How to stabilize shift-commute reliability when the control room is under pressure
You run the EMS control room on every shift, facing driver shortages, weather disruptions, and sudden route changes. This playbook translates on-ground realities into a repeatable, SOP-grade framework you can implement today to reduce firefighting, protect drivers, and keep leadership calm. It’s not a sales pitch; it’s a practical guardrail system. Five operational lenses turn feedback loops, escalation hygiene, and cross-functional governance into concrete actions that deliver stable commutes and auditable outcomes.
Is your operation showing these patterns?
- Chronic late pickups and missed routes despite available fleet
- Grievance tickets sit open with no visible action
- Night shifts overwhelmed by back-to-back escalations
- Driver no-shows or last-minute substitutions spike during peak
- Conflicting ownership between HR, Facilities, and vendors
Operational Framework & FAQ
end-to-end grievance governance and escalation hygiene
Establish clear ownership, end-to-end SLA definitions, and a closed-loop process so grievances are acknowledged, investigated, and resolved with visible follow-up.
For our shift commute program, what does it really mean to link commute experience to EVP and employer brand, and how do HR teams usually measure if transport is impacting retention and hiring?
B0374 Define commute UX for EVP — In India-based Employee Mobility Services (EMS) for shift commute, what does “commute experience tied to EVP and employer brand” actually mean in operational terms, and how do CHROs typically measure whether daily transport is helping or hurting retention and hiring outcomes?
In India-based Employee Mobility Services, “commute experience tied to EVP and employer brand” means that daily pickup–drop performance, safety, and reliability are treated as part of the organization’s value proposition to employees rather than as a background facility cost. It means HR considers the daily commute as a core element of well-being, inclusion, and trust, on par with policy, pay, and workplace culture.
In operational terms, this linkage shows up as HR and Transport embedding commute into employee experience programs. This includes codified night-shift women-safety protocols, predictable on-time performance for shift start, audit-ready incident handling, and integration of the EMS platform with HRMS and attendance. A commute program is considered EVP-aligned when it quietly reduces friction in getting to work, when managers stop complaining about transport-related late logins, and when safety credibility withstands internal and external scrutiny.
CHROs typically measure whether EMS is helping or hurting retention and hiring using a mix of hard and soft signals. They track attendance stability and late-login patterns for shift staff and correlate these with transport exceptions. They monitor complaint volumes, escalation patterns, and closure SLAs coming from commute channels. They look at commute-specific satisfaction or NPS in transport user surveys and compare these with overall employee satisfaction benchmarks. They also monitor attrition and offer-decline reasons where commuting difficulty, safety fear, or unreliable shifts are explicitly cited.
More mature CHROs push for cross-linking these measures. They relate commute NPS to attendance and attrition in high-risk populations such as women on night shifts or critical operations teams. They also use incident logs and audit trails from centralized command centers as proof that commute is not a hidden risk to EVP or employer brand.
For women’s night shifts, why do feedback and grievance SLAs matter so much, and what usually goes wrong when they’re not strong?
B0375 Why grievance SLAs affect brand — In corporate ground transportation in India, especially women’s night-shift commute under Employee Mobility Services (EMS), why do feedback loops and grievance SLAs matter for employer brand risk, and what typically happens inside organizations when those mechanisms are weak?
In corporate employee mobility in India, feedback loops and grievance SLAs matter because they convert individual commute complaints into controlled, traceable issues before they become employer-brand incidents. When feedback and grievances are captured, triaged, and closed within defined SLAs, organizations reduce repeat safety lapses, demonstrate duty of care, and protect HR and leadership from “you did nothing” narratives after a night‑shift event.
In Employee Mobility Services, women’s night-shift commutes sit at the intersection of HR, Security/EHS, Transport and ESG expectations. Without structured feedback channels linked to trip data and escalation matrices, small signals such as frequent late pickups, unsafe routing, or driver behaviour never crystallize into actionable risk intelligence. A common failure pattern is that complaints stay informal, move through WhatsApp or verbal channels, and are not reconciled with route logs, driver compliance records, or vendor SLAs.
When mechanisms are weak, several predictable internal dynamics follow. HR becomes the de facto complaint desk without the data to answer, “How often does this happen?” or “What changed after the last incident?”. The Facility/Transport Head is forced into reactive firefighting because issues only surface once employees escalate to managers or social channels. Procurement and Finance lose confidence in vendors because incident noise is high but structured evidence is thin.
Over time, women employees perceive that safety protocols are “on paper only”, which erodes Commute Experience Index scores and can impact attendance, retention, and diversity goals. One serious night-shift incident with no clear grievance trail or closure record can rapidly escalate to a reputational risk, where leadership, auditors, and sometimes regulators question not just the event, but the maturity of the organization’s overall EMS governance.
How do I explain escalation hygiene and communication playbooks to leadership who thinks commute complaints are just noise?
B0376 Explain escalation hygiene simply — In India corporate Employee Mobility Services (EMS), how should a facilities/transport head explain “escalation hygiene” and “communication playbooks” to a skeptical business leader who thinks commute complaints are just noise?
Escalation hygiene and communication playbooks turn “commute complaints” from noisy distractions into an early‑warning system that protects shifts, safety, and leadership time. They define what gets escalated, to whom, in what format, and by when, so that only real risks reach leaders and most issues are contained at the operations layer.
Escalation hygiene is about signal vs noise control. It sets clear thresholds for what stays in the command room and what becomes a formal escalation. It also enforces disciplined logging, closure times, and root-cause tracking. Without this, genuine risks hide inside a pile of ad‑hoc emails, WhatsApp messages, and angry calls, and leadership only sees problems when they have already hit production, HR, or social media.
Communication playbooks are pre-agreed SOPs for different scenarios. They define who informs whom when there is a delay cluster, a safety deviation, a night‑shift breakdown, or a tech outage. They also prescribe standard templates for messages to employees, HR, security, and leadership. This reduces 2 a.m. confusion, avoids contradictory messages from different departments, and keeps the narrative fact-based and audit-ready.
For a skeptical business leader, the practical framing is simple. Clean escalation hygiene reduces the number of issues that reach them. It also shortens recovery time when something does go wrong, because transport, HR, security, and vendors follow the same playbook instead of improvising. Over time, the data from these controlled escalations feeds into route optimization, vendor governance, and EV/ICE fleet decisions, which directly improves OTP, reduces cost per trip, and lowers safety and reputational risk.
In practice, an effective facilities/transport head typically anchors this discussion around three outcomes:
• Fewer surprise escalations to leadership because issues are filtered and closed at the right level.
• Faster, calmer recovery during disruptions because every stakeholder knows their role and message.
• Better decisions on vendors, routes, and fleet mix because escalations are structured data, not anecdotes.
What early signals tell us transport dissatisfaction is turning into an employer brand problem, not just an ops issue?
B0377 Spot early employer brand risk — In India-based employee transport (EMS) for large shift workforces, what are the most reliable early warning signals that commute dissatisfaction is becoming an employer brand issue rather than a routine operations issue?
In India-based employee transport for large shift workforces, commute dissatisfaction becomes an employer brand issue when signals move from isolated trip complaints to patterns that show loss of trust, safety anxiety, and reputational spill-over outside the transport function. The strongest early warnings are sustained negative sentiment from employees, linkage to attendance or attrition patterns, and safety-related fear narratives, especially from women or night-shift staff.
Repeated low-level OTP issues usually stay as an operations problem. It starts to affect employer brand when employees begin framing the commute as “unfair” or “unsafe” rather than “late.” A common failure mode is when Facility/Transport teams keep firefighting trip-level breakdowns, while HR starts seeing anonymous comments on internal forums and town halls describing the commute as a reason not to join certain shifts, teams, or locations. That shift in language is a leading indicator that employer value proposition is being questioned.
A practical pattern is when commute complaints begin to correlate with HR metrics. These include an uptick in sick leaves on early-morning or late-night shifts, higher no-show rates on routes already flagged for poor OTP, or early resignations where “transport” appears in exit interviews. When these effects cluster around key diversity groups, such as women on night shifts, the risk of reputational damage increases sharply.
Another early marker is when CHROs or HRBPs are pulled into what used to be routine routing calls. If line managers escalate transport issues directly to HR leadership, or HR is asked for “what is HR doing about this?” after a near-miss incident, the issue is no longer seen as a back-end logistics problem. It has crossed into perceived duty-of-care and culture.
Transport and Facility Heads can treat the following as escalation triggers that signal an employer brand risk, not just an EMS efficiency gap:
- Commute shows up repeatedly in pulse surveys, town halls, or anonymous forums as a top 2–3 negative theme.
- Women or night-shift employees begin using words like “unsafe,” “scared,” or “no one listens” in feedback, not just “late” or “uncomfortable.”
- Managers report they are adjusting project plans, shift patterns, or return-to-office adoption because “transport will not support it.”
- Recruiters and HR hear candidates or new joiners say they have “heard” about bad transport from friends, ex-employees, or social media.
- Security/EHS or Legal asks for detailed commute data and SOP proof after an incident or social media post, even if nothing major has yet occurred.
Most organizations underestimate how quickly EMS dissatisfaction can leak into employer brand once it touches safety, perceived fairness of shift policies, or hybrid-work flexibility. Once commute is part of the narrative about “how this company treats people,” the brand impact is already in motion, and recovery requires visible governance changes, not just routing tweaks.
How can we set up a feedback loop employees trust—especially for women and night shifts—without overwhelming the ops team with too many low-quality complaints?
B0378 Design trusted feedback without overload — In Indian corporate ground transportation for Employee Mobility Services (EMS), how do HR and transport teams practically design a feedback loop that employees trust (especially women and night shifts) without creating a flood of low-signal tickets that burns out the control room?
HR and transport teams in Indian Employee Mobility Services build a trusted, low-noise feedback loop by separating “safety-critical alerts” from “experience feedback” and by linking every channel to clear SOPs, not open-ended complaint boxes.
A trusted loop starts with simple, predictable channels. Most organizations pair an in-app SOS and panic feature for emergencies with structured post-trip feedback in rider apps and periodic user satisfaction surveys. Women and night-shift users trust these tools when they see visible safeguards such as verified chauffeurs, strict driver compliance and induction processes, women-centric safety protocols, real-time tracking, and a 24/7 command or transport control centre with clear escalation matrices and business continuity plans.
Noise is controlled by designing structured inputs instead of free-form complaints. Post-trip forms use short rating scales tied to specific EMS KPIs like on-time performance, driver behaviour, and safety perception, while only high-severity triggers, like SOS, escort violations, or route deviations, open tickets in the Alert Supervision System and command centre. Data-driven insights dashboards, indicative management reports, and user satisfaction index frameworks help aggregate trends so HR can act on patterns rather than individual low-signal tickets.
Operations avoid burnout by routing alerts through a centralized command centre with role-based escalation, predefined on-time service delivery plans, and defined safety and security SOPs. HR uses periodic floor connects, women-safety briefings, and transport policy communication to show employees how feedback leads to action. This creates credibility without overwhelming the control room, because every channel has a clear purpose, severity band, owner, and closure SLA.
How do we set grievance SLAs that actually reduce attrition, without overpromising something ops and procurement can’t deliver across sites and vendors?
B0379 Set grievance SLAs that hold — In India Employee Mobility Services (EMS) programs, how do you set grievance SLAs that reduce attrition risk without setting unrealistic expectations that procurement and operations can’t sustain across multiple sites and vendors?
In Indian Employee Mobility Services programs, grievance SLAs reduce attrition risk when they are tied to incident severity, data-backed baselines, and command-center observability rather than a single aggressive number applied everywhere. Grievance SLAs become sustainable when they are aligned with on-ground constraints, multi-vendor capabilities, and clear escalation paths that work the same way on every night shift.
A common failure mode is promising blanket “instant response” to HR to calm safety fears. This usually breaks in tier‑2 or high-traffic clusters where vendors, GPS, or drivers cannot support it. Most organizations instead standardize a small set of SLA bands. These bands are driven by risk and impact severity, for example critical safety incidents, OTP-related service failures, and routine complaints on behavior or billing. The EMS command center then maps each band to a measurable closure target and an escalation matrix. Centralized NOC tooling, ticketing, and audit trails allow HR to demonstrate control and pattern-level improvements, while Transport and vendors work within realistic response windows.
Trade-offs are easier to manage if the SLA design separates three dimensions. First is acknowledgment time, which calms employees and HR by proving someone is listening. Second is initial action time, which covers steps like arranging alternate cabs or contacting the driver. Third is final closure time, where root cause and preventive actions are documented for Procurement, Finance, and Security. Organizations usually tighten SLAs only for high-risk categories that affect women’s safety, night-shift routing, or repeated OTP failures, while keeping more moderate targets for low-risk issues that do not directly drive attrition.
A practical approach is to pilot grievance SLAs on a few high-volume routes or sites, measure real response/closure performance by vendor and timeband, and then codify only those SLA levels that the integrated vendor ecosystem can sustain. Centralized command-center governance, outcome-based contracts, and periodic QBRs help align Procurement, Transport, and vendors on what is realistically deliverable across regions without overpromising to HR and employees.
images:


What should a solid comms playbook cover for late cabs, vehicle changes, route deviations, or driver no-shows, and how do we stop these from turning into HR escalations?
B0380 Comms playbook for failure modes — In India corporate employee transport (EMS), what does a realistic communication playbook look like for common failure modes (late cab, vehicle change, route deviation, driver no-show), and how do strong teams prevent those incidents from becoming HR escalations?
Communication playbook for common EMS failures in India
Strong employee transport teams treat late cabs, vehicle changes, route deviations, and driver no‑shows as expected scenarios with scripted responses rather than surprises. The objective is to detect early in the command center, communicate before the employee complains, and give HR audit-ready evidence that the issue was contained.
1. Late cab (ETA slip)
Realistic practice is to run ETA monitoring in the command center against OTP thresholds and trigger alerts when a cab will miss pickup by a defined margin.
- 0–5 minutes delay. Notify employee and supervisor via app/SMS with revised ETA and reason. Command center acknowledges in the trip log.
- 5–15 minutes delay. Command center calls the driver to confirm cause, updates roster, and informs employee plus shift lead. Offer alternative (car swap or backup cab) if risk to shift start is high.
- >15 minutes delay. Dispatch backup vehicle and clearly mark “vendor delay” in the system for billing/penalty and MIS.
Teams prevent HR escalations by sending proactive notifications, logging root cause (traffic, breakdown, gate clearance), and showing in MIS that delays are within SLA bands with trend actions.
2. Vehicle change (last‑minute swap)
Vehicle swaps are scripted as a managed event in fleet operations rather than ad‑hoc driver decisions.
- Command center approves the swap and pushes updated vehicle and driver details to employee app/SMS before arrival.
- Compliance desk verifies new vehicle documents and driver credentials in the centralized system before release.
- Security/EHS is notified if night shift or women passengers are involved, to preserve escort and women‑safety rules.
HR escalation is avoided when employees never see an “unknown car and unknown driver” at the gate; they see a pre‑notified change with verified details and SOS coverage.
3. Route deviation
Route deviation is handled as a geo‑fence and route‑adherence issue from the command center, not as a rider dispute later.
- Telematics generates immediate alerts for off‑route travel beyond a defined buffer.
- Command center calls the driver to confirm reason and realigns the route if it is a wrong turn or diversion.
- For sensitive cases (solo woman, night shift, unsafe areas), command center calls the employee to reassure and keep the line open until back on approved route.
Strong teams document deviation, driver explanation, and closure in an incident log so Security/EHS and HR can reconstruct events without guesswork.
4. Driver no‑show / last‑minute drop
Driver no‑show is treated as a predictable staffing risk with buffers built into rostering and vendor governance.
- Check‑in SOP requires drivers to confirm duty readiness well before first pickup; non‑response triggers an early alert.
- Standby vehicles or partner vendors are pre‑tagged by time‑band and zone for immediate substitution.
- Employee communication states the replacement plan and revised ETA, not just the problem.
Teams reduce HR noise by proving that no‑shows were covered by buffer capacity, low impact on OTP, and vendor penalties where patterns emerge.
How strong teams keep failures away from HR
High‑maturity EMS operations blend command‑center monitoring, SOPs, and clear ownership so day‑to‑day failures do not become reputational events for HR.
- Early detection in command center. 24x7 dashboards for ETA, route adherence, driver check‑in, and geo‑fence alerts ensure operations see problems before employees do.
- Pre‑approved playbooks. For each failure mode, there is a written SOP covering who calls whom, time limits, fallback options, and when to escalate.
- Single source of truth. Trip logs, alerts, calls, and resolutions are captured in one system so HR can answer “what happened?” with data, not anecdotes.
- Vendor and driver governance. Repeat offenders trigger retraining, roster changes, or vendor penalties so chronic issues reduce over time.
- Transparent MIS to HR. Monthly reports show OTP, exception counts, causes, and corrective actions so HR can show leadership that commute risks are understood and under control.
In practice, failures still happen, but controlled communication plus audit‑grade evidence prevents them from turning into HR‑level escalations or trust crises.
Where do HR and Security/EHS usually disagree on women-safety experience for night shifts, and what governance setup reduces finger-pointing after incidents or complaint spikes?
B0381 Resolve HR vs EHS women-safety — In India-based EMS for night shifts, how do EHS/security leaders and HR leaders typically disagree on “what good looks like” for women-safety experience, and what governance mechanism reduces blame-shifting after an incident or complaint spike?
In India-based employee mobility for night shifts, HR leaders usually define “good” women-safety experience as low visible complaints and high perceived comfort, while EHS or security leaders define “good” as zero serious incidents with audit-ready evidence and full policy compliance on every trip.
HR leaders focus on employee sentiment, trust, and employer brand. HR teams track whether women feel safe using the commute, whether escalations reach leadership, and whether commute issues affect attendance, attrition, or internal forums. HR often prioritizes flexible exceptions, empathetic handling of complaints, and frictionless app experience for booking, tracking, and SOS use.
EHS or security leaders focus on enforcement, traceability, and regulatory defence. EHS teams prioritize escort rules adherence, correct routing for night drops, rest-hour norms for chauffeurs, and integrity of trip logs and GPS data. A common disagreement arises when HR pushes for operational flexibility to keep employees happy, while EHS insists that non-negotiable protocols must apply even if they are inconvenient.
A governance mechanism that reduces blame-shifting is a joint, evidence-based incident governance framework anchored in a shared dashboard and command-center workflow. This framework links HR, transport operations, and security around the same trip ledger, alerts, and escalation matrix. It defines in advance the SOP for women-centric routing, SOS handling, escort deployment, and complaint closure SLAs, and it records every exception and response as an auditable trail.
Such a framework makes “what good looks like” explicit and measurable for both functions. It ties women-safety KPIs and complaint-closure performance into scheduled governance reviews rather than post-incident finger-pointing. It allows EHS to reconstruct what happened from tamper-evident logs, while giving HR clear data to respond to leadership and employees.
How can Finance verify that ‘better employee experience’ is real and not just complaints moving to another channel, and what evidence will hold up with auditors and the board?
B0382 Validate EX claims for CFO — In corporate ground transportation in India for Employee Mobility Services (EMS), how can a CFO tell whether “employee experience improvement” claims are real versus just shifting complaints to a different channel, and what evidence is usually credible in audit and board conversations?
The most reliable way for a CFO to judge “employee experience improvement” in Employee Mobility Services is to demand hard, reconciled operational and HR-linked metrics rather than relying on app ratings or anecdotal feedback. Credible evidence connects commute KPIs to attendance, attrition, and escalation patterns, and it remains traceable back to underlying trip and incident data.
Vendors often highlight app stars or one-off testimonials, but these can mask shifted complaints that move from calls to in-app chats. A stronger signal is a sustained reduction in complaint volume per 1,000 trips, faster complaint closure SLAs, and fewer transport-related escalations to HR or senior leadership. These numbers should be normalized by trip count and timeband and supported by clear SLA reports.
For audit and board conversations, the most defensible package usually includes three layers of proof. The first is operational reliability data such as OTP%, trip adherence, no‑show rates, and incident counts extracted from a governed trip ledger. The second is experience metrics like commute-specific satisfaction scores and grievance closure performance that can be cross-checked against HRMS data on late logins, shift adherence, or transport-linked attrition. The third is governance evidence such as QBR decks, route-adherence audits, safety-incident RCAs, and change logs showing how issues led to specific SOP or routing adjustments.
Signals that employee experience claims are weak include flat or rising HR complaints while app ratings improve, OTP gains achieved only by quietly relaxing SLAs, or dashboards that cannot export raw trip and incident data for Finance or Internal Audit to re-run calculations.
How can we measure complaint closure quality—not just speed—so HR doesn’t feel the vendor is gaming the SLA?
B0383 Measure closure quality vs speed — In India EMS programs for shift-based employee commute, what is a practical way to measure “complaint closure quality” (not just closure speed) so that HR doesn’t feel the vendor is gaming grievance SLAs?
Complaint closure quality in Indian EMS programs is best measured through a small, fixed post-closure checklist that is auditable, user-rated, and linked to HR-visible dashboards, not just “ticket closed within X hours.” A practical model combines a short employee feedback score, root-cause tagging, evidence of corrective action, and re-open rates into one quality index that Procurement can contract and HR can trust.
Vendors and transport teams can set a standard closure SOP where every resolved grievance carries four mandatory data points. These points are employee feedback on resolution (e.g., 1–5 rating in the employee app), a mandatory root-cause category selected by the command center, a recorded corrective action (such as driver coaching, route change, or vendor warning), and a lockout period where the ticket can be re-opened by the employee. Command centers already run alert supervision, daily shift briefings, and SOS workflows, so this checklist can be embedded into their existing dashboards.
HR and Facility Heads can then track a “Complaint Closure Quality Index” alongside regular SLA metrics. This index can be constructed from average post-resolution rating, percentage of tickets with clear root-cause tags and corrective actions, re-open rate within 72 hours, and recurrence of similar complaints on the same route, driver, or shift. Contracts can tie vendor incentives to this index, not only to closure time, so that vendors cannot game SLAs by closing tickets quickly without fixing underlying issues.
How do we make booking/boarding and roster changes easy for employees, without weakening safety and compliance steps—especially for women and night shifts?
B0384 Lower employee cognitive load safely — In India corporate Employee Mobility Services (EMS), how do transport operations teams reduce the cognitive load on employees (OTP, boarding, roster changes) while still enforcing necessary safety and compliance steps for women and night shifts?
In India EMS operations, transport teams reduce employee cognitive load by automating most commute tasks in apps and command centers while pushing safety and compliance checks “backstage” into SOPs, routing rules, and system workflows. The employee mostly sees simple, predictable boarding steps, while the complex safety logic runs in the background under NOC and vendor governance.
Operations teams standardize predictable patterns first. They align routes to shift windows, fix standard pick-up points, and stabilize vendor and fleet allocation so OTP becomes a default outcome, not a daily improvisation. Roster changes flow from HRMS into the transport platform, which recalculates routes and sends updated ETAs and vehicle details to employees automatically. This reduces the need for employees to call the transport desk for every change.
Safety and compliance for women and night shifts are enforced at the routing and policy level. Systems embed escort rules, women-first policies, and geo-fencing of high-risk zones into route approval logic. The driver app, IVMS, and GPS provide route adherence and tamper alerts to the command center. This allows employees to perform only minimal visible actions such as OTP-based trip verification or ride check-in, instead of remembering complex rules.
The command center runs 24x7 monitoring, exception alerts, and escalation matrices. This shifts cognitive burden from riders to trained operators who handle delays, app glitches, and re-routing during disruptions. Night-shift and women-safety SOPs are codified into driver credentialing, training, and periodic audits, so employees rely on a small set of consistent interactions rather than tracking compliance themselves.
images:

Why do employees push back on new transport apps/process changes, and how can HR and Facilities roll it out without hurting morale?
B0385 De-risk adoption and morale — In India corporate ground transportation (EMS), what are the most common reasons frontline employees resist new mobility apps or processes, and how do HR and facilities leaders de-risk adoption so it doesn’t turn into morale damage?
In Indian employee mobility programs, frontline staff usually resist new transport apps and processes when changes increase uncertainty, add friction to their day, or feel risky for safety or pay. HR and facilities leaders reduce this resistance when they treat transport change as an operational and trust issue, not just a tech rollout, and when they back every new rule with clear SOPs, visible safeguards, and rapid issue closure.
Most resistance patterns are predictable. Employees push back when app-based rostering replaces familiar manual lists without guaranteeing on-time pickups. They distrust systems that look like surveillance rather than safety, especially if GPS tracking and check-in rules are not explained. Shift workers resent complex logins, unstable apps, or workflows that require multiple confirmations for each ride. Women employees are particularly sensitive to any perceived downgrade in escort rules, driver quality, or night-routing safeguards. Hybrid workers resist rigid booking cut-offs that do not match real meeting overruns or last-minute shift changes.
HR and facility heads de-risk adoption when they move in three steps. They first run small pilots on critical shifts, track OTP, safety incidents, and complaint types, and only scale once new SOPs hold at peak load. They then integrate the mobility platform with HRMS and rosters so employees see fewer duplicate steps and less confusion about entitlement, routes, and timing. Finally, they keep a 24/7 command-center plus manual override option live for exceptions, so app glitches, GPS failures, or vendor gaps do not cascade into missed shifts or viral morale damage.
Effective leaders also front-load communication and proof. They explain what will change in boarding, cut-off times, SOS, and escalation routes, and they show how trip logs, GPS trails, and alert systems protect employees and HR in case of incidents. They train drivers and dispatchers first, because a good app with a confused chauffeur still feels unsafe on the ground. They give employees simple ways to report issues from within the app, and they commit to visible SLAs for complaint closure, especially for women-safety and night-shift trips.
To keep adoption from turning into a morale problem, HR and facilities should monitor a short set of signals in the first 90 days. These include OTP%, no-show disputes, spike in helpdesk calls, and commute-related complaints in internal forums. They should be ready to temporarily relax cut-offs, add standby vehicles, or selectively revert to manual routing on sensitive routes or time bands. When leadership is seen adjusting rules based on data and frontline feedback, employees tend to accept the new mobility system as a reliability upgrade rather than another control layer.
How do we stop the NOC and the HR helpdesk from becoming two different ‘truths’ for the same commute issue—causing duplicate tickets and messy escalations?
B0386 Avoid NOC vs HR truth split — In India EMS programs, how do you prevent the transport NOC and HR helpdesk from becoming competing ‘sources of truth’ for commute issues, leading to duplicate tickets, inconsistent employee communication, and blame during escalations?
Indian EMS programs prevent the transport NOC and HR helpdesk from becoming competing “sources of truth” by defining a single operational owner for commute incidents and then making all other teams consume that system’s data, not recreate it. The NOC usually owns live trip data and SLA governance, and HR becomes a policy and escalation consumer of that data rather than a parallel logging desk.
Most organizations treat the NOC or Transport Command Centre as the sole place where trips, GPS, SOS, alerts, and exceptions are created and closed. The employee apps, driver apps, and alert supervision systems feed into this one command layer, which then exposes dashboards, MIS, and incident status to HR, Security, and leadership. This preserves one trip ledger, one incident ID, and one audit trail for safety, OTP, and BCP reporting.
HR and EHS teams stay in the loop by getting role-based views and notifications from that same platform. They can view CO₂ dashboards, safety reports, and complaint closures without opening separate tickets or manually re-entering data. Centralized compliance management, women-centric safety protocols, and SOS panels all log back into the same command system, which avoids fragmented evidence and conflicting narratives during investigations.
Clear SOPs then define who logs what, where, and when. The NOC opens and owns every commute incident. HR logs only HR issues and references the NOC incident ID for commute-related complaints. Monthly engagement reviews, BCP drills, and user-satisfaction reports are generated from the same underlying data, which reduces duplicate work, inconsistent employee communication, and blame during escalations.
In the RFP, what should Procurement ask for so grievance SLAs, feedback ownership, and escalation paths are truly enforceable and not just ‘best effort’?
B0387 RFP terms for grievance enforceability — In India corporate Employee Mobility Services (EMS), what should procurement ask for in an RFP to ensure grievance SLAs, feedback loop ownership, and escalation paths are contractually enforceable—not just ‘best effort’ promises?
In India corporate Employee Mobility Services, procurement should hard-code grievance SLAs, ownership, and escalation paths into the RFP as measurable obligations with data, tooling, and penalties rather than as generic “support” statements. Procurement teams should require vendors to expose how complaints are captured, tracked, escalated, and closed through auditable workflows that link directly to trip data and command center operations.
