contacts where the vendor runs similar employee mobility services or corporate car rental models, including shift-based EMS, airport/intercity CRD, and event or project commute services. The most reliable validation comes from references who are using comparable SLA-driven operations and centralized command-and-control models in India.
2. City- and Timeband-Specific Reference Calls
Buyers should request reference calls filtered by critical risk zones. They should ask to speak with customers where the vendor runs night-shift EMS in similar Indian cities, where women-safety protocols, escort rules, and hybrid-work variability stress the system. This is especially important for high-traffic or adverse-weather locations, because these environments test routing, command-center responsiveness, and business continuity plans.
3. Anonymized KPI Distributions, Not Highlight Reels
A robust check is to demand KPI distributions over at least one to two quarters. Buyers should ask for anonymized data that covers on-time performance, exception-closure times, incident rates, and fleet uptime across multiple accounts, rather than a single top-performing site. Distributions give a more realistic view of median performance, tail risk, and the impact of peak loads or disruptions on daily reliability.
4. Evidence of Command-Center and BCP Behavior Under Stress
Buyers should validate how the vendor performs when things go wrong. They should request references and supporting material that describe vendor behavior during adverse events such as monsoon disruptions, political strikes, or technology failures. This includes evidence of dynamic route recalibration, centralized command-center escalation, and business continuity actions that kept EMS and CRD operations stable.
5. Cross-Function Reference Validation (HR, Transport, Finance)
A strong proof pattern is to speak with multiple stakeholders at the same reference client. Buyers should ask for separate calls with the client’s HR or CHRO team, Facility or Transport Head, and Finance or Procurement owner. This triangulation helps confirm that safety, daily reliability, and billing control are all performing to expectation, rather than relying on a single enthusiastic sponsor.