Procurement should first define what counts as a grievance event. The RFP should ask vendors to classify events such as safety complaints, no-shows, rude behavior, GPS failures, app issues or late pickups as distinct categories with specific response and closure SLAs. The RFP should require a centralized command center or Transport Command Centre with 24/7 coverage that acts as the single owner of incoming grievances and that connects to driver apps, employee apps, and alert supervision systems.
The RFP should mandate a ticketing or alert supervision system. The system should generate a unique incident ID for each complaint. It should track time-to-acknowledge, time-to-resolve, and whether root-cause and corrective actions are documented. Procurement should insist that vendors provide periodic reports or a single-window dashboard that includes complaint volume, category breakdown, SLA compliance for closure, and repeat-issue detection.
Escalation paths must be defined as a matrix. The RFP should ask vendors to provide a named escalation mechanism and matrix that identifies each escalation tier, from shift executives to key account managers. It should require clear time thresholds for auto-escalation and explicit communication channels. It should require integration with the command center so that safety events, SOS triggers, and women-safety issues route into higher-priority queues and have shorter SLAs.
To make grievance SLAs enforceable, procurement should link them to commercial terms. The RFP should ask for service credits, penalties, or other remedies tied to breach of response and resolution SLAs. It should require that grievance handling, safety and compliance be covered under the broader governance, compliance, and BCP frameworks described in the vendor’s operational excellence and business continuity plans.
Procurement can strengthen ownership by demanding governance rhythms. The RFP should require that vendors participate in structured engagement models with leadership, senior management, and service delivery executors, where complaint analytics and user satisfaction indices are reviewed. It should require that grievance trends, women-safety escalations, and SOS logs are reviewed in periodic governance or QBR meetings, and that corrective action plans are documented and tracked.
How do Legal and HR balance DPDP privacy expectations with having enough evidence to investigate grievances—without employees feeling like they’re being watched?
B0388 Balance privacy with grievance evidence — In India corporate ground transportation for employee commute (EMS), how do legal and HR teams balance DPDP Act privacy expectations with the need for audit-ready evidence in grievance investigations, without employees feeling surveilled?
In Indian employee commute programs, legal and HR teams usually balance DPDP Act privacy expectations with audit-ready evidence by strictly limiting what they collect, who can see it, and when it is used. They position telemetry and trip data as a safety and compliance control with clear SOPs and consent, not as a continuous performance monitoring tool.
They start by defining a narrow data purpose for EMS platforms. Location, trip logs, and IVMS data are tagged as “safety, compliance, and SLA governance” data. This aligns with the EMS value proposition of duty of care, women’s safety compliance, and reliability KPIs. HR and legal teams then codify in policy that this data will not be used for routine performance ratings or unrelated HR actions. This separation of purpose is critical under the DPDP Act and reduces the perception of surveillance.
They also rely on role-based access and governance. Command centers, Security/EHS, and Transport teams get real-time and historical data for incident response and route adherence audits. HR, Internal Audit, and Legal get controlled, case-based access only when handling a grievance or compliance review. This supports the need for audit-ready evidence, chain-of-custody, and reconstructable trip histories while keeping everyday visibility low and controlled.
To prevent employees from feeling constantly watched, organizations standardize transparent communication and consent at onboarding and in mobility policies. The EMS program explains which data points are collected, how long they are retained, how they are protected, and in what scenarios they may be reviewed. This framing treats safety features like SOS, geo-fencing, and driver KYC as benefits, and it is reinforced via user-facing apps and employee FAQs rather than hidden fine print.
In investigations, they operate on a “minimum necessary evidence” principle. Legal and HR request specific trip logs, GPS snippets, and alert histories relevant to a grievance, rather than broad data pulls. This meets auditability expectations around incident response, women’s night-shift policies, and labor/OSH compliance. At the same time, it avoids open-ended analytics on individual behavior that would create DPDP and cultural risk.
Operationally, command centers and EMS platforms are designed for observability of the service, not surveillance of individuals. KPIs such as On-Time Performance, Trip Adherence Rate, and Incident Rate are monitored in aggregate. Individuals are de-identified in routine dashboards, with re-identification requiring an authorized workflow tied to a safety or compliance case. This preserves the ability to prove reliability and safety to leadership and auditors without normalizing personal tracking.
images:

During a pilot, how can we tell if the vendor will genuinely improve employee sentiment, not just deliver on-time trips?
B0389 Test sentiment impact in pilots — In India-based EMS for shift commute, what operational behaviors differentiate a vendor that actually improves employee sentiment from one that just runs vehicles on time, and how do facilities leaders test this during pilots?
In India-based employee mobility for shift commute, vendors that truly improve employee sentiment treat “on-time cabs” as baseline hygiene and change how employees experience safety, predictability, and communication every day. Vendors that only “run vehicles on time” focus on dispatch and ETAs. Vendors that improve sentiment embed safety, transparency, and early-alert behaviors into daily operations and command-center routines.
Vendors that lift sentiment institutionalize predictable communication. They send timely app or SMS updates when routing changes, capture feedback at trip closure, and close the loop on complaints within defined SLAs. Vendors that only dispatch cabs leave employees guessing when something slips, which amplifies anxiety on late-night and monsoon-affected shifts.
High-sentiment vendors run safety and compliance as live practices. They ensure escort / women-first routing, driver KYC and POSH training, SOS readiness, and geo-fenced alerts are continuously monitored from a 24x7 command center. Transactional vendors treat these as documents or checklists and cannot quickly reconstruct incidents or show audit-ready proof when questioned.
Facilities leaders can test these behaviors during pilots by designing scenarios rather than just measuring OTP. They can observe how the vendor handles a controlled disruption such as a temporary road closure, vehicle breakdown, or GPS outage during a night shift. They can track whether communication to riders is proactive, whether command-center staff follow escalation SOPs without prompting, and how quickly an alternate vehicle or route is arranged.
Facilities leaders can also monitor three pilot-period signals. They can track the volume and tone of employee feedback, including whether complaints reduce and positive comments increase without HR campaigns. They can verify that safety protocols are followed on random night audits, matching app logs with field checks. They can review incident and exception reports weekly to see if issues are caught by the vendor’s own monitoring before employees escalate, which indicates real operational maturity rather than surface-level punctuality.
If a commute incident becomes a leadership flashpoint, what governance artifacts help HR show control and avoid looking reactive?
B0390 Protect HR credibility after incidents — In India corporate Employee Mobility Services (EMS), how do CHROs protect their political capital when a commute incident becomes a leadership flashpoint, and what governance artifacts (logs, SLAs, escalation records) help HR avoid looking reactive or evasive?
CHROs in India protect their political capital during commute incidents by shifting the discussion from blame to governed evidence, using pre-agreed mobility policies, auditable data, and clear escalation trails to show that risks were understood, controlled, and acted on. The CHRO looks in control when leadership questions can be answered from documented logs and SLAs instead of ad-hoc explanations.
How CHROs protect their position when incidents escalate
The CHRO anchors employee transport under a formal Employee Mobility Services (EMS) policy that encodes night-shift rules, women-safety protocols, escort norms, and vendor responsibilities. The CHRO insists that Transport, Security/EHS, and vendors operate under SLA-linked contracts where safety, OTP, and incident-response times are defined as measurable obligations. The CHRO connects EMS systems to HRMS so attendance, shift data, and incident timelines can be reconstructed without ambiguity.
During a flashpoint, the CHRO uses the command-center view and trip lifecycle records to reconstruct “what exactly happened, when, and who was informed” instead of relying on verbal accounts. The CHRO convenes post-incident reviews using pre-defined risk registers and playbooks, which shows leadership that incidents feed into structured improvement, not one-off firefighting.
Governance artifacts that keep HR from looking reactive
Several specific artifacts help CHROs answer hard questions calmly and precisely.
- Trip and GPS logs. These include time-stamped pickup/drop, route adherence, geo-fence events, SOS triggers, and ETA deviations tied to each employee and shift.
- Safety and incident registers. These capture incident type, severity, root cause, actions taken, and closure SLA, with cross-links to Security/EHS and vendor reports.
- SLA and KPI dashboards. These show OTP%, incident rates, escort compliance, and complaint-closure SLAs at vendor, site, and time-band levels.
- Escalation and alert records. These document who was alerted, via which channel, at what time, and when each escalation level (transport desk, vendor, security, leadership) responded.
- Driver and vehicle compliance logs. These maintain current KYC, PSV, background checks, training sessions, fitness certificates, and random audit results.
- Women-safety and night-shift audit trails. These record adherence to female-first policies, escort rules, routing restrictions, and any exception approvals.
- Quarterly reviews and governance minutes. These store agreed actions with vendors and internal teams, demonstrating continuous assurance rather than post-crisis improvisation.
When these artifacts exist and are routinely reviewed, CHROs can show leadership a defensible narrative. The incident becomes an exception inside a governed EMS program with evidence, not a sign that HR was uninformed or evasive.
How do we set escalation tiers so employees feel heard, managers don’t bypass the process, and ops isn’t constantly disrupted by VIP escalations?
B0391 Design escalation tiers that work — In Indian corporate employee transport (EMS), how do you design escalation tiers so employees feel heard, managers don’t bypass process, and the transport ops team isn’t constantly disrupted by VIP escalations?
In Indian corporate employee transport, escalation tiers work best when they are few, crystal-clear, time-bound at each level, and backed by a command-center that can triage issues before they jump to HR or CXOs. Escalation design must separate “safety and SOS” from “service quality and comfort” so life-critical alerts bypass hierarchy, while routine noise is contained and resolved at the lowest effective tier.
A common failure mode is when employees and line managers do not trust first-line resolution. This usually happens when the transport desk is under-staffed, SLAs are vague, or feedback disappears into email threads. A centralized command center with an Alert Supervision System and clear SLAs for response and closure builds credibility. Real-time alerts for geofence violations, speeding, device tampering, and SOS must land directly in this command center, not in personal inboxes, so the night-shift team has a single view and standard playbooks.
VIP escalations become unmanageable when there is no defined “fast lane” that still respects process. A separate, published path for CXO / BU-head escalations, anchored on a key account manager and a formal escalation matrix, keeps pressure visible without bypassing the command center. Command center dashboards and indicative management reports then give HR, Security, and Facility Heads a single source of truth on OTP, safety incidents, and complaint closure SLA, which reduces side-channel calls.
In practice, stable escalation design usually includes: - A Tier 0 in-app layer for tracking, SOS, and simple complaints. - A Tier 1 command-center team with 24/7 responsibility and defined response times. - A Tier 2 account or site lead for pattern issues, repeated failures, or VIPs. - A Tier 3 joint client–vendor governance level for structural fixes and penalties.
Employees feel heard when every ticket has an ID, a promised response time, and visible closure. Managers stick to process when reports and QBRs use the same data the command center sees. The operations team avoids burnout when most issues are auto-routed, prioritized by severity, and only true exceptions reach senior leadership.
How do we align HR’s employee-first expectations with Procurement’s cost constraints when we set grievance SLAs and communication commitments?
B0392 Align HR and procurement expectations — In India corporate ground transportation for EMS, what is a realistic approach to aligning HR’s “employee-first” expectations with procurement’s cost discipline when setting grievance SLAs and communication commitments?
A realistic approach is to treat grievance SLAs and communication rules as a joint “safety + cost” contract, where HR defines non‑negotiable employee protections and Procurement defines measurable, auditable service levels and commercials around them. The joint design must make every response step predictable, timed, and costed, so it can be defended in audits and still feel employee‑first on the ground.
HR’s employee‑first expectations are best captured as clear service outcomes. These include maximum time to acknowledge a complaint, maximum time to provide a first resolution, night‑shift and women‑safety escalation rules, and requirements for 24x7 channels and language support. Procurement can then translate these into SLA metrics with defined bands, such as response time, closure time, and complaint‑to‑closure ratio, backed by incident logs and audit trails.
Procurement’s cost discipline is protected by linking commercial terms directly to these SLA bands. This means outcome‑based incentives and penalties on response and closure SLAs, caps on free re‑runs or compensations, and clear rules on what is billable versus non‑billable rework. A centralized command center and ticketing flow, with standard playbooks and reporting, reduces manual firefighting and fragmented data.
To keep both sides aligned, organizations typically establish a small HR–Procurement–Transport working group that: defines a minimal, common grievance taxonomy, agrees on a limited set of core SLAs and communication commitments, assigns a single owner for 24x7 incident triage, and reviews SLA and grievance data in quarterly performance reviews. This structure gives HR predictable, employee‑visible commitments and gives Procurement a finite, priced set of obligations that can be compared across vendors and defended in audits.
operational reliability and early-warning signals
Prioritize reliability with rapid triage and predictive alerting to prevent escalations, ensuring early actions are taken before issues escalate into brand risk.
How do we reduce complaints without shutting down legitimate safety or dignity issues, especially for women and vulnerable groups?
B0393 Reduce complaints without silencing — In India EMS operations for shift commute, how do you “stop the complaints” without suppressing legitimate safety and dignity issues—especially for women and vulnerable cohorts—so employees don’t lose trust in HR?
In India EMS shift operations, complaints reduce sustainably only when safety controls, dignity safeguards, and evidence systems are strengthened so issues are resolved early and visibly, not muted. Complaints disappear in a healthy way when women and vulnerable cohorts see that every trip is governed by clear SOPs, real-time monitoring, and accountable closure of issues.
A stable pattern in EMS is to treat “complaints” as signals in a governed system rather than noise to be suppressed. Centralized command centers with real-time tracking, SOS workflows, and alert supervision convert raw incidents into auditable tickets. This gives HR, Transport, and Security a single source of truth for route adherence, driver behavior, and night-shift exceptions. It also supports predictable OTP and reduces firefighting for the Facility / Transport Head.
A common failure mode is making it harder to complain. This erodes trust quickly, especially among women employees. In practice, organizations that succeed do the opposite. They make it easy and low-friction to report through employee apps with SOS, ride check-in, and feedback features. They also ensure driver assessment, induction, and compliance processes are strict, with background checks, POSH training, and continuous refresher programs.
To “stop the complaints” without silencing employees, operations leaders typically anchor on three routines:
- Daily control-room discipline with alert dashboards, early-warning on delays, and clear escalation matrices for safety and OTP breaches.
- Women-centric protocols that are visible to users, such as verified chauffeurs, dedicated fleets for night shifts, geo-fencing, and 24/7 women’s safety support cells.
- Closed-loop communication from HR and Transport back to employees, showing what changed after complaints, supported by management reports and user satisfaction indices.
When EMS, CRD-style governance, safety and compliance automation, and data-driven insights work together, most “complaints” turn into structured, auditable inputs. This protects employee dignity, improves commute experience, and lets HR credibly say to leadership and staff that they are in control, not in denial.
What training do employees, escorts/guards, and transport desk staff actually need so the rollout feels easy and not like a forced new process?
B0394 Enablement for zero learning curve — In India-based Employee Mobility Services (EMS), what training and enablement is realistically needed for employees, guards/escorts, and transport desk staff so adoption feels “zero learning curve” rather than a forced new process?
In India-based Employee Mobility Services, “zero learning curve” adoption happens when employees, guards or escorts, and transport desk staff are trained only on the 3–4 actions they must perform per shift and everything else is automated, pre-configured, or handled by the command center. Training needs to be short, role-specific, app-on-hand, and backed by clear SOPs, not generic classroom theory.
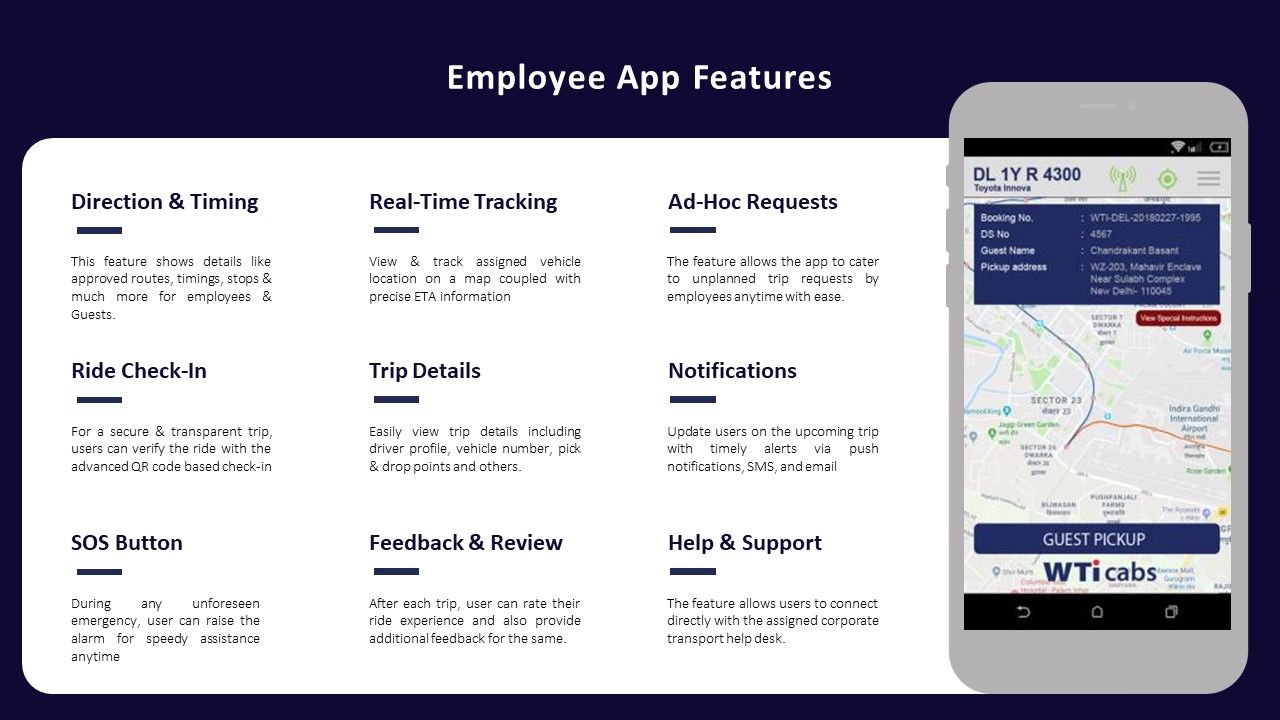
For employees, most organizations succeed when they treat the commute app like any other workplace tool. Employees need a one-time, 10–15 minute onboarding on login, booking or roster confirmation, live tracking, ride check-in, SOS use, and feedback. The Employee App Features collateral shows that direction and timing details, ad-hoc trip requests, SOS, notifications, and help and support are already bundled in a single interface, so training should focus on two or three “standard journeys” such as booking a shift, boarding with check-in, and raising an issue mid-trip. This reduces confusion and keeps night-shift escalations low.
For guards and escorts, enablement needs to act like a safety drill, not a tech tutorial. Most of the load should sit with the driver app, geo-fencing, and the command center, as outlined in Safety & Security for Employees and Women-Centric Safety Protocols. Guards should be trained on verifying employee identity, understanding approved route and escort rules, using SOS or escalation channels, and following incident SOPs during breakdowns, GPS failure, or women-safety breaches. Short, repeated, shift-wise briefings like those shown in Daily Shift Wise Briefing work better than long, one-time sessions.
For transport desk staff, the goal is to turn fragmented manual decisions into control-room routines. Desk teams need focused training on roster uploads, exception handling, escalation matrices, and reading real-time dashboards, not on every platform feature. Collateral such as the Transport Command Centre, Alert Supervision System, and Dashboard – Single Window System show that real-time alerts, CO₂ tracking, and compliance views are available in a single window, so training should center on “what to watch, when to act, and whom to call” during over-speeding, device tampering, geofence violation, or missed pickup alerts.
Practically, this usually means three layers of enablement:
- Micro-SOP cards or PDFs by role that define 5–7 core actions and 2–3 emergency steps.
- App-based tooltips, screen walk-throughs, and videos embedded in employee, driver, and admin apps such as Commutr and the Admin Transportation App.
- Recurring refreshers tied to real issues surfaced by the command center, supported by dashboards like Data Driven Insights and safety frameworks like Safety and Compliances.
This approach keeps daily operations stable, prevents technology from feeling like a burden, and lets the command center quietly absorb complexity so front-line users experience predictable, low-friction commutes.
images:

If commute issues spill into social media or internal forums, what’s the right HR + Facilities comms playbook to protect employer brand without making things worse?
B0395 Crisis comms for commute sentiment — In India corporate employee transport (EMS), how should HR and facilities teams handle public-facing employer brand risk when commute issues spill into social media or internal forums, and what comms playbook avoids making the situation worse?
Handling employer brand risk when commute issues go public
When commute failures spill into social media or internal forums, HR and Facilities teams protect employer brand best by treating it first as a safety and trust issue and only then as a PR issue. A response works when it is fact-based, empathetic to employees, and visibly backed by data from the transport command setup, not by defensive explanations.
Most organizations lose control of the narrative when HR appears surprised, Facilities looks unprepared, and nobody can quote simple numbers on OTP, incident history, or corrective actions. A common failure mode is responding with generic assurances or blaming “traffic” while employees already have screenshots, GPS traces, and chat histories. Brand damage escalates when leadership sees issues on social media before seeing an internal incident report.
A practical communications playbook relies on pre-agreed roles between HR, Facilities/Transport, Security/EHS, and Corporate Communications with clear escalation thresholds. Transport should own the factual timeline and route or roster details. HR should own employee-facing messaging and acknowledgement of impact. Security/EHS should own statements on risk, compliance, and safeguards. Corporate Communications should own any public-facing response and media handling.
- First response acknowledges the problem, confirms immediate safety status, and states that the route or shift is under active review.
- Within a defined SLA, HR shares a short root-cause outline and specific corrective steps, using data from command center logs and incident systems.
- Follow-up communication closes the loop with affected employees and, where needed, with all staff, sharing before-and-after metrics like OTP improvement or new escort/SOS controls.
- Public-facing statements, if required, mirror the internal facts, avoid blaming individual employees or drivers, and reference existing safety and compliance frameworks.
This approach reduces firefighting and blame because the same data and SOP backbone that runs EMS operations also underpins the narrative. It turns a visible failure into evidence that the organization has governed processes, auditable logs, and a predictable improvement cycle, which protects employer brand credibility over time.
When we say ‘grievance SLA,’ what should it include end-to-end (ack, investigation, fix, employee update), and where do teams usually leave gaps?
B0396 Define grievance SLA end-to-end — In India EMS programs, what does “grievance SLA” mean end-to-end—acknowledgement, investigation, corrective action, employee communication—and where do most vendors and internal teams accidentally leave gaps?
In Indian Employee Mobility Services programs, a “grievance SLA” is a time-bound, end-to-end commitment that starts when an employee raises a transport complaint and ends only when the issue is investigated, corrected, and clearly closed back with the employee and stakeholders. It is not just a response-time promise. It is a full lifecycle standard covering acknowledgement, triage, investigation, corrective action, and communication, with audit-ready evidence at each step.
A grievance SLA usually defines how fast the system acknowledges the complaint in the app or call center, how quickly the NOC or command center must classify severity, and by when the first human must speak to the employee. It also sets timelines for root-cause analysis using trip logs, GPS data, driver records, and roster details, and it specifies ownership for each stage across transport, security, HR, and vendor partners.
Stronger EMS programs link grievance SLAs to outcome metrics like complaint closure time, recurrence of similar issues, and impact on Commute Experience Index or OTP, and they integrate these into vendor governance and QBRs. They treat women-safety, night-shift and escort-related complaints as a separate, stricter SLA band because of HSSE and reputational risk.
Most gaps arise when vendors treat SLA as “ticket closed in the system” rather than “employee feels it is resolved.” A common failure mode is fast acknowledgement with slow or shallow investigation. Many teams do not consistently use command center data, route adherence audits, or driver compliance records to prove what happened. Another frequent gap is weak closure communication, where the employee never gets a clear explanation, corrective step, or escalation route, so the issue resurfaces through HR or leadership.
Internal gaps often appear at hand-offs between the control room, HR, Security/EHS, and Procurement. Transport teams may resolve the immediate operational problem but not log structured root causes, so patterns around a specific route, driver, or timeband are missed. Vendors also under-invest in measurable, auditable workflows and rely on manual follow-ups, which break down during night shifts, peak loads, or app downtime. In practice, grievance SLAs fail when acknowledgement is automated but accountability, investigation depth, and evidence-backed closure are not equally governed.
How do we run closed-loop feedback where employees actually see follow-through, so it doesn’t feel like a black hole and hurt trust in HR/Admin?
B0397 Make feedback visibly closed-loop — In India corporate employee transport (EMS), how do you set up a closed-loop feedback program where employees see visible follow-through, so the system doesn’t become a “black hole” that damages trust in HR and Admin?
Design principle
A feedback program in employee transport only builds trust when every complaint and suggestion is traceable from capture to closure and the employee can see what changed. A closed-loop design therefore needs clear intake channels, triage SLAs, root-cause tagging, and visible communication of actions taken.
1. Standardize how feedback enters the system
Transport teams should fix 2–3 primary channels and make them part of the daily commute habit. Mobile apps can capture trip-level feedback, SOS follow-ups, and ratings, as shown in the employee app features and SOS control panel collaterals. Centralized call centers and command centers can log complaints in a common ticketing system, rather than leaving them in email threads or WhatsApp groups.
2. Route every input into a command-center workflow
Feedback should flow into the same environment used for real-time operations, not a separate offline spreadsheet. Command centers and transport command centres already manage alerts, geofencing violations, and incidents. The same console should auto-create tickets from low OTP, safety concerns, and app issues with severity levels and ownership. Escalation matrices and TCC roles and responsibilities can define who picks up what, and in what time.
3. Attach transport KPIs to feedback categories
Each complaint type should map to a measurable KPI. Low punctuality feeds into on-time performance, routing issues into trip adherence and dead mileage, and safety concerns into incident rate and audit trail integrity. User satisfaction index and indicative management reports can then surface patterns, not just individual tickets. This prevents feedback from being treated as “noise” and anchors it in EMS KPIs.
4. Enforce closure SLAs and root-cause tags
Closed loop means every ticket has a due date and a closure note. Transport and vendor teams should tag causes such as driver behavior, fleet condition, routing, or app failure. Centralized compliance management and driver compliance frameworks can be linked directly to these tags, so repeat issues lead to retraining, route audits, or fleet changes instead of one-off apologies.
5. Make follow-through visible to employees
Employees trust the system when they see outcomes. Apps can show “issue status” and “resolved with action” banners on the same screen where trips are booked, similar to how SOS and trip details are surfaced. Quarterly “you said, we did” summaries can highlight themes: improved OTP, new safety protocols, or EV deployment to address ESG feedback. HR can use dashboards like the single-window system to present this back to employees and leadership.
6. Tie vendor governance and BCP to feedback data
Vendor scorecards should include complaint volumes, closure time, and repeat incident rates alongside OTP and utilization. Business continuity plans already address strikes, tech failures, and cab shortages. Feedback patterns can trigger specific BCP actions, like activating standby vehicles or backup apps, so employees see fewer recurrences.
7. Keep HR visible but not manually overloaded
HR should not be the manual router of every complaint, but they should have a live view of trends through dashboards and management reports. This allows HR to answer leadership questions with data, while operations and command center teams do the day-to-day triage. When a serious safety or women-safety issue occurs, HR and Security can rely on the same auditable trip and incident logs used by the safety and compliance frameworks.
- Define standard channels and scripts for feedback capture.
- Log every item into a command-center ticketing flow with SLAs.
- Map categories to EMS KPIs and vendor scorecards.
- Publish “you said, we did” updates so employees see change.
For multi-site commute, what governance cadence works best (weekly reviews, monthly QBRs, incident councils) to stop small issues from turning into attrition and brand problems?
B0398 Governance cadence to prevent buildup — In India-based EMS for multi-site shift commute, what governance cadence (weekly reviews, monthly QBRs, incident councils) best prevents small experience issues from accumulating into an attrition and employer brand problem?
In India-based multi-site EMS, small commute issues stay contained when organizations run a tight weekly–monthly–quarterly governance cadence with clear owners, hard KPIs, and an always-on incident loop. The most effective pattern is a weekly operational review for OTP and exceptions, a monthly cross-function review for trends and policy fixes, and a quarterly CX/ESG council that links commute metrics to HR, finance, and employer brand outcomes.
The weekly review needs to live close to the command center and transport desk. It should track on-time performance, trip adherence rate, seat-fill, exception closure times, safety deviations, and driver fatigue indicators for each site. This cadence allows dynamic route recalibration, vendor capacity rebalancing, and targeted driver coaching before daily noise becomes systemic failure. In multi-site EMS, this weekly rhythm is where hybrid-work volatility, monsoon disruptions, and vendor-specific issues are first surfaced and contained.
The monthly review works best as an HR–Transport–Vendor forum. It should consolidate NPS/CEI feedback, complaint categories, no-show patterns, and women-safety compliance metrics, then translate them into route policy changes, SLA refinements, and training or roster adjustments. This is where procurement and finance can plug in to align commercials with outcomes such as OTP, incident rates, and CET/CPK, and where ESG leads can review EV utilization and emission intensity per trip without derailing day-to-day stability.
The quarterly council should sit at CHRO and senior-ops level and focus on commute-linked attrition, attendance deltas, diversity participation in night shifts, and employer brand signals from surveys or social channels. This council can mandate structural changes, like vendor tiering, EV transition pilots on stable corridors, or new women-centric routing rules. It should also review business continuity drills and HSSE audit findings, so that rare but serious failures do not become reputational flashpoints.
- Weekly: site-wise SLA and exception review anchored by transport head and command center.
- Monthly: cross-functional trend and policy review with HR, Transport, vendor, and Finance.
- Quarterly: strategic CX/ESG council tying commute KPIs to attrition, EVP, and brand risk.
How do we stop over-escalation where every small delay goes to leadership, but still fast-track real safety or harassment concerns?
B0399 Prevent over-escalation while prioritizing safety — In India corporate Employee Mobility Services (EMS), how do you avoid ‘over-escalation’ where every small delay becomes a leadership complaint, while still ensuring genuine safety or harassment concerns get immediate priority?
In corporate Employee Mobility Services in India, over-escalation reduces trust in the system, so organizations need a tiered, evidence-backed escalation model that separates service noise from safety-critical events and routes them through different SOPs and teams. Genuine safety or harassment concerns must always cut through to a 24x7 command center and Security/EHS, while routine delays stay within transport operations with clear closure SLAs and transparent status to HR and employees.
A common failure mode is treating every late cab, routing error, or GPS glitch as a “critical” issue. This overwhelms CHRO and leadership, and it numbs the system so real women-safety or harassment escalations do not stand out. A better pattern is to classify incidents by type and risk. Safety-critical categories include SOS activations, escort or women-first policy violations, route deviations with women at night, driver misconduct, tampering or geo-fence breaches, and accident flags from IVMS or command center dashboards. These should auto-trigger an incident ticket, immediate call-back to the employee, and simultaneous notification to Security/EHS and the 24x7 NOC.
Routine service issues such as 10–15 minute ETA slips inside a defined buffer, non-critical GPS drops, or low-severity complaints about vehicle comfort should sit in a different queue. These should be handled by the transport desk or vendor supervisor, with OTP%, Trip Adherence Rate, and complaint closure SLA reviewed in weekly or monthly governance forums instead of daily leadership calls. Data-driven dashboards and a central command center help show HR and leadership that issues are tracked and closed, without requiring their intervention in every case.
Practical guardrails usually include:
- A clear escalation matrix that links specific event types to CHRO, Transport Head, Security, and vendor KAM so everyone knows “who answers the phone at 2 a.m.” for which issue.
- Pre-defined time and impact thresholds for auto-escalation of delays, for example, only repeated breaches beyond a set OTP% for a corridor or shift get summarized to leadership.
- Role-based access to incident logs and audit trails so HR and ESG can verify patterns and exceptional cases without being pulled into every ticket.
This structure improves operational calm for the Facility/Transport Head. It reduces leadership fatigue from minor escalations. It also strengthens duty-of-care by ensuring that real safety, harassment, or women-centric incidents move faster, are better documented, and remain defensible during audits or investigations.
For our employee commute program, how can we tell if the complaints are mainly about experience vs day-to-day operations issues before we change tools or vendors?
B0400 Diagnose UX vs reliability — In India’s corporate Employee Mobility Services (EMS) for shift-based employee transport, how do HR and Admin teams diagnose whether recurring commute complaints are an “experience” problem versus an “operations reliability” problem, before they invest in new tooling or change vendors?
Diagnosing “experience” vs “operations reliability” issues in EMS
HR and Admin teams distinguish commute “experience” problems from “operations reliability” problems by first anchoring on hard reliability KPIs, then overlaying safety and employee feedback signals that describe how the commute feels. Teams treat OTP, route adherence, and exception-closure time as primary indicators of operational reliability, and they treat complaint themes, NPS/CEI scores, and safety-perception feedback as primary indicators of commute experience.
Most organizations start by checking command-center style metrics for Employee Mobility Services. They look at on-time performance, trip adherence rate, no-show rate, and exception latency to see if shift-aligned routing and vehicle allocation are fundamentally working. They also review incident logs, women-safety protocol breaches, and business continuity events to understand whether failures are due to vendors, infrastructure, or internal rostering and hybrid-work volatility.
In parallel, HR consolidates grievance channels and employee feedback into a Commute Experience Index. Teams classify complaints into buckets such as app usability, booking friction, driver behaviour, perceived safety, communication gaps, and billing transparency. If reliability KPIs are healthy while perception scores and complaint volumes are poor, the pattern indicates an experience-layer problem. If both KPIs and complaints show missed pickups, late drops, and routing chaos, the problem is operational reliability or vendor governance.
- Signals of operations reliability gaps include unstable OTP across sites or timebands, repeated emergency playbook use, and heavy manual firefighting in the transport desk.
- Signals of experience gaps include confusing booking flows, weak communication during disruptions, or low trust in safety protocols despite acceptable OTP.
Before changing tools or vendors, mature teams run a short diagnostic period. They align HRMS–transport data, standardize how OTP and incidents are measured, tag complaints to specific routes or vendors, and review SLA governance and business continuity playbooks. This approach reduces the risk of blaming platforms for issues rooted in routing policy, capacity planning, or fragmented command-center operations.
What early signs show employee sentiment is becoming an employer brand risk (especially for women/night shifts), and should HR, Security, or Facilities own that monitoring?
B0401 Early warning brand risk — In India’s corporate ground transportation (EMS) for women and night-shift employees, what are practical early-warning signals (before a major incident) that employee sentiment is turning into an employer brand risk, and who should own monitoring—HR, EHS/Security, or Facilities?
In employee mobility for women and night-shift staff, the earliest warning signals are small, repeated deviations in commute reliability, perceived safety, and grievance closure. These weak signals usually appear in OTP, routing, escort compliance, and app feedback data before any major incident or public escalation. Monitoring should be jointly owned, but with clear roles. HR should own sentiment and escalation governance, EHS/Security should own safety compliance and risk scoring, and Facilities/Transport should own day-to-day operational signals and immediate fixes.
Practical early-warning signals that sentiment is becoming a brand risk include patterns like night-shift OTP dipping, repeated routing or no-show complaints, and rising safety-related feedback even when no major incident has occurred. Early deterioration in On-Time Performance (OTP) and Trip Adherence Rate (TAR) for late-evening and night bands is a critical signal. An uptick in re-routed trips, last-minute cab substitutions, or dead mileage in certain corridors often indicates stretched capacity and higher failure risk. A visible increase in SOS presses, geo-fence violations, and over-speeding or device-tampering alerts from command-center tooling is another red flag. Higher complaint volume around “driver behavior,” “escort missing,” or “felt unsafe” in app feedback, even when not formal incidents, suggests trust erosion among women employees. A growing gap between neutral internal commute-NPS scores and sharper comments on internal forums, WhatsApp groups, or unmanaged feedback channels indicates that sentiment is moving outside formal reporting structures. Rising driver attrition and fatigue indicators on night routes also increase the probability of safety and reliability failures.
Most organizations misread these as isolated operational noise instead of precursors to reputation damage. A common failure mode is treating women-safety and night-shift compliance as a static policy, while ignoring the continuous assurance signals from routing engines, trip logs, and command center dashboards. Another failure mode is leaving monitoring to only one function. If Facilities alone tracks OTP without HR linking it to attendance and attrition, or if EHS focuses only on incident logs without reading early commute feedback, brand risk accumulates unnoticed.
Ownership works best as a layered model with a clear “who watches what” view. HR should own a commute experience and sentiment dashboard tied to attendance, attrition, and commute-specific NPS for women and night-shift employees. EHS/Security should own safety and compliance early-warning metrics, including escort compliance, high-risk routes, incident response SLAs, and audit trail completeness for night shifts. Facilities/Transport should own real-time operational health indicators, including OTP, route adherence, fleet uptime, driver fatigue proxies, and exception closure time from the command center. Together they should run a joint monthly review focused specifically on women and night-shift mobility, with predefined thresholds for when operational drift becomes an employer brand escalation and triggers corrective action.
How do we make a credible case to Finance and Procurement that better commute experience is EVP-critical, not just a nice-to-have expense?
B0402 EVP business case framing — In India’s corporate employee commute programs (EMS), how can a CHRO frame the business case for improving commute UX as part of the Employee Value Proposition (EVP) without it sounding like “nice-to-have” spend to the CFO and Procurement?
In India’s employee mobility context, a CHRO strengthens the business case for commute UX by framing it as a risk-control and reliability lever that protects attendance, safety, and ESG credibility, not as a discretionary perk. The argument lands best when commute experience is linked to measurable outcomes like on-time performance, attrition risk, compliance exposure, and ESG reporting, and when those outcomes are expressed in the same language Finance and Procurement already use for EMS contracts and audits.
A CHRO can first position commute UX as a stabilizer for shift adherence and productivity. Employee Mobility Services are defined around shift-aligned routing, real-time tracking, and SLA-driven delivery. Poor UX usually appears as late pickups, opaque communication, or unreliable apps, which then surface for HR as late logins, manager complaints, and avoidable “no-show” disputes. When commute UX is improved using governed platforms with centralized command-center visibility and clear incident workflows, it directly supports OTP, reduces exception handling, and lowers the operational noise that otherwise keeps HR on the defensive.
Second, commute UX can be framed as a safety and audit-readiness control. EMS is already expected to embed safety by design via driver KYC, women-safety protocols, escort rules, SOS, geo-fencing, and auditable trip logs. A better rider app, clearer routing, and consistent feedback closure reduce incident probability and make every trip more reconstructable if something goes wrong. This lowers compliance and reputational risk for HR, Security, and Finance, and it gives Procurement a stronger SLA and audit-trail foundation to defend the contract later.
Third, commute UX is now part of the Employee Value Proposition that affects retention and employer brand. Industry insight links commute experience to attendance, attrition, and overall EVP. If the commute repeatedly fails, HR absorbs the blame even when operations sit elsewhere. By integrating EMS telemetry with HRMS and transport KPIs, a CHRO can show correlations between commute complaints, absenteeism patterns, and team churn. That allows UX improvements to be positioned as targeted investment to reduce hidden costs like backfilling, overtime, and productivity loss, rather than as a generic comfort upgrade.
For the CFO, the CHRO can translate UX improvements into cost and control terms. Employee transport already carries substantial spend under cost per kilometer and cost per employee trip metrics. Fragmented experiences and manual escalation handling produce leakage through dead mileage, re-routing inefficiencies, and disputed invoices. Platformized EMS with better booking UX, real-time tracking, and centralized dashboards reduce these leakages by improving trip fill ratios, reducing dead mileage, and providing cleaner trip-level data for reconciliation. This meets Finance’s need for predictable, defensible numbers while making it easier to support ESG or EV initiatives with verifiable data rather than narrative alone.
For Procurement, the same UX investments can be framed as contract stability and dispute avoidance. Improved commute experience typically comes from standardized SLAs, routing engines, NOC visibility, and measurable KPIs like OTP, incident rate, and complaint resolution time. These elements directly enable outcome-based contracts where payouts are indexed to reliability and safety rather than just volume. Procurement gets fewer post-award escalations, clearer penalty and incentive logic, and better comparability across vendors, which addresses their fear of choosing an over-promising supplier.
A practical way for a CHRO to reframe commute UX with these functions is:
- Anchor on risk and continuity. Position UX gaps as leading indicators of safety incidents, SLA breaches, and reputational risk, not as comfort issues.
- Show baselines and deltas. Use existing EMS data on OTP, complaints, and absenteeism to quantify the operational impact of poor commute experience.
- Tie UX features to contract levers. Explain how better apps, tracking, and feedback loops enable outcome-linked commercials and cleaner billing.
- Link to ESG and EV. Where EV fleets or sustainability reporting are in scope, show how commute UX supports auditable emission tracking and EV utilization without disrupting reliability.
When commute UX is positioned as a control-room tool that reduces escalations, stabilizes shifts, and strengthens audit and ESG narratives, CFO and Procurement are more likely to see it as core infrastructure for EMS rather than “nice-to-have” spend.
In our shift commute, which complaint types are most likely to cause attrition, and how do we pick the top two to fix first if budget is tight?
B0403 Prioritize grievance fixes — In India’s shift-based EMS operations, what grievance categories typically drive the most attrition risk (e.g., punctuality, driver behavior, routing, women-safety protocols), and how should HR prioritize fixes when budget only allows tackling two issues this quarter?
In India’s shift-based employee mobility services, the two grievance categories that most consistently drive attrition risk are repeat punctuality failures and perceived gaps in women-safety protocols. HR should prioritize fixing on-time performance and women-safety by design before deeper routing tweaks or generic driver-behavior programs when budget is constrained.
Punctuality failures directly hit attendance, manager relationships, and salary-linked incentives. Employees experience them as daily friction. Recurrent late pickups, missed cabs, or unreliable night coverage quickly erode trust in both the transport program and the employer. In EMS, on-time performance is a primary value outcome and sits at the center of reliability KPIs such as OTP%, Trip Adherence Rate, and exception-closure time. When OTP problems are not controlled from a command-center level with governed routing, fleet buffers, and early alerts, HR faces continuous noise, escalations, and attendance volatility.
Women-safety lapses, or even the perception that safeguards are weak, create disproportionate attrition and reputational risk. Night-shift policies, escort rules, verified drivers, geo-fencing, SOS mechanisms, and audit trails are non-negotiable in India’s regulatory and social context. A single serious incident, or a visible breach of women-first night routing norms, can undo months of employer-brand effort and trigger immediate exit decisions among affected employees. Safety and duty of care are explicit buyer priorities and are tightly coupled to HR’s moral and reputational accountability.
With budget for only two focus areas in a quarter, a pragmatic HR sequence is:
- Stabilize OTP and reliability. Work with Transport and vendors to tighten shift windowing, routing and fleet buffers. Use centralized command-center monitoring, early alerts, and clear exception SLAs so that late pickups and no-shows drop sharply and stay low.
- Harden women-safety protocols and evidence. Ensure driver KYC/PSV currency, escort compliance on mandated shifts, active SOS and geo-fencing, and auditable incident-response SOPs. Make proof visible to staff and leadership so HR can confidently stand behind safety assurances.
Routing convenience and general driver-behavior coaching still matter for satisfaction and NPS. However, they typically influence comfort and preference rather than immediate “I will quit” decisions when compared to chronic lateness and safety anxiety. Focusing first on punctuality and women-safety gives HR the strongest reduction in attrition risk per rupee spent and the clearest story to leadership that commute risks are under control.
What’s a practical grievance SLA flow that really reduces repeat complaints, not just more tickets and bureaucracy?
B0404 Grievance SLA that works — In India’s corporate EMS for large campuses, what does a realistic grievance SLA model look like (acknowledge, investigate, resolve, and close-the-loop) that actually reduces repeat complaints instead of creating a ticketing bureaucracy?
A realistic grievance SLA model in Indian corporate EMS reduces repeat complaints when SLAs are tied to risk and impact, are driven from the transport command center, and always include a verifiable “closure with the employee” step, not just ticket status change.
An effective model uses differentiated SLA bands instead of a single generic timeline. High-severity cases like women-safety concerns, SOS triggers, route deviation, or missed night pickups need immediate acknowledgement from the command center within 2–5 minutes and live engagement until the employee is safe. Medium cases such as repeated OTP failures, rude behavior, or chronic routing issues need acknowledgement within 30–60 minutes and a same-shift or next-shift investigation that includes driver and vendor input plus GPS and app logs. Low-severity issues like minor delays in non‑critical windows or one‑off comfort complaints can run on a 24‑hour closure window with batched root-cause analysis.
The model works when the command center runs SOP-led triage using telematics, route adherence data, and driver-compliance history rather than relying on “he said–she said” versions. Transport teams need clear escalation ladders, integration with HR and Security for safety cases, and the ability to push corrective actions back into routing rules, driver training, and vendor scorecards. Every complaint should close only after the employee confirms outcome via the app or a short survey and the incident is tagged to a root cause category that is reviewed in monthly governance with HR and Procurement.
Signals of a healthy grievance SLA include falling repeat complaints per 1,000 trips on the same route or driver, improved on‑time performance after clusters of delay-related tickets, reduced safety‑related escalations to HR, and visible linkage between grievance data, driver RNR or corrective training, and vendor performance tiers. Without this feedback loop, SLAs tend to devolve into a ticketing bureaucracy that measures “time to close” instead of whether the underlying commute problem actually disappeared.
How do we set escalation rules so night-shift issues don’t become WhatsApp chaos but also don’t get slowed down by rigid process?
B0405 Escalation hygiene for NOC — In India’s employee transport (EMS) with a centralized NOC, how should escalation hygiene be defined so that night-shift incidents don’t turn into chaotic WhatsApp chains, but also don’t get stuck in a slow formal workflow?
Escalation hygiene in Indian EMS with a centralized NOC should be defined as a two-track system. One track must enable immediate, voice-based response within minutes for any safety or service-risk incident. The second track must ensure every incident is captured, classified, and closed on a ticketed, auditable workflow tied to SLAs, so nothing lives only on WhatsApp.
Most organizations need clear, pre-agreed “what goes where” rules for night shifts. Safety and women-security events should always trigger SOS and command-center calls, supported by tools like the SOS control panel, alert supervision systems, and transport command centre dashboards. Routine issues like minor delays or vehicle swaps should stay within app or dashboard notifications, and should not spill into leadership WhatsApp groups. Centralized NOC teams should act as the single point of coordination with drivers, vendors, and security instead of allowing employees or line managers to start parallel chats.
A practical definition of escalation hygiene links each incident type to three fixed elements. The first is a maximum first-response time and channel, such as “within 120 seconds via NOC phone call” for SOS, or “within 15 minutes via app update” for delay. The second is ownership, where the NOC or transport head owns on-ground recovery, and HR or Security only join when predefined thresholds are crossed. The third is closure discipline, where every incident must end with a short ticket summary, cause tag, and closure time, feeding into command-center KPIs like OTP, safety incident rate, and complaint closure SLAs.
To prevent chaos, escalation hygiene should also include rules for who may escalate to which level at night, such as using an escalation matrix with time-bound handoffs, and which information must be logged before escalation, such as trip ID, location, and driver details. This reduces noise for the facility or transport head, keeps WhatsApp focused on broadcast-only alerts when systems fail, and preserves a clean audit trail for HR, Security, and ESG teams after the shift.
When supervisors are under pressure, how do we stop them from bypassing the system and calling drivers directly for ad-hoc pickups?
B0406 Prevent system bypass behavior — In India’s EMS for shift-based workforce transport, how do Facilities/Transport Heads prevent frontline supervisors from bypassing the official system (calling drivers directly, ad-hoc pickups) when they’re under pressure to avoid late logins?
In India’s EMS context, Facilities and Transport Heads prevent supervisors from bypassing official systems by making the “right way” the fastest and safest way to avoid late logins. They do this by combining clear SOPs, tech-enforced controls, and a command-center that solves exceptions faster than ad‑hoc calls to drivers.
They start with a governed ETS operation cycle that standardizes every step from booking to billing. The ETS Operation Cycle and ETS Operation Cycle Detailed collaterals show defined stages like booking, rostering, routing, vendor allocation, tracking, shift reports, and feedback. A clear SOP gives supervisors a single, predictable path, and makes manual phone-based routing a documented deviation rather than a “favor.”
Command centers and alert systems are then used to detect and contain workarounds early. The Transport Command Centre, WTI Command Center, and Alert Supervision System collaterals describe centralized monitoring of geofence violations, overspeeding, and route deviations, plus escalation matrices. When an ad-hoc pickup or off-roster cab appears on GPS, the control room can intervene and log it as an exception tied to SLA and vendor governance.
Technology products like Commutr, the WTicabs Mobility App, and driver/employee apps reduce the operational incentive to bypass systems. Dynamic routing linked to rosters, live tracking, and real-time re-routing during disruptions (for example, the Mumbai monsoon case study) give supervisors a fast, sanctioned way to add or adjust pickups without calling drivers directly.
Facilities leaders also use data-driven insights and single-window dashboards to enforce discipline with evidence. Dashboards, Data Driven Insights, and Indicative Management Report collaterals show how OTP, route adherence, and exception reports are surfaced by branch or supervisor. Repeated off-platform behavior becomes visible during governance reviews and feeds into vendor and staff performance management.
Practical guardrails typically include:
- Shift-wise cut-off times and approval flows in the app, backed by SOPs that define when a manual intervention is allowed and how it must be logged.
- Vendor and driver compliance frameworks that require trips to originate from the platform for billing and payment (Billing & Invoicing and Billing – Centralized Operations), so off-system trips are financially discouraged.
- Business continuity and on-time service delivery playbooks that give supervisors buffer vehicles, rerouting rules, and escalation contacts, so they have sanctioned tools when disruptions hit instead of calling “their” drivers informally.
When these elements are combined with daily briefings (Daily Shift Wise Briefing) and clear escalation matrices, supervisors learn that staying within the system keeps them safer from blame, and gets problems solved faster than bypassing controls.
During major disruptions like rain or protests, what communication playbooks reduce employee frustration without creating reputational or legal risk?
B0407 Disruption communication playbooks — In India’s corporate ground transportation for employee commute (EMS), what communication playbooks actually calm employee frustration during widespread disruptions (heavy rain, protests, major traffic blocks) without creating legal or reputational exposure?
In India’s employee commute operations, the communication that actually calms employees during heavy rain, protests, or gridlock is pre-agreed, SOP-based, and evidence-backed. It sets clear expectations early, gives timely and honest updates during the disruption, and documents decisions in a way that can stand up to HR, legal, and social-media scrutiny later.
During widespread disruptions, most employee frustration comes from silence, last‑minute surprises, and conflicting messages rather than from the delay itself. A stable playbook therefore anchors three things. It defines who speaks, on which channels, and with what pre-approved language. It wires transport apps, command center dashboards, and alert systems so that employees see consistent ETAs, not guesses. It keeps a clean audit trail of decisions, alerts, and exceptions that HR and Legal can reference if incidents or complaints arise.
A common failure mode is ad-hoc WhatsApp broadcasts or driver-led updates without command-center oversight. This tends to create inconsistent promises, informal commitments, and screenshots that can later be used against the company. Another failure mode is over-optimism. This happens when transport teams keep promising “10 more minutes” without factoring traffic patterns or weather data, which erodes trust and increases escalation volume.
An effective, low-risk communication playbook for EMS disruptions in India usually includes:
- Pre-drafted scenario templates for rain, protests, and police diversions. These templates avoid blame, avoid speculation on causes, and focus on safety, expected impact, and next review time.
- A single “source of truth” for ETAs, ideally from a transport platform or command center that uses live traffic and route recalibration, so employees, HR, and security all see the same status.
- Tiered alerts from the command center or NOC, not from individual drivers. The first alert should be risk-focused (“expect 30–45 minutes corridor-wide impact”) rather than vehicle-specific guesses.
- Time-boxed updates that commit to a next checkpoint, not to unrealistic arrival times. For example, “We will re-evaluate and update this route cluster at 21:15” calms more than “Cab will reach in 10 minutes” repeated every 10 minutes.
- Aligned scripts for HR, Transport, and Security teams so employees do not receive contradictory instructions on working from home, shift adjustments, or late-mark relaxations.
- Auditable records of who triggered alerts, which routes were reprioritized, and how safety decisions (for example, cancelling last-mile in high-risk zones) were justified.
In practice, organizations that already run centralized command centers and alert supervision systems have a structural advantage. They can trigger geo-fenced alerts, SOS support, and rerouting instructions with a consistent tone and timing. Case evidence from monsoon-focused route optimization shows that when employees receive early, honest communication and see the system actively re-routing to maintain a high on-time rate, customer satisfaction remains high despite weather.
The safest communication style is calm, factual, and specific about employee options. It should clearly state whether the company is relaxing attendance rules, allowing WFH, or adjusting shift start times. It should avoid making commitments on safety outcomes (“nothing will happen”) and instead emphasize the mechanisms in place (GPS tracking, SOS, command center monitoring, women-centric safety protocols). This framing lowers legal exposure while still showing duty of care.
For reputational protection, every disruption communication should be designed as if it might be screenshotted and shared externally. Avoid blaming authorities, communities, or specific employee groups in writing. Refer to disruptions in neutral, descriptive terms and highlight that decisions are being taken under documented safety and compliance policies that apply to all employees.
To keep transport heads out of constant firefighting, the playbook should also define internal communication cadences. This means a clear escalation tree to HR, Security, and leadership, and standard status dashboards that show route impacts, delayed trips, and mitigation measures. When these artifacts exist, HR can answer leadership questions with data instead of forwarding individual complaints, which further reduces pressure on operations teams.
images: 
For women’s night-shift safety incidents, what does a ‘trustworthy’ response look like for the employee—timelines, updates, privacy, escalation—beyond just closing the ticket?
B0408 Define trustworthy incident response — In India’s women-safety focused EMS programs for night shifts, how should HR and EHS define a “trustworthy” incident response experience from the employee’s perspective (timelines, updates, privacy, escalation), not just operational closure?
In women-safety focused night-shift EMS programs, a “trustworthy” incident response experience is one where the employee feels believed, protected, and informed at every step, with fast first response, predictable updates, and clear privacy and escalation safeguards that are visible to her, not just recorded in backend logs.
Employees judge trust by what happens in the first 15–30 minutes after an SOS or complaint. They expect a live human to acknowledge the issue immediately, confirm their location from GPS, and prioritize their physical safety before any procedural questions. A trustworthy experience includes clear communication of what will happen next, such as vehicle replacement, escort arrangement, or security deployment, and it avoids making the employee repeat details to multiple teams. This aligns with safety-focused EMS practices that use command centers, live tracking, and SOS features to coordinate rapid on-ground support.
Trust also depends on how information is handled after the incident. Employees need assurance that sensitive details, including location data and statements, are used only for safety, investigation, and compliance, not shared casually across teams. HR and EHS should define visible escalation paths, with known timelines for callbacks and closure, and then close the loop with the employee with an explanation of actions taken. This reinforces a “safety and compliance by design” culture, where command center operations, driver compliance checks, and audit trails exist to protect her and provide evidence, not to shift blame.
What are the common ways grievance data gets ‘gamed’ or distorted, and how can we audit sentiment accurately without employees feeling surveilled?
B0409 Audit sentiment data integrity — In India’s corporate employee mobility services (EMS), what are the most common ways grievance data gets distorted (fear of retaliation, manager pressure, ticket reclassification), and how can HR audit sentiment accuracy without making employees feel surveilled?
In India’s corporate employee mobility services, grievance data is most often distorted by social pressure, process loopholes, and misaligned KPIs rather than by the absence of tools. Distortion usually appears as under-reporting of issues, softening or reclassification of complaints, and routing of serious concerns into informal channels that never hit the official log.
Distortion typically arises at three points. Employees self-censor when they fear vendor or driver retaliation, manager backlash for “making noise,” or being perceived as difficult, especially in probation or contract roles. Frontline managers and transport desks dilute or reclassify tickets to protect their own OTP or “no-incident” metrics, recoding safety issues as “service feedback” or “routing queries.” Vendors sometimes nudge employees to call them directly instead of using official apps or helplines, so problems get resolved informally but disappear from auditable data.
HR can audit sentiment accuracy by triangulating independent signals instead of intensifying individual-level monitoring. HR leaders can periodically compare app-based grievance data with anonymous pulse surveys, townhalls, and independent feedback channels run outside vendor systems. HR can correlate ticket volumes with operational patterns like night-shift density, women ridership, route risk scores, and OTP dips, to spot under-reporting where risk should be high. HR can review reclassification patterns in the command center or transport desk logs to detect if categories like “service issue” or “no fault” are growing while safety or harassment tickets fall.
HR avoids a “surveillance” feel by aggregating and anonymizing analysis and by being explicit about purpose. Individual trips should not be monitored for performance judgement. Instead, HR can publish periodic, aggregated commute safety and satisfaction reports, show what changed because of feedback, and emphasize protections such as non-retaliation and vendor-neutral escalation routes. HR can maintain a small number of clearly advertised, low-friction channels for night-shift and women employees that bypass both line managers and vendors, and ensure closing the loop visibly so employees see that raising issues leads to safer, more reliable commutes rather than personal risk.
How do we capture detailed commute feedback while staying DPDP-compliant on consent, data minimization, and retention—without weakening the feedback loop?
B0410 Feedback vs DPDP compliance — In India’s corporate EMS, how should HR and Legal balance collecting detailed commute feedback (driver behavior, location context, incident narratives) with DPDP Act expectations around consent, minimization, and retention—without weakening the feedback loop?
In India’s corporate employee mobility, HR and Legal should treat commute feedback as safety-critical data that is collected with explicit, narrow consent, minimized to what is operationally necessary, and retained against a clear, written schedule that is tied to incident-risk windows and audit requirements. Strong, auditable controls around purpose limitation, role-based access, and redaction allow organizations to keep a robust feedback loop without breaching DPDP expectations.
HR teams benefit when commute data is modeled as part of a governed EMS platform rather than informal channels. A structured ETS operation cycle with app-based feedback, incident tickets, and centralized dashboards gives cleaner inputs for Legal and Security, and it also supports women-centric safety protocols, chauffeur compliance checks, and command-center monitoring. Legal can then codify which fields are “must-have” for safety and compliance, and which can be optional, anonymized, or dropped.
The most practical balance is achieved through very specific SOPs that HR and Legal own jointly. These SOPs should define what feedback fields are captured for routine trips, what additional detail is requested after a safety or conduct incident, how long raw narratives and GPS-linked logs are kept before aggregation or anonymization, and who can see personally identifiable details. Clear notice in employee and driver apps about why feedback is collected and how long it is stored preserves trust, while still enabling transport heads, command centers, and safety teams to act on patterns of driver behavior, route risk, and service reliability.
What rider-app issues usually make employees reject a new system, and how can we pilot changes without causing backlash?
B0411 Avoid rider app backlash — In India’s employee mobility services (EMS), what adoption pitfalls cause employees to reject new rider apps (OTP flows, boarding UX, language, device constraints), and how should Admin teams pilot changes without triggering a morale revolt?
In India’s employee mobility services, employees usually reject new rider apps when the app increases cognitive load during already-stressful commutes, when it does not respect local device realities, or when it silently breaks existing informal workarounds that employees rely on to feel safe and in control. Admin teams reduce revolt risk when they treat app rollout like a shift-critical change process, with guarded pilots, human backup options, and explicit safeguards for safety and attendance.
Common adoption pitfalls appear at multiple layers of the rider experience. A frequent failure mode is OTP and boarding flows that are too rigid or slow for real-world shift pressure. Employees abandon apps that require multiple OTP steps at 2 a.m., that expire OTPs during low network coverage, or that block boarding if the app or GPS glitches. Language and UX mismatches are another cause of rejection. Riders lose trust in apps that rely on dense English-only text, tiny buttons, or unclear icons, especially when many frontline staff are more comfortable with regional languages and simple, visual cues.
Device and connectivity constraints strongly influence adoption in India. Apps that assume the latest Android versions, large storage, and always-on mobile data fail among contract staff who share devices, have limited storage, or keep data switched off between shifts. Battery-heavy live-tracking or GPS polling causes users to uninstall or force-stop apps. Strict dependency on GPS or network for boarding, SOS, or check-in creates anxiety when riders know that monsoon conditions, basement parking, or remote project sites frequently break connectivity, as seen in WTicabs’ monsoon-operations case studies.
Change management design is as important as UX design. A common pitfall is treating the app as a mandatory overnight switch rather than a co-pilot to existing SOPs. Employees push back when they feel the app is a surveillance tool with no clear benefit to them, especially if it appears suddenly without clear communication on safety features, SOS escalation, or complaint closure SLAs. If night-shift women employees feel that verified drivers, escort rules, or call-center support are being quietly replaced by “just use the app,” morale and trust erode quickly.
Admin and Transport teams can de-risk rollout by designing a staged, operations-first pilot. The safest pattern is to run the new rider app in parallel with existing manual or semi-manual processes, such as call-center based rostering or SMS-based confirmations, for at least one or two full roster cycles. During this period, riders should be allowed to board even if OTP or app check-in fails, with the driver app, command center, or transport desk authorised to override and record the trip. This mirrors the “manual operation mode” and command-center override capabilities shown in WTicabs’ technology collateral.
A practical pilot playbook usually includes a limited cohort rollout, clear benefit messaging, and on-ground support. Admin teams get better adoption when they start with one or two locations or specific shifts, publish a simple “how your commute changes” one-pager, and emphasise visible benefits such as live tracking, SOS buttons, and predictable routing rather than just “digitization.” On-ground help during the first weeks, such as transport coordinators or floor walkers helping employees with app install, login, and first-trip check-in, reduces friction and escalations.
Feedback loops and observability are critical for preventing morale damage. Admin teams should monitor specific KPIs during pilots, such as app-based check-in success rate, exceptions resolved without delaying trips, and complaint closure time. Short, focused surveys after a week or two, particularly for night-shift and women riders, help detect patterns like confusing OTP screens, battery complaints, or language issues. Rapid, visible fixes to these issues signal respect for employee input and reduce perceptions that technology is being forced without listening.
Safety and attendance assurances need to be explicit. Employees accept new apps more easily when they know that their ability to reach the site, get paid for the shift, and stay safe does not depend entirely on an app working perfectly every day. Written SOPs that state “no employee will be penalised for app failures,” combined with clear escalation contacts at the command centre or transport desk, preserve trust. This aligns with the 24/7 centralized monitoring, SOS, and women-centric safety protocols highlighted in WTicabs’ safety and command-centre material.
To keep operations stable, Admin teams can use a few disciplined steps when piloting app changes:
- Start with pilot cohorts and timebands where on-ground support and backup vehicles are readily available.
- Maintain manual or hybrid options for boarding and trip verification until app error rates fall below an agreed threshold.
- Involve HR and Security in communications so safety and policy implications are clearly addressed.
When Admin treats the rider app as part of a governed EMS operation, with command-centre observability, safety redundancies, and employee feedback loops, adoption improves, escalations fall, and morale remains stable even as underlying processes become more digital and data-driven.
safety, communication playbooks, and fatigue management
Build safety-first reporting channels and clear comms playbooks that protect privacy, reduce fatigue, and keep frontline teams empowered to act without burnout.
How do we collect feedback in a way that leads to visible actions (‘you said, we did’) instead of just ratings with no follow-through?
B0412 Make feedback visibly actionable — In India’s shift transport (EMS), how do you design feedback collection so it doesn’t become performative (ratings with no action), and employees can see ‘you said, we did’ outcomes tied to grievance SLAs?
Effective EMS feedback in India works only when every complaint is traceable to an owner, a closure SLA, and a visible “you said, we did” loop that employees can see. Feedback must feed a live ticketing and command-center workflow, not just a rating screen at trip end.
Most organizations fail when feedback is anonymous, non-mandatory, and decoupled from the Transport Command Centre and escalation matrix. Feedback then becomes a dead-end star rating. A better design links rider apps, driver apps, and the command centre so every low rating or safety flag automatically creates a case with time-stamped status, just like the SOS control panel and alert supervision systems described in the collateral.
The “you said, we did” loop becomes credible when the EMS platform surfaces outcomes back to employees. The employee app should show case status, resolution notes, and SLA timers in the same place as trip history, mirroring how CO₂ reductions and EV metrics are surfaced on dashboards for ESG. Monthly or quarterly summaries can highlight resolved themes such as “route optimization during monsoon” or “driver retraining under the Driver Management & Training framework.”
To keep it operationally calm for a Facility / Transport Head, the command centre should auto-prioritize feedback by risk (safety, OTP, comfort) and auto-route it to the right owner using the escalation mechanism and matrix. Closure performance must show up in the same single-window dashboards that already track OTP, safety alerts, and billing accuracy, so leadership can see grievance SLA compliance alongside core KPIs.
- Define clear feedback categories mapped to owners and SLAs.
- Auto-convert low ratings and safety flags into tickets in the command centre.
- Expose ticket status and resolution to employees inside the app.
- Publish periodic “you said, we did” summaries with hard numbers.
- Review grievance KPIs in governance and account-management forums.
In a multi-vendor setup, how do we set grievance SLAs/penalties so vendors don’t just suppress complaints or fight classifications, and quality genuinely improves?
B0413 Prevent SLA gaming by vendors — In India’s corporate EMS with multi-vendor aggregation, how can Procurement structure grievance SLAs and penalties so vendors don’t simply suppress complaints or argue classifications, but service quality actually improves?
Procurement teams in India’s corporate EMS improve service quality when grievance SLAs are tied to speed and quality of resolution, correlated with independent data sources, and protected by “no-retaliation, no-suppression” design. Penalties should target patterns of poor closure, repeat issues, and audit failures rather than raw complaint volume so vendors are rewarded for visibility and fixes, not for hiding problems.
Procurement should first define grievance SLAs on objectively measurable events. Each complaint should have a unique ID, time-stamped creation, severity tag, and closure time. Closure quality should be checked via mandatory employee feedback, transport head validation for serious incidents, and randomized audits by HR or Security. This reduces scope for vendors to downgrade severity or claim informal closure.
Penalties should apply to closure SLA miss percentages, repeat incidents by route, driver, or vendor, and discrepancies between app logs, command center data, and billing. Incentives can be linked to high closure compliance, falling repeat-incident rates, and stable or improving Commute Experience Index. This improves behavior because vendors see that documented issues with fast, durable fixes are commercially safer than denial.
Procurement should mandate transparent data access and classification rules in the contract. Grievance records must be generated from the EMS platform or command center, not vendor Excel sheets. Any unilateral downgrading of severity, deletion, or late logging should itself count as a critical SLA breach with higher penalties. This discourages complaint suppression.
To keep vendors engaged rather than defensive, Procurement can structure a small “continuous improvement” pool. Vendors can earn back part of penalties through demonstrable improvement projects that reduce driver fatigue, routing errors, or safety exceptions identified in grievances. This maintains commercial pressure while signaling that visibility plus corrective action is the desired outcome, not zero recorded complaints.
What should ‘grievance closed’ mean for HR, Facilities, and the vendor—employee confirmation, fix done, or RCA documented—and what breaks when we don’t agree?
B0414 Define ‘closed’ grievance — In India’s corporate employee commute (EMS), what should be the shared definition of a “closed” grievance between HR, Facilities, and the vendor NOC—employee confirmation, operational fix, or documented RCA—and what goes wrong when those definitions differ?
A grievance in employee commute should be defined as “closed” only when three conditions are all met. The employee has explicitly confirmed satisfaction, the operational fix has been implemented and verified in live runs, and a documented RCA with a preventive action is logged in the system. Any weaker definition shifts the problem into the next shift instead of removing it from the system.
Most organizations treat a grievance as closed at a different stage. HR tends to anchor closure on employee experience and expects explicit confirmation. The Facility or Transport Head often prioritizes operational continuity and may treat a case as closed once the immediate workaround is in place and the next shift is protected. The vendor NOC and command center usually frame closure as an internal ticket status, which changes once a response is logged, even if the root cause and SOP updates are pending.
When these definitions diverge, several predictable failure modes appear. Escalation volume stays high because the same issue recurs under new tickets. HR loses credibility because employees keep seeing repeat failures despite being told issues are “resolved.” Facilities lose control-room stability because known edge cases are not converted into routing rules, buffer capacity, or Business Continuity Plan actions. Vendor NOC metrics look healthy on paper, but OTP%, incident rate, and user satisfaction index stagnate or deteriorate. During audits or board reviews, Safety, ESG, or Finance cannot reconcile complaint, SLA, and billing data because the grievance lifecycle is not consistently defined or logged across systems.
A shared, practical definition of “closed” therefore requires three non-negotiable checks. There must be employee-level closure captured in the app or through the command center. There must be operational validation that the fix has worked over at least one or two comparable shifts or routes. There must be a documented RCA and preventive control reflected in routing, capacity planning, compliance dashboards, or BCP playbooks. Only this three-part definition reduces nightly firefighting and makes grievance metrics a reliable proxy for real operational stability.
How can we credibly link commute experience issues to attendance and attrition without overclaiming causality when Finance challenges it?
B0415 Link UX to HR outcomes — In India’s employee transport (EMS) for large shift-based workforces, what’s a realistic way to connect commute experience issues (missed pickups, rude driver behavior, unsafe feel) to HR outcomes like attendance volatility and attrition—without overclaiming causality to the CFO?
In Indian employee transport programs, commute experience issues should be linked to HR outcomes using correlated operational and HR patterns with clear caveats, not absolute causality claims. The most realistic position is that poor commute reliability and safety correlate with attendance volatility and attrition, and that transport is a controllable risk factor and amplifier, not the single root cause.
The starting point is to treat transport as one input in a broader employee experience and attendance system. HR teams can compare OTP%, missed-pickup incidents, and safety complaints at route or site level with HRMS data on late logins, short leave, and team-level attrition. A consistent pattern across routes and time bands is reasonable evidence of influence, especially in night shifts and female-employee cohorts where safety concerns are more acute.
CFOs and Finance teams usually react badly to statements that commute “causes” attrition, because many variables drive exits. A more defensible framing is that unreliable or unsafe commutes increase friction for employees who are already under pressure, and that this shows up as higher no-show rates, more short leaves around specific shifts, and elevated exit risk in affected cohorts. This framing preserves credibility and still justifies operational improvements.
To keep claims realistic, HR and Transport leaders can present commute metrics and HR metrics on the same dashboard while being explicit that these are associations. They can position investments in EMS reliability, safety compliance, and employee apps as ways to de-risk attendance and retention, rather than as guaranteed cost savings. CFOs tend to accept this argument more readily when they see that mobility data is audit-ready, traceable, and integrated with HRMS rather than based on anecdotes or survey snippets.
How do we ensure employees, especially women on night shifts, feel safe reporting issues if they fear manager backlash or being ‘noticed’?
B0416 Enable safe issue reporting — In India’s corporate ground transportation (EMS), how do HR leaders protect psychological safety so employees—especially women on night shifts—actually report issues, when they suspect complaints will ‘get them noticed’ by managers?
In Indian employee mobility programs, HR leaders protect psychological safety when they make reporting commute issues low-friction, low-visibility, and clearly separated from performance evaluation. Employees trust the system more when complaints go into an auditable safety channel, not to their manager’s WhatsApp or the transport desk’s shared phone.
HR leaders who succeed usually remove three specific fears. They separate transport feedback from line-manager appraisal data. They formalize women-safety and night-shift protocols as policy, then show employees that using SOS, helplines, or apps will never be held against them. They route all serious incidents through a centralized command center or transport control centre, with a documented escalation matrix and closure SLA, so employees see action instead of blame.
A common failure mode is asking employees to “tell your manager or admin if there is any issue.” That approach ties safety reporting directly to hierarchy. It also creates data that is not traceable or audit-ready. Transport command centers, alert supervision systems, and SOS dashboards provide a safer pattern. They centralize alerts like geofence violations, device tampering, over-speeding, and SOS triggers. They also create a chain of custody for every complaint, which can be shown to HR, Security, and auditors.
To keep psychological safety intact, organizations need clear, simple SOPs that are repeated in every induction and shift briefing. Employees must know which app button, number, or channel to use for safety, and they must hear the same message from HR, transport, and security: “If you feel unsafe, use it. This is about your safety, not your rating.”
Practical guardrails HR leaders can put in place include:
- A dedicated, 24/7 safety or women-safety cell that sits outside the reporting line of managers.
- Anonymized or non-attributable pattern analysis for recurring issues (route, driver, vendor) instead of naming employees in routine reviews.
- Formal instructions to managers that no appraisal, shift-allocation, or roster privilege may be linked to who raised commute complaints.
- Joint HR–Security reviews of incident logs and user satisfaction indices, so patterns trigger vendor or route corrections instead of informal pushback on complainants.
When HR combines these policy guardrails with a central command center, app-based SOS, and a documented business continuity plan for incidents, employees see that the organization is prepared. That reduces the fear of “getting noticed for the wrong reasons” and turns commute reporting into a normal, safe part of daily operations rather than a career risk.
After an incident, what minimum evidence should HR have ready—logs, grievance history, response timelines—so we don’t look unprepared to leadership?
B0417 Minimum evidence for leadership — In India’s corporate EMS, when leadership asks HR after an incident, “How often does this happen and what changed since last quarter?”, what minimum evidence (incident logs, grievance history, response timelines, communications) must exist to avoid HR looking unprepared?
In India’s corporate EMS, HR avoids looking unprepared only when every incident and grievance is captured in a structured, time-stamped trail that can be sliced by period, severity, and closure status. The minimum bar is a single source of truth that shows “what happened, how often, how fast we responded, and what we changed” with auditable detail, not anecdotes.
At a basic level, incident and grievance logs need unique IDs, date–time stamps, trip and route references, employee identifiers, driver and vehicle tags, severity classification, and a closed-loop status field. The same record should show detection time, acknowledgment time, escalation time, and closure time so HR can state average and worst-case response timelines. Logs need to be filterable by timeband, gender, site, vendor, and type of issue so comparisons “since last quarter” are evidence-based rather than narrative.
Communications and actions must be anchored back to those IDs. Every major incident should have a linked communication record that shows who was informed (employee, manager, security, transport, leadership), on which channel, and within what time window. Corrective actions need explicit entries such as driver retraining, route change, vendor warning, or protocol update so HR can point to concrete changes rather than generic “sensitization.”
To answer “how often does this happen?” credibly, HR requires quarterly summary views that aggregate incident counts, women-safety escalations, SOS activations, and transport complaints, along with trend deltas versus the previous quarter. To answer “what changed?” HR needs a dated register of policy and SOP changes in EMS, vendor governance actions, and safety training sessions, all cross-referenced to incident patterns and command center observations like on-time performance and exception closure SLAs.
What operational changes usually reduce repetitive commute complaints (cold, crowded, pickup chaos), and how do we confirm the fixes really stuck over a few weeks?
B0418 Reduce repetitive complaints sustainably — In India’s employee commute operations (EMS), what operational changes typically reduce the volume of repetitive “it’s too cold / too crowded / double-booked pickup point” complaints, and how do Facilities teams verify the fixes actually stuck over multiple weeks?
In India’s employee commute operations, repetitive comfort and routing complaints reduce when organizations standardize how capacity is planned, how rosters are locked, and how real-time exceptions are handled through a command-center rather than ad-hoc driver decisions. Facilities teams then verify the fixes through route-level dashboards, exception reports, and feedback trends tied to shift-wise OTP and seat-fill metrics over several weeks.
Most operators first stabilize basic supply and routing. Facilities teams introduce structured ETS operation cycles with clear steps from booking to routing, vendor distribution, tracking, shift reports, and MIS. Dynamic route optimization is used to manage weather and congestion, which reduces “double-booked pickup point” and “driver changed route” noise. Capacity planning is tightened using package options and operating models that define duty duration, distance slabs, and fleet type, which helps avoid chronically overcrowded cabs on specific shifts.
Comfort issues like “too cold” are handled through SOPs for chauffeurs and induction frameworks that detail vehicle condition, amenities, and driver behavior. Daily shift-wise briefings reinforce rules on AC usage, seating discipline, and women-centric safety protocols so drivers do not improvise under pressure. Facilities heads back this with a structured driver management and training program and periodic audits using vehicle deployment and quality assurance checklists.
To verify that changes have stuck, Facilities teams rely on a single-window dashboard system and indicative management reports that consolidate deviation reports, user feedback, and safety or service issues. They track complaint categories over time against on-time performance, trip fill ratios, and no-show reports. They also use data-driven insights platforms and command centre operations to monitor route adherence, geofence violations, and live alerts, ensuring that any resurgence in overcrowding, routing conflicts, or repeated comfort issues is caught early and pushed back into driver coaching and routing adjustments.
Should we manage commute grievances in the mobility platform or in our ITSM tool, if our priority is faster closure and clear ownership (not more tools)?
B0419 Mobility platform vs ITSM — In India’s corporate EMS, how should IT and HR decide whether to run grievance management inside the mobility platform versus in an enterprise ITSM/ticketing tool, if the goal is fast closure and clear accountability rather than tool sprawl?
In India’s corporate EMS, grievance management works best when capture and context live in the mobility platform, while ownership, SLAs, and audit trails run through the enterprise ITSM or ticketing tool. This pattern preserves fast closure at the command center level and gives HR and IT one accountable, enterprise-wide system of record.
A common failure mode is pushing everything into the mobility platform. Transport teams then see issues quickly, but HR, IT, Security, and Finance lose visibility, and grievance data is fragmented from HRMS, audits, and risk registers. The opposite failure mode is forcing employees and drivers to leave the EMS app and log tickets in a generic ITSM. That breaks real-time command center workflows and slows response during night-shift incidents.
Most organizations resolve this by keeping the “front door” for complaints inside the EMS stack and routing the grievance payload into the ITSM via APIs. The mobility platform supplies rich trip context, GPS logs, driver IDs, and routing data. The ITSM supplies queueing, cross-functional workflows, escalation matrices, and closure SLAs that span HR, Security, and Transport.
When deciding architecture, IT and HR can use a few concrete criteria:
- Use the EMS platform for on-trip and post-trip capture when the complaint is time-sensitive or safety-adjacent.
- Use the enterprise ITSM as the canonical ledger for all grievances that require cross-functional action, auditability, or policy enforcement.
- Require bi-directional sync so the command center sees ticket status, and the ITSM keeps immutable trip and incident evidence.
- Standardize SLAs and ownership in the ITSM, but expose simplified status and escalation paths in the employee and driver apps.
This approach supports fast, on-ground decision-making through the command center and centralized observability, privacy control, and evidence retention through ITSM and HR systems, without adding another standalone tool to maintain.
What signs show the feedback process is turning into HR vs Facilities blame, and how do we reset shared accountability?
B0420 Stop HR–Facilities blame loop — In India’s shift-based EMS programs, what are the warning signs that “feedback loops” are becoming a blame engine between HR and Facilities (HR saying ops is failing; ops saying HR is overreacting), and how do leaders reset shared accountability?
In India’s shift-based employee mobility services, feedback loops turn into a blame engine when feedback stops changing operations and instead becomes ammunition in HR–Facilities conversations. A clear warning sign is when recurring commute complaints and safety concerns show up in multiple forums, but roster design, routing, and vendor behavior remain unchanged.
Another signal is when HR and Facilities run on different “truths.” HR cites anonymous surveys or social media posts. Facilities cites trip logs and GPS data. Neither side can reconcile OTP%, incident counts, or no-show reasons from a single dashboard. At that point, feedback meetings become argument sessions about whose data is right, not what needs to change. Escalations that bypass SOPs and go directly to business heads or CHROs are a further indicator that structured feedback has lost credibility.
Leaders reset accountability by standardizing one observable metric set for EMS, such as OTP%, incident rate, complaint closure SLA, and Trip Adherence Rate. They route all employee feedback, safety complaints, and transport desk issues into a single command-center view that both HR and Facilities use. They also define which issues are HR-policy decisions versus transport-SOP decisions, so that HR owns night-shift and women-safety policy, while Facilities owns vendor SLAs, routing, and driver compliance.
To keep feedback loops productive, leadership can run short, time-boxed improvement sprints. Each sprint has a clear owner on HR and on Facilities, fixed KPIs, and pre-agreed actions, like route recalibration or driver coaching. This shifts the conversation from “who failed” to “what changed in OTP%, safety incidents, and commute experience index after we acted.”
How do we avoid grievance SLAs pushing teams to close tickets fast with templates instead of fixing the real issue and building trust?
B0421 Avoid superficial grievance closures — In India’s corporate employee transport (EMS), how do you prevent grievance SLAs from incentivizing superficial closures (quick acknowledgements, templated responses) instead of genuine fixes that improve employee trust?
In Indian corporate employee transport, grievance SLAs stop incentivizing superficial closures when they are tied to verifiable trip outcomes and repeat‑incident patterns, not just timestamped “ticket closed” events. Genuine fixes emerge when organizations measure grievance prevention and trust indicators alongside response time, and when command centers are governed on root‑cause removal, not inbox clearance.
Most operations teams over‑optimize on first response and closure TAT, which pushes agents toward quick acknowledgements and template replies. A more resilient model treats the Transport Command Centre and Alert Supervision System as outcome owners for OTP%, safety incidents, and repeat complaints. This model uses data from trip logs, GPS tracking, SOS workflows, and women‑safety protocols to validate whether the underlying EMS issue actually changed on the ground.
Grievance SLAs work better when they explicitly include second‑order signals such as recurrence of the same issue on the same route, repeat complaints against a driver despite compliance checks, or patterns of no‑shows and routing failures in a shift window. Centralized dashboards and indicative management reports already track OTP, deviations, safety alerts, and exception handling, so grievance metrics can be layered on top as “closure quality” rather than only “closure speed”.
A practical guardrail is to split SLAs into a small set of clear bands:
- Response SLA for acknowledgement and initial triage.
- Resolution SLA only counted when route, driver, or process changes are implemented and visible in ETS/Commutr rosters and routing.
- Recurrence SLA that penalizes repeat complaints on the same root cause within a defined period.
- Experience SLA using user satisfaction indices, shift‑wise feedback, and women‑safety survey scores tied back to specific routes and vendors.
Linking vendor commercials and internal performance reviews to these layered SLAs changes behavior. Transport heads and vendors then have an incentive to use data‑driven insights, driver training, fleet compliance checks, and business continuity playbooks to remove systemic issues. This reduces night‑shift firefighting and escalations, and over time it builds employee trust because users see fewer reasons to complain, not just faster replies when they do.
For high-risk cases like a women-safety allegation or a viral post, what should the exec escalation protocol be so Legal, HR, and Security act fast but still follow due process?
B0422 Protocol for sensitive escalations — In India’s corporate ground transportation for employees (EMS), what should an executive escalation protocol look like for reputationally sensitive cases (women-safety allegation, harassment claim, viral social post) so Legal, HR, and Security move fast without compromising due process?
In reputationally sensitive EMS cases, an effective escalation protocol in India routes every incident through a single command channel within minutes, assigns legal/HR/security ownership early, and locks an evidence trail before narrative or blame starts spreading. The protocol must prioritize immediate employee safety and containment while deferring judgments until facts are verified and documented.
A strong protocol starts with automatic alerting from the transport command center or SOS system to a named “critical incident cell” that includes HR, Legal, Security/EHS, and the Transport Head. The first actions are operational and safety-focused. The employee is contacted and secured. The vehicle is tracked and immobilized if required. The driver is stood down from duty pending enquiry. GPS traces, trip logs, IVMS/dashcam footage, driver credentials, and call-center records are frozen to protect auditability.
Due process depends on clean separation of roles. Security/EHS reconstructs the physical sequence using trip data, rosters, and geo-fencing logs. HR manages the employee’s immediate needs, communication, and non-retaliation assurances. Legal vets every external-facing step, including responses to police, regulators, or viral posts, to avoid defamation or privacy breaches. Transport operations supply data but avoid informal “clearing” of drivers or vendors.
Time-bound steps keep Legal, HR, and Security aligned. Within 30–60 minutes the incident cell decides on interim measures such as driver suspension, escort adjustments, or route lockouts. Within 24 hours a documented preliminary report is prepared using a standard template that maps incident facts, data sources, and open questions. Only designated spokespeople communicate with leadership, the employee, and (if needed) law enforcement, ensuring the organization does not appear to prejudge guilt or dismiss the complaint.
To prevent escalation chaos, organizations use predefined severity tiers, escalation matrices, and command-center SOPs. Reputationally sensitive cases involving women, night shifts, or social media virality are always treated as top-tier. These cases trigger automatic leadership notification, mandatory Legal review, and enhanced monitoring for similar routes or drivers. The same protocol later feeds into audits, board-level safety reviews, and ESG or diversity reporting, providing defensible evidence that the company acted quickly, fairly, and traceably.
How do we measure if a new grievance process is actually reducing calls, follow-ups, and escalations for the transport desk—not just improving dashboard numbers?
B0423 Measure operational drag reduction — In India’s employee mobility services (EMS), how do Admin and HR leaders measure whether a new grievance process is reducing operational drag (calls, manual follow-ups, escalations) for the transport desk, not just improving dashboard metrics?
Admin and HR leaders in India’s employee mobility services measure whether a new grievance process is reducing operational drag by tracking shifts in real-world workload on the transport desk, not just improvements in ticket dashboards or NPS scores. They rely on evidence that inbound noise, exception handling time, and manual coordination are actually going down across shifts and locations.
The most practical indicator is the volume and pattern of “unstructured” contacts to the transport desk. Leaders compare pre‑ and post‑implementation counts of calls, WhatsApp messages, and ad‑hoc emails about cabs, routing, and safety, and check whether more issues are entering through a structured app or command-center workflow instead of direct personal calls. A second measure is exception latency, where they use command-center or alert systems to see if geofence violations, delays, and SOS events are being resolved faster with fewer manual interventions needed to close each incident.
Leaders also review escalation matrices and on‑time performance reports to see whether fewer issues need to move up to HR, Security, or senior Admin, and whether SLA breaches are being closed through defined SOPs rather than one-off follow-ups. They use indicative management reports, centralized dashboards, and transport command-center logs to correlate user complaints, deviation reports, and safety alerts with the number of manual follow-ups and field interventions required.
Qualitative checks remain important alongside data. Admin and HR leaders hold floor connects with shift supervisors, transport desk staff, and command-center teams to validate whether night shifts feel calmer, if fewer drivers and employees bypass the system, and if business continuity playbooks are being used less frequently. When desk staff report fewer last-minute roster changes, reduced need for manual rerouting during disruption scenarios, and more predictable closure of safety or women-centric complaints, leaders treat this as evidence that operational drag is falling rather than just being better visualized.
When we change pooling or routes due to hybrid attendance, how do we communicate it so employees see it as fair and caring, not just cost-cutting?
B0424 Communicate policy changes fairly — In India’s EMS for hybrid-work attendance variability, how should HR communicate policy changes (cutoffs, route rationalization, pooling rules) so employees perceive fairness and care, rather than cost-cutting that hurts morale?
Core principle
Employees perceive transport policy changes as fair and care-led when HR links them transparently to safety, reliability, and predictability, and backs this with clear rules, advance notice, and data-backed communication. Employees see changes as pure cost-cutting when the “why,” “who is impacted,” and “what safeguards exist” are left vague.
How to frame the “why”
HR should explicitly connect new cutoffs, pooling rules, and route rationalization to hybrid-work realities like variable attendance, traffic risks, and the need to protect on-time performance and safety for night shifts. HR should state that EMS is being tuned to meet duty-of-care obligations and shift adherence, not to shift risk or inconvenience to employees.
HR should explain how routing and pooling support fewer last-minute failures, better driver fatigue management, and stronger compliance with women-safety and night-shift regulations. HR should acknowledge trade-offs openly, such as slightly earlier cutoffs enabling higher reliability and fewer escalations.
How to design and announce the rules
HR should publish simple, stable SOPs for booking cutoffs, pooling criteria, and minimum seat-fill that employees can reference. HR should give advance notice before changes take effect and run overlap periods where supervisors can override rules for genuine business-critical cases.
HR should coordinate with the Facility / Transport Head so command-center and helpdesk teams can explain the same logic consistently during escalations. HR should include examples by shift type or location to show that high-risk windows, such as late-night for women employees, keep stricter safety-first routing and escort norms.
Evidence and feedback to protect morale
HR should share high-level metrics, such as improvements in on-time performance or reduction in no-shows, after policy changes to demonstrate operational benefits to employees. HR should offer clear escalation paths and a simple feedback loop in the employee app or HRMS so edge cases are heard and patterns of unfair impact can be corrected.
HR should review complaints, attendance volatility, and employee satisfaction scores by route and shift in partnership with Transport and Security, and be prepared to adjust pooling thresholds or cutoffs where the data shows genuine hardship rather than abuse.
- State safety and reliability as primary goals, with cost efficiency as a secondary outcome.
- Explain concrete operational constraints like fleet uptime, driver duty cycles, and hybrid attendance variability.
- Codify exceptions for vulnerable cohorts such as women on night shifts and employees in low-connectivity areas.
- Commit to a time-bound review of the policy with published adjustment criteria.
Why do employees usually distrust commute feedback channels, and what changes build trust (like anonymity and visible actions) without opening the door to misuse?
B0425 Restore trust in feedback — In India’s corporate EMS, what are the most common reasons employees distrust commute feedback channels (no anonymity, no action, fear of retaliation), and what design choices restore trust without encouraging misuse?
In India’s corporate employee mobility services, employees usually distrust commute feedback channels because the channels feel traceable, nothing visibly changes after complaints, and past incidents suggest that complainers get labelled as “troublemakers.”
Trust is restored when the system separates identity from case-handling, guarantees visible and time-bound action, and routes sensitive inputs through independent or higher-level reviewers with clear anti-retaliation rules and pattern-based misuse controls.
Most employees assume feedback is not anonymous because apps link directly to employee IDs, trip manifests, and GPS logs. Employees see that transport desks, vendors, and even specific drivers can often infer “who complained” on a given route or shift. A common failure mode is giving location and trip-level detail to vendors without masking employee identity, which makes retaliation or social friction with drivers more likely.
Fear of retaliation increases when drivers, supervisors, or line managers informally confront employees after a complaint. This fear rises if vendors control routing and allocation, if women-safety protocols exist only on paper, or if there is no visible escalation matrix above the vendor and transport desk. Night-shift workers and women employees are especially cautious when prior complaints have led to argument, subtle route-level harassment, or being dropped from preferred shifts.
Perception that “nothing happens” is reinforced when employees repeatedly report late pickups, unsafe driving, or app glitches but OTP, driver behaviour, and routing do not improve. When feedback is not acknowledged with a ticket ID, closure note, or visible change in routing or driver allocation, employees downgrade the channel to “venting” rather than a risk-control tool.
Practical design choices that restore trust start with clear separation of data and decision-making. Identity should be collected for audit and follow-up but protected behind role-based access, with frontline vendors and drivers seeing only anonymized issues and patterns. Sensitive complaints, especially on women’s safety, should route directly to HR, Security/EHS, or a command center with an explicit non-retaliation policy and predefined response SOPs.
Each feedback item should generate a trackable ticket with a simple status timeline. Time-bound SLAs for acknowledgement and closure, plus summary changes communicated back to employees by channel (e.g., “driver reassigned,” “route audited,” “escort added”), create a cause–effect loop. When employees see that their inputs trigger re-training, driver rotation, or routing changes, they start using the channel earlier, before incidents escalate.
Misuse can be contained by designing pattern-based controls rather than restricting genuine complaints. Systems should correlate complaints with trip logs, GPS data, and other employee feedback on the same driver or route to distinguish isolated, potentially malicious reports from corroborated patterns. Clear policy communication that frivolous or bad-faith complaints can themselves be investigated helps set behavioural expectations without discouraging legitimate safety or reliability reports.
Transport heads and command centers gain operational calm when feedback design reduces direct interpersonal confrontations. When apps provide structured categories, optional anonymous flags for high-risk issues, and escalation routes that bypass local conflicts, employees are less likely to resort to informal WhatsApp or late-night calls. This also improves data quality for route optimization, driver coaching, and safety audits, while keeping daily firefighting under control.
When vendors claim they improved commute NPS, how do we validate it given NPS can be manipulated by sampling and timing?
B0426 Validate vendor NPS claims — In India’s employee transport (EMS), how should Procurement and HR evaluate vendor claims like “we improved commute NPS” when NPS can be manipulated by timing, sampling, and forced ratings?
In India’s employee transport, Procurement and HR should treat “we improved commute NPS” as a weak claim unless the vendor can show how NPS is captured, governed, and linked to independent operational data. Vendor NPS is credible only when sampling, question design, and response flows are controlled, auditable, and correlated with metrics like OTP, incident logs, and complaint closure SLAs from the command center or EMS platform.
Procurement and HR should insist on seeing the full measurement design. A robust commute NPS program uses the same question and scale for all vendors, avoids leading language, and does not force ratings through app design tricks. A serious failure mode is when only successful trips or “happy-hour” timebands are sampled, or when low-scoring employees are steered away from feedback flows, which inflates apparent satisfaction but hides structural reliability gaps.
Stronger evaluation comes from triangulation. Organizations should compare vendor-reported NPS with independent indicators such as on-time performance percentages, no‑show and cancellation patterns, safety incidents, women-safety escalations, and ticket resolution times from the centralized command center or transport command centre dashboards. Commute sentiment is far more trustworthy when HRMS-linked attendance stability, attrition in transport-dependent teams, and complaint volumes move in the same direction as NPS.
For due diligence, Procurement and HR can use a simple checklist: - Require raw, anonymized survey exports with timestamps, trip IDs, and opt‑out rates. - Verify that surveys trigger across all shifts, routes, and personas, including night shifts and female employees. - Check that negative feedback leads to trackable tickets with closure timestamps. - Ask for at least one longitudinal view where a route or site’s NPS trend aligns with changes in OTP, EMS routing optimization, or vendor changes.
Most organizations gain control when they own the NPS program on their EMS platform or HRMS, rather than letting each vendor run separate, opaque surveys. Vendor claims like “we improved commute NPS” are then validated against an enterprise-governed measurement layer, which reduces manipulation risk and makes NPS a usable signal for SLA governance and outcome-linked procurement instead of a marketing number.
What automation can we set up (auto-escalations, routing, templates) to reduce transport-desk stress without making replies feel robotic to employees?
B0427 Automation without robotic feel — In India’s corporate employee mobility (EMS), what are practical “set it and forget it” configurations (auto-escalations, standard response templates, ownership routing) that reduce daily transport-desk stress without making responses feel robotic to employees?
In Indian employee mobility operations, the lowest‑stress setup uses a few pre‑defined, rule‑based configurations that auto‑triage issues but still route a human quickly for anything sensitive or unusual. These configurations sit on top of the routing engine, trip logs, and the command center so the transport desk is not manually chasing every delay, GPS fault, or driver issue.
The most effective patterns start with auto‑escalations driven by clear EMS KPIs. Delays beyond a defined OTP threshold, repeated geo‑fence violations, device‑tamper alerts, or SOS triggers should auto‑create incidents in the command center with priority and owner pre‑assigned. Safety‑linked alerts such as women’s night‑shift trips, escort non‑availability, or route deviations need a stricter rule set and should go straight to Security or EHS leads, with the NOC watching closure SLAs.
Standard response templates work when they are context‑aware. The system should pull live trip data, ETA, and driver details into the message so employees see the response as specific to their situation rather than a generic apology. Messages for traffic delays, vehicle breakdowns, or roster mismatches can share accurate ETAs, escalation paths, and basic reassurance. Templates for safety or SOS events should be minimal and focused on confirmation and reassurance, with follow‑up handled by a human.
Ownership routing reduces confusion inside the transport function. Issues mapped to categories such as routing and rostering, driver behavior and fatigue, app or GPS failure, vendor non‑availability, and compliance or safety should auto‑assign to named roles in the command center and vendors, not to a generic inbox. Closure SLAs for each category can be tracked in a single dashboard so the Facility or Transport Head sees patterns, not just noise.
A practical “set it and forget it” design uses automation only for first‑line triage and updates. The system handles routine status messages and incident logging, while the command center focuses on exceptions where judgment, empathy, and cross‑functional coordination with HR, Security, or vendors are required. This balance keeps responses fast and predictable for employees without turning the experience into a rigid, robotic workflow for edge cases or safety‑critical situations.
How do we decide when commute issues need a bigger employer brand response (townhall/leadership note) vs quiet operational fixes?
B0428 When to escalate to brand — In India’s corporate ground transportation (EMS), how do senior HR leaders decide when commute issues have crossed the threshold to warrant an employer brand intervention (townhall, leadership note, policy change) versus handling quietly through operational fixes?
In India’s employee mobility context, senior HR leaders usually trigger an employer brand intervention only when commute issues start eroding trust, safety confidence, or talent outcomes at scale. Day‑to‑day delays and isolated errors are typically managed quietly through EMS vendors, transport teams, and command‑center SOPs as long as HR can show leadership that issues are known, contained, and trending down with evidence.
HR leaders treat commute problems as an employer brand risk when they see persistent patterns linked to safety, women’s night‑shift experience, or attendance and attrition. Repeated safety escalations, visible social‑media chatter, or women‑centric incidents push them beyond “ops noise” into “reputational threat,” especially where duty‑of‑care and night‑shift escort norms apply. At that point, they look for audit‑ready trip logs, incident workflows, and command‑center evidence to decide whether a formal townhall, leadership note, or explicit women‑safety reinforcement is needed.
The decision is also shaped by data and accountability. HR escalates publicly when commute complaints show up in surveys or NPS, when OTP misses begin to affect shift adherence and manager productivity, or when they cannot answer basic leadership questions about “how often” and “what’s changing” from a centralized EMS dashboard. When telemetry, BCP playbooks, and vendor governance show that issues are localized, improving, and backed by SLAs, HR tends to stay in the background and drive corrective actions through routing tweaks, driver retraining, and command‑center tightening rather than front‑facing brand commitments or policy resets.
For our employee transport program, how can we tell if commute issues are actually hurting our employer brand and increasing attrition—not just creating noise and complaints?
B0429 Link commute pain to attrition — In India’s corporate Employee Mobility Services (EMS) for shift-based employee transport, how do you diagnose whether commute dissatisfaction is materially impacting employer brand (EVP) and attrition—beyond anecdotal complaints from managers and employees?
Employer brand and attrition impact from commute dissatisfaction can be diagnosed only when transport data, HR data, and employee feedback are linked into a single, auditable view rather than relying on complaints alone.
Most organizations start by correlating basic EMS reliability metrics with HR outcomes. Transport teams track on-time performance, trip adherence, no-show rates, and exception closure times from the command center. HR teams track attendance volatility, late logins, and location or shift-wise attrition. When recurring low OTP or frequent routing disruptions in certain time bands line up with higher late coming, warnings, or exits from the same cohorts, commute dissatisfaction is almost always a material driver.
A common failure mode is treating transport feedback as a separate channel. More mature employers fold commute questions into regular engagement or pulse surveys and tag results by site, shift window, gender, and team. If low commute scores consistently co-occur with lower overall employee satisfaction or higher regretted exits in those segments, then commute has moved from an operational nuisance to an EVP risk.
Centralized Employee Mobility Services make this diagnosis easier because routing, safety incidents, SOS usage, and grievance closure SLAs can be matched to HRMS data. Organizations then monitor whether EX-linked KPIs like attendance, retention, and complaint volume improve after specific EMS changes such as better routing, women-safety protocols, or EV deployment. When improvements in transport KPIs are followed by reduced escalations to HR and lower attrition in affected groups, it confirms that commute experience is materially impacting employer brand.
vendor orchestration and governance across sites
Create cross-site, multi-vendor governance with defined escalation paths, contract guardrails, and consistency in employee-facing experience.
What early signs should HR watch for so we catch women-safety sentiment going bad before it turns into a major escalation or reputational issue?
B0430 Early warnings for women-safety sentiment — In India’s corporate employee transportation (EMS) for night shifts, what early warning signals should an HR leader look for to catch women-safety sentiment deterioration before it becomes an internal escalation or social-media reputational event?
HR leaders in India’s night-shift EMS should treat small, repeated friction in women’s commute experience as early warning signals of a coming safety-sentiment escalation. Deterioration usually shows up first as subtle shifts in feedback, routing patterns, and incident logs long before a major complaint or social-media post appears.
The earliest and most reliable signals sit in transport and HR data. A rising volume of “soft” complaints from women about late pickups, uncommunicated route changes, or being last-drop alone on routes indicates perceived risk even when no formal incident has occurred. An uptick in SOS-trigger tests, missed check-ins, or calls to the 24/7 support line during night bands suggests that women do not fully trust the current escort rules, driver behavior, or command-center responsiveness. A pattern of repeated driver substitutions, unfamiliar chauffeurs, or gaps in escort compliance on specific routes often erodes confidence silently.
Operational metrics give additional early alerts. Degrading on-time performance on women-heavy routes, more geo-fence deviations at night, or increased “app not working, please track manually” incidents undermine the sense of control. Guard or escort no-shows, vehicles briefly dropping off the GPS map, or frequent detours outside approved corridors are operational red flags that quickly become emotional flashpoints for women travelers. Rising no-show rates or last-minute self-arranged transport by women for night shifts is often a behavioral proxy for eroding commute trust.
HR should combine these signals into a simple, recurring “women commute safety sentiment” review. Key watch items include:
- Trend in women-specific complaints and informal feedback mentioning fear, discomfort, or distrust.
- Changes in usage of SOS, helplines, and safety features versus the number of night trips.
- Route and escort compliance exceptions for women’s trips, even if closed without incident.
- Correlations between night-shift attendance dips and clusters of commute-related concerns.
Most organizations that get surprised by reputational events had these signals present but uncorrelated. A common failure mode is treating each “small” complaint as an isolated service issue instead of reading them as trend data on women’s perceived safety. A second failure mode is relying only on vendor self-reporting rather than insisting on auditable trip logs, geo-fence data, and closure SLAs for any women-safety related ticket. HR leaders who demand a command-center view of these indicators, and who run joint reviews with Transport, Security/EHS, and the vendor, are far more likely to intervene early with route changes, driver re-induction, or policy clarifications before sentiment breaks into formal escalation or social media.
How do we separate normal daily variability from real, systemic commute experience issues that will keep causing repeat complaints?
B0431 Differentiate noise vs systemic failures — In India’s enterprise-managed employee commute (EMS), how can Facilities/Transport ops separate ‘normal variability’ (traffic, roster churn) from systemic experience failures that will keep generating repeat complaints and morale damage?
In India’s employee commute operations, facilities and transport teams can separate normal variability from systemic failures by tracking a small, fixed set of metrics at the route and shift level and seeing what patterns persist over time. Normal variability shows as occasional spikes tied to traffic or one-off roster changes, while systemic failures appear as repeat patterns on the same corridors, time bands, vendors, or driver clusters.
Normal variability is usually random and self-correcting. It correlates with known external causes such as heavy rain, citywide events, or last-minute HR roster changes. These incidents do not cluster around a specific driver, vehicle, or route, and they do not create sustained dips in OTP, attendance, or Commute Experience Index scores once conditions normalize. They are visible in command center logs but do not produce persistent complaint patterns or repeated safety exceptions.
Systemic experience failures create repeat friction even when the city and rosters are “normal.” They typically show as chronic low OTP on particular routes, recurring no-shows in the same time band, elevated complaint volumes from specific locations, or consistent gaps in women-safety protocols during night shifts. They often map back to structural issues such as poor vendor capacity in certain zones, fragile routing rules, weak driver retention, or incomplete integration between EMS tools and HRMS rosters.
Practical signals transport heads can use as an SOP include:
- A route or time band that stays below target OTP% for multiple weeks despite normal traffic.
- Employees raising similar complaints about the same corridor, shift, vendor, or driver group.
- Frequent manual overrides in rostering or routing for the same sites, indicating design flaws rather than bad luck.
- Safety or compliance exceptions repeating on the same lane or driver despite corrective instructions.
Teams that codify these signals into their command-center dashboards, and review them in weekly operations huddles, gain early warning of systemic failures before they become morale issues or reach senior leadership.
images:
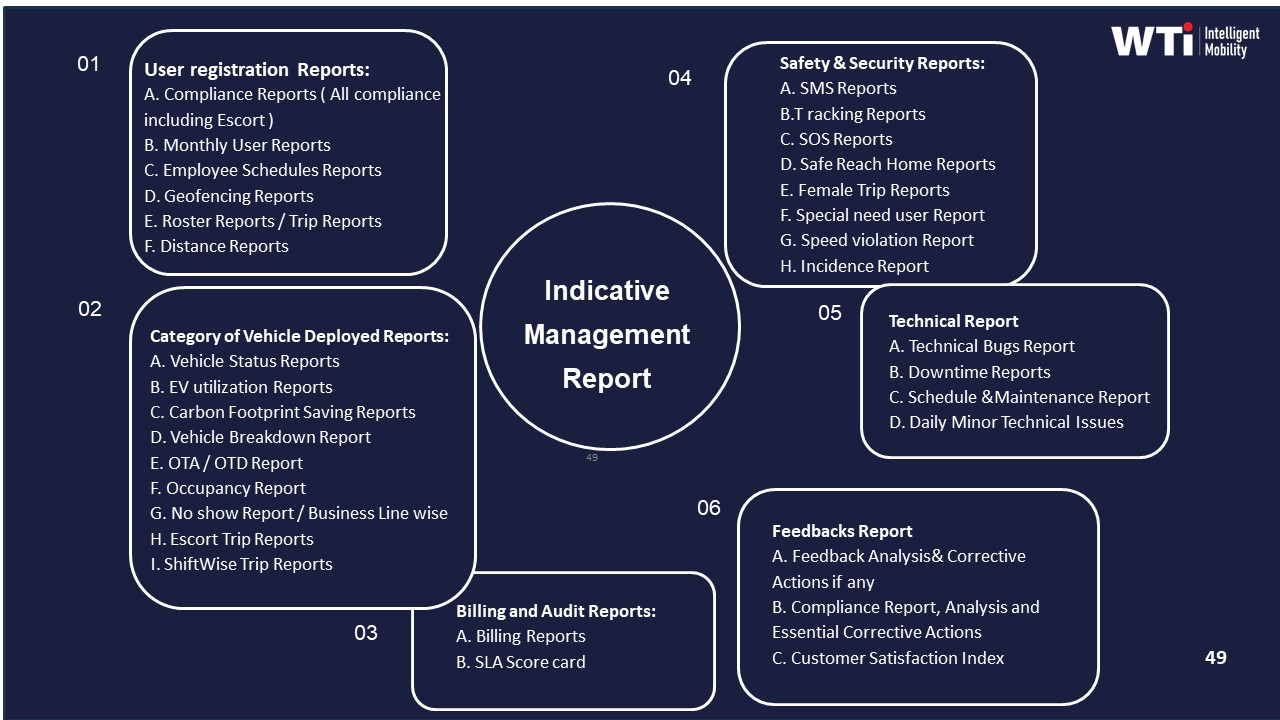
What does a practical feedback loop look like for transport—who owns it, how fast do issues close, and how do we stop it from becoming a black hole?
B0432 Operational feedback loop ownership — In India’s corporate ground transportation programs (EMS/CRD), what does a credible ‘commute experience feedback loop’ look like in day-to-day operations—who owns it, how quickly does it close, and how do you prevent it from becoming a black hole?
A credible commute experience feedback loop in Indian EMS/CRD is run like a standing operational process. It has a clear owner in transport/command-center operations, a fixed closure SLA (typically within the same shift or 24 hours), and it feeds directly into routing, vendor, and driver actions that employees can see in their next trips.
A strong loop usually sits inside the 24x7 command-center or transport desk. The command-center already tracks GPS, OTP, safety alerts, and driver behavior, so it is best placed to own intake, triage, and closure of ride-level feedback. HR owns policy and employee communication, but not ticket chasing. HR reviews patterns and escalations in weekly or monthly dashboards, while the command-center works the queue every shift.
The loop only works if response times are explicit. Most organizations define separate SLAs. Safety or women-safety issues are acknowledged immediately and acted on in real time. Service issues such as delay, behavior, or app glitches are acknowledged within the shift and closed in 24–72 hours. Billing or policy concerns go into a slower lane but still carry a defined SLA. These SLAs need to appear in the contract with vendors and in the KPIs for internal transport teams.
To avoid the “black hole” effect, the loop needs structured steps instead of ad-hoc replies. The minimum pattern is: capture the issue from app/call/email, tag it with trip and vehicle IDs, classify severity, act on it (reroute, replace driver, fix roster, coach vendor), close the incident with a specific resolution, and log it for audits. Daily shift briefings and driver training then use this data to adjust behavior and routes. Quarterly or monthly governance reviews use aggregated feedback to adjust vendor tiers, fleet mix, and routing logic, so complaints visibly drop over time instead of repeating.
Useful practical guardrails include: - Single intake channel per site or program, even if there are multiple apps and numbers. - A simple categorization schema that operations can work with under pressure. - Command-center dashboards that show open vs closed issues, by vendor, route, timeband, and driver. - Explicit linkage between feedback patterns and vendor scorecards, driver rewards, and route changes.
When this structure is in place, facility and transport heads get earlier warnings and fewer 2 a.m. surprises. HR gets auditable proof that complaints are heard and acted on. Finance and Procurement see that disputes about delays or no-shows resolve against clean trip logs, not opinions. Employees see that commenting on a bad shift leads to a visible change in the next few commutes, so feedback remains active instead of dropping into silence.
How do we set grievance SLAs employees actually feel, without drowning our transport team in tickets and follow-ups?
B0433 Grievance SLAs without ticket overload — In India’s shift-based Employee Mobility Services (EMS), how do you define and enforce grievance SLAs that employees actually feel—while keeping the transport control room from being overwhelmed by tickets and follow-ups?
In India’s shift-based Employee Mobility Services, grievance SLAs work best when they are tiered by risk, driven by the command center, and tightly integrated with trip data, so serious issues get fast, predictable responses without flooding the transport desk with low‑impact tickets. Employees feel the SLA when every complaint gets an immediate acknowledgment, a clear resolution time based on severity, and a visible closure loop inside the same app they used to travel.
A practical model begins with a simple severity matrix. Safety and women-safety issues, SOS triggers, and missed pickups for live shifts sit at the highest priority tier. App glitches, ETA queries, or minor service complaints fall into lower tiers. Each tier maps to explicit response and resolution times that transport, HR, and security agree on. The routing engine, GPS logs, and command center tools then auto-classify many grievances using trip metadata, which prevents manual triage overload.
The control room stays in control when most grievance events are auto-created from operations data rather than free-form calls. No-show, late arrival, and route deviation can auto-generate tickets from the NOC dashboards instead of relying only on employee complaints. Unified dashboards with trip adherence, OTP, and incident logs let supervisors see patterns, apply standard SOPs, and escalate only the cases that breach safety or SLA thresholds. HRMS and attendance integration reduces duplicate queries because employees can see which incidents already link to their shifts and whether they are closed.
To avoid ticket fatigue, organizations can set three to four SLA bands only, publish them clearly in the employee app, and enforce a strict closure protocol. Every closed ticket must carry a short resolution note, a linked trip record, and a simple feedback option that feeds into the Commute Experience Index. Command centers then review SLA breaches, repeat offenders, and grievance themes during weekly reviews, which supports continuous route optimization, driver coaching, and vendor governance without adding more daily firefighting.
What escalation rules stop the same transport issue from bouncing between HR, Facilities, Security, and the vendor with no clear owner?
B0434 Stop escalation ping-pong — In India’s corporate employee transport (EMS), what escalation hygiene practices prevent the same incident (missed pickup, driver misconduct allegation, route deviation) from bouncing between HR, Facilities, Security/EHS, and the vendor with no clear owner?
Escalation hygiene in Indian corporate employee transport depends on pre-agreed ownership, codified workflows, and audit-ready tools that make every incident traceable from trigger to closure.
Most organizations reduce “ping-pong” between HR, Facilities, Security/EHS, and vendors by defining a single operational owner for commute incidents. The Facility or Transport Head usually operates as the command center, and every missed pickup, misconduct allegation, or route deviation is first logged and triaged there. HR, Security/EHS, and the vendor are treated as stakeholders in a workflow, not competing owners.
Effective programs publish a written escalation matrix that is service-specific and time-bound. Each severity level has a named first responder, an escalation path, and clear closure SLAs. The escalation matrix sits inside the transport platform or command center tooling, so alerts and tickets auto-tag the right role rather than relying on ad hoc emails or calls.
Centralized command centers and alert supervision systems strengthen escalation hygiene when they enforce single-ticket ownership. Every incident generates a unique record that captures source (app SOS, IVR, HR mail, security call), timestamps, evidence (GPS trace, call logs), actions taken, and who is currently accountable for closure. HR or Security can be @-tagged for specific steps like employee support or disciplinary review, but the ticket never loses its primary owner.
Organizations also hard-wire safety and route deviations into automated alerts. Geofence violations, over-speeding, fixed device tampering, or route deviations flow to the command center in real time, which triggers SOPs without waiting for employee complaints. For missed pickups, EMS operations rely on trip adherence metrics, no-show reports, and VUI/OTP dashboards to catch patterns and enforce penalties with vendors before HR escalations spike.
Vendor governance frameworks and centralized compliance management reduce blame-shifting by tying SLAs and penalties directly to auditable incident data. Vendor contracts specify who must respond within minutes, who must provide driver statements or GPS logs, and what happens if evidence is incomplete. This converts disagreements about “what happened” into fact-based reviews under a shared data set.
Stronger escalation hygiene links back into HSSE culture reinforcement and safety and compliance frameworks. Teams conduct periodic audits of incidents, identify root causes across routing, driver behavior, and tech gaps, and then update SOPs and training. Driver management and training, women-centric safety protocols, and business continuity plans are reviewed against real incident logs so the same failure mode is not repeated shift after shift.
In practice, stable EMS operations treat escalation hygiene as an ongoing governance habit. Organizations run engagement models with structured review cadences, where HR, Transport, Security/EHS, and vendors review indicative management reports and user satisfaction indices. They align on patterns, not one-off blame, and agree in advance which persona owns which step in the next night’s crisis, so at 2 a.m. there is one playbook and one control room, not four inboxes arguing over ownership.
During incidents, what should HR and the control room say (and not say) to protect employee trust without over-promising or creating legal risk?
B0435 Incident communications that preserve trust — In India’s enterprise employee mobility (EMS) supporting women and night shifts, what communication playbooks should HR and the transport NOC use during incidents to preserve trust—without over-promising or triggering legal exposure?
Effective incident communication in Indian enterprise employee mobility must be scripted, short, and evidence-backed. HR and the transport NOC need pre-approved playbooks that prioritize immediate reassurance and facts, avoid speculation or blame, and leave room for investigation and legal follow‑through.
1. Core principles for any incident communication
Every communication should separate three elements. These elements are what happened, what is being done now, and what will happen next. HR and NOC teams should never guess causes or liability during live response.
HR and NOC teams should acknowledge employee impact in simple language. HR and NOC teams should avoid emotional exaggeration and absolute promises like “this will never happen again.”
HR and NOC teams should refer to documented SOPs, such as escort rules, women-safety protocols, and SOS escalation matrices. HR and NOC teams should not improvise new guarantees on the call or chat.
2. Live-incident playbook for NOC / Transport Command Centre
The NOC should use a standard first-response script when an SOS is triggered or a complaint is received. The NOC should confirm caller identity, location, and safety status first.
The NOC should state what action is being taken in operational terms. The NOC should name steps like alerting security, rerouting the vehicle, dispatching a backup cab, or involving local authorities as per the company’s HSSE and women-safety SOPs.
The NOC should time-stamp actions in a ticketing or command-center tool to maintain an audit trail. The NOC should avoid discussing fault, disciplinary action, or compensation on the live call.
The NOC should escalate based on a predefined safety escalation matrix. The NOC should bring in Security or HR when the incident crosses defined severity thresholds.
3. HR communication playbook in the first 24 hours
HR should own employee-facing communication once the immediate safety risk is contained. HR should send a concise written note to the affected employee and, if needed, her manager.
HR should state three things clearly. HR should state that the incident is acknowledged, that the employee’s safety and well-being are the first priority, and that a formal review has started under the company’s transport and safety policy.
HR should avoid promising specific outcomes before investigation. HR should avoid phrases like “the driver will be terminated” or “the vendor will be blacklisted” until Security and Legal close the case.
HR should offer concrete support, such as alternate transport, schedule flexibility, and access to POSH or counselling channels, where relevant. HR should avoid collecting detailed witness statements over informal channels like WhatsApp.
4. Alignment with Security, Legal, and vendor
Security should lead fact-finding and evidence review using GPS logs, trip manifests, IVMS, and call recordings. Security should ensure chain-of-custody for all data to preserve auditability.
Legal should pre-define what HR and NOC may or may not say about police involvement, vendor liability, or employee fault. Legal should approve master templates for external or regulator-facing responses.
Vendor managers should route any comments about driver discipline or vendor penalties through the contract governance process. Vendor managers should not allow NOC agents to negotiate outcomes directly with drivers or vendors on recorded lines.
5. Templates and channels that reduce risk
Organizations should maintain three to five pre-approved templates. These templates should cover live-SOS acknowledgement, same-night closure update, next-day HR note to employee and manager, internal leadership update, and a short FAQ for managers on “what to say” and “what to avoid.”
Organizations should route all incident-related communication through traceable channels. These channels should include the command-center system, official email, or the employee app, not personal messaging apps.
Organizations should train NOC agents and HR business partners using role-play scenarios. These scenarios should include women returning from night shifts, vehicle breakdowns in unsafe areas, app or GPS failures, and disagreements over route or escort compliance.
6. Preserving trust without over‑promising
Trust is preserved when employees see quick, visible action and later see consistent follow‑through. Trust is damaged when employees hear big promises that are not followed by demonstrable change.
HR and NOC should always close the loop with the employee once corrective actions are implemented. HR and NOC should share only what is appropriate, such as “route rules updated,” “escort deployment tightened,” or “driver removed from your route,” without disclosing sensitive disciplinary details.
HR should periodically communicate aggregated, anonymized safety metrics, such as incident closure SLAs and improvements in OTP during night shifts. HR should avoid publishing incident narratives that can identify individuals or prejudice ongoing processes.
How do we align business managers so transport exceptions don’t instantly become ‘HR’s fault’ when late logins happen?
B0436 Prevent HR blame after exceptions — In India’s corporate Employee Mobility Services (EMS), how do you set expectations with business managers so late logins don’t automatically become an HR blame-game when transport exceptions occur?
In India’s corporate Employee Mobility Services, expectations with business managers stay realistic when commute exceptions are treated as a governed operational risk with shared accountability, backed by transparent SLAs, exception codes, and audit-ready reports. HR avoids the “blame sink” role when transport deviations are codified, visible in dashboards, and linked to clear SOPs for how managers handle late logins, not handled ad hoc on email or WhatsApp.
The most stable pattern is to define a transport–attendance contract in advance. Organizations publish shift windowing rules, cut-off times for roster changes, and acceptable buffers for traffic or weather based on real OTP and ETS Operation Cycle data. These rules sit in HR policy and are mirrored in EMS routing logic and Transport Command Centre playbooks. Business managers are told explicitly which delays qualify as transport exceptions and which are regular attendance issues.
A common failure mode is opaque incident handling. When drivers, NOC, and managers lack a shared exception taxonomy, every delay looks like HR’s fault. A centralized command center with alert supervision, SOS handling, and Management of On-Time Service Delivery converts raw events into standardized reasons. These reasons feed attendance notes and MIS so managers can see if a late login was due to geofence issues, driver fatigue interventions, EV charging downtime, or employee no-show.
To shift the culture away from blame, transport heads use data-driven insights and Indicative Management Reports in monthly reviews with HR and business leaders. They show OTP%, route adherence, and no-show rates by team. They also agree up front how many exceptions per month are “normal” under monsoon, election, or construction scenarios documented in Business Continuity Plans. Managers then plan buffer staffing instead of escalating every deviation to HR.
Clear communication protocols anchor this. SOPs specify who informs whom when a trip breaches ETA, how NOC updates are relayed to managers, and what counts as an excused delay in the HRMS. Employee apps and manager dashboards surface live ETA and incident notes so supervisors see issues as they unfold. This reduces surprise and prevents post-facto disputes over “who knew what, when.”
Practical guardrails that usually work include:
- A joint HR–Transport–Business “attendance & transport” note that defines exception categories and how they reflect in timesheets.
- Quarterly governance reviews where Transport presents OTP and incident data, and HR aligns consequences with real-world patterns instead of anecdotes.
- Escalation matrices that separate safety-critical incidents from routine delays so HR is involved where duty of care is at stake, not in every missed cab.
By turning commute reliability into a measurable service with shared governance, organizations keep HR as the guardian of safety and experience, while making business managers co-owners of planning and buffer decisions whenever EMS exceptions are inevitable.
images:
How do we get employees to actually use the new feedback/grievance channel instead of just calling the old coordinator and resisting change?
B0437 Reduce resistance to new channels — In India’s corporate ground transportation (EMS/CRD), what practical steps reduce frontline workforce resistance to new feedback or grievance channels, especially when employees are used to calling a known coordinator directly?
In India’s corporate ground transportation, frontline resistance to new feedback or grievance channels reduces when organizations keep the old “human” bridge visible, prove faster resolutions with the new flow, and give employees clear, simple SOPs for what to do when something goes wrong. Resistance increases when digital tools feel like a barrier to the known transport coordinator or appear to delay urgent help in night shifts.
Frontline employees usually trust a known coordinator because that person answers the phone during real issues like late pickups, GPS failures, or no-show drivers. Any new app, IVR, or ticketing tool must keep that coordinator visibly in the loop at first. A practical pattern is to route app/portal complaints directly into a command-center or transport desk queue where the same familiar coordinator acknowledges, calls back, and closes the case. This links new channels to existing relationships rather than replacing them overnight.
Adoption improves when feedback channels are introduced as part of a clear SOP, not as optional “nice to have” tools. Transport heads can publish a one-page playbook that explains which channel to use for which scenario, such as “late cab,” “safety concern,” or “billing query,” and what response time to expect. Resistance drops when employees see that app/SOS complaints are timestamped, tracked, and escalated automatically, while informal calls are not. This addresses HR’s and Security’s need for audit trails while giving the frontline workforce predictable closure and fewer repeated calls.
Command-center style dashboards and alert systems help transform complaints into early alerts that reduce firefighting. When organizations use real-time visibility and centralized supervision to close issues before they escalate to HR or leadership, employees gradually experience the new channel as faster and more reliable than chasing a single coordinator’s phone.
What UX elements matter most so employees and guards can use the boarding/OTP flow with almost no training, and how do we validate it before rollout?
B0438 Validate low-friction user UX — In India’s Employee Mobility Services (EMS) with shift-based routing, what ‘zero learning curve’ UX elements matter most for employees and security guards (boarding confirmation, OTP, manifests), and how do you validate them before rollout to avoid user backlash?
In India’s EMS programs, “zero learning curve” UX means employees and security guards can board, verify, and escalate without training, manuals, or FAQs. The most critical elements are simple boarding confirmation, idiot-proof OTP flows, and manifests that match how guards already work, then validating these through on-ground pilots, shadowing, and failure-scenario drills before full rollout.
For employees, one-tap actions reduce confusion and calls to the transport desk. Boarding confirmations work best as a single large “Check-in / I’ve boarded” button with clear status text. OTP flows work when the OTP is auto-read or copyable and the app tells the rider exactly what to tell the driver or guard. Live trip cards with driver photo, vehicle number, and ETA visible on one screen reduce panic at shift change.
For security guards, UX must match gate SOPs rather than tech ideals. Guards need a simple manifest view with clear names, IDs, and pickup times, and a single green/red boarding status per employee. QR or OTP verification should work offline with cached data and a visible “override + reason” path for genuine exceptions, so they are not stuck when networks fail.
Validation requires treating UX as an operational SOP test, not just a UI review. Operations teams should run pilot routes on real shifts, including night shifts, with 10–20% of the workforce and existing security staff. Teams should observe at the gate how many riders and guards complete boarding without explanation, track error and dropout rates, and log where people get stuck. It is essential to simulate failure modes like low battery, no network, driver app downtime, and mismatched rosters, and measure how quickly guards and employees find workarounds using built-in override options.
Organizations should use short, structured checklists and interviews with employees, guards, and transport desks after pilots. Key signals of “zero learning curve” include no printed instruction posters needed at gates, no spike in calls to the command center during first-week rollout, and clean boarding/closure data in dashboards such as the ETS Operation Cycle and WTI Command Center views. If complaints or confusion cluster around specific steps like OTP sharing or manifest lookup, those flows should be redesigned and re-piloted before scaling to all sites.
images:
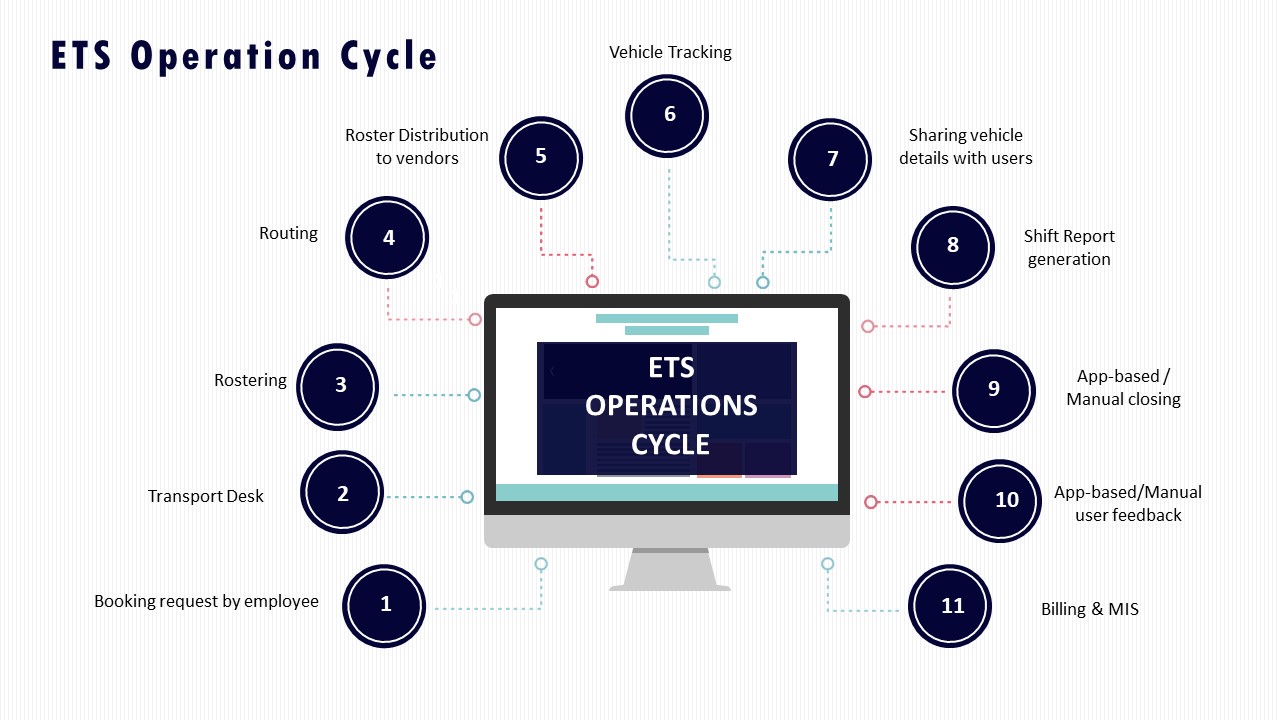
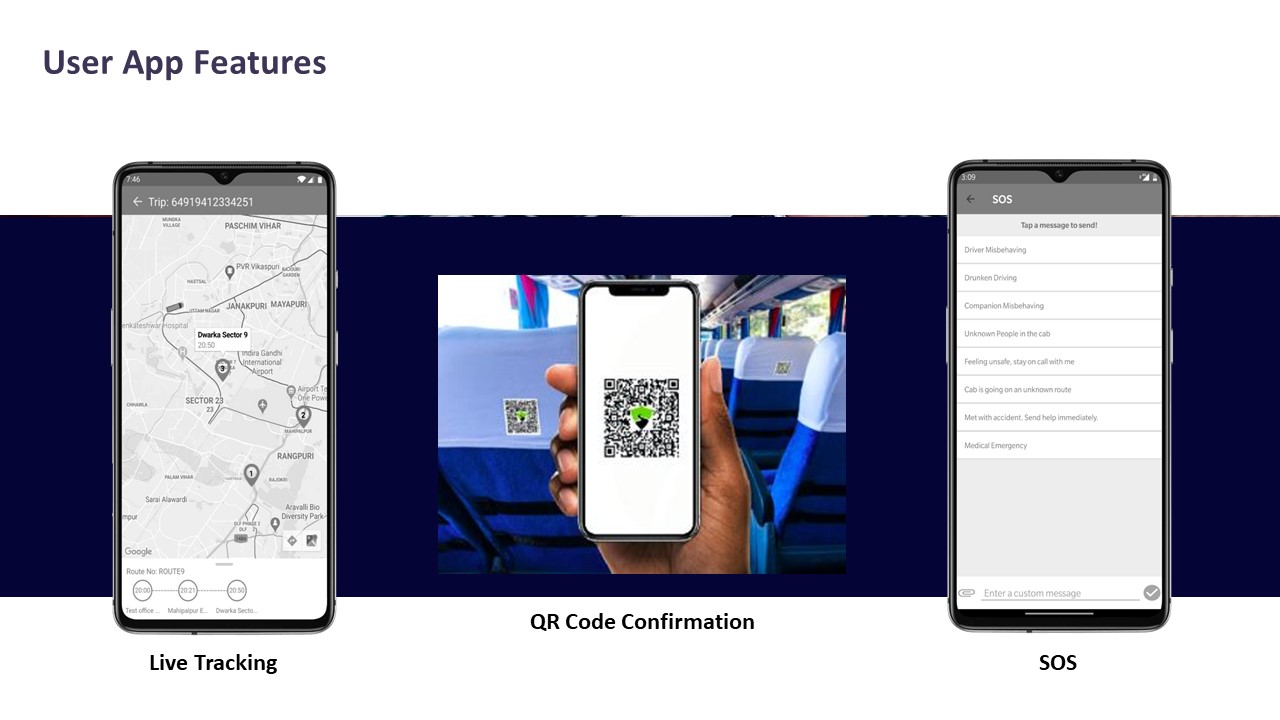
How do we collect employee transport feedback in a way that’s honest and useful, but doesn’t turn into a venting channel that drags down the ops team?
B0439 Feedback design without venting spiral — In India’s corporate employee transport (EMS), how should an HR team structure feedback collection so it captures real experience (safety, respect, predictability) without becoming a venting channel that demoralizes operations teams?
HR teams in India’s employee mobility programs should treat commute feedback as a governed “safety and service signal system” with clear rules, categories, and closure SLAs instead of an open-ended complaint box. A structured, tiered feedback design captures real experience on safety, respect, and predictability while protecting transport teams from constant, demoralizing noise.
Most organizations get into trouble when every negative comment is free-text, anonymous, and untriaged. That pattern blurs critical safety signals with generic frustration and creates defensiveness in operations. A better approach is to anchor feedback around a Commute Experience Index with fixed questions on on-time performance, driver behavior, vehicle condition, and feeling of safety, and then split inputs into three pipes. The first pipe covers routine service scores that feed into dashboards and trend analysis. The second pipe handles “amber” operational issues like repeated delays or routing irritation with clear closure timelines owned jointly by HR and transport. The third pipe is a hard “red channel” for safety, POSH, or women-safety escalations with automatic alerts, audit trails, and direct linkage to security or EHS processes.
This structure works when HR links feedback to transparent SOPs, not ad-hoc reactions. HR can publish what will be done with each type of feedback, how quickly, and by whom, and then share monthly summarized trends with operations rather than forwarding raw complaints. HR should close the loop with employees through standard responses and visible fixes while also recognizing drivers and transport staff when OTP, incident rates, and satisfaction metrics improve. That balance of data, defined channels, and recognition shifts feedback from venting to continuous improvement and keeps command-center and field teams engaged instead of blamed.
If we get a serious night-shift complaint, what should the first 60 minutes look like—who acts, how do we protect the employee, and how do we preserve evidence without chaos?
B0440 First-hour workflow for serious complaints — In India’s corporate ground transport for night shifts (EMS), when a serious complaint occurs (harassment allegation, unsafe drop location, escort lapse), what should the first 60 minutes of the grievance workflow look like to protect the employee and preserve evidence without chaos?
The first 60 minutes after a serious night-shift complaint in employee mobility should follow a tightly scripted SOP that prioritizes the employee’s physical and psychological safety first, then locks trip data and evidence, and only then activates the investigation and escalation chain. Any deviation from this order increases risk, noise, and blame.
0–15 minutes: Secure the employee and stabilize the situation
The transport or security team should first confirm the employee’s immediate safety through a live call, app SOS response, or local security contact. The employee should be moved to a safe, supervised location such as office security, a guarded gate, or a known safe point rather than left alone at an unsafe drop. The team should stop any further interaction between the employee and the driver or escort except what is absolutely necessary to move to safety.
Medical help or emergency services should be called if there is any sign of physical harm or acute distress. A single, designated responder should speak to the employee to avoid conflicting instructions and repeated questioning.
15–30 minutes: Freeze the trip and evidence trail
The command center or NOC should immediately lock all digital traces of the trip in the mobility platform and telematics systems. This includes GPS logs, IVMS and dashcam footage if installed, call logs, SOS activations, routing data, and app chat or notification history. The driver profile, KYC, escort allocation, and route plan should be tagged and prevented from deletion or alteration.
The vehicle involved should be instructed to halt at a safe, observable location if possible, and the driver should be taken off duty for the shift pending review. All actions taken in this window should be time-stamped in the command-center dashboard or incident management system.
30–60 minutes: Controlled escalation and documentation
A formal incident ticket should be opened in the alert supervision or command-center system with a clear, unique ID linked to the trip and employee, instead of using informal channels like ad-hoc chats. The predefined escalation matrix should be triggered, notifying Security or EHS, HR, and the Facility or Transport Head, while limiting broadcast to “need-to-know” stakeholders to avoid rumor and panic.
A brief factual incident note should be captured, recording who reported the complaint, the time, type of allegation, immediate safety steps taken, and which data sources have been frozen. The organization should avoid pressuring the employee for a detailed statement in this first hour and instead confirm next steps, including follow-up interview, support options, and possible involvement of external authorities where required by policy or law.
- Employee first, evidence second, reputational management later.
- Single command center or control room, not fragmented responses, to manage calls, GPS, and SOS.
- Pre-agreed escalation matrix and women-safety protocols embedded in EMS operations, not improvised at 2 a.m.
How do we stop ‘paper closures’ where a ticket is marked resolved but the employee still feels unsafe or unheard?
B0441 Prevent paper-only grievance closure — In India’s enterprise Employee Mobility Services (EMS), how do you prevent ‘closure theater’—tickets marked resolved on paper—when employees still feel unsafe or unheard after a grievance is ‘closed’?
In India’s enterprise Employee Mobility Services, organizations prevent “closure theater” by separating ticket closure from true resolution, and by tying closure to auditable evidence of outcome, not just system status. Closure becomes a multi-signal decision that blends employee feedback, safety/compliance checks, and command-center review rather than a dispatcher clicking “resolved.”
Most operations reduce closure theater when the 24x7 command center owns a clear, written incident SOP that covers detection, escalation, and post-incident verification. Command centers in this sector already manage SOS alerts, geofence violations, over-speeding, and device tampering through tools like alert supervision systems, centralized dashboards, and escalation matrices. The same rigor needs to apply to complaints about unsafe routing, driver behaviour, or missed pickups, with each case tracked until the employee confirms that they feel safe to travel again or an alternative arrangement is in place.
A common failure mode is treating women-safety features, SOS panels, and GPS monitoring as technology checkboxes without linking them to human follow-up and Root Cause Analysis. Women-centric safety protocols, night-shift escort rules, and chauffeur excellence programs only reduce fear when each incident triggers coaching, re-routing, or vendor action that is documented and visible to HR, Security/EHS, and Transport heads.
To avoid closure theater, organizations typically add hard gates to closure such as mandatory employee feedback capture, independent review by Security or HR for safety-related tickets, and periodic audit of closed cases from the command center dashboard. This shifts performance emphasis from “tickets closed” to SLA-backed metrics like complaint closure time with satisfaction, reduction in repeat complaints on the same route or driver, and improvement in commute experience scores, especially for night-shift and women employees.
What governance model reduces recurring complaints best—central NOC, site transport desks, or hybrid—and what typically breaks in each model?
B0442 Governance model to cut complaints — In India’s corporate employee transport (EMS), what governance model best reduces recurring complaints: centralized 24x7 NOC ownership, site-level transport desks, or a hybrid—and what failure modes should we watch for with each model?
In India’s corporate employee transport, a hybrid governance model with a central 24x7 NOC plus site-level desks usually reduces recurring complaints best. A central command center stabilizes standards, visibility, and SLA governance, while local desks handle on-ground exceptions and employee communication in real time.
A centralized NOC works when organizations need uniform policies, automated routing, and continuous SLA monitoring across cities. It improves observability, incident readiness, and compliance assurance by consolidating GPS data, alerts, and audit trails under one governed platform. A common failure mode is “central blindness” to local realities, where policies ignore plant gates, union dynamics, or monsoon bottlenecks, which pushes employees to escalate outside the official process.
Site-level transport desks work where the footprint is small or concentrated and where local teams know shift leaders and guard posts well. This structure is strong at relationship management, quick decisions, and last-minute roster changes. Common failure modes include inconsistent SOPs between sites, manual rostering, fragmented data, and over-dependence on a few individuals, which leads to burnout and untraceable decisions during audits.
The hybrid model minimizes daily firefighting by combining central routing engines, compliance dashboards, and standardized SLAs with location-specific command centers for driver allocation, live coordination, and immediate issue handling. Failure modes arise when the division of responsibility between central and site teams is unclear, when escalation matrices are not followed, or when data flows are not integrated, which creates duplicated effort, blame games, and missed early alerts for HR, Security, and Procurement.
If we have multiple vendors, how do we keep employee communications consistent so it still feels like one program and doesn’t hurt our brand?
B0443 Consistent comms across vendors — In India’s corporate ground transportation (EMS/CRD), how do you keep employee-facing communications consistent across multiple fleet vendors so the experience feels ‘one program’ rather than a patchwork that damages employer brand?
Consistent employee-facing communication in multi-vendor mobility programs comes from centralizing the “voice” and rules of the program, then forcing every vendor to plug into that, rather than letting each vendor talk to employees in its own way. A unified command center, a single app or portal, and common SOPs turn fragmented supply into one governed experience.
A central platform for EMS/CRD communication gives employees one source of truth for bookings, rosters, trip details, SOS, and feedback, even if there are many fleet vendors underneath. This platform can integrate multiple vendors through APIs, but it keeps all notifications, ETAs, vehicle details, and issue updates in a standard format and tone. When the WTicabs Mobility or Commutr-style app is used as the front door, employees deal with one brand and one workflow, not with individual cab vendors.
A centralized command center or Transport Command Centre can own all real-time broadcast communication during disruptions, monsoon routing changes, EV charger issues, or night-shift safety incidents. Vendors can talk to the command center, but the command center talks to employees. This reduces conflicting messages and protects the employer brand when OTP is under stress.
To enforce “one program” instead of a patchwork, most organizations need three hard controls:
- A common communication SOP and template pack for all trip SMS/app notifications, delay alerts, safety messages, and feedback requests.
- Vendor contracts that restrict direct, unmanaged communication with employees and mandate use of the enterprise platform and scripts.
- Centralized dashboards for complaints and NPS so responses, escalations, and apology or make-good messages are coordinated across EMS, CRD, and event/project commute services.
When combined with a unified safety framework, centralized compliance dashboards, and a single EV/ESG narrative, this approach keeps operations flexible across vendors but makes the employee experience, safety messaging, and brand tone feel like one stable, governed program rather than a collection of vendors.
What are realistic grievance SLA targets by severity, and how do we keep them from collapsing during peak hours or disruptions?
B0444 Set grievance SLAs by severity — In India’s enterprise Employee Mobility Services (EMS), what are realistic grievance SLA targets by severity (e.g., missed pickup vs. safety concern), and how do you operationalize them so they don’t collapse during peak shifts or weather disruption?
In India’s enterprise Employee Mobility Services, realistic grievance SLAs set fast human acknowledgement for every case, ultra-fast closure for safety-critical issues, and more relaxed but still same-shift closure for service or billing issues. These SLAs only work in real life when they sit on top of a command-center model, clear severity coding, and pre-approved playbooks for peaks and disruptions.
Practical SLA Bands by Severity
Critical safety / women-safety / SOS events. Acknowledge within 1–3 minutes via command center or security desk. Stabilize the employee and arrange alternate transport within 10–15 minutes. Complete incident logging and escalation within the same shift. Close RCA and corrective actions in 24–72 hours with audit-ready evidence.
High severity operational issues (missed pickup, serious delay causing shift impact). Acknowledge within 5–10 minutes. Arrange alternate cab or reroute within 20–30 minutes, with clear ETA shared to employee and transport desk. Complete investigation, vendor feedback, and closure within 24 hours, including fare adjustments if applicable.
Medium severity (rude driver, app glitch with ride still completed, routing complaints). Acknowledge within 1 working hour. Analyse trip data, driver history, and telematics within the day. Close with response, counselling or warning to driver, and communication to employee within 24–48 hours.
Low severity / commercial or billing disputes. Acknowledge within 4 business hours. Resolve via billing system checks, tariff mapping, and trip-log verification within 3–5 working days, aligned with centralized billing cycles.
How to Make These SLAs Survive Peaks and Disruptions
Grievance SLAs remain realistic only when severity is auto-tagged from systems where possible and not left to manual judgement alone. Most organizations depend on a 24x7 command center or Transport Command Centre that monitors GPS feeds, alerts, and SOS panels, so many “grievances” are detected as deviations before the employee raises a ticket.
During monsoons or city-wide disruption, a business continuity plan and emergency playbooks are essential. These include pre-defined buffers of vehicles, alternate routing rules, flexible shift start-times, and escalation matrices that allow temporary relaxation of non-critical SLAs without touching safety timelines.
Operations leaders keep the model stable by using data-driven insights from dashboards and indicative management reports. These tools surface patterns such as recurring driver issues, routes with frequent delays, or vendor-specific gaps, so the number of grievances during peaks reduces over time instead of rising.
Transport heads rely on structured engagement and escalation models to keep Finance, HR, and Security aligned. This ensures that when a spike hits during weather or political events, safety and critical operations complaints still meet tight SLAs, while cost and comfort issues are transparently re-prioritized and communicated.
How do Finance and HR agree on what counts as an ‘experience failure’ so budget discussions don’t dismiss this as a soft benefit?
B0445 Align Finance and HR on experience — In India’s corporate Employee Mobility Services (EMS), how should Finance and HR align on what constitutes ‘experience failure’ so employee experience investments don’t get dismissed as soft benefits during budget reviews?
In India’s Employee Mobility Services, Finance and HR need a shared, operational definition of “experience failure” that is measurable in transport KPIs and HR outcomes, not just sentiment. Experience failure should be framed as a set of trigger conditions tied to on-time performance, safety incidents, and attendance or attrition impact so that commute investments are treated as risk and productivity controls, not discretionary perks.
Finance usually looks for defensible numbers such as cost per employee trip, SLA breaches, and audit findings. HR typically experiences commute issues as complaints, morale dips, and safety concerns, especially for women and night shifts. Alignment happens when HR converts these “soft” signals into thresholds that map directly onto measurable EMS metrics like on-time performance, exception-closure time, incident rate, and complaint closure SLAs.
A common failure mode is defining experience only through periodic satisfaction scores without connecting them to shift adherence, no-show rates, or attrition in high-dependency teams. Another is tracking escalations informally, which makes it impossible for Finance to see patterns or justify interventions during budget cycles.
A practical alignment approach is to agree upfront that certain patterns constitute experience failure warranting corrective investment, for example:
- A defined on-time performance floor, below which late logins, production loss, and overtime increase.
- Any verified women-safety lapse or escort non-compliance, which creates legal and reputational exposure.
- Recurrent night-shift escalations that breach an agreed closure SLA, indicating inadequate command-center or vendor controls.
- Commute-linked spikes in absence or attrition in specific locations or shifts, based on HR and roster data.
Once these conditions and thresholds are codified into EMS governance and reporting, HR can present “experience failures” to Finance as quantified risk and productivity loss. Finance can then evaluate EMS investments in routing automation, command-center capability, compliance automation, or EV transition as levers to improve on-time performance, safety metrics, and attendance stability rather than as optional employee benefits.
How should we handle anonymous transport feedback so employees feel safe, but HR can still act fast and avoid false/malicious claims?
B0446 Anonymous feedback without misuse — In India’s corporate employee commute programs (EMS), what’s the best way to handle anonymous feedback so employees feel safe to report issues while HR can still act quickly and avoid false or malicious claims damaging trust?
Anonymous feedback in employee commute programs works best when it is structured, evidence-linked, and governed by clear SOPs that HR and Transport teams follow consistently. A robust model separates identity from incident details, standardizes intake questions, and routes only “actionable with evidence” cases into fast operational workflows while handling low-evidence or pattern-based complaints through trend monitoring instead of immediate punitive action.
Most organizations gain control when they treat commute feedback as part of a governed EMS stack rather than a loose suggestion box. Anonymous reports should flow into the same command-center environment that already handles OTP%, incident alerts, and SOS tickets, with defined fields for route, timeband, vehicle ID, driver tag, and nature of issue. This lets HR and Transport correlate feedback with GPS logs, trip manifests, and duty slips without exposing employee identity, which strengthens both speed of response and auditability.
A common failure mode occurs when every anonymous claim is treated as either fully true or fully suspect. Mature teams define a small set of SOPs that explicitly state what triggers immediate action, what triggers quiet observation, and what is ignored unless it recurs as a pattern across trips, drivers, or routes. This reduces the risk of malicious claims harming driver morale while still protecting employees who fear retaliation, especially on women-safety and night-shift routes.
- Use the EMS platform or command center as the single intake channel for anonymous commute feedback.
- Force incident details and evidence fields, but make employee identity optional with clear privacy language.
- Link every report to telematics, routing, and roster data before escalation decisions.
- Escalate serious safety signals immediately, and treat uncorroborated issues as trend inputs, not grounds for discipline.
How do we improve driver behavior and ‘respectful commute’ issues without making it so punitive that we lose drivers and reliability drops?
B0447 Improve respectful commute without churn — In India’s corporate employee transportation (EMS), how do you measure and improve ‘respectful commute’ factors—driver behavior, language, waiting etiquette—without turning it into a punitive program that worsens driver retention and service reliability?
Respectful commute in Indian EMS is best measured and improved by treating driver behavior as a managed service quality dimension with coaching, incentives, and structured evidence, rather than as a pure disciplinary program. Operations teams who combine clear behavior standards, simple feedback channels, and training plus rewards typically see better driver retention and more stable on-time performance.
Organizations can start by defining respectful commute in concrete operational terms. Driver behavior can be broken into observable items such as greeting employees, following waiting etiquette at gates, avoiding arguments, and handling delays calmly. These behaviors can be embedded into driver assessment and training modules, like the documented Driver Assessment & Selection Procedure (DASP) and two-day soft-skills sessions, so that expectations are set before a driver ever joins a route.
Measurement should rely on lightweight, repeated signals instead of ad-hoc escalations. Employee apps that already capture feedback, ride check-in, and SOS can add one or two quick questions about courtesy and waiting conduct per trip. Periodic audits, transport command center observations, and supervisor ride-checks can complement app feedback to build an objective view without over-surveying riders. Centralized dashboards and indicative management reports can then track complaint patterns, repeat offenders, and positive outliers across vendors and sites.
To avoid a punitive culture that harms driver morale and retention, the same data should be used first for coaching and recognition. Documented driver training and rewards programs show that safe driving, customer handling, and seasonal training can be linked to rewards and recognition, not just penalties. High-scoring drivers on courtesy and waiting etiquette can receive RNR awards, better duty allocations, or preference in long-term rentals and project commutes.
Corrective actions for poor behavior should follow a transparent, staged SOP that mirrors wider compliance frameworks. Initial issues can trigger coaching and refresher training, supported by trip-level evidence from apps and the alert supervision system, rather than unsubstantiated complaints. Escalation matrices and centralized compliance management allow only repeated or severe violations to move into formal warnings or de-induction, with all steps logged for auditability.
Transport and facility heads can protect daily reliability by integrating behavior programmes with business continuity and fatigue controls. Driver duty cycles, rest norms, and seasonal briefings (for example before monsoons or peak-festive periods) reduce stress that often surfaces as rude behavior or poor waiting etiquette. Daily shift-wise briefings and “safety first, on-time delivery” meetings provide a forum to reinforce respectful conduct, share real incidents, and clarify what will be supported by management if a driver refuses unsafe or abusive passenger demands.
Finally, respectful commute metrics should be positioned as part of overall service quality and user satisfaction, not as personal fault-finding. User satisfaction indices, women-centric safety protocols, and commute experience dashboards can include behavior scores alongside OTP and safety indicators. This framing encourages vendors and drivers to view courtesy as a path to more stable contracts and predictable earnings, while giving HR and transport heads auditable proof that driver behavior is being managed systematically, not reactively.
What should our communication playbook include for recurring issues like cab no-shows or double bookings so employees don’t feel ignored?
B0448 Playbook for chronic service issues — In India’s corporate employee mobility (EMS) for shift-based workforces, what does a realistic ‘communication playbook’ include for chronic issues like repeated cab no-shows or double bookings so employees don’t feel ignored?
Communication playbook for chronic EMS issues in India (no‑shows, double bookings)
A realistic communication playbook for chronic EMS issues combines clear SOPs, command-centre visibility, and time-bound response rules so employees never feel ignored even when a cab fails. The core principle is that the transport team must communicate before, during, and after every disruption with evidence, not excuses.
Most organizations anchor this in a 24x7 command centre or transport desk that has real-time trip visibility and alert supervision. Repeated no-shows and double bookings are treated as “managed incidents” with predefined triggers, not ad-hoc problems. When a GPS signal drops or a cab misses a geofence, the command centre uses tools like the Alert Supervision System and Transport Command Centre reporting to push proactive updates instead of waiting for employee complaints.
A practical playbook usually defines three layers of communication.
- Pre-trip. Auto-confirmations from the employee app with driver, vehicle, ETA, and a cut-off time for changes. Clear messages on roster freeze times and SOPs for last-minute edits, supported by ETS Operation Cycle controls.
- During disruption. If a cab has not reached a checkpoint, the command centre calls the driver first, then calls or messages the employee with a revised ETA or instant reassignment. SOS and women-centric protocols ensure night-shift and female-first cases are prioritized and escalated via a visible matrix.
- Post-incident. Same-day closure note stating what went wrong, what was done immediately (alternate cab, cost waiver), and what has changed structurally (driver warning, vendor de-tagging, route change), with clear ownership at the vendor and transport desk level.
The playbook also links every communication step to measurable SLAs for response time and closure, logged in systems like the Commutr platform or the central dashboard. Most successful EMS programs then feed these incident and feedback logs into a User Satisfaction Index, so HR can show employees that patterns of no-shows or double bookings lead to visible changes in routing, vendor allocation, or driver retraining rather than being ignored.
measurement, evidence, and leadership-ready reporting
Capture audit-ready data and credible evidence to demonstrate improvements to executive leadership, while avoiding data distortion or false attribution.
If HR wants a premium experience but Procurement pushes lowest cost, where do contracts usually fail in ways that later create employee backlash?
B0449 Contract traps that trigger backlash — In India’s enterprise-managed Employee Mobility Services (EMS), when HR wants a ‘premium experience’ to support EVP but Procurement is optimizing for lowest cost, what are the common failure points in the contract that later create employee backlash?
In India’s enterprise Employee Mobility Services, contracts that chase lowest cost while promising a “premium” experience usually fail where expectations are not encoded as measurable, enforceable clauses. The most common failure points are vague service definitions, weak safety/compliance requirements, and misaligned SLAs that ignore employee experience and women’s safety realities in shift operations.
Contracts often describe “premium” service qualitatively but miss hard metrics for reliability. On-time performance targets, trip adherence, and exception-closure SLAs are either absent or set without penalties, so vendors optimize fleet and driver costs instead of OTP and route adherence. This leads to late pickups, missed shift windows, no-show confusion, and repeated night-shift disruptions that employees experience directly.
Safety and women-safety requirements are frequently under-specified. Escort rules, geo-fencing, SOS response times, and driver credential currency are not written as auditable obligations tied to payment or continuation of contract. This creates gaps during night shifts, irregular enforcement across cities, and weak incident readiness, which becomes visible the first time there is a safety scare or social media escalation.
Commercial structure is another failure zone. Contracts focus on headline per-kilometer or per-trip rates but ignore dead mileage caps, seat-fill targets, and hybrid-work variability. Vendors respond by over-pooling, stretching routes, using older vehicles, or cutting spare-buffer capacity. Employees then see longer detours, cramped pooling, and poor vehicle quality, while HR’s “premium” narrative collapses.
Data and auditability are typically not embedded. Without obligations for trip logs, GPS trails, and complaint closure reporting, HR cannot answer leadership questions about “how often this happens,” and ESG or security teams cannot substantiate safety or reliability claims. This loss of traceability fuels employee distrust, since issues feel anecdotal and unresolved rather than systematically addressed.
images:
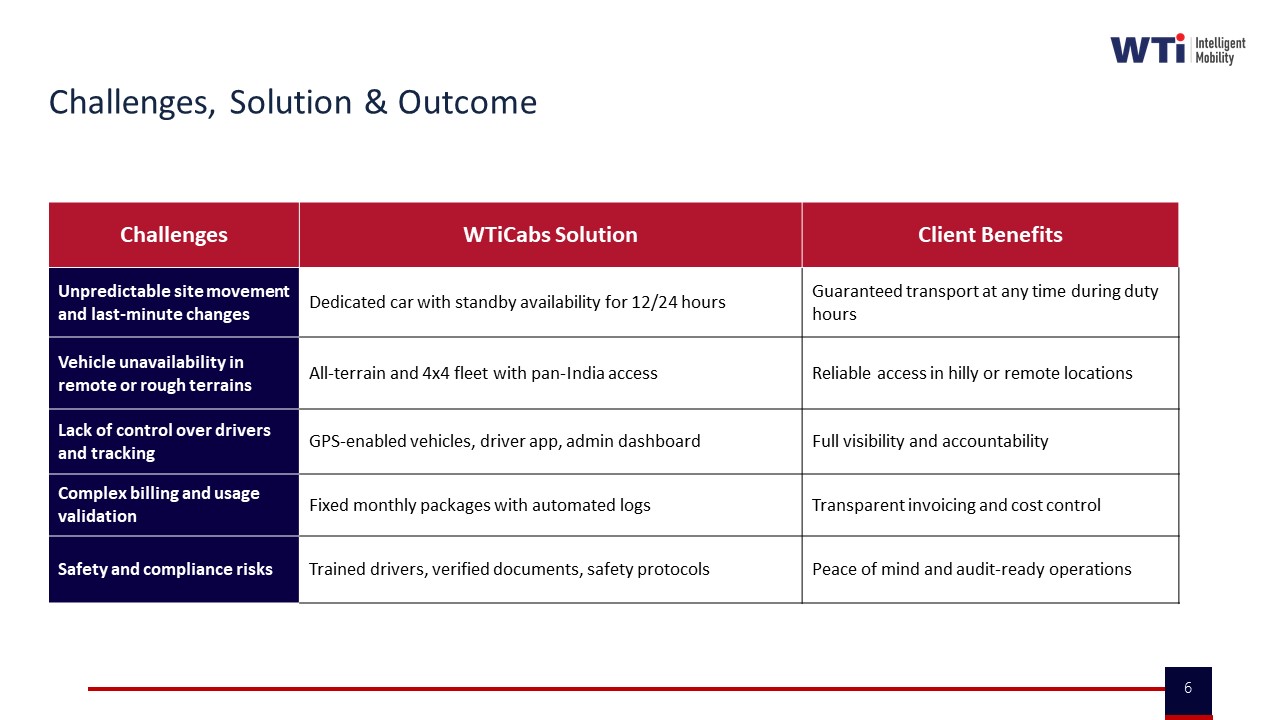
How do we design escalation rules so our night coordinators can act at 2 a.m. without fear of being blamed later?
B0450 Empower night coordinators safely — In India’s corporate employee transport (EMS), how do you design escalation matrices so junior coordinators can act confidently at 2 a.m. without fearing they’ll be blamed later for making the ‘wrong call’?
In Indian corporate employee transport, escalation matrices work best when they codify decision rights by scenario and timeband, and when leadership explicitly protects coordinators who follow the SOP. Junior coordinators act confidently at 2 a.m. when they have clear authority levels, predefined playbooks for common failures, and audit trails that show they stayed within agreed rules.
A common failure mode is escalation charts that only show “who to call” but not “who can decide what.” Coordinators then hesitate to reroute a cab, approve a backup vehicle, or call security because they fear post‑facto blame. In mature EMS operations, the matrix defines for each incident type, such as “cab no-show,” “female employee stranded,” “app/GPS outage,” or “political/traffic disruption,” what actions are mandatory, what decisions are allowed at L1, and when escalation to L2 or security is non‑negotiable. Each step links to Command Center operations, safety and compliance requirements, and business continuity playbooks so coordinators are never improvising from scratch.
To reduce fear of blame, organizations need explicit governance. Leadership in transport, HR, and Security must sign off that decisions taken within the matrix and documented in the command-center tools are presumptively “right,” even if outcomes are imperfect. This creates a traceable chain-of-command, aligns with incident response SOPs and women-safety policies, and feeds back into quarterly reviews where matrices are refined using data from on-time performance, incident logs, and business continuity drills.
What can we realistically automate in grievance intake/triage/closure so Admin gets relief, without losing the human sensitivity needed for safety complaints?
B0451 Automate grievances without losing empathy — In India’s corporate ground transportation (EMS/CRD), what does ‘set it and forget it’ realistically mean for admin teams—what can be automated in grievance intake, triage, and closure without losing the human sensitivity needed for safety-related complaints?
In India’s corporate ground transport, “set it and forget it” for admin teams means automating the mechanics of grievance intake, routing, tracking, and reporting, while keeping human control over safety-critical conversations and final closure decisions. Automation should remove manual chasing and blind spots, not replace a human when an employee is scared, unsafe, or angry.
Most organizations can safely automate how grievances are captured and organized. Employee, driver, and vendor apps can standardize intake with in-app forms, SOS buttons, and tagged categories for issues like late pickup, no-show, overcharging, or app glitches. Systems can log every ticket with trip ID, timestamp, GPS trail, and involved vehicle or driver, so admins do not have to reconstruct events from calls and emails.
Routing and triage can also be automated. Rules can route billing disputes to finance support, routing errors to the transport desk, and app issues to IT, while auto-escalating high-severity tags such as women-safety complaints, SOS triggers, or repeated OTP failures to the command centre and security or HR. Centralized command dashboards and alert supervision systems can give a single operational view, with SLA timers and escalation matrices to ensure nothing silently ages in someone’s inbox.
Closure workflows and reporting are strong candidates for “set and forget.” Systems can enforce that no grievance closes without an action code, attach GPS and trip logs for audits, and push CSAT or feedback prompts after resolution. Admins can then work from a queue of prioritized exceptions, using evidence-rich tickets instead of starting from scratch each time.
Human sensitivity must remain for safety, women-centric issues, and situations where trust is fragile. A common pattern is to combine automated intake and triage with explicit rules that require live human engagement for SOS events, any allegation of harassment or unsafe driving, and repeat complaints on the same route, driver, or timeband. Command centres and transport heads can use automation to see risk early and intervene personally, rather than only reacting when a crisis escalates to senior leadership.
Admin teams typically look for designs where routine noise is handled autonomously but the system never auto-closes a high-severity ticket. Most rely on command-centre playbooks, HSSE roles, and women-safety protocols to define which complaint types always trigger a call-back or manual review. This balance gives predictable SLA compliance, audit-ready evidence, and calmer night shifts without turning sensitive grievances into anonymous, automated transactions.
If we run transport across multiple sites, how do we keep grievance handling consistent so employees don’t feel it’s unfair between locations?
B0452 Consistent grievance handling across sites — In India’s corporate Employee Mobility Services (EMS) across multiple office locations, how do you keep grievance handling consistent so employees don’t perceive unfairness between sites that damages morale and employer brand?
In multi-location Employee Mobility Services in India, consistent grievance handling comes from running one governed playbook with a single source of truth for complaints, rather than letting each site improvise. Organizations that succeed standardize policies, SLAs, and escalation paths across offices, and then enforce them through a central command center, audit trails, and data-backed reporting.
A common failure mode is allowing each facility or vendor supervisor to “handle it their way”. Employees then compare experiences between locations and perceive bias. Centralized governance counters this by defining uniform commute entitlements, safety protocols, and response SLAs, and by routing every complaint through a shared ticketing or command-center workflow with clear time-bound closure rules.
A central NOC or Transport Command Centre can monitor OTP, safety incidents, and complaint closure across all sites in real time. This control-room view enables early alerts when one location is slipping on SLA or soft skills, so operations can coach local teams before reputational damage spreads. Case studies from adverse-weather and women-safety programs show that real-time communication plus dynamic routing and a clear escalation matrix can preserve both OTP and perceived fairness.
To keep employees from feeling that “HQ gets priority and satellite offices suffer”, organizations typically standardize three elements:
- One grievance taxonomy and SOP for what qualifies as a complaint, incident, or safety escalation.
- Common SLAs for acknowledgement, investigation, and closure, enforced for every site and every vendor.
- Transparent feedback loops and dashboards so HR and Transport can see complaint patterns by location and vendor, and communicate actions taken.
When this governance is in place and backed by continuous compliance monitoring, women-safety protocols, and audit-ready logs, employees experience fewer discrepancies between locations. That reduces “us vs them” morale issues and stabilizes employer brand around transport reliability and safety rather than exceptions.
How should the control room document and share RCA for repeat failures so HR can brief leadership confidently without sounding defensive or just blaming the vendor?
B0453 RCA communication that protects HR — In India’s corporate employee transport (EMS), how should the transport NOC document and communicate root-cause analysis for repeated failures so HR can defend decisions to leadership without sounding defensive or blaming the vendor?
In Indian corporate employee transport, the transport NOC should treat every repeated failure as a structured, auditable “incident record” that links data, root cause, corrective action, and prevention, rather than as a blame note on a vendor. A clear, evidence-backed template allows HR to answer leadership with facts, trends, and actions, not emotions or finger-pointing.
The NOC needs a standard RCA format that is used every time. Each record should capture the shift window, affected routes or trips, OTP impact, safety impact, and escalation timeline based on live command-center data and trip logs. Command-center workflows and alert systems should be documented so leadership can see that issues were detected and triaged through defined SOPs, not reactively.
Root cause must be expressed in system terms, not personalities. For example, the RCA should classify failures as routing logic gaps, roster quality issues, vendor fleet shortfall, driver non-compliance, technology downtime, or external disruptions, using language consistent with existing governance and BCP collateral. Where vendors are involved, the NOC should reference SLA terms, compliance status, and corrective actions agreed in governance forums instead of attributing generic “vendor failure.”
To help HR defend decisions, every RCA pack should end with three elements: what has already changed operationally, what is in the improvement backlog with target dates, and how the command center will monitor for recurrence. This shifts the narrative from “what went wrong” to “what we now control,” and gives HR a stable, repeatable story they can take into leadership reviews and audits without sounding defensive.
images:
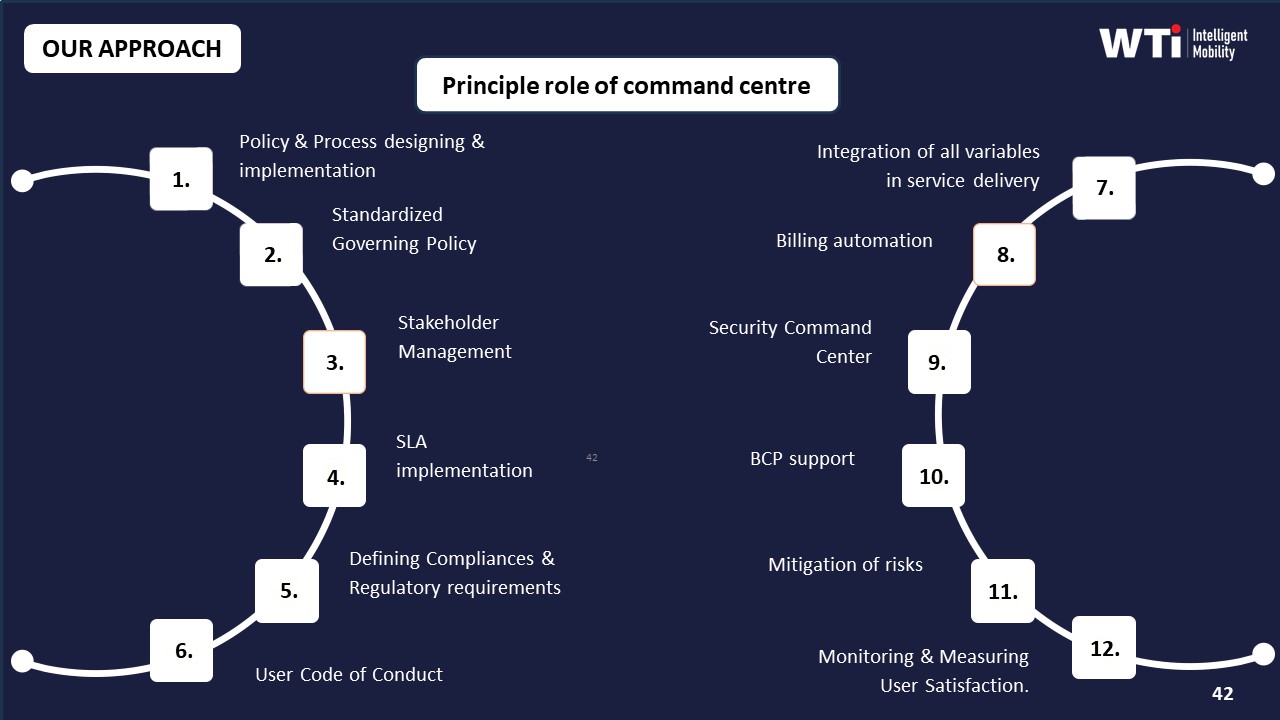
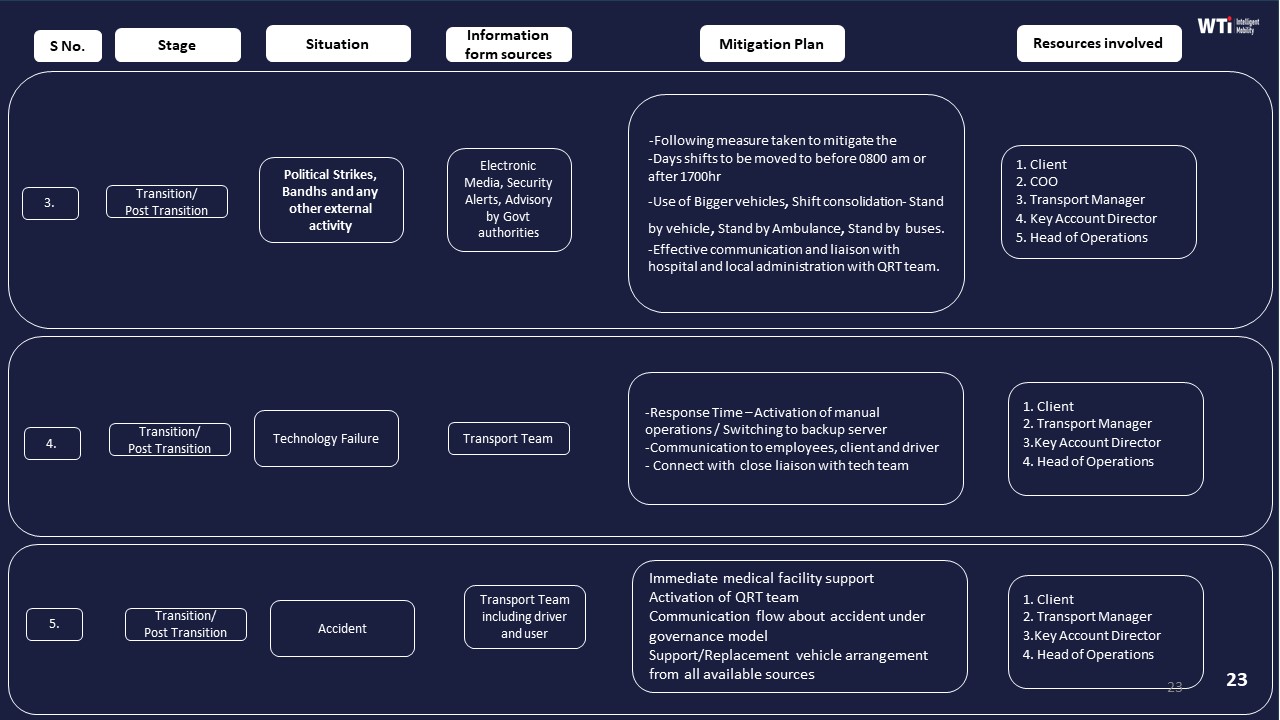
How do we make sure our grievance process doesn’t expose the complainant’s identity to drivers or others, which would scare people from reporting?
B0454 Protect complainant identity in workflows — In India’s enterprise mobility (EMS) for women and night shifts, how do you ensure grievance workflows don’t accidentally expose the complainant’s identity to drivers, supervisors, or peers, which could create fear and suppress reporting?
In Indian enterprise mobility for women and night shifts, grievance workflows protect complainant identity by separating “who reported” from “what happened,” and by routing only anonymized, need‑to‑know details to drivers, supervisors, and peers. Identity is held in a restricted HR/Security system with audit logs, while operations only see case IDs, trip metadata, and action instructions.
Most organizations that succeed treat the grievance system like an HR and security tool, not a transport helpdesk. The WTicabs ecosystem shows safety handled via dedicated cells, SOS control panels, and centralized command centers, where incidents are logged with tickets, escalated through a defined matrix, and acted on using dashboards instead of ad‑hoc calls to employees or drivers. This reduces the need to reveal who raised the issue while still enabling immediate operational action, like driver suspension, retraining, or route changes.
A common failure mode is letting grievances flow directly through local transport desks or supervisors. These desks often know employees and drivers personally, which increases the temptation to “check directly” with the complainant or the accused. That behavior creates fear and suppresses future reporting. Centralized compliance management, women‑centric safety protocols, and command‑center based monitoring counter this by enforcing standardized SOPs, centralized recording, and traceable actions.
To keep life easier for the Facility / Transport Head while protecting anonymity, practical guardrails usually include:
- Use a central command center or safety cell as the only point of intake for incidents from SOS buttons, calls, or app forms, with clear segregation from day‑to‑day rostering functions.
- Log each grievance as a unique incident ID with trip details, vehicle, route, and time, but do not expose the complainant’s name or contact to transport operations dashboards.
- Communicate actions to vendors and drivers in behavioral and procedural terms only, such as “based on a compliance review this driver is off‑roster pending training,” without naming who complained.
- Route all follow‑up with the complainant through HR or a women’s safety cell, using dedicated channels, not via the transport desk or driver.
- Lock down access rights in mobility apps and dashboards so only HR/Security can see personally identifiable grievance details, with audit‑logged access.
These controls work best when combined with visible women‑centric safety protocols, driver compliance and induction programs, and structured HSSE governance. Employees then see that complaints are handled centrally, quietly, and with real consequences, without exposing them to the people they reported.
After an incident, what follow-up should we do—when, through which channel, and owned by whom—so trust is rebuilt instead of making things worse?
B0455 Post-incident follow-up to rebuild trust — In India’s corporate ground transportation (EMS), what should a post-incident employee follow-up look like (timing, channel, ownership) so the organization rebuilds trust rather than triggering a second wave of dissatisfaction?
A post-incident employee follow‑up in Indian EMS works best as a fast, staged protocol. The organization should respond within defined time windows, use predictable channels the employee already trusts, and assign clear ownership across Transport, HR, and Security so the employee never has to “chase” the system for answers.
Timing: Clear SLAs for each stage
The first acknowledgement should reach the affected employee within 15–30 minutes of the incident being logged. A short message is sufficient at this stage if it confirms who is handling the issue and how to reach them. Within 2–4 hours, a named person from Transport or Security should speak to the employee by phone to capture facts, check on physical and emotional state, and explain immediate safeguards. Within 24–72 hours, HR should close the loop with a documented update on findings, actions taken, and any policy or route changes.
Channel: Use layered, low‑friction communication
Initial acknowledgement is most stable over SMS or WhatsApp plus in‑app notification when available. The primary fact‑finding and reassurance step should be a voice call from a trained supervisor or safety owner rather than email. Written closure should follow via email and in‑app or portal, so there is an auditable trail for HR, Security, and Procurement aligned with centralized command‑center and incident dashboards.
Ownership: One face to the employee, shared backend responsibility
A single “case owner” should be visible to the employee, usually the Transport or Command Center lead, with HR as co‑owner for any safety or dignity risk. Security or EHS should own root‑cause analysis and corrective actions, with clear documentation in the incident response SOP and mobility governance reports. Finance and Procurement should stay in the background, using the same incident record later for SLA and vendor governance, so the employee only experiences support and resolution, not internal blame shifting.
From an IT lens, how do we check if the employee app and grievance channels will be too confusing and trigger pushback that hurts adoption?
B0456 Assess cognitive load and backlash risk — In India’s corporate Employee Mobility Services (EMS), how can a CIO evaluate whether employee-facing apps and grievance channels will increase cognitive load (too many logins, confusing UX) and spark workforce pushback that undermines adoption?
In India’s corporate Employee Mobility Services, a CIO can evaluate cognitive load and adoption risk by stress‑testing apps and grievance channels against a small set of concrete signals. The CIO should test how many different identities, workflows, and attention channels an employee must juggle to complete basic transport tasks and raise or track complaints. Any design that fragments these flows across multiple apps, logins, or inconsistent UX patterns will reliably trigger workforce pushback and low adoption.
A practical evaluation starts with mapping the full trip lifecycle from an employee’s point of view. The CIO should document how staff register once, book or roster, receive trip notifications, board, track rides, escalate issues, and give feedback. This flow should then be compared against integrated solutions such as the Commutr employee app, where booking, real‑time tracking, SOS, notifications, and support sit behind a single interface and consistent journey. If the proposed setup replicates features already available in HRMS, existing employee apps, or the transport app, the duplication itself is a cognitive‑load red flag.
CIOs should also insist on short, task‑based usability tests with real employees from different shifts and locations. Employees should be able to onboard in a few clear steps, as seen in simple four‑step registration flows, and complete core actions like checking pickup time or raising an SOS without training. If users cannot do this reliably in their first attempt, adoption will falter and frontline operations teams will receive more calls instead of fewer.
To avoid fragmented attention and grievance fatigue, the CIO should check that incident reporting and SOS use the same app and identity as routine commuting. Centralized command‑centre tooling, alert supervision systems, and SOS control panels only reduce cognitive load when employees do not have to remember separate numbers, forms, or channels for normal and emergency situations. Any design that requires a different app or login only during incidents is likely to fail when it is needed most.
A CIO can use the following checks before approving an EMS employee app and grievance stack:
- Count logins and identities per user.
- Count apps and channels required across the commute and complaint lifecycle.
- Measure steps and decisions per core task through short usability tests.
- Verify reuse of existing enterprise identity and notification channels.
- Confirm that emergency and grievance flows reuse the same UX as daily operations.
If these checks show rising complexity for employees or added support load for transport teams, the CIO can push for tighter integration, fewer apps, and a single‑window, role‑based experience before scaling EMS technology.
How should HR and Employer Branding align on what we say about commute safety and reliability so it stays credible and doesn’t backfire when exceptions happen?
B0457 Align EVP messaging with reality — In India’s corporate mobility programs (EMS/CRD), how should Marketing/Employer Branding and HR coordinate messaging about commute safety and reliability so claims are credible and don’t backfire when exceptions happen?
In India’s corporate mobility programs, Marketing/Employer Branding should only make commute safety and reliability claims that HR can back with live data, SOPs, and incident logs from EMS/CRD operations. Claims remain credible when they are framed as “governed processes and measurable outcomes” rather than “guarantees,” and when HR owns an internal playbook for what is said externally and what evidence exists if an exception is escalated.
Marketing and HR alignment works best when HR treats commute safety as an “audit-ready product” before it becomes an “employer brand story.” HR should first ensure there is a clear safety framework in employee mobility services, including women-centric protocols, centralized command center monitoring, driver compliance checks, and SOS workflows, as shown in the safety and women-safety collaterals from WTi’s ecosystem. Only then should Marketing describe these controls, and even then with precise wording such as “24/7 GPS-tracked cabs with women-centric safety protocols and defined escalation matrices,” not “zero incidents” or “100% safe.”
A common failure mode is Marketing over-claiming around EV safety, night-shift routing, or “always-on” command centers without matching HR’s actual SLA and exception data from the transport command centre, alert supervision, and business continuity plans. This creates reputational risk when a single late pickup, geofence breach, or safety complaint surfaces and employees compare their lived experience with the campaign message. To avoid that, HR and Transport should pre-agree “disclosure limits” for metrics such as on-time performance, incident response times, or EV uptime, and Marketing should reference only those verified ranges.
Practical coordination between Marketing/EB and HR for EMS/CRD usually requires a simple joint SOP covering three areas:
- Approved language and numbers: HR, Transport, and Security validate which safety features, SLAs, and reliability metrics are stable enough to be quoted in employer branding content.
- Exception narrative: HR defines how to communicate when there are disruptions, using the same language as business continuity and safety collaterals, so external messaging acknowledges that controlled exceptions are anticipated and managed.
- Evidence pack: HR curates a set of dashboards, case studies, and compliance artefacts (for example, women-centric safety protocols or command centre monitoring views) that Marketing can reference or summarize without exaggeration.
When Marketing and HR stay inside this jointly agreed “evidence-backed envelope,” commute narratives strengthen trust instead of raising expectations that daily EMS/CRD operations cannot support.
What SOPs or quick training should we give guards/reception so boarding disputes don’t become daily friction and escalations?
B0458 SOPs for guards and reception — In India’s shift-based employee transport (EMS), what practical training or SOP support should be provided to on-ground security and reception teams so boarding disputes and last-minute escalations don’t create daily friction for employees?
In India’s shift-based employee transport, on-ground security and reception teams need simple, written SOPs plus repeat training focused on verification, exceptions, and escalation so boarding is predictable and not negotiated at the gate each day. Clear rules for ID checks, roster validation, women-safety protocols, and last-minute changes reduce friction for employees and protect the transport and HR teams from avoidable nightly disputes.
Security and reception teams work best when they use the transport system, not manual judgment. A standard process for each trip should cover how to verify employee identity against the manifest or app, how to handle “extra” employees at the vehicle, and how to log no-shows or reassign seats. This works especially well when security has access to a single-window dashboard or transport app view that shows live rosters, route changes, and vehicle details, as seen in command-center and dashboard collateral and employee/driver app features in the context.
Friction usually arises in three zones. One zone is entitlement confusion when eligibility rules are not visible at the gate. Another zone is last-minute roster changes that do not flow cleanly from HRMS or the transport app to security. A third zone is women-safety rules during night shifts when escort or “first pick-up/last drop” protocols are unclear. Training and SOPs should therefore be structured around a few repeatable flows.
Useful SOP elements include:
- A standard pre-shift briefing checklist for security and reception that reviews routes, special cases, and any blocked IDs for that shift.
- Step-by-step boarding scripts for guards and receptionists that define what to say and check at boarding to avoid ad-hoc decisions or arguments.
- A clear exception-handling flow for walk-ins, swapped shifts, visitors, and missed cabs that defines who can approve, how to record it, and which backup option to use.
- Night-shift women-safety protocols that specify escort requirements, seating order, SOS triggers, and documentation needs.
- An escalation matrix with time-bound response expectations so guards know when to call transport desk, command center, or HR, instead of negotiating with employees.
A common failure mode is training security only once at launch and treating procedures as static. Most organizations do better when they run quick, daily shift-wise briefings for drivers and security teams, maintain visual SOP posters at reception and boarding points, and refresh training before peak seasons, severe weather, or policy updates. Centralized command centers and alert supervision systems help when they back these SOPs with real-time alerts and support, rather than leaving guards isolated when GPS fails or vehicles are delayed.
images:

When employees complain about AC/vehicle quality, how do we decide what’s a policy choice vs a vendor execution issue, without creating nonstop disputes?
B0459 Separate policy vs vendor issues — In India’s corporate employee mobility (EMS), when employees say ‘it’s too cold’ or complain about vehicle quality, how do you decide which experience issues are policy decisions (fleet spec) versus vendor execution problems (non-compliance) without creating constant disputes?
In Indian corporate employee mobility programs, teams separate “policy” experience issues from “vendor execution” problems by first codifying comfort and vehicle-quality standards into fleet specifications, and then treating any deviation from those written specs as a compliance issue visible in audits and SLAs. This creates a clear line between what is a design choice the company has made, and what is a failure to deliver against that design.
A common pattern is to define comfort-related expectations inside the EMS operating model instead of leaving them as ad‑hoc complaints. Organizations specify vehicle age and condition, interior cleanliness, and statutory documentation in written fleet compliance and induction requirements. They also use checklists for mechanical and safety items like seat belts and brakes. When these standards are documented and automated into centralized compliance management, vendor lapses surface as measurable non-compliance instead of becoming subjective debates.
Cab temperature or “too cold” complaints are usually treated as a policy topic linked to employee experience, not only as vendor behavior. Transport heads work with HR to decide default AC settings or temperature bands per shift, site, or persona. Once agreed, these temperature expectations are embedded into SOPs, driver training, and driver apps. At that point, a driver ignoring the SOP becomes an execution issue, while employees requesting a different standard triggers a policy review.
To avoid constant disputes, mature EMS programs use three mechanisms. First, they define a minimum fleet spec and comfort baseline that all vendors must comply with across locations. Second, they run periodic route and vehicle audits using checklists and dashboards to separate pattern issues from one-off complaints. Third, they channel employee feedback and NPS into structured reports that feed quarterly reviews, so changes to policy are driven by data rather than individual escalations.
During heavy rain/protests/roster shocks, what safeguards should we have so complaint volume doesn’t explode and morale stays stable?
B0460 Experience safeguards during disruptions — In India’s enterprise Employee Mobility Services (EMS), what experience safeguards should be built for peak-stress scenarios like heavy rains, protests, or sudden roster changes so complaint volume doesn’t explode and morale doesn’t collapse?
In India’s enterprise Employee Mobility Services, peak‑stress safeguards need to be built around early alerts, predictable backups, and clear SOPs so that employees see controlled adjustments, not chaos. Experience stays stable when a 24x7 command room, playbook-based rerouting, and transparent communication absorb the shock before it reaches the floor.
A common failure mode is treating heavy rain, protests, or sudden roster changes as ad‑hoc incidents instead of pre-classified scenarios with predefined routing, fleet buffers, and escalation paths. Complaint volume spikes when employees get no proactive information, when GPS or apps glitch without manual fallback, and when drivers and transport desks receive conflicting instructions. Morale drops fastest during night shifts and women’s commutes if safety assurances feel improvised.
The most resilient EMS setups use command-center operations, dynamic route recalibration, and business continuity planning together. Centralized NOC or transport command centers monitor weather, traffic, and city alerts and then adjust rosters and routes before shift windows open. Business continuity plans define buffers for cab shortages, political strikes, technology failures, and natural disruptions, with clear roles and time-bound mitigation steps. Data-driven insights from telematics and past deviations help define where to pre-position standby vehicles, how to cap dead mileage, and how much buffer capacity to hold by route or timeband.
Key experience safeguards that reduce complaints and keep morale intact include:
- Predefined disruption playbooks for rain, protests, road closures, and tech downtime, including alternate routes, pickup window relaxations, and escort rules.
- Fleet and driver buffers sized by shift and corridor, so additional vehicles can be activated quickly without renegotiation.
- Centralized command center visibility with live tracking, alert supervision (overspeeding, geofence violations, device tampering), and escalation matrices.
- Employee and driver apps that support offline or manual modes for trip manifests, OTPs, and SOS when networks or GPS are unstable.
- Proactive communication SOPs that push revised ETAs, route changes, and safety updates before employees raise tickets.
- Women-centric and night-shift safety protocols that still hold under stress, including verified chauffeurs, route audit trails, and SOS control panels.
- Integrated BCP coverage for system downtime, cab shortages, and external disruptions, including redundancy and interim power or tech backup plans.
These safeguards improve on-time performance and trip adherence during disruption, but they also require investment in routing engines, telematics dashboards, and continuous assurance workflows. They reduce firefighting effort for transport heads and HR teams, but they also demand disciplined governance, driver management and training, and vendor and statutory compliance control.
How do we detect when people stop complaining but are actually disengaging—especially women on night shifts—so we don’t assume experience is improving?
B0461 Detect silent disengagement from commute — In India’s corporate employee transport (EMS), how do you prevent ‘silent suffering’—employees, especially women on night shifts, who stop complaining and just disengage—so HR doesn’t get a false sense of improving experience?
In Indian employee transport programs, silent suffering is reduced when complaints, fear signals, and near-misses are captured automatically from operations data, not only from people raising tickets. Reliance on low complaint volumes as a “good news” signal usually masks disengagement, especially for women on night shifts.
A structured EMS program treats the commute as an auditable process. Transport teams use real-time command-centre monitoring, alert supervision, and data-driven insights to surface problems early. These tools track OTP%, route deviations, SOS triggers, geofence violations and over-speeding incidents so that HR sees risk patterns even when employees do not log complaints. Case studies in this context show on-time arrival rates of 98% after dynamic routing and monsoon management, which indicates that proactive control-room intervention can stabilise operations before dissatisfaction hardens.
Silent suffering also drops when there are clear user protocols, women-centric safety measures, and visible safeguards. Women-only fleets, verified drivers, escort and POSH training, and panic/SOS features in employee apps signal that it is safe to report issues. Dedicated women-safety cells, driver assessment and training programs, and centralized compliance management create traceable evidence of how incidents are prevented and handled.
To avoid a false sense of improvement, HR and Facility heads can track a small, fixed set of leading indicators instead of complaint counts alone. Useful signals include night-shift OTP by gender, usage of SOS and helplines, geofence and over-speed alerts on night routes, seat-fill and no-show rates, and closure SLAs for even “minor” grievances. Periodic user-satisfaction surveys and structured floor connects, integrated with command-centre dashboards, complete the picture.
images:
What should our single view of transport issues include so HR, Ops, Security, and vendors stop arguing about what actually happened?
B0462 Single source of truth for grievances — In India’s corporate ground transportation (EMS), what should a ‘single source of truth’ for employee experience issues include—complaints, incident logs, vendor actions, and closure notes—so cross-functional teams stop arguing about what happened?
A ‘single source of truth’ for employee experience issues in Indian EMS must capture the full trip-linked story in one place. It must join employee complaints, safety incidents, vendor actions, and closure notes to objective trip, roster, and GPS data so HR, Transport, Security, Finance, and vendors see the same facts.
The record needs a unique incident ID and trip linkage for every case. It needs basic employee and route context, including shift, gender flag for women-safety cases, vendor, vehicle, and driver identifiers. It should pull objective telemetry from the mobility platform, such as GPS trace, timestamps, OTP status, and any SOS or geofence alerts triggered during the trip.
The same record should store the employee’s complaint text or category, plus any attachments, alongside structured safety and compliance fields. These fields include whether escort rules applied, whether statutory or internal women-safety protocols were triggered, and whether any HSSE violations occurred. This connects experience issues directly to compliance and duty-of-care questions.
The system must then log vendor and command-center actions with precise timestamps. It should record who acknowledged the issue, what immediate mitigations were taken (driver replacement, alternate cab, manual routing, call to employee), and what root cause was identified. It should also capture whether the event affected OTP, no-shows, or shift adherence.
Closure notes must be standardized and auditable. Each case should record final resolution, approvals by HR or Security where relevant, communication back to the employee, and whether any penalties, coaching, or process changes were applied to the vendor or drivers. This enables pattern analysis across multiple incidents and vendors.
To prevent disputes, the same system should be the reference for dashboards, QBR reviews, and billing or penalty discussions. It should support exportable, time-stamped reports that correlate employee-experience incidents with fleet uptime, SLA breaches, women-safety controls, and vendor performance, so cross-functional teams debate decisions, not basic facts.
How do we make sure employees see real outcomes and fair resolutions, not just faster acknowledgements that feel performative?
B0463 Move from acknowledgements to outcomes — In India’s corporate Employee Mobility Services (EMS), how do you structure governance so employees see consistent outcomes (fair resolution) rather than just faster acknowledgements, which can feel like performative customer service?
In Indian corporate Employee Mobility Services, governance must be built around transparent, auditable closures and pattern-level fixes, not just rapid acknowledgements at the helpdesk layer. Employees perceive fairness when every complaint has a clear owner, a time-bound closure SLA, visible outcomes, and when recurring issues actually disappear from daily experience.
A practical model starts with a central 24×7 command or transport control centre that acts as the “single source of truth” for OTP, safety, and incident data. This command centre uses live tracking, alert supervision, and exception dashboards to detect issues early, but it also owns the end-to-end closure workflow for delay, safety, or service-quality incidents. Governance improves when escalation matrices, business continuity plans, and women-centric safety protocols are codified, and every incident can be traced from trigger to resolution with a digital audit trail.
Consistent outcomes require layered review above the control room. Leadership, senior management, and service delivery executors need a fixed cadence of reviews where they see complaint patterns, CO₂ and safety dashboards, EV uptime reports, and user satisfaction indices, and then agree on route redesigns, vendor changes, driver retraining, or fleet/charging upgrades. Employees interpret fairness when recurring monsoon delays, night-shift safety concerns, or EV range issues are addressed through visible changes to routes, buffers, or SOPs, not just apologetic messages.
To shift perception from “performative” to “fair and effective,” organizations typically lock in four elements:
- Clear, published SLAs for response and closure, with ownership at each level of the escalation matrix.
- Integrated data from apps, GPS, safety tools, and billing, so every case can be reconstructed and explained.
- Business continuity and contingency playbooks that prevent repeat failures in strikes, tech outages, or weather events.
- Regular feedback loops and surveys where employees see their inputs translated into route, safety, or policy changes.
How do we resolve the tension where Ops wants fewer escalations but HR wants every employee to feel heard, and both sides feel the other doesn’t care?
B0464 Resolve HR vs Ops experience tension — In India’s corporate employee mobility (EMS), what’s the best way to handle conflict when the transport team’s goal is fewer escalations but HR’s goal is ‘every employee feels heard,’ and both sides accuse the other of not caring?
In Indian corporate employee mobility, conflict between Transport and HR reduces when both teams share one operating truth. Every incident must be handled through a single, agreed SOP that protects shift reliability and also gives each employee a dignified, traceable voice.
The breakdown usually happens because Transport optimizes for on-time performance and fewer escalations, while HR optimizes for emotional reassurance and perception of care. Without a shared process, Transport sees HR as “over-escalating” and HR sees Transport as “hiding” or “minimizing” issues. A common failure mode is informal WhatsApp complaints to HR that never hit the command center, so Transport cannot fix patterns but is still blamed.
A practical approach is to anchor on a clear, control-room style framework. Every complaint must enter one ticketing channel linked to the mobility platform and command centre logs. Each ticket should have a severity code, a response SLA, and a close-out note that HR can see and use in conversations with employees. This preserves operational calm for the Transport Head and gives HR evidence of care.
Three concrete guardrails usually help:
- Define a joint “incident taxonomy.” For example, critical safety vs service quality vs experience, each with different SLAs and escalation paths.
- Run a fixed weekly 30-minute HR–Transport review using command-centre and app data, focusing on top recurring issues instead of individual blame.
- Publish a simple, two-line promise to employees. “Your complaint will be acknowledged within X minutes and resolved within Y hours, and you will see the outcome.”
This approach aligns EMS priorities from the Industry Insight brief. It links employee experience, safety, and reliability into one auditable loop instead of competing narratives about “who cares more.”
What should managers handle in transport escalations versus HR/Facilities, and how do we stop shadow processes that confuse employees?
B0465 Define manager role in escalations — In India’s Employee Mobility Services (EMS), what role should line managers play in commute issue escalation versus HR and Facilities, and how do you prevent managers from creating shadow processes that confuse employees?
In India’s employee mobility programs, line managers should act as first-line listeners and documenters of commute issues, while HR and Facilities or Transport own formal escalation, vendor coordination, and policy decisions. Line managers should capture employee complaints, validate impact on work, and trigger defined escalation paths into HR and Transport, rather than improvising their own fixes or creating alternate channels.
Line managers are closest to attendance and productivity impact, so they are well placed to identify patterns in late pickups, safety concerns, or no-shows. They should log these issues in a common system or ticketing channel, tag shift details and teams affected, and support employees in using the official rider app or helpdesk, not bypassing it. A common failure mode is managers sharing personal driver numbers or ad-hoc WhatsApp groups, which fragments data and weakens SLA governance and audit trails.
To prevent “shadow processes,” organizations need a single, published SOP that explains who employees call for real-time trip issues, how night-shift safety or SOS is handled, and how formal complaints are raised and closed. Transport and HR should give line managers a simple playbook and dashboard view of OTP trends and complaint status, but restrict them from changing routes, vendors, or entitlements on their own. Clear communication, app-based workflows, and centralized command-center observability reduce confusion, keep evidence consolidated for audits, and protect managers from blame when things go wrong.
How do we tell if our grievance process is genuinely improving morale, not just lowering complaints because people have given up?
B0466 Verify morale improvement is real — In India’s corporate employee transportation (EMS), what practical indicators show that the grievance process is improving workforce morale (not just reducing visible complaints because employees give up)?
In Indian corporate employee transport, grievance processes improve workforce morale when transport KPIs, engagement signals, and safety metrics move positively together, not just when complaint counts fall. Morale improves when employees keep using channels, issues close faster with better outcomes, and commute reliability, safety perception, and attendance all strengthen in parallel.
Improving morale usually shows up as stable or rising complaint volumes through official channels, alongside a drop in repeat issues for the same route, driver, or vendor. Employees use in-app feedback, SOS, or helpdesk more when they trust action will follow, so a sharp decline in usage with no other change is often a warning sign, not a success metric.
Transport heads should track closure quality, not just closure count. That means more grievances resolved within defined SLAs, fewer escalations to HR or leadership, and visible process changes such as routing tweaks, driver retraining, or vendor swaps after patterns are detected. When command center tools and alert supervision systems are used well, they reduce live disruptions and protect night-shift and women employees before issues turn into crises.
Positive morale also reflects in commute-linked outcomes. On-time performance, fleet uptime, and Trip Adherence Rate typically improve when drivers are better managed, routes are optimized, and safety and compliance frameworks are enforced consistently. Over time, this supports better employee satisfaction scores for transport, higher usage of EMS instead of ad-hoc alternatives, and fewer transport-related no-shows.
Practical indicators that morale is genuinely improving include: - Steady or increased feedback volume with reduced repeat complaints on the same theme. - Higher share of proactive suggestions versus only crisis escalations. - Faster, SLA-bound closure with clear communication back to employees. - Improved commute satisfaction scores and reduced negative sentiment in informal channels. - Better OTP and safety records, especially on night and women-centric routes.
When grievance data is fed into a centralized dashboard and acted on through clear SOPs, the daily firefighting at the transport desk drops, escalations to senior leadership reduce, and employees begin to treat transport as a dependable utility rather than a daily stress point.
For a transport pilot, what should we define as success for experience/brand so HR can convince Finance and Procurement beyond ‘employees liked it’?
B0467 Define experience success for pilots — In India’s corporate Employee Mobility Services (EMS), what should a pilot success definition include for experience and employer brand—so HR can build credibility with the CFO and Procurement beyond ‘employees liked it’?
A credible EMS pilot success definition for experience and employer brand must convert “employees liked it” into a small set of stable, HR-owned metrics that link commute to attendance, safety perception, escalations, and retention intent. These metrics need clear baselines, target deltas, and evidence trails so HR can defend them with CFO, Procurement, and Audit teams.
HR should define employee-experience success in terms of a measurable Commute Experience Index rather than generic satisfaction. This index can combine ride-level feedback, complaint-closure SLAs, and a reduction in negative escalations to HR. A clear before/after comparison on late-logins, no-shows, and night-shift adherence shows how improved OTP and route adherence reduce productivity noise. For women’s mobility and night shifts, HR should track perceived safety via structured feedback plus evidence of escort compliance, SOS readiness, and zero serious-incident outcomes.
To build credibility with Finance and Procurement, HR should tie experience gains to operational reliability and control. This includes demonstrating improved on-time performance, lower exception-closure times, and fewer emergency interventions by the transport team. HR should insist on audit-ready trip logs, incident registers, and complaint-resolution reports so Procurement can see that SLA language is enforceable, and the CFO can see that improved experience does not come with hidden risk or opaque billing. Over time, HR can link better commute scores to lower attendance volatility or reduced attrition in shift-heavy functions, positioning EMS as a governed, data-backed lever for employer brand rather than a soft benefit.
images